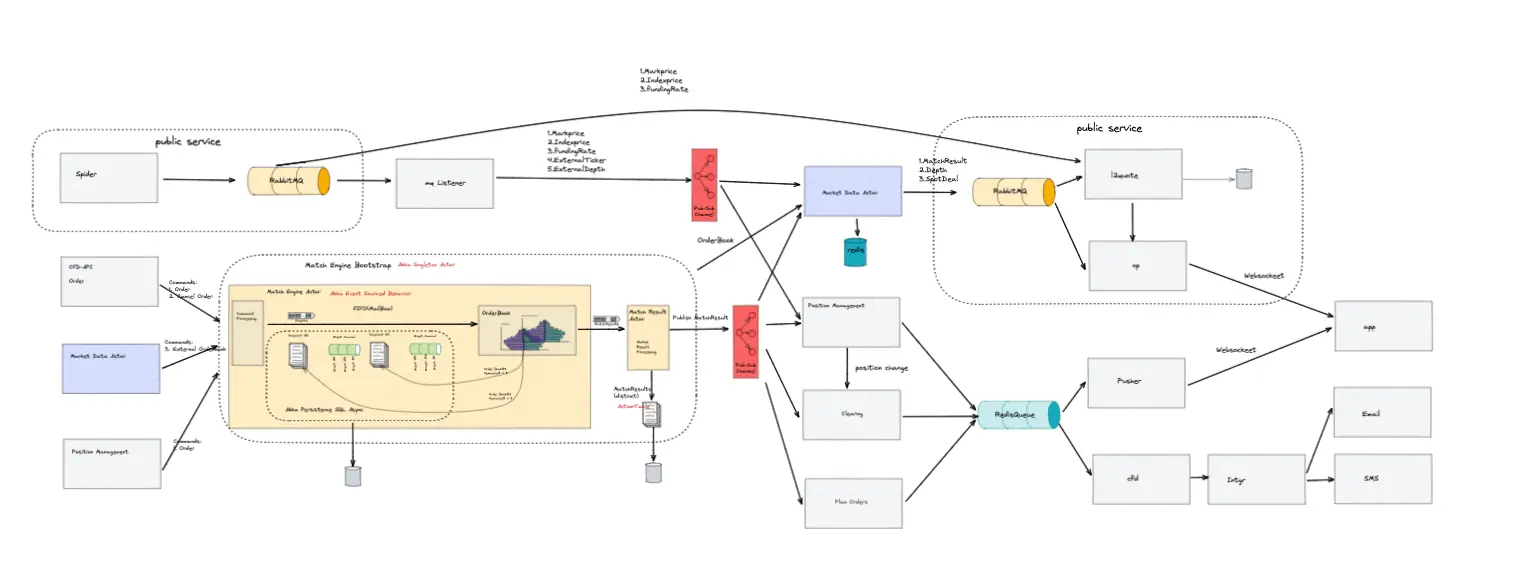
在现代电子交易系统中,撮合引擎作为核心组件,其性能和可靠性犹如系统的"心脏",直接决定了整个系统的交易效率和稳定性,关乎着交易平台的生死存亡。在高频交易日益盛行的今天,如何提升撮合引擎的处理速度、保障数据的一致性以及实现系统的高可用性,成为了交易系统设计中的关键挑战。本文将结合系统架构图和相关技术实践,深入分享本人在高性能撮合引擎设计中的关键技术与创新点,主要包括内存化撮合、内存化仓位管理、事件化处理以及基于Akka的异步处理模式。
一、内存化撮合:速度与可靠性的双重提升
内存化撮合是提高交易系统处理速度的关键技术之一,它犹如给撮合引擎装上了"加速器"。在原来的撮合系统中,通常依赖于数据库进行数据存储和检索。数据库的磁盘I/O操作在面对高频交易时,就像一条狭窄的瓶颈道路,严重限制了系统的处理能力。每次订单的插入、匹配和撤销操作都需要与磁盘进行交互,不仅耗时,而且在高并发场景下容易导致系统性能急剧下降。
为了突破这一瓶颈,我们将撮合引擎的核心数据结构,如订单簿(OrderBook),完全加载到内存中。内存的读写速度相较于磁盘有着数量级的提升,这使得订单的插入、匹配和撤销操作都可以在内存中快速完成。就好比将货物存储在离生产线最近的仓库,大大缩短了取货和送货的时间,极大地减少了磁盘I/O带来的延迟。
然而,内存化也带来了新的挑战,即数据的一致性和可恢复性。内存中的数据是易失的,一旦系统出现故障,数据可能会丢失。为了解决这一问题,我们结合了事件溯源(Event Sourcing)和快照(Snapshot)技术。每次撮合操作都会生成相应的事件,并记录到事件日志中。这些事件就像一部详细的"历史纪录片",记录了撮合引擎的每一个操作步骤。当系统出现故障时,可以通过重放事件日志来恢复撮合引擎的状态,就像根据历史记录重新构建出故障前的场景。
同时,定期的快照机制可以进一步加快恢复速度,减少恢复时间。快照就像是给撮合引擎的状态拍了一张"照片",保存了某一时刻的完整状态。当需要恢复时,可以直接加载最近的快照,然后重放快照之后的事件日志,大大缩短了恢复过程。这种Event Journal + Snapshot Dump的组合方式,为撮合引擎提供了可靠的故障恢复能力,确保了系统的稳定性和数据的一致性。
二、内存化仓位管理:精准与高效的仓位掌控
仓位管理是交易系统中另一个重要的环节,它直接关系到用户账户的资金安全和交易策略的执行,如同交易系统的"财务管家"。用户的仓位信息包括持仓数量、成本、盈亏等关键数据,这些数据的准确性和及时性对于用户的交易决策至关重要。
类似于内存化撮合,我们将仓位管理也进行了内存化处理。每个用户的仓位信息都存储在内存中,实现了快速的仓位查询和更新操作。当撮合引擎完成一笔订单的撮合后,会立即触发仓位的更新操作。由于数据存储在内存中,仓位的更新可以在瞬间完成,确保了用户能够实时获取到最新的仓位信息。
为了确保仓位数据的一致性,我们采用了与撮合引擎类似的事件驱动架构。仓位的任何变化都会触发相应的事件,这些事件会被记录并用于后续的恢复和审计。例如,当用户进行一笔买入操作时,仓位增加的事件会被记录下来。如果后续系统出现故障,可以通过这些事件重新构建出用户的仓位状态。
同时,通过与撮合引擎的紧密集成,仓位管理能够实时响应撮合结果。撮合引擎在完成订单撮合后,会立即将结果通知仓位管理模块,仓位管理模块根据撮合结果更新用户的仓位信息。这种实时的交互机制确保了用户仓位的准确性和及时性,为用户提供了可靠的交易保障。
三、事件化处理代理轮询和定时器:并行与灵活的任务处理
在原来的交易系统中,代理轮询和定时器任务通常采用同步或基于定时器的方式进行处理。这种方式就像一条单行道,所有的任务都按照固定的顺序依次执行。在高并发场景下,容易导致资源竞争和性能瓶颈,许多任务可能需要等待前面的任务完成才能执行,从而降低了系统的整体处理效率。
为了解决这一问题,我们引入了基于Akka的异步处理模式。Akka是一个基于Actor模型的消息传递框架,它就像一个高效的"任务调度中心",提供了高效的异步处理机制。我们将代理轮询和定时器任务封装为独立的Actor,每个Actor就像一个独立的"工人",负责处理特定的任务,如订单轮询、仓位更新等。
通过消息传递的方式进行通信和协调,不同的Actor可以并行地处理任务,充分利用系统的资源。例如,订单轮询Actor可以不断地从订单队列中获取订单,并进行相应的处理;而仓位更新Actor则可以实时响应仓位的变化事件,进行仓位信息的更新。这种并行处理的方式大大提高了系统的响应速度和处理能力。
同时,事件化处理还使得系统更加灵活。当市场行情剧烈波动时,系统可以自动调整轮询频率。例如,在行情活跃时,增加订单轮询的频率,确保订单的及时撮合;而在行情相对平稳时,适当降低轮询频率,减少系统的资源消耗。这种灵活的调整机制使得系统能够更好地适应不同的市场环境,提高了系统的适应性和稳定性。
四、基于Akka的异步处理与撮合系统数据一致性:可靠与唯一的撮合保障
撮合系统作为交易系统的核心,其数据一致性至关重要。一旦撮合过程中出现数据不一致的情况,可能会导致订单的重复撮合、仓位的错误计算等严重问题,给用户带来巨大的损失。为了确保撮合过程中的数据一致性,我们采用了EventSourcedActor作为撮合引擎的基本架构。
EventSourcedActor结合了事件溯源和Actor模型的优势,实现了撮合引擎的可故障恢复和状态一致性。每个撮合引擎都是一个独立的EventSourcedActor,它负责处理特定合约类型的订单撮合。撮合引擎的状态变化通过事件进行记录,这些事件被持久化到事件日志中。当需要恢复撮合引擎的状态时,可以通过重放事件日志来重新构建出撮合引擎的历史状态,确保了数据的一致性和可恢复性。
此外,为了确保撮合引擎在整个集群范围内的唯一性,我们采用了Singleton模式。这意味着每个合约类型的撮合引擎在整个集群中只有一个实例运行,就像每个合约类型都有一个专属的"撮合专家",避免了数据不一致和重复撮合的问题。例如,对于某个特定的股票合约,整个集群中只有一个撮合引擎负责处理该合约的订单撮合,确保了订单的唯一处理和数据的准确性。
在冗余配置的硬件上,我们部署了多个撮合引擎实例作为备用。这些备用实例就像"替补队员",随时准备接替主撮合引擎的工作。当主撮合引擎出现故障或主动退出时,备用实例可以快速启动并接替工作。通过事件日志的重放,备用实例可以迅速恢复到主撮合引擎故障前的状态,确保系统的连续性和稳定性。这种冗余配置和快速切换机制,大大提高了系统的可用性,减少了因撮合引擎故障而导致的交易中断时间。
五、总结与展望
通过内存化撮合、内存化仓位管理、事件化处理以及基于Akka的异步处理模式,我们构建了一个高性能、高可靠性的撮合引擎。该引擎不仅实现了低延迟的订单撮合和仓位管理,还确保了数据的一致性和系统的可恢复性。在实际运行中,该撮合引擎表现出了卓越的性能,能够快速、准确地处理大量的订单,为用户提供了稳定、高效的交易体验。
然而,技术的发展永无止境。未来,我们将继续优化系统架构,进一步提升系统性能。例如,我们可以探索更高效的内存管理策略,减少内存占用和提高内存访问效率;同时,也可以研究更先进的事件处理和恢复机制,提高系统的容错能力和恢复速度。此外,随着人工智能和机器学习技术的不断发展,我们还可以考虑将这些技术应用到撮合引擎中,实现智能化的订单撮合和风险管理,为交易用户提供更加个性化、智能化的交易服务。