本案例根据用户上传的电子警察或道路卡口抓拍的图片,使用豆包全新视觉深度思考模型Doubao-1.5-thinking-vision-pro,精准识别车牌号码、车牌颜色、车身颜色、车辆品牌等车辆信息,同时通过算法精确识别开车打电话、未系安全带等交通违法行为,具有极强的实用价值。而DIFY工作流只需3步,下面具体看看豆包Seed1.5-VL模型以及提示词的魅力吧。
一、创建应用
打开浏览器登录DIFY平台,点击"工作室"菜单,创建空白应用,选择"工作流",填写"应用名称",选择图标,点击创建。
二、节点配置
本工作流由"开始"、"LLM生成故事"、"LLM交通违法行为识别"和"直接回复"三个节点实现。

1、开始
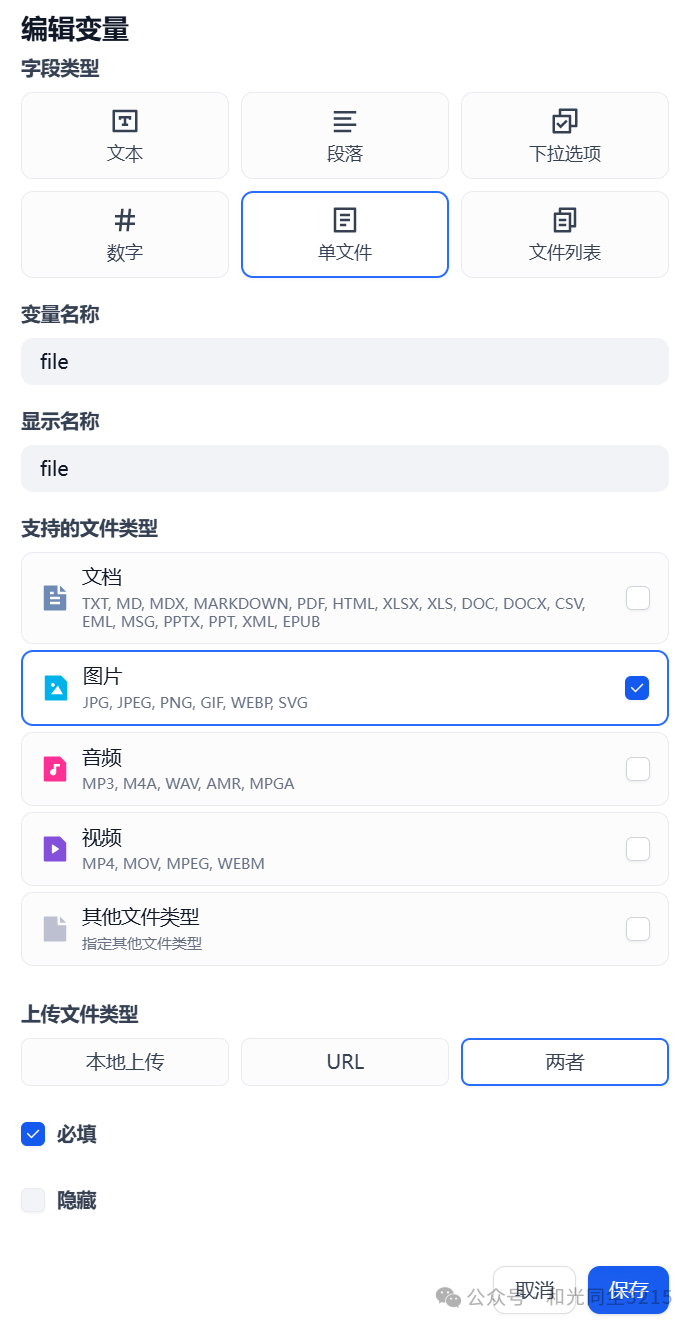
开始节点,添加一个图片类型的文件变量file,用于上传电子警察或道路卡口抓拍的图片。
2、LLM交通违法行为识别
此处是本案例的核心所在,通过精准的提示词,让豆包Doubao-1.5-thinking-vision-pro模型,精准识别车牌号码、车牌颜色、车身颜色、车辆品牌等车辆信息,同时通过算法精确识别开车打电话、未系安全带等交通违法行为。
**模型:**Doubao-1.5-thinking-vision-pro
**上下文:**开始/file
SYSTEM提示词:
你是专业的交通违法图片识别专家,请根据用户上传的图片,准确识别图中的机动车号牌号码、车牌颜色、车身颜色、车辆品牌,同时识别驾驶人是否具有开车打电话或未系安全带的交通违法行为。
# 交通违法图像识别指令
## 核心任务
1. 机动车识别:
- 号牌号码:首位必为34省简称汉字
- 车牌颜色:蓝/黄/白/绿/黑
- 车身颜色:黑/白/灰/红/蓝/绿/黄/棕/其他
- 车辆品牌:识别主流品牌(含进口车)
2. 驾驶行为检测:
- 开车打电话:手持设备贴耳部
- 未系安全带:肩部无斜向带状物
## 车牌首位汉字识别
1. 特征对比:
- 34省简称(京/津/冀/晋/蒙/辽/吉/黑/沪/苏/浙/皖/闽/赣/鲁/豫/鄂/湘/粤/桂/琼/渝/川/贵/云/藏/陕/甘/青/宁/新/台/港/澳)
- 重点区分易混淆字:
• "苏" vs "鄂"(右上角闭合差异)
• "浙" vs "赣"(右侧折角特征)
• "鲁" vs "晋"(田字框比例)
• "甘" vs "豫"
2. 抗干扰处理:
- 滤除反光伪影(HSV空间检测高光区)
- 修复模糊字符(超分辨率重建)
- 排除污渍干扰(形态学开运算除噪)
3. 三重验证:
1) 原始识别结果
2) 字符结构分析(笔画端点/交叉点数量)
3) 上下文校验(符合省简称规范)
# 最终输出格式(严格遵循)
车牌号码:{完整车牌}
车牌颜色:{颜色}
车身颜色:{颜色}
车辆品牌:{品牌}
开车打电话:{是/否}
未系安全带:{是/否}
# 执行约束
1. 车牌首位识别必须完成34选1匹配
2. 不确定时输出"识别失败"而非猜测USER提示词:
请根据用户上传的图片{{#1753663527066.file#}},准确识别图中的机动车号牌号码、车牌颜色、车身颜色、车辆品牌以及开车打电话、未系安全带等交通违法行为开启视觉功能。

3、直接回复
此处非常简单,只要将"LLM交通违法行为识别"节点识别结果输出即可。
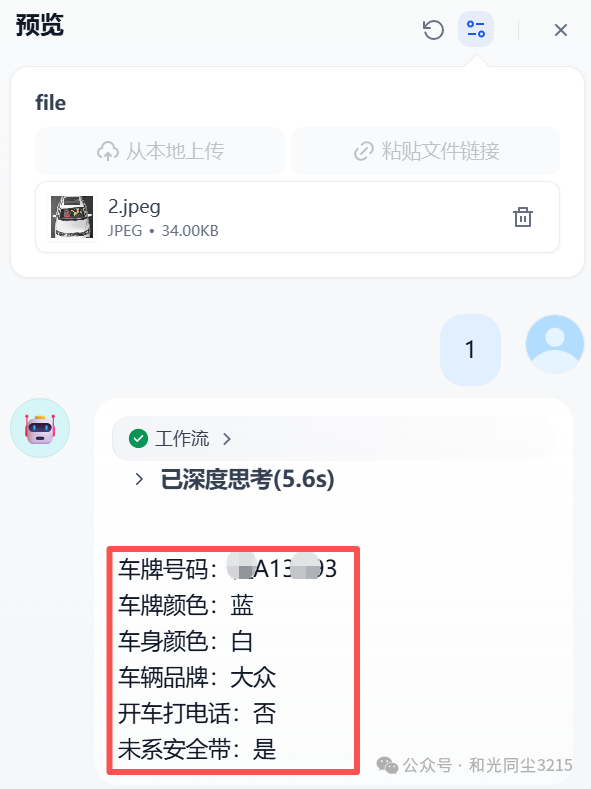
三、预览验证
接下来我们看看识别结果到底如何,我们上传一张驾驶员"未系安全带"的图片,看看识别结果。

点击"预览",从本地上传这张图片,看看识别结果。