下面采用的方式是转成markdown然后再导出word,网上有些说用AI转成html并导出word的,自己没有尝试成功。
预处理
LaTeX文件有一些多余的换行符,另外还有一些markdown不识别的环境,需要用AI处理一下。
比如LaTeX原文为
这一段在LaTeX中编译显示为完整段落,但在Word中需要删除多余空行。
人工智能的历史可以追溯到20世纪中叶,其起源与计算机科学的发展密切相关。
1950年,英国数学家艾伦·图灵发表了具有里程碑意义的论文《计算机器与智能》,首次提出了"机器是否能够思考"的问题。
1956年,在美国达特茅斯学院举行的一次学术会议上,麦卡锡等人正式提出了"人工智能"这一术语,标志着该领域作为一门独立学科的诞生。
像上面这样, LaTeX的段落之间还可能有大量多余的换行符。
这里尝试插入几个行内公式$T$、$\alpha$。
下面是一个行间公式,其中的\eu是正体的e。
\begin{equation}
o_t=\left\{R_{k},\dot{R}_{k},\dot{\lambda}_{k}\right\},\; k\in\{MT,MD\}
\end{equation}
下面是align环境的行间公式。
\begin{align}
&f_1(x)=\eu^{-\beta_1|x|}+\eu^{-\beta_2|x|}\\[-5pt]
&f_2(y)=\alpha[(y\leq R_1)+(y\leq R_2)+(y\leq R_3)]\\[-5pt]
&r_t = f_1(R_{MT})+f_2(R_{MT})-f_1(R_{MD})-f_2(R_{MD})
\end{align}在大模型中输入提示词
bash
下面是论文的latex代码,将以下内容转换为markdown格式,给出可复制的markdown代码。
删除多余的换行符。
其中的\eu是正体的e,改为\mathrm{e}。Qwen输出的结果为(不用开深度思考,不然输出太慢)
人工智能的历史可以追溯到20世纪中叶,其起源与计算机科学的发展密切相关。1950年,英国数学家艾伦·图灵发表了具有里程碑意义的论文《计算机器与智能》,首次提出了"机器是否能够思考"的问题。1956年,在美国达特茅斯学院举行的一次学术会议上,麦卡锡等人正式提出了"人工智能"这一术语,标志着该领域作为一门独立学科的诞生。
这里尝试插入几个行内公式 $T$、$\alpha$。下面是一个行间公式,其中的 $\mathrm{e}$ 是正体的 e。
$$
o_t=\left\{R_{k},\dot{R}_{k},\dot{\lambda}_{k}\right\},\; k\in\{MT,MD\}
$$
下面是 `align` 环境的行间公式。
$$
\begin{aligned}
f_1(x)&=\mathrm{e}^{-\beta_1|x|}+\mathrm{e}^{-\beta_2|x|} \\
f_2(y)&=\alpha[(y\leq R_1)+(y\leq R_2)+(y\leq R_3)] \\
r_t &= f_1(R_{MT})+f_2(R_{MT})-f_1(R_{MD})-f_2(R_{MD})
\end{aligned}
$$转换word
下面是一个将AI输出的Markdown文本转成Word的网站,需要注册付费,但不贵。
Markdown转Word
将预处理后的文本粘贴过去
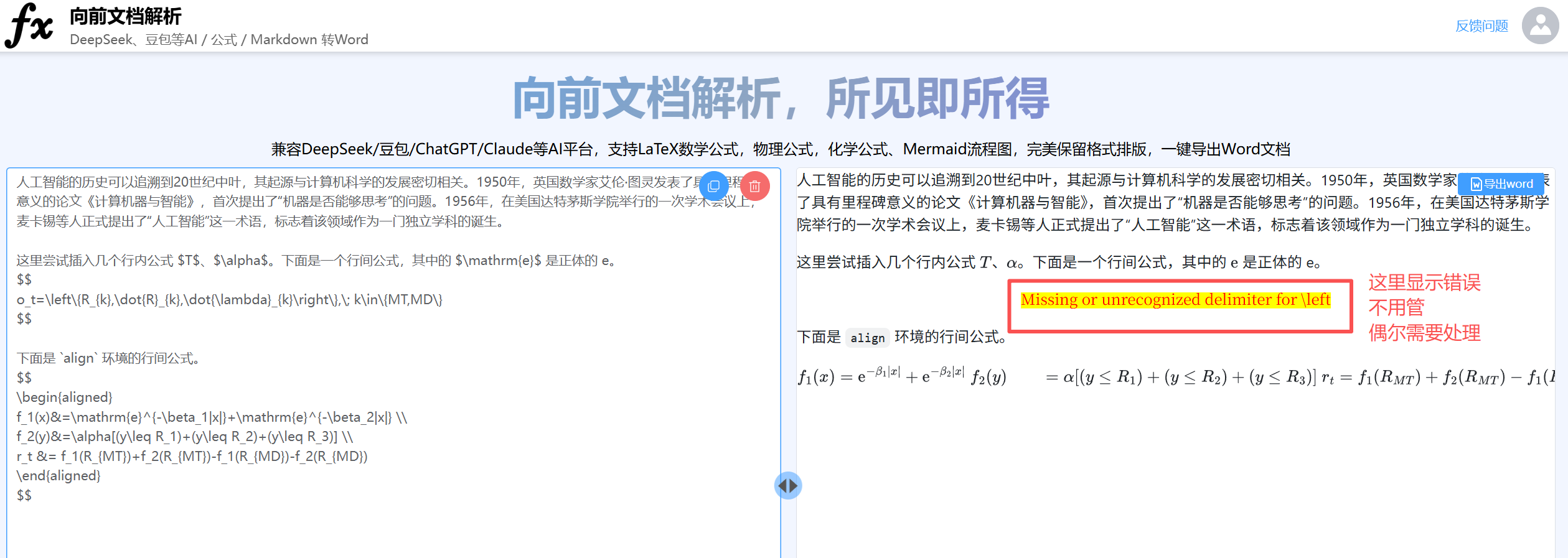
导出的word公式使用的是内置公式,有些可能没有完全识别,但已经极大减轻工作量。

公式
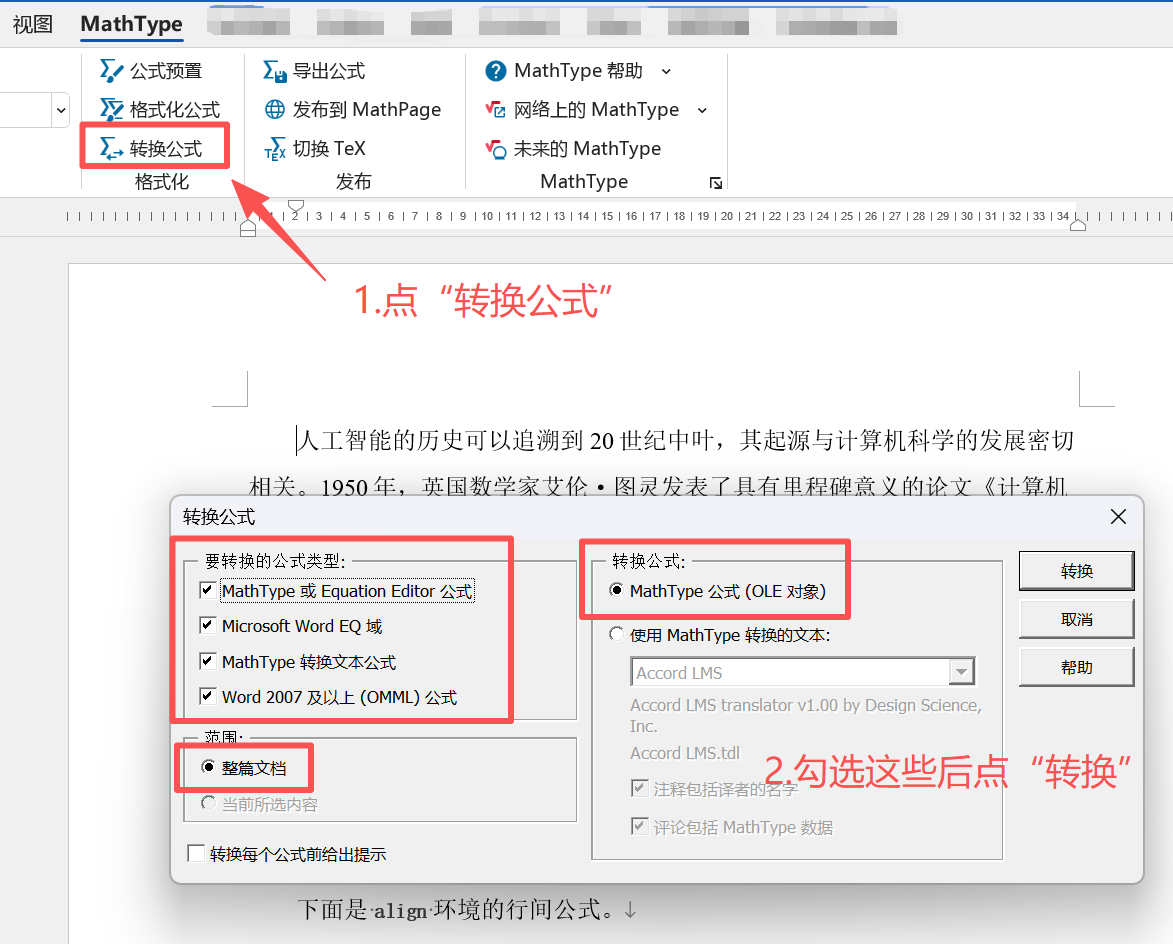
接下来需要把公式转为mathtype。
转换后效果如下
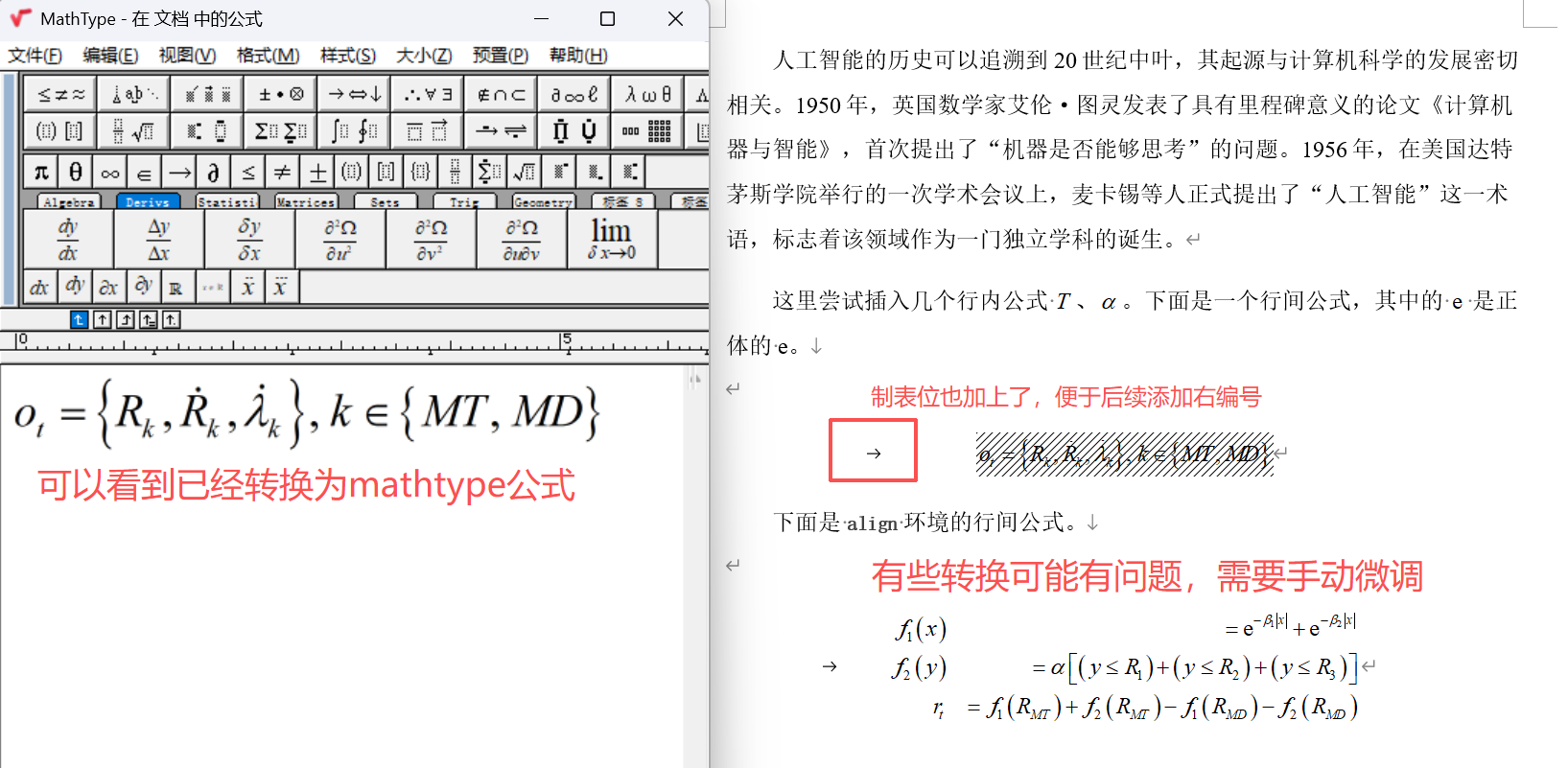
接下来给行间公式添加右编号。
将光标放在公式后,按Tab键,用mathtype插入编号。
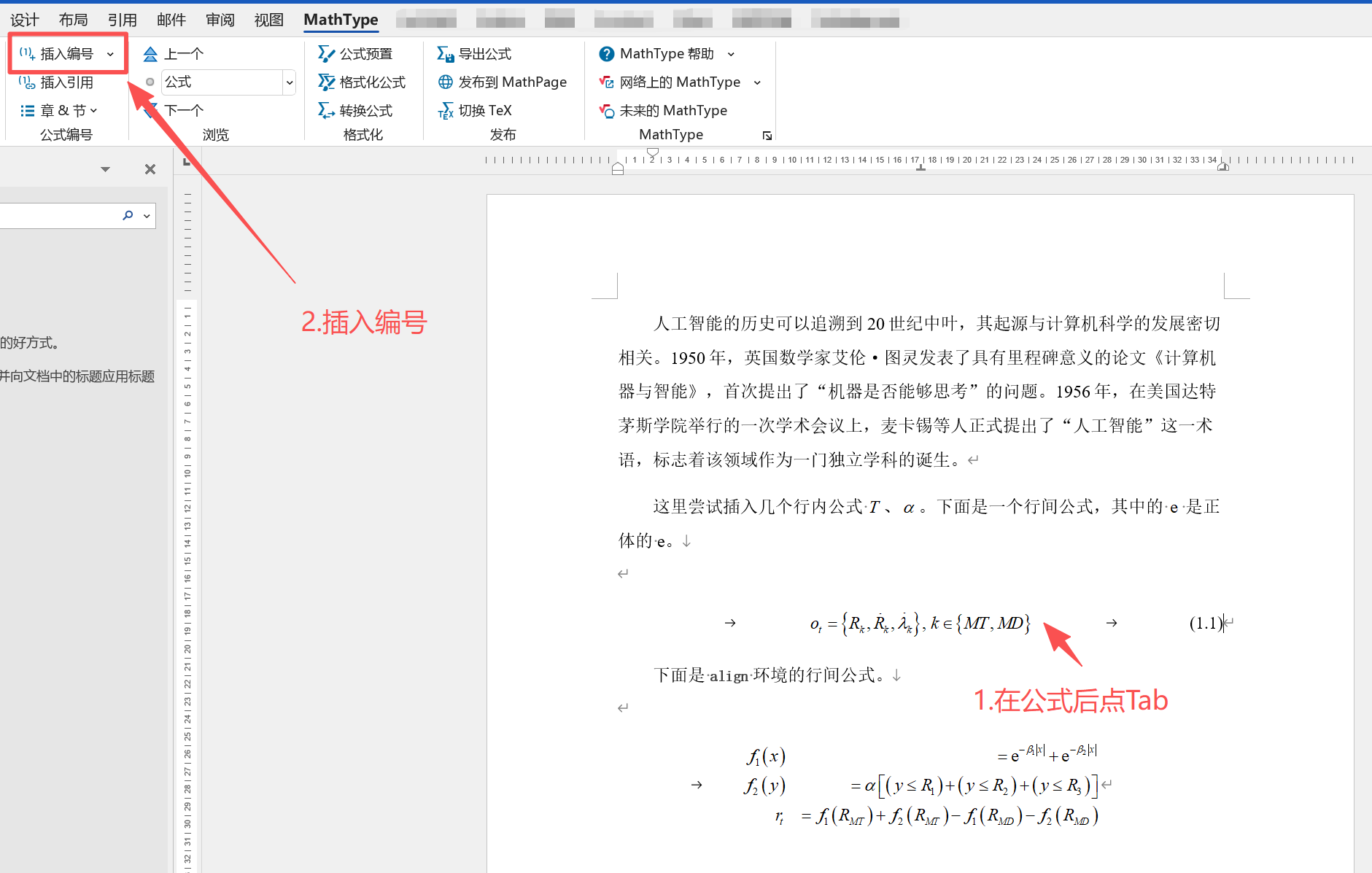
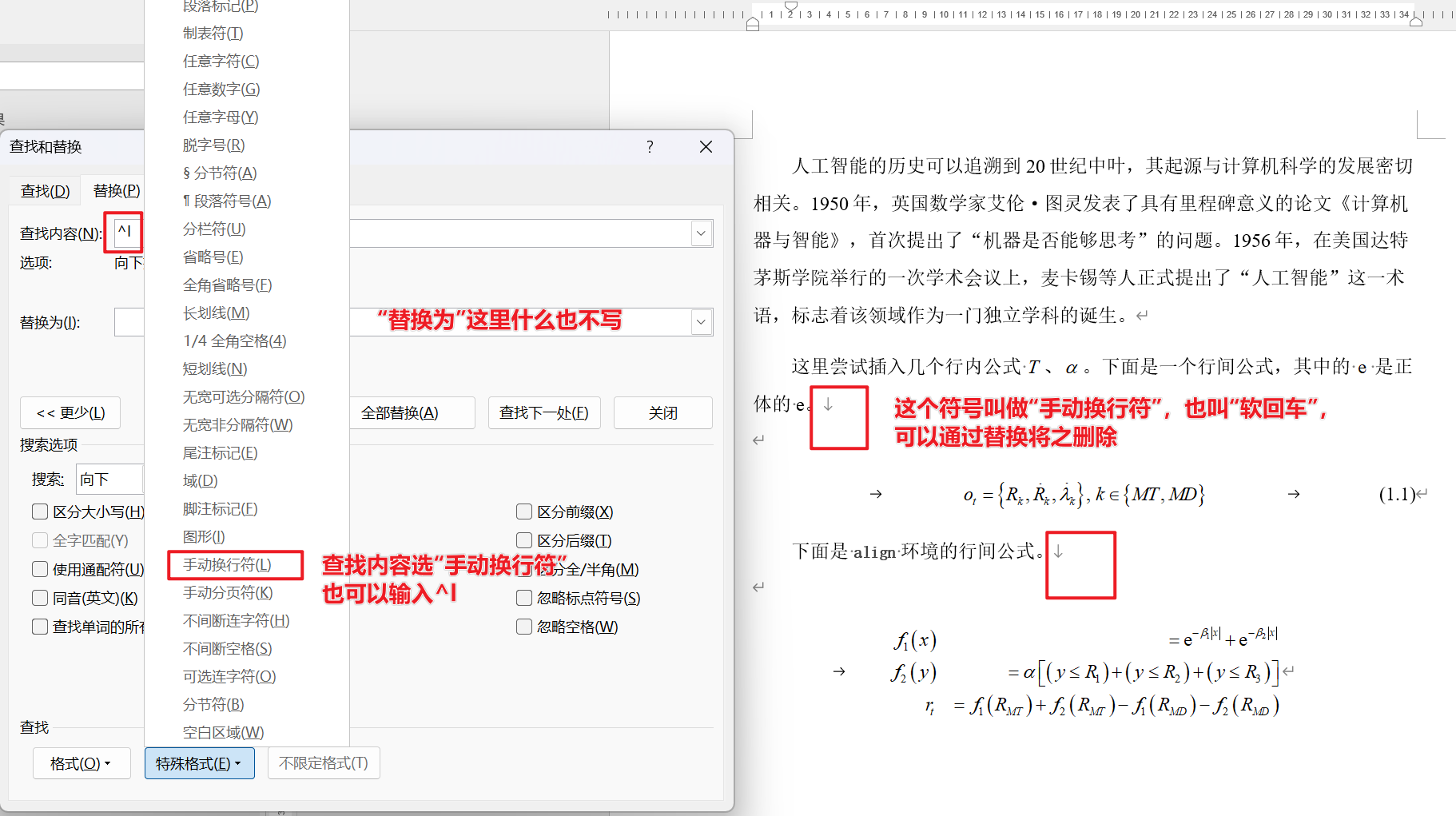
如果想删除手动换行符可以直接查找替换。
图片
有时候LaTeX中插入的图片是pdf格式,现在需要插入到word中。
可以使用下面的python程序,将所有子文件夹中的pdf和图片插到word中。然后再插到相应的位置。
python
import os
from pdf2image import convert_from_path # 将PDF转换为图像的库
from docx import Document # 用于创建和操作Word文档
from docx.shared import Cm # 用于设置厘米单位的尺寸
from docx.enum.text import WD_PARAGRAPH_ALIGNMENT # 段落对齐方式枚举
from docx.oxml import OxmlElement # 低级XML操作(用于插入域代码)
from docx.oxml.ns import qn # XML命名空间处理
import tempfile # 用于创建临时目录
import re # 正则表达式处理
# =====================
# 配置参数
# =====================
DPI_SETTING = 300 # PDF转图片的分辨率设置(300 DPI保证清晰度)
IMAGE_EXTENSIONS = ['.png', '.jpg', '.jpeg', '.gif', '.bmp', '.tiff'] # 支持的图片格式
base_folder = "pic" # 默认图片基础目录(脚本将扫描此目录)
# =====================
# 工具函数
# =====================
def get_unique_filename(base_path):
"""
生成不冲突的唯一文件名(自动添加序号后缀)
:param base_path: 基础文件路径
:return: 可用的唯一文件路径
"""
dir_name = os.path.dirname(base_path) # 获取目录部分
base_name = os.path.basename(base_path) # 获取文件名部分
name, ext = os.path.splitext(base_name) # 分离文件名和扩展名
# 如果文件不存在,直接返回原路径
if not os.path.exists(base_path):
return base_path
# 文件已存在时,循环尝试添加序号后缀
counter = 1
while True:
new_name = f"{name}_{counter}{ext}" # 生成带序号的文件名
new_path = os.path.join(dir_name, new_name)
if not os.path.exists(new_path): # 检查新路径是否可用
return new_path
counter += 1
def sanitize_filename(name):
"""
清理文件名中的非法字符(Windows文件系统限制)
:param name: 原始文件名
:return: 清理后的安全文件名
"""
# 移除Windows文件名中禁止的字符:\ / * ? " < > |
return re.sub(r'[\\/*?:"<>|]', "", name)
def add_caption(paragraph, label="图"):
"""
在段落中插入自动编号的题注域(SEQ域)
:param paragraph: 要插入题注的段落对象
:param label: 题注前缀标签(默认"图")
注意:此函数通过操作底层XML实现Word自动编号功能
"""
run = paragraph.add_run() # 创建空文本段落
# 插入域开始标记(w:fldCharType="begin")
fldChar = OxmlElement('w:fldChar')
fldChar.set(qn('w:fldCharType'), 'begin')
run._r.append(fldChar)
# 插入域指令文本(SEQ 图 \* ARABIC 表示按阿拉伯数字编号)
instrText = OxmlElement('w:instrText')
instrText.set(qn('xml:space'), 'preserve')
instrText.text = f" SEQ {label} \\* ARABIC "
run._r.append(instrText)
# 插入域分隔标记(w:fldCharType="separate")
fldChar = OxmlElement('w:fldChar')
fldChar.set(qn('w:fldCharType'), 'separate')
run._r.append(fldChar)
# 插入显示文本(初始显示为"1")
text = OxmlElement('w:t')
text.text = "1"
run._r.append(text)
# 插入域结束标记(w:fldCharType="end")
fldChar = OxmlElement('w:fldChar')
fldChar.set(qn('w:fldCharType'), 'end')
run._r.append(fldChar)
def insert_centered_picture(doc, img_path, width):
"""
在文档中插入居中对齐的图片
:param doc: Document对象
:param img_path: 图片文件路径
:param width: 图片显示宽度
"""
p = doc.add_paragraph() # 创建新段落
p.alignment = WD_PARAGRAPH_ALIGNMENT.CENTER # 段落居中对齐
run = p.add_run() # 创建运行对象
run.add_picture(img_path, width=width) # 插入图片并设置宽度
# =====================
# 主逻辑
# =====================
# 从基础目录名生成输出文件名(如"pic汇总.docx")
folder_name = os.path.basename(os.path.normpath(base_folder))
output_docx = f"{folder_name}汇总.docx"
# 尝试使用模板文档(如果存在)
template_path = "template.docx"
try:
doc = Document(template_path) # 从模板创建文档
print(f"使用模板: {template_path}")
except:
doc = Document() # 模板不存在时创建空白文档
print("未找到模板,创建新文档")
# 获取当前文档的第一个节(section)用于设置页面布局
section = doc.sections[0]
# 设置标准页边距(单位可用 Inches 或 Cm)
section.left_margin = Cm(3.17) # 左边距,默认值3.175
section.right_margin = Cm(3.17) # 右边距,默认值3.175
section.top_margin = Cm(2.54) # 上边距,默认值2.54
section.bottom_margin = Cm(2.54) # 下边距,默认值2.54
# 添加居中的主标题(使用一级标题样式)
title = doc.add_heading(folder_name, level=1)
title.alignment = WD_PARAGRAPH_ALIGNMENT.CENTER
# 创建临时目录用于存储转换的PDF图片(自动清理)
with tempfile.TemporaryDirectory() as tmpdir:
print(f"临时目录:{tmpdir}")
print(f"PDF转换分辨率设置为: {DPI_SETTING} DPI")
added_dirs = set() # 记录已添加的目录(避免重复标题)
# 递归遍历基础目录
for dirpath, dirnames, filenames in os.walk(base_folder):
# 计算相对于基础目录的路径(标准化为正斜杠)
rel_path = os.path.relpath(dirpath, base_folder).replace(os.sep, '/')
# 筛选PDF文件(不区分大小写)
pdf_files = [f for f in filenames if f.lower().endswith('.pdf')]
# 筛选支持的图片文件
image_files = [f for f in filenames if any(f.lower().endswith(ext) for ext in IMAGE_EXTENSIONS)]
# 跳过空目录
if not pdf_files and not image_files:
continue
# 添加目录标题(仅当首次遇到该目录时)
if rel_path not in added_dirs:
if rel_path == '.':
doc.add_heading("根目录", level=2) # 根目录特殊处理
else:
doc.add_heading(rel_path, level=2) # 子目录标题
added_dirs.add(rel_path)
print(f"添加目录: {rel_path}")
# 处理PDF文件
for filename in sorted(pdf_files):
pdf_path = os.path.join(dirpath, filename)
print(f"正在处理PDF:{pdf_path}")
# 清理文件名作为标题(移除非法字符)
title_name = sanitize_filename(os.path.splitext(filename)[0])
doc.add_heading(title_name, level=3) # 三级标题
# 生成安全的相对路径标识符(替换斜杠为下划线)
safe_rel_path = sanitize_filename(rel_path.replace('/', '_'))
img_prefix = f"{safe_rel_path}_{title_name}" # 图片前缀名
try:
# 将PDF转换为图像列表(每页一张图)
images = convert_from_path(pdf_path, dpi=DPI_SETTING)
except Exception as e:
print(f"转换失败 {pdf_path}: {e}")
# 添加错误提示段落(使用强调引用样式)
doc.add_paragraph(f"[PDF转换失败:{filename}]", style='Intense Quote')
continue
# 处理PDF的每一页
for i, image in enumerate(images):
# 生成临时图片文件名(格式:目录_文件名_page_序号.png)
img_filename = f"{img_prefix}_page_{i+1}.png"
img_path = os.path.join(tmpdir, img_filename)
image.save(img_path, "PNG") # 保存为PNG格式
# 计算可用页面宽度(考虑页边距)
available_width = (section.page_width -
section.left_margin -
section.right_margin)
# 插入居中图片(宽度设为可用宽度的95%)
insert_centered_picture(doc, img_path, width=available_width * 0.95)
# 添加题注(Caption样式)
p = doc.add_paragraph(style='Caption')
p.alignment = WD_PARAGRAPH_ALIGNMENT.CENTER
p.add_run("图 ") # 手动添加"图 "前缀
add_caption(p, label="图") # 插入自动编号域
p.add_run(f" {title_name}_page_{i+1}") # 添加描述文本
# 处理图片文件
for filename in sorted(image_files):
img_path = os.path.join(dirpath, filename)
print(f"正在处理图片:{img_path}")
# 清理文件名作为标题
title_name = sanitize_filename(os.path.splitext(filename)[0])
doc.add_heading(title_name, level=3) # 三级标题
# 计算可用页面宽度
available_width = (section.page_width -
section.left_margin -
section.right_margin)
try:
# 插入居中图片
insert_centered_picture(doc, img_path, width=available_width * 0.95)
except Exception as e:
print(f"插入图片失败 {img_path}: {e}")
# 添加错误提示段落
doc.add_paragraph(f"[图片插入失败:{filename}]", style='Intense Quote')
continue
# 添加题注(与PDF处理逻辑一致)
p = doc.add_paragraph(style='Caption')
p.alignment = WD_PARAGRAPH_ALIGNMENT.CENTER
p.add_run("图 ")
add_caption(p, label="图")
p.add_run(f" {title_name}")
# 保存文档(自动处理文件名冲突)
unique_output = get_unique_filename(output_docx)
doc.save(unique_output)
print(f"\nWord 文档已生成:{unique_output}")
print(f"输出路径: {os.path.abspath(unique_output)}")
# =====================
# 更新Word域(需要 Windows + Word)
# =====================
try:
# 尝试通过COM接口更新域(仅Windows有效)
import win32com.client as win32
word = win32.Dispatch("Word.Application") # 启动Word
word.Visible = False # 后台运行
docx_path = os.path.abspath(unique_output)
docx = word.Documents.Open(docx_path) # 打开文档
docx.Fields.Update() # 更新所有域(自动编号、目录等)
docx.Save() # 保存更新
docx.Close() # 关闭文档
word.Quit() # 退出Word
print("已自动更新所有域(编号、目录等)")
except Exception as e:
# 非Windows环境或权限问题时的提示
print("无法自动更新域,请在Word中手动全选(Ctrl+A)后按F9 刷新。")
print(f"错误信息: {e}")
# 提示文件名冲突情况
if unique_output != output_docx:
counter = unique_output.split('_')[-1].split('.')[0] # 提取序号
print(f"注意: 由于文件名冲突,已自动添加编号后缀(_{counter})")表格
暂时没有太好的方法,都不如直接插更快。
markdown也行,但不一定比手动插更快。
格式调整建议
善用 F4