大家好,我是吾鳴。专注于分享提升工作与生活效率的工具,无偿分享AI领域相关的精选报告,持续关注AI的前沿动向。
近年来,中国大模型领域迅猛发展,从"百模大战"进入"效率与场景"的深度竞争阶段。目前国内市场呈现出百花齐放的局面,不同厂商依托自身技术优势和场景特色,推出了各具特色的大模型产品。
对于普通用户和企业开发者而言,如何在这些眼花缭乱的选项中做出最佳选择,成为了一道难题。本文将为您介绍国内最强的6个文本大模型,帮助您在纷繁复杂的市场中找到最适合的那一款。

1. 国内六大文本大模型详解
1.1. 阿里通义千问:代码与长文本的性价比之王
阿里云推出的通义千问在代码生成领域独树一帜,其 qwen-coder-turbo 模型支持 256K tokens 的超长上下文。输入成本仅 0.002 元 / 千 Token,输出成本 0.006 元 / 千 Token,配合各 100 万 Token 的免费额度,成为开发者首选工具。该模型采用 "文本 + 代码" 融合训练方式,在金融量化策略编写、企业级应用开发等场景中准确率领先。
通义千问的分层产品体系颇具特色:开源版本 qwen2.5-coder 系列支持本地化部署,3B 参数模型限时免费体验;闭源的 plus 版本则提供企业级 SLA 保障。其长文本处理能力虽限于 32K tokens,但信息提取准确率仍达到 82.1%,在合同审查、财报分析等商务场景中性价比突出。官方提供的 API 文档详尽且支持在线调试,即使是非专业开发者也能快速上手。
1.2. 百度文心一言(ERNIE 4.5 Turbo):多模态生态的长文专家
作为百度 AI 生态的核心产品,文心一言 ERNIE 4.5 Turbo 在 2025 年迎来重大升级,将上下文窗口扩展至 128K tokens,相当于一次性处理 20 万字的文本内容。该模型最显著的优势在于多模态文档处理能力,能够无缝衔接文本、表格、公式等复杂内容格式,特别适合学术论文解析、技术手册生成等场景。
在成本控制方面,文心一言采用差异化定价策略,输入侧成本与同类产品持平,而输出侧成本仅为 3.2 元 / 百万 Token,在长文本生成场景中具备明显价格优势。通过百度千帆平台提供的低代码工具,开发者可快速实现模型集成,API 响应速度较上一代提升 44%,即使在处理 10 万字文档时也能保持流畅体验。其封闭域问答幻觉率为 3.4%,在需要平衡创造性与准确性的企业文案创作场景中表现均衡。
1.3. 华为盘古 NLP:政企场景的安全守护者
华为盘古 NLP 凭借 256K 长序列处理能力和严苛的隐私保护机制,成为政企领域的标杆产品。该模型采用 Encoder-Decoder 架构,在保持强大文本生成能力的同时,实现了行业知识检索、会议纪要自动生成等专业功能。其独特的 "3+2" 隐私保护方案 ------ 包括推理阶段敏感信息过滤、模型加密和混淆保护,完美满足政务、金融等领域的数据安全要求。
盘古 NLP 的优势体现在垂直领域的深度优化,通过预训练、微调、强化学习三级工作流,可快速适配能源、制造等行业知识库。在 2019 年 CLUE 榜单中,其曾刷新三项世界记录,中文理解能力久经考验。不过该模型主要面向企业客户提供定制化服务,公开渠道未披露具体定价,使用门槛相对较高,通常需要华为云团队提供技术支持。
1.4. 字节跳动豆包 V1.6:实时交互的低幻觉先锋
字节跳动旗下豆包大模型 V1.6 以 256K 超大上下文和 10ms 级首 Token 延迟,重新定义了实时交互体验。在 InfiniteBench 评测中,其长文本信息提取准确率达到 91.43%,远超行业平均水平,特别适合法律卷宗分析、学术文献综述等需要精准信息定位的场景。
豆包最引人注目的是其 2.1% 的超低幻觉率,在金融法规问答等封闭域任务中表现尤为突出。这得益于其优化的检索增强生成(RAG)技术,通过内置知识图谱与多源事实校验模块,有效抑制了无依据内容生成。成本方面,其处理成本为 42.4 元 / 百万 Token,虽高于同类产品,但在对准确性要求极高的医疗咨询、法律建议等场景中仍具成本效益。
1.5. 腾讯混元:开源生态的超长文本能手
腾讯混元在 2025 年 8 月开源四款小尺寸模型,其中 MOE 结构的 hunyuan-lite 支持 256K 上下文窗口,可一次性处理 40 万中文字符,相当于 3 本《哈利波特》的内容量。该模型在 "大海捞针" 测试中达到 99.9% 的准确率,能精准记忆超长文本中的人物关系和细节信息,在会议记录分析、书籍内容提炼等场景中表现出色。
混元系列采用模块化设计,提供从基础文本处理到复杂 Function Call 的全功能支持。其中长文本专用模型 hunyuan-turbos-longtext-128k 擅长文档摘要和问答任务,而 code 模型则在程序开发领域具备竞争力。作为腾讯云生态的重要组成,混元可与企业微信、腾讯会议等产品无缝集成,但公开渠道未明确其收费标准,推测采用阶梯定价模式。
1.6. 智谱清言(GLM-4-9B-Chat):专业领域的事实派代表
智谱 AI 推出的清言模型凭借 1.3% 的超低幻觉率,在需要强事实性的专业场景中占据一席之地。该模型基于清华大学研发的 GLM 架构,特别优化了中文语义理解能力,在历史研究、文化传承等领域的知识问答中表现优异。虽然在长文本总结测试中仅能处理约 41.75% 的文件内容,但其 32K 上下文版本在中小型文档处理上仍具优势。
智谱清言的开源特性使其成为研究机构和开发者的热门选择,支持灵活微调以适应特定领域需求。其 API 设计简洁直观,文档完善度较高,但在处理超长篇文本时需要额外的分片逻辑处理。目前官方未公布详细收费标准,推测采用与参数规模挂钩的阶梯定价模式。
2. 六大文本大模型深度比较
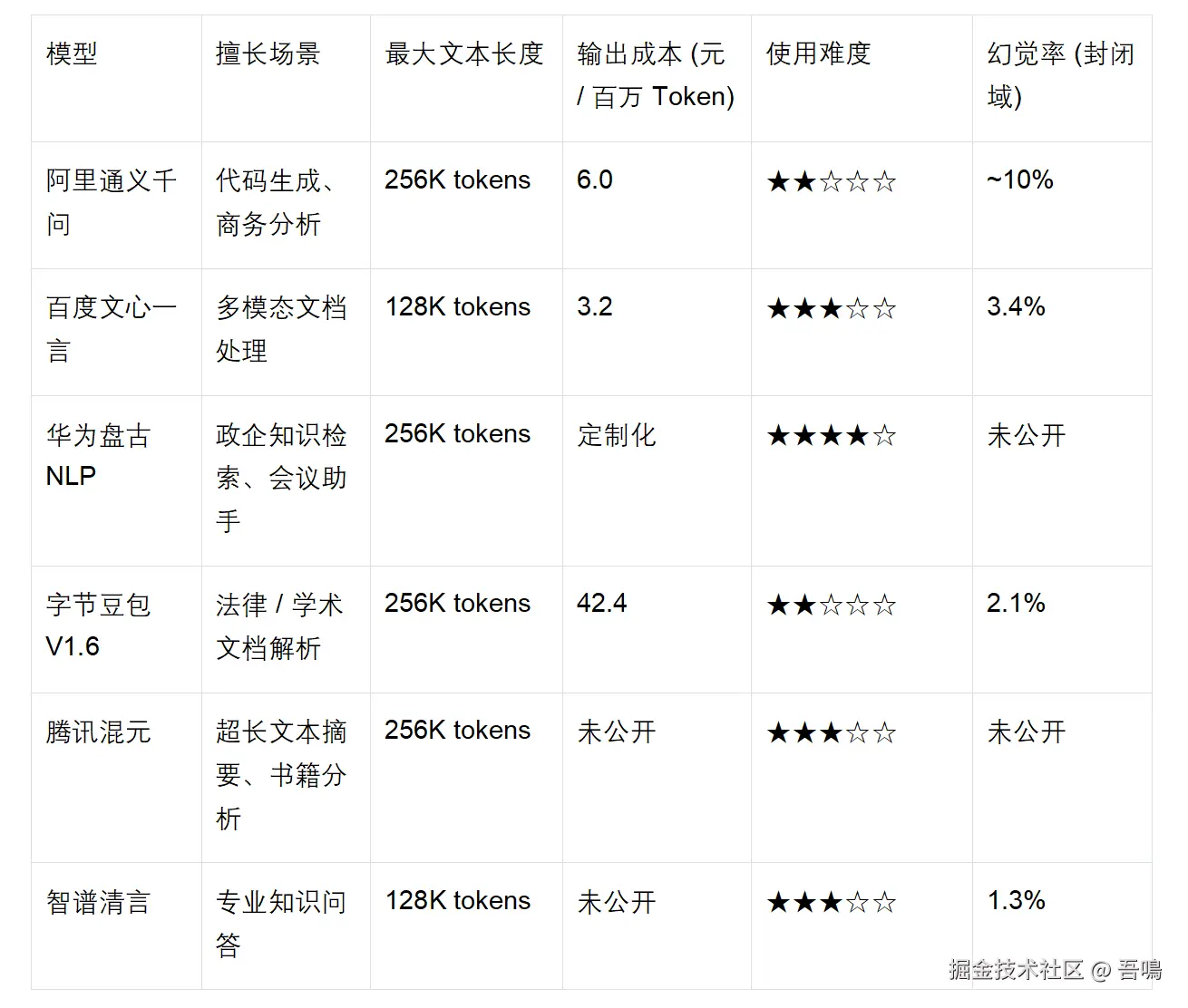
通过对六大模型的技术参数、场景表现和成本结构进行系统梳理,我们可以构建出清晰的能力对比框架。
在上下文长度方面: 通义千文、华为盘古 NLP、字节豆包和腾讯混元均达到 256K 级别,领先于文心一言的 128K 和智谱清言的 128K,这种差异直接决定了模型在处理书籍、大型报告等超长文本时的表现上限。
幻觉率控制上呈现明显分化: 智谱清言 1.3% 和豆包 2.1% 的表现最为突出,适合医疗诊断说明、法律条文解释等零容错场景;文心一言 3.4% 的水平处于中游,可满足多数企业级应用需求;而通义千问虽未公布具体数据,但参考同类产品推测在 10% 左右,更适合创意写作等对事实准确性要求不极致的场景。
成本结构方面: 文心一言 Turbo 和通义千问 Turbo 的输出成本最低,分别为 3.2 元 / 百万 Token 和 6 元 / 百万 Token,适合大规模内容生成;豆包 42.4 元 / 百万 Token 的成本虽高,但在低幻觉率场景中仍具性价比;华为盘古、腾讯混元和智谱清言因主要面向企业客户,具体定价需定制咨询。
使用难度上: 通义千问和豆包凭借完善的文档和低代码工具,对开发者最友好;文心一言和智谱清言次之,需具备基础 API 调用能力;华为盘古因涉及定制化配置,使用门槛最高。
3. 不同场景下的模型选择建议
在学术研究场景 中,字节豆包 V1.6 凭借 256K 超长上下文和 91.43% 的信息提取准确率成为首选,其 10ms 级的响应速度可支持实时文献交互批注,2.1% 的低幻觉率能有效避免引用错误。对于需要处理多语言文献 的研究者,华为盘古 NLP 即将推出的西语 / 葡语版本值得期待。
企业内容创作 方面,文心一言 ERNIE 4.5 Turbo 表现均衡,128K 上下文足以应对产品手册生成,3.2 元 / 百万 Token 的成本优势适合大规模内容生产。而注重品牌调性一致性 的企业,可选择腾讯混元进行定制化训练,其开源的小尺寸模型便于在自有平台部署。
代码开发场景 无疑是通义千问的天下,256 tokens 上下文可支持完整项目代码理解,0.006 元 / 千 Token 的输出成本使批量脚本生成极具经济性。对于金融科技公司,其代码模型的量化策略编写能力可显著提升研发效率。
政务与法律领域 的首选当属智谱清言 和华为盘古 NLP。智谱清言 1.3% 的超低幻觉率在法规解读中极具价值,而盘古 NLP 的隐私保护机制和行业知识检索能力,完美适配政企知识库建设需求。在处理超过 10 万字的卷宗材料时,盘古 256K 的长文本能力可减少分块处理带来的信息损失。
客服与教育场景 建议选择通义千问 或文心一言。通义千问的免费额度政策适合初创企业试用,而文心一言的多轮对话优化能提供更自然的交互体验。对于需要实时响应的在线教育平台,豆包的 Flash 推理技术可确保流畅的师生互动。
4. 总结
面对这场正在重塑千行百业的文本智能革命,没有放之四海而皆准的完美模型,只有基于场景需求的最优解。企业和开发者应结合文本长度、准确性要求、成本预算等核心要素,在这场 "百模大战" 中找到最适合自己的那一款文本大模型。随着技术的持续迭代,我们有理由相信,国产文本大模型将在准确性、效率和安全性上实现更大突破,为数字经济发展注入更强动力。
最近实战了一些扣子(Coze)工作流相关的案例,包含小红薯图文生成、爆款视频剪辑、办公提效等扣子案例,内附详细的教程和工作流安装包,感兴趣的朋友可以来个一键三连 ,文章评论区评论"扣子案例"领取。