注:本系列源码分析基于XxlJob 2.3.0,gitee仓库链接:gitee.com/funcy/xxl-j....
本文将分析xxl-job执行器(executor)的启动流程。
执行器接入流程
在分析xxl-job执行器启动流程之前,我们先来看下如何让自己的项目变成xxl-job执行器,这里以springboot框架集成为例,示例项目为xxl-job-executor-sample-springboot。
1. 引入xxl-job-core包
要使用xxl-job的功能,第一步当然是引入其依赖包了,xxl-job-core的GAV坐标如下:
xml
<!-- xxl-job-core -->
<dependency>
<groupId>com.xuxueli</groupId>
<artifactId>xxl-job-core</artifactId>
<version>${latest.version}</version>
</dependency>2. 新增配置类
这块是为了在项目中引入xxl-job的配置,配置类为 com.xxl.job.executor.core.config.XxlJobConfig:
java
@Configuration
public class XxlJobConfig {
private Logger logger = LoggerFactory.getLogger(XxlJobConfig.class);
@Value("${xxl.job.admin.addresses}")
private String adminAddresses;
@Value("${xxl.job.accessToken}")
private String accessToken;
@Value("${xxl.job.executor.appname}")
private String appname;
@Value("${xxl.job.executor.address}")
private String address;
@Value("${xxl.job.executor.ip}")
private String ip;
@Value("${xxl.job.executor.port}")
private int port;
@Value("${xxl.job.executor.logpath}")
private String logPath;
@Value("${xxl.job.executor.logretentiondays}")
private int logRetentionDays;
@Bean
public XxlJobSpringExecutor xxlJobExecutor() {
logger.info(">>>>>>>>>>> xxl-job config init.");
XxlJobSpringExecutor xxlJobSpringExecutor = new XxlJobSpringExecutor();
xxlJobSpringExecutor.setAdminAddresses(adminAddresses);
xxlJobSpringExecutor.setAppname(appname);
xxlJobSpringExecutor.setAddress(address);
xxlJobSpringExecutor.setIp(ip);
xxlJobSpringExecutor.setPort(port);
xxlJobSpringExecutor.setAccessToken(accessToken);
xxlJobSpringExecutor.setLogPath(logPath);
xxlJobSpringExecutor.setLogRetentionDays(logRetentionDays);
return xxlJobSpringExecutor;
}
}这是一个配置类,该类先是定义了一系列的属性,用于获取application.properties的配置,接着以@Bean注解的方式向spring容器中引入了xxlJobExecutor,该bean才是xxl-job执行器的关键,在本文的后面会详细分析。
3. application.properties中添加xxl-job相关配置
这块就是处理执行器的相关配置了,这些配置如下:
properties
# xxl-job admin address 地址列表,多个使用,分开
xxl.job.admin.addresses=http://127.0.0.1:8080/xxl-job-admin
# 与admin通读的token,不配置表示不启用
xxl.job.accessToken=
# 执行器名称,同一个执行器的不同实例,应该使用同一个名称
xxl.job.executor.appname=xxl-job-executor-sample
# 执行器地址,可以指定,不指定时则使用ip:port的形式
xxl.job.executor.address=
# 服务器ip与端口信息
## 如果不指定ip,则自行获取服务器ip地址
xxl.job.executor.ip=
## 如果不指定端口,则先获取 9999 ~ 65535之间可用的端口,如果无
## 可用端口,再获取9999~0中可用的端口
xxl.job.executor.port=9998
# 执行日志保存路径
xxl.job.executor.logpath=./data/applogs/xxl-job/jobhandler
# 执行日志保存时长
xxl.job.executor.logretentiondays=304. 编写任务
任务的示例类为com.xxl.job.executor.service.jobhandler.SampleXxlJob,代码如下:
java
@Component
public class SampleXxlJob {
/**
* 注意 @XxlJob 注解
*/
@XxlJob("demoJobHandler")
public void demoJobHandler() throws Exception {
XxlJobHelper.log("XXL-JOB, Hello World.");
for (int i = 0; i < 5; i++) {
XxlJobHelper.log("beat at:" + i);
TimeUnit.SECONDS.sleep(2);
}
// default success
}
}实际上,对于一个bean类型的任务来说,只需满足两个条件即可:
- 该类是一个 spring bean 中:
SampleXxlJob由@Component注解标记 - 任务的执行方法由
@XxlJob注解标记:demoJobHandler()由@XxlJob注解标记,并且指定了任务名称为demoJobHandler
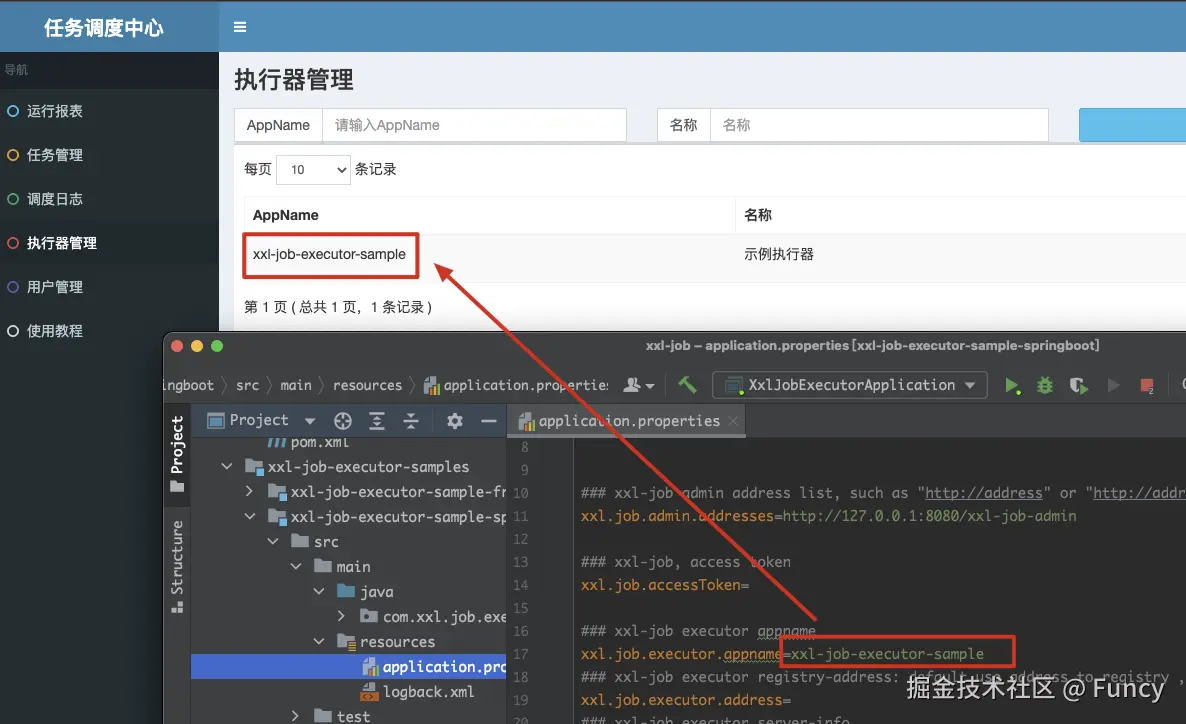
5. 界面配置任务
然后是配置执行器,界面如下(注意名称与项目中配置的xxl.job.executor.appname一致):
接着配置任务:
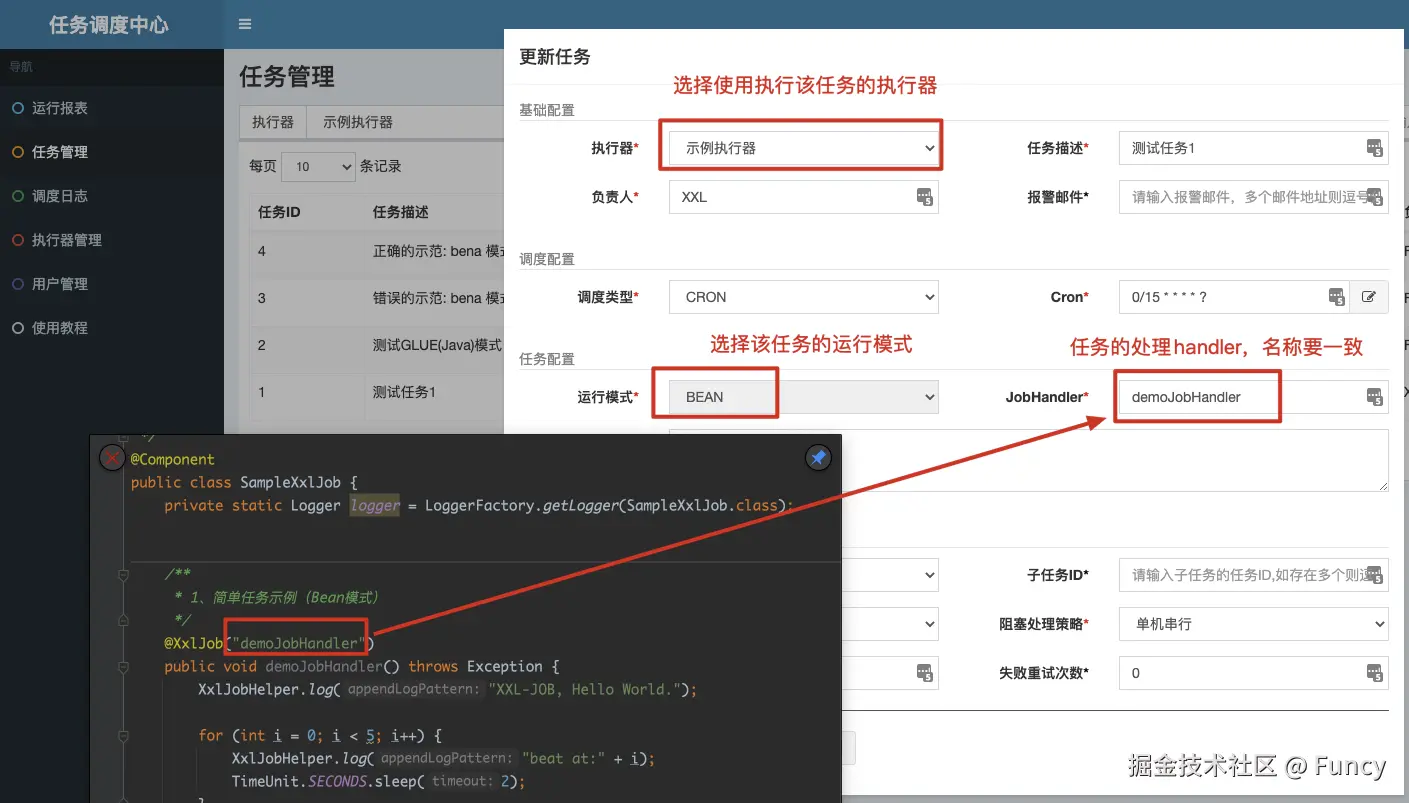
配置之后,就可以执行任务了。
配置类:XxlJobConfig
前面的介绍中,我们向代码中编写了一个配置类:com.xxl.job.executor.core.config.XxlJobConfig,而这个类也是启动xxl-job执行器组件的关键所在,它的xxlJobExecutor()方法如下:
java
@Bean
public XxlJobSpringExecutor xxlJobExecutor() {
logger.info(">>>>>>>>>>> xxl-job config init.");
XxlJobSpringExecutor xxlJobSpringExecutor = new XxlJobSpringExecutor();
xxlJobSpringExecutor.setAdminAddresses(adminAddresses);
xxlJobSpringExecutor.setAppname(appname);
xxlJobSpringExecutor.setAddress(address);
xxlJobSpringExecutor.setIp(ip);
xxlJobSpringExecutor.setPort(port);
xxlJobSpringExecutor.setAccessToken(accessToken);
xxlJobSpringExecutor.setLogPath(logPath);
xxlJobSpringExecutor.setLogRetentionDays(logRetentionDays);
return xxlJobSpringExecutor;
}该方法就是XxlJobConfig的核心所在,可以说,XxlJobConfig就是为了向spring容器中引入 类型为XxlJobSpringExecutor的bean,接下来我们就来探索XxlJobSpringExecutor的奥秘。
com.xxl.job.core.executor.impl.XxlJobSpringExecutor关键内容如下:
java
public class XxlJobSpringExecutor extends XxlJobExecutor implements
ApplicationContextAware, SmartInitializingSingleton, DisposableBean {
@Override
public void afterSingletonsInstantiated() {
// 带 @XxlJob 注解的方法就是在这里扫描的
initJobHandlerMethodRepository(applicationContext);
// refresh GlueFactory
GlueFactory.refreshInstance(1);
// super start
try {
super.start();
} catch (Exception e) {
throw new RuntimeException(e);
}
}
// destroy
@Override
public void destroy() {
super.destroy();
}
...
}该类实现了3个类,我们重点分析其中两个:
SmartInitializingSingleton:由spring提供,其afterSingletonsInstantiated()的方法会在容器中所有的单例bean初始化完成后调用;DisposableBean:由spring提供,其destroy()方法会在当前的spring bean销毁时调用
接下来我们就只需重点关注afterSingletonsInstantiated()与destroy()方法了.
上面已经展示了XxlJobSpringExecutor的afterSingletonsInstantiated()方法,该方法一共有3行关键代码,总结如下:
initJobHandlerMethodRepository(xxx):初始化jobHandlerMethod,实际上就是处理@XxlJob注解的方法GlueFactory.refreshInstance(1):初始化GlueFactory类,该类在glue模式下会用到,由于本系列重点分析bean模式,这块就不关注了super.start():调用的是XxlJobExecutor#start,这里是执行器真正启动的地方,后面我们会花大量篇幅来介绍该方法
1. initJobHandlerMethodRepository()
XxlJobSpringExecutor#initJobHandlerMethodRepository主要用来处理被@XxlJob标记的方法,代码如下:
java
private void initJobHandlerMethodRepository(ApplicationContext applicationContext) {
if (applicationContext == null) {
return;
}
// 1. 获取spring所有bean的名称
String[] beanDefinitionNames = applicationContext.getBeanNamesForType(
Object.class, false, true);
for (String beanDefinitionName : beanDefinitionNames) {
Object bean = applicationContext.getBean(beanDefinitionName);
// 2. 获取到所有标记了 @XxlJob 的方法
Map<Method, XxlJob> annotatedMethods = null;
try {
annotatedMethods = MethodIntrospector.selectMethods(bean.getClass(),
new MethodIntrospector.MetadataLookup<XxlJob>() {
@Override
public XxlJob inspect(Method method) {
return AnnotatedElementUtils.findMergedAnnotation(
method, XxlJob.class);
}
});
} catch (Throwable ex) {
logger.error("xxl-job method-jobhandler resolve error for bean["
+ beanDefinitionName + "].", ex);
}
if (annotatedMethods==null || annotatedMethods.isEmpty()) {
continue;
}
// 3. 遍历得到的方法,注册
for (Map.Entry<Method, XxlJob> methodXxlJobEntry : annotatedMethods.entrySet()) {
Method executeMethod = methodXxlJobEntry.getKey();
XxlJob xxlJob = methodXxlJobEntry.getValue();
if (xxlJob == null) {
continue;
}
String name = xxlJob.value();
if (name.trim().length() == 0) {
throw new RuntimeException("xxl-job method-jobhandler name invalid, for["
+ bean.getClass() + "#" + executeMethod.getName() + "] .");
}
// 3.1 判断任务是否重复
if (loadJobHandler(name) != null) {
throw new RuntimeException("xxl-job jobhandler[" + name
+ "] naming conflicts.");
}
executeMethod.setAccessible(true);
// init and destory
Method initMethod = null;
Method destroyMethod = null;
// 3.2 初始化方法
if (xxlJob.init().trim().length() > 0) {
try {
initMethod = bean.getClass().getDeclaredMethod(xxlJob.init());
initMethod.setAccessible(true);
} catch (NoSuchMethodException e) {
throw new RuntimeException("xxl-job method-jobhandler initMethod "
+ "invalid, for["
+ bean.getClass() + "#" + executeMethod.getName() + "] .");
}
}
// 3.3 销毁方法
if (xxlJob.destroy().trim().length() > 0) {
try {
destroyMethod = bean.getClass().getDeclaredMethod(xxlJob.destroy());
destroyMethod.setAccessible(true);
} catch (NoSuchMethodException e) {
throw new RuntimeException("xxl-job method-jobhandler destroyMethod "
+ "invalid, for["
+ bean.getClass() + "#" + executeMethod.getName() + "] .");
}
}
// 3.4 注册任务处理handler
// registry jobhandler
registJobHandler(name, new MethodJobHandler(bean, executeMethod,
initMethod, destroyMethod));
}
}
}该方法看着有点长,但逻辑还是非常清晰的,注释已经在代码中标明了,这里再来总结下该方法执行的流程:
- 获取spring所有bean的名称,使用的是spring提供的方法
applicationContext.getBeanNamesForType,这表明被@XxlJob标记的方法一定要在spring bean中才会被识别到; - 从第1步得到的
bean中获取到所有标记了@XxlJob的方法,使用的是spring提供的方法MethodIntrospector.selectMethods - 遍历得到的方法,注册
- 判断任务是否重复,即判断之前是否有注册过
- 解析初始化方法,
@XxlJob注解可以指定初始化方法,这一步是把初始化方法名(字符串)转化为Method实例 - 解析初始化方法,
@XxlJob注解可以指定销毁方法,这一步是把销毁方法名(字符串)转化为Method实例 - 注册任务处理handler,一个完整的handler包含
bean、任务处理方法、初始化方法、销毁方法
任务注册方法是XxlJobExecutor#registJobHandler,相关代码如下:
java
// XxlJobExecutor.java
/** 保存任务handler */
private static ConcurrentMap<String, IJobHandler> jobHandlerRepository
= new ConcurrentHashMap<String, IJobHandler>();
/** 获取任务handler */
public static IJobHandler loadJobHandler(String name){
return jobHandlerRepository.get(name);
}
/** 注册任务handler */
public static IJobHandler registJobHandler(String name, IJobHandler jobHandler){
logger.info(">>>>>>>>>>> xxl-job register jobhandler success, "
+ "name:{}, jobHandler:{}", name, jobHandler);
return jobHandlerRepository.put(name, jobHandler);
}XxlJobExecutor中有一个名为jobHandlerRepository的属性用来保存任务handler,该属性类型为ConcurrentMap,key是@XxlJob的value,value是MethodJobHandler,该类包含的属性如下:
Object target:实例,就是前面所说的spring beanMethod method:任务处理方法Method initMethod:任务的初始化方法Method destroyMethod:任务的销毁方法
以示例项目中的SampleXxlJob#demoJobHandler2为例,该方法对应的各属性如下:
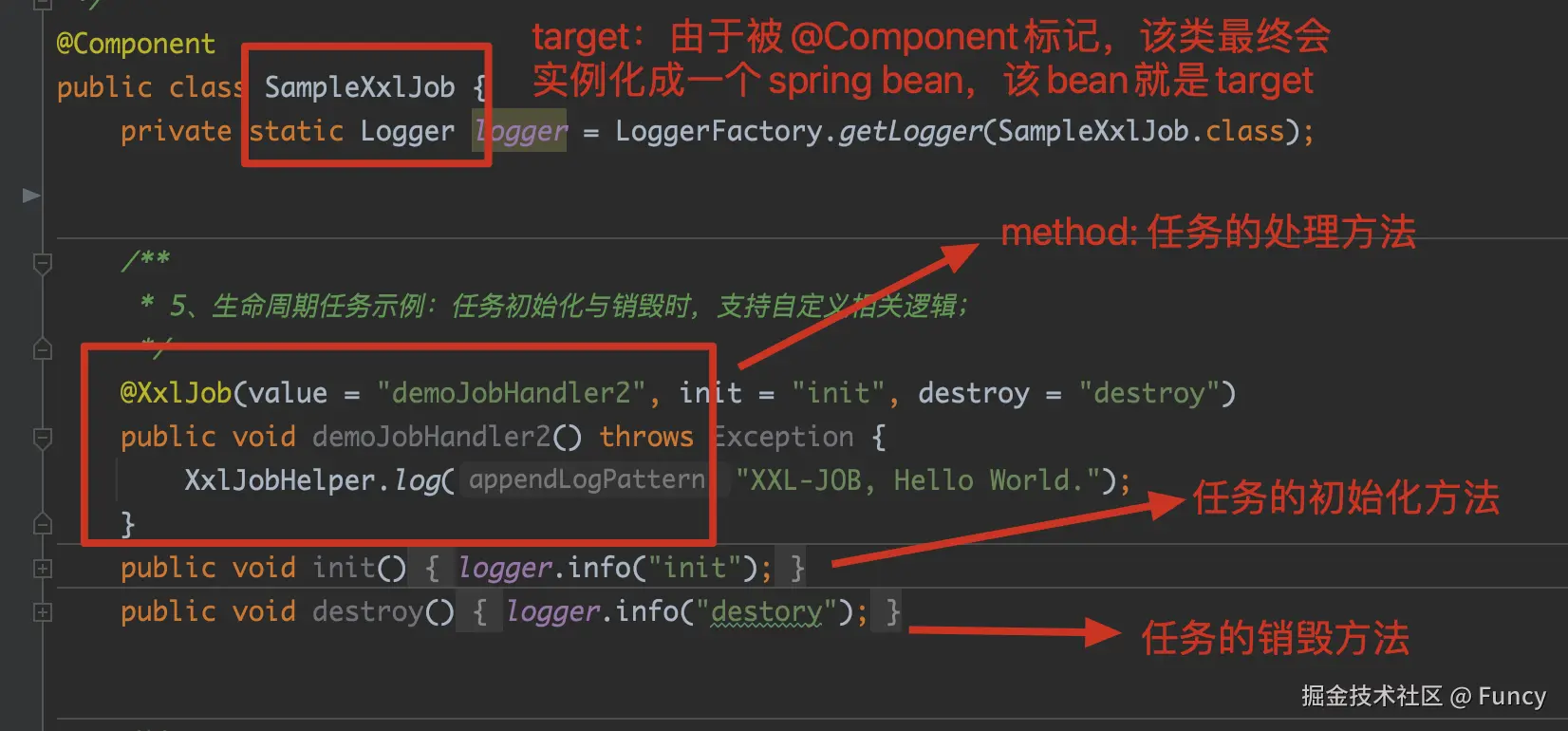
最终,任务handler会注册到XxlJobExecutor的jobHandlerRepository中了。从代码中可以看到,这块操作主要是使用spring提供的方法。
2. GlueFactory#refreshInstance
GlueFactory.refreshInstance代码如下:
java
public static void refreshInstance(int type){
if (type == 0) {
glueFactory = new GlueFactory();
} else if (type == 1) {
glueFactory = new SpringGlueFactory();
}
}这段代码主要是创建glueFactory对象,由于代码中传入的参数是1,因此创建的是SpringGlueFactory的实例。
该类在glue模式下会用到,由于本系列重点分析bean模式,这块就不关注了。
3. XxlJobExecutor#start
继续,接着调用了一个非常重要的方法:XxlJobExecutor#start,这个方法就是xxl-job执行器的启动关键所在了,代码如下:
java
public void start() throws Exception {
// init logpath
// 1. 初始化日志路径,logBasePath 与 glueSrcPath
XxlJobFileAppender.initLogPath(logPath);
// init invoker, admin-client
// 2. 初始化admin客户端,最后得到的是一个client list, 每个admin的
// 地址都会生成一个client
initAdminBizList(adminAddresses, accessToken);
// init JobLogFileCleanThread
// 3. 清除job日志执行文件
JobLogFileCleanThread.getInstance().start(logRetentionDays);
// init TriggerCallbackThread
// 4. 处理回调admin的线程
TriggerCallbackThread.getInstance().start();
// init executor-server
// 5. 初始化内部的http服务器,用于接收admin的请求
initEmbedServer(address, ip, port, appname, accessToken);
}该方法只有5行,不过每行都是关键,这5行代码分别的处理的功能如下:
- 初始化日志路径
- 初始化admin客户端
- 清除job日志执行文件
- 处理回调admin的线程
- 初始化内部的http服务器
关于这些功能,我们下一小节再详细展开。
启动方法:XxlJobExecutor#start
上一小节我们介绍了XxlJobExecutor#start方法,介绍了该方法所进行的功能如下:
- 初始化日志路径
- 初始化admin客户端
- 清除job日志执行文件
- 处理回调admin的线程
- 初始化内部的http服务器
本节我们将逐一分析这些功能。
1. 初始化日志路径
初始化日志路径的方法为XxlJobFileAppender#initLogPath,内容如下:
java
private static String logBasePath = "/data/applogs/xxl-job/jobhandler";
private static String glueSrcPath = logBasePath.concat("/gluesource");
/**
* 初始化日志路径
*/
public static void initLogPath(String logPath){
// init
if (logPath!=null && logPath.trim().length()>0) {
logBasePath = logPath;
}
// mk base dir
// 如果路径不存在就创建
File logPathDir = new File(logBasePath);
if (!logPathDir.exists()) {
logPathDir.mkdirs();
}
logBasePath = logPathDir.getPath();
// mk glue dir
// 如果路径不存在就创建
File glueBaseDir = new File(logPathDir, "gluesource");
if (!glueBaseDir.exists()) {
glueBaseDir.mkdirs();
}
glueSrcPath = glueBaseDir.getPath();
}这块内容比较简单,就是初始化了两个路径: logBasePath:任务执行日志路径,默认为/data/applogs/xxl-job/jobhandler,可以在application.properties中配置 glueSrcPath:glue脚本保存路径,默认为${logBasePath}/gluesource
关于任务的执行日志,效果如下:
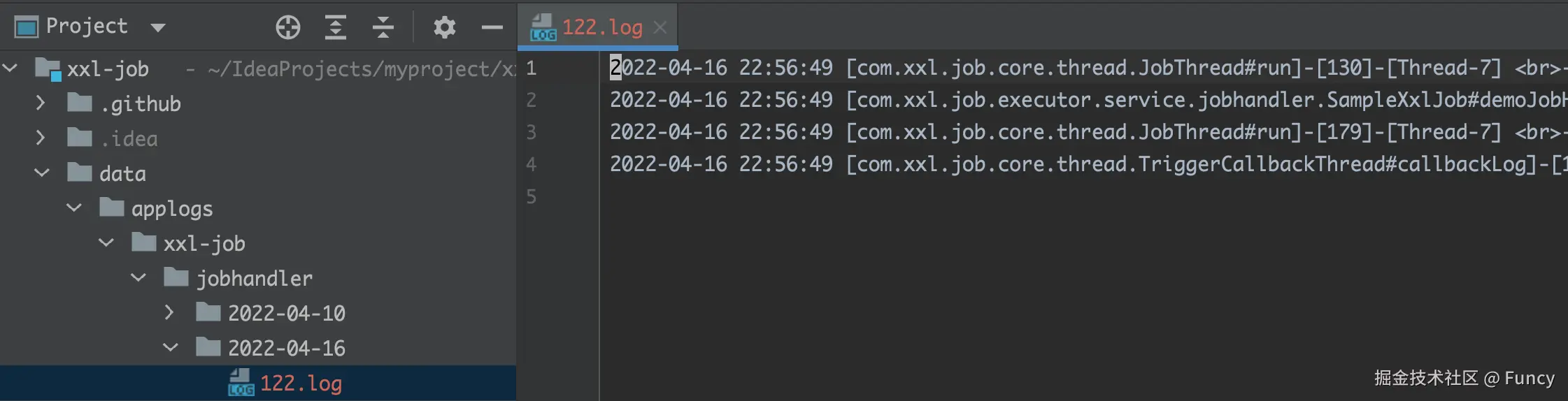
122.log中的122就是xxl_job_log表的Id,在界面查看如下:
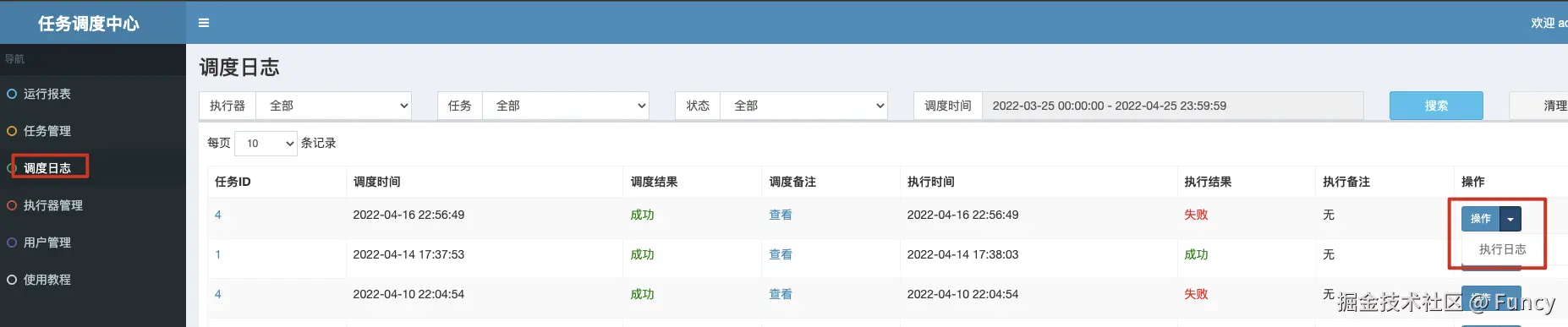
然后发现两者内容一致:
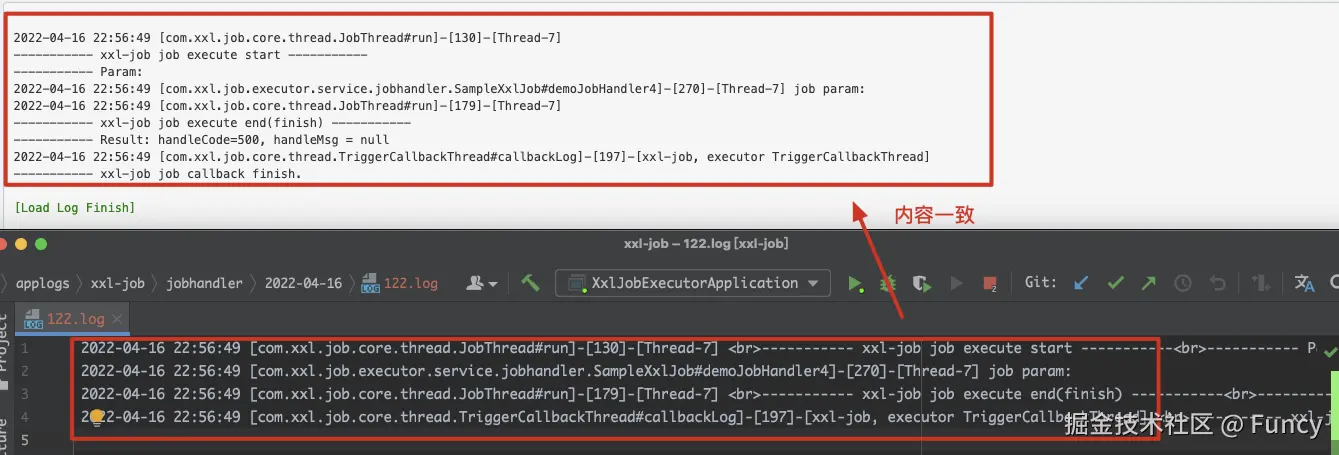
从而可知,执行日志就是从这里来的。对于任务来说,每执行1次任务,都会在xxl_job_log中生成一条记录,并且在相应的执行器上生成一个日志文件,日志文件的名称${jobLogId}.log(${jobLogId}为xxl_job_log表的Id)。
值得一提的是,执行日志保存在了执行器所在服务器,管理后台则是通过http请求到执行器获取执行日志的,关于admin与executor之间的通讯,我们后面再作讨论。
2. 初始化admin客户端
前面提到,在application.properties中配置admin的地址时,可以配置多个并且使用,分开,这里就是将一个个adminAddress变成一个AdminBizClient的操作了,处理方法为XxlJobExecutor#initAdminBizList,代码如下:
java
private static List<AdminBiz> adminBizList;
private void initAdminBizList(String adminAddresses, String accessToken)
throws Exception {
if (adminAddresses!=null && adminAddresses.trim().length()>0) {
for (String address: adminAddresses.trim().split(",")) {
if (address!=null && address.trim().length()>0) {
// 创建 AdminBizClient 对象
AdminBiz adminBiz = new AdminBizClient(address.trim(), accessToken);
if (adminBizList == null) {
adminBizList = new ArrayList<AdminBiz>();
}
adminBizList.add(adminBiz);
}
}
}
}这样之后,就可以得到一个AdminBizClient的List了,List中的每个AdminBizClient实例都对应着一个adminAddress。
AdminBizClient主要是用来处理中executor到admin的http请求,代码如下:
java
public class AdminBizClient implements AdminBiz {
public AdminBizClient() {
}
/**
* 构造方法
*/
public AdminBizClient(String addressUrl, String accessToken) {
this.addressUrl = addressUrl;
this.accessToken = accessToken;
// valid
if (!this.addressUrl.endsWith("/")) {
this.addressUrl = this.addressUrl + "/";
}
}
/** admin项目的url地址 */
private String addressUrl ;
/** 请求admin的token */
private String accessToken;
/** 请求超时时间,默认3s */
private int timeout = 3;
/**
*
*/
@Override
public ReturnT<String> callback(List<HandleCallbackParam> callbackParamList) {
return XxlJobRemotingUtil.postBody(addressUrl+"api/callback",
accessToken, timeout, callbackParamList, String.class);
}
/**
* 执行器注册
* 在执行器启动的时候,需要把该执行器的地址信息注册到admin项目
*/
@Override
public ReturnT<String> registry(RegistryParam registryParam) {
return XxlJobRemotingUtil.postBody(addressUrl + "api/registry",
accessToken, timeout, registryParam, String.class);
}
/**
* 执行器移除
* 在执行器关闭前,需要把该执行器的地址信息从admin项目移除
*/
@Override
public ReturnT<String> registryRemove(RegistryParam registryParam) {
return XxlJobRemotingUtil.postBody(addressUrl + "api/registryRemove",
accessToken, timeout, registryParam, String.class);
}
}AdminBizClient主要包含了3个属性与3个方法,这3个方法就是用来处理admin交互的相关操作的。注意区别上一小节中日志文件内容的获取操作:
- admin获取任务的执行日志,是由admin请求执行器获取的;
- 本小节说的
AdminBizClient,是由执行器请求admin的
3. 清除任务执行日志
在前面提到过,每执行一次任务,都会在执行器上生成一个${jobLogId}.log的文件,久而久之,这些日志文件将会非常多,持续占用磁盘空间。为了解决这个问题,xxl-job提供了清理任务执行日志的线程,方法为JobLogFileCleanThread#start:
java
/**
* 启动方法
*/
public void start(final long logRetentionDays){
// limit min value
// 日志至少要保存3天,如果小于3天,线程就不启动了,也就是不清理日志文件了
if (logRetentionDays < 3 ) {
return;
}
localThread = new Thread(new Runnable() {
// 省略run()方法,下面会介绍
...
});
localThread.setDaemon(true);
localThread.setName("xxl-job, executor JobLogFileCleanThread");
localThread.start();
}
/**
* 停止方法
*/
public void toStop() {
toStop = true;
if (localThread == null) {
return;
}
// interrupt and wait
localThread.interrupt();
try {
localThread.join();
} catch (InterruptedException e) {
logger.error(e.getMessage(), e);
}
}JobLogFileCleanThread类的启动与停止方法,与前面介绍的admin模块的几个线程可谓是一模一样的套路啊,这些就不赘述了,直接来看localThread的run()方法:
java
@Override
public void run() {
while (!toStop) {
try {
// clean log dir, over logRetentionDays
// 获取日志文件夹下的所有文件与文件夹
File[] childDirs = new File(XxlJobFileAppender.getLogPath()).listFiles();
if (childDirs!=null && childDirs.length>0) {
// today
// 今天开始的时间
Calendar todayCal = Calendar.getInstance();
todayCal.set(Calendar.HOUR_OF_DAY,0);
todayCal.set(Calendar.MINUTE,0);
todayCal.set(Calendar.SECOND,0);
todayCal.set(Calendar.MILLISECOND,0);
Date todayDate = todayCal.getTime();
for (File childFile: childDirs) {
// valid
if (!childFile.isDirectory()) {
continue;
}
if (childFile.getName().indexOf("-") == -1) {
continue;
}
// file create date
// 获取文件夹创建日期,文件夹以 yyyy-MM-dd 的形式命名
Date logFileCreateDate = null;
try {
SimpleDateFormat simpleDateFormat = new SimpleDateFormat("yyyy-MM-dd");
logFileCreateDate = simpleDateFormat.parse(childFile.getName());
} catch (ParseException e) {
logger.error(e.getMessage(), e);
}
if (logFileCreateDate == null) {
continue;
}
// 比较日期,超过最大保留时间,就删除该目录及其子目录中的文件
if ((todayDate.getTime()-logFileCreateDate.getTime())
>= logRetentionDays * (24 * 60 * 60 * 1000) ) {
// 递归删除日志文件:删除目录及其子目录中的文件
FileUtil.deleteRecursively(childFile);
}
}
}
} catch (Exception e) {
if (!toStop) {
logger.error(e.getMessage(), e);
}
}
// 休眠,时间为1天
try {
TimeUnit.DAYS.sleep(1);
} catch (InterruptedException e) {
if (!toStop) {
logger.error(e.getMessage(), e);
}
}
}
logger.info(">>>>>>>>>>> xxl-job, executor JobLogFileCleanThread"
+" thread destory.");
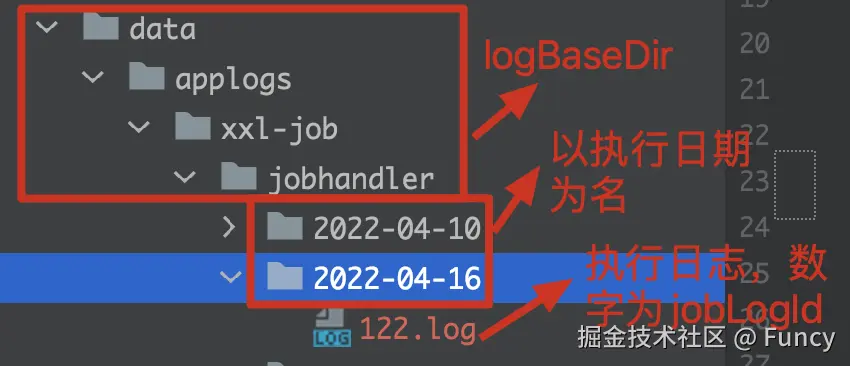
}删除执行日志代码比较简单,相关逻辑注释中已经标明了,就细细分析了。总结下该线程的执行内容:从执行日志目录下找到日志文件夹,解析出任务执行日期,如果执行日期超过了最大保留天数,就删除该目录及其文件。
再来看一眼执行日志的目录结构:
4. 处理回调admin的线程
继续,看看 TriggerCallbackThread#start 方法:
java
/**
* 启动方法
*/
public void start() {
// valid
if (XxlJobExecutor.getAdminBizList() == null) {
logger.warn(">>>>>>>>>>> xxl-job, executor callback config fail, "
+ "adminAddresses is null.");
return;
}
// callback
triggerCallbackThread = new Thread(new Runnable() {
@Override
public void run() {
// 省略线程执行的内容
...
}
});
triggerCallbackThread.setDaemon(true);
triggerCallbackThread.setName("xxl-job, executor TriggerCallbackThread");
triggerCallbackThread.start();
// retry
triggerRetryCallbackThread = new Thread(new Runnable() {
@Override
public void run() {
// 省略线程执行的内容
...
}
});
triggerRetryCallbackThread.setDaemon(true);
triggerRetryCallbackThread.start();
}
/**
* 停止方法
*/
public void toStop(){
toStop = true;
// stop callback, interrupt and wait
if (triggerCallbackThread != null) {
triggerCallbackThread.interrupt();
try {
triggerCallbackThread.join();
} catch (InterruptedException e) {
logger.error(e.getMessage(), e);
}
}
// stop retry, interrupt and wait
if (triggerRetryCallbackThread != null) {
triggerRetryCallbackThread.interrupt();
try {
triggerRetryCallbackThread.join();
} catch (InterruptedException e) {
logger.error(e.getMessage(), e);
}
}
}这个方法创建了两个线程并启动:
triggerCallbackThread:处理回调的线程triggerRetryCallbackThread:处理重试的线程
可以看到,xxl-job线程的启动与关闭套路是一模一样的,这套路前面已经分析过了,这里就不多说了。关于这两个线程的run()方法,后面分析任务的执行时再详细展开。
5. 初始化内部的http服务器
接下来就是重头戏:初始化内部的http服务器,方法是XxlJobExecutor#initEmbedServer,代码如下:
java
private void initEmbedServer(String address, String ip, int port, String appname,
String accessToken) throws Exception {
// 端口,如果未配置,就找一个可用的
port = port>0?port: NetUtil.findAvailablePort(9999);
// ip,如果没指定就自动获取本机ip
ip = (ip!=null&&ip.trim().length()>0)?ip: IpUtil.getIp();
// 如果未配置执行器的http访问地址,就生成,形式:http://{ip}:{端口}
if (address==null || address.trim().length()==0) {
// registry-address:default use address to registry ,
// otherwise use ip:port if address is null
String ip_port_address = IpUtil.getIpPort(ip, port);
address = "http://{ip_port}/".replace("{ip_port}", ip_port_address);
}
// 执行器与admin的访问token
if (accessToken==null || accessToken.trim().length()==0) {
logger.warn(">>>>>>>>>>> xxl-job accessToken is empty. To ensure system "
+ "security, please set the accessToken.");
}
// 启动http服务器
embedServer = new EmbedServer();
embedServer.start(address, port, appname, accessToken);
}实际上,该方法就做了两件事:
- 准备参数,如ip、port、address、accessToken等
- 启动http服务器,第1步准备的参数就是这里用到的
继续看http服务器的服务,进入EmbedServer#start方法:
java
public void start(final String address, final int port, final String appname,
final String accessToken) {
// 业务执行器
executorBiz = new ExecutorBizImpl();
thread = new Thread(new Runnable() {
@Override
public void run() {
// 省略 run() 方法的内容
...
}
});
thread.setDaemon(true);
thread.start();
}这个方法先是创建了一个executorBiz实例,类型是ExecutorBizImpl,这个处理的是执行器相关业务,后面再详细分析;接着就是新建了一个线程,在线程里进行一系列的操作,接下来我们重点关注这个run()方法:
java
@Override
public void run() {
// netty 的两个线程池
EventLoopGroup bossGroup = new NioEventLoopGroup();
EventLoopGroup workerGroup = new NioEventLoopGroup();
// 处理业务的线程池
ThreadPoolExecutor bizThreadPool = new ThreadPoolExecutor(
0,
200,
60L,
TimeUnit.SECONDS,
new LinkedBlockingQueue<Runnable>(2000),
new ThreadFactory() {
@Override
public Thread newThread(Runnable r) {
return new Thread(r, "xxl-rpc, EmbedServer bizThreadPool-"
+ r.hashCode());
}
},
// 注意拒绝策略:直接抛出异常
new RejectedExecutionHandler() {
@Override
public void rejectedExecution(Runnable r, ThreadPoolExecutor executor) {
throw new RuntimeException("xxl-job, EmbedServer bizThreadPool "
+ " is EXHAUSTED!");
}
});
try {
// 组装服务器端
ServerBootstrap bootstrap = new ServerBootstrap();
bootstrap.group(bossGroup, workerGroup)
// 使用的是 nio
.channel(NioServerSocketChannel.class)
.childHandler(new ChannelInitializer<SocketChannel>() {
@Override
public void initChannel(SocketChannel channel) throws Exception {
channel.pipeline()
// 空闲监听,在 EmbedHttpServerHandler#userEventTriggered 处理空闲事件
.addLast(new IdleStateHandler(0, 0, 30 * 3, TimeUnit.SECONDS))
// http 相关处理
.addLast(new HttpServerCodec())
.addLast(new HttpObjectAggregator(5 * 1024 * 1024))
// 业务处理
.addLast(new EmbedHttpServerHandler(executorBiz, accessToken,
bizThreadPool));
}
})
.childOption(ChannelOption.SO_KEEPALIVE, true);
// 绑定端口
ChannelFuture future = bootstrap.bind(port).sync();
logger.info(">>>>>>>>>>> xxl-job remoting server start success, nettype = {}, "
+ "port = {}", EmbedServer.class, port);
// start registry
// 注册执行器到 admin
startRegistry(appname, address);
// 在这里真正启动服务,并且会在这里阻塞
future.channel().closeFuture().sync();
} catch (InterruptedException e) {
if (e instanceof InterruptedException) {
logger.info(">>>>>>>>>>> xxl-job remoting server stop.");
} else {
logger.error(">>>>>>>>>>> xxl-job remoting server error.", e);
}
} finally {
// 停止
try {
workerGroup.shutdownGracefully();
bossGroup.shutdownGracefully();
} catch (Exception e) {
logger.error(e.getMessage(), e);
}
}
}在这个方法里终于看到了内置的http服务的神秘面纱:原来底层是由netty实现的!关于该方法,几点说明如下:
-
处理业务的线程池
bizThreadPool:该线程池是用来处理业务,注意区别于netty的bossGroup与workerGroup(分别处理网络连接与读写事件),netty建议耗时久的操作使用专门的线程池来处理,避免阻塞网络事件的处理。注意
bizThreadPool的拒绝策略为直接抛出异常,不使用当前线程来处理也是在避免阻塞网络事件的处理。 -
netty的childHandler中,添加了空闲监听:IdleStateHandler,这是netty提供的空闲监测器,所谓的空闲,是指网络连接有一段时间没有发生读、写以及读写事件。根据
IdleStateHandler构造方法的参数来看,在90秒内连接上没有发生读写事件时,即表示出现了空闲。当监测到当前连接有空闲时,就发出IdleStateEvent事件,该事件会在EmbedHttpServerHandler#userEventTriggered中处理:java@Override public void userEventTriggered(ChannelHandlerContext ctx, Object evt) throws Exception { // 处理空闲事件,即监听到当前channel空闲了 if (evt instanceof IdleStateEvent) { // 关闭当前连接 ctx.channel().close(); logger.debug(">>>>>>>>>>> xxl-job provider netty_http server" + " close an idle channel."); } else { super.userEventTriggered(ctx, evt); } } -
这个内置的http服务器究竟是用来干嘛的呢?根据
netty的代码套咱,答案就在EmbedHttpServerHandler#channelRead0方法中:java@Override protected void channelRead0(final ChannelHandlerContext ctx, FullHttpRequest msg) throws Exception { // 处理http的相关内容:请求体、uri、请求方法、请求token String requestData = msg.content().toString(CharsetUtil.UTF_8); String uri = msg.uri(); HttpMethod httpMethod = msg.method(); boolean keepAlive = HttpUtil.isKeepAlive(msg); String accessTokenReq = msg.headers().get( XxlJobRemotingUtil.XXL_JOB_ACCESS_TOKEN); // 在业务线程池中处理 bizThreadPool.execute(new Runnable() { @Override public void run() { // 具体的执行操作在这里 Object responseObj = process(httpMethod, uri, requestData, accessTokenReq); // 转成json String responseJson = GsonTool.toJson(responseObj); // http的响应 writeResponse(ctx, keepAlive, responseJson); } }); }这个方法比较简单,就是获取http的相关内容,如请求体、uri、请求方法、请求token等,然后在业务线程池中执行业务操作,执行业务操作的关键方法是
EmbedHttpServerHandler#process,关于该方法的执行内容本文就不介绍了,后面介绍具体操作时再详细展开。对于执行器提供的http接口,可以参考xxl-job官方文档中关于
执行器 RESTful API的介绍。 -
处理执行器的注册,方法是
EmbedServer#startRegistry,其实就是将执行器的地址告知admin,这样admin才会感知到执行器的存在,关于执行器的注册流程,后面会单独分析。 -
启动
netty服务,代码为future.channel().closeFuture().sync(),到这里内置的http服务器就真正启动了,可以对外提供服务了,并且线程会在这里阻塞直到停止。那么这个服务要如何停止呢?我们来看看
EmbedServer#toStop方法:javapublic void stop() throws Exception { // destroy server thread if (thread!=null && thread.isAlive()) { thread.interrupt(); } // stop registry stopRegistry(); logger.info(">>>>>>>>>>> xxl-job remoting server destroy success."); }停止方法比较粗暴,直接使用
thread.interrupt()中断该线程的执行,接着就调用stopRegistry()方法来结束执行器的注册,其实就是从admin中删除当前执行器的信息。
总的来说,EmbedServer#start方法的逻辑还是很清晰明了的,不过该方法主要依赖了netty,对于netty不熟悉的小伙伴理解起来可能比较困难,这块可参考本人的《netty入门与实战》系列文章.
总结
本文先是介绍了xxl-job执行器集成流程,接着重点介绍了执行器启动流程,用一张图来总结下启动流程:
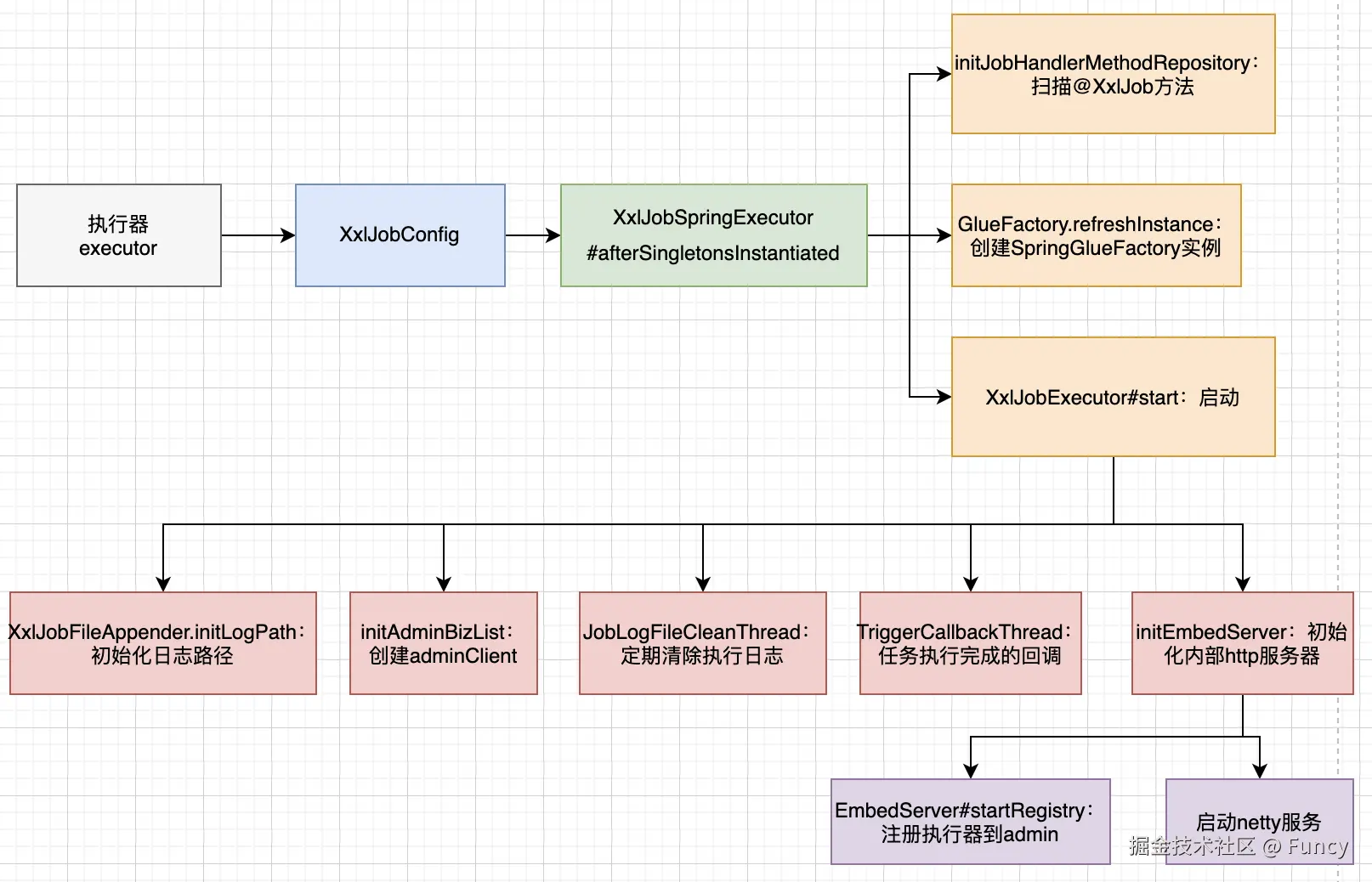
本文也挖了两个坑:
- 内置服务器的业务操作,也就是
EmbedHttpServerHandler#process方法 - 执行器注册到
admin,也就是EmbedServer#startRegistry方法
我们下一篇继续。
限于作者个人水平,文中难免有错误之处,欢迎指正!原创不易,商业转载请联系作者获得授权,非商业转载请注明出处。