业务分类:
-
硬件拓扑感知
-
硬件类型及特性注册
-
硬件分配
-
硬件资源回收
-
硬件检查
-
硬件接口兼容性
-
硬件驱动
1. Device Plugin 源起
Kubernetes 社区为解决异构设备全生命周期管理的痛点,在1.8版本引入Device Plugin 框架:
- 核心目标:标准化设备管理接口,实现动态注册、发现、分配、监控的闭环。
- 关键设计思想:
-
- 插件化架构:硬件厂商只需实现 Device Plugin 接口,无需修改kubelet 核心代码。
- gRPC 长连接通信:通过 ListAndWatch 接口实时同步设备列表与健康状态。
- 资源分配原子性:kubele t在 Pod 调度成功后直接调用 Allocate接口,确保设备初始化(如 GPU 显存清空、FPGA 程序烧录)与容器启动的原子性。
设备管理需求场景
随着技术的发展,越来越多的硬件资源需要接入 k8s 平台调度管理,例如:
- GPU 场景:深度学习训练
-
- 自动挂载设备与驱动库(gpu operator):通过 Allocate 返回的mounts 将 libcuda.so 等库注入容器
- 健康检查:监控 GP U的 XID 错误(通过 nvidia-smi 查询),自动标记故障设备
-
- 设备隔离性:多个 Pod 共享物理 GPU 时需隔离显存与计算单元(如NVIDIA MIG 技术)
- 驱动兼容性:容器内 GPU 驱动版本需与宿主机一致(通过 nvidia-docker2 的 --gpu s参数注入设备)
- 资源超分:通过 vGPU 技术(如 vCUDA )实现单卡多容器共享 (HAMI)
-
- 核心需求:
- Device Plugin 的作用:
- FPGA 场景:动态重配置
-
- 预烧录检查:在 Allocate 阶段调用厂商工具(如 Xilinx 的vivado)验证比特流兼容性
- 设备状态机管理:通过 ListAndWatch 标记 FPGA 为InProgramming/Ready 状态
-
- 比特流(Bitstream)动态烧录:不同 Pod 可能需要不同的 FPGA 逻辑功能(如加密/解密切换)
- 设备锁定:烧录过程中需独占访问 FPGA,防止并发操作导致硬件损坏
-
- 核心需求:
- Device Plugin 的定制逻辑:
- 其他异构计算场景
-
- 按 NUMA 节点分配内存模式存储,避免跨节点访问延迟
-
- 分配 SR-IOV VF(Virtual Function)给 Pod,加速网络包处理
- 通过 Device Plugin 实现 VF 与 PF(Physical Function)的绑定关系管理
-
- 需要为容器注入专属 SDK(如 TensorFlow TPU 驱动)
- 监控加速器温度与功耗,实现弹性调度
-
- AI 加速器(如TPU、NPU):
- 智能网卡( SmartNIC ):
- 高性能存储设备(如 Optane PMem ):
HAMI 依赖 gpu operator 提供驱动动态库一来(宿主机可以不用部署)
行业实践案例:
- NVIDIA GPU Operator:通过 Device Plugin 自动部署 GPU 驱动、容器运行时、监控组件,实现"一键式" GPU 集群管理
- AWS Inferentia:使用 Device Plugin 为机器学习推理容器分配NeuronCore 资源,并注入神经加速运行时库
- Intel FPGA Plugin:实现 FPGA 设备的区域管理(Region),支持多租户共享同一物理 FPGA 卡
kubelet 和 device plugin 交互
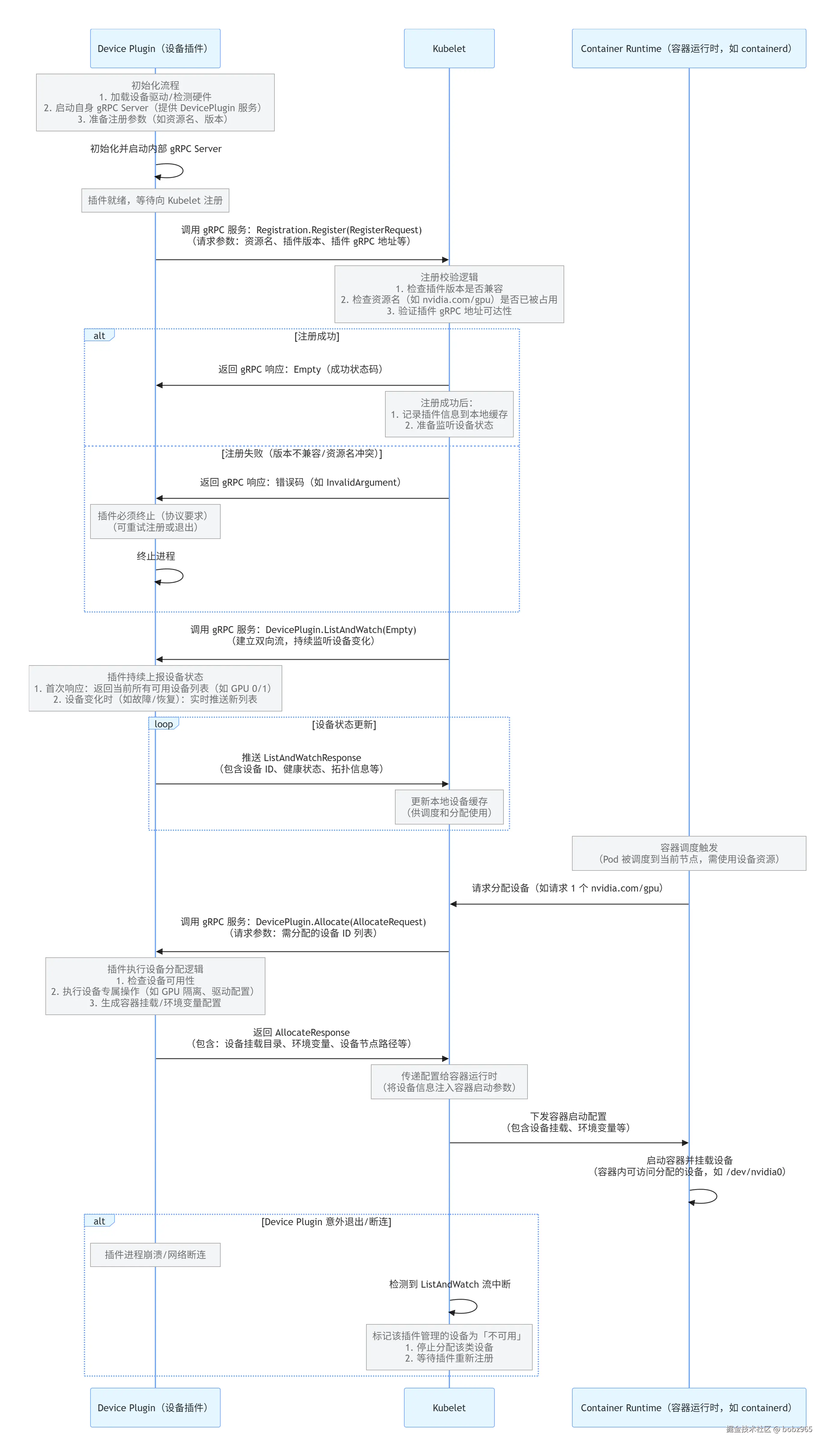
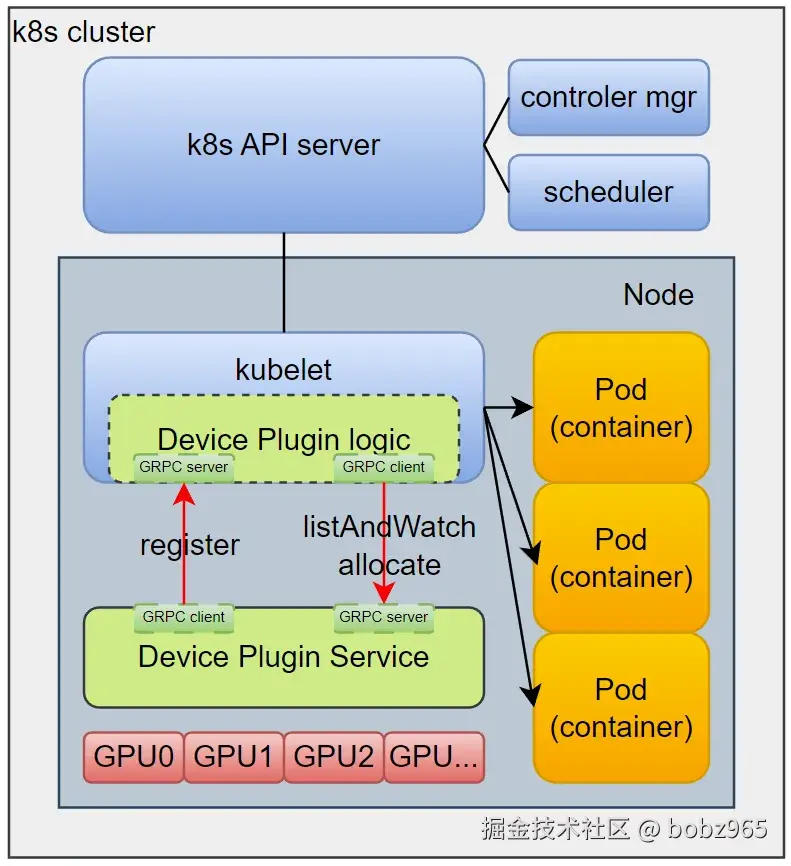
2. Device Plugin 架构的局限性讨论
Kubernetes 的 Device Plugin 架构为硬件设备管理提供了一种标准化接口,但在实际大规模生产环境中逐渐暴露出一些局限性。以下从多个维度分析其不足:
- 设备依赖传递复杂
问题:Device Plugin 的 Allocate 接口仅负责向容器传递设备文件路径和环境变量,无法处理复杂的设备初始化依赖(如 FPGA 固件加载、GPU 驱动版本匹配)。
示例:某 FPGA 设备需在容器启动前加载特定固件,但 Device Plugin 无法保证固件加载顺序,需依赖外部初始化容器(Init Container)或自定义准入控制器。
- 资源分配粒度不灵活
问题:Device Plugin 的分配模型以 整数资源(如 nvidia.com/gpu: 1)为基础,无法直接支持分片资源(如 GPU 算力切片、FPGA 部分重配置区域)。
解决方案局限:尽管可通过自定义资源名称(如 nvidia.com/mig-1g.5gb: 1 )实现分片,但需修改调度器插件,维护成本高。
- 多设备协同支持不足
问题:在多设备协同场景(如 GPU+ 高速网卡 RDMA 通信)中,Device Plugin 无法保证设备间的拓扑亲和性(如 NUMA 对齐、PCIe Switch 分组)。
后果:资源分配可能导致跨 NUMA 访问,显著降低性能。
- 升级与维护成本高
问题:Device Plugin 与 kubelet 通过 GRPC 长连接 通信,升级插件需重启 kubelet 或处理连接重建,可能引发资源分配中断。
案例:升级 NVIDIA GPU 插件时,需确保所有运行中的 GPU 任务已完成,否则可能触发 Pod 驱逐。
- 生态系统碎片化
问题:不同硬件厂商的 Device Plugin 实现差异大(如资源命名、健康检查逻辑),导致运维标准化困难。
示例:Intel FPGA 插件与 Habana Gaudi 插件的设备发现接口完全不同,增加集群管理复杂度。
2. CDI
2.1 CDI 简介
CDI 是由容器运行时社区(如 containerd、CRI-O)提出的一种设备注入标准,旨在通过解耦设备管理与 Kubernetes 核心组件,解决 Device Plugin 的局限性。CDI 核心设计理念:
- 声明式设备注入:通过 JSON 配置文件描述设备需求,由容器运行时在容器启动时动态注入设备。
- 解耦设备管理:硬件厂商提供 CDI 配置文件,无需实现特定 API(如GRPC),降低与 Kubernetes 的耦合。
- 支持复杂设备拓扑:允许定义设备依赖关系(如GPU需要特定驱动版本)、资源组合和拓扑约束。
设备管理和执行继续下沉
2.2 CDI 与 Device Plugin 的对比:
| 维度 | Device Plugin | CDI |
|---|---|---|
| 架构层级 | Kubernetes核心层(kubelet集成) | 容器运行时层(containerd/CRI-O集成) |
| 通信协议 | GRPC长连接 | 静态配置文件(JSON) |
| 设备分配粒度 | 整数资源(如 nvidia.com/gpu: 1) | 灵活(支持设备文件、环境变量、挂载等任意组合) |
| 多设备协同 | 依赖调度器扩展(如拓扑管理器) | 通过配置文件定义设备组和依赖关系 |
| 升级维护 | 需处理GRPC连接重建 | 修改配置文件无需重启组件 |
| 生态系统支持 | 广泛(社区成熟) | 逐步成熟(containerd/CRI-O已支持) |
| 性能开销 | GRPC通信延迟 | 配置文件解析开销(可忽略) |
设备管理和执行继续下沉
2.3 CDI 的核心优势
- 灵活的设备注入模型
示例配置:
json
{
"cdiVersion": "0.4.0",
"kind": "nvidia.com/gpu",
"devices": [
{
"name": "gpu0",
"containerEdits": {
"deviceNodes": [{"path": "/dev/nvidia0"}],
"env": {"NVIDIA_VISIBLE_DEVICES": "0"}
}
}
]
}能力扩展:可注入设备文件、环境变量、挂载卷、内核模块加载等操作。
- 解耦硬件与 Kubernetes
厂商只需提供 CDI 配置文件,无需维护 Device Plugin 守护进程,支持异构运行时(如 containerd、CRI-O、Docker)。
- 拓扑感知与设备组合
定义设备组确保协同分配:
json
{
"kind": "qat.intel.com/group",
"devices": [
{
"name": "qat-group0",
"containerEdits": {
"deviceNodes": [
{"path": "/dev/qat0"},
{"path": "/dev/usdm0"}
]
},
"requirements": {
"devices": ["qat.intel.com/qat0", "qat.intel.com/usdm0"]
}
}
]
}2.4 CDI 的当前挑战
-
生态成熟度:CDI 标准仍处于演进阶段,部分高级功能(如动态配置生成)尚未被所有运行时支持;硬件厂商需适配 CDI 规范,迁移现有 Device Plugin 逻辑。
-
Kubernetes 集成:CDI 本身不处理资源调度,需结合 Kubernetes 扩展(如 Scheduling Framework)实现配额管理;资源预留(kube-reserved)等特性需额外开发。
-
安全边界:CDI 配置文件需严格审核,避免恶意设备注入(如特权设备挂载)。
4.2.5 实际场景对比
-
- 场景1:FPGA 部分重配置
-
Device Plugin:需自定义资源名称(如intel.com/fpga-region-1: 1),并修改调度器插件支持分片。
-
CDI:通过配置文件描述可重配置区域,直接作为独立设备注入,无需修改Kubernetes核心。
-
- 场景2:GPU 与 RDMA 网卡协同
-
Device Plugin:依赖拓扑管理器确保 NUMA 亲和性,但需定制调度策略。
-
CDI:在配置文件中定义设备组,强制绑定 GPU 和网卡设备,由运行时保证同时注入。
4.2.6 未来演进方向
-
- 混合模式:短期过渡方案中,CDI 可与 Device Plugin 共存,CDI负责设备注入,Device Plugin 负责资源调度。
- Kubernetes 原生支持:社区正在推动 KEP-3063 将 CDI 集成到Kubernetes 资源模型。