前端性能优化之 HTTP/2 多路复用
回顾 HTTP/1.x 的队头阻塞问题
要理解多路复用的重要性,我们首先要回顾一下 HTTP/1.x 的工作模式。
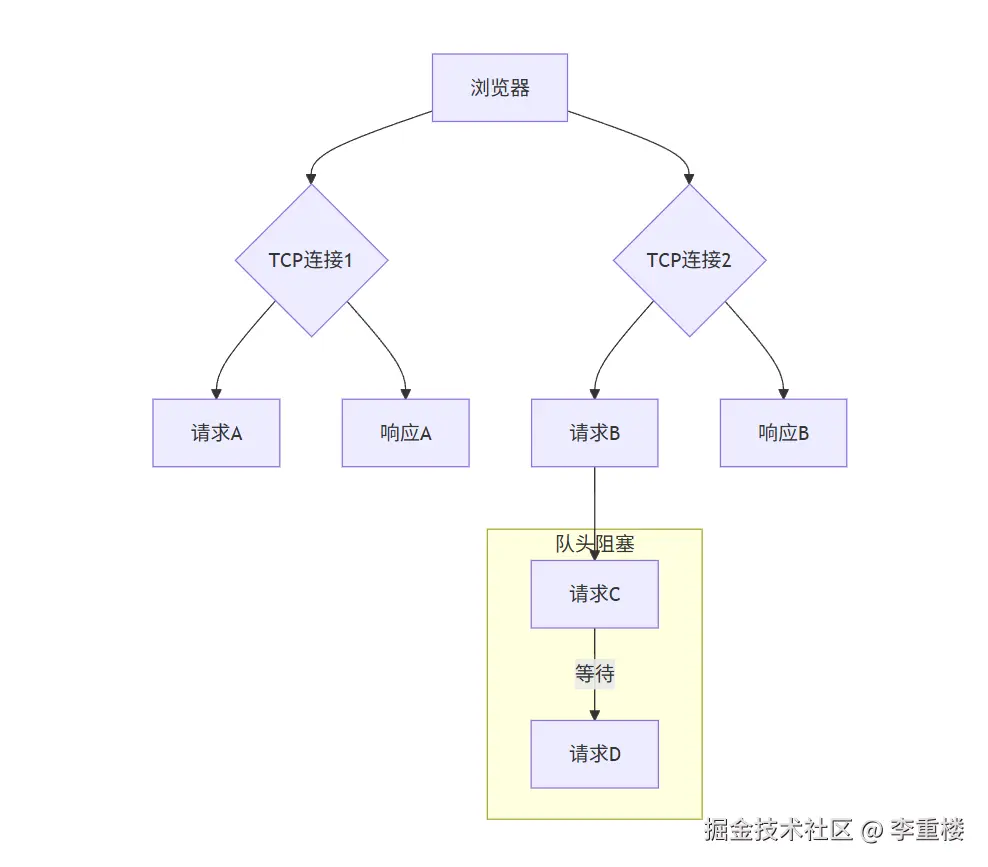
在 HTTP/1.x 中,浏览器在同一时间,只能对同一个域名建立有限数量的 TCP 连接(通常是 6-8 个)。而每个 TCP 连接,一次只能处理一个 HTTP 请求。
这种模式导致了一个严重的问题:队头阻塞(Head-of-Line Blocking) 。
想象一下站在一条单行道的隧道入口,前面有一辆慢悠悠的卡车。虽然身后有许多快速的跑车,但它们都必须排队,等待前面的卡车通过。
在 HTTP/1.x 中,这个"卡车"就是前面那个正在处理的 HTTP 请求。如果一个请求因为某种原因(比如服务器处理慢、网络延迟高)迟迟没有返回,那么它后面的所有请求,即使它们已经准备就绪,也必须等待,无法被处理。
为了解决这个问题,HTTP/1.x 引入了并发连接,允许浏览器同时建立多个 TCP 连接。但这治标不治本,因为并发连接数有限,而且创建和维护额外的 TCP 连接会带来额外的开销。
HTTP/2 多路复用的核心原理
HTTP/2 引入了二进制分帧 (Binary Framing)的概念,核心思想是:在一个 TCP 连接上,可以同时传输多个 HTTP 请求和响应。
这就像把之前的单行道隧道,变成了一条多车道的高速公路。每辆车(每个请求或响应)都有自己的"车道",互不影响,可以并行通过。
它将所有通信数据流都拆分成小的、独立的帧(Frames) :
- 流(Streams) :每个 HTTP 请求和响应都被拆分为一个个独立的"流"。流是双向的,可以并行传输。
- 消息(Messages) :一个完整的请求或响应,由一个或多个帧组成。
- 帧(Frames) :通信的最小单位,包含类型、标志位、流标识符等信息。
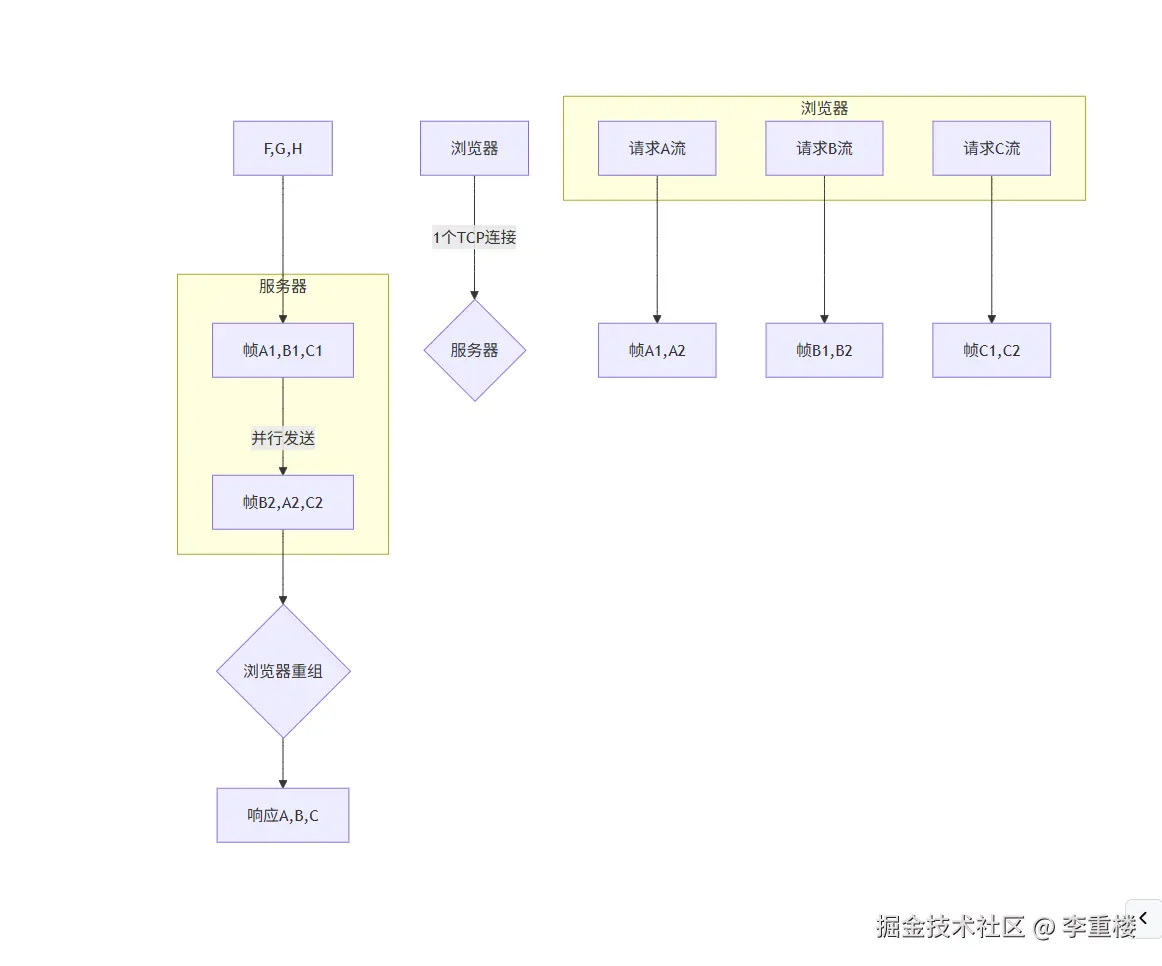
当浏览器发起请求时,它会为每个请求分配一个唯一的"流标识符"。请求数据被拆分成多个帧,这些帧可以乱序发送。当服务器接收到这些帧时,会根据流标识符重新组装,还原出完整的请求。
同样,服务器返回的响应数据也会被拆分为帧,乱序发送给浏览器,浏览器再根据流标识符重组。
由于所有数据都封装在一个 TCP 连接中,并且每个帧都有自己的标识,所以浏览器和服务器可以自由地交错发送和接收多个请求的帧,从而实现了真正的并行通信。
理解模型
- 浏览器:始发地(货物发送方)。
- 服务器:终点(货物接收方)。
- TCP 连接 :一条多车道的高速公路。这是 HTTP/2 的核心,所有的通信都通过这一条高速公路进行,避免了 HTTP/1.x 时代频繁开辟新"单车道小路"的低效。
- 流(Streams) :高速公路上的多条独立车道。每个请求和响应都拥有自己的车道,它们可以并行地、互不干扰地行驶。
- 请求/响应(Messages) :一定量的货物。这是一个完整的逻辑单元,比如一个完整的图片文件、一个 CSS 文件或一个 JSON 数据。
- 帧(Frames) :运输货物的车辆。每个请求和响应(货物)都会被拆解成许多小的二进制帧(车辆),这些车辆带有唯一的"流 ID",标识它们属于哪条车道。
- 乱序到达与重组:不同车道上的车辆(帧)可以交错行驶,甚至乱序到达。但在终点(服务器或浏览器),接收方会根据每个车辆携带的"流 ID"标签,将属于同一条车道的所有车辆重新组合,从而还原出完整的货物。只有当所有车辆都到达,货物才算完整送达。
对比 HTTP/1.x:
- HTTP/1.x :没有多车道高速公路,只有多条单车道小路。
- 请求/响应:每送一个货物,就必须开辟一条新的小路。
- 队头阻塞:如果第一辆车(第一个请求)在路上出了故障(网络延迟),那么这条小路上所有的车都必须停下来,等待故障排除,即使它们本身没有任何问题。
浏览器最大并发请求数限制
HTTP/2 时代:流(Streams)并发限制
HTTP/2 的核心是多路复用(Multiplexing) ,它在一个 TCP 连接上可以同时处理多个请求和响应。
那么,为什么浏览器还要限制流的数量呢?这个限制并非为了解决队头阻塞,而是出于以下几个主要原因:
- 服务器资源保护 服务器需要为每个并发的流分配内存和计算资源。一个服务器不可能无限地处理请求。如果浏览器没有限制,一次性发送数千个流,服务器可能会因资源耗尽而崩溃。这个限制实际上是服务器为防止过载而设定的。
- 浏览器资源保护 浏览器同样需要为每个并发的流分配资源。管理数百甚至数千个同时进行的请求会占用大量的内存和 CPU。设置一个合理的上限可以防止浏览器卡顿甚至崩溃。
- 流量控制与网络拥塞 虽然 HTTP/2 解决了应用层的队头阻塞,但底层 TCP 协议依然存在流量控制(Flow Control)和拥塞控制(Congestion Control) 。如果一条 TCP 连接上的数据量过大,TCP 协议会减慢数据传输速度,导致所有流都变慢。限制并发流的数量,有助于避免过度的网络拥塞。
- 实际需求 在大多数情况下,一个页面上的并发请求数量通常不会超过这个上限(通常在 100-200 个)。一个合理的限制既能满足大多数页面的需求,又能保证系统稳定性。
HTTP/1.x 时代:TCP 连接限制
在 HTTP/1.x 中,浏览器限制的是对同一个域名 建立的最大 TCP 连接数,通常为 6-8 个。
之所以有这个限制,是因为 HTTP/1.x 存在一个严重的**队头阻塞(Head-of-Line Blocking)**问题。在一个 TCP 连接上,一次只能处理一个请求和响应。如果前面的请求因为网络或服务器原因迟迟没有完成,后面的请求就必须排队等待,即使它们的数据量很小。为了缓解这个问题,浏览器不得不开启多个连接来并行处理请求。但无限开启连接会消耗大量的系统资源(如内存、CPU),因此浏览器设定了一个硬性上限。
对前端开发的影响
HTTP/2 的多路复用,是前端性能优化的一个重大转折点。它对传统的"性能优化黄金法则"产生了深远影响:
- 减少请求数不再是首要任务 :在 HTTP/1.x 时代,我们通过精灵图(Sprite)、文件合并(JS/CSS Bundling)等方式来减少 HTTP 请求数,以避免队头阻塞和并发连接数的限制。但在 HTTP/2 中,请求数本身带来的开销大大降低,所以我们可以大胆地将文件拆分为更小、更细粒度的模块,实现按需加载。
- 域名分片(Domain Sharding)失去意义:为了突破浏览器对同一域名 6-8 个连接数的限制,我们曾将资源分散到多个子域名下。在 HTTP/2 中,所有资源都可以通过一个 TCP 连接传输,域名分片反而会增加额外的 DNS 解析和 TCP 连接开销,得不偿失。
- HTTP/2 Push :多路复用为服务器推送(Server Push)奠定了基础。服务器可以在浏览器请求 HTML 页面时,提前将页面所需的 CSS、JS 等资源主动推送给浏览器,而无需等待浏览器发起二次请求。这进一步减少了网络延迟。
因此,在 HTTP/2 时代,前端性能优化的重点已经从减少请求数 转向了合理拆分资源 和优化单个资源的大小。
例如,可以大胆地将 CSS 和 JavaScript 文件拆分成更小的模块,实现按需加载,从而更好地利用 HTTP/2 的多路复用优势。
总结
HTTP/2 多路复用通过在一个 TCP 连接上并行传输多个请求和响应,彻底解决了 HTTP/1.x 的队头阻塞问题。它让前端开发者可以将注意力从"减少请求数"转移到"按需加载和合理拆分资源"上,从而构建更现代化、性能更优的 Web 应用。
by lichonglou