引言
图形处理单元(GPU)作为现代计算系统中的重要组件,不仅在图形渲染领域发挥关键作用,也在人工智能、科学计算等通用计算领域展现出强大的并行计算能力。本文将深入探讨GPU的核心概念、架构特点以及其与CPU的区别。
我是 SharkChili ,Java 开发者,Java Guide 开源项目维护者。欢迎关注我的公众号:写代码的SharkChili ,也欢迎您了解我的开源项目 mini-redis:github.com/shark-ctrl/...
为方便与读者交流,现已创建读者群。关注上方公众号获取我的联系方式,添加时备注加群即可加入。
详解GPU的核心概念
GPU的诞生
GPU即图形处理器,在发展初期只能执行一些固定的操作,计算电路固定且不可编程。随着技术发展,出现了GPGPU(General-Purpose computing on Graphics Processing Units,通用图形处理器)架构,它不仅计算高效且具备完整的编程能力。
为了提升图形渲染或模型训练时大量重复运算的效率,避免这些计算占用CPU大量时钟周期而导致其他进程执行效率低下,业界提出了GPU这种专用处理单元。GPU具有大量简单的计算单元,专门用于处理大规模并行计算任务。如下图所示,GPU的架构特点包括:
- 由大量ALU(算术逻辑单元)运算单元、少量控制单元和缓存构成
- 具有高带宽的内存子系统,但相比CPU具有较少的片上缓存
- 计算单元以大量简单的ALU为主,没有像CPU那样的复杂控制逻辑电路(如分支预测和乱序执行)
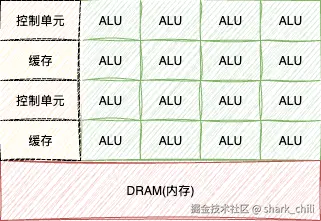
为什么GPU中有大量的ALU
图形渲染和模型训练等任务具有一种共同特点:需要对大量不同的数据执行相同或相似的简单计算操作。为了提升这类运算的效率,GPU的设计摒弃了复杂的控制单元,转而引入大量ALU算术单元来并行处理这些计算密集型任务。
对应地,设计者们将这种技术命名为SIMT(Single Instruction, Multiple Thread,单指令多线程)技术:
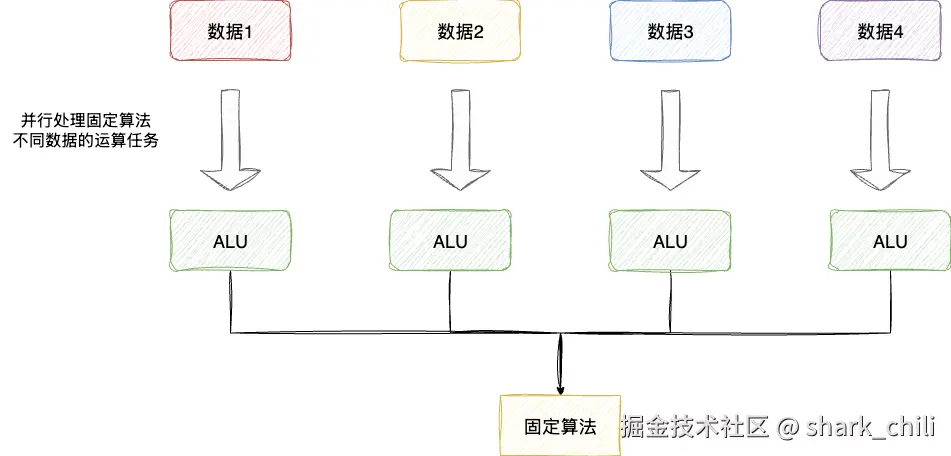
实际上,这种设计理念并非GPU原创。早在CPU中就已经涉及类似技术,即为提升批量数据重复运算执行效率而提出的SIMD(Single Instruction, Multiple Data,单指令多数据流)技术。两者的主要区别在于:
- SIMD:在同一条指令下,对多个数据执行相同操作,所有处理单元严格同步
- SIMT:在同一条指令下,多个线程可以独立执行,允许存在分支 diverge(分歧)
GPU的优势与特点
GPU相较于CPU,减少了复杂控制逻辑单元的设计,相反设计了大量的ALU和简单控制电路,专门用于处理大规模并行的简单运算,保证图形渲染和模型训练的高效执行。
这也进一步说明了CPU和GPU的不同应用场景:
- CPU涉及各种复杂逻辑判断和运算,包括I/O密集型和计算密集型任务,因此设计了复杂的控制单元和较少的运算单元
- GPU专注于大规模并行计算,设计了大量简单的运算单元和高效的内存子系统
为什么GPU中有大量的执行上下文
在GPU执行大量并行运算任务的过程中,难免会涉及一些需要等待内存访问或其他操作完成的任务。为了尽可能充分利用运算单元,GPU采用了大量执行上下文的设计。
当某些任务需要阻塞等待时,GPU会切换到其他准备就绪的任务继续执行,从而最大化硬件利用率。这一点GPU借鉴了CPU的超线程技术思想(即单个CPU核心中维护多个线程上下文),但GPU将其扩展到了数千个并行线程的规模。
小结
总的来说,现代GPU已经具备完整的虚拟内存管理和中断处理能力,能够在硬件层面独立完成复杂任务调度。但在实际应用中,CPU通常负责任务调度和复杂逻辑控制,然后将大规模并行计算任务交给GPU处理,充分发挥各自的优势。
我是 SharkChili ,Java 开发者,Java Guide 开源项目维护者。欢迎关注我的公众号:写代码的SharkChili ,也欢迎您了解我的开源项目 mini-redis:github.com/shark-ctrl/...
为方便与读者交流,现已创建读者群。关注上方公众号获取我的联系方式,添加时备注加群即可加入。
参考
《趣话计算机底层技术》 深入理解GPU硬件架构及运行机制:zhuanlan.zhihu.com/p/678001378
本文使用 markdown.com.cn 排版