存储方式对比
| 存储方式 | 存储容量 | API难度 | 优点 | 缺点 |
|---|---|---|---|---|
| LocalStorage / SessionStorage | ~5MB-10MB/~5MB | ⭐️️ | 简单,API 同步、直接 setItem/getItem 就能用。 |
+ 容量极小(一般只有 5MB 左右 ,不同浏览器有差异)。 + 同步阻塞 API,数据量大时会卡 UI 线程。 + 只能存字符串,不支持复杂对象结构,得自己做 JSON 序列化/反序列化。 + 没有事务、没有索引 ,查询只能全量遍历 。 + 安全性差,容易被脚本直接读出。 |
| Cookie | ~4KB | ⭐⭐ | 最早期的存储方式,服务端自动可见(随请求发送) | + 存储空间极小 (单个 cookie 4KB 限制,域名下总量也有限制)。 + 每次请求都会自动携带 → 增加请求头流量(性能差)。 + 安全风险大(容易被 XSS 窃取 ,除非设置 HttpOnly)。 + API 原始,读写不方便。 + 完全不适合存大数据。 |
| ⭐⭐⭐ | + |
|||
| Cache API (Service Worker 缓存) | ~50MB以上 | ⭐⭐⭐ | 专门用于离线缓存请求响应(静态资源、接口数据)。 | + 面向缓存,而不是数据存储 。 + 不能方便地按字段查询,只能按 request key 检索。 + 适合资源层面的缓存,不适合结构化数据。 |
| 文件系统 API (File System Access API) | 操作本地文件 | ⭐⭐⭐⭐ | 直接访问本地文件系统,适合大文件存储(比如视频、图片)。 | + 权限复杂 (需要用户明确授权)。 + 兼容性差,只有部分 Chromium 内核支持。 + 不适合做结构化数据的持久存储。 |
| SQLite | 理论上 140 TB(取决于文件系统和编译选项),对绝大多数应用都够用。几十 MB 到几 GB 都没压力 | ⭐⭐⭐⭐ | SQL 查询强大,可以 JOIN、事务灵活,API 是同步或 Promise 封装的异步,但本质上要操作文件 | + 是一个嵌入式数据库,需要操作系统文件访问权限 + 浏览器里没法直接访问文件系统 |
| IndexDB | 几十MB - GB | ⭐⭐⭐ | 👇👇👇👇👇👇 | 👇👇👇👇👇👇👇 |
✅ 总而言之
-
存储空间太小,缺少事务/索引,安全性差
-
键值对总是以字符串形式存储,不支持其他数据格式
-
不支持异步操作,数据量大时进行I/O操作性能体验差
indexDB简介
MDN官网解释
IndexedDB 是一种底层 API,用于在客户端存储大量的结构化数据。该 API 使用索引实现对数据的高性能搜索。虽然 Web Storage 在存储较少量的数据很有用,但对于存储更大量的结构化数据来说力不从心。而 IndexedDB 提供了这种场景的解决方案。
官网上的这句话也很简单明了,意思就是IndexedDB主要用来客户端存储大量数据而生的 。如果数据量很大,且都需要客户端存储时,那么就可以使用IndexedDB数据库。
Blob、ArrayBuffer,这种就可以使用indexDB来实现
- 可以把 图片、音频、视频、PDF、Office 文件 之类直接放到 IndexedDB 里,而不是只存一堆 Base64。节省空间 + 提高性能。
- IndexedDB + Blob = 可以实现"断网也能打开文件"的体验
- 文件大时,可以把它切成 Blob chunk 存入 IndexedDB,上传时一块一块发给服务端
<font style="color:rgb(37, 41, 51);">FileReader.readAsArrayBuffer(file)</font>把文件读成二进制然后自己处理。- WebCrypto API、音视频编解码器、压缩库,都直接操作
<font style="color:rgb(37, 41, 51);">ArrayBuffer</font>- 图形渲染需要把顶点坐标、纹理像素数据传到 GPU,用
<font style="color:rgb(37, 41, 51);">ArrayBuffer</font>/<font style="color:rgb(37, 41, 51);">TypedArray</font>
🔶 兼容性
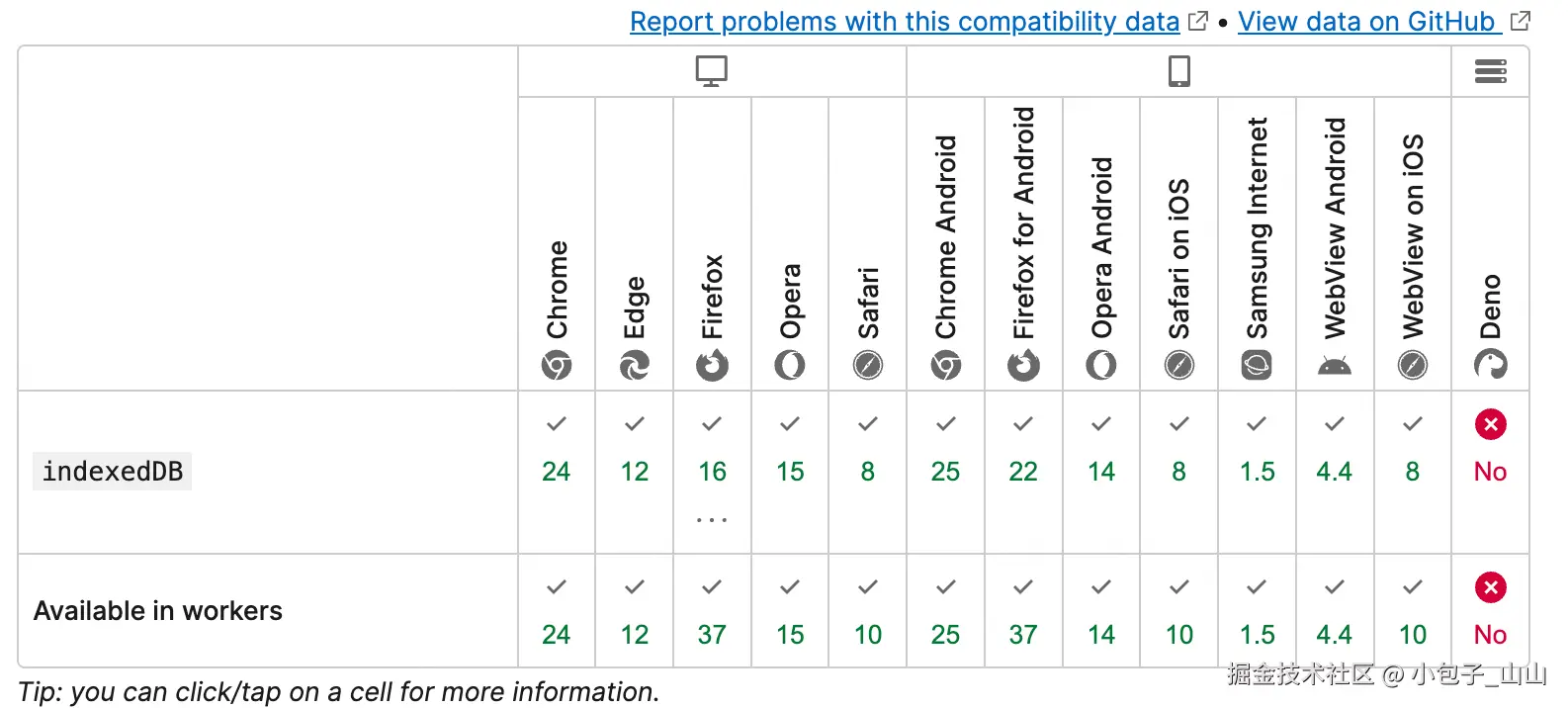
特点
空间大小
这也是IndexedDB最显著的特点之一了,这也是不用localStorage等存储方式的最好理由。
IndexDB存储空间根据不同的设备而定,因为不同设备存储空间大小不一致,浏览器的最大存储空间是动态的,它完全取决于你的磁盘大小。全局限制为可用磁盘空间的 50%。
非关系型数据库(NoSql)
都知道MySQL等数据库都是关系型数据库,它们的主要特点就是数据都以一张二维表的形式存储,而Indexed DB是非关系型数据库,主要以键值对的形式存储数据。
持久化存储
cookie、localStorage、sessionStorage等方式存储的数据当清除浏览器缓存后,这些数据都会被清除掉的,而使用IndexedDB存储的数据则不会,除非手动删除该数据库。(注意:选择删除其它数据还是会清除的)
异步操作
IndexedDB操作时不会锁死浏览器,用户依然可以进行其他的操作,这与localstorage形成鲜明的对比,后者是同步的。
支持事务
IndexedDB支持事务(transaction),这意味着一系列的操作步骤之中,只要有一步失败了,整个事务都会取消,数据库回滚的事务发生之前的状态,这和MySQL等数据库的事务类似。
- 主键冲突:
add()操作要求主键唯一,如果重复则报错 → 触发事务回滚- 唯一索引冲突:设置了
unique: true的索引冲突 → 回滚- 手动 abort()
- 访问不存在的 store 或索引
安全机制
1️⃣ 同源策略(Same-Origin Policy)
- 同源限制访问:不同域名、协议或端口的网页无法访问你的 IndexedDB 数据。
- 跨标签页共享:同一个域名下的多个标签页可以共享数据库,但其他网站无法访问。
🆚 不同之处:多标签页同时操作时,事务会排队执行,避免数据竞争,更安全可靠
✅ 安全性体现:防止跨站点直接读取你的数据。
2️⃣ 存储权限和浏览器控制
- IndexedDB 数据由浏览器管理,无法被普通网页脚本绕过。
- 浏览器会限制:
- 存储空间(Quota)
- 用户清理(清理浏览器缓存/数据可以删除 IndexedDB 数据)
- 私密模式下通常不会长期存储 IndexedDB 数据。
✅ 安全性体现:用户和浏览器可控制存储生命周期和大小,减少持久化风险。
3️⃣ 隔离与沙箱机制
- IndexedDB 数据存放在浏览器沙箱内,网页无法直接访问文件系统。
- 只有通过浏览器提供的 API 才能操作数据。
✅ 安全性体现:防止网页/恶意脚本直接修改本地磁盘数据。
普通沙箱 🆚 indexDB沙箱
1️⃣ 普通沙箱(所有网页都有)
- 网页脚本(JS)没有直接访问本地文件系统的权限。
- 你必须通过
<input type="file">或 File System Access API(并且要用户交互授权)才能读写。- 这是浏览器普遍的安全规则。
2️⃣IndexedDB 的「额外沙箱隔离」
IndexedDB 本质上是浏览器在本地存储了一个数据库文件 (在 Chrome、Firefox、Safari 的 profile 目录里都能找到物理文件)。
但网页 JS 看不到真实的文件路径 、也不能用
fs方式直接访问:
- 只能通过 IndexedDB API 访问数据。
- 物理层面的存储文件对开发者不可见、不可控。
- 数据库文件放在浏览器内部的「profile 沙箱」中,和系统文件完全隔离。
总结:IndexedDB 虽然是本地数据库,但对网页代码来说只有 API 层,不会暴露文件层。
4️⃣ 数据敏感性与加密
- IndexedDB 不自动加密数据,存储的是明文 JSON / Blob 等。
- 如果存储敏感信息(密码、身份证号、金融信息),建议:
- 在写入 IndexedDB 前先做 加密处理
- 结合 Crypto API 或自己管理加密密钥
⚠️ 风险:恶意本地程序或浏览器插件可能读取明文数据。
浏览器统一支持
- 所有现代浏览器(Chrome、Firefox、Safari、Edge)都支持 IndexedDB。
- 相比 File System Access API、OPFS 等新 API,它的兼容性最好。
不同电脑配置的影响
🤔
依赖电脑配置,但是不是主要的瓶颈。IndexDB的存储效率(写入/查询性能,可存储容量)等影响程度和纬度要分开来看:
1️⃣ 硬件层面
🔸 CPU 性能
- 写入/查询时需要 JS 主线程参与(序列化/反序列化、建索引、事务管理等),CPU 性能越好,IndexedDB 操作越快。
- 特别是处理大批量 JSON 或 Blob 时,弱 CPU 会成为瓶颈。
🔸 磁盘类型/速度
- IndexedDB 底层依赖浏览器的存储引擎(Chromium 用 LevelDB,Firefox 用 SQLite),最终还是落到磁盘上。
- SSD 比 HDD 快得多,批量写入/查询性能差异明显。
🔸 内存大小
- 批量查询或大对象写入时需要先经过内存缓冲,如果内存小,GC 频繁,会拖慢速度。
- IndexedDB 不会无限制吃内存,但缓存不足时会频繁写回磁盘,效率下降。
2️⃣ 浏览器层面
- 不同浏览器用的存储引擎不同(Chrome/Edge → LevelDB,Firefox → SQLite,Safari → WebKit 自研),性能差异明显。
- 同样的数据量,在 Chrome/Safari/Firfox表现都是也许不同。
3️⃣ 系统层面
🔸 操作系统的文件系统实现
- NTFS、APFS、ext4 在小文件、大文件、随机读写上的表现不一样,导致 IndexedDB IO 性能差异。
🔸 磁盘配额限制
- 浏览器通常给 IndexedDB 分配磁盘空间上限(全局限制为可用磁盘空间的 50%)
4️⃣ 应用设计层面(往往比硬件更关键)
- 批量写入时是否用事务、是否拆分成小块写入。
- 是否滥用 JSON.stringify / parse。
- 是否给查询字段建索引(避免全表扫描)。
- 是否在主线程里做了大量处理,导致 UI 卡顿。
✅ 结论
- 硬件配置(CPU/磁盘/内存)会直接影响 IndexedDB 的效率,尤其是在处理大数据量时。
- 但实际瓶颈往往是实现和应用设计,例如不建索引、大量同步操作、一次性写入几十 MB。
- 如果设计得好,即便在配置一般的电脑上,IndexedDB 也能应付几十万甚至百万级数据存储和检索。
核心概念
数据库(Database)
数据库是一系列相关数据的容器,每个协议+域名+端口都可以新建任意个数据库
indexDB数据库有版本的概念,同一个时刻只能有一个版本的数据库存在,如果要修改数据库结构,只能通过升级数据库版本
🛑 版本升级注意点:
- 不允许跨版本修改
- 如果原先数据库里 store 很多、索引复杂,浏览器就需要 检查现有结构并准备新结构(保证数据一致性)。升级操作会稍微慢一些。
对象仓库(objectStore)
IndexedDB没有表的概念,它只有仓库store的概念,大家可以把仓库理解为表即可,即一个store是一张表。
操作请求(Request)
操作请求对象,indexedDB 每个操作都是异步的,也就是说每个请求会先返回这个这个对象,然后根据这个对象的回调去进行后续的处理。
| 基本属性 | 说明 | 事件回调 |
|---|---|---|
result |
操作成功后,结果会保存在这里 | onsuccess onerror |
error |
操作失败时的错误对象 | |
readyState |
请求的当前状态 | |
source |
发起请求的来源 | |
transaction |
请求所属的事务对象 |
索引(index)
- 在关系型数据库当中也有索引的概念,可以给对应的表字段添加索引,以便加快查找速率。
- 在IndexedDB中同样有索引,可以在创建store的时候同时创建索引,在后续对store进行查询的时候即可通过索引来筛选
- 索引可以设置
unique: true,保证索引字段的值唯一。这样就能实现类似数据库"唯一索引"的功能,防止重复数据。 - 索引不仅支持精确匹配查询,还能做范围查询,比如查找年龄在20到30岁之间的人。
IndexedDB 的索引实现基本都依赖 LevelDB(Chromium / Edge / Opera) 或 SQLite(Firefox / Safari) 。
这些数据库的索引结构通常是 B+Tree 或 SkipList:
- 键存储在有序结构里,支持范围查询(>=, <=, between)。
- 叶子节点按顺序存储,游标可以顺序遍历(正序/倒序)。
- 插入数据时,主表和索引表会分别写入:
- 主表存完整对象(JSON / Blob)
- 索引表存「索引键 → 主键 ID」的映射
当你建一个
createTime索引时,IndexedDB 背后实际上维护了一个单独的 B+Tree,key 是时间戳,value 是记录的主键(比如自增 id)。
索引范围(KeyRange)
索引范围对象,主要用来批量查询数据,或者批量删除数据的时候使用。
游标(cursor)
- 游标是IndexedDB数据库新的概念,大家可以把游标想象为一个指针,比如要查询满足某一条件的所有数据时,就需要用到游标,让游标一行一行的往下走,游标走到的地方便会返回这一行数据,此时便可对此行数据进行判断,是否满足条件。
- 适合没法直接用主键或索引精确定位时,遍历筛选数据。
- 游标(cursor)通过索引遍历数据,能按索引字段排序,这对分页、筛选非常有用。
【注意】:IndexedDB查询不像MySQL等数据库方便,它只能通过主键、索引、游标方式查询数据。
注意: IndexedDB 在做分页查询时,确实有两条典型路线:
- 直接用索引 + getAll / getAllKeys 搭配 offset/limit
- 用游标(openCursor / openKeyCursor)手动遍历并截断
内存与性能
- getAll :会一次性把符合条件的所有记录读到内存里,然后你再在 JS 层做 slice 分页。
- 如果数据量大,比如几万甚至几十万条,内存消耗和前端性能压力非常明显。
- 游标 :是逐条拉取,你可以边遍历边决定是否 push 到结果集,到够
pageSize就立刻停止,不会把无关数据都拉出来。
👉 优势:分页时只取需要的部分,内存开销小,性能更稳定。
灵活性
- getAll 只能获取到一批数据,你想跳页(比如第 100 页)只能整批加载前 100 页的数据再 slice,非常低效。
- 游标 可以很自然地做到"跳过前 N 条,然后取 M 条",类似数据库里的
OFFSET + LIMIT。
👉 优势:适合大数据量的深度分页。
排序支持
- IndexedDB 的排序是基于 索引顺序 的,openCursor 时可以指定
"next"/"prev",天然支持正序倒序。 - getAll 则只能按索引自然顺序取全量,再在前端手动翻转或排序。
👉 优势:游标分页时可以利用底层 B+Tree 的顺序遍历,性能更高。
停止控制
- getAll 没法中途停,必须全拉完。
- 游标 可以随时
cursor.continue()或者break,拿够了就停。
👉 优势:只取需要的数据,不浪费 IO。
✅ 总结一句话:
- 数据量小(几百条以内) →
getAll简单粗暴,代码量少。 - 数据量大、需要分页/排序/跳页 → 游标才是正解,节省内存,性能稳定,支持深度分页和双向遍历。
事务(Transaction)
IndexedDB支持事务,即对数据库进行操作时,只要失败了,都会回滚到最初始的状态,确保数据的一致性。
触发事务条件:
- 主键/唯一索引冲突冲突
- 手动调用
.abort,主动结束事务 - 磁盘写入/存储空间错误
- 访问了不存在对象仓库或者索引
局限性
多表关联
IndexedDB 没有像 MySQL 那样的 JOIN 功能,两个表(Object Store)之间的"关联"只能靠你自己去实现,本质上就是在一个表里存另一个表的主键,然后代码里手动去查第二个表。
javascript
function getUserWithOrders(userId) {
return new Promise((resolve, reject) => {
const tx = db.transaction(['users', 'orders'], 'readonly');
const usersStore = tx.objectStore('users');
const ordersStore = tx.objectStore('orders').index('userId');
// 1. 查用户
const userReq = usersStore.get(userId);
userReq.onsuccess = () => {
const user = userReq.result;
if (!user) {
resolve(null);
return;
}
// 2. 查订单
const orders = [];
const orderReq = ordersStore.openCursor(IDBKeyRange.only(userId));
orderReq.onsuccess = (e) => {
const cursor = e.target.result;
if (cursor) {
orders.push(cursor.value);
cursor.continue();
} else {
resolve({ ...user, orders });
}
};
orderReq.onerror = reject;
};
userReq.onerror = reject;
});
}
javascript
{
"id": 1,
"name": "小包子",
"orders": [
{ "id": 101, "userId": 1, "product": "电脑", "price": 5000 },
{ "id": 102, "userId": 1, "product": "耳机", "price": 500 }
]
}索引查询
查询能力有限,不支持复杂搜索
- 不支持全文搜索:只能做基于主键或索引的精确匹配或范围查询,没法直接支持模糊匹配、正则、全文检索。
- 不支持多字段复杂查询:复合索引有限,复杂条件组合(多字段且模糊匹配)很难实现高效查询。
查询性能瓶颈明显
- 索引类型单一:只能建立单字段或有限的复合索引,没办法支持复杂查询策略。
- 游标遍历代价大:复杂查询时必须用游标遍历整个数据集合,数据量大时性能急剧下降。
- 事务锁导致并发查询受限:事务机制会阻塞其它操作,影响并发性能。
解决方案
| 查询类型 | IndexedDB 支持情况 | 性能瓶颈 | 解决办法 |
|---|---|---|---|
| 精确匹配 | 支持,走索引 | 较快 | 直接索引查询 |
| 前缀匹配 | 支持范围查询 | 还可以 | IDBKeyRange.bound |
| 模糊包含关键字 | 不支持 | 需全表扫描 性能极差 | 1. 自建倒排索引 2. 结合全文搜索库 |
实际操作
创建/连接数据库、创建索引
javascript
/**
* 打开数据库
* @param {object} dbName 数据库的名字
* @param {string} storeName 仓库名称
* @param {string} version 数据库的版本
* @return {object} 该函数会返回一个数据库实例
*/
export function openDB(dbName, version = 1) {
return new Promise((resolve, reject) => {
// 兼容浏览器
var indexedDB =
window.indexedDB || window.mozIndexedDB || window.webkitIndexedDB || window.msIndexedDB
let db
// 打开数据库,若没有则会创建
const request = indexedDB.open(dbName, version)
// 数据库打开成功回调
request.onsuccess = function (event) {
db = event.target.result // 数据库对象
console.log('数据库打开成功')
resolve(db)
}
// 数据库打开失败的回调
request.onerror = function (event) {
console.log('数据库打开报错')
reject(event)
}
// 数据库有更新时候的回调
request.onupgradeneeded = function (event) {
// 数据库创建或升级的时候会触发
console.log('onupgradeneeded')
db = event.target.result // 数据库对象
var objectStore
// 创建存储库
objectStore = db.createObjectStore('ragFile', {
keyPath: 'fileId' // 这是主键
// autoIncrement: true // 实现自增
})
// 创建索引,在后面查询数据的时候可以根据索引查
// (索引名,索引对应字段,唯一性限制)
objectStore.createIndex('fileId', 'fileId', { unique: false }) //文件主键
objectStore.createIndex('title', 'title', { unique: false }) //文件名称
}
})
}将创建数据库的操作封装成了一个函数,并且该函数返回一个promise对象,使得在调用的时候可以链式调用,函数主要接收两个参数:数据库名称、数据库版本。函数内部主要有三个回调函数,分别是:
- onsuccess:数据库打开成功或者创建成功后的回调,这里将数据库实例返回了出去。
- onerror:数据库打开或创建失败后的回调。
- onupgradeneeded:当数据库版本有变化的时候会执行该函数,比如想创建新的存储库(表),就可以在该函数里面操作,更新数据库版本即可。
插入数据
javascript
/**
* 新增数据
* @param {object} db 数据库实例
* @param {string} storeName 仓库名称
* @param {string} data 数据
*/
function addData(db, storeName, data) {
var request = db
.transaction([storeName], "readwrite") // 事务对象 指定表格名称和操作模式("只读"或"读写")
.objectStore(storeName) // 仓库对象
.add(data);
request.onsuccess = function (event) {
console.log("数据写入成功");
};
request.onerror = function (event) {
console.log("数据写入失败");
};
}ndexedDB插入数据需要通过事务来进行操作,插入的方法也很简单,利用IndexedDB提供的add方法即可,这里同样将插入数据的操作封装成了一个函数,接收三个参数,分别如下:
- db:在创建或连接数据库时,返回的db实例,需要那个时候保存下来。
- storeName:仓库名称(或者表名),在创建或连接数据库时就已经创建好了仓库。
- data:需要插入的数据,通常是一个对象
**【注意】:**插入的数据是一个对象,而且必须包含声明的索引键值对。
通过主键读取数据
javascript
/**
* 通过主键读取数据
* @param {object} db 数据库实例
* @param {string} storeName 仓库名称
* @param {string} key 主键值
*/
function getDataByKey(db, storeName, key) {
return new Promise((resolve, reject) => {
var transaction = db.transaction([storeName]); // 事务
var objectStore = transaction.objectStore(storeName); // 仓库对象
var request = objectStore.get(key); // 通过主键获取数据
request.onerror = function (event) {
console.log("事务失败");
};
request.onsuccess = function (event) {
console.log("主键查询结果: ", request.result);
resolve(request.result);
};
});
}主键即刚刚在创建数据库时声明的keyPath,通过主键只能查询出一条数据。
通过游标查询数据
javascript
/**
* 通过游标读取数据
* @param {object} db 数据库实例
* @param {string} storeName 仓库名称
*/
function cursorGetData(db, storeName) {
let list = [];
var store = db
.transaction(storeName, "readwrite") // 事务
.objectStore(storeName); // 仓库对象
var request = store.openCursor(); // 指针对象
// 游标开启成功,逐行读数据
request.onsuccess = function (e) {
var cursor = e.target.result;
if (cursor) {
// 必须要检查
list.push(cursor.value);
cursor.continue(); // 遍历了存储对象中的所有内容
} else {
console.log("游标读取的数据:", list);
}
};
}上面函数开启了一个游标,然后逐行读取数据,存入数组,最终得到整个仓库的所有数据。
通过索引查询数据
索引名称即创建仓库的时候创建的索引名称,也就是键值对中的键,最终会查询出所有满足传入函数索引值的数据。
javascript
/**
* 通过索引读取数据
* @param {object} db 数据库实例
* @param {string} storeName 仓库名称
* @param {string} indexName 索引名称
* @param {string} indexValue 索引值
*/
function getDataByIndex(db, storeName, indexName, indexValue) {
var store = db.transaction(storeName, "readwrite").objectStore(storeName);
var request = store.index(indexName).get(indexValue);
request.onerror = function () {
console.log("事务失败");
};
request.onsuccess = function (e) {
var result = e.target.result;
console.log("索引查询结果:", result);
};
}通过索引和游标查询数据
通过5.4节和5.5节发现,单独通过索引或者游标查询出的数据都是部分或者所有数据,如果想要查询出索引中满足某些条件的所有数据,那么单独使用索引或游标是无法实现的。当然,你也可以查询出所有数据之后在循环数组筛选出合适的数据,但是这不是最好的实现方式,最好的方式当然是将索引和游标结合起来。
javascript
/**
* 通过索引和游标查询记录
* @param {object} db 数据库实例
* @param {string} storeName 仓库名称
* @param {string} indexName 索引名称
* @param {string} indexValue 索引值
*/
function cursorGetDataByIndex(db, storeName, indexName, indexValue) {
let list = [];
var store = db.transaction(storeName, "readwrite").objectStore(storeName); // 仓库对象
var request = store
.index(indexName) // 索引对象
.openCursor(IDBKeyRange.only(indexValue)); // 指针对象
request.onsuccess = function (e) {
var cursor = e.target.result;
if (cursor) {
// 必须要检查
list.push(cursor.value);
cursor.continue(); // 遍历了存储对象中的所有内容
} else {
console.log("游标索引查询结果:", list);
}
};
request.onerror = function (e) {};
}上面函数接收四个参数,分别是:
- db:数据库实例
- storeName:仓库名
- indexName:索引名称
- indexName:索引值
利用索引和游标结合查询,可以查询出索引值满足传入函数值的所有数据对象,而不是只查询出一条数据或者所有数据。
过索引和游标分页查询
IndexedDB分页查询不像MySQL分页查询那么简单,没有提供现成的API,如limit等,所以需要自己实现分页。
代码如下:
javascript
/**
* 通过索引和游标分页查询记录
* @param {object} db 数据库实例
* @param {string} storeName 仓库名称
* @param {string} indexName 索引名称
* @param {string} indexValue 索引值
* @param {number} page 页码
* @param {number} pageSize 查询条数
*/
function cursorGetDataByIndexAndPage(
db,
storeName,
indexName,
indexValue,
page,
pageSize
) {
let list = [];
let counter = 0; // 计数器
let advanced = true; // 是否跳过多少条查询
var store = db.transaction(storeName, "readwrite").objectStore(storeName); // 仓库对象
var request = store
.index(indexName) // 索引对象
.openCursor(IDBKeyRange.only(indexValue)); // 指针对象
request.onsuccess = function (e) {
var cursor = e.target.result;
if (page > 1 && advanced) {
advanced = false;
cursor.advance((page - 1) * pageSize); // 跳过多少条
return;
}
if (cursor) {
// 必须要检查
list.push(cursor.value);
counter++;
if (counter < pageSize) {
cursor.continue(); // 遍历了存储对象中的所有内容
} else {
cursor = null;
console.log("分页查询结果", list);
}
} else {
console.log("分页查询结果", list);
}
};
request.onerror = function (e) {};
}这里用到了IndexedDB的一个API:advance。该函数可以让的游标跳过多少条开始查询。假如的额分页是每页10条数据,现在需要查询第2页,那么就需要跳过前面10条数据,从11条数据开始查询,直到计数器等于10,那么就关闭游标,结束查询。
更新数据
IndexedDB更新数据较为简单,直接使用put方法,值得注意的是如果数据库中没有该条数据,则会默认增加该条数据,否则更新。有些小伙伴喜欢更新和新增都是用put方法,这也是可行的。
代码如下:
javascript
/**
* 更新数据
* @param {object} db 数据库实例
* @param {string} storeName 仓库名称
* @param {object} data 数据
*/
function updateDB(db, storeName, data) {
var request = db
.transaction([storeName], "readwrite") // 事务对象
.objectStore(storeName) // 仓库对象
.put(data);
request.onsuccess = function () {
console.log("数据更新成功");
};
request.onerror = function () {
console.log("数据更新失败");
};
}put方法接收一个数据对象。
通过主键删除数据
主键即创建数据库时申明的keyPath,它是唯一的。
代码如下:
javascript
/**
* 通过主键删除数据
* @param {object} db 数据库实例
* @param {string} storeName 仓库名称
* @param {object} id 主键值
*/
function deleteDB(db, storeName, id) {
var request = db
.transaction([storeName], "readwrite")
.objectStore(storeName)
.delete(id);
request.onsuccess = function () {
console.log("数据删除成功");
};
request.onerror = function () {
console.log("数据删除失败");
};
}该种删除只能删除一条数据,必须传入主键。
通过索引和游标删除指定数据
有时候拿不到主键值,只能只能通过索引值来删除,通过这种方式,可以删除一条数据(索引值唯一)或者所有满足条件的数据(索引值不唯一)。
代码如下:
javascript
/**
* 通过索引和游标删除指定的数据
* @param {object} db 数据库实例
* @param {string} storeName 仓库名称
* @param {string} indexName 索引名
* @param {object} indexValue 索引值
*/
function cursorDelete(db, storeName, indexName, indexValue) {
var store = db.transaction(storeName, "readwrite").objectStore(storeName);
var request = store
.index(indexName) // 索引对象
.openCursor(IDBKeyRange.only(indexValue)); // 指针对象
request.onsuccess = function (e) {
var cursor = e.target.result;
var deleteRequest;
if (cursor) {
deleteRequest = cursor.delete(); // 请求删除当前项
deleteRequest.onerror = function () {
console.log("游标删除该记录失败");
};
deleteRequest.onsuccess = function () {
console.log("游标删除该记录成功");
};
cursor.continue();
}
};
request.onerror = function (e) {};
}上段代码可以删除索引值为indexValue的所有数据,值得注意的是使用了IDBKeyRange.only()API,该API代表只能当两个值相等时,具体API解释可参考MDN官网。
关闭数据库
在使用 IndexedDB 时,关闭数据库连接是个好习惯,主要有以下几个好处:
- 释放资源:每个数据库连接都消耗系统资源,尤其是在数据较多时。如果你不关闭连接,可能会浪费内存和其他系统资源,导致性能下降。
- 避免连接泄露:如果忘记关闭连接,可能会导致数据库连接泄露。尤其在单页面应用(SPA)中,如果频繁打开数据库连接而没有关闭,可能会引发浏览器崩溃或变得迟钝。
- 事务完成后的清理:如果数据库连接没有在操作完成后关闭,可能导致事务没有完全提交或者数据库处于不稳定状态。关闭连接能确保所有的操作都完成并提交。
- 允许数据库升级:关闭连接后,你可以更容易地维护操作。如果连接一直保持着,就无法进行这些操作。
- 防止并发冲突:IndexedDB 是异步操作,长时间保持连接可能引发并发操作冲突。如果你不及时关闭连接,可能会增加数据库锁定或事务冲突的几率,影响应用的可靠性。
总之,关闭连接可以保持应用的高效、稳定,并防止一些潜在的性能和安全问题。
代码如下:
javascript
/**
* 关闭数据库
* @param {object} db 数据库实例
*/
function closeDB(db) {
db.close();
console.log("数据库已关闭");
}删除数据库
如果需要删库,删除操作也很简单。
代码如下:
javascript
/**
* 删除数据库
* @param {object} dbName 数据库名称
*/
function deleteDBAll(dbName) {
console.log(dbName);
let deleteRequest = window.indexedDB.deleteDatabase(dbName);
deleteRequest.onerror = function (event) {
console.log("删除失败");
};
deleteRequest.onsuccess = function (event) {
console.log("删除成功");
};
}总结
| 操作 | API | 说明 |
|---|---|---|
| 打开数据库 | indexedDB.open(name, version) |
打开或创建数据库。 有数据库就打开,没有就创建;如果传入更高的 version,会触发 onupgradeneeded 事件。 |
| 创建仓库对象 | db.createObjectStore(store_name, { keyPath, autoIncrement }) |
在 onupgradeneeded 里调用。 参数: • store_name:仓库(表)名称 • keyPath:指定主键字段 • autoIncrement:是否自动生成主键 |
| 创建索引 | store.createIndex(index_name, keyPath, { unique }) |
为仓库里的字段创建索引,加快查询。 参数: • index_name:索引名称 • keyPath:要索引的字段 • unique:是否唯一 |
| 插入 | store.add(value, key?) |
向仓库里插入新数据。 如果主键冲突会报错。 |
| 主键读取 | store.get(key) |
通过主键读取单条记录。 |
| 游标查询 | store.openCursor(range?, direction?) |
遍历仓库里的数据。 可以加范围 IDBKeyRange 限定查询区间,可选 next、prev 进行排序等。 |
| 索引查询 | store.index(index_name).get(value) |
通过索引来查询数据。 |
| 更新数据 | store.put(value, key?) |
新增或更新数据。 主键存在时覆盖,主键不存在时插入。 |
| 删除数据 | store.delete(key) |
按主键删除一条记录。 |
| 关闭数据库 | db.close() |
关闭当前连接的数据库。 |
| 删除数据库 | indexedDB.deleteDatabase(name) |
删除整个数据库,异步操作。 |
使用场景
大数据量存储
用途 :localStorage 存储容量太小(5MB 左右),IndexedDB 可以存储 几十 MB 到 GB 级别 的结构化数据。
示例:
- 大型游戏资源文件(图片、音频)本地缓存
- 电子书阅读器(如 EPUB 本地解包缓存)
- 地图数据(如离线地图块)
媒体文件本地缓存与处理
用途:存储 Blob(二进制文件)如图片、视频、音频等,支持文件分片、断点续传。
示例:
- 上传视频断点续传
- 摄像头采集数据缓存
- 本地图像编辑器(如 Canva 离线草稿)
表单缓存 & 自动保存草稿
用途:提升用户体验,避免表单丢失或中断填写。
示例:
- 电商下单流程信息暂存
- 博客撰写时自动保存草稿
- 简历填写进度记录
加速应用启动 & 网络请求优化
用途:将请求数据缓存到本地,提高首次加载速度,并减少网络请求。
示例:
- 首页卡片数据缓存(推荐列表等)
- 配置项缓存(字典数据、地区树等)
- 用户访问记录或预热数据
数据分析 & 可视化缓存
用途:本地缓存数据后用于图表绘制、趋势分析,避免每次请求都重新拉取。
示例:
- 工业/物联网设备数据记录
- 股票行情本地分析
- 仪表盘历史数据对比
离线应用(Offline Web App / PWA)
用途:在无网络或网络不稳定时,仍能访问和操作数据。
示例:
- TodoList、笔记类 App(如 Notion 离线)
随心记demo:suixin-note.netlify.app/- Markdown 编辑器(如 StackEdit)
- CRM 表单数据暂存,网络恢复后再同步
总结
- 轻量级增强:表单缓存、草稿、配置缓存
- 中量级存储:电商订单列表缓存、离线地图块
- 重量级存储:视频分片、PDF、图像编辑器草稿、PWA 离线应用