最近,我利用空闲时间对 AWS 数据服务进行了大量学习和试验,发现它们非常令人着迷。
在本文中,我们将探讨如何使用 AWS 服务(例如 Data Catalog、DataBrew、DynamoDB)构建实时无服务器数据管道,并在 Terraform 的帮助下将其无缝部署到 AWS。
无论您是数据工程领域的新手还是经验丰富的专家,本指南都能满足您的需求!
先决条件
为什么选择 Terraform
- 开源
- 庞大的开发者社区
- 不可变基础设施
- IaC
- Cloud agnostic
- 希望提高我对新技术的了解
项目结构
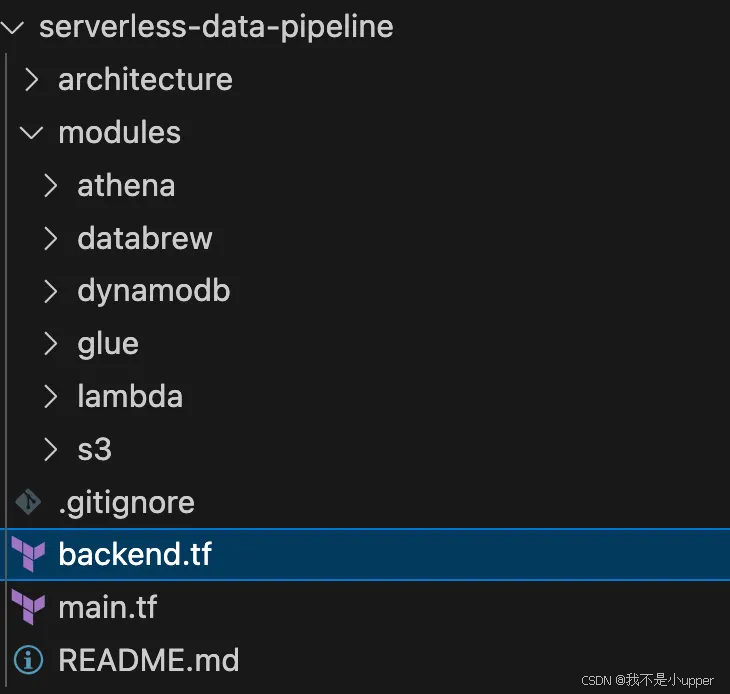
图为项目结构
概述
我不是数据工程师,也没有主动构建数据管道;不过,最近我接触了一些数据服务。结合我对 AWS 的了解,我决定尝试一下这些服务。
本文源于我构建数据管道这个有趣项目的经历,我发现整个经历非常有趣且有益。
使用的关键服务
1**.亚马逊S3**
- 充当数据存储层。
- 存储项目中使用的JSON文件
2.亚马逊DynamoDB
- 充当数据库层。
- 使用 DynamoDB 流和 AWS Lambda 将 JSON 数据从 DynamoDB 导出到 S3
3. AWS Glue
- 处理数据提取、转换和加载(ETL)。
- 使用 Glue 数据目录管理数据集的元数据。
- 还支持使用自动发现模式并创建表的爬虫进行爬取;但是,在这个项目中,我们手动定义模式,所以不需要这样做。
4.亚马逊DataBrew
- 用于通过删除重复的条目来转换存储在 S3 中的数据。
- 一旦项目被放置在路径上的 S3 存储桶中,就会作为触发作业(来自 lambda)运行
/data - 指向 Glue 数据目录作为输入数据集。
5.亚马逊****Athena
- 使用标准 SQL 查询存储在 Glue Catalog 中的转换数据。
- 完全无服务器并与 Glue 数据目录集成。
最终架构
按 Enter 键或单击即可查看完整尺寸的图像
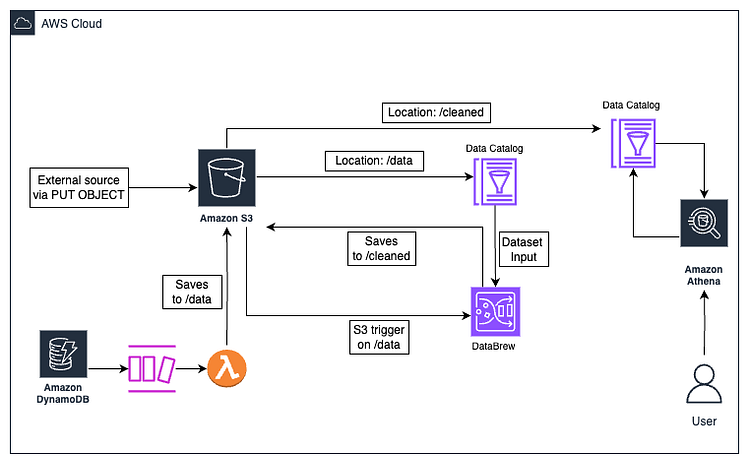
数据管道架构
架构详解
第一流程:
- .json 文件被添加到 S3 的路径上
/data - 第一个 Glue Catalog Table 从
/dataS3 中的路径读取 - 上传到触发一个 lambda 函数,该函数启动 DataBrew 转换作业,通过使用列
/data删除任何重复的行来清理 First Glue Catalog Table(输入数据集)中的数据email - DataBrew 作业将转换后的数据输出到
/cleaned路径下 S3 中的新路径,覆盖该路径中的其他项目以避免输出路径中的重复。 - 第二个 Glue 目录表从
/cleanedS3 中的路径读取 - Athena 工作组从第二个 Glue 目录表读取数据并对其进行查询。查询结果随后存储在 S3 中的新输出位置。
/athena-results/
第二个 流程:
- 一个项目已添加到 DynamoDB。
- 添加新项目时触发 DynamoDB 流
- 调用连接到 DynamoDB Stream 的 Lambda 函数(Python 语言),将新项目转换为*.json*文件
- 第一个流程中的所有步骤
综上所述,使用 DynamoDB Streams 和 S3 Bucket Notification 与 Lambda 集成来实现实时数据处理的目标。
代码定义
主文件
提供商:第一步通常是定义提供商。这里我们将云提供商定义为aws。
此外,我们还包括在项目中使用的各种模块,并传递所有必需的变量
adh
terraform {
required_providers {
aws = {
source = "hashicorp/aws"
version = "~> 5.0"
}
}
required_version = ">= 1.3.0"
}
aeg
provider "aws" {
region = "us-east-1"
}
module "s3_bucket" {
source = "./modules/s3"
bucket_name = "upload-bucket-data-pipeline-234"
}
module "dynamodb_table" {
source = "./modules/dynamodb"
table_name = "dynamodb-table"
}
module "lambda_function" {
source = "./modules/lambda"
lambda_name = "dynamodb_to_s3"
handler_trigger = "dynamodb_to_s3_trigger.lambda_handler"
s3_bucket = module.s3_bucket.bucket_name
table_name = module.dynamodb_table.table_name
dynamodb_stream_arn = module.dynamodb_table.stream_arn
}
module "glue_catalog" {
source = "./modules/glue/glue_raw"
database_name = "catalog_db"
table_name = "catalog_json_table"
s3_location = "s3://${module.s3_bucket.bucket_name}/data/"
}
module "databrew" {
source = "./modules/databrew"
glue_table = module.glue_catalog.table_name
glue_db = module.glue_catalog.database_name
s3_bucket_name = module.s3_bucket.bucket_name
data_zip = module.lambda_function.data_zip
}
module "glue_catalog_cleaned" {
source = "./modules/glue/glue_cleaned"
database_name = "catalog_cleaned_db"
table_name = "catalog_cleaned_json_table"
s3_location = "s3://${module.s3_bucket.bucket_name}/cleaned/"
}
module "athena" {
source = "./modules/athena"
result_output_location = "s3://${module.s3_bucket.bucket_name}/athena-results/"
}后端.tf
首先,创建 S3 存储桶以远程存储 Terraform 状态文件,以促进协作。
按 Enter 键或单击即可查看完整尺寸的图像
Terraform 状态文件的 S3 存储桶
创建完成后在文件中添加如下内容backend.tf:
adh
<span style="background-color:#f9f9f9"><span style="color:#242424">terraform {
后端<span style="color:#c41a16">"s3"</span> {
bucket = <span style="color:#c41a16">"serverless-data-pipeline-backend-bucket"</span>
键 = <span style="color:#c41a16">"serverless-pipeline/dev/terraform.tfstate"</span>
区域 = <span style="color:#c41a16">"us-east-1"</span>
}
}</span></span>一旦我们运行terraform init并terraform apply部署项目,我们应该看到存储在存储桶中的状态,如下所示:
按 Enter 键或单击即可查看完整尺寸的图像
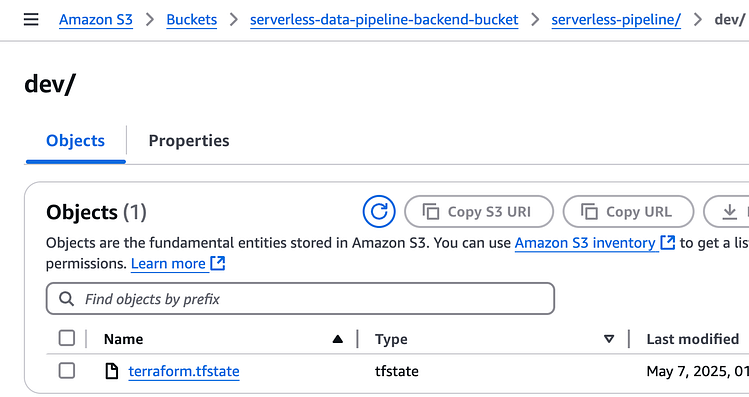
S3 中的 Terraform 状态文件
模块/main.tf
每个服务的基础结构和配置都放在各自的main.tf文件中
模块/output.tf
每个服务的输出详细信息都放在各自的output.tf文件中
模块/variable.tf
每个服务所需的导出变量都放在各自的variable.tf文件中
部署应用程序
现在我们已经准备好部署我们的应用程序了。运行以下命令进行部署。
Terraform init:这将初始化项目,提取部署所需的所有必需包。
adh
terraform initTerraform 计划:这可视化了提议的更改,对于在部署之前捕获任何意外更改非常有用。
adh
terraform planTerraform apply:将项目部署到 AWS
adh
terraform apply测试应用程序
S3 存储桶最初加载了一个 sample.json 文件,其内容如下:
bash
[{
"id":"1",
"name":"John Doe",
"email":"john@example.com",
"timestamp":"2025-04-19T12:00:00Z"
},
{
"id":"2",
"name":"Mary Doe",
"email":"mary@example.com",
"timestamp":"2025-06-20T12:00:00Z"
},
{
"id":"3",
"name":"Jane Doe",
"email":"john@example.com",
"timestamp":"2025-06-22T12:00:00Z"
}
]注意:B:可以看出,我们有一个重复的电子邮件 john@example.com*,理想的结果是删除重复的条目。*
这是在使用 Terraform 创建存储桶后立即上传的,因此它不会触发 DataBrew 作业,因为触发器设置在项目后期发生。
为了测试实时功能和项目的完整流程,我们可以将新对象上传到 S3,也可以将新项目添加到 DynamoDB。我们将向 DynamoDB 添加一个新项目来测试完整流程:
通过 AWS 控制台转到 DynamoDB 并添加新项目:
按 Enter 键或单击即可查看完整尺寸的图像
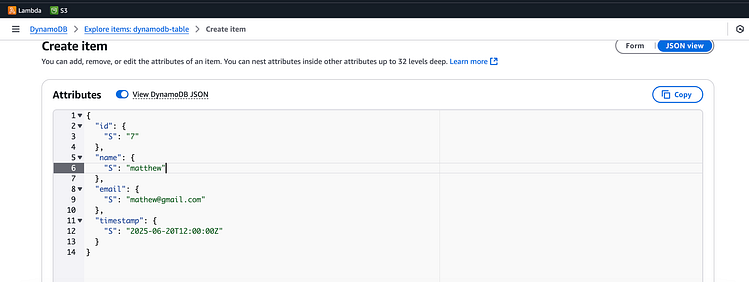
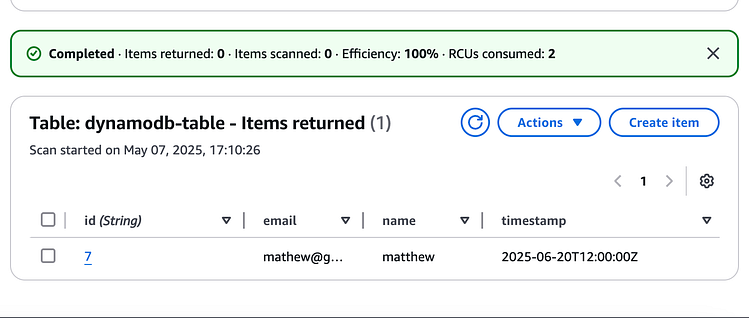
添加此项将触发 DynamoDB 流,该流使用相关的 lambda 函数将新对象插入 S3。
按 Enter 键或单击即可查看完整尺寸的图像
按 Enter 键或单击即可查看完整尺寸的图像
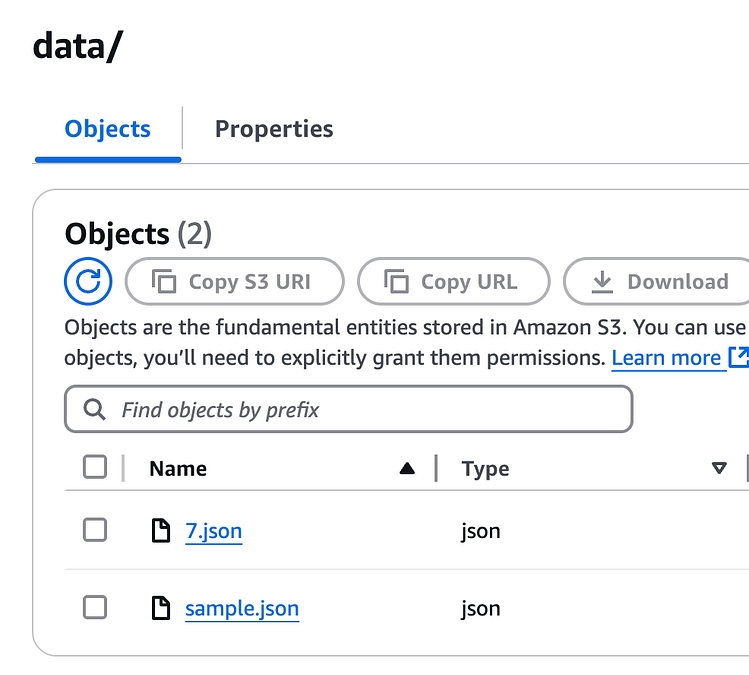
转到 S3,我们看到7.json添加了新项目:
按 Enter 键或单击即可查看完整尺寸的图像
接下来,转到数据目录,我们可以看到数据库和表
按 Enter 键或单击即可查看完整尺寸的图像
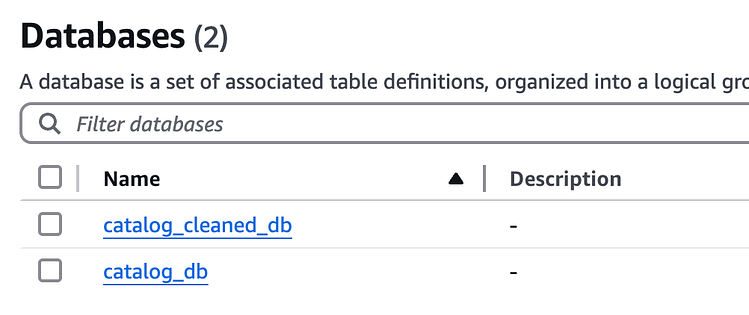
数据目录数据库
按 Enter 键或单击即可查看完整尺寸的图像
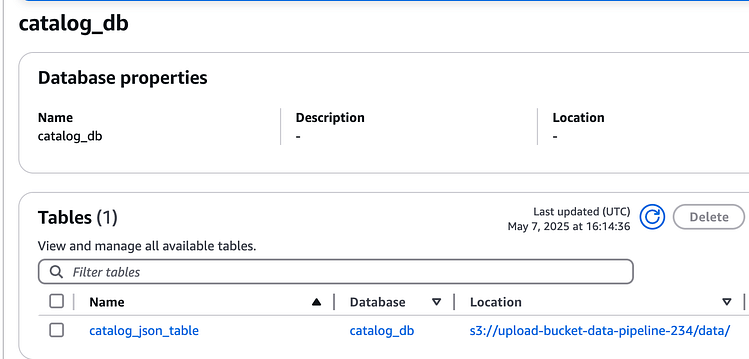
数据目录表
前往 DataBrew,我们看到了该项目。
一旦路径中的新添加内容触发了 lambda 函数/data,它就会启动 DataBrew 转换作业:
按 Enter 键或单击即可查看完整尺寸的图像
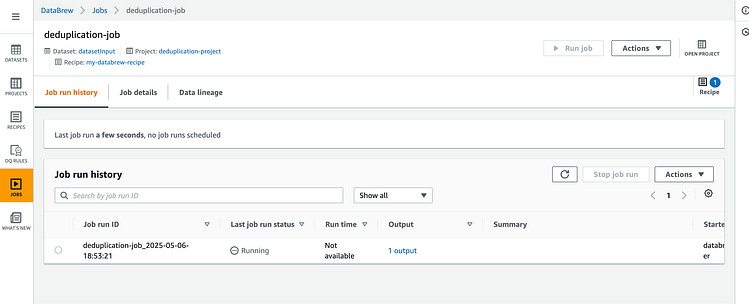
一旦完成,它看起来是这样的:
按 Enter 键或单击即可查看完整尺寸的图像
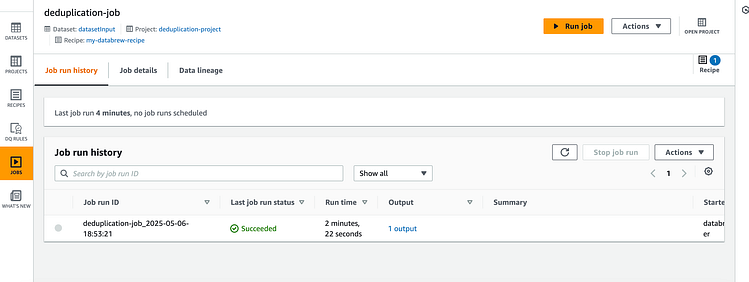
已完成 DataBrew 作业
DataBrew 数据沿袭使我们能够通过 DataBrew 查看流程的图形表示。
空闲作业:
按 Enter 键或单击即可查看完整尺寸的图像
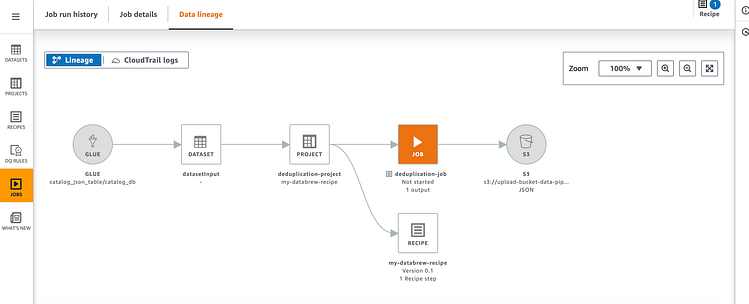
空闲作业的数据沿袭
正在运行的作业:
按 Enter 键或单击即可查看完整尺寸的图像
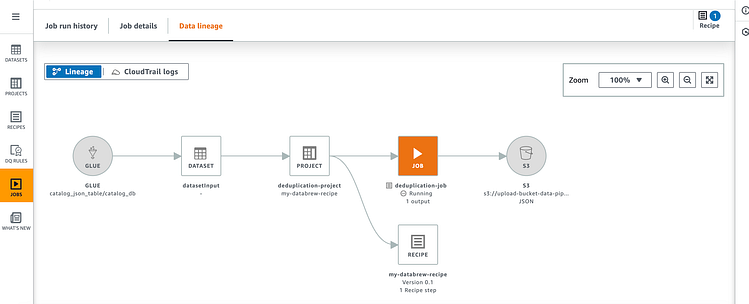
正在运行的作业的数据沿袭
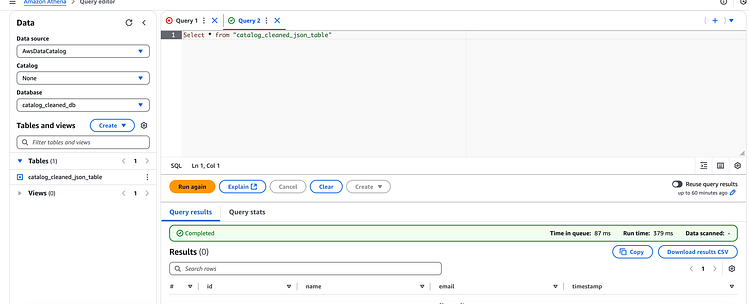
最后,前往 Athena 并选择my-athena-workgroup要运行查询的工作组。
在 DataBrew Job 运行之前,如果我们使用 Athena 运行查询,则不会有任何结果,因为该/cleaned路径还没有任何项目:
按 Enter 键或单击即可查看完整尺寸的图像
但是,在 Databrew Job 成功运行后,我们单击再次运行按钮在 Athena 中重新运行查询:
按 Enter 键或单击即可查看完整尺寸的图像
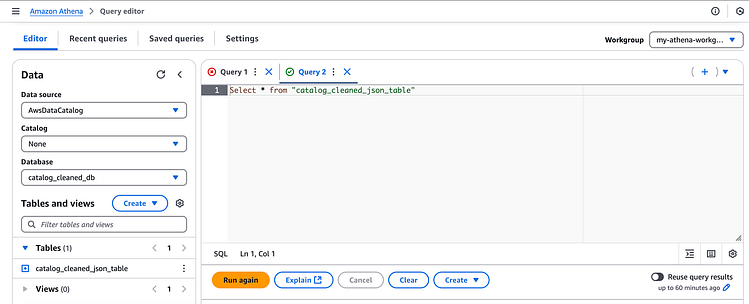
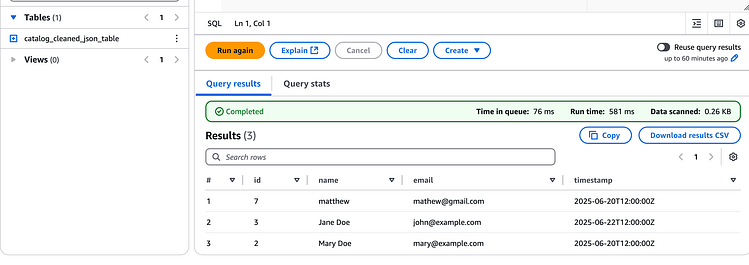
结果如下:
按 Enter 键或单击即可查看完整尺寸的图像
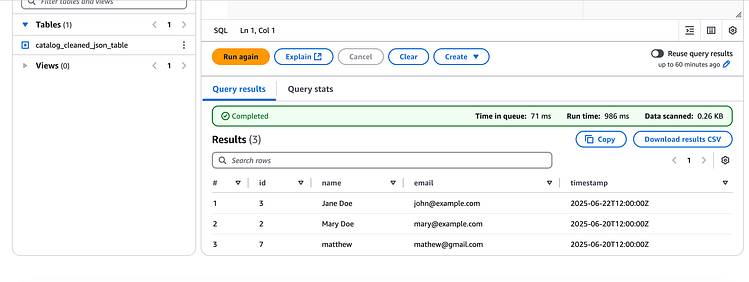
如果您观察一下,就会发现它删除了在项目创建期间上传到 S3 的文件john@example.com中找到的带有电子邮件的重复条目。sample.json
它还具有添加了电子邮件的新 DynamoDB 项目mathew@gmail.com。
这意味着我们的管道按预期工作!!
通过 DynamoDB 添加重复项
让我们通过向 DynamoDB 添加新项目来进一步测试,但这次它将有一封与我们现有的记录匹配的电子邮件。
按 Enter 键或单击即可查看完整尺寸的图像
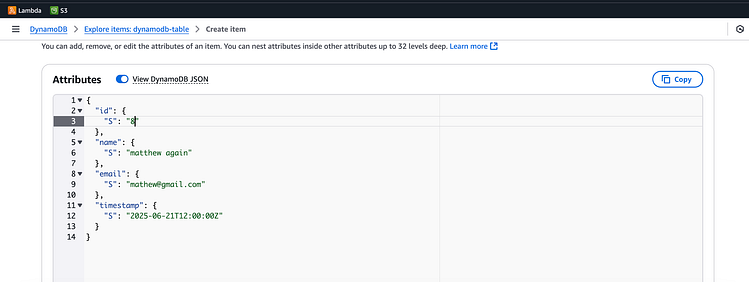
我们添加了一个有冲突电子邮件的新项目mathew@gmail.com
按 Enter 键或单击即可查看完整尺寸的图像
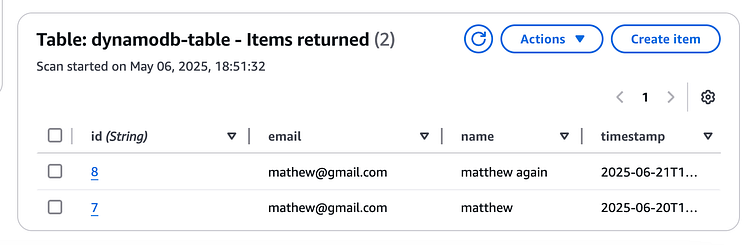
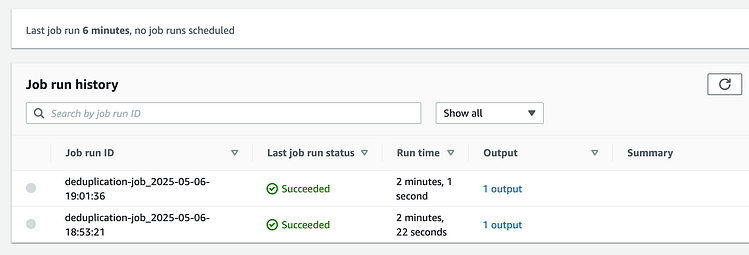
这将触发一个新的 DataBrew 作业:
按 Enter 键或单击即可查看完整尺寸的图像
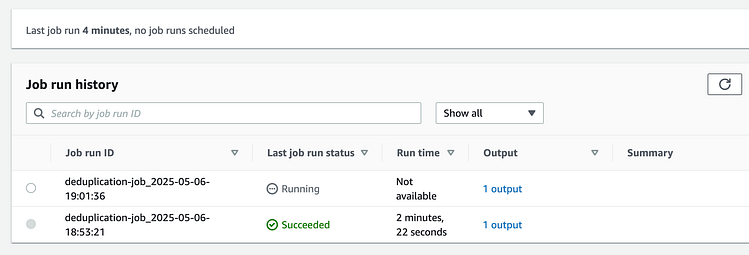
一旦成功,我们就会看到:
按 Enter 键或单击即可查看完整尺寸的图像
接下来,转到 Athena 并再次运行查询,这次它没有重复的记录!
按 Enter 键或单击即可查看完整尺寸的图像
结论
我创建这个项目和文章是为了提高我在 Terraform 方面的技能,并在磨练我的 Python 技能的同时在数据工程领域亲身体验。