在当今互联网、物联网、云计算、大数据等高速发展的大背景下,数据呈现出几何式增长。这些数据不仅需要巨量的存储空间,而且数据类型繁多、数据大小变化大、流动快等特点,往往产生数亿级的海量小文件。由于在元数据管理、存储效率、访问的性能等方面面临巨大的挑战,因此海量小文件(LSOF,lots of small files)问题是工业界和学术界公认的难题。
本文汇总之前文章以及参考网上关于海量小文件问题的论述和常见系统的解决方案,阐述在大数据系统中对于LSOF的系统性解决方案,以及针对目前大数据领域常用的技术框架面临小文件问题时的原因探讨和解决方法。
小文件问题概述
衡量存储系统性能主要有两个关键指标,即IOPS和数据吞吐量。
IOPS (Input/Output Per Second) 即每秒的输入输出量 (或读写次数) ,是衡量存储系统性能的主要指标之一。IOPS是指单位时间内系统能处理的I/O请求数量,一般以每秒处理的I/O请求数量为单位,I/O请求通常为读或写数据操作请求。随机读写频繁的应用,如OLTP(OnlineTransaction Processing),IOPS是关键衡量指标。
另一个重要指标是数据吞吐量(Throughput),指单位时间内可以成功传输的数据数量。对于大量顺序读写的应用,如VOD(VideoOn Demand),则更关注吞吐量指标。
我们的存储磁盘最适合顺序的大文件I/O读写模式,非常不适合随机的小文件I/O读写模式,这是磁盘文件系统在海量小文件应用下性能表现不佳的根本原因。磁盘文件系统的设计大多都侧重于大文件,包括元数据管理、数据布局和I/O访问流程,另外VFS系统调用机制也非常不利于海量小文件,这些软件层面的机制和实现加剧了小文件读写的性能问题。
对于LOSF而言,IOPS/OPS是关键性能衡量指标,造成性能和存储效率低下的主要原因包括元数据管理、数据布局和I/O管理、Cache管理、网络开销等方面。从理论分析以及上面LOSF优化实践来看,优化应该从元数据管理、缓存机制、合并小文件等方面展开,而且优化是一个系统工程,结合硬件、软件,从多个层面同时着手,优化效果会更显著。
小文件过多引起的主要问题
(1)元数据管理低效
由于小文件数据内容较少,因此元数据的访问性能对小文件访问性能影响巨大。当前主流的磁盘文件系统基本都是面向大文件高聚合带宽设计的,而不是小文件的低延迟访问。
磁盘文件系统中,目录项(dentry)、索引节点(inode)和数据(data)保存在存储介质的不同位置上。因此,访问一个文件需要经历至少3次独立的访问。这样,并发的小文件访问就转变成了大量的随机访问,而这种访问对于广泛使用的磁盘来说是非常低效的。
同时,文件系统通常采用Hash树、B+树或B*树来组织和索引目录,这种方法不能在数以亿计的大目录中很好的扩展,海量目录下检索效率会明显下降。正是由于单个目录元数据组织能力的低效,文件系统使用者通常被鼓励把文件分散在多层次的目录中以提高性能。然而,这种方法会进一步加大路径查询的开销。
(2)数据布局低效
磁盘文件系统使用块来组织磁盘数据,并在inode中使用多级指针或hash树来索引文件数据块。数据块通常比较小,一般为1KB、2KB或4KB。当文件需要存储数据时,文件系统根据预定的策略分配数据块,分配策略会综合考虑数据局部性、存储空间利用效率等因素,通常会优先考虑大文件I/O带宽。
对于大文件,数据块会尽量进行连续分配,具有比较好的空间局部性。
对于小文件,尤其是大文件和小文件混合存储或者经过大量删除和修改后,数据块分配的随机性会进一步加剧,数据块可能零散分布在磁盘上的不同位置,并且会造成大量的磁盘碎片(包括内部碎片和外部碎片),不仅造成访问性能下降,还导致大量磁盘空间浪费。
对于特别小的小文件,比如小于4KB,inode与数据分开存储,这种数据布局也没有充分利用空间局部性,导致随机I/O访问,目前已经有文件系统实现了data in inode。
(3)I/O访问流程复杂
Linux等操作系统采用VFS或类似机制来抽象文件系统的实现,提供标准统一访问接口和流程,它提供通用的Cache机制,处理文件系统相关的所有系统调用,与具体文件系统和其他内核组件(如内存管理)交互。VFS可以屏蔽底层文件系统实现细节,简化文件系统设计,实现对不同文件系统支持的扩展。
VFS通用模型中有涉及四种数据类型:超级块对象(superblock object)、索引结点对象(inode object)、文件对象(file object)和目录项对象(dentry object),进程在进行I/O访问过程中需要频繁与它们交互(如下图所示)。
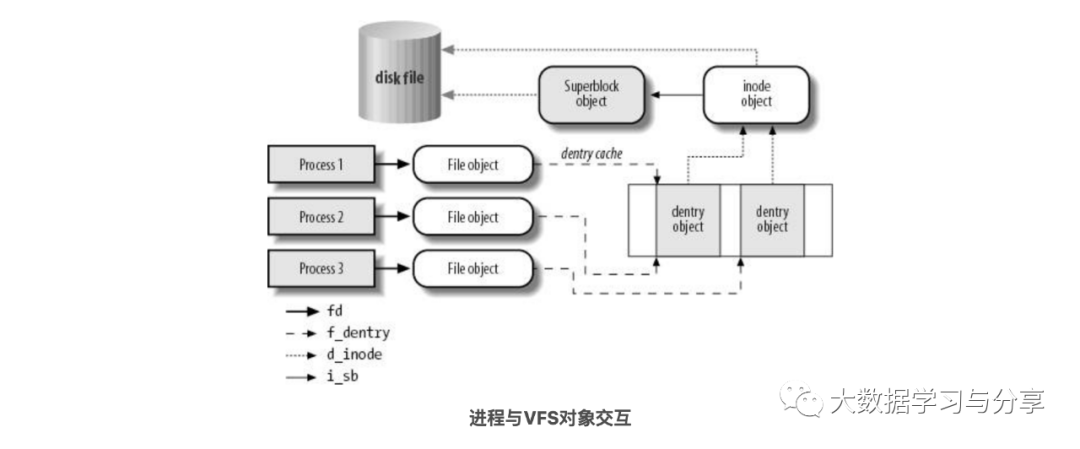
对于小文件的I/O访问过程,读写数据量比较小,这些流程太过复杂,系统调用开销太大,尤其是其中的open()操作占用了大部分的操作时间。当面对海量小文件并发访问,读写之前的准备工作占用了绝大部分系统时间,有效磁盘服务时间非常低,从而导致小I/O性能极度低下。
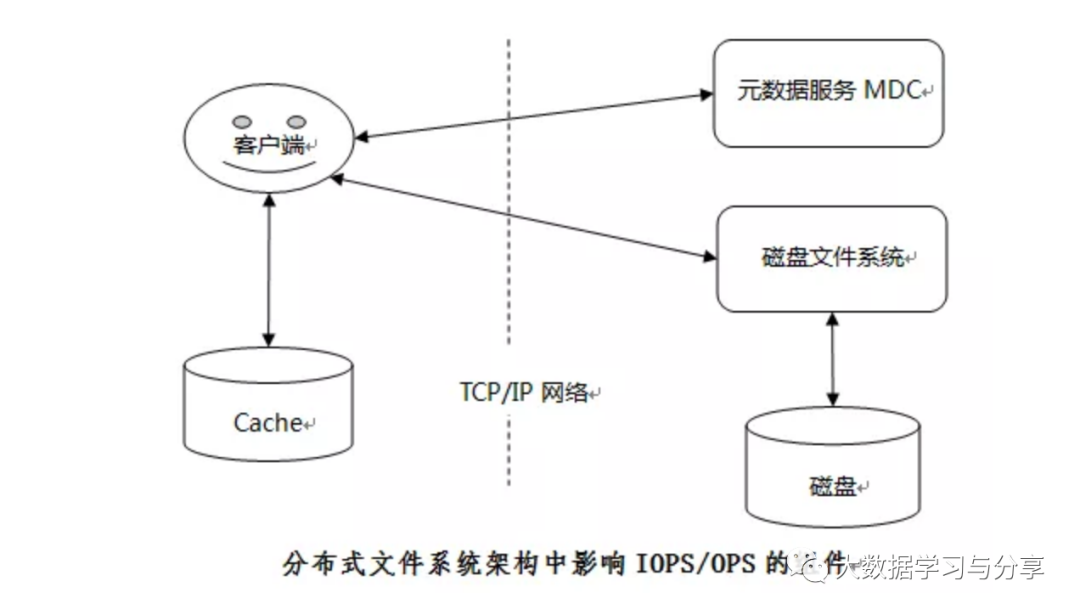
对于大多数分布式文件系统而言,通常将元数据与数据两者独立开来,即控制流与数据流进行分离,从而获得更高的系统扩展性和I/O并发性。数据和I/O访问负载被分散到多个物理独立的存储节点,从而实现系统的高扩展性和高性能,每个节点使用磁盘文件系统管理数据,比如XFS、EXT4、XFS等。
因此,相对于磁盘文件系统而言,每个节点的小文件问题是相同的。由于分布式的架构,分布式文件系统中的网络通信、元数据服务MDC、Cache管理、数据布局和I/O访问模式等都会对IOPS/OPS性能产生影响,进一步加剧小文件问题。
小文件合并
小文件合并存储是目前优化LOSF问题最为成功的策略,已经被包括Facebook Haystack和淘宝TFS在内多个分布式存储系统采用。它通过多个逻辑文件共享同一个物理文件,将多个小文件合并存储到一个大文件中,实现高效的小文件存储。为什么这种策略对LOSF效果显著呢?
首先减少了大量元数据,提高了元数据的检索和查询效率,降低了文件读写的 I/O 操作延时。其次将可能连续访问的小文件一同合并存储,增加了文件之间的局部性,将原本小文件间的随机访问变为了顺序访问,大大提高了性能。同时,合并存储能够有效的减少小文件存储时所产生的磁盘碎片问题,提高了磁盘的利用率。最后,合并之后小文件的访问流程也有了很大的变化,由原来许多的open操作转变为了seek操作,定位到大文件具体的位置即可。
大文件加上索引文件,小文件合并存储实际上相当于一个微型文件系统。这种机制对于WORM(Write Once Read Many)模式的分布式存储系统非常适合,而不适合允许改写和删除的存储系统。因为文件改写和删除操作,会造成大文件内部的碎片空洞,如果进行空间管理并在合适时候执行碎片整理,实现比较复杂而且产生额外开销。如果不对碎片进行处理,采用追加写的方式,一方面会浪费存储容量,另一方面又会破坏数据局部性,增加数据分布的随机性,导致读性能下降。此外,如果支持随机读写,大小文件如何统一处理,小文件增长成大文件,大文件退化为小文件,这些问题都是在实际处理时面临的挑战。
Hadoop小文件合并策略和方式
Hadoop中的小文件一般是指明显小于HDFS的block size(默认128M,一般整数倍配置如256M)的文件。但需要注意,HDFS上的有些小文件是不可避免的,比如jar、临时缓存文件等。但当小文件数量变的"海量",以至于Hadoop集群中存储了大量的小文件,就需要对小文件进行处理,而处理的目标是让文件大小尽可能接近HDFS的block size大小或者整数倍。
Hadoop小文件带来的问题
1)众所周知,在HDFS中数据和元数据分别由DataNode和NameNode负责,这些元数据每个对象一般占用大约150个字节。大量的小文件相对于大文件会占用大量的NameNode内存。对NameNode内存管理产生巨大挑战,此外对JVM稳定性也有影响如GC。
2)当NameNode重启时,它需要将文件系统元数据从本地磁盘加载到内存中。如果NameNode的元数据很大,重启速度会非常慢。
3)一般来说,NameNode会不断跟踪并检查集群中每个block块的存储位置。这是通过DataNode的定时心跳上报其数据块来实现的。数据节点需要上报的block越多,则也会消耗越多的网络带宽/时延。
4)更多的文件意味着更多的读取请求需要请求NameNode,这可能最终会堵塞NameNode的容量,增加RPC队列和处理延迟,进而导致性能和响应能力下降。
5)对计算引擎如Spark、MapReduce性能造成负面影响。以MapReduce(以下简称MR)为例,大量小文件意味着大量的磁盘IO,磁盘IO通常是MR性能的最大瓶颈之一,在HDFS中对于相同数量的数据,一次大的顺序读取往往优于几次随机读取的性能。如果可以将数据存储在较少,而更大的一些block中,可以降低磁盘IO的性能影响。除了磁盘IO,还有内部任务的划分、资源分配等,建议阅读:《详解MapReduce》。
Hadoop小文件是怎么来的
一个Hadoop集群中存在小文件的可能原因如下:
1.流式任务(如spark streaming/flink等实时计算框架)
在做数据处理时,无论是纯实时还是基于batch的准实时,在小的时间窗口内都可能产生大量的小文件。此外对于Spark任务如果过度并行化,每个分区一个文件,产生的文件也可能会增多
2.Hive分区表的过度分区
这里的过度分区是指Hive分区表的每个分区数据量很小(比如小于HDFS block size)的Hive表。那么Hive Metastore Server调用开销会随着表拥有的分区数量而增加,影响性能。此时,要衡量数据量重新进行表结构设计(如减少分区粒度)。
3.数据源有大量小文件,未做处理直接迁移到Hadoop集群。
4.对于计算引擎处理任务,以MR为例。
大量的map和reduce task存在。在HDFS上生成的文件基本上与map数量(对于Map-Only作业)或reduce数量(对于MR作业)成正比。此外,MR任务如果未设置合理的reduce数或者未做限制,每个reduce都会生成一个独立的文件。对于数据倾斜,导致大部分的数据都shuffle到一个或几个reduce,然后其他的reduce都会处理较小的数据量并输出小文件。
对于Spark任务,过度并行化也是导致小文件过多的原因之一。
在Spark作业中,根据写任务中提到的分区数量,每个分区会写一个新文件。这类似于MapReduce框架中的每个reduce任务都会创建一个新文件。Spark分区越多,写入的文件就越多。控制分区的数量来减少小文件的生成。
Hadoop小文件的发现
NameNode存储了所有与文件相关的元数据,所以它将整个命名空间保存在内存中,而fsimage是NameNode的本地本机文件系统中的持久化记录。因此,我们可以通过分析fsimage来找出文件的元信息。fsimage中可用的字段有:
Path, Replication, ModificationTime, AccessTime, PreferredBlockSize, BlocksCount, FileSize, NSQUOTA, DSQUOTA, Permission, UserName, GroupName
通常可以采用以下方法来解析fsimage,拷贝Namenode数据目录下的fsimage文件到其他目录,然后执行:
hdfs oiv -p Delimited -delimiter "|" -t /tmp/tmpdir/ -i fsimage_copy_file -o fsimage_deal.out
关于hdfs oiv命令的使用,可以查看useage。
Usage: bin/hdfs oiv [OPTIONS] -i INPUTFILE -o OUTPUTFILE
Offline Image Viewer
View a Hadoop fsimage INPUTFILE using the specified PROCESSOR,
saving the results in OUTPUTFILE.
The oiv utility will attempt to parse correctly formed image files
and will abort fail with mal-formed image files.
The tool works offline and does not require a running cluster in
order to process an image file.
The following image processors are available:
* XML: This processor creates an XML document with all elements of
the fsimage enumerated, suitable for further analysis by XML
tools.
* FileDistribution: This processor analyzes the file size
distribution in the image.
-maxSize specifies the range [0, maxSize] of file sizes to be
analyzed (128GB by default).
-step defines the granularity of the distribution. (2MB by default)
* Web: Run a viewer to expose read-only WebHDFS API.
-addr specifies the address to listen. (localhost:5978 by default)
* Delimited (experimental): Generate a text file with all of the elements common
to both inodes and inodes-under-construction, separated by a
delimiter. The default delimiter is \t, though this may be
changed via the -delimiter argument.
Required command line arguments:
-i,--inputFile <arg> FSImage file to process.
Optional command line arguments:
-o,--outputFile <arg> Name of output file. If the specified
file exists, it will be overwritten.
(output to stdout by default)
-p,--processor <arg> Select which type of processor to apply
against image file. (XML|FileDistribution|Web|Delimited)
(Web by default)
-delimiter <arg> Delimiting string to use with Delimited processor.
-t,--temp <arg> Use temporary dir to cache intermediate result to generate
Delimited outputs. If not set, Delimited processor constructs
the namespace in memory before outputting text.
-h,--help Display usage information and exit另一种方法是使用fsck命令扫描当前的HDFS目录并保存扫描后的信息。但是不建议在生产环境使用fsck命令,因为它会带来额外的开销,可能影响集群的稳定性。
敬请期待下篇更多小文件解决攻略。
更多干货抢先看: 数仓建模