为什么需要流式响应
在与大模型交互时,用户通常希望立刻看到用户的输出,而不是等待整个响应生成完毕。例如,在与AI聊天时,你希望看到模型逐字逐句地回复,就像对面有人在打字一样。这要求服务器在生成内容的过程中,能够分块,实时地将数据发送给前端。
效果观赏:
前端在流式响应的方案
方案一:WebSocket
WebSocket 通过三个关键特性完美解决了大模型流式响应的需要:持久化的全双工连接,帧机制和消息实时推送:
-
持久化的全双工连接:
- 工作方式:一旦 WebSocket 连接建立,它就会一直保持开放状态,直到被显示关闭,这个单一的 TCP 连接可以同时进行双向通信。
- 解决的问题:与 HTTP/1.1 每次请求都要重新建立连接不同,WebSocket 避免了反复握手和连接的开销,这对于需要长时间通信的流式应用至关重要。
-
帧机制:
- 工作方式:WebSocket 在应用层将数据分割成多个"帧"(Frames)。服务器在模型上生成一个词或者一个句子后,立刻将这个小块的数据打包成一个帧发送出去。
- 解决的问题:WebSocket 协议的低开销帧机制,使得前端不需要等待一个完整的JSON对象,而是可以接受一个又一个的文本或二进制数据。
-
消息推送:
-
工作方式:由于 WebSocket 是服务器主动推送的。当大模型生成新的内容时,服务器可以立即通过已建立的连接将这些内容发送给前端,而无需前端进行轮询。
-
解决的问题:消除了传统 HTTP 轮询模式带来的延迟和资源浪费,前端页面可以实时地接收数据并渲染数据,实现流畅的打字机效果。
-
具体的工作流程如下:
-
连接建立:前端页面通过
new WebSocket()方法,向服务器发起一个请求(wss://)。 -
握手:服务器验证请求,如果通过,会返回一个特殊的响应,完成握手,连接正式建立。
-
请求发起:前端会向服务器发送一个请求。
-
服务器处理:服务器把收到的请求交给大模型处理。
-
流式响应:大模型开始生成输出。每生成一小段内容,服务器就会把其封装成一个 WebSocket 消息帧,通过已建立的连接立即发送给前端。
-
前端实时渲染:前端的 onmessage 监听器会不断地接收这些消息帧。每收到一个,前端就会把新的内容追加到页面上,实现实时渲染。
-
结束标志:当大模型生成完毕,服务器会发送一个特殊的"结束帧",告诉前端流式响应已完成。
-
连接保持:连接保持:整个过程结束后,WebSocket 连接依然保持开放,等待下一次通信。
方案二:SSE(Server-Sent Events,服务器发送事件)
在前端大模型应用中,SSE(Server-Sent Events,服务器发送事件)是另一种实现流式响应的有效方式。与 WebSocket 不同,SSE是一种基于 HTTP 的协议,专门用于服务器向客户端单向推送数据流。
SSE 的工作机制非常简洁:
-
基于HTTP的长连接:客户端发起一个普通的HTTP请求,但服务器不会立即关闭连接,而是保持它开放。
-
MIME类型:服务器返回的 Content-Type 必须是 text/event-stream。
-
数据流:服务器不断地向这个开放的连接写入格式化的文本数据,每一条消息都已特定的格式(data:...)发送。
-
自动重连:如果这个连接中断,浏览器会自动尝试重新连接。
SSE如何实现 大模型 响应:
-
建立连接:前端会使用内置的 EventSource() 创建一个到服务器的连接
-
服务器处理:服务器接收到这个请求后,它不会向处理普通 HTTP 请求那样一次性返回所有数据,而是保持连接开放,并将大模型生成的内容逐块写入响应流。
-
数据格式:服务器发送的每一条消息都必须遵循 SSE 的特定格式,通常以
data:开头,并以换行符结束。 -
前端监听:前端的 EventSource 对象会持续监听数据流。每当服务器发送一个完整的消息块,onmessage 事件就会被触发。
-
错误和重连:EventSource 内置了自动重连机制,大大简化了前端的异常处理。
方案三:fetch方法+ReadStream
适用场景
fetch 的流式输出特别适合那些只需要从服务器获取数据流 ,而不需要双向实时交互的场景。
- 大模型 生成:客户端发起一个请求,接收大模型的完整输出,且在此过程中不需要向服务器发送其他指令。
- 文件下载:当下载大文件时,可以分块接收数据并实时写入本地文件,避免一次性加载到内存。
总结 :fetch 提供了实现流式输出的能力,让你可以在不依赖第三方库 的情况下,实现高效的数据流处理。它的主要缺点是需要手动处理重试和缺乏双向通信能力,但对于许多大模型应用来说,这已经足够了。
下文会结合项目详细讲解
WebSocket 与 SSE 的区别
- WebSocket 与 SSE 对比如下:
| 特性 | SSE | WebSocket |
|---|---|---|
| 通信模式 | 单向通信:服务器向客户端推送 | 全双工,双向通信 |
| 协议 | 基于 HTTP | 基于 TCP 的独立协议 |
| 实现复杂性 | 简单,浏览器内置EventSource API | 较复杂,需要专门的库 |
| 自动重连 | 内置,浏览器自动处理 | 需要手动实现 |
| 二进制数据 | 不支持,仅支持 UTF-8编码的文本 | 支持。文本/二进制均可传输 |
| 适用场景 | 实时股票行情,新闻推送等"只读流" | 在线聊天,多人协作游戏等需要双向交互的场景 |
-
总结:
-
如果只需要从服务器接收大模型的流式响应,且无需再流传输过程中向服务器发送消息,那 SSE 是一个优雅且简单的选择。它利用了 HTTP 协议,内置了自动重连功能,降低开发复杂度。
-
如果你的应用需要更复杂的双向实时通信,比如聊天机器人等,那么 WebSocket 是更为灵活和复杂的方案。
-
项目场景实现
背景
在使用 Coze 智能体实现大模型流式响应时,HelloKitty 同学遇到了一个问题:Coze 的 API 需要通过请求头传输 Token 进行身份验证,但原生的 SSE (Server-Sent Events) 不支持自定义请求头。
为了解决这个矛盾,HelloKitty 同学选择了 fetch 结合 ReadableStream 的方案。这种方法不仅能够处理流式数据,还能通过 fetch 请求头灵活地发送 Token,完美解决了认证问题。
代码示例分析
javascript
const response = await fetch(`https://api.coze.cn/v3/chat${params}`, {
method: "post",
headers: {
Authorization: `Bearer ${cozeToken}`,
"Content-Type": "application/json",
},
body: JSON.stringify({
stream: true,
bot_id: botId,
user_id: userName,
additional_messages: additionalMessages,
}),
})
if (!response.ok) {
throw new Error("Network response was not ok")
}
if (!response.body) {
throw new Error("Response body is null")
}
const reader = response.body.getReader() // 获取可读流
const decoder = new TextDecoder("utf-8") // 解码流
let done = false
let buffer = "" // 用于存储流数据
let answer = "" // 用于存储回复
// 逐步读取流,处理流式数据
while (!done) {
const { value, done: isDone } = await reader.read()
done = isDone
if (value) {
const decodeValue = decoder.decode(value, { stream: true })
buffer += decodeValue
// 可以打印 decodeValue 查看流数据
// console.log(decodeValue);
try {
const parsedData = parseEventStream(decodeValue)
if (parsedData) {
const eventData = parsedData
for (let i = 0; i < eventData.length; i++) {
if (eventData[i].event === "conversation.message.delta") {
answer += eventData[i].data.content
}
// 处理其他事件,有一些联想问题,可通过 event:conversation.message.completed 和 "type":"follow_up" 判断
}
}
} catch (error) {
// Continue accumulating buffer if parsing fails
console.error("解析流数据时出错:", error)
}
}
// 此answer为持续更新的回复
console.log(answer)
}
return buffer // 返回流处理后的结果
}结合以上代码,我们总结出如何如何实现的流式响应:
- 发起流式请求 :利用 Fetch 函数发起一个 POST 请求。与传统请求不同的是,它在请求体中设置了
stream:true,这是告诉 Coze API 服务器,希望以流的形式返回响应数据。同时,它在请求头中加入了 ``Authorization: `Bearer ${cozeToken}```,用于身份验证。 - 获取可读流(ReadableStream) :请求发送后,fetch返回的响应对象 response 上的 body 属性就是流式数据的源头,一个 ReadableStream 的对象。代码通过 response.body.getReader() 获取了一个 reader。这个 reader 提供了 read 的方法,用于从流中逐块读取数据。
- 逐块读取与解码数据:代码进入一个 while 循环,直至流被全部读取完毕(isDone:true)。每次循环中,await reader.read()会读取流中的下一块数据。
注:流数据是二进制格式,但是 SSE 不支持二进制格式的传输,因此代码中使用了 Web 内置的 API TextDecoder("utf-8"), 将这些字节块解码为字符串,并附加到 Buffer 变量中。
-
解析 SSE 数据:Coze API 返回的流数据遵循 Server-Sent Events(SSE) 格式。它会接受一个字符串作为输入,按行分割,并查找 event:和 data:标记。
-
实时处理和拼接回复:每当成功解析一块数据后,都会提取文本片段,逐步追加。
场景思考
思考一:大模型流式响应输出到一半终止了怎么办
如果大模型在流式响应输出到一半终止了,通常是由于网络连接,服务端或客户端的异常导致的。处理这种情况,需要做一套健壮的机制来完善,从而确保用户体验和数据完整性。我们遇到这种情况,需要通过"发现问题 ------> 定位问题 ------>解决问题 ------>完善后端------>前端提升体验"这个流程。
流程模型:
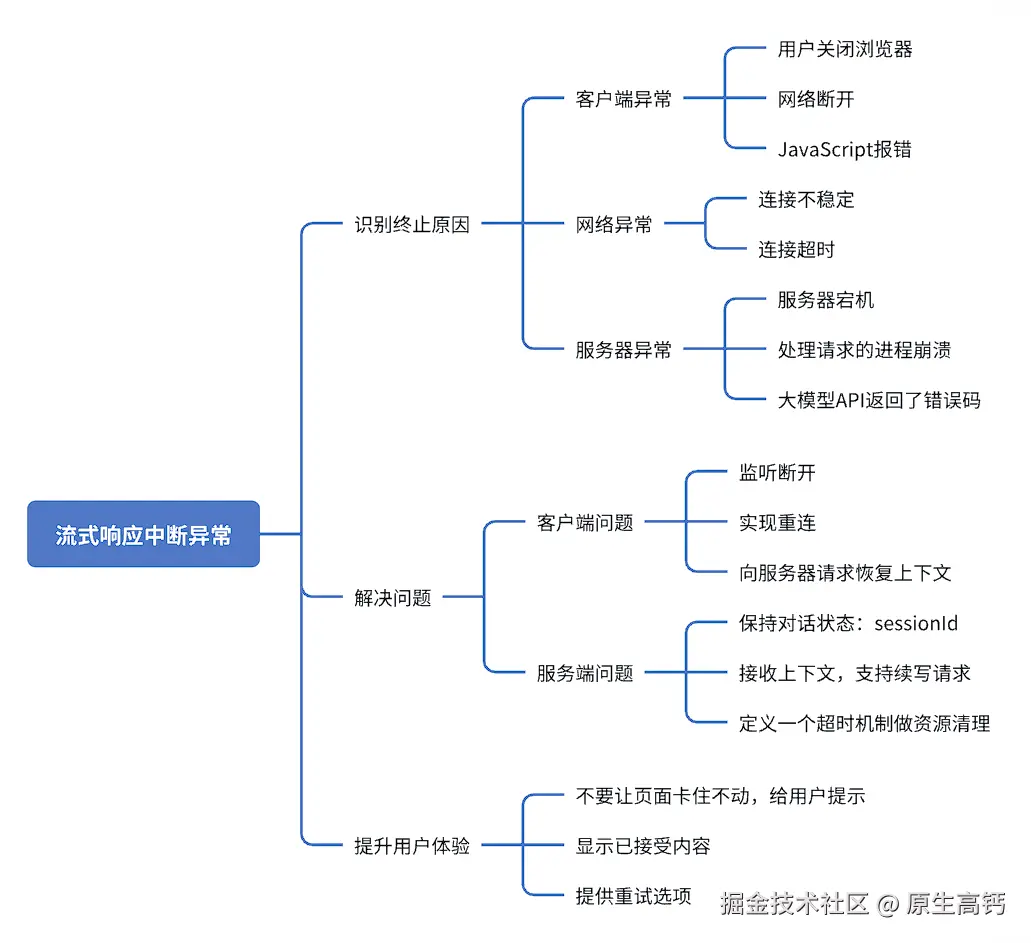
总结 :处理大模型流式响应中断的核心在于**客户端的容错机制和服务器的上下文管理**。
- 客户端:通过监听断开事件,并结合重连策略
- 服务器:通过保存对话状态和支持续写请求,保证在连接恢复后能够继续生成
思考二:对接多个LLM时,数据块返回不完整怎么办
核心思路:利用 TransformStream 来搭建一个数据管理通道,它能够实时处理和转换从大模型 API 返回的流式数据。
步骤如下:
-
流式数据获取与解码:
response.body.pipeThrough(...):通过管道pipeThrough将原始的 HTTP 响应流连接到一个自定义的转换流,并将二进制 chunk 转换为字符串。
-
缓冲区与数据累积:
buffer+=textChunk缓存所有接收到的数据,即使数据时不完整的,也就可以被联系累积到这个字符串中 -
数据格式判断与处理:
- 完整 JSON 对象:如果返回一个完整 JSON 错误信息,这个逻辑就可以被捕获
- SSE 格式处理:开始标记通过寻找 data: 来识别一个事件的开始,结束标记通过 }\n\n 来判断完整JSON对象的结束。
-
适配与转换转换:
- adapter.transform2OpenAiResponse4Stream(...) 这是一个适配器模式,将不同 LLM 返回的原始数据格式转换为统一你想要的格式。转换后的数据会被重新编码,并重新推入管道形成统一格式的流
代码如下:
ini
export function isValidJsonStr(str: string) {
if (typeof str !== 'string') {
return false;
}
try {
const parsed = JSON.parse(str);
return typeof parsed === 'object' && parsed !== null;
} catch (e) {
return false;
}
}
const response: Response = await fetch(requestInit);
const decoder = new TextDecoder('utf-8');
const encode = new TextEncoder();
if (response.body) {
let accumulatedData = ''; // 初始化累积的数据为空字符串
let buffer = ""; // 初始化缓冲区为空字符串
response.body
.pipeThrough(
new TransformStream({
transform(chunk, controller) {
const textChunk = decoder.decode(chunk, { stream: true }); // 解码数据块
accumulatedData += textChunk; // 将解码后的数据块添加到累积的数据中
// 查找完整的 JSON 对象
while (true) {
// 如果返回的是 json 字符串 一般都是大模型直接报错了
if (isValidJsonStr(accumulatedData)) {
const transformedChunk =
adapter.transform2OpenAiResponse4Stream(accumulatedData); // 转换数据块 这里自己实现转换方法吧!
const handledChunk = encode.encode(transformedChunk); // 编码转换后的数据块
self.chunks.push(transformedChunk); // 将转换后的数据块添加到数据片段数组中
controller.enqueue(handledChunk); // 将编码后的数据块推入控制器
accumulatedData = ""; // 重置累积的数据为空字符串
break; // 退出循环
} else {
const dataStartIndex = accumulatedData.indexOf("data: "); // 查找 'data: ' 开头的数据块
if (dataStartIndex === -1) {
// 如果没有找到 'data: ' 开头的数据块,保留当前累积的数据
buffer = accumulatedData;
accumulatedData = "";
break;
}
const jsonStartIndex = dataStartIndex + 6; // 跳过 'data: '
const jsonEndIndex = accumulatedData.indexOf(
"}\n\n",
jsonStartIndex
); // 查找完整的 JSON 对象结束位置 这里可以进一步优化,因为担心json中也会出现 "}\n\n"
if (jsonEndIndex === -1) {
// 如果没有找到完整的 JSON 对象,保留当前累积的数据
buffer = accumulatedData;
accumulatedData = "";
break;
}
// 提取完整的 JSON 对象
const jsonString = accumulatedData.slice(
jsonStartIndex,
jsonEndIndex + 1
);
try {
// 处理完整的 JSON 对象
const transformedChunk =
adapter.transform2OpenAiResponse4Stream(
"data: " + jsonString
) + "\n\n"; // 转换数据块
const handledChunk = encode.encode(transformedChunk); // 编码转换后的数据块
self.chunks.push(transformedChunk); // 将转换后的数据块添加到数据片段数组中
controller.enqueue(handledChunk); // 将编码后的数据块推入控制器
} catch (error) {
console.error("Error parsing JSON:", error); // 如果解析 JSON 失败,打印错误信息
// 如果解析 JSON 失败,保留当前累积的数据
buffer = accumulatedData;
accumulatedData = "";
break;
}
// 移除已处理的 JSON 对象
accumulatedData = accumulatedData.slice(jsonEndIndex + 3);
}
}
},
})
)
.pipeTo(writable) // 将处理后的数据流管道连接到可写流
.catch((error) => {
console.error("Error:", error); // 捕获并打印错误
throw new Error("Handle stream response error"); // 抛出错误
});
const processedResponse = new Response(readable, {
status: response.status,
statusText: response.statusText,
headers: response.headers,
});
return processedResponse; // 构建并返回处理后的响应对象
}总结展望
在实践中,尽管会遇到数据不完整、格式不统一等挑战,但通过缓冲区 、智能解析器 和适配器模式等技术,我们能够构建一个健壮的系统,确保无论是哪个大模型,都能提供流畅、可靠的流式响应体验。
最终,流式响应不仅仅是技术上的优化,更是用户体验上的一大飞跃,它让大模型的交互变得更加自然、高效,也为未来的 AI 应用开启了更多可能性。