本篇为KMP 技术与实践系列文章的第四篇。在这篇技术文章我们会聚焦于如何在 iOS 平台上把 Kotlin/Native 的研发体验提升到一等公民(追平及超越 Apple 官方提供的基于 ObjC & Swift 的研发范式)
Make the iOS target a pleasure to work with
提升iOS目标开发的愉悦感,是KMP 2025 官方路线图(blog.jetbrains.com/kotlin/2025... )中明确提出的核心优先级的第一位,而能排到第一位自然的原因就是现在非常的"不愉悦"。作为重度结合了KMP技术作为日常研发一步的我们自然也同样把这个问题是提到第一优先级的。
让我们先定义一个愉悦的定义:最短的"改一行 → 看到结果"的内环反馈。
图示(编码→编译/运行→调试 的最小闭环):

三大朴素诉求:
-
Coding:输入低延迟、智能补全与误用即报;ObjC/Swift/C/Kotlin 边界可导航、可重构。
-
Build System:增量优先、远程缓存与分布式编译最大化命中;构建确定可复现。
-
Debugging:符号完备、断点稳定、路径一致;Attach/热重启快速可靠。
KMP官方生态的现状:
-
Coding: 虽然Xcode在自家的ObjC/Swift上做的也并不好,即使Kotlin-Native在IDEA体系上有了比较好的Coding体验支持,但我们依然需要照顾大多数在Xcode上研发的同学。而不能像官方推荐的黑盒交付的方式,仅仅使用xcodebuild作为一个容器。无论从出度上的编译调试、还是入度上的调试器的信息返回的回环都是不那么自然的。
-
Build System: KMP 官方生态的编译系统(Kotlin Gradle Plugin)是基于 Gradle 的,而 Gradle 虽然是一个语言无关的编译系统,但是在 iOS 生态的普及程度几乎为零,同时即使不考虑普及程度,KGP 的增量编译速度、稳定性和可预测可重放都不理想。我们对构建系统的预期为Never clean build ,表现在我们包括生产环境的发布也都是基于增量编译,然而基于KGP的增量缓存等策略连本地的正确性都无法得到保证,离我们的 Never clean build 的诉求还有很大差距。
-
Debugging: 基于Xcode体系的例如Instruments是苹果生态上最强最好用的部分,但是官方的KGP生态由于自身和xcodeproj体系的脱离,需要依靠第三方插件xcode-kotlin来桥接两套生态,即使我们不考虑 Xcode 的插件使用复杂,类似「Debug的符号的source-map的映射」,「konan.lldb.py的版本关系映射」都使得Debugging体验大打折扣。
是什么造成了这个现状?
笔者认为KMP生态已经竭尽所能的去适配iOS的生态了 。更现实的是,社区在实践中形成了多条并行且彼此割裂的工程化路径(CocoaPods、SPM、Tuist、CMake、原生 .xcodeproj 等),缺乏一个统一、声明式、可复现的标准。不同工具链在依赖解析、可见性、缓存/分布式编译、调试符号与后处理上的行为各异,KMP 很难对所有路径都深度适配并保持一致体验。因此,我们看到诸如「基于 Build Phase 的脚本注入」「SPM 集成」「CocoaPods 集成」「基于 xcodeproj 的环境注入」等,都是尽力适配但难以覆盖全貌的尝试。
我们的目标?
- Coding:
- 在Xcode上让Kotlin-Native生态达到和Swift/ObjC达到同等的read的体验。
- 在IDEA、VSCode让Kotlin-Native达到IDEA一贯的read & write体验。
- Build System:
- 由于 xcodeproj 本身的局限性,无法满足我们对可重放以及增量编译的诉求,所以我们已经全量采取了 Bazel 作为编译系统。自然的我们也需要让KMP生态在 Bazel 上工作就能达到相同的体验。
- 为了充分发挥 Bazel 在高并发、增量/分布式构建方面的优势,需要提升 Kotlin-Native 的并发编译能力。
- Debugging:
- 在 Xcode 和 VSCode 中,实现 Kotlin-Native 与 Swift/ObjC 同等水平的调试体验。
拆解Kotlin-Native
架构全貌图以及问题点标记为😈的是严重问题:
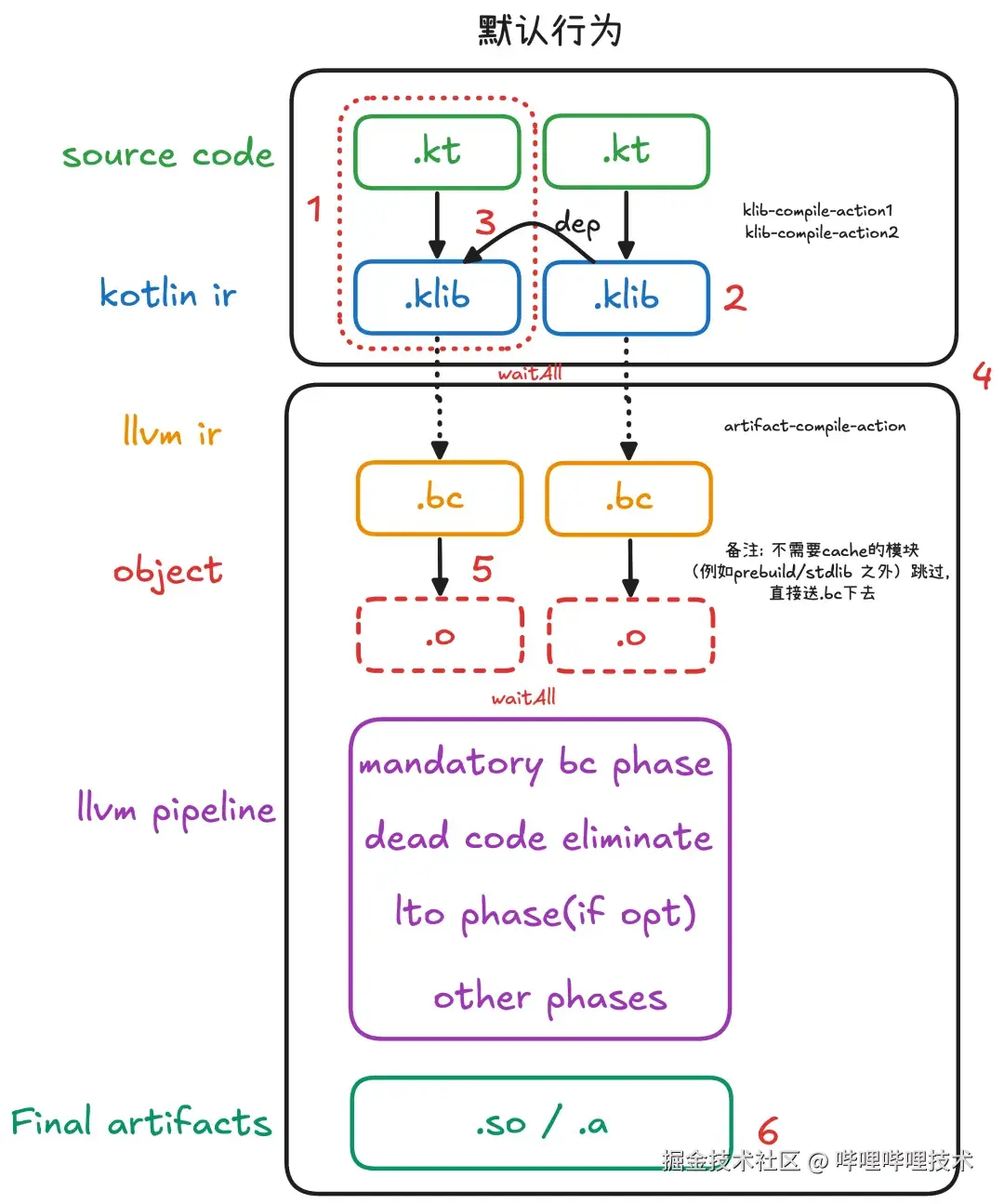
- Issue 1: Kotlin-Native 并没有提供Kotlin模块级别的接入 😈
- Kotlin 的模块只到 .klib,并没有为其他语言(.h / .module / ...)提供模块级接入的可能性
- Kotlin 默认只提供批量的Kotlin 模块集合作为 shared library 被其他语言调用的能力
- Issue 2: 以二进制分发的 Kotlin-Native 产物无法在 lldb 中还原调试断点
- Kotlin-Native的编译产物 .klib 不仅在通过中心化仓库(maven)下载的产物也在非本机(分布式/缓存)场景下无法稳定还原 source map,路径不一致影响调试符号与断点
- Issue 3: 模块(klib)之间的私有依赖(implementation_deps)能力缺失 😈
- 虽然在 KGP 中依然保留的 implementation 这个配置,但是事实上所有的依赖都是基于api的方式递归穿透的
- 这个导致了非常严重的增量编译的效率问题,要求工程从工程角度设计做好编译防火墙(接口实现分离,面向接口编程)对于现在的"高度迭代效率"的时代背景下是不现实的。
- 放着高等级语言特性的例如 visibility 能力不用而是使用模块拆分的方式来实现编译防火墙,导致研发心智模型割裂。
- Issue 4: Kotlin IR 阶段与 Final Artifact 阶段割裂,重复/过度的正确性检查影响编译时长
- 由于 Kotlin IR 的编译与 Final Artifact 是多个不同的 Action/Task 考虑到鲁棒性在 Final Compiler 上做了非常多的正确性检查,导致编译时长增加
- Issue 5: IR → Object 聚合在最终链接阶段,导致并发度低下 😈
- 传统的心智是,高并发度编译,一个 long time 的链接。然而Kotlin-Native的高并发度编译仅仅只做了 kotlin-ir 的编译。
- 更长时间的 Kotlin-IR => Object 的编译全部聚合在了最后的 long time 的链接,而经过我们的实践可能这一步的研发的忍耐程度也就是一分钟,而在 konanc 上这一步极限情况可以达到几十分钟。
- 由于我们使用了 Bazel 的高并发度编译,结合第 6 点我们根本无法实现高并发,因为大多数 Task 都在 waiting 一个"悠悠哉哉"低效使用 CPU 时间的 konanc Final Compiler 之上。
- Issue 6: Kotlin 的语言能力远超 ObjC,对溢出能力(重载、命名空间等)的处理过于粗暴,易产生冲突 😈
-
Naming clashes (Multi-module support/Package support/Flattened package structure): 包层级合并到同一模块名,易与现有 Swift/ObjC 符号冲突。
-
Overloads(): fun foo(Int)/fun foo(String) 在 ObjC/Swift 扁平化后产生命名冲突或不稳定前缀。
我们的优化
优化后的架构全貌图:
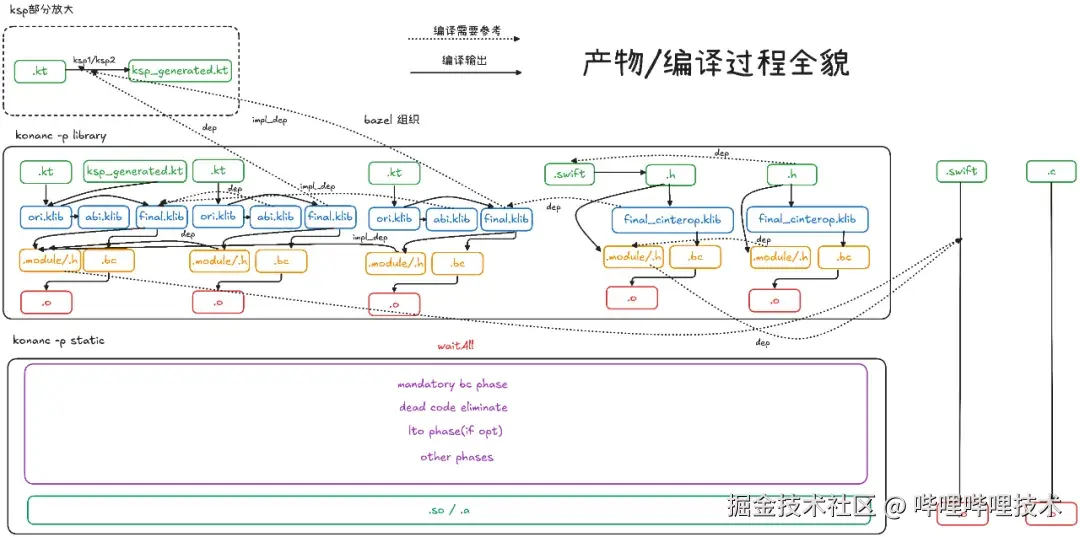
乍看像对原来的架构有点恐怖,我们拆分来看:
- ori.klib 原始基于 konanc -p library 编译出的产物
- abi.klib 以 ori.klib 为基础,去除所有 kotlin.ir ,只保留元数据(FIR / metadata)产物,用作编译参考依赖
- 通过 kotlinx.metadata.klib.KlibModuleMetadata 解析 klib 中的声明,并剔除所有非 public 符号
- ⚠️ Kotlin 2.1.20 存在问题 KT-78015(*youtrack.jetbrains.com/issue/KT-78...
- final.klib 以 ori.klib 修复 kotlin.ir 中的 fileEntries 以便 LLVM 后正确还原 source map
- 在 < 2.2 的版本中没有 fileEntries 结构,需要在编译时通过 -Xdebug-prefix-map={ROOT}=. 修复路径
- final_cinterop.klib 通过 bazel.headerInfo 调用 cinterop 生成,对应依赖基于 CcInfo 还原
- .module/.h 基于 ori.klib 及其依赖通过 konanc -p framework -Xomit-framework-binary 生成 Clang module ,并通过 Bazel CcInfo 还原 CompilationContext(*bazel.build/rules/lib/b...
- ksp_generated.kt 通过 ksp1 (embed Kotlin compiler)或 ksp2 依赖对应模块 ori.klib 进行代码生成
- ⚠️ 不能使用 abi.klib ,因为 KSP 需要感知 private 等非 ABI 部分
- implementation_deps 切断依赖向上传播链
- .o 通过 konanc -p static_cache 为每个独立 kt 模块静态编译,显著增加并发度
基于此,我们解决了默认的架构全貌中的前三个最重要的问题(ISSUE 1-3):
- 通过双向机制解决了Kotlin无法提供模块级别的互操作的限制。
- Kotlin 供外部调用(Export): 独立编译生成每个 Kotlin 模块的 Clang module 和相应的Bazel CompilationContext (基于C/ObjC),使得 Swift、ObjC、Zig 等可调用C语言的模块能直接调用Kotlin模块。
- Kotlin 调用外部(Import): 利用 Bazel 提供的 headerInfo 结合 Kotlin Native cinterop 工具,为任何提供 CcInfo 的Bazel Target(如 cc_library、swift_library、objc_library等)自动生成 Kotlin 绑定 (binding),实现对外部语言模块的调用。
- 默认的klib无法还原分布式编译/缓存后的source-map信息。
- 通过清洗 fileEntries(默认为绝对路径),将源文件信息转换为当前 Bazel workspace 的相对路径
- 具体方式为,通过KotlinIr.proto反序列化default/ir/fileEntries.knf 清洗掉name字段的绝对路径,保留path字段的相对路径。
- 模块之间的私有依赖(implementation_deps)能力缺失。
-
我们通过在 BUILD.bazel 中分离 deps 与 implementation_deps 属性,实现模块私有依赖,切断不必要的传播链。
-
不像 KGP 中设计的那么粗粒度的任务维度,由于我们自己设计管理了任务的粒度和依赖关系,使得私有依赖的实现可以精准切入需要加速的部分,从而使得实现成为可能。
makefile
KlibInfo = provider(
fields = {
# Kotlin source 模块则输出当前的 final.klib
# C Family 模块则输出当前的 final_cinterop.klib
"klibs": "The output klibs",
# 当前隔绝 api 传播依赖穿透后的 final.klibs,提供 static_cache / KSP 编译使用
"transitive_compile_klibs": "The transitive compile klibs.",
# 当前隔绝 api 传播依赖穿透后的 abi.klibs,提供 kotlin.ir 编译使用
"transitive_compile_interface_klibs": "The transitive compile interface klibs.",
# 当前递归穿透传播依赖后的 final.klibs,提供最终链接使用
"transitive_klibs": "The transitive klibs (All transitive klibs)",
# 当前递归穿透传播依赖后的 abi.klibs, 提供 clang module compiler等场景使用
"transitive_interface_klibs": "The dependencies for compile klibs(interface klib if we enable abi klibs) (attr: deps + implementation_deps)",
},
)为什么 KGP(Gradle Kotlin Plugin) 不支持 implementation_deps?
个人理解:
- 在多类型 konanc 的编译语境下有的是需要完整的依赖Tree的,例如LLVM Object 优化,例如kotlin-ir => .o
- 在ksp情况下完整依赖树也是必要的,例如getSymbolsFromPackage等API。
- 在Final Target Compiler下,完整的依赖结构也是必要的。
既然都那么复杂,使用Case又各不同,那么最保险的永远提供完整的依赖子树,提供每个编译单元的上下文就是最安全的做法。
Parallel Compilation (ISSUE 4-5):
- 我们对这个问题的解决方案称为Parallel Compilation ,即在编译时对每个kt_library模块进行独立的编译,编译对应的.a文件。
- 在说明Parallel Compilation之前我们需要先了解一下Kotlin/Native Compiler自身的几种Cache类型以及他默认的增量相关的配置
- Cache类型
- stdlib
- platform cinterop klibs
- external klibs
- user klibs (include cinterop)
- CLI默认行为(不带任何参数)
- stdlib 会缓存至 {KONAN_HOME}/klib/cache/{TARGET_VARIANT}-{IS_ DEBUG?g:""}STATIC-system/stdlib-cache
- platform cinterop klibs 当他的unique name被依赖者使用到时会缓存至 stdlib cache的同级目录中
- external klibs & user klibs 会一视同仁,没有Cache机制,直接以llvm.bc的方式从kotlin.ir转换后一同送给Linker进行后处理以及链接。
- -Xauto-cache-from (KGP 默认开启)
- KGP会默认设置-Xauto-cache-from=${getGradleUserHome()}
- -Xauto-cache-from会用来区分external klibs 以及 user klibs(即如果klibs的目录在-Xauto-cache-from目录下则视为external klibs,否则视为user klibs)
- external klibs 会被缓存至{KONAN_HOME}/klib/cache/{TARGET_VARIANT}-{IS_DEBUG?g:""}STATIC-user/{UNIQUE_NAME}-cache/
- -Xauto-cache-dir用来指定把external klibs的位置从/klib/cache/`改为其他目录
- -Xenable-incremental-compilation (KGP 默认关闭)
- 上述提到的cache都是库级别的缓存,而-Xenable-incremental-compilation会使用缓存颗粒度变成文件级别的缓存。
- -Xic-cache-dir=用来指定-Xenable-incremental-compilation的缓存目录,必须与-Xenable-incremental-compilation一起使用。
- -Xmake-per-file-cache目前主要在Cache目录上有区分,即使不指定-Xenable-incremental-compilation也会开启文件级别的缓存。
- -Xcache-directory=
-
手动指定某个UNIQUE_NAME的KLIB的缓存目录
-
⚠️-Xcache-directory= 指定缓存的KLIB必须要求他的子依赖也全部在Cache中,Kotlin Compiler自身不会在对例如stdlib platform cinterop klibs进行缓存编译。
-
Parallel Compilation前我们的方案
-
类似KMP默认模板的一个超大Shared Library并不适合大多数的工程化场景,尤其是在由monorepo组织的比如我们的工程中。经过一些简单Profile除了模版中一个超大的Shared Library的场景之外,文件粒度的缓存都是负优化。
-
由于我们的模块是高度Interface(接口)和Implementation(实现)分离的,所以相对于默认只把external klibs进行缓存,我们目前会把无论是external klibs还是user klibs都进行缓存。
-
Parallel Compilation前我们的问题
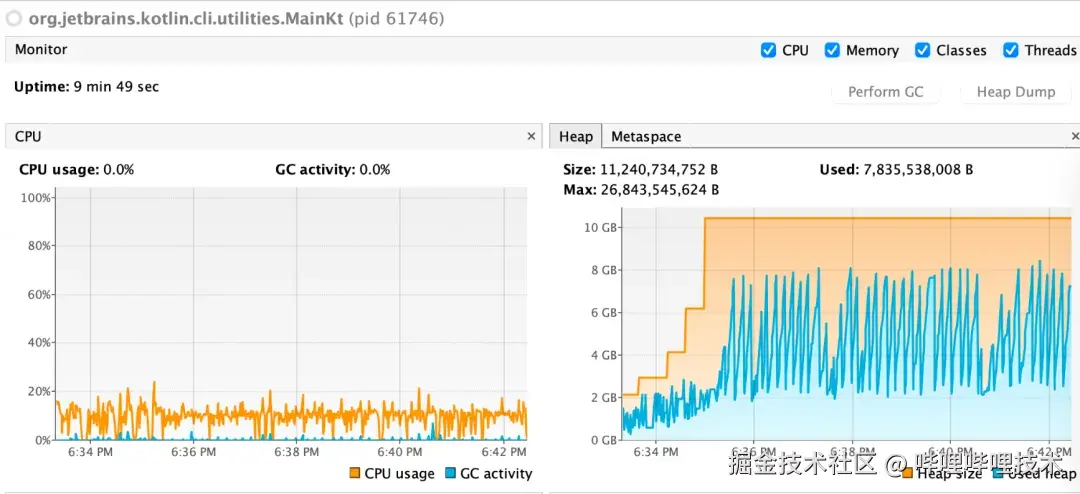
- 慢!并发度太低。 Kotlin/Native Compiler 的编译阶段 Lowering 中 CPU 长期低负载。
-
我们可以看到在编译过程中 CPU 长期处于低负载。
-
同时全局 Profile 可见其成为耗时极长的 Critical Path,阻塞其他并发。(也可以反映出第一点中提到的CPU负载过低)
- 不可靠Cache
-
整个Cache体系的目录对Bazel而言是SideEffects也就是不可见的,我们没法通过Bazel自身的remote cache机制来进行编译加速。而研发自身的Cache目录的稳定性堪忧。即使我们已经尽量把缓存目录固定到了bazel output_base中,依然会出现大量的Cache Miss近乎全局的Cache Miss。
-
Parallel Compilation
- 方案
- 朴素到极致的并发,为每个kt_library模块的.klib产物独立通过konanc -p static_cache编译成.a文件。
- 并通过 -Xcache-directory= 为 Final Artifact Compiler 提供对于UNIQUE_NAME的.klib的object位置。
- 让Final Artifact Compiler彻底退化成一个最简单的LLVM Linker ,而他的唯一工作就是链接。
- 对于通过Include a static library的内置embed的产物,例如skiko.klib之类的我们需要把内置的.a抽出来通过LinkingContext传递给顶层Binary进行链接。
- Build performance
·方法与基线
· Clean Build:本地冷启动(首次无本地/远程缓存/清理掉所有的AnalysisCache),禁用远程缓存;
· Incremental Build:本地Bazel守护进程启用;远程缓存开启仅用于不变外部依赖;
· Kotlin/Native 版本:2.2.0;iOS 工具链:Apple clang(Xcode 16.4);Harmony 工具链:OHOS clang(5.0.9.300)。
· 我们选取了我们目前生产环境的代码进行测试(涉及了367个Kotlin-Native模块),Apple M3 8核心进行测试。
· iOS: 采取对比前序提到的Parallel Compilation前我们的方案
· Harmony: 采取对比前序提到的CLI默认行为
· iOS Clean Build:
· 数据结论:
-
Clean build 下从原来的 1959s(32.6 分钟)降到 1865s(31.1 分钟),降幅约 5%
-
Final Artifacts 编译时间从 590.7s(9.8 分钟)降到 12.6s(0.2 分钟),降幅约 98%
-
获得了环境无关的Cache能力,在CI基于稳定增量的情况下,稳定小于30s
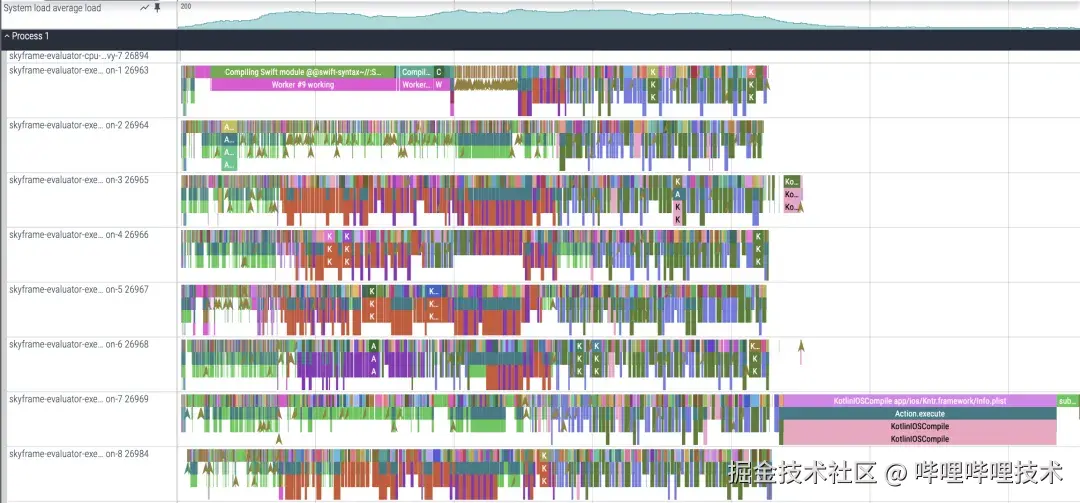
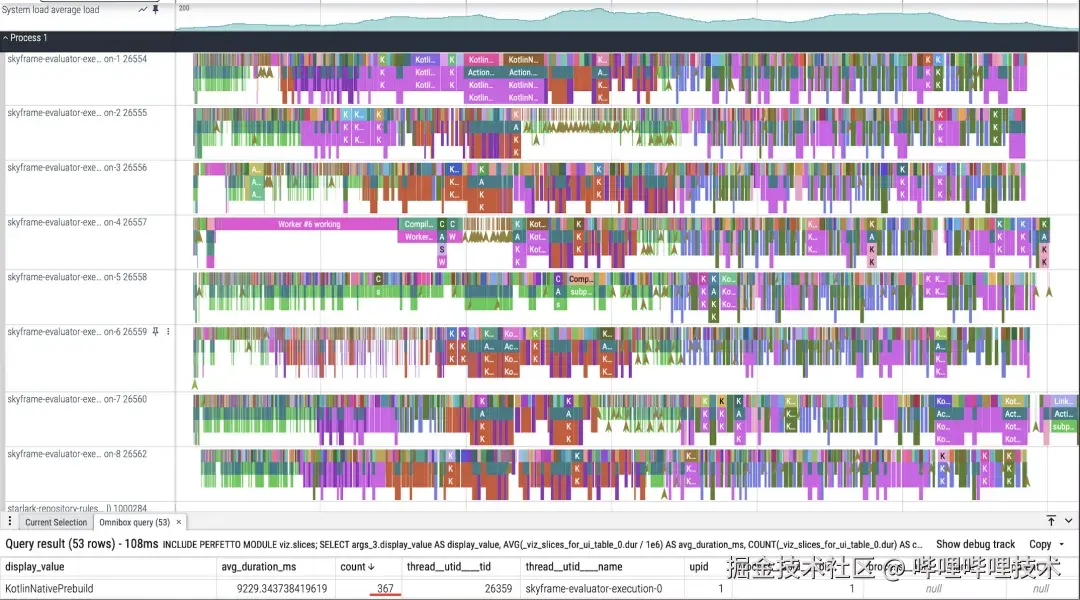
· iOS Incremental Build:
· 数据结论:
-
我们在上层穿透较小的业务模块上可以达到一半的增量编译速度的提升,从研发体感上从分钟级进入到了秒级 ,是一个体感上的飞跃。
-
我们在下层穿透巨大的例如日志模块的实现变更上有接近40倍的速度提升,这对基础架构的迭代是一个巨大的提升。
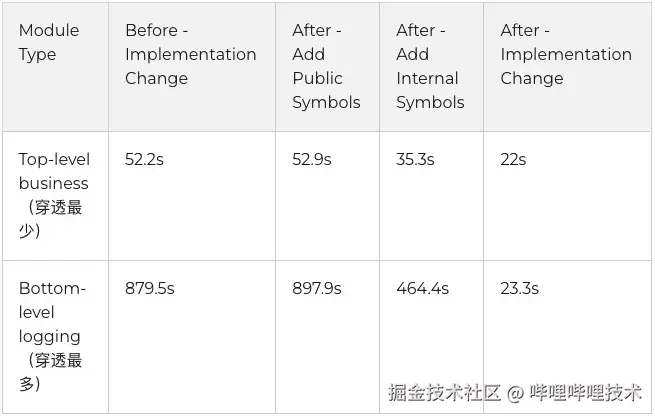
· Harmony Incremental Build: 说明:同 Kotlin/Native 2.2.0,对照组为 CLI 默认行为;工具链差异仅在目标平台(Apple clang vs OHOS clang)。
· 数据结论:
- 在HarmonyOS上相对于iOS,我们的对照组没有经过任何优化,就是默认的CLI默认行为,我们可以看到特别是在顶层业务层面,我们从一个不可用的状态变成了一 个还不错的状态。
Kotlin Module Level Export(ISSUE 6):
正如上文提到的,Kotlin-Native的模版也就是导出一个超大聚合Library在我们这样的monorepo的场景下是完全无法工作的。而且个个都是工程化灾难无法忍受的😈级问题
- 😈 巨大的Module export的头文件。实验性地把我们项目当前的public header进行全部导出,有将近200k行的头文件。无论是IDE(Xcode/VSCode)还是研发的阅读都是有巨大障碍的。
- 😈 聚合导出也就意味着要写配置文件,而在monorepo下模块例如Kotlin的组装是自由的,根据不同的App类型、UITest类型、编译类型都是不同的,我们无法去前置为每一个Target去组装(配置)一套产物。我们希望他通过默认的Bazel的deps树自组装。
- 😈 Kotlin的语意是远强于ObjC的,前文提到的特别是Overloads的问题,会严重破坏ABI稳定,导致项目出现非常严重的不可预期的错误。
- 我们项目中的较先改造KMP的模块甚至占用了最常用最短的几乎所有的namespace无论对先来者还是后来者都是工程化的灾难。
-
😈 任何导致ABI变更,也就是头文件变更的Kotlin模块的改动都会导致任何依赖任意Kotlin模块的ObjC/C模块的重编。
-
😈 任何Kotlin模块的改动,哪怕是修改一个实现,由于Swift自身对外部依赖分析(PCM)的过于粗暴,都会导致任何依赖任意Kotlin模块的Swift模块,以及传播整个依赖树进行重编。
-
考虑到并发度问题,我们不可能让上层例如Swift/ObjC的模块wait一个Kotlin Final Compiler的编译结果。这样相当于凭空造出了一个新的Critical Path ,导致了上层的编译并发速度大幅度下降。
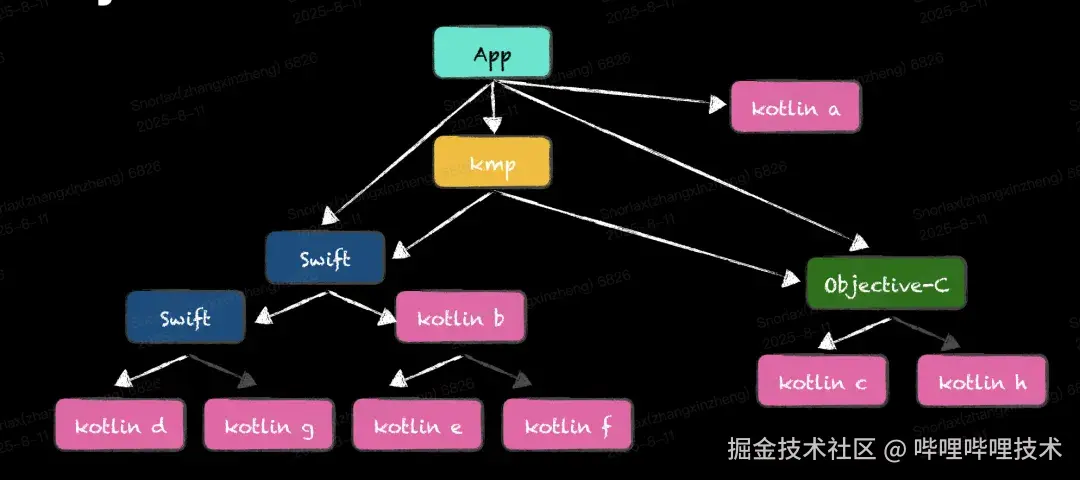
- 拆分Compilation以及LinkingContext
- 既然链接(也就是Kotlin Final Compiler)是不可少的,那么很自然的解决方案就是拆分编译以及链接上下文。我们让Final Compiler只被最终的App Linker所依赖就可以让他高效的并发。
- 而CompilationContext,那么在C体系最自然的就是拆分为一个个独立的clang module ,我们只需要依赖clang module即可做到全项目级别的高效并发编译。
- CompilationContext
- 对于 CompilationContext 的拆分只需为所有被 ObjC / Swift / C 依赖的 Kotlin 模块提供 CcInfo 。方式即 konanc -p framework -Xomit-framework-binary。
- 对于 stdlib 依赖,需要为 kotlin.stdlib 以及平台 cinterop klib 提供对应 CompilationContext。实质上 iOS 上也就是 -framework UIKit -framework Foundation 这类依赖;binding 由 Kotlin/Native compiler 自身的 cinterop.def 生成.
- Naming clashes
- 这里非常感谢支付宝团队的分享,基于 -Xbinary=objcExportEntryPointsPath 实现注解标记 @ObjCExport ,替换原来"全部 public 默认导出"。
- 在显式大幅缩小导出范围后,同时开启 -Xbinary=objcExportReportNameCollisions=true 严格报冲突,解决命名冲突的问题。
- 工程化
-
我们借助了 deps/implementation_deps 的语意来描述模块之间的依赖导出关系,并自动分析出了LinkingContext具体的大小范围。
-
仅仅导出被c family直接可见的kotlin模块,避免了递归依赖穿透。
-
对于kotlin模块的递归依赖,我们只需导出api依赖的导出部分,避免过大的kotlin模块的无效导出。
-
隐藏链接上下文,即图中的黄色部分,对于研发而言kotlin模块与c family模块的依赖和调用关系是完全透明的。0胶水交互的配置及代码。
总结
我们最初的目标是,在 iOS 平台上将 KMP 的研发体验提升至"一等公民"水准,即追平乃至超越苹果官方的 Swift 开发范式。通过对 Kotlin/Native 编译管线的深度拆解与重构,我们系统性地解决了其在模块化、编译并发和增量构建方面的核心瓶颈,成功达成了这一目标。
-
在构建系统与编译速度上 : 我们实现了 Parallel Compilation ,将每个 Kotlin 模块独立编译为 .a 文件,在一些日常的底层修改的场景下最终产物编译耗时锐减 98% 。这不仅充分释放了 Bazel 的高并发优势,更让"改一行代码、秒级看到结果"的内环反馈成为现实,又由于引入了可靠的remote cache机制兑现了我们对 Never clean build 的预期。
-
在编码与跨语言交互上 : 我们告别了 KMP 默认的"大一统"框架模式。通过为每个 Kotlin 模块生成独立的 Clang module ,并以 @ObjCExport 注解精确控制导出,我们实现了真正的模块化。这为 Xcode 提供了与原生 Swift/ObjC 无异的模块化 read 体验,也为 IDEA 带来了清晰、可控的跨语言 write 体验。
-
在调试与工程化上 : 通过修复 source-map 路径和实现可靠的 implementation_deps ,我们保证了跨语言调试的稳定性和构建的确定性,解决了社区方案中的常见痛点。

综上所述,即使不考虑跨平台的收益,仅在 iOS 端,一套深度工程化的 KMP 方案也足以构建出比原生更高效、更稳定的研发体系。
未来展望
我们的探索不止于此。为了最终实现"在任何平台都提供超越原生的研发体验"的愿景,我们规划了以下三个方向的演进路径:
1. 近期目标:打造无缝的统一开发环境
当前的首要任务是彻底消除 IDE 间的壁垒,实现真正的"单一 IDE 工作流"。
- 统一 IDE:
- VSCode 方案: 借助官方 Kotlin LSP,为其开发基于 Bazel 的扩展,实现精准的依赖分析与代码导航。
- IDEA 方案: 深入集成 sourcekit-lsp ,让 IDEA 具备对 Swift 的一流支持,补全跨语言开发的最后一块拼图。
- 深化 Swift 交互: 将我们自研的 @ObjCExport 方案的后端无缝切换至官方的 Swift Direct Export ,在享受更优性能与类型映射的同时,利用 Swift 自身的符号剥离能力,进一步降低开发者的心智负担。
2. 中期目标:追求极致的内环开发效率
在打通环境的基础上,我们将致力于将"改动到反馈"的时间压缩到极致。
- 探索 Hot Reload: 借鉴 Flutter、Kotlin/JS 的热重载机制,或类似游戏引擎的 Preview 模式,探索在 Kotlin/Native 上实现状态保持的热重载或快速预览能力,带来颠覆性的调试体验。
- 完善研发诊断生态:
-
将 UI/单元测试的执行与覆盖率统计全面融入 Bazel。
-
为 Compose for iOS 引入静态诊断和 Layout Inspector,提供完整的 UI 开发工具链。
3. 长期愿景:反哺社区与引领生态
一些建议
-
社区内的主流的跨平台框架都基本采取了黑盒的方式来进行交付,虽然Kotlin Multiplatform在往白盒化原生化的方向走到了很前的位置,但在默认的Kotlin Gradle Plugin生态下笔者认为类似腾讯开源的 KuiklyUI(*github.com/Tencent-TDS...
-
另一种基于KMP/CMP比较好的实践方式就是尽量纯Kotlin化,放大KMP自身作为一个很好的胶水层的能力。减少与其他语言的交互层。
-
如果需要在超大复杂规模的项目上使用KMP,类似我们这样通过类似Bazel这样的构建系统,自定义化管线来优化目前看上去还是必要的。
我们希望基于KMP的技术,在不考虑跨端的前提下依然可以在每个端领域的开发体验都超过平台原生,这也是我们在KMP生态上持续投入建设的重要原因。 以上 Profile 分析优化基于 Kotlin 2.2.0,未来会持续关注并尝试 upstream Kotlin/Native 的迭代与优化。
延伸阅读
-
Google Testing Blog(工程质量与调试稳定性的长期实践):testing.googleblog.com/
-
Bazel 文档:Remote Caching:bazel.build/remote/cach...
-
Google Cloud Remote Build Execution:cloud.google.com/remote-buil...
-
Android 官方文档:Optimize your build speed:developer.android.com/build/optim...
-
Kotlin/Native 官方文档(编译管线与缓存):kotlinlang.org/docs/native...
-
Kotlin Multiplatform Swift Export 指南:kotlinlang.org/docs/swift-...
-
Kotlin/Native C Interop 指南:kotlinlang.org/docs/native...
-
KSP 官方文档:kotlinlang.org/docs/ksp-ov...
-
rules_kotlin 仓库(Bazel 集成):github.com/bazelbuild/...
-
rules_swift 仓库:github.com/bazelbuild/...
-
Apple: Swift Library Evolution:www.swift.org/blog/librar...
-
Apple: Swift Dependency Analysis:github.com/swiftlang/s...
-End-
作者丨Snorlax