@浙大疏锦行知识点回顾:
1.通道注意力模块复习
2.空间注意力模块
3.CBAM的定义
最近临近毕业,事情有点多。如果有之前的基础的话,今天的难度相对较低。
后面说完几种模块提取特征的组合方式后,会提供整理的开源模块的文件。
现在大家已近可以去读这类文章了,应该已经可以无压力看懂三四区的很多这类文章。
作业:尝试对今天的模型检查参数数目,并用tensorboard查看训练过程

python
import torch
import torch.nn as nn
# 定义通道注意力
class ChannelAttention(nn.Module):
def __init__(self, in_channels, ratio=16):
"""
通道注意力机制初始化
参数:
in_channels: 输入特征图的通道数
ratio: 降维比例,用于减少参数量,默认为16
"""
super().__init__()
# 全局平均池化,将每个通道的特征图压缩为1x1,保留通道间的平均值信息
self.avg_pool = nn.AdaptiveAvgPool2d(1)
# 全局最大池化,将每个通道的特征图压缩为1x1,保留通道间的最显著特征
self.max_pool = nn.AdaptiveMaxPool2d(1)
# 共享全连接层,用于学习通道间的关系
# 先降维(除以ratio),再通过ReLU激活,最后升维回原始通道数
self.fc = nn.Sequential(
nn.Linear(in_channels, in_channels // ratio, bias=False), # 降维层
nn.ReLU(), # 非线性激活函数
nn.Linear(in_channels // ratio, in_channels, bias=False) # 升维层
)
# Sigmoid函数将输出映射到0-1之间,作为各通道的权重
self.sigmoid = nn.Sigmoid()
def forward(self, x):
"""
前向传播函数
参数:
x: 输入特征图,形状为 [batch_size, channels, height, width]
返回:
调整后的特征图,通道权重已应用
"""
# 获取输入特征图的维度信息,这是一种元组的解包写法
b, c, h, w = x.shape
# 对平均池化结果进行处理:展平后通过全连接网络
avg_out = self.fc(self.avg_pool(x).view(b, c))
# 对最大池化结果进行处理:展平后通过全连接网络
max_out = self.fc(self.max_pool(x).view(b, c))
# 将平均池化和最大池化的结果相加并通过sigmoid函数得到通道权重
attention = self.sigmoid(avg_out + max_out).view(b, c, 1, 1)
# 将注意力权重与原始特征相乘,增强重要通道,抑制不重要通道
return x * attention #这个运算是pytorch的广播机制
## 空间注意力模块
class SpatialAttention(nn.Module):
def __init__(self, kernel_size=7):
super().__init__()
self.conv = nn.Conv2d(2, 1, kernel_size, padding=kernel_size//2, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
# 通道维度池化
avg_out = torch.mean(x, dim=1, keepdim=True) # 平均池化:(B,1,H,W)
max_out, _ = torch.max(x, dim=1, keepdim=True) # 最大池化:(B,1,H,W)
pool_out = torch.cat([avg_out, max_out], dim=1) # 拼接:(B,2,H,W)
attention = self.conv(pool_out) # 卷积提取空间特征
return x * self.sigmoid(attention) # 特征与空间权重相乘
## CBAM模块
class CBAM(nn.Module):
def __init__(self, in_channels, ratio=16, kernel_size=7):
super().__init__()
self.channel_attn = ChannelAttention(in_channels, ratio)
self.spatial_attn = SpatialAttention(kernel_size)
def forward(self, x):
x = self.channel_attn(x)
x = self.spatial_attn(x)
return x
# 测试下通过CBAM模块的维度变化
# 输入卷积的尺寸为
# 假设输入特征图:batch=2,通道=512,尺寸=26x26
x = torch.randn(2, 512, 26, 26)
cbam = CBAM(in_channels=512)
output = cbam(x) # 输出形状不变:(2, 512, 26, 26)
print(f"Output shape: {output.shape}") # 验证输出维度
#cnn+cbam训练
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
import numpy as np
# 设置中文字体支持
plt.rcParams["font.family"] = ["SimHei"]
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示问题
# 检查GPU是否可用
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"使用设备: {device}")
# 数据预处理(与原代码一致)
train_transform = transforms.Compose([
transforms.RandomCrop(32, padding=4),
transforms.RandomHorizontalFlip(),
transforms.ColorJitter(brightness=0.2, contrast=0.2, saturation=0.2, hue=0.1),
transforms.RandomRotation(15),
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010))
])
test_transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010))
])
# 加载数据集(与原代码一致)
train_dataset = datasets.CIFAR10(root='./data', train=True, download=True, transform=train_transform)
test_dataset = datasets.CIFAR10(root='./data', train=False, transform=test_transform)
train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=64, shuffle=False)
# 定义带有CBAM的CNN模型
class CBAM_CNN(nn.Module):
def __init__(self):
super(CBAM_CNN, self).__init__()
# ---------------------- 第一个卷积块(带CBAM) ----------------------
self.conv1 = nn.Conv2d(3, 32, kernel_size=3, padding=1)
self.bn1 = nn.BatchNorm2d(32) # 批归一化
self.relu1 = nn.ReLU()
self.pool1 = nn.MaxPool2d(kernel_size=2)
self.cbam1 = CBAM(in_channels=32) # 在第一个卷积块后添加CBAM
# ---------------------- 第二个卷积块(带CBAM) ----------------------
self.conv2 = nn.Conv2d(32, 64, kernel_size=3, padding=1)
self.bn2 = nn.BatchNorm2d(64)
self.relu2 = nn.ReLU()
self.pool2 = nn.MaxPool2d(kernel_size=2)
self.cbam2 = CBAM(in_channels=64) # 在第二个卷积块后添加CBAM
# ---------------------- 第三个卷积块(带CBAM) ----------------------
self.conv3 = nn.Conv2d(64, 128, kernel_size=3, padding=1)
self.bn3 = nn.BatchNorm2d(128)
self.relu3 = nn.ReLU()
self.pool3 = nn.MaxPool2d(kernel_size=2)
self.cbam3 = CBAM(in_channels=128) # 在第三个卷积块后添加CBAM
# ---------------------- 全连接层 ----------------------
self.fc1 = nn.Linear(128 * 4 * 4, 512)
self.dropout = nn.Dropout(p=0.5)
self.fc2 = nn.Linear(512, 10)
def forward(self, x):
# 第一个卷积块
x = self.conv1(x)
x = self.bn1(x)
x = self.relu1(x)
x = self.pool1(x)
x = self.cbam1(x) # 应用CBAM
# 第二个卷积块
x = self.conv2(x)
x = self.bn2(x)
x = self.relu2(x)
x = self.pool2(x)
x = self.cbam2(x) # 应用CBAM
# 第三个卷积块
x = self.conv3(x)
x = self.bn3(x)
x = self.relu3(x)
x = self.pool3(x)
x = self.cbam3(x) # 应用CBAM
# 全连接层
x = x.view(-1, 128 * 4 * 4)
x = self.fc1(x)
x = self.relu3(x)
x = self.dropout(x)
x = self.fc2(x)
return x
# 初始化模型并移至设备
model = CBAM_CNN().to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
scheduler = optim.lr_scheduler.ReduceLROnPlateau(optimizer, mode='min', patience=3, factor=0.5)
# 训练函数
def train(model, train_loader, test_loader, criterion, optimizer, scheduler, device, epochs):
model.train()
all_iter_losses = []
iter_indices = []
train_acc_history = []
test_acc_history = []
train_loss_history = []
test_loss_history = []
for epoch in range(epochs):
running_loss = 0.0
correct = 0
total = 0
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = model(data)
loss = criterion(output, target)
loss.backward()
optimizer.step()
iter_loss = loss.item()
all_iter_losses.append(iter_loss)
iter_indices.append(epoch * len(train_loader) + batch_idx + 1)
running_loss += iter_loss
_, predicted = output.max(1)
total += target.size(0)
correct += predicted.eq(target).sum().item()
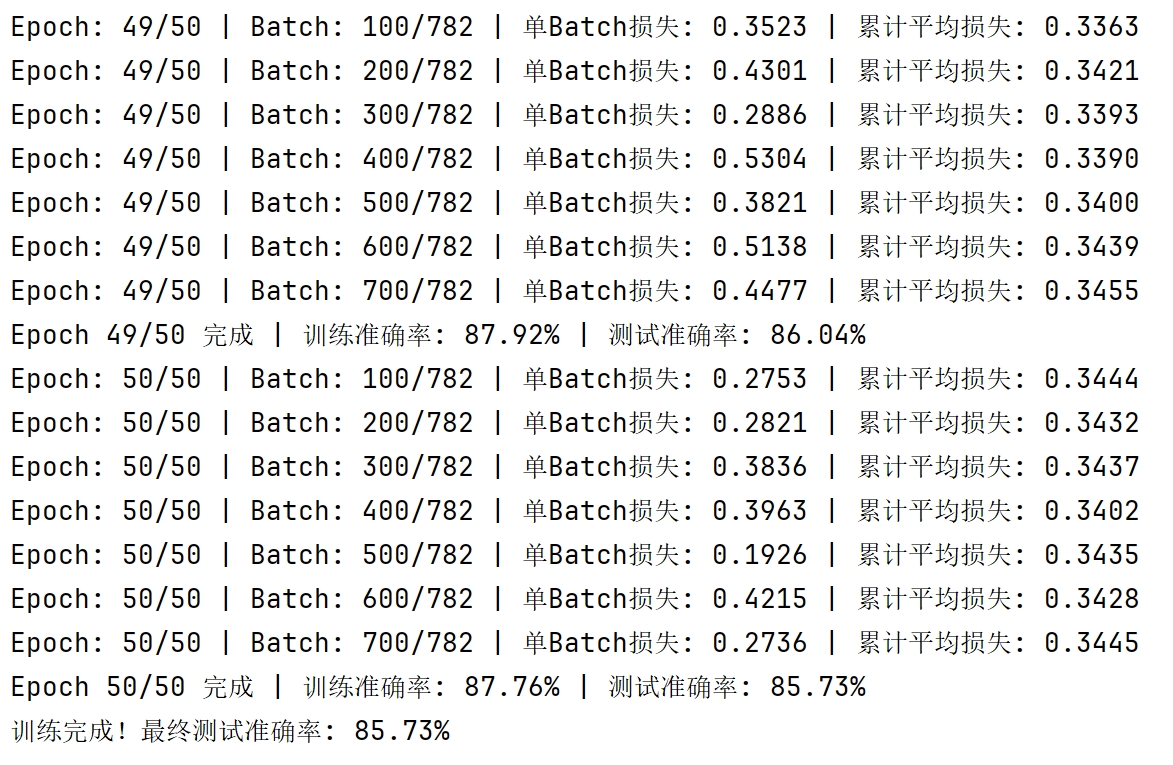
if (batch_idx + 1) % 100 == 0:
print(f'Epoch: {epoch + 1}/{epochs} | Batch: {batch_idx + 1}/{len(train_loader)} '
f'| 单Batch损失: {iter_loss:.4f} | 累计平均损失: {running_loss / (batch_idx + 1):.4f}')
epoch_train_loss = running_loss / len(train_loader)
epoch_train_acc = 100. * correct / total
train_acc_history.append(epoch_train_acc)
train_loss_history.append(epoch_train_loss)
# 测试阶段
model.eval()
test_loss = 0
correct_test = 0
total_test = 0
with torch.no_grad():
for data, target in test_loader:
data, target = data.to(device), target.to(device)
output = model(data)
test_loss += criterion(output, target).item()
_, predicted = output.max(1)
total_test += target.size(0)
correct_test += predicted.eq(target).sum().item()
epoch_test_loss = test_loss / len(test_loader)
epoch_test_acc = 100. * correct_test / total_test
test_acc_history.append(epoch_test_acc)
test_loss_history.append(epoch_test_loss)
scheduler.step(epoch_test_loss)
print(
f'Epoch {epoch + 1}/{epochs} 完成 | 训练准确率: {epoch_train_acc:.2f}% | 测试准确率: {epoch_test_acc:.2f}%')
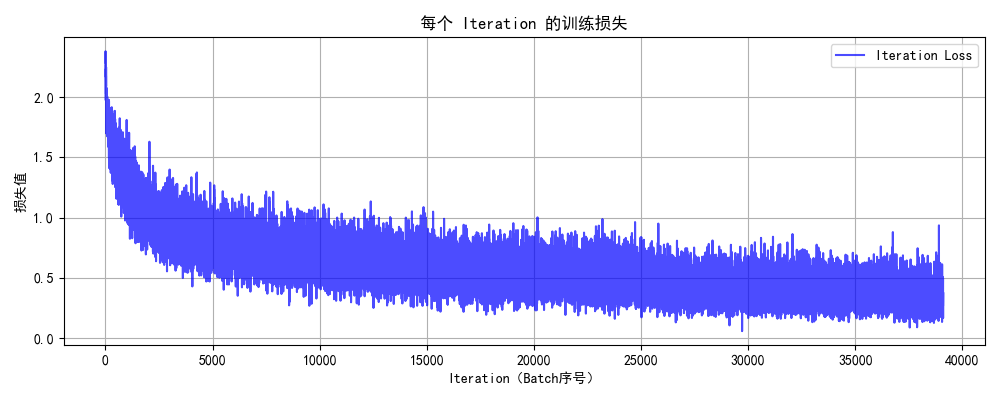
plot_iter_losses(all_iter_losses, iter_indices)
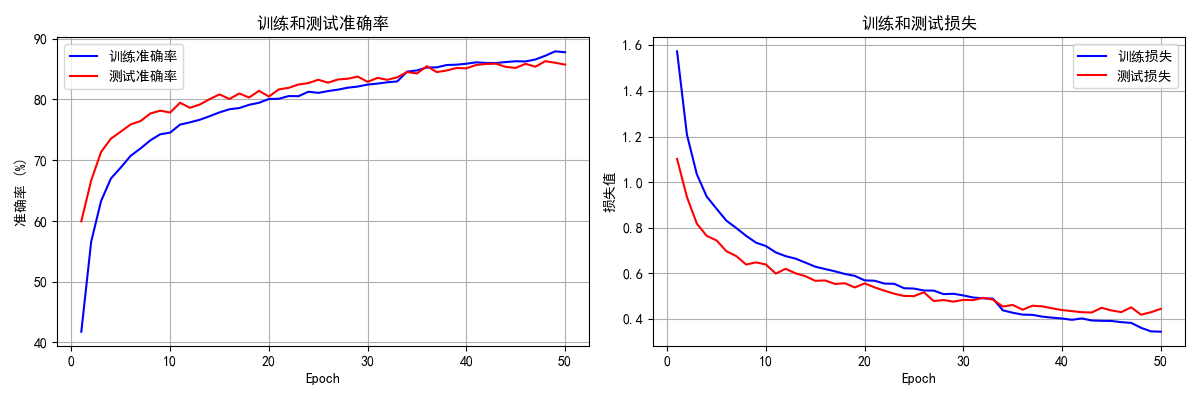
plot_epoch_metrics(train_acc_history, test_acc_history, train_loss_history, test_loss_history)
return epoch_test_acc
# 绘图函数
def plot_iter_losses(losses, indices):
plt.figure(figsize=(10, 4))
plt.plot(indices, losses, 'b-', alpha=0.7, label='Iteration Loss')
plt.xlabel('Iteration(Batch序号)')
plt.ylabel('损失值')
plt.title('每个 Iteration 的训练损失')
plt.legend()
plt.grid(True)
plt.tight_layout()
plt.show()
def plot_epoch_metrics(train_acc, test_acc, train_loss, test_loss):
epochs = range(1, len(train_acc) + 1)
plt.figure(figsize=(12, 4))
plt.subplot(1, 2, 1)
plt.plot(epochs, train_acc, 'b-', label='训练准确率')
plt.plot(epochs, test_acc, 'r-', label='测试准确率')
plt.xlabel('Epoch')
plt.ylabel('准确率 (%)')
plt.title('训练和测试准确率')
plt.legend()
plt.grid(True)
plt.subplot(1, 2, 2)
plt.plot(epochs, train_loss, 'b-', label='训练损失')
plt.plot(epochs, test_loss, 'r-', label='测试损失')
plt.xlabel('Epoch')
plt.ylabel('损失值')
plt.title('训练和测试损失')
plt.legend()
plt.grid(True)
plt.tight_layout()
plt.show()
# 执行训练
epochs = 50
print("开始使用带CBAM的CNN训练模型...")
final_accuracy = train(model, train_loader, test_loader, criterion, optimizer, scheduler, device, epochs)
print(f"训练完成!最终测试准确率: {final_accuracy:.2f}%")
# # 保存模型
# torch.save(model.state_dict(), 'cifar10_cbam_cnn_model.pth')
# print("模型已保存为: cifar10_cbam_cnn_model.pth")
python
import torch
import torch.nn as nn
# 定义通道注意力
class ChannelAttention(nn.Module):
def __init__(self, in_channels, ratio=16):
"""
通道注意力机制初始化
参数:
in_channels: 输入特征图的通道数
ratio: 降维比例,用于减少参数量,默认为16
"""
super().__init__()
# 全局平均池化,将每个通道的特征图压缩为1x1,保留通道间的平均值信息
self.avg_pool = nn.AdaptiveAvgPool2d(1)
# 全局最大池化,将每个通道的特征图压缩为1x1,保留通道间的最显著特征
self.max_pool = nn.AdaptiveMaxPool2d(1)
# 共享全连接层,用于学习通道间的关系
# 先降维(除以ratio),再通过ReLU激活,最后升维回原始通道数
self.fc = nn.Sequential(
nn.Linear(in_channels, in_channels // ratio, bias=False), # 降维层
nn.ReLU(), # 非线性激活函数
nn.Linear(in_channels // ratio, in_channels, bias=False) # 升维层
)
# Sigmoid函数将输出映射到0-1之间,作为各通道的权重
self.sigmoid = nn.Sigmoid()
def forward(self, x):
"""
前向传播函数
参数:
x: 输入特征图,形状为 [batch_size, channels, height, width]
返回:
调整后的特征图,通道权重已应用
"""
# 获取输入特征图的维度信息,这是一种元组的解包写法
b, c, h, w = x.shape
# 对平均池化结果进行处理:展平后通过全连接网络
avg_out = self.fc(self.avg_pool(x).view(b, c))
# 对最大池化结果进行处理:展平后通过全连接网络
max_out = self.fc(self.max_pool(x).view(b, c))
# 将平均池化和最大池化的结果相加并通过sigmoid函数得到通道权重
attention = self.sigmoid(avg_out + max_out).view(b, c, 1, 1)
# 将注意力权重与原始特征相乘,增强重要通道,抑制不重要通道
return x * attention #这个运算是pytorch的广播机制 这段代码是什么意思上述代码的通俗理解
想象一下,你是一个工厂的质检员,面前有一条生产线(这就是我们的输入 `x`)。这条生产线同时生产多种口味的饼干(比如巧克力味、草莓味、香草味...),每种口味就是一个"通道"。
你的工作是:**判断哪种口味的饼干最受欢迎,然后就给那种口味分配更多的原料,让它生产得更突出;同时减少不受欢迎口味的原料。**
这个"通道注意力"模块,就是这个智能质检员。
第一步:收集信息(池化层)
质检员怎么知道哪种口味受欢迎呢?他有两种方法:
-
**平均池化 (`avg_pool`)**:他随机品尝每一批饼干**一小口**,然后算出每种口味的**平均评分**。这代表了这种口味的"整体受欢迎程度"。
-
**最大池化 (`max_pool`)**:他专门去找每一批饼干中**最好吃的那一块**来品尝。这代表了这种口味的"潜力"或"巅峰水平"。
通过这两种方法,他把每一整盘饼干(一个二维的特征图)都总结成了**一个数字**(1x1)。这样,对于`C`种口味(通道),他就得到了`C`个平均分和`C`个最高分。
> **简单说:** 池化层把 `b, c, h, w` 形状的数据,变成了 `b, c, 1, 1` 的形状。`h`和`w`(高度和宽度)被压缩成了1,只留下了通道信息。
第二步:分析报告(全连接层 `fc`)
现在,质检员手里有两份报告(平均分报告和最高分报告)。他不能直接下结论,需要深入分析。
他把这两份报告分别交给同一个智能分析团队(`self.fc`)。这个团队的工作流程是:
-
**降维(第一个 `Linear` 层)**:团队先只看报告的重点,把冗长的报告精简(从 `c` 个数字减少到 `c//16` 个数字)。这是为了节省工作量,防止过度分析。
-
**激活(`ReLU`)**:团队进行一些非线性的思考,"如果这个口味得分高,那么..."。
-
**升维(第二个 `Linear` 层)**:团队根据分析出的重点,再还原出一份完整的、包含`c`个数字的**最终建议报告**。这份报告说明了每种口味应该被重视的程度。
**注意:** 在原始论文中,平均报告和最高报告是交给**两个不同的**分析团队(两个独立的MLP)的。但在这段代码里,为了节省人手(减少参数),让**同一个团队**先后分析了两份报告。这是代码和论文的一个小区别,但效果类似。
第三步:做出决策(Sigmoid)
质检员拿到了两份"最终建议报告"(平均池化路径的`avg_out`和最大池化路径的`max_out`)。他觉得两份报告都很有道理,于是把两份建议**加在一起**综合考虑。
然后,他使用一个"决策器"(`sigmoid`函数)来处理这个综合建议。这个决策器非常厉害,能把任何数字都转换成 **0 到 1 之间的一个百分比**。
-
**接近 1**:意味着"这个口味非常非常受欢迎,必须大力加强!"
-
**接近 0**:意味着"这个口味不行,可以削弱它"。
-
**0.5**:意味着"保持原样就好"。
最终,他得到了一个"权重列表",形状是 `b, c, 1, 1`。比如:
-
巧克力味:`0.95`
-
草莓味:`0.23`
-
香草味:`0.76`
-
...
第四步:指挥生产(广播乘法 `x * attention`)
现在,最神奇的一步来了------"广播机制"。
原始的饼干生产线 `x` 的形状是 `b, c, h, w`,意思是每一块具体的小饼干(`h x w` 这么多块)都在生产线上。
质检员拿着他的权重列表(形状是`b, c, 1, 1`),对着生产线大喊:
-
**"所有巧克力味的饼干!你们的权重是 0.95,都给我变得更突出!"**
-
于是,生产线上**每一块**巧克力味饼干的值都乘以了 0.95(实际上是乘以一个比1大的数,变得更突出了)。
-
**"所有草莓味的饼干!你们的权重是 0.23,都给我减弱!"**
-
于是,生产线上**每一块**草莓味饼干的值都乘以了 0.23(变得很不显眼)。
因为他喊的是"所有"(即针对每个通道的所有高度和宽度位置),PyTorch 就自动帮他把 `b, c, 1, 1` 的权重列表,"广播"成了和原始生产线 `b, c, h, w` 一样的形状,从而完成逐元素相乘。
**最终,工厂产出了一批经过优化的饼干,好吃的口味更突出了,不好吃的口味被淡化了。** 这就是通道注意力的最终输出。
总结
这段代码就是一个**智能加权器**:
-
**看**:用池化层看每个通道的全局情况。
-
**想**:用全连接层分析哪个通道更重要。
-
**定**:用Sigmoid决定每个通道的权重(0-1之间)。
-
**改**:用广播机制把权重应用到每个通道的所有位置上。
python
## CBAM模块
class CBAM(nn.Module):
def __init__(self, in_channels, ratio=16, kernel_size=7):
super().__init__()
self.channel_attn = ChannelAttention(in_channels, ratio)
self.spatial_attn = SpatialAttention(kernel_size)
def forward(self, x):
x = self.channel_attn(x)
x = self.spatial_attn(x)
return x这段代码定义了一个完整的 **CBAM(Convolutional Block Attention Module)注意力模块**。它非常强大,能够帮助神经网络"更智能地"关注图像中重要的部分。
我们可以继续用之前的**饼干工厂**比喻来理解它:
回顾:通道注意力 (Channel Attention)
- **它关心"口味"**。就像质检员,它判断哪种口味的饼干(哪个特征通道)更重要,然后增强重要口味的信号,减弱不重要的。
现在:空间注意力 (Spatial Attention)
-
**它关心"位置"**。想象另一个质检员,他不在乎口味,只在乎**饼干在烤盘上的哪个位置**烤得最好。他发现烤盘的中间区域温度最均匀,烤出来的饼干成色最好,而边缘容易烤焦或没烤熟。
-
他的工作是:生成一个地图,标记出烤盘上**哪些位置是"好位置"**,需要保留和强化;哪些位置是"坏位置",需要弱化其影响。
CBAM:两位质检员协同工作
CBAM模块将这两位专家**串联**起来,让他们依次对生产线上的饼干进行处理。
- **初始化 `init`**:
-
`self.channel_attn = ...`: 雇用了第一位专家------**口味质检员(通道注意力)**。
-
`self.spatial_attn = ...`: 雇用了第二位专家------**位置质检员(空间注意力)**。
- **工作流程 `forward`**:
- **第一步**: 生产线上的饼干 `x` 先交给**口味质检员**。
```python
x = self.channel_attn(x) # 经过处理后,重要口味的饼干被增强了
```
- **第二步**: 经过口味筛选的饼干,现在交给**位置质检员**。
```python
x = self.spatial_attn(x) # 经过处理后,烤盘上好位置的饼干又被增强了
```
- **最终**,生产线上得到的是既**口味突出**又**成色完美**的饼干。
空间注意力 (SpatialAttention) 是做什么的?
(虽然代码中没有给出`SpatialAttention`的定义,但它是CBAM的标准组成部分,其典型结构如下:)
- **收集信息**: 它会在每个空间位置(烤盘的每个点)上,查看**所有口味(所有通道)** 的信息。
- 它会计算两个值:所有通道在这个位置上的**平均值**和**最大值**。这代表了该位置的"整体水平"和"突出水平"。
-
**合并信息**: 它将这两个值(平均和最大)堆叠在一起,形成一个2-channel的"特征图"。
-
**分析决策**: 用一个简单的卷积层(比如`kernel_size=7`)来分析这个2-channel地图,判断哪些空间区域是重要的。最后同样通过Sigmoid函数生成一个0到1的**空间权重图**(`b, 1, h, w`)。
-
**应用权重**: 这个权重图会与输入特征图相乘,**增强重要区域的特征,抑制不重要区域的特征**。
为什么CBAM如此有效?
因为它从两个互补的维度(**通道维**和**空间维**)进行了注意力筛选,形成了"**先选重要口味,再选重要位置**"的精细化处理流程。这极大地提升了网络对关键特征的捕捉能力,让网络性能更好。
总结
这段代码意味着:
-
`CBAM` 是一个包装好的、完整的注意力模块。
-
它的工作流程是:**输入 → 通道注意力 → 空间注意力 → 输出**。
-
它让神经网络学会同时关注 **"What"(什么特征重要)** 和 **"Where"(哪里重要)**,是提升CNN性能的经典模块。