在一家中型零售企业的数字化转型项目中,数据团队面临着一个典型的困境:市场部需要将来自抖音、京东、自有商城和CRM系统的用户行为数据整合到数据仓库,以支持实时营销分析。传统方案下,这需要3位技术同事耗时两周开发ETL脚本,涉及API调用、字段映射、数据清洗和异常处理。然而,企业希望在一周内上线,且团队中并无专职ETL开发人员。
这个场景,正是当前企业数据集成痛点的缩影。随着微服务架构、SaaS应用和云原生系统的普及,企业的数据源日益分散。IDC预测,到2027年,中国数据管理解决方案市场规模将达160亿美元,年复合增长率16%。在这一背景下,零代码ETL平台迅速兴起,宣称"无需编程即可完成数据集成",成为市场新宠。
但问题也随之而来:零代码集成,究竟是技术进步的必然产物,还是一场包装精美的营销游戏?它能否真正替代传统ETL?作为企业技术决策者,我们该如何理性评估其价值?
一、零代码集成的兴起与争议
过去十年,企业数据源从单一数据库扩展到包括云服务、API、IoT设备、日志文件在内的多源异构体系。传统ETL工具如Informatica、Kettle等虽功能强大,但依赖专业开发人员,开发周期长、维护成本高,难以满足敏捷业务需求。
零代码集成平台的出现,试图解决这一矛盾。其核心理念是通过可视化拖拽界面,将数据抽取、转换、加载流程图形化,用户只需配置连接、选择字段、设置规则,即可自动生成数据管道。表面上看,这大幅降低了技术门槛。
然而,争议也正源于此:"零代码"是否意味着"无技术"? 实际上,任何数据集成都涉及连接管理、并发控制、错误处理、性能优化等底层逻辑。零代码平台并非消除技术复杂性,而是将其封装在后台。关键在于,这种封装是否足够健壮,能否应对真实业务场景中的复杂性。
二、零代码集成的核心理念:从"写代码"到"配流程"
零代码(No-Code)与低代码(Low-Code)常被混用,但有本质区别:
低代码:仍需少量脚本或表达式,适用于技术人员快速开发。
零代码:完全通过图形界面完成配置,目标用户是非技术人员或业务分析师。
在ETL场景中,零代码平台将传统ETL的三个阶段重构为:
Extract(抽取):通过预置连接器(Connector)连接数据库、API或文件系统;
Transform(转换):通过拖拽组件实现字段映射、清洗、聚合、去重等操作;
Load(加载):将处理后的数据写入目标系统,支持批量、增量或CDC模式。
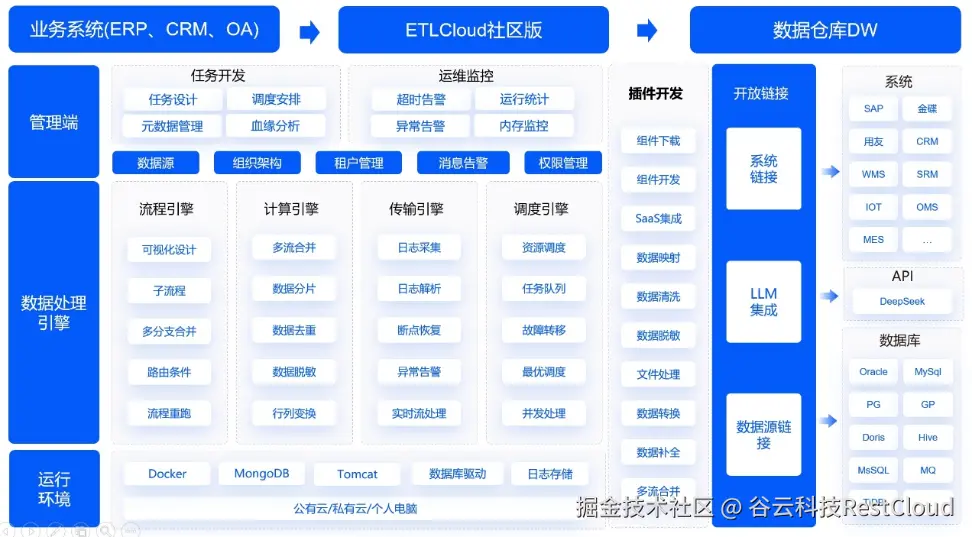
ETLCloud架构图
三、ETL平台的幕后技术揭秘
要判断一个零代码平台是否"靠谱",必须深入其技术架构。真正的技术实力,不在于界面多美观,而在于背后如何处理以下核心问题。
1.数据连接与适配层
现代企业常使用多种数据库(MySQL、Oracle、MongoDB)、SaaS系统(钉钉、飞书、Salesforce)和云服务(阿里云、AWS)。零代码平台必须提供标准化连接器,封装不同数据源的协议、认证和查询语法。
以RestCloud ETLCloud平台为例,其支持超过100种数据库和SaaS应用,通过统一的连接器框架实现跨平台兼容。每个连接器内部封装了驱动加载、连接池管理、超时重试等机制,对外暴露统一的配置接口。这种设计既降低了用户操作复杂度,也保证了连接的稳定性。
2.数据抽取与并发处理
数据抽取面临两大挑战:批处理延迟与实时性要求。
-
批处理:适用于离线报表,但存在T+1延迟;
-
流式处理:通过CDC(变更数据捕获)技术,实时捕获数据库日志(如MySQL binlog),实现秒级同步。
ETLCloud平台支持CDC模式,用户仅需配置源库和目标库,平台自动解析binlog并生成增量数据流。其任务调度引擎采用分布式架构,支持高并发任务执行,每天可运行20万+自动化流程,处理数百亿条数据。
3.数据转换引擎
可视化拖拽的背后,是复杂的规则翻译机制。当用户拖入"去重"组件时,平台需自动生成对应的SQL或脚本。这要求引擎具备:
-
规则到代码的映射能力:如"按字段A去重" → GROUP BY A 或 ROW_NUMBER() OVER (PARTITION BY A);
-
内置函数库:支持字符串处理、日期转换、正则匹配等常用操作;
-
复杂逻辑支持:如条件分支、循环、自定义表达式。
ETLCloud提供500+预置组件和1500+数据处理模板,覆盖90%常见场景。对于特殊需求,也支持嵌入自定义脚本,实现零代码与代码模式的混合使用。
4.数据加载与容错机制
数据加载不仅关乎性能,更涉及一致性与容错。
-
批量加载:采用分批提交(batch commit)减少事务开销;
-
增量同步:基于时间戳或自增ID,避免全量重刷;
-
CDC同步:确保源与目标数据最终一致。
在错误处理方面,平台需具备:
-
数据质量校验:自动检测空值、格式错误、编码异常;
-
错误恢复策略:支持断点续传、失败重试、异常数据隔离;
-
日志与监控:记录每一步执行状态,便于排查问题。
四、零代码集成的优势与局限
优势
- 快速上手,缩短项目周期
无需编写SQL或Python脚本,业务人员可在数小时内完成数据对接,尤其适合临时分析需求。
- 降低人力成本
减少对专业ETL工程师的依赖,释放开发资源用于高价值任务。
- 标准化与可视化管理
所有数据流程集中管理,支持版本控制、依赖分析和影响评估,提升数据治理水平。
局限
- 灵活性不足
对于复杂逻辑(如递归计算、机器学习预处理),仍需手动编码,零代码平台难以覆盖。
- 性能瓶颈
在处理TB级数据时,图形化引擎可能成为性能瓶颈,需依赖底层分布式计算框架(如Spark)。
- 平台依赖与厂商锁定
流程配置深度绑定平台,迁移成本高。选择时需评估厂商的技术开放性和生态兼容性。
五、如何评估一个零代码ETL平台?
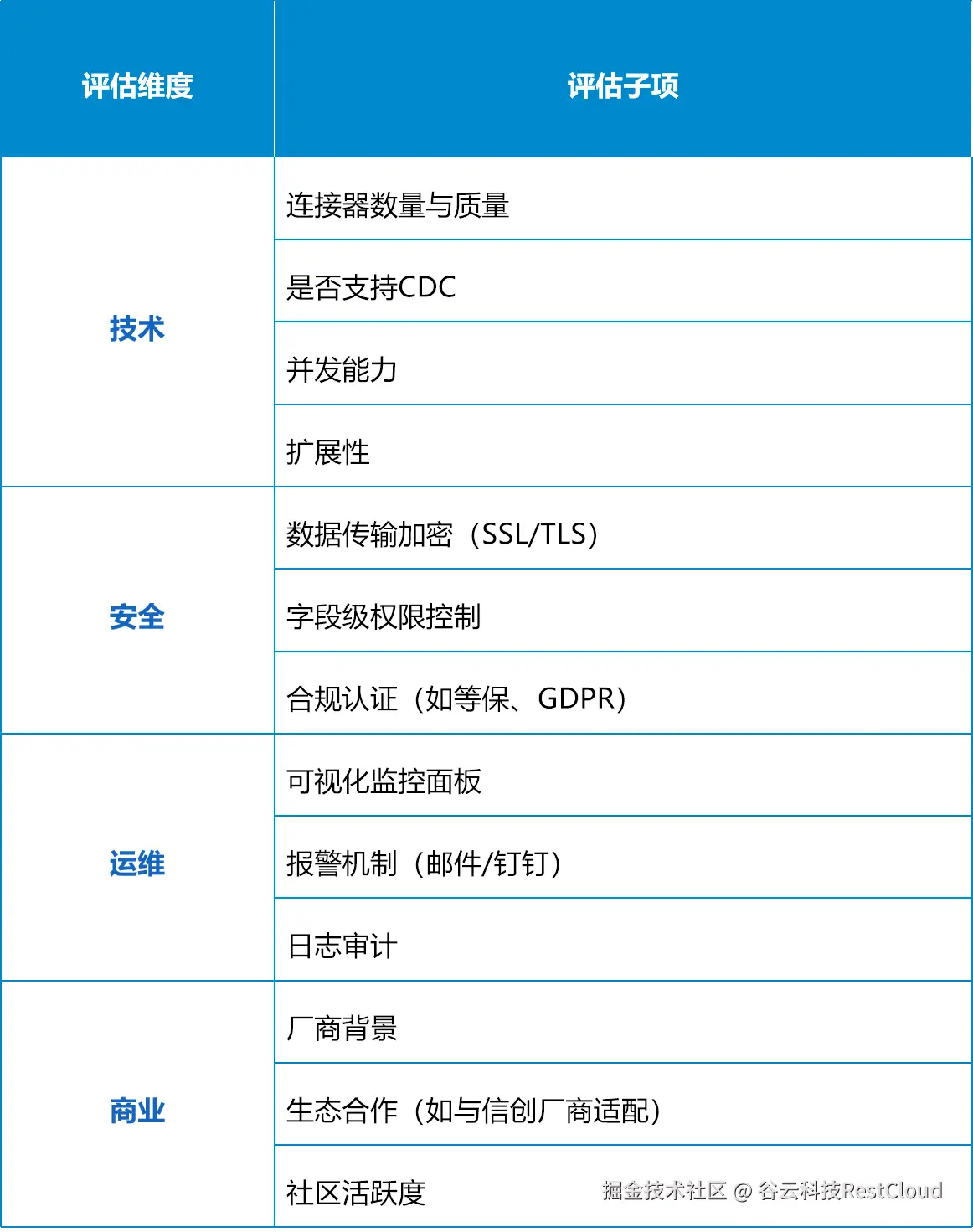
六、结论与未来趋势
零代码ETL不是对传统ETL的颠覆,而是对数据集成民主化的推动。它无法替代所有编码场景,但在80%的常规集成任务中,能显著提升效率。
未来,"零代码 + 可扩展代码" 的混合模式将成为主流。平台既提供开箱即用的可视化能力,也允许高级用户嵌入脚本或调用API,实现灵活性与易用性的平衡。
对企业而言,建议采取"场景化选型"策略:
对于标准化、高频的数据同步,优先采用零代码平台;
对于复杂数据处理或高性能要求场景,仍保留专业开发能力。
数据集成的终极目标,不是工具的先进性,而是让数据真正流动起来,支撑业务决策。在这个过程中,零代码ETL或许不是终点,但它确实为更多企业打开了通往数据智能的大门。