github地址
网页btc预测demo使用的Kronos-mini模型
huggingface的仓库
文章目录
配置环境
使用conda的环境.
首先进行换源(太久没用发现原来的源挂了)
bash
conda config --show-sources当前源
bash
==> C:\Users\maten\.condarc <==
channel_priority: strict
channels:
- https://mirrors.aliyun.com/anaconda/cloud/bioconda/
- https://mirrors.aliyun.com/anaconda/cloud/msys2/
- https://mirrors.aliyun.com/anaconda/cloud/conda-forge/
- https://mirrors.aliyun.com/anaconda/pkgs/free/
- https://mirrors.aliyun.com/anaconda/pkgs/main/
- defaults
show_channel_urls: True打开Windows: C:\Users<你的用户名>.condarc
修改为下面的源
bash
channels:
- defaults
show_channel_urls: true
default_channels:
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/r
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/msys2
custom_channels:
conda-forge: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
msys2: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
bioconda: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
menpo: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
pytorch: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
simpleitk: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud安装python环境
文章推荐3.10+的版本
bash
conda create -n kronos python=3.10激活对应环境。
bash
(base) C:\Users\maten> conda activate kronos
(kronos) C:\Users\maten>requirement.txt如下,torch没有设置版本,默认下载可能是cpu版本,默认调用模型,应该无所谓。
bash
numpy
pandas
torch
einops==0.8.1
huggingface_hub==0.33.1
matplotlib==3.9.3
pandas==2.2.2
tqdm==4.67.1
safetensors==0.6.2在这个地方下载仓库的代码。
bash
https://github.com/shiyu-coder/Kronos/tree/master在此处配置需要的pytorchgpu的版本。
pytorch的官网
bash
pip3 install torch torchvision --index-url https://download.pytorch.org/whl/cu128
bash
cd G:\Kronos-master\Kronos-master
g:
pip install -r requirement.txt使用vscode或者trae,用python environments插件


获取市场数据的库
bash
#以加密货币为例
pip install ccxt #多交易所
pip install python-binance #仅支持币安通过webui使用
在命令行中打开的
通过python脚本来启动。
bash
conda activate kronos
cd webui
python run.py会要求下载网页端需要使用的flask。
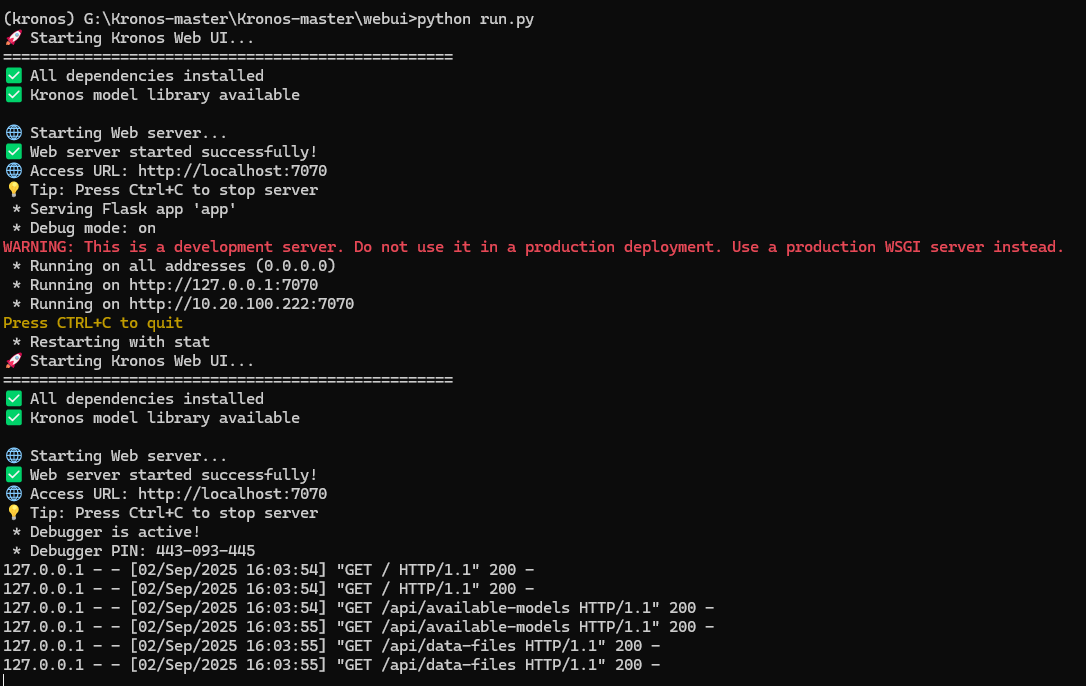
执行会打开这个页面。
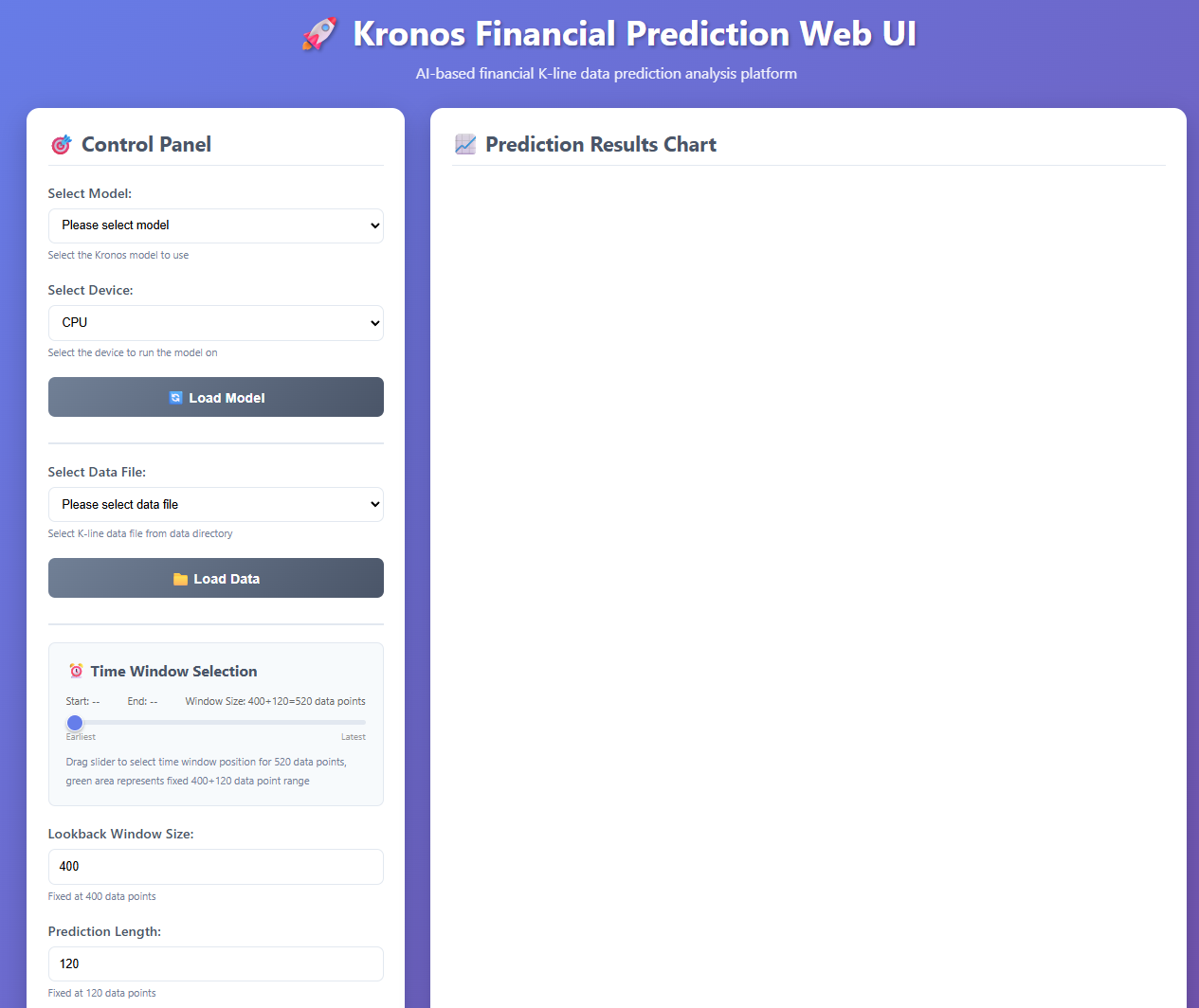
可以选择模型,在加载数据的时候,需要在项目的根目录下创建一个data文件夹,并将所使用的数据(csv格式的)放在这个里面,才能访问到。
这都是固定值,网页设置了无法修改,代码中应该可以修改。
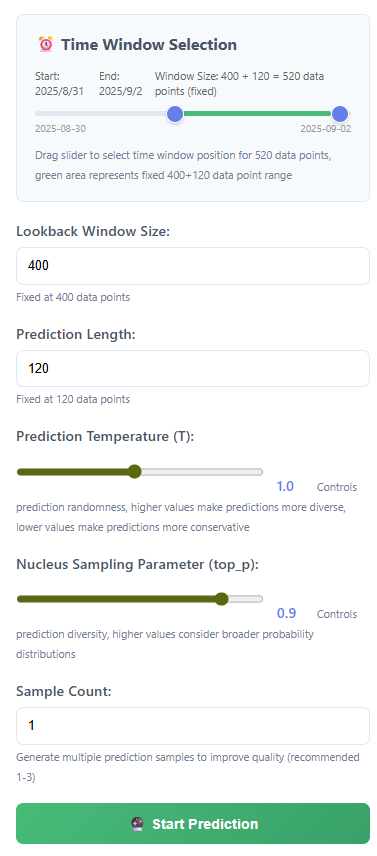
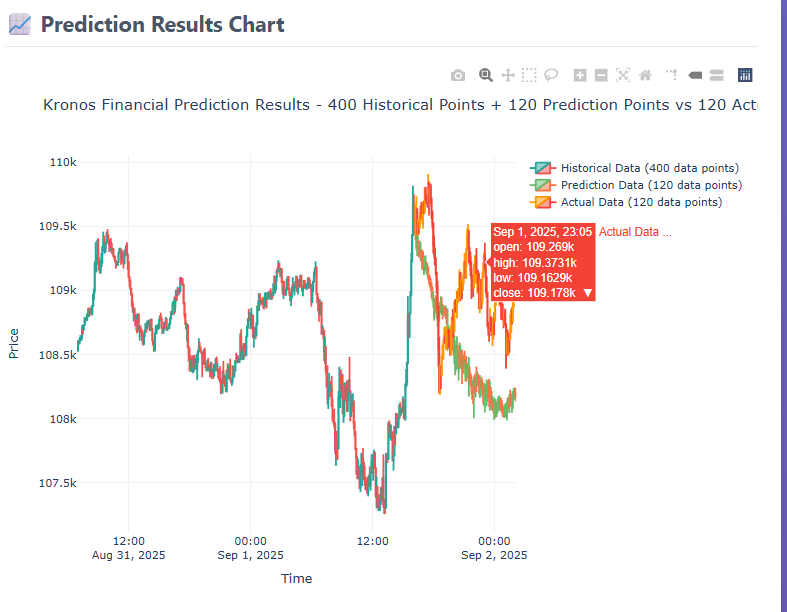
sample设置的多,应该会增强这个细节,但是耗时也会增加很多。
真实的准确性,有待进一步探索。
example中的例子
此函数进行预测
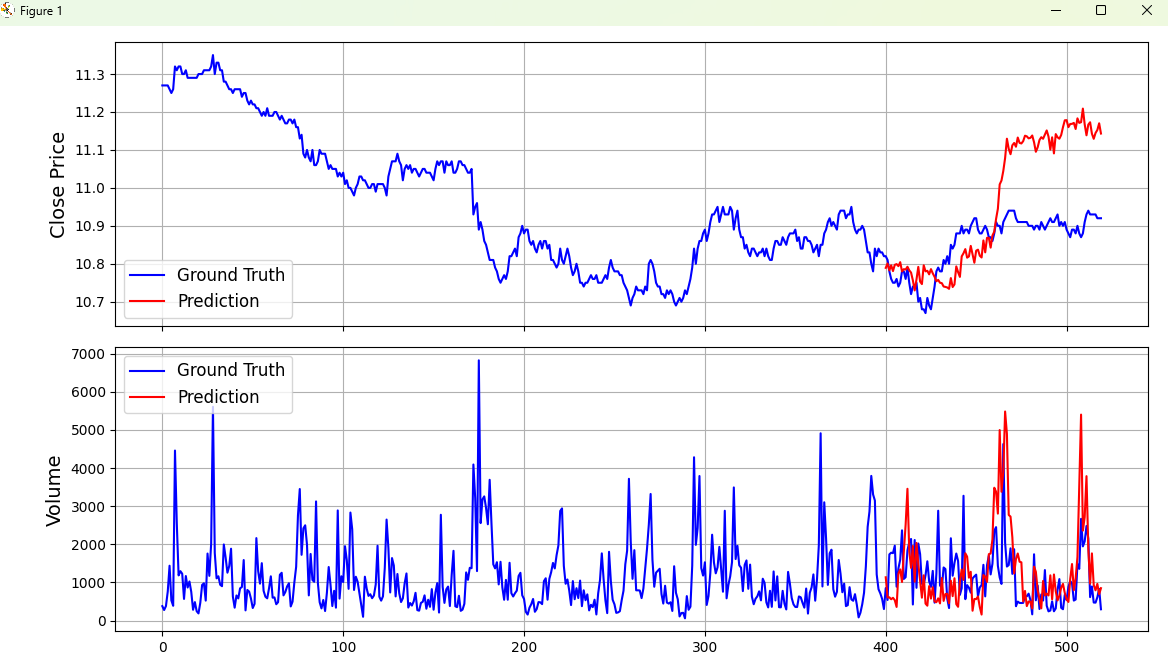
prediction_example.py
python
# 导入必要的库
import pandas as pd # 用于数据处理和分析
import matplotlib.pyplot as plt # 用于数据可视化
import os
print(os.getcwd())
# 添加这个,可以确定当前执行文件夹是那个,如果为项目文件夹,可自行修改下面添加的目录。"./"
import sys
# 添加上级目录到Python路径,以便导入model模块
sys.path.append("../")
from model import Kronos, KronosTokenizer, KronosPredictor
def plot_prediction(kline_df, pred_df):
"""
绘制预测结果对比图
参数:
kline_df: 包含历史数据的DataFrame
pred_df: 包含预测数据的DataFrame
"""
# 将预测数据的索引设置为与历史数据的最后部分对齐
pred_df.index = kline_df.index[-pred_df.shape[0]:]
# 提取收盘价数据
sr_close = kline_df['close'] # 历史收盘价
sr_pred_close = pred_df['close'] # 预测收盘价
sr_close.name = 'Ground Truth' # 真实值标签
sr_pred_close.name = "Prediction" # 预测值标签
# 提取成交量数据
sr_volume = kline_df['volume'] # 历史成交量
sr_pred_volume = pred_df['volume'] # 预测成交量
sr_volume.name = 'Ground Truth' # 真实值标签
sr_pred_volume.name = "Prediction" # 预测值标签
# 合并数据用于绘图
close_df = pd.concat([sr_close, sr_pred_close], axis=1) # 合并收盘价数据
volume_df = pd.concat([sr_volume, sr_pred_volume], axis=1) # 合并成交量数据
# 创建包含两个子图的图形:上图显示价格,下图显示成交量
fig, (ax1, ax2) = plt.subplots(2, 1, figsize=(8, 6), sharex=True)
# 绘制收盘价对比图(上图)
ax1.plot(close_df['Ground Truth'], label='Ground Truth', color='blue', linewidth=1.5)
ax1.plot(close_df['Prediction'], label='Prediction', color='red', linewidth=1.5)
ax1.set_ylabel('Close Price', fontsize=14) # 设置Y轴标签
ax1.legend(loc='lower left', fontsize=12) # 添加图例
ax1.grid(True) # 显示网格
# 绘制成交量对比图(下图)
ax2.plot(volume_df['Ground Truth'], label='Ground Truth', color='blue', linewidth=1.5)
ax2.plot(volume_df['Prediction'], label='Prediction', color='red', linewidth=1.5)
ax2.set_ylabel('Volume', fontsize=14) # 设置Y轴标签
ax2.legend(loc='upper left', fontsize=12) # 添加图例
ax2.grid(True) # 显示网格
plt.tight_layout() # 自动调整子图间距
plt.show() # 显示图形
# ==================== Kronos金融时间序列预测示例 ====================
# 1. 加载模型和分词器
print("正在加载Kronos模型和分词器...")
# 从预训练模型加载分词器,用于将数据转换为模型可理解的格式
tokenizer = KronosTokenizer.from_pretrained("NeoQuasar/Kronos-Tokenizer-base")
# 从预训练模型加载Kronos小型模型,结构已经在Kronos中定义好了
model = Kronos.from_pretrained("NeoQuasar/Kronos-base")
print("模型和分词器加载完成!")
# 2. 实例化预测器
print("正在初始化预测器...")
# 创建预测器实例,指定使用GPU设备和最大上下文长度
predictor = KronosPredictor(model, tokenizer, device="cuda:0", max_context=512)
print("预测器初始化完成!")
# 3. 准备数据
print("正在加载和处理数据...")
# 读取CSV格式的金融数据文件
df = pd.read_csv("./data/XSHG_5min_600977.csv")
# 将时间戳列转换为pandas的datetime格式
df['timestamps'] = pd.to_datetime(df['timestamps'])
print(f"数据加载完成,共{len(df)}行数据")
# 设置预测参数
lookback = 400 # 用于预测的历史数据长度(400个时间点)
pred_len = 120 # 预测未来的数据长度(120个时间点)
print(f"使用前{lookback}个数据点进行训练,预测未来{pred_len}个数据点")
# 准备输入数据:选择前lookback行的OHLCVA数据
# 构造预测数据
x_df = df.loc[:lookback-1, ['open', 'high', 'low', 'close', 'volume', 'amount']]
# 准备输入时间戳:对应的时间序列
x_timestamp = df.loc[:lookback-1, 'timestamps']
# 准备预测时间戳:需要预测的时间点
y_timestamp = df.loc[lookback:lookback+pred_len-1, 'timestamps']
print(f"输入数据形状: {x_df.shape}")
print(f"预测时间范围: {y_timestamp.iloc[0]} 到 {y_timestamp.iloc[-1]}")
# 4. 执行预测
print("\n开始执行预测...")
pred_df = predictor.predict(
df=x_df, # 输入的历史数据
x_timestamp=x_timestamp, # 输入数据的时间戳
y_timestamp=y_timestamp, # 预测数据的时间戳
pred_len=pred_len, # 预测长度
T=1.0, # 温度参数,控制预测的随机性
top_p=0.9, # Top-p采样参数,控制预测的多样性
sample_count=1, # 采样次数
verbose=True # 显示详细信息
)
print("预测完成!")
# 5. 可视化结果
print("\n预测结果前5行:")
print(pred_df.head())
# 合并历史数据和预测数据用于绘图
# 选择包含历史数据和对应预测时间段的真实数据
kline_df = df.loc[:lookback+pred_len-1]
print(f"\n绘图数据范围: {len(kline_df)}行")
print("正在生成预测结果对比图...")
# 调用可视化函数
plot_prediction(kline_df, pred_df)补充说明
实例化预测器的参数说明
python
def init (self, model, tokenizer, device="cuda:0", max_context=512, clip=5)
#- model:已经构建好的时间序列生成模型(Kronos 实例),用于解码预测。
#- tokenizer:与模型配套的量化分词器(KronosTokenizer 实例),负责把连续值序列编码为离散 token,并将 token 解码回连续值。
#- device:推理设备,默认 "cuda:0"。可改为 "cpu" 或 "cuda:1" 等。
#- max_context:最大上下文窗口长度。超过此长度会在自回归推理时自动只保留最近 max_context 个 token 作为输入。
#- clip:标准化后输入的截断阈值,表示把输入特征按元素裁剪到 [-clip, clip] 区间,用于抑制异常值对生成过程的破坏。在进行数据预测的时候,会先对数据进行标准化,此时,如果数据超过一定范围,就会导致预测的连续性变差,clip是确定方差的大小,默认 5 意味着保留绝大多数正态范围内的数值(约 ±5σ)。如果你的数据异常值很多、想更稳健,可适当减小;如果担心信号被过度截断,可适当增大。过小会丢信息,过大则抑制效果减弱。
根据原例优化的代码
python
import pandas as pd
import matplotlib.pyplot as plt
import os
print(os.getcwd())
# 确定当前路径的位置,修改下面系统路径的添加
import sys
sys.path.append("../")
sys.path.append("./")
from model import Kronos, KronosTokenizer, KronosPredictor
try:
from multi_timeframe_prediction.data_fetcher import CryptoDataFetcher
except Exception as e:
print("导入数据获取器失败,请确保已安装 python-binance 并在项目根目录运行。错误:", e)
raise
##############################
# 代码思路
# 1. 加载模型
# 2. 加载数据
# 3. 预测
# 4. 可视化
##############################
# 1. 加载模型和分词器
print("正在加载Kronos模型和分词器...")
# 模型配置
model_name = "NeoQuasar/Kronos-base"
tokenizer_name = "NeoQuasar/Kronos-Tokenizer-base"
# 从预训练模型加载
tokenizer = KronosTokenizer.from_pretrained(tokenizer_name)
model = Kronos.from_pretrained(model_name)
print("模型和分词器加载完成!")
# 2. Instantiate Predictor
predictor = KronosPredictor(model, tokenizer, device="cuda:0", max_context=512)
# 3. 准备数据
print("正在加载和处理数据...")
# 使用多周期数据获取器,仅拉取 BTC 与 ETH 的 30m 数据
timeframe = '30m'
# 初始化两个交易对的数据获取器
btc_fetcher = CryptoDataFetcher(symbol='BTCUSDT', validate_symbol=True)
eth_fetcher = CryptoDataFetcher(symbol='ETHUSDT', validate_symbol=True)
# 获取数据(默认 limit=1000,可按需调整)
btc_df, btc_path = btc_fetcher.get_data(timeframe, limit=1500)
eth_df, eth_path = eth_fetcher.get_data(timeframe, limit=1500)
print(f"BTCUSDT {timeframe} 数据已加载,文件: {btc_path},行数: {len(btc_df)}")
print(f"ETHUSDT {timeframe} 数据已加载,文件: {eth_path},行数: {len(eth_df)}")
# 双重预测策略实现
lookback = 512
pred_len = 60
# 判断数据是否为最新区间(检查是否有足够的未来数据用于验证)
data_length = len(eth_df)
has_future_data = data_length >= (lookback + pred_len)
print(f"数据总长度: {data_length}")
print(f"需要的最小长度: {lookback + pred_len}")
print(f"是否有足够的未来数据进行验证: {has_future_data}")
# 第一轮预测:历史数据预测(如果数据不在最新区间)
if has_future_data:
print("\n=== 第一轮预测:历史数据验证预测 ===")
print(f"使用前{lookback}个数据点进行训练,预测未来{pred_len}个数据点(用于验证)")
# 准备历史验证预测的输入数据
x_df_hist = eth_df.loc[:lookback-1, ['open', 'high', 'low', 'close', 'volume', 'amount']]
x_timestamp_hist = eth_df.loc[:lookback-1, 'timestamps']
y_timestamp_hist = eth_df.loc[lookback:lookback+pred_len-1, 'timestamps']
pred_df_list_hist = []
else:
print("\n数据长度不足,跳过历史验证预测")
pred_df_list_hist = []
# 定义三组不同的预测参数
predict_configs = [
{"T": 0.8, "top_p": 0.85, "sample_count": 3, "name": "保守预测"},
{"T": 1.0, "top_p": 0.9, "sample_count": 5, "name": "标准预测"},
{"T": 1.2, "top_p": 0.95, "sample_count": 8, "name": "激进预测"}
]
# 执行第一轮历史验证预测
if has_future_data:
print(f"开始进行{len(predict_configs)}次历史验证预测...")
for i, config in enumerate(predict_configs, 1):
print(f"\n正在执行第{i}次历史验证预测 - {config['name']} (T={config['T']}, top_p={config['top_p']}, sample_count={config['sample_count']})...")
pred_df = predictor.predict(
df=x_df_hist, # 输入的历史数据
x_timestamp=x_timestamp_hist, # 输入数据的时间戳
y_timestamp=y_timestamp_hist, # 预测数据的时间戳
pred_len=pred_len, # 预测长度
T=config['T'], # 温度参数,控制预测的随机性
top_p=config['top_p'], # Top-p采样参数,控制预测的多样性
sample_count=config['sample_count'], # 采样次数
verbose=False # 关闭详细信息以减少输出
)
# 为预测结果添加标识
pred_df.name = config['name'] + "(历史验证)"
pred_df_list_hist.append(pred_df)
print(f"第{i}次历史验证预测完成!")
print(f"\n所有{len(pred_df_list_hist)}次历史验证预测完成!")
# 第二轮预测:最新数据的未来预测
print("\n=== 第二轮预测:最新数据未来预测 ===")
print(f"使用最新{lookback}个数据点进行训练,预测真正的未来{pred_len}个数据点")
# 准备最新数据的未来预测输入
latest_start_idx = max(0, data_length - lookback - pred_len)
if has_future_data:
# 如果有足够数据,使用最新的lookback个点
x_df_latest = eth_df.iloc[-lookback:][['open', 'high', 'low', 'close', 'volume', 'amount']]
x_timestamp_latest = eth_df.iloc[-lookback:]['timestamps']
else:
# 如果数据不足,使用所有可用数据
available_data = min(lookback, data_length)
x_df_latest = eth_df.iloc[-available_data:][['open', 'high', 'low', 'close', 'volume', 'amount']]
x_timestamp_latest = eth_df.iloc[-available_data:]['timestamps']
# 生成未来时间戳(基于最后一个时间戳推算)
import pandas as pd
from datetime import timedelta
last_timestamp = eth_df['timestamps'].iloc[-1]
if timeframe == '30m':
time_delta = timedelta(minutes=30)
elif timeframe == '1h':
time_delta = timedelta(hours=1)
elif timeframe == '1d':
time_delta = timedelta(days=1)
else:
time_delta = timedelta(minutes=30) # 默认30分钟
# 生成未来时间戳序列
future_timestamps = []
for i in range(1, pred_len + 1):
future_timestamps.append(last_timestamp + i * time_delta)
y_timestamp_future = pd.Series(future_timestamps)
print(f"最新数据起始时间: {x_timestamp_latest.iloc[0]}")
print(f"最新数据结束时间: {x_timestamp_latest.iloc[-1]}")
print(f"未来预测起始时间: {y_timestamp_future.iloc[0]}")
print(f"未来预测结束时间: {y_timestamp_future.iloc[-1]}")
pred_df_list_future = []
print(f"开始进行{len(predict_configs)}次未来预测...")
# 执行未来预测
for i, config in enumerate(predict_configs, 1):
print(f"\n正在执行第{i}次未来预测 - {config['name']} (T={config['T']}, top_p={config['top_p']}, sample_count={config['sample_count']})...")
pred_df = predictor.predict(
df=x_df_latest, # 输入的最新历史数据
x_timestamp=x_timestamp_latest, # 输入数据的时间戳
y_timestamp=y_timestamp_future, # 未来预测的时间戳
pred_len=pred_len, # 预测长度
T=config['T'], # 温度参数,控制预测的随机性
top_p=config['top_p'], # Top-p采样参数,控制预测的多样性
sample_count=config['sample_count'], # 采样次数
verbose=False # 关闭详细信息以减少输出
)
# 为预测结果添加标识
pred_df.name = config['name'] + "(未来预测)"
pred_df_list_future.append(pred_df)
print(f"第{i}次未来预测完成!")
print(f"\n所有{len(pred_df_list_future)}次未来预测完成!")
# 4. 可视化多次预测结果
print("\n开始绘制预测结果对比图...")
# 创建图形 - 根据是否有历史验证预测决定子图数量
if has_future_data:
fig, ((ax1, ax2), (ax3, ax4)) = plt.subplots(2, 2, figsize=(20, 12))
# 第一组图:历史验证预测
print("绘制历史验证预测结果...")
historical_df = eth_df.loc[:lookback+pred_len-1]
historical_close = historical_df['close']
historical_volume = historical_df['volume']
# 绘制历史收盘价
ax1.plot(historical_close.index[:lookback], historical_close.iloc[:lookback],
label='历史数据', color='black', linewidth=2, alpha=0.8)
# 绘制真实的未来数据(用于验证对比)
true_future = historical_close.iloc[lookback:]
ax1.plot(true_future.index, true_future.values,
label='真实数据', color='green', linewidth=2, alpha=0.7)
# 绘制历史验证预测结果
colors = ['red', 'blue', 'orange']
for i, pred_df in enumerate(pred_df_list_hist):
pred_index = historical_df.index[lookback:lookback+len(pred_df)]
ax1.plot(pred_index, pred_df['close'].values,
label=f'{pred_df.name}', color=colors[i],
linewidth=1.5, linestyle='--', alpha=0.8)
ax1.set_title(f'ETH/USDT {timeframe} 历史验证预测对比', fontsize=14, fontweight='bold')
ax1.set_ylabel('价格 (USDT)', fontsize=12)
ax1.legend(loc='upper left')
ax1.grid(True, alpha=0.3)
# 绘制历史验证的成交量对比
ax2.bar(range(len(historical_volume[:lookback])), historical_volume.iloc[:lookback],
label='历史成交量', color='gray', alpha=0.6, width=0.8)
for i, pred_df in enumerate(pred_df_list_hist):
start_idx = lookback
end_idx = lookback + len(pred_df)
ax2.bar(range(start_idx, end_idx), pred_df['volume'].values,
label=f'{pred_df.name}成交量', color=colors[i], alpha=0.6, width=0.8)
ax2.set_title('历史验证成交量对比', fontsize=12)
ax2.set_xlabel('时间点', fontsize=12)
ax2.set_ylabel('成交量', fontsize=12)
ax2.legend(loc='upper right')
ax2.grid(True, alpha=0.3)
# 第二组图:未来预测
print("绘制未来预测结果...")
latest_close = x_df_latest['close']
latest_volume = x_df_latest['volume']
# 绘制最新历史数据
ax3.plot(range(len(latest_close)), latest_close.values,
label='最新历史数据', color='black', linewidth=2, alpha=0.8)
# 绘制未来预测结果
for i, pred_df in enumerate(pred_df_list_future):
pred_start_idx = len(latest_close)
pred_end_idx = pred_start_idx + len(pred_df)
ax3.plot(range(pred_start_idx, pred_end_idx), pred_df['close'].values,
label=f'{pred_df.name}', color=colors[i],
linewidth=1.5, linestyle='--', alpha=0.8)
ax3.set_title(f'ETH/USDT {timeframe} 未来预测', fontsize=14, fontweight='bold')
ax3.set_ylabel('价格 (USDT)', fontsize=12)
ax3.legend(loc='upper left')
ax3.grid(True, alpha=0.3)
# 绘制未来预测的成交量
ax4.bar(range(len(latest_volume)), latest_volume.values,
label='最新历史成交量', color='gray', alpha=0.6, width=0.8)
for i, pred_df in enumerate(pred_df_list_future):
pred_start_idx = len(latest_volume)
pred_end_idx = pred_start_idx + len(pred_df)
ax4.bar(range(pred_start_idx, pred_end_idx), pred_df['volume'].values,
label=f'{pred_df.name}成交量', color=colors[i], alpha=0.6, width=0.8)
ax4.set_title('未来预测成交量', fontsize=12)
ax4.set_xlabel('时间点', fontsize=12)
ax4.set_ylabel('成交量', fontsize=12)
ax4.legend(loc='upper right')
ax4.grid(True, alpha=0.3)
else:
# 只有未来预测的情况
fig, (ax1, ax2) = plt.subplots(2, 1, figsize=(15, 10), sharex=True)
print("绘制未来预测结果...")
latest_close = x_df_latest['close']
latest_volume = x_df_latest['volume']
# 绘制最新历史数据
ax1.plot(range(len(latest_close)), latest_close.values,
label='最新历史数据', color='black', linewidth=2, alpha=0.8)
# 绘制未来预测结果
colors = ['red', 'blue', 'orange']
for i, pred_df in enumerate(pred_df_list_future):
pred_start_idx = len(latest_close)
pred_end_idx = pred_start_idx + len(pred_df)
ax1.plot(range(pred_start_idx, pred_end_idx), pred_df['close'].values,
label=f'{pred_df.name}', color=colors[i],
linewidth=1.5, linestyle='--', alpha=0.8)
ax1.set_title(f'ETH/USDT {timeframe} 未来预测', fontsize=14, fontweight='bold')
ax1.set_ylabel('价格 (USDT)', fontsize=12)
ax1.legend(loc='upper left')
ax1.grid(True, alpha=0.3)
# 绘制未来预测的成交量
ax2.bar(range(len(latest_volume)), latest_volume.values,
label='最新历史成交量', color='gray', alpha=0.6, width=0.8)
for i, pred_df in enumerate(pred_df_list_future):
pred_start_idx = len(latest_volume)
pred_end_idx = pred_start_idx + len(pred_df)
ax2.bar(range(pred_start_idx, pred_end_idx), pred_df['volume'].values,
label=f'{pred_df.name}成交量', color=colors[i], alpha=0.6, width=0.8)
ax2.set_title('未来预测成交量', fontsize=12)
ax2.set_xlabel('时间点', fontsize=12)
ax2.set_ylabel('成交量', fontsize=12)
ax2.legend(loc='upper right')
ax2.grid(True, alpha=0.3)
plt.tight_layout()
plt.show()
# 打印预测结果统计信息
print("\n=== 预测结果统计分析 ===")
# 历史验证预测统计
if has_future_data:
print("\n--- 历史验证预测统计 ---")
for i, pred_df in enumerate(pred_df_list_hist):
close_prices = pred_df['close']
print(f"\n{pred_df.name}:")
print(f" 收盘价范围: {close_prices.min():.2f} - {close_prices.max():.2f} USDT")
print(f" 平均收盘价: {close_prices.mean():.2f} USDT")
print(f" 价格标准差: {close_prices.std():.2f} USDT")
# 计算价格变化
price_change = ((close_prices.iloc[-1] - close_prices.iloc[0]) / close_prices.iloc[0]) * 100
print(f" 预测期间价格变化: {price_change:+.2f}%")
# 与真实数据对比(如果有的话)
if len(eth_df) > lookback + pred_len - 1:
true_data = eth_df.iloc[lookback:lookback+len(pred_df)]['close']
mae = abs(pred_df['close'] - true_data.values).mean()
mape = (abs(pred_df['close'] - true_data.values) / true_data.values * 100).mean()
print(f" 平均绝对误差 (MAE): {mae:.2f} USDT")
print(f" 平均绝对百分比误差 (MAPE): {mape:.2f}%")
# 未来预测统计
print("\n--- 未来预测统计 ---")
for i, pred_df in enumerate(pred_df_list_future):
close_prices = pred_df['close']
print(f"\n{pred_df.name}:")
print(f" 收盘价范围: {close_prices.min():.2f} - {close_prices.max():.2f} USDT")
print(f" 平均收盘价: {close_prices.mean():.2f} USDT")
print(f" 价格标准差: {close_prices.std():.2f} USDT")
# 计算价格变化
price_change = ((close_prices.iloc[-1] - close_prices.iloc[0]) / close_prices.iloc[0]) * 100
print(f" 预测期间价格变化: {price_change:+.2f}%")
# 与当前价格对比
current_price = x_df_latest['close'].iloc[-1]
initial_change = ((close_prices.iloc[0] - current_price) / current_price) * 100
final_change = ((close_prices.iloc[-1] - current_price) / current_price) * 100
print(f" 相对当前价格初始变化: {initial_change:+.2f}%")
print(f" 相对当前价格最终变化: {final_change:+.2f}%")
print("\n=== 双重预测分析完成 ===")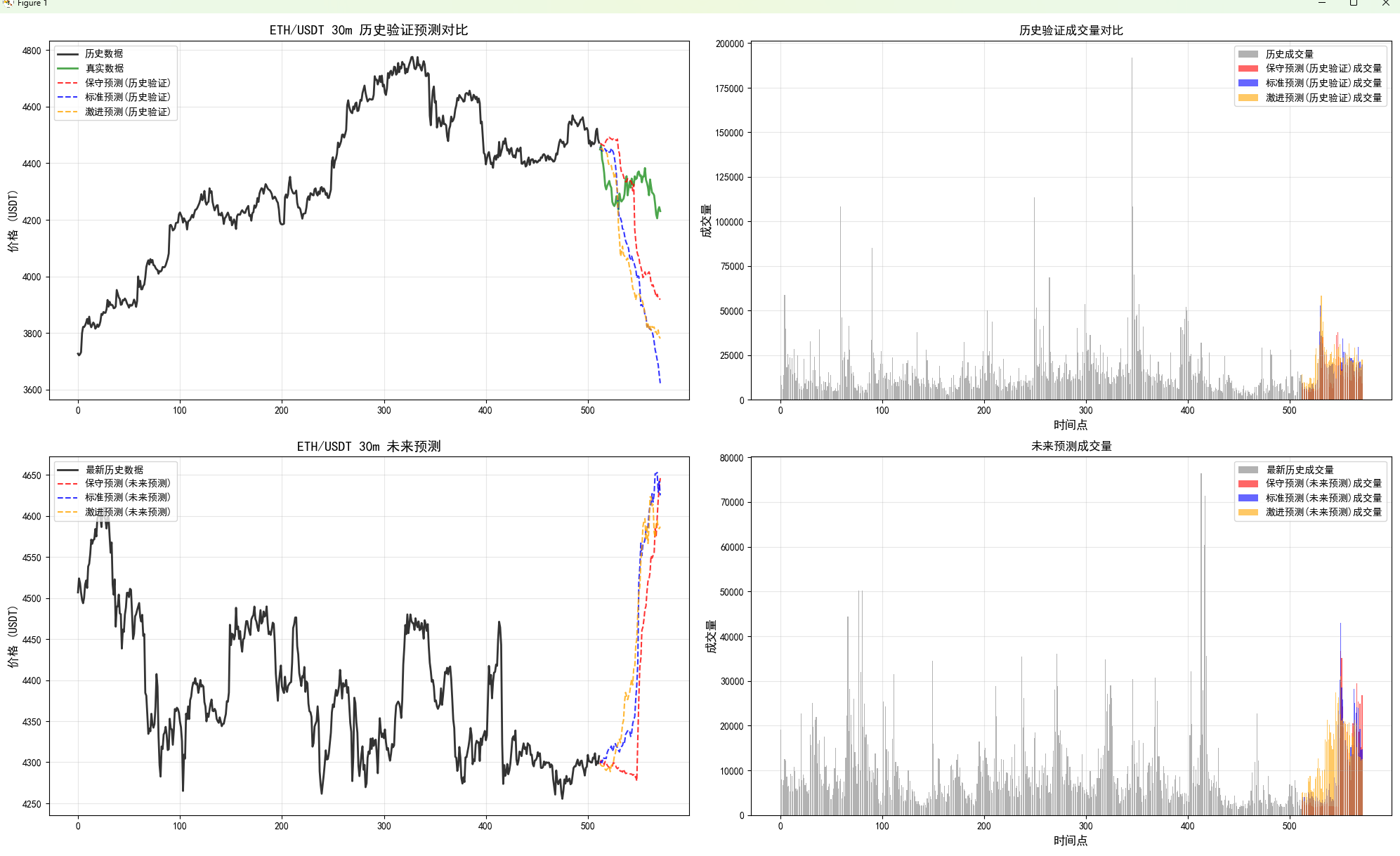
CryptoDataFetcher
python
#CryptoDataFetcher
# 加密货币多周期数据获取模块
# Multi-timeframe cryptocurrency data fetcher using Binance API
import os
import pandas as pd
import time
from datetime import datetime
from binance.client import Client
from typing import Dict, Tuple, Optional, List
class CryptoDataFetcher:
"""
加密货币多周期数据获取器
支持多种交易对和时间周期的K线数据获取
"""
# 默认交易对 - 在这里修改可以统一更改整个系统的交易对
# DEFAULT_SYMBOL = 'BTCUSDT' # 可修改为 'ETHUSDT', 'ADAUSDT' 等其他交易对
DEFAULT_SYMBOL = 'ETHUSDT' # 可修改为 'ETHUSDT', 'ADAUSDT' 等其他交易对
# 支持的时间周期映射
TIMEFRAME_MAP = {
# 分钟级别
'1m': Client.KLINE_INTERVAL_1MINUTE,
'3m': Client.KLINE_INTERVAL_3MINUTE,
'5m': Client.KLINE_INTERVAL_5MINUTE,
'15m': Client.KLINE_INTERVAL_15MINUTE,
'30m': Client.KLINE_INTERVAL_30MINUTE,
# 小时级别
'1h': Client.KLINE_INTERVAL_1HOUR,
'2h': Client.KLINE_INTERVAL_2HOUR,
'4h': Client.KLINE_INTERVAL_4HOUR,
'6h': Client.KLINE_INTERVAL_6HOUR,
'8h': Client.KLINE_INTERVAL_8HOUR,
'12h': Client.KLINE_INTERVAL_12HOUR,
# 日级别
'1d': Client.KLINE_INTERVAL_1DAY,
'3d': Client.KLINE_INTERVAL_3DAY,
# 周月级别
'1w': Client.KLINE_INTERVAL_1WEEK,
'1M': Client.KLINE_INTERVAL_1MONTH
}
# 时间周期描述
TIMEFRAME_DESC = {
# 分钟级别
'1m': '1分钟',
'3m': '3分钟',
'5m': '5分钟',
'15m': '15分钟',
'30m': '30分钟',
# 小时级别
'1h': '1小时',
'2h': '2小时',
'4h': '4小时',
'6h': '6小时',
'8h': '8小时',
'12h': '12小时',
# 日级别
'1d': '1天',
'3d': '3天',
# 周月级别
'1w': '1周',
'1M': '1月'
}
# 推荐的时间周期组合
TIMEFRAME_COMBINATIONS = {
'scalping': ['1m', '5m', '15m'], # 超短线
'day_trading': ['5m', '15m', '1h', '4h'], # 日内交易
'swing_trading': ['1h', '4h', '1d'], # 波段交易
'position_trading': ['4h', '1d', '1w'], # 趋势交易
'comprehensive': ['5m', '15m', '1h', '4h', '1d'] # 综合分析
}
# 常用交易对列表 (主流货币)
POPULAR_SYMBOLS = {
'BTCUSDT': 'Bitcoin',
'ETHUSDT': 'Ethereum',
'DOGEUSDT': 'Dogecoin',
'SOLUSDT': 'Solana'
}
def __init__(self, symbol: str = None, validate_symbol: bool = True):
"""
初始化数据获取器
参数:
symbol: 交易对符号,默认使用 DEFAULT_SYMBOL
validate_symbol: 是否验证交易对有效性,默认True
"""
self.symbol = (symbol or self.DEFAULT_SYMBOL).upper()
self.client = Client() # 无需API Key的公共客户端
# 验证交易对
if validate_symbol:
self._validate_symbol()
print(f"初始化数据获取器 - 交易对: {self.symbol}")
if self.symbol in self.POPULAR_SYMBOLS:
print(f"币种名称: {self.POPULAR_SYMBOLS[self.symbol]}")
def get_data(self, timeframe: str, limit: int = 1000, start_time: Optional[datetime] = None, end_time: Optional[datetime] = None, sleep_sec: float = 0.2, strict_limit: bool = True) -> Tuple[pd.DataFrame, str]:
"""
获取指定时间周期的K线数据(支持自动分页)
参数:
timeframe: 时间周期 ('1m', '5m', '15m', '30m', '1h', '4h', '1d')
limit: 目标获取的数据条数,默认1000条;超过1000将自动分页抓取
start_time: 可选,起始时间(datetime),如提供将从此时间开始向后拉取
end_time: 可选,结束时间(datetime),如提供将不超过该时间
sleep_sec: 分页请求之间的休眠秒数,默认0.2,避免触发频率限制
strict_limit: 若为True,最终返回不超过limit条;若为False,若最后一页跨越end_time边界可能略多
返回:
tuple: (DataFrame, 文件路径)
"""
if timeframe not in self.TIMEFRAME_MAP:
raise ValueError(f"不支持的时间周期: {timeframe}. 支持的周期: {list(self.TIMEFRAME_MAP.keys())}")
print(f"正在获取{self.symbol} {self.TIMEFRAME_DESC[timeframe]}K线数据...")
try:
max_per_req = 1000
interval = self.TIMEFRAME_MAP[timeframe]
collected: List[list] = []
# 情况1:未提供时间范围 -> 从最新开始向过去分页
if start_time is None and end_time is None:
fetched = 0
end_ms = None # 第一页不指定endTime,拿最近的数据
while True:
batch_limit = min(max_per_req, limit - fetched) if strict_limit else max_per_req
if batch_limit <= 0:
break
params = {
'symbol': self.symbol,
'interval': interval,
'limit': batch_limit
}
if end_ms is not None:
params['endTime'] = end_ms
batch = self.client.get_klines(**params)
if not batch:
print(" 未返回更多数据,提前结束。")
break
# 将更老的一批放在前面,保持时间正序
collected = batch + collected
fetched += len(batch)
# 下一页向过去推进:使用本批次最早一根的open time - 1
first_open_time = batch[0][0]
next_end_ms = first_open_time - 1
if end_ms is not None and next_end_ms >= end_ms:
print(" 未能向更早时间推进,停止。")
break
end_ms = next_end_ms
print(f" 已获取: {fetched} 条...")
if strict_limit and fetched >= limit:
break
if sleep_sec and sleep_sec > 0:
time.sleep(sleep_sec)
# 情况2:提供start_time(可选end_time) -> 从start_time向未来分页
elif start_time is not None:
fetched = 0
start_ms = int(start_time.timestamp() * 1000)
end_ms = int(end_time.timestamp() * 1000) if end_time else None
while True:
batch_limit = min(max_per_req, limit - fetched) if strict_limit else max_per_req
if batch_limit <= 0:
break
params = {
'symbol': self.symbol,
'interval': interval,
'limit': batch_limit,
'startTime': start_ms
}
if end_ms is not None:
params['endTime'] = end_ms
batch = self.client.get_klines(**params)
if not batch:
print(" 未返回更多数据,提前结束。")
break
collected.extend(batch)
fetched += len(batch)
last_open_time = batch[-1][0]
# 如达到end_time或已无前进空间,则停止
if end_ms is not None and last_open_time >= end_ms:
break
next_start = last_open_time + 1
if next_start <= start_ms:
print(" 未能向更晚时间推进,停止。")
break
start_ms = next_start
print(f" 已获取: {fetched} 条...")
if strict_limit and fetched >= limit:
break
if sleep_sec and sleep_sec > 0:
time.sleep(sleep_sec)
# 情况3:仅提供end_time -> 从end_time开始向过去分页
else:
fetched = 0
end_ms = int(end_time.timestamp() * 1000)
while True:
batch_limit = min(max_per_req, limit - fetched) if strict_limit else max_per_req
if batch_limit <= 0:
break
params = {
'symbol': self.symbol,
'interval': interval,
'limit': batch_limit,
'endTime': end_ms
}
batch = self.client.get_klines(**params)
if not batch:
print(" 未返回更多数据,提前结束。")
break
collected = batch + collected
fetched += len(batch)
first_open_time = batch[0][0]
next_end = first_open_time - 1
if next_end >= end_ms:
print(" 未能向更早时间推进,停止。")
break
end_ms = next_end
print(f" 已获取: {fetched} 条...")
if strict_limit and fetched >= limit:
break
if sleep_sec and sleep_sec > 0:
time.sleep(sleep_sec)
klines = collected
# 转换数据格式
data = []
for kline in klines:
timestamp = datetime.fromtimestamp(kline[0] / 1000)
data.append({
'timestamps': timestamp,
'open': float(kline[1]),
'high': float(kline[2]),
'low': float(kline[3]),
'close': float(kline[4]),
'volume': float(kline[5]),
'amount': float(kline[7]) # quote asset volume
})
df = pd.DataFrame(data)
# 规范化顺序与去重
if not df.empty:
df = df.sort_values('timestamps').drop_duplicates(subset=['timestamps'], keep='last').reset_index(drop=True)
# 若严格限制且实际超过limit,根据方向裁剪
if strict_limit and len(df) > limit:
if start_time is not None:
df = df.iloc[:limit].reset_index(drop=True) # 从start_time开始的前limit条
else:
df = df.iloc[-limit:].reset_index(drop=True) # 最近的limit条
# 保存数据到文件(使用实际行数命名)
filepath = self._save_data(df, timeframe, len(df))
# 打印数据信息
self._print_data_info(df, timeframe)
return df, filepath
except Exception as e:
print(f"获取{self.TIMEFRAME_DESC[timeframe]}数据失败: {e}")
raise
def get_multiple_timeframes(self, timeframes: list, limit: int = 1000) -> Dict[str, Tuple[pd.DataFrame, str]]:
"""
获取多个时间周期的数据
参数:
timeframes: 时间周期列表
limit: 每个周期获取的数据条数
返回:
dict: {timeframe: (DataFrame, filepath)}
"""
results = {}
print(f"\n开始获取{len(timeframes)}个时间周期的数据...")
print("="*60)
for i, timeframe in enumerate(timeframes, 1):
print(f"\n[{i}/{len(timeframes)}] 获取{self.TIMEFRAME_DESC[timeframe]}数据")
try:
df, filepath = self.get_data(timeframe, limit)
results[timeframe] = (df, filepath)
print(f"✓ {self.TIMEFRAME_DESC[timeframe]}数据获取成功")
except Exception as e:
print(f"✗ {self.TIMEFRAME_DESC[timeframe]}数据获取失败: {e}")
results[timeframe] = (None, None)
print("\n" + "="*60)
print(f"数据获取完成!成功获取 {sum(1 for v in results.values() if v[0] is not None)}/{len(timeframes)} 个时间周期")
return results
def _save_data(self, df: pd.DataFrame, timeframe: str, limit: int) -> str:
"""
保存数据到文件
参数:
df: 数据DataFrame
timeframe: 时间周期
limit: 数据条数
返回:
str: 文件路径
"""
# 创建数据目录
data_dir = os.path.join(
os.path.dirname(os.path.dirname(os.path.abspath(__file__))),
'multi_timeframe_data'
)
os.makedirs(data_dir, exist_ok=True)
# 生成文件名
timestamp = datetime.now().strftime('%Y%m%d_%H%M%S')
filename = f"{self.symbol}_{timeframe}_{limit}_{timestamp}.csv"
filepath = os.path.join(data_dir, filename)
# 保存文件
df.to_csv(filepath, index=False)
return filepath
def _print_data_info(self, df: pd.DataFrame, timeframe: str):
"""
打印数据信息
参数:
df: 数据DataFrame
timeframe: 时间周期
"""
print(f" 数据行数: {len(df)}")
print(f" 时间范围: {df['timestamps'].min()} 到 {df['timestamps'].max()}")
# 提取交易对的基础货币名称(如BTCUSDT -> BTC)
base_currency = self.symbol.replace('USDT', '').replace('BUSD', '').replace('USD', '')
print(f" 当前{base_currency}价格: ${df['close'].iloc[-1]:.2f}")
# 计算时间跨度
time_span = df['timestamps'].max() - df['timestamps'].min()
print(f" 数据时间跨度: {time_span}")
@classmethod
def get_supported_timeframes(cls) -> Dict[str, str]:
"""
获取支持的时间周期列表
返回:
dict: {timeframe: description}
"""
return cls.TIMEFRAME_DESC.copy()
@classmethod
def get_default_timeframes(cls) -> list:
"""
获取默认的时间周期列表
返回:
list: 默认时间周期列表
"""
return ['1m', '5m', '15m', '1h', '4h', '1d']
@classmethod
def get_timeframe_combinations(cls) -> Dict[str, List[str]]:
"""
获取推荐的时间周期组合
返回:
dict: {策略名称: [时间周期列表]}
"""
return cls.TIMEFRAME_COMBINATIONS.copy()
@classmethod
def get_popular_symbols(cls) -> Dict[str, str]:
"""
获取常用交易对列表
返回:
dict: {交易对: 币种名称}
"""
return cls.POPULAR_SYMBOLS.copy()
def _validate_symbol(self):
"""
验证交易对是否有效
抛出:
ValueError: 如果交易对无效
"""
try:
# 尝试获取交易对信息
ticker = self.client.get_symbol_ticker(symbol=self.symbol)
print(f"✓ 交易对 {self.symbol} 验证成功,当前价格: ${float(ticker['price']):.4f}")
except Exception as e:
available_symbols = ', '.join(list(self.POPULAR_SYMBOLS.keys())[:10])
raise ValueError(
f"交易对 {self.symbol} 无效或不存在。\n"
f"常用交易对示例: {available_symbols}...\n"
f"错误详情: {str(e)}"
)
def get_symbol_info(self) -> Dict:
"""
获取当前交易对的详细信息
返回:
dict: 交易对信息
"""
try:
# 获取交易对信息
symbol_info = self.client.get_symbol_info(self.symbol)
ticker = self.client.get_symbol_ticker(symbol=self.symbol)
info = {
'symbol': self.symbol,
'name': self.POPULAR_SYMBOLS.get(self.symbol, 'Unknown'),
'status': symbol_info['status'],
'current_price': float(ticker['price']),
'base_asset': symbol_info['baseAsset'],
'quote_asset': symbol_info['quoteAsset'],
'price_precision': symbol_info['quotePrecision'],
'quantity_precision': symbol_info['baseAssetPrecision']
}
return info
except Exception as e:
print(f"获取交易对信息失败: {e}")
return {}
@classmethod
def search_symbols(cls, keyword: str) -> List[str]:
"""
搜索包含关键词的交易对
参数:
keyword: 搜索关键词
返回:
list: 匹配的交易对列表
"""
keyword = keyword.upper()
matches = []
for symbol, name in cls.POPULAR_SYMBOLS.items():
if keyword in symbol or keyword in name.upper():
matches.append(symbol)
return matches
def change_symbol(self, new_symbol: str, validate: bool = True):
"""
更改当前交易对
参数:
new_symbol: 新的交易对符号
validate: 是否验证新交易对
"""
old_symbol = self.symbol
self.symbol = new_symbol.upper()
if validate:
try:
self._validate_symbol()
print(f"交易对已从 {old_symbol} 更改为 {self.symbol}")
except ValueError as e:
self.symbol = old_symbol # 恢复原交易对
raise e
else:
print(f"交易对已从 {old_symbol} 更改为 {self.symbol} (未验证)")
# 为了向后兼容,保留原类名作为别名
BTCDataFetcher = CryptoDataFetcher单币对多周期预测
结果保存在文件夹里。
有历史回测,默认使用最新的一些时间点。在TIMEFRAMES 这些配置参数的地方修改。
# 双重预测策略实现
lookback = 512
pred_len = 60lookback是模型支持的预测的长度,最大就是512.
还有未来值预测,使用三种参数的预测策略,进行对比。
python
import pandas as pd
import matplotlib.pyplot as plt
import os
print(os.getcwd())
# 确定当前路径的位置,修改下面系统路径的添加
import sys
sys.path.append("../")
sys.path.append("./")
from model import Kronos, KronosTokenizer, KronosPredictor
try:
from multi_timeframe_prediction.data_fetcher import CryptoDataFetcher
except Exception as e:
print("导入数据获取器失败,请确保已安装 python-binance 并在项目根目录运行。错误:", e)
raise
##############################
# 代码思路
# 1. 加载模型
# 2. 加载数据
# 3. 预测
# 4. 可视化
##############################
# 1. 加载模型和分词器
print("正在加载Kronos模型和分词器...")
# 模型配置
model_name = "NeoQuasar/Kronos-base"
tokenizer_name = "NeoQuasar/Kronos-Tokenizer-base"
# 从预训练模型加载
tokenizer = KronosTokenizer.from_pretrained(tokenizer_name)
model = Kronos.from_pretrained(model_name)
print("模型和分词器加载完成!")
# 2. Instantiate Predictor
predictor = KronosPredictor(model, tokenizer, device="cuda:0", max_context=512)
# 3. 准备数据
print("正在加载和处理数据...")
# 配置参数
SYMBOL = 'ETHUSDT' # 可选择的币种: BTCUSDT, ETHUSDT, ADAUSDT, DOTUSDT 等
TIMEFRAMES = ['5m', '15m', '1h'] # 多个时间周期
DATA_LIMIT = 1500 # 数据获取数量
SAVE_RESULTS = True # 是否保存结果到文件
RESULTS_DIR = '../prediction_results' # 结果保存目录
# 创建结果保存目录
import os
from datetime import datetime
if SAVE_RESULTS and not os.path.exists(RESULTS_DIR):
os.makedirs(RESULTS_DIR)
# 初始化数据获取器
fetcher = CryptoDataFetcher(symbol=SYMBOL, validate_symbol=True)
# 存储所有时间周期的数据和预测结果
all_results = {}
print(f"开始处理 {SYMBOL} 的多时间周期预测...")
print(f"时间周期: {TIMEFRAMES}")
print(f"数据获取数量: {DATA_LIMIT}")
if SAVE_RESULTS:
print(f"结果将保存到: {RESULTS_DIR}")
for timeframe in TIMEFRAMES:
print(f"\n=== 处理 {SYMBOL} {timeframe} 时间周期 ===")
# 获取当前时间周期的数据
df, data_path = fetcher.get_data(timeframe, limit=DATA_LIMIT)
print(f"{SYMBOL} {timeframe} 数据已加载,文件: {data_path},行数: {len(df)}")
# 将数据存储到结果字典中
all_results[timeframe] = {
'data': df,
'data_path': data_path,
'predictions': {'historical': [], 'future': []}
}
# 使用当前时间周期的数据进行预测
current_df = df
# 双重预测策略实现
lookback = 512
pred_len = 60
# 判断数据是否为最新区间(检查是否有足够的未来数据用于验证)
data_length = len(current_df)
has_future_data = data_length >= (lookback + pred_len)
print(f"数据总长度: {data_length}")
print(f"需要的最小长度: {lookback + pred_len}")
print(f"是否有足够的未来数据进行验证: {has_future_data}")
# 第一轮预测:历史数据预测(如果数据不在最新区间)
if has_future_data:
print("\n=== 第一轮预测:历史数据验证预测 ===")
print(f"使用最新数据的倒数第{pred_len+1}到倒数第{pred_len+lookback}个数据点进行训练")
print(f"预测最新的{pred_len}个数据点(用于验证)")
# 准备历史验证预测的输入数据 - 使用最新数据但预留最后pred_len个点用于验证
# 输入数据:倒数第(pred_len+lookback)到倒数第(pred_len+1)个数据点
start_idx = data_length - pred_len - lookback
end_idx = data_length - pred_len
x_df_hist = current_df.iloc[start_idx:end_idx][['open', 'high', 'low', 'close', 'volume', 'amount']]
x_timestamp_hist = current_df.iloc[start_idx:end_idx]['timestamps']
# 预测目标:最新的pred_len个数据点(用于验证)
y_timestamp_hist = current_df.iloc[-pred_len:]['timestamps']
print(f"训练数据范围:第{start_idx+1}到第{end_idx}个数据点")
print(f"验证数据范围:第{data_length-pred_len+1}到第{data_length}个数据点(最新{pred_len}个点)")
pred_df_list_hist = []
else:
print("\n数据长度不足,跳过历史验证预测")
pred_df_list_hist = []
# 定义三组不同的预测参数
predict_configs = [
{"T": 0.8, "top_p": 0.85, "sample_count": 3, "name": "保守预测"},
{"T": 1.0, "top_p": 0.9, "sample_count": 5, "name": "标准预测"},
{"T": 1.2, "top_p": 0.95, "sample_count": 8, "name": "激进预测"}
]
# 执行第一轮历史验证预测
if has_future_data:
print(f"开始进行{len(predict_configs)}次历史验证预测...")
for i, config in enumerate(predict_configs, 1):
print(f"\n正在执行第{i}次历史验证预测 - {config['name']} (T={config['T']}, top_p={config['top_p']}, sample_count={config['sample_count']})...")
pred_df = predictor.predict(
df=x_df_hist, # 输入的历史数据
x_timestamp=x_timestamp_hist, # 输入数据的时间戳
y_timestamp=y_timestamp_hist, # 预测数据的时间戳
pred_len=pred_len, # 预测长度
T=config['T'], # 温度参数,控制预测的随机性
top_p=config['top_p'], # Top-p采样参数,控制预测的多样性
sample_count=config['sample_count'], # 采样次数
verbose=False # 关闭详细信息以减少输出
)
# 为预测结果添加标识
pred_df.name = config['name'] + "(历史验证)"
pred_df_list_hist.append(pred_df)
print(f"第{i}次历史验证预测完成!")
print(f"\n所有{len(pred_df_list_hist)}次历史验证预测完成!")
# 保存历史验证预测结果
all_results[timeframe]['predictions']['historical'] = pred_df_list_hist
# 第二轮预测:最新数据的未来预测
print("\n=== 第二轮预测:最新数据未来预测 ===")
print(f"使用最新{lookback}个数据点进行训练,预测真正的未来{pred_len}个数据点")
# 准备最新数据的未来预测输入
latest_start_idx = max(0, data_length - lookback - pred_len)
if has_future_data:
# 如果有足够数据,使用最新的lookback个点
x_df_latest = current_df.iloc[-lookback:][['open', 'high', 'low', 'close', 'volume', 'amount']]
x_timestamp_latest = current_df.iloc[-lookback:]['timestamps']
else:
# 如果数据不足,使用所有可用数据
available_data = min(lookback, data_length)
x_df_latest = current_df.iloc[-available_data:][['open', 'high', 'low', 'close', 'volume', 'amount']]
x_timestamp_latest = current_df.iloc[-available_data:]['timestamps']
# 生成未来时间戳(基于最后一个时间戳推算)
from datetime import timedelta
last_timestamp = current_df['timestamps'].iloc[-1]
if timeframe == '5m':
time_delta = timedelta(minutes=5)
elif timeframe == '15m':
time_delta = timedelta(minutes=15)
elif timeframe == '30m':
time_delta = timedelta(minutes=30)
elif timeframe == '1h':
time_delta = timedelta(hours=1)
elif timeframe == '1d':
time_delta = timedelta(days=1)
else:
time_delta = timedelta(minutes=30) # 默认30分钟
# 生成未来时间戳序列
future_timestamps = []
for i in range(1, pred_len + 1):
future_timestamps.append(last_timestamp + i * time_delta)
y_timestamp_future = pd.Series(future_timestamps)
print(f"最新数据起始时间: {x_timestamp_latest.iloc[0]}")
print(f"最新数据结束时间: {x_timestamp_latest.iloc[-1]}")
print(f"未来预测起始时间: {y_timestamp_future.iloc[0]}")
print(f"未来预测结束时间: {y_timestamp_future.iloc[-1]}")
pred_df_list_future = []
print(f"开始进行{len(predict_configs)}次未来预测...")
# 执行未来预测
for i, config in enumerate(predict_configs, 1):
print(f"\n正在执行第{i}次未来预测 - {config['name']} (T={config['T']}, top_p={config['top_p']}, sample_count={config['sample_count']})...")
pred_df = predictor.predict(
df=x_df_latest, # 输入的最新历史数据
x_timestamp=x_timestamp_latest, # 输入数据的时间戳
y_timestamp=y_timestamp_future, # 未来预测的时间戳
pred_len=pred_len, # 预测长度
T=config['T'], # 温度参数,控制预测的随机性
top_p=config['top_p'], # Top-p采样参数,控制预测的多样性
sample_count=config['sample_count'], # 采样次数
verbose=False # 关闭详细信息以减少输出
)
# 为预测结果添加标识
pred_df.name = config['name'] + "(未来预测)"
pred_df_list_future.append(pred_df)
print(f"第{i}次未来预测完成!")
print(f"\n所有{len(pred_df_list_future)}次未来预测完成!")
# 保存未来预测结果
all_results[timeframe]['predictions']['future'] = pred_df_list_future
# 4. 可视化多次预测结果
print(f"\n开始绘制 {timeframe} 预测结果对比图...")
# 创建图形 - 根据是否有历史验证预测决定子图数量
if has_future_data:
fig, ((ax1, ax2), (ax3, ax4)) = plt.subplots(2, 2, figsize=(20, 12))
# 第一组图:历史验证预测
print("绘制历史验证预测结果...")
# 使用最新数据进行历史验证预测的可视化
# 训练数据:倒数第(pred_len+lookback)到倒数第(pred_len+1)个数据点
start_idx = data_length - pred_len - lookback
end_idx = data_length - pred_len
# 训练数据部分
train_data = current_df.iloc[start_idx:end_idx]
train_close = train_data['close']
train_volume = train_data['volume']
# 真实的最新数据(用于验证对比)
true_latest = current_df.iloc[-pred_len:]
true_latest_close = true_latest['close']
true_latest_volume = true_latest['volume']
# 绘制训练数据
train_x = range(len(train_close))
ax1.plot(train_x, train_close.values,
label='训练数据', color='black', linewidth=2, alpha=0.8)
# 绘制真实的最新数据(用于验证对比)
true_x = range(len(train_close), len(train_close) + len(true_latest_close))
ax1.plot(true_x, true_latest_close.values,
label='真实最新数据', color='green', linewidth=2, alpha=0.7)
# 绘制历史验证预测结果
colors = ['red', 'blue', 'orange']
for i, pred_df in enumerate(pred_df_list_hist):
pred_x = range(len(train_close), len(train_close) + len(pred_df))
ax1.plot(pred_x, pred_df['close'].values,
label=f'{pred_df.name}', color=colors[i],
linewidth=1.5, linestyle='--', alpha=0.8)
ax1.set_title(f'{SYMBOL} {timeframe} 历史验证预测对比(最新数据验证)', fontsize=14, fontweight='bold')
ax1.set_ylabel('价格 (USDT)', fontsize=12)
ax1.legend(loc='upper left')
ax1.grid(True, alpha=0.3)
# 绘制历史验证的成交量对比
ax2.bar(train_x, train_volume.values,
label='训练数据成交量', color='gray', alpha=0.6, width=0.8)
ax2.bar(true_x, true_latest_volume.values,
label='真实最新成交量', color='green', alpha=0.6, width=0.8)
for i, pred_df in enumerate(pred_df_list_hist):
pred_x = range(len(train_close), len(train_close) + len(pred_df))
ax2.bar(pred_x, pred_df['volume'].values,
label=f'{pred_df.name}成交量', color=colors[i], alpha=0.6, width=0.8)
ax2.set_title('历史验证成交量对比(最新数据验证)', fontsize=12)
ax2.set_xlabel('时间点', fontsize=12)
ax2.set_ylabel('成交量', fontsize=12)
ax2.legend(loc='upper right')
ax2.grid(True, alpha=0.3)
# 第二组图:未来预测
print("绘制未来预测结果...")
latest_close = x_df_latest['close']
latest_volume = x_df_latest['volume']
# 绘制最新历史数据
ax3.plot(range(len(latest_close)), latest_close.values,
label='最新历史数据', color='black', linewidth=2, alpha=0.8)
# 绘制未来预测结果
for i, pred_df in enumerate(pred_df_list_future):
pred_start_idx = len(latest_close)
pred_end_idx = pred_start_idx + len(pred_df)
ax3.plot(range(pred_start_idx, pred_end_idx), pred_df['close'].values,
label=f'{pred_df.name}', color=colors[i],
linewidth=1.5, linestyle='--', alpha=0.8)
ax3.set_title(f'{SYMBOL} {timeframe} 未来预测', fontsize=14, fontweight='bold')
ax3.set_ylabel('价格 (USDT)', fontsize=12)
ax3.legend(loc='upper left')
ax3.grid(True, alpha=0.3)
# 绘制未来预测的成交量
ax4.bar(range(len(latest_volume)), latest_volume.values,
label='最新历史成交量', color='gray', alpha=0.6, width=0.8)
for i, pred_df in enumerate(pred_df_list_future):
pred_start_idx = len(latest_volume)
pred_end_idx = pred_start_idx + len(pred_df)
ax4.bar(range(pred_start_idx, pred_end_idx), pred_df['volume'].values,
label=f'{pred_df.name}成交量', color=colors[i], alpha=0.6, width=0.8)
ax4.set_title('未来预测成交量', fontsize=12)
ax4.set_xlabel('时间点', fontsize=12)
ax4.set_ylabel('成交量', fontsize=12)
ax4.legend(loc='upper right')
ax4.grid(True, alpha=0.3)
else:
# 只有未来预测的情况
fig, (ax1, ax2) = plt.subplots(2, 1, figsize=(15, 10), sharex=True)
print("绘制未来预测结果...")
latest_close = x_df_latest['close']
latest_volume = x_df_latest['volume']
# 绘制最新历史数据
ax1.plot(range(len(latest_close)), latest_close.values,
label='最新历史数据', color='black', linewidth=2, alpha=0.8)
# 绘制未来预测结果
colors = ['red', 'blue', 'orange']
for i, pred_df in enumerate(pred_df_list_future):
pred_start_idx = len(latest_close)
pred_end_idx = pred_start_idx + len(pred_df)
ax1.plot(range(pred_start_idx, pred_end_idx), pred_df['close'].values,
label=f'{pred_df.name}', color=colors[i],
linewidth=1.5, linestyle='--', alpha=0.8)
ax1.set_title(f'{SYMBOL} {timeframe} 未来预测', fontsize=14, fontweight='bold')
ax1.set_ylabel('价格 (USDT)', fontsize=12)
ax1.legend(loc='upper left')
ax1.grid(True, alpha=0.3)
# 绘制未来预测的成交量
ax2.bar(range(len(latest_volume)), latest_volume.values,
label='最新历史成交量', color='gray', alpha=0.6, width=0.8)
for i, pred_df in enumerate(pred_df_list_future):
pred_start_idx = len(latest_volume)
pred_end_idx = pred_start_idx + len(pred_df)
ax2.bar(range(pred_start_idx, pred_end_idx), pred_df['volume'].values,
label=f'{pred_df.name}成交量', color=colors[i], alpha=0.6, width=0.8)
ax2.set_title('未来预测成交量', fontsize=12)
ax2.set_xlabel('时间点', fontsize=12)
ax2.set_ylabel('成交量', fontsize=12)
ax2.legend(loc='upper right')
ax2.grid(True, alpha=0.3)
plt.tight_layout()
# 保存图表到文件
chart_filename = f"{SYMBOL}_{timeframe}_prediction_results.png"
chart_path = os.path.join(RESULTS_DIR, chart_filename)
plt.savefig(chart_path, dpi=300, bbox_inches='tight')
plt.close() # 关闭图表以释放内存
print(f"图表已保存到: {chart_path}")
# 保存图表路径到结果字典
all_results[timeframe]['chart_path'] = chart_path
# 保存预测数据到CSV文件
print(f"正在保存 {timeframe} 预测数据到文件...")
# 保存历史验证预测数据
if has_future_data and pred_df_list_hist:
for i, pred_df in enumerate(pred_df_list_hist):
hist_filename = f"{SYMBOL}_{timeframe}_historical_prediction_{i+1}_{pred_df.name.replace(' ', '_').replace('(', '').replace(')', '')}.csv"
hist_path = os.path.join(RESULTS_DIR, hist_filename)
pred_df.to_csv(hist_path, index=False)
print(f" 历史验证预测 {i+1} 已保存: {hist_filename}")
# 保存未来预测数据
for i, pred_df in enumerate(pred_df_list_future):
future_filename = f"{SYMBOL}_{timeframe}_future_prediction_{i+1}_{pred_df.name.replace(' ', '_').replace('(', '').replace(')', '')}.csv"
future_path = os.path.join(RESULTS_DIR, future_filename)
pred_df.to_csv(future_path, index=False)
print(f" 未来预测 {i+1} 已保存: {future_filename}")
# 保存原始数据(用于参考)
data_filename = f"{SYMBOL}_{timeframe}_original_data.csv"
data_path = os.path.join(RESULTS_DIR, data_filename)
current_df.to_csv(data_path, index=False)
print(f" 原始数据已保存: {data_filename}")
# 打印预测结果统计信息
print(f"\n=== {timeframe} 预测结果统计分析 ===")
# 历史验证预测统计
if has_future_data:
print("\n--- 历史验证预测统计 ---")
for i, pred_df in enumerate(pred_df_list_hist):
close_prices = pred_df['close']
print(f"\n{pred_df.name}:")
print(f" 收盘价范围: {close_prices.min():.2f} - {close_prices.max():.2f} USDT")
print(f" 平均收盘价: {close_prices.mean():.2f} USDT")
print(f" 价格标准差: {close_prices.std():.2f} USDT")
# 计算价格变化
price_change = ((close_prices.iloc[-1] - close_prices.iloc[0]) / close_prices.iloc[0]) * 100
print(f" 预测期间价格变化: {price_change:+.2f}%")
# 与真实最新数据对比
true_latest_data = current_df.iloc[-pred_len:]['close']
mae = abs(pred_df['close'] - true_latest_data.values).mean()
mape = (abs(pred_df['close'] - true_latest_data.values) / true_latest_data.values * 100).mean()
# 计算相关系数
correlation = pred_df['close'].corr(pd.Series(true_latest_data.values))
print(f" 平均绝对误差 (MAE): {mae:.2f} USDT")
print(f" 平均绝对百分比误差 (MAPE): {mape:.2f}%")
print(f" 与真实数据相关系数: {correlation:.4f}")
# 计算方向准确性(涨跌方向预测准确率)
pred_direction = (pred_df['close'].diff() > 0).iloc[1:]
true_direction = (pd.Series(true_latest_data.values).diff() > 0).iloc[1:]
# 重置索引以确保两个Series可以正确比较
pred_direction = pred_direction.reset_index(drop=True)
true_direction = true_direction.reset_index(drop=True)
direction_accuracy = (pred_direction == true_direction).mean() * 100
print(f" 方向预测准确率: {direction_accuracy:.1f}%")
# 未来预测统计
print("\n--- 未来预测统计 ---")
for i, pred_df in enumerate(pred_df_list_future):
close_prices = pred_df['close']
print(f"\n{pred_df.name}:")
print(f" 收盘价范围: {close_prices.min():.2f} - {close_prices.max():.2f} USDT")
print(f" 平均收盘价: {close_prices.mean():.2f} USDT")
print(f" 价格标准差: {close_prices.std():.2f} USDT")
# 计算价格变化
price_change = ((close_prices.iloc[-1] - close_prices.iloc[0]) / close_prices.iloc[0]) * 100
print(f" 预测期间价格变化: {price_change:+.2f}%")
# 与当前价格对比
current_price = x_df_latest['close'].iloc[-1]
initial_change = ((close_prices.iloc[0] - current_price) / current_price) * 100
final_change = ((close_prices.iloc[-1] - current_price) / current_price) * 100
print(f" 相对当前价格初始变化: {initial_change:+.2f}%")
print(f" 相对当前价格最终变化: {final_change:+.2f}%")
print(f"\n=== {timeframe} 预测分析完成 ===")
# 所有时间周期处理完成后的总结
print("\n=== 所有时间周期预测完成 ===")
for tf in TIMEFRAMES:
hist_count = len(all_results[tf]['predictions']['historical'])
future_count = len(all_results[tf]['predictions']['future'])
print(f"{tf}: 历史验证预测{hist_count}次, 未来预测{future_count}次")
# 保存完整结果摘要到JSON文件
print("\n正在保存完整结果摘要...")
summary_data = {
'symbol': SYMBOL,
'timeframes': TIMEFRAMES,
'prediction_configs': predict_configs,
'results_directory': RESULTS_DIR,
'timestamp': pd.Timestamp.now().isoformat(),
'summary': {}
}
for tf in TIMEFRAMES:
summary_data['summary'][tf] = {
'historical_predictions_count': len(all_results[tf]['predictions']['historical']),
'future_predictions_count': len(all_results[tf]['predictions']['future']),
'chart_path': all_results[tf]['chart_path'],
'data_length': len(all_results[tf]['data']),
'has_future_data': len(all_results[tf]['data']) > lookback + pred_len
}
summary_filename = f"{SYMBOL}_prediction_summary_{pd.Timestamp.now().strftime('%Y%m%d_%H%M%S')}.json"
summary_path = os.path.join(RESULTS_DIR, summary_filename)
import json
with open(summary_path, 'w', encoding='utf-8') as f:
json.dump(summary_data, f, indent=2, ensure_ascii=False)
print(f"结果摘要已保存: {summary_filename}")
print(f"\n=== 所有预测任务完成 ===")
print(f"币种: {SYMBOL}")
print(f"时间周期: {', '.join(TIMEFRAMES)}")
print(f"结果保存目录: {RESULTS_DIR}")
print("\n保存的文件包含:")
print("- 各时间周期的预测数据 (CSV格式)")
print("- 对应的可视化图表 (PNG格式)")
print("- 原始K线数据 (CSV格式)")
print("- 完整结果摘要 (JSON格式)")
print("- 预测结果字典变量 all_results (内存中)")
print("\n可以通过以下方式查看结果:")
print(f"1. 打开目录: {RESULTS_DIR}")
print("2. 查看图表文件了解预测趋势")
print("3. 分析CSV数据文件进行详细研究")
print("4. 使用 all_results 变量进行进一步的程序化分析")=== 所有预测任务完成 ===
币种: ETHUSDT
时间周期: 5m, 15m, 30m, 1h, 4h
结果保存目录: .../prediction_results
保存的文件包含:
- 各时间周期的预测数据 (CSV格式)
- 对应的可视化图表 (PNG格式)
- 原始K线数据 (CSV格式)
- 完整结果摘要 (JSON格式)
- 预测结果字典变量 all_results (内存中)
可以通过以下方式查看结果:
- 打开目录: .../prediction_results
- 查看图表文件了解预测趋势
- 分析CSV数据文件进行详细研究
- 使用 all_results 变量进行进一步的程序化分析
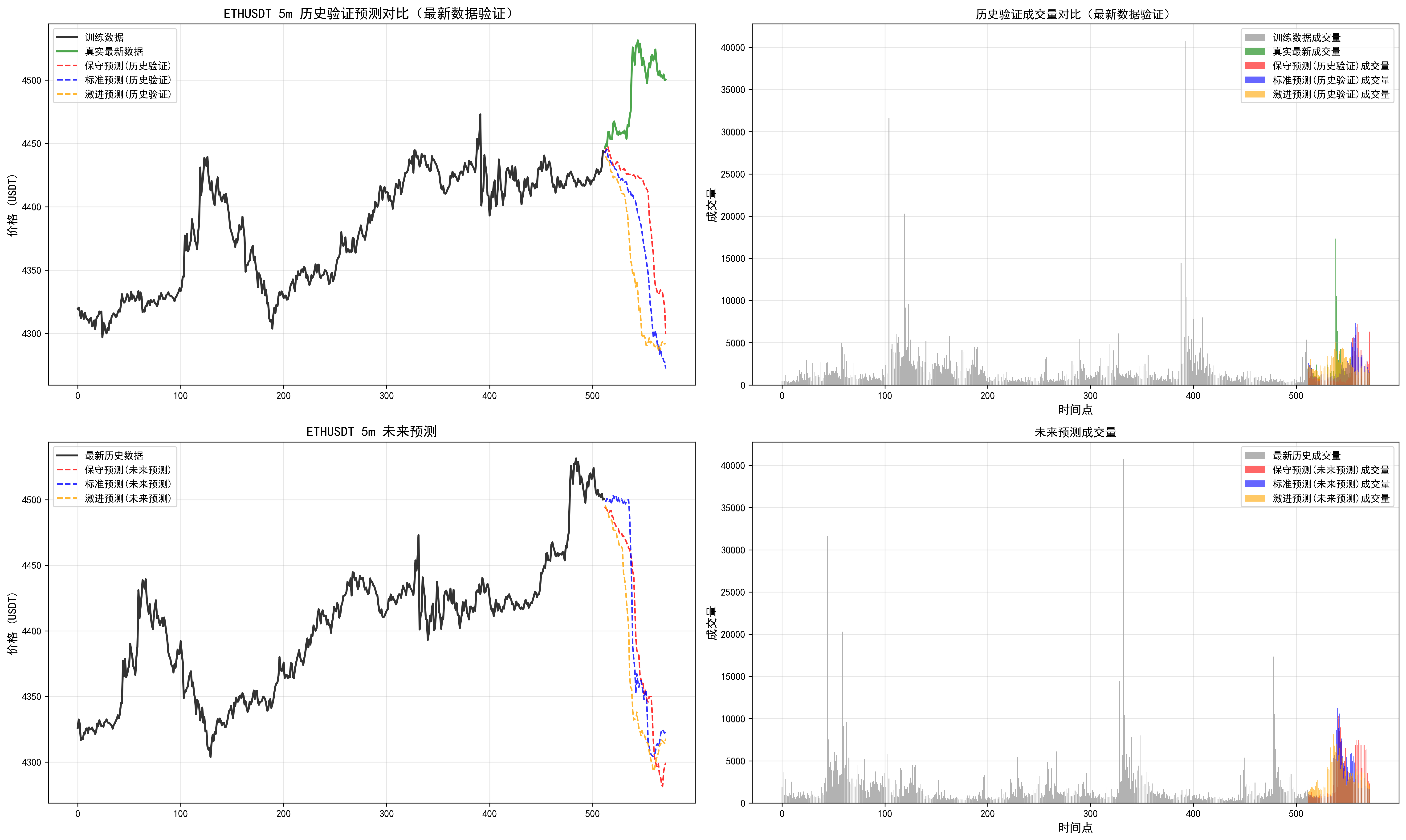
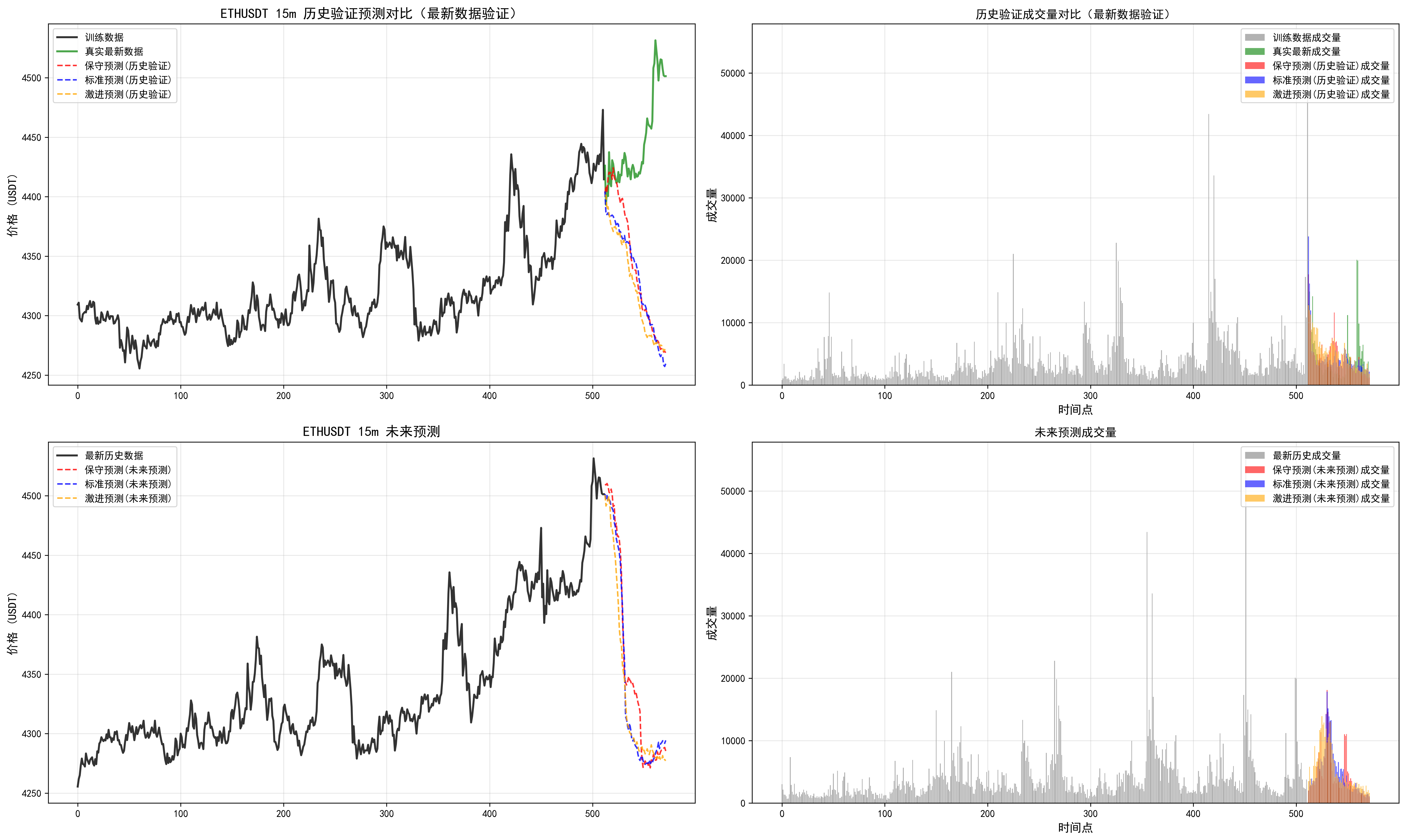
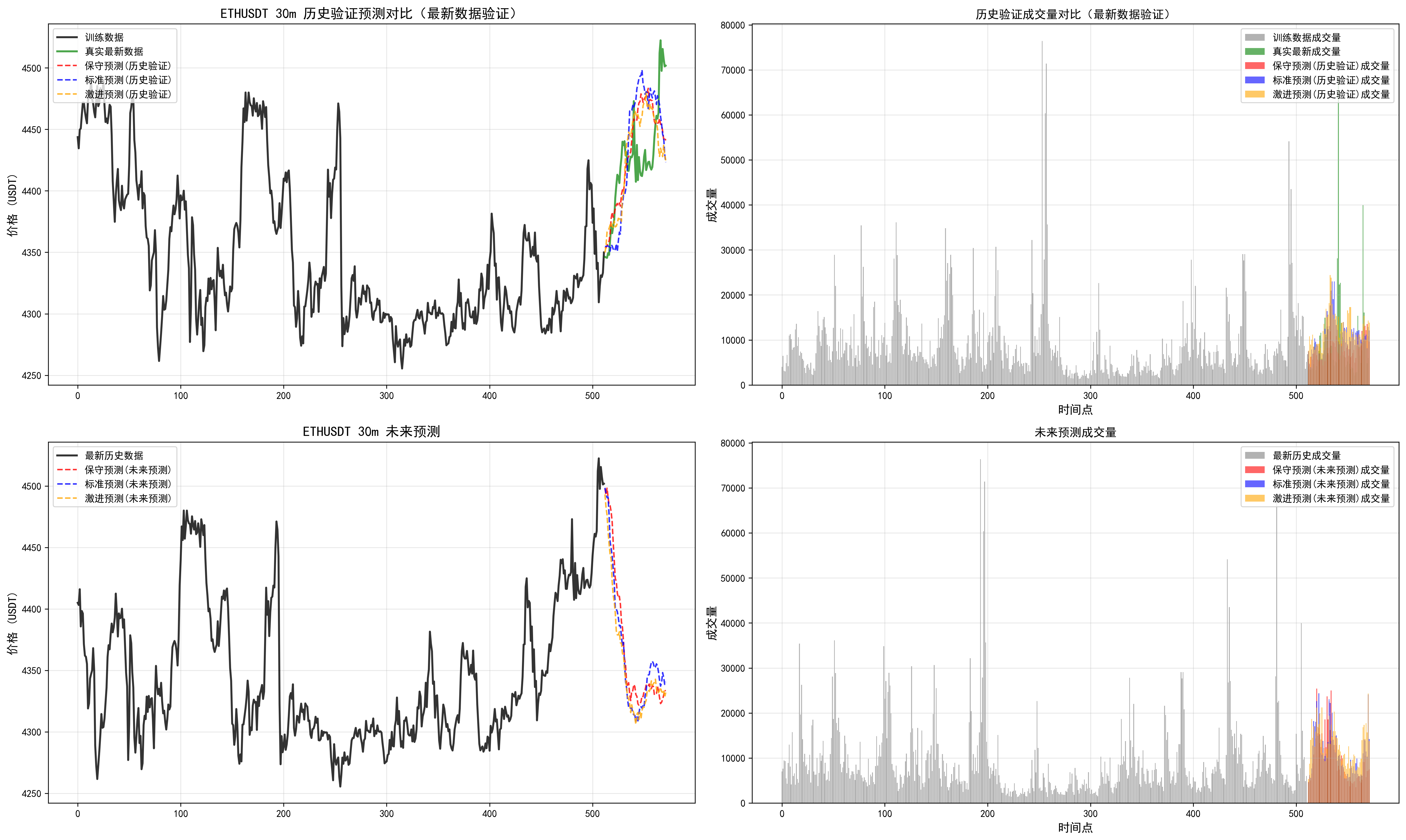
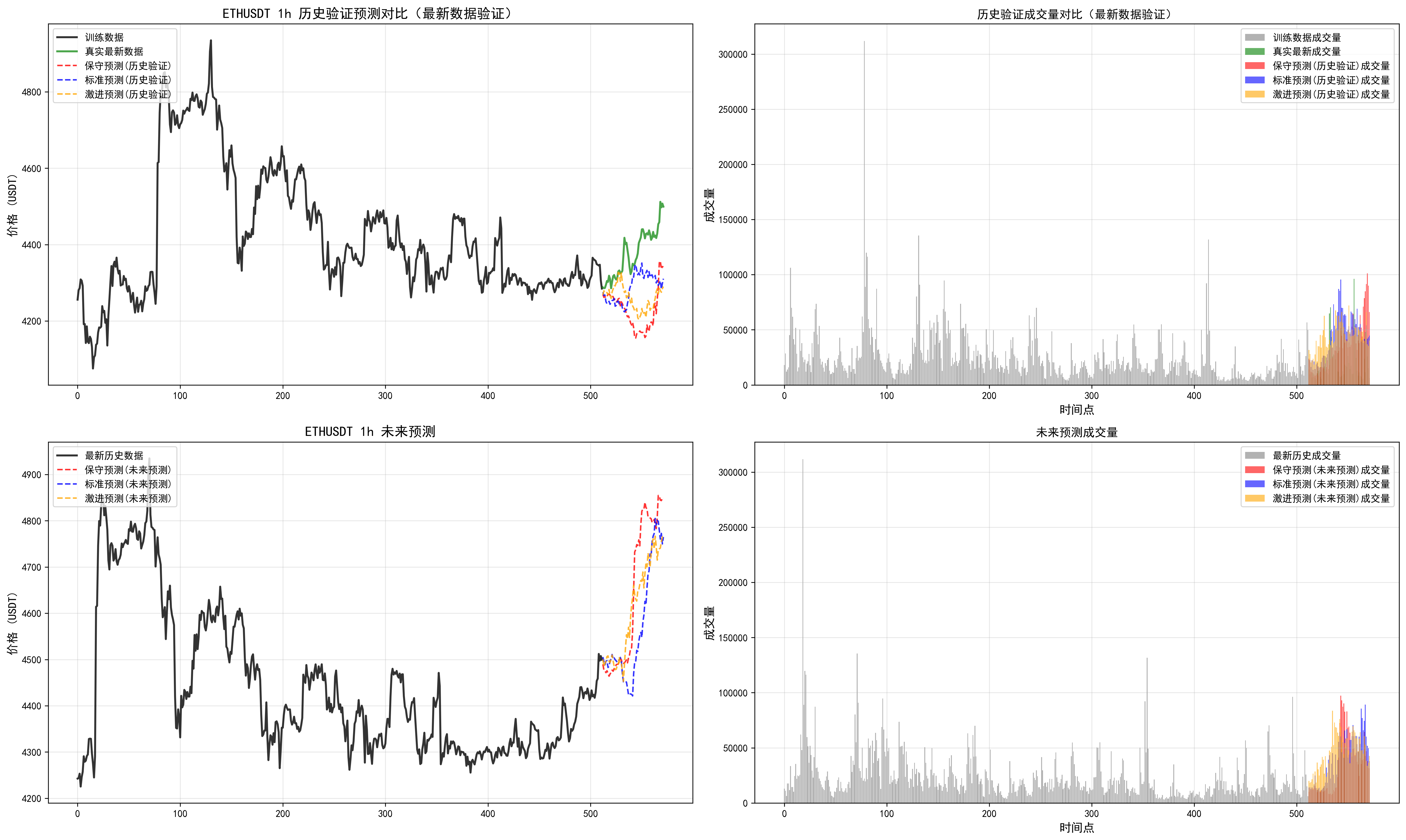
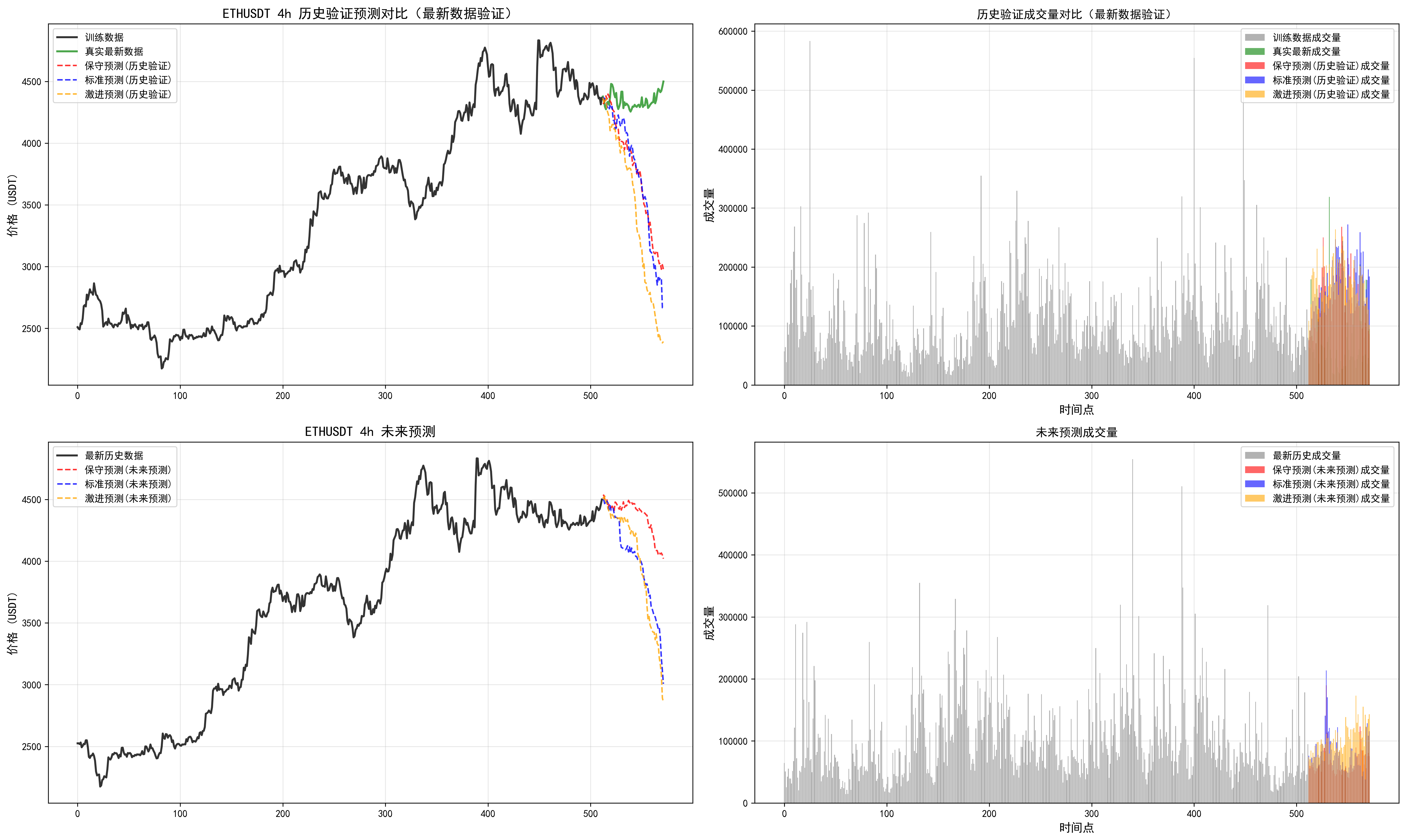
我们可以发现多周期是有分歧的,可以根据最近回测偏离不大的时间周期,追随未来的结果。但是实践看来,并不是总是很准,(因为读取的长度是有限的,最大只能读取512个k线,最长周期4h,读取了85天)。需要借助传统指标,查看当前较长周期和多周期指标支持度。从而综合下来进行判断。
因此对于这个预测长度和读取长度还需要实际进行调整。
对于周期的把握,这个相关信息也需要进一步优化。