点一下关注吧!!!非常感谢!!持续更新!!!
🚀 AI篇持续更新中!(长期更新)
AI炼丹日志-31- 千呼万唤始出来 GPT-5 发布!"快的模型 + 深度思考模型 + 实时路由",持续打造实用AI工具指南!📐🤖
💻 Java篇正式开启!(300篇)
目前2025年08月18日更新到:
Java-100 深入浅出 MySQL事务隔离级别:读未提交、已提交、可重复读与串行化
MyBatis 已完结,Spring 已完结,Nginx已完结,Tomcat已完结,分布式服务正在更新!深入浅出助你打牢基础!
📊 大数据板块已完成多项干货更新(300篇):
包括 Hadoop、Hive、Kafka、Flink、ClickHouse、Elasticsearch 等二十余项核心组件,覆盖离线+实时数仓全栈!
大数据-278 Spark MLib - 基础介绍 机器学习算法 梯度提升树 GBDT案例 详解
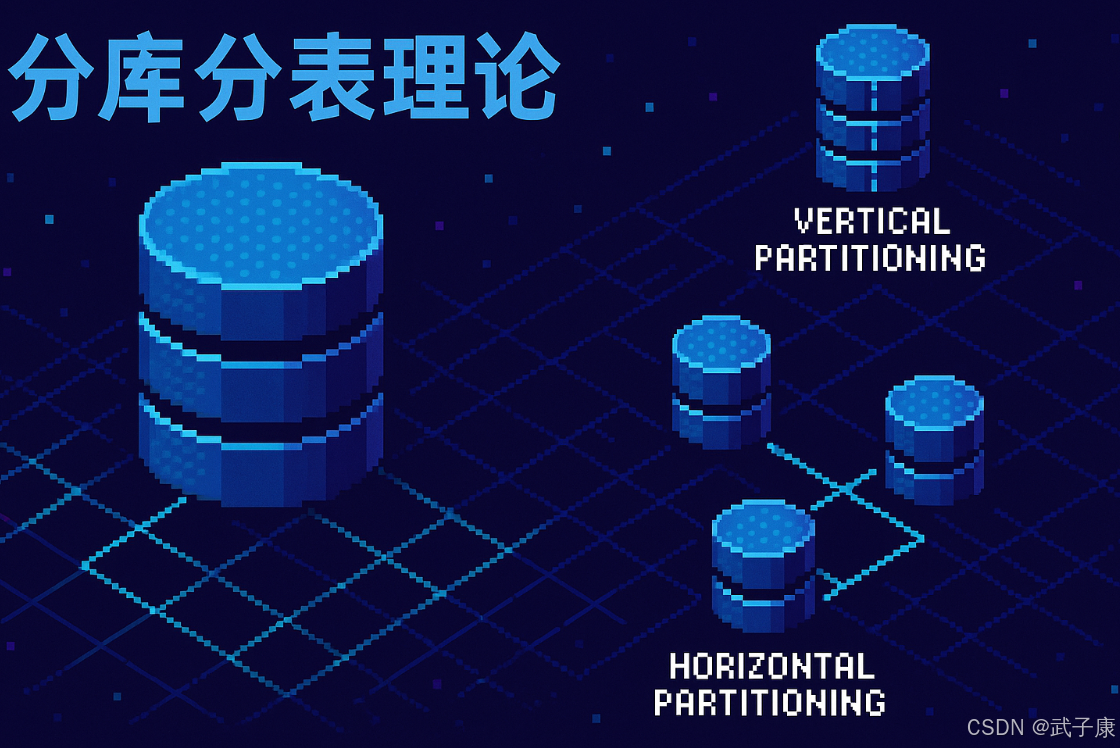
分库分表理论
基本介绍
互联网系统需要处理海量用户的并发请求和数据存储。以微信为例,其日活跃用户已突破10亿大关,每天产生数百亿条消息记录;美团外卖平台每日处理超过3000万订单;支付宝在双十一期间每秒要处理数十万笔交易。这些系统都面临着用户表、订单表、交易流水表等数据表的存储和查询压力。
随着业务持续发展,这些核心数据表呈现以下特点:
- 数据量呈指数级增长,单表记录可能达到数十亿条
- 历史数据必须长期保存,不能简单删除
- 需要支持高并发读写,峰值QPS可能达到百万级
- 查询延迟必须控制在毫秒级别
当传统的关系型数据库(如MySQL)面临这些挑战时,单纯的读写分离和缓存方案往往存在局限性:
- 读写分离只能缓解读压力,无法解决写入瓶颈
- 缓存不适合存储全量数据,且存在一致性问题
目前主流的解决方案包括:
- NoSQL数据库(如MongoDB、HBase):适合非结构化数据存储
- NewSQL数据库(如TiDB):兼具SQL和分布式特性
- 分库分表:对现有关系型数据库的扩展方案
分库分表策略
分库分表主要分为两种物理拆分模式:
垂直拆分(Vertical Partitioning)
- 适用场景:单个数据库中存在大量表(如超过1000张表)
- 拆分原则:按业务领域将表分类到不同数据库
- 示例:将用户基础信息表、用户行为表拆分到不同库
- 优势:
- 降低单库表数量
- 不同业务可以使用独立的数据库资源
- 注意事项:
- 跨库事务处理复杂
- 关联查询需要应用层实现
水平拆分(Horizontal Partitioning)
- 适用场景:单表数据量过大(如超过5000万条记录)
- 拆分方式:
- 按范围拆分:如按用户ID区间划分
- 按哈希值拆分:如对订单ID取模
- 按时间拆分:如按月分表
- 优势:
- 分散单表存储压力
- 提高并行查询效率
- 挑战:
- 需要处理分布式ID生成
- 跨分片查询性能较差
- 数据再平衡较复杂
实际应用中,这两种拆分方式经常结合使用。例如电商系统可能先按业务垂直拆分为订单库、商品库、用户库,再对订单库按时间进行水平拆分。
拆分方式
垂直拆分
垂直拆分(Vertical Partitioning)又称为纵向拆分,是一种数据库架构设计方法,通过将表按照业务维度进行分离,或者修改表结构按照数据访问模式的差异将某些列拆分出去。这种拆分方式主要应用于关系型数据库的优化场景,能够有效解决单表数据量过大、字段过多导致的性能问题。
垂直拆分的两种主要实现方式:
-
垂直分库(Vertical Database Sharding)
- 按照业务模块将不同的表拆分到不同的数据库中
- 例如:将电商系统中的用户数据、订单数据、商品数据分别存放在不同的数据库实例
- 典型场景:微服务架构中,每个服务使用独立的数据库
- 优势:降低单库压力,提高系统整体吞吐量
-
垂直分表(Vertical Table Partitioning)
- 将一个大表按照字段访问频率拆分成多个小表
- 例如:将用户表拆分为基础信息表(高频访问)和详细信息表(低频访问)
- 典型场景:用户表中包含大量不常访问的字段(如个人简介、扩展信息等)
- 优势:减少I/O开销,提高热点数据的访问效率
适用场景:
- 表中包含大量不经常访问的字段
- 不同业务模块的数据访问模式差异较大
- 单表数据量过大导致查询性能下降
- 需要实现业务模块的高内聚、低耦合
实施注意事项:
- 需要考虑跨库事务的处理方案
- 可能需要调整应用层的数据访问逻辑
- 评估JOIN操作的影响,可能需要引入数据冗余
- 监控系统整体性能变化
注:在实际应用中,虽然垂直拆分包含分库和分表两种方式,但业界讨论垂直拆分时通常主要指的是垂直分库方案,因为垂直分表更多被视为一种表结构优化技术。
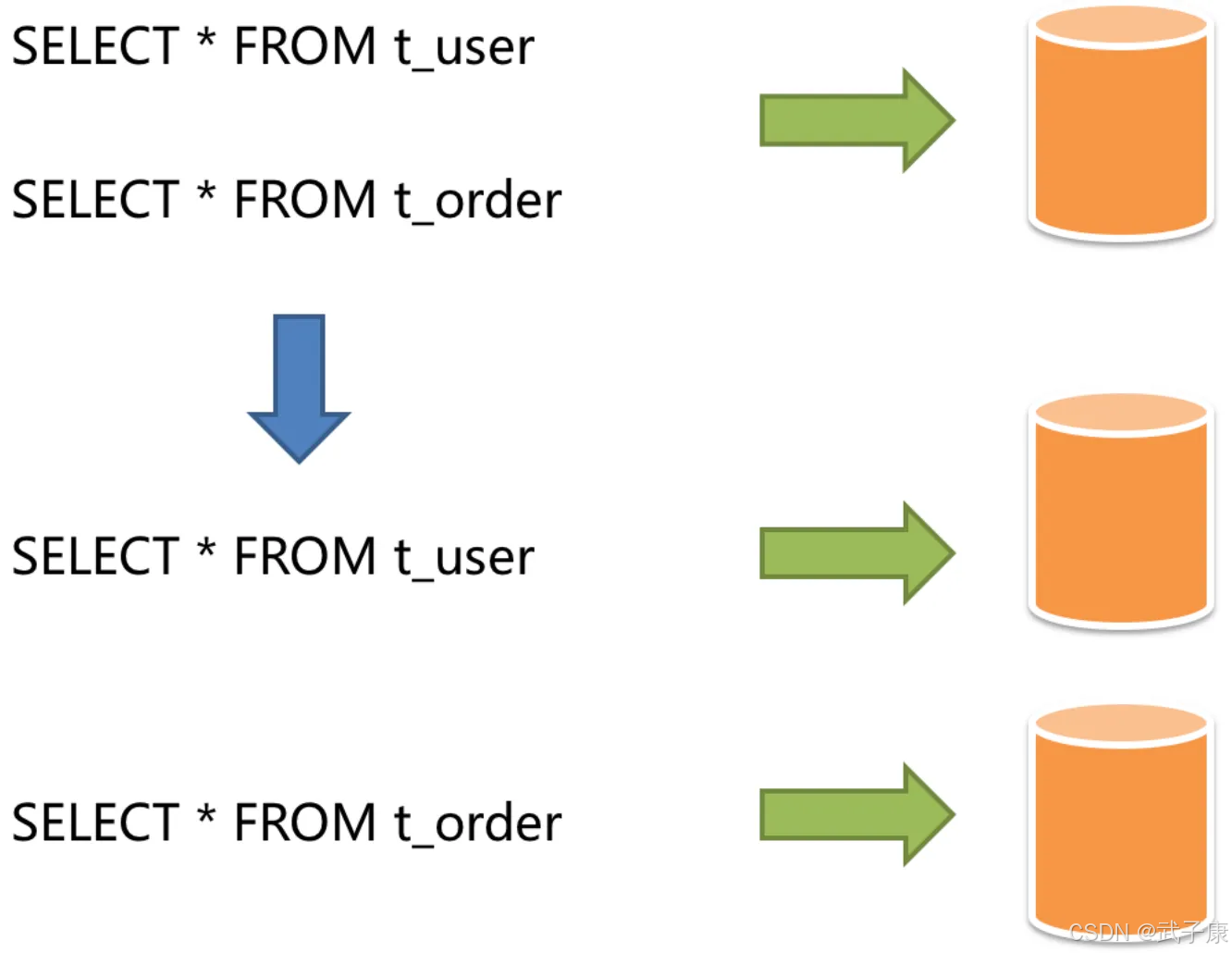
垂直分库
如下图所示,采用垂直分库,将用户表和订单表拆分到不同的数据库中:
垂直分表
垂直分表是将一张表中不常用的字段拆到另一张表中,从而保证主表中仅保留高频访问的字段。这种拆分方式能有效解决以下问题:
-
数据跨页存储问题:当表中存在大量字段时,单条记录可能会跨多个数据页存储,导致查询时需要读取更多的数据页,降低I/O效率。通过垂直分表可以减少主表的字段数量,使单条记录更紧凑地存储在单个数据页中。
-
查询性能优化:将不常用的字段(如用户档案中的"个人简介"、"备注"等)分离出去后,主表仅保留核心字段(如用户ID、姓名、联系方式等),这样在执行高频查询时只需访问较小的主表,提高查询速度。
-
大字段管理:对于TEXT、BLOB等大字段类型,垂直分表是特别有效的优化手段。这些大字段往往占用大量存储空间但访问频率较低,将其拆分到副表可以避免它们影响主表的性能。
典型应用场景
-
用户信息表:
- 主表(user_basic):用户ID、用户名、手机号、邮箱、状态等高频字段
- 副表(user_profile):个人简介、兴趣爱好、教育背景等低频字段
-
商品信息表:
- 主表(product_basic):商品ID、名称、价格、库存等核心信息
- 副表(product_detail):商品详情描述、规格参数、使用说明等大文本字段
-
内容管理系统:
- 主表(article_basic):文章ID、标题、作者、发布时间
- 副表(article_content):文章正文内容
实施步骤
- 字段分析:统计各字段的访问频率和重要性
- 拆分方案设计:确定主表和副表包含的字段
- 外键关联:确保主表和副表通过主键关联
- 应用层改造:修改业务代码,按需查询主表或关联查询
- 数据迁移:将现有数据拆分到新的表结构中
- 性能测试:验证拆分效果
注意事项
- 需要权衡查询性能与关联查询的代价
- 对于需要同时访问主副表字段的查询,要考虑JOIN操作的开销
- 确保事务一致性,特别是跨表更新的场景
- 合理设计索引,特别是关联字段的索引
通过合理的垂直分表,可以有效优化数据库性能,特别是在处理包含大量字段或大字段的表时效果显著。
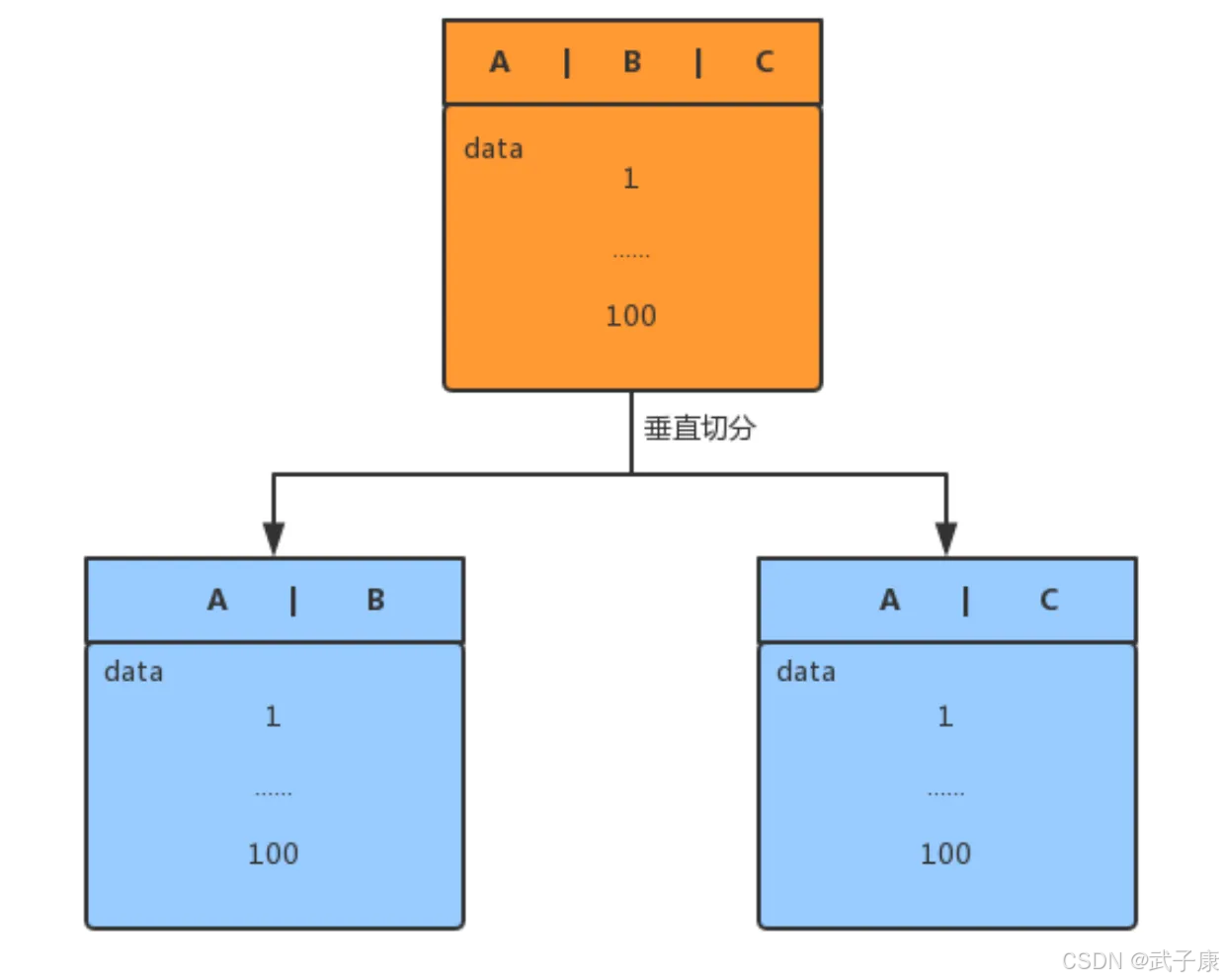
按列进行垂直拆分,即把一条记录分开到多个地方保存,每个子表的行数相同,把主键和一些列放到一个表,然后把主键和另外的列放到另一个表中。
垂直优点
● 业务解耦清晰:拆分后业务边界划分明确,各业务模块职责单一。例如电商系统可以拆分为用户中心、商品中心、订单中心等,每个中心只处理特定业务数据。
● 数据可维护性强:数据表结构简化后更容易进行维护和扩展。当需要新增字段时,只需在对应的垂直分表中添加,不会影响其他业务模块的数据表。
● 查询性能提升:行数据变小后,单个数据块(Block)能存储更多行数据。例如用户基础信息表拆分为核心表(用户ID、用户名)和扩展表(地址、爱好等),查询用户列表时IO次数显著减少。
● 缓存利用率优化:通过合理拆分可以将高频访问的"热数据"(如价格、库存)和低频访问的"冷数据"(如商品描述)分离,使得热点数据更容易被缓存命中。例如将商品详情页的浏览数和商品参数分开存储。
● 冷热数据分离:便于实现冷热数据分层存储策略。可以将历史订单等冷数据迁移到成本更低的存储系统,而活跃订单等热数据保留在高性能数据库中。
垂直缺点
● 主键冗余管理:拆分后各分表都需要包含原表主键,例如订单表和订单明细表都需要order_id字段。这会带来额外的存储开销,并需要确保主键值的一致性。
● 跨表连接问题:业务逻辑需要关联多个分表数据时,必须进行JOIN操作。例如查询订单详情需要关联订单基本信息和商品信息。虽然可以通过应用层JOIN减轻数据库压力,但增加了代码复杂度。
● 单表容量限制:垂直拆分仅解决表字段过多的问题,单个分表的数据量仍可能过大。例如用户行为日志表即使用户ID、操作类型等字段拆分后,日志记录数仍可能超亿级。
● 事务处理困难:跨分表的事务操作需要分布式事务支持。例如下单时需要同时更新库存表和订单表,在微服务架构下可能涉及跨服务事务,处理复杂度显著增加。
水平拆分
水平拆表
水平拆分又称为横向拆分,相对于垂直拆分,它不再将数据根据业务逻辑分类,而是通过某个字段(或者几个字段),根据某种规则将数据分散到多个库或者表中,每个表仅包含一部分数据,如下图所示:
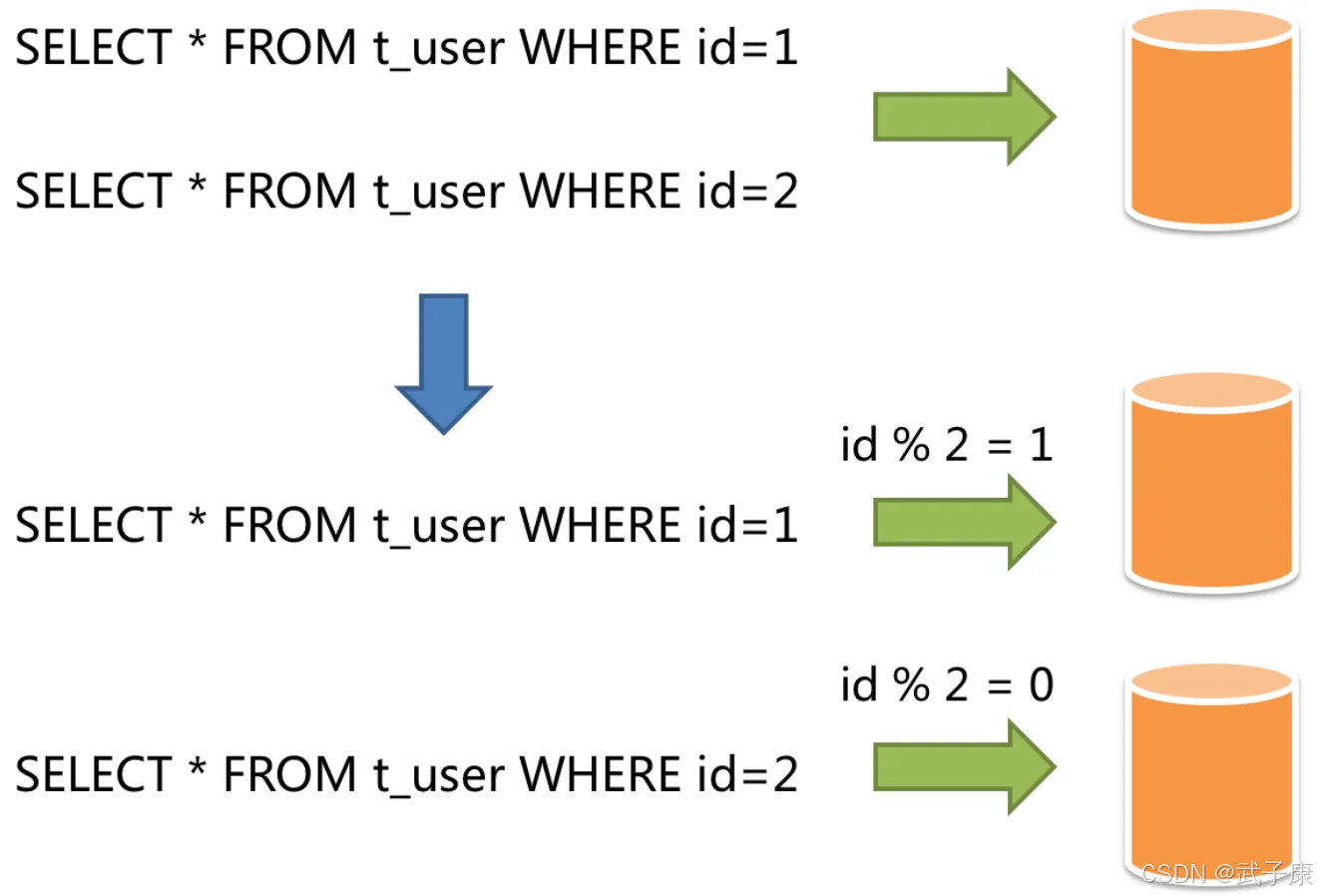
水平分表是将一张含有多个记录数的表水平切分,不同的记录可以分开保存,拆成几张结构相同的表,如果一张表中的记录数过多,那么会对数据库的读写性能产生较大的影响,虽然此时仍然能够正确的读写,但读写的速度已经到了业务无法忍受的地步,此时就需要使用水平分表来解决这个问题。
● 水平拆分:解决表中记录过多的问题
● 垂直拆分:解决表过多或者是表字段过多问题
水平拆分重点考虑拆分规则:时间、范围、Hash算法
拆分优点
● 数据库分担计算压力:通过精心设计的拆分规则,大部分join操作可以直接在数据库层面完成,减少应用层处理逻辑。例如用户表和订单表按照相同的用户ID哈希分片,关联查询时各分片可以并行执行。
● 解决单库性能瓶颈:将单表数据分散到多个物理节点,每个分片只存储部分数据,有效避免了单表数据量过大导致的索引膨胀、查询变慢等问题。比如电商平台的订单表按月分片后,每月的订单查询性能可保持稳定。
● 应用改造成本可控:采用水平分片策略时,各分片表结构完全一致,应用层主要需要改造数据访问层,增加分片路由逻辑(如基于ShardingKey的路由算法),业务代码无需大规模调整。
● 系统扩展性提升:通过增加分片节点可以线性扩展系统处理能力。当某个分片负载过高时,可以单独对该分片进行扩容。例如双11期间可以临时增加热点商品所在的分片资源。
拆分缺点
● 分片规则设计复杂:需要综合考虑数据分布、查询模式、业务增长等因素。例如用户数据按地域分片时,可能出现某些地区用户激增导致数据倾斜。不合理的分片规则可能导致后期重构。
● 跨分片查询性能低下:需要合并多个分片结果的查询(如全表扫描)性能较差。例如未带分片键的用户订单统计查询,需要访问所有分片后再聚合计算,响应时间可能增长数倍。
● 分布式事务挑战:涉及多个分片的写操作难以保证ACID特性。例如转账业务需要同时更新两个分片的账户余额,只能通过最终一致性方案补偿,增加了业务复杂度。
● 扩容维护成本高:数据再平衡需要停机迁移,如从2个分片扩展到4个分片时,需重新计算所有记录的分片位置并迁移数据。这期间可能影响线上服务,且需要开发专门的数据迁移工具。