
引言
那天我正对着电脑假装敲代码,实则偷偷刷短视频摸鱼,运营部的小美突然凑过来,声音甜得能齁死人:
"哥~我这儿有 200 多个文档 URL,得把每个标题都抄下来,手动复制快把我手戳酸了,嘤嘤嘤~"
我斜眼瞥了眼她手里的 Excel,心里嘀咕:这标题肯定存在某个数据库里啊,但我哪知道存哪儿?作为一个只会切页面的 "前端仔",只能硬装高冷:"没辙,只能手动复制。"
小美瞬间垮了脸,像只泄了气的小气球:"好吧..." 转身要走,又突然眼睛一亮跑回来:"哥!爬虫能爬吗?" 说着还眨了眨她的卡姿兰大眼睛,满是期待。
我心里咯噔一下:爬虫? 听着就像黑客大佬玩的活,海量数据随手拈来,可我连爬虫的门都没摸过啊!但看着小美期待的眼神,要是说不会,我之前在她心里 "技术大神" 的形象不就崩了?
还没等我组织语言,小美好像看出了我的为难,赶紧打圆场:"算啦算啦,可能爬虫也没那么好用,我还是慢慢复制吧,不打扰你啦~"
她踩着高跟鞋刚转身,我突然扯住她的包带:"等等!"
小美一脸诧异地回头,我喉结滚动,扯了扯领口:"这... 这堆标题,我来爬!"
她眼睛瞬间亮得像装了灯泡:"真的假的?别逗我啊!"
我硬着头皮梗着脖子:"我什么时候骗过你?明天早上,保证把数据甩你桌上!"
(偷偷摸出手机,百度框疯狂输入:"Puppeteer 爬虫教程 30 分钟速成")
她原地蹦了两下,马尾辫都跟着晃悠:"救命!你简直是我的神!"
而我表面淡定摆手,内心 OS:完犊子,这次要是翻车,以后公司茶水间都没脸去了。
屌丝逆袭开始
毕竟吹出去的牛,跪着也得实现。
在数据驱动的当下,批量扒数据这事儿说难不难,但对我这种 "半吊子" 来说,选对工具是关键。最后我盯上了 Puppeteer ------ 这玩意儿能控制浏览器自动化操作,正好适合爬需要登录的文档页面。
下面就跟大家唠唠,我是怎么用它搭了个爬取系统,保住男神形象的~
一、系统架构设计
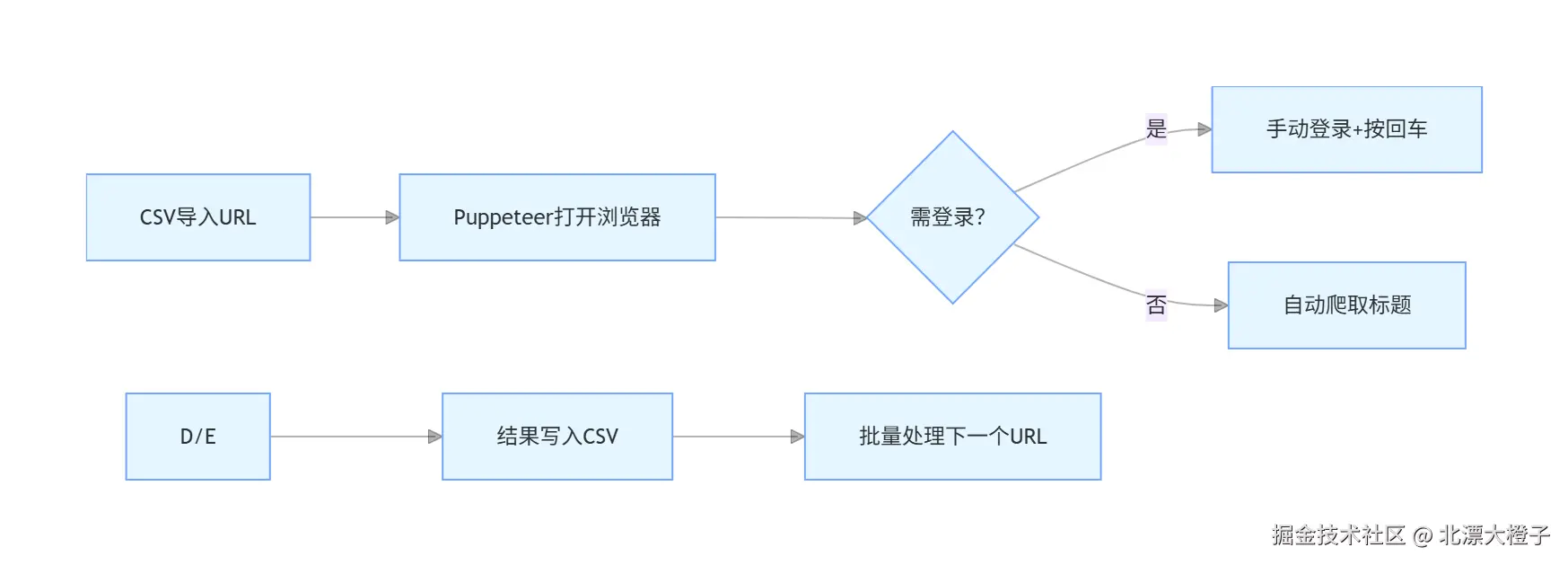
我搭的这个爬取系统,其实就是个 "懒人工具",核心就四个模块,简单粗暴:
✅ 浏览器自动化模块:靠 Puppeteer 驱动 Chrome,自动打开页面、扒标题,不用我手动点
✅ 数据管理模块:小美给的是 Excel,我先手动转成 CSV(谁让 CSV 比 Excel 好读多了),再用代码读 URL、写结果
✅ 用户交互模块:有些页面要登录,自动登录太麻烦(验证码、勾选协议全是坑),干脆让用户手动登,登完按回车继续
✅ 批量处理模块:把 URL 一个个喂给程序,爬完一个接一个,最后把结果汇总
二、核心技术实现
1. Puppeteer 浏览器自动化
Puppeteer 这玩意儿是真好用,用 Node.js 写几行代码就能控制 Chrome。
我刚开始配置的时候踩了不少坑,比如登录状态存不住,后来才调对参数:
js
const browser = await puppeteer.launch({
headless: false, // 非无头模式,便于查看登录过程
executablePath: executablePath, // 使用系统已安装的Chrome
userDataDir: './chrome-user-data', // 保存用户数据,包括登录状态
args: [
'--no-sandbox',
'--disable-setuid-sandbox',
'--disable-gpu',
'--disable-dev-shm-usage',
'--window-size=1920,1080'
]
});💡 踩坑提醒 :虽然加了 userDataDir 想保存登录状态,结果每次运行还是要重新登,估计是网站做了限制。算了,手动登就手动登,总比写一堆验证码逻辑强~
2. CSV 文件的读取与写入
处理 CSV 我用了 csv-parser 和 csv-stringify,一个读一个写,用流处理还不占内存,适合小美给的几百个 URL:
js
// 读取CSV文件中的URL
function readUrlsFromCsv(filePath) {
return new Promise((resolve, reject) => {
const urls = [];
fs.createReadStream(filePath)
.pipe(csv(['url']))
.on('data', (row) => {
urls.push(row.url);
})
.on('end', () => {
resolve(urls);
});
});
}
// 写入结果到CSV文件
function writeResultsToCsv(filePath, results) {
return new Promise((resolve, reject) => {
const output = fs.createWriteStream(filePath);
const stringifier = stringify({
header: true,
columns: ['url', 'finalTitle']
});
stringifier.pipe(output);
results.forEach(result => {
stringifier.write([result.url, result.finalTitle]);
});
stringifier.end();
});
}✨ 小技巧:当初小美给我 Excel 的时候,我差点直接用 Excel 处理库,后来发现转成 CSV 更简单,省了不少代码。果然 "偷懒" 才是技术进步的动力!
3. 登录状态管理与人工干预
最烦的就是登录!
我一开始想自动填账号密码,结果遇到验证码就算了,有的页面还得先勾 "我已阅读协议",各种奇葩情况,写代码兼容太费时间。
最后想了个笨办法:让程序检测到登录页就停下来,等用户手动登完再继续:
js
// 检查是否需要登录
const currentUrl = page.url();
if (currentUrl.includes('/login') || currentUrl.includes('auth') ||
currentUrl.includes('signin') || currentUrl.includes('sign-in')) {
console.log('检测到需要登录,请在浏览器中完成登录操作...');
// 等待用户手动登录
await askQuestion('登录成功后请按Enter键继续...');
// 登录完成后,重新访问确认登录状态
await page.goto(sampleUrl, {waitUntil: 'networkidle2'});
}虽然是笨办法,但管用啊!不管是验证码还是双因素认证,用户手动操作都能搞定,比写一堆复杂逻辑强多了,效率直接拉满~
4. 网页内容提取技术
扒标题的时候我先看了看页面结构,发现所有文档标题都在 id="doc-title" 的元素里,这就简单了!
用 Puppeteer 的 page.evaluate 直接在浏览器里拿内容:
js
// 提取标题和面包屑导航
const docTitle = await page.evaluate(() => {
const element = document.getElementById('doc-title');
return element ? element.textContent.trim() : '未找到doc-title元素';
});
const breadcrumb = await page.evaluate(() => {
const breadcrumbElement = document.querySelector('.breadcrumb_-XUU4');
if (breadcrumbElement) {
const links = breadcrumbElement.querySelectorAll('li a');
if (links.length > 0) {
const texts = Array.from(links).map(link => link.textContent.trim());
return texts.join('-');
}
}
return '未找到面包屑导航元素';
});我还加了 "兜底" 逻辑,要是元素没找到,就返回提示,省得程序直接崩了,到时候还得找 bug,太麻烦。
三、批量处理与性能优化
小美给了两百多个 URL,要是一个个慢慢爬,半天肯定搞不定。我加了几个小优化,速度快多了:
-
复用浏览器实例:只开一个 Chrome 窗口,爬每个 URL 的时候新建标签页,省得反复开浏览器,占内存还慢
-
控制爬取频率:每爬 10 个 URL 就停 3 秒,怕爬太快被网站封 IP,到时候就得不偿失了
-
错误容错:哪个 URL 爬失败了,就记录 "处理失败",不影响其他 URL,最后一起告诉小美
js
// 循环处理每个URL
for (let i = 0; i < urls.length; i++) {
const url = urls[i];
console.log(`处理URL ${i + 1}/${urls.length}`);
try {
const result = await getTitleForUrl(page, url);
results.push(result);
} catch (error) {
console.error(`处理URL失败 ${url}:`, error.message);
results.push({url, finalTitle: `处理失败: ${error.message}`});
}
// 频率控制
if ((i + 1) % 10 === 0) {
await page.waitForTimeout(3000);
}
}这么一改,不到一小时就爬完了所有 URL,比我预想的快多了!
四、用户友好的运行方式
小美对代码一窍不通,我得让她双击就能用。
于是写了个批处理文件,把 "装依赖""运行程序" 全集成了,还解决了 Windows 下中文乱码的问题(虽然最后为了快,直接输出英文了):
bash
@echo off
chcp 65001 >nul
rem 导航到当前脚本所在目录
cd /d %~dp0
rem 检查并安装依赖
pnpm install csv-parser csv-stringify
rem 执行爬虫程序
npm start
rem 程序运行完成后暂停
pause小美拿到后,双击图标就开始跑,不用管任何代码,完事儿还能看到结果,"小美点开 CSV 文件,哇了一声,给我递了杯热奶茶:'以后我就是你粉丝了!'" ~😘
五、代码优化建议
虽然这次救急成功了,但这代码还有不少可优化的地方,以后要是再遇到类似需求,能更省事:
🔧 并发爬取 :现在是一个一个爬,以后可以用 cluster 模块多开几个浏览器,同时爬,速度能再翻几倍
🔧 自动重试:有的 URL 可能因为网络问题爬失败,加个重试逻辑,失败了自动再爬一次
🔧 断点续爬:要是爬几百个 URL 中途断了,得从头再来,以后可以把爬过的结果存下来,下次接着爬
🔧 完善日志:现在就控制台输点信息,以后加个日志文件,哪个步骤错了,一看日志就知道
🔧 无头模式切换:给个参数,想看着爬就开窗口,想后台爬就开无头模式,更灵活
六、总结
这次用 Puppeteer 搭爬取系统,算是赶鸭子上架,但结果还不错 ------ 不仅帮小美解决了手酸的问题,还保住了我在她心里的 "技术大神" 形象。
这系统最适合爬那种需要登录的页面,还有批量提取数据的场景,比如爬商品信息、文档标题之类的。要是你们也遇到类似的麻烦,不妨试试 Puppeteer,上手不难,还能省不少力。
最后小美拿着爬好的标题,开开心心地去交差了,还说以后有技术问题再找我。嘿,这下不仅保住了形象,还多了个 "粉丝",值了!
互动时间
你们有没有过'用技术救急'的经历?比如帮同事做过批量处理工具、解决过重复劳动?评论区晒出你的'技术救急故事',抽 1 人送【前端入门电子书】
🐟️如果你的同事也在手动复制数据,转发这篇文章给他,一起省出时间摸鱼~🐟️