一、介绍
MinerU 是由上海人工智能实验室(OpenDataLab)团队开发的一款开源智能文档解析工具,专注于将复杂的PDF文档、网页和电子书内容,高效、精准地提取并转换为机器可读的结构化格式(如Markdown、JSON等),可以很方便地抽取为任意格式。
主要功能
- 删除页眉、页脚、脚注、页码等元素,确保语义连贯
- 输出符合人类阅读顺序的文本,适用于单栏、多栏及复杂排版
- 保留原文档的结构,包括标题、段落、列表等
- 提取图像、图片描述、表格、表格标题及脚注
- 自动识别并转换文档中的公式为 LaTeX 格式
- 自动识别并转换文档中的表格为 HTML 格式
- 自动检测扫描版 PDF 和乱码 PDF,并启用 OCR 功能
- OCR 支持 84 种语言的检测与识别
- 支持多种输出格式,如多模态与 NLP 的 Markdown、按阅读顺序排序的 JSON、含有丰富信息的中间格式等
- 支持多种可视化结果,包括 layout 可视化、span 可视化等,便于高效确认输出效果与质检
- 支持纯 CPU 环境运行,并支持 GPU(CUDA)/NPU(CANN)/MPS 加速
- 兼容 Windows、Linux 和 Mac 平台
二、部署
1、基础环境
- Miniconda3
- Ubuntu:22.04
- cuda12.4.1
- 4090D
2、安装 MinerU
通过源码安装MinerU,首先创建虚拟环境,然后安装UV,克隆MinerU的源码,最后UV来安装
bash
conda create -n mineru python=3.12 -y
conda activate mineru
pip install uv -i https://mirrors.aliyun.com/pypi/simple
git clone https://github.com/opendatalab/MinerU.git
cd MinerU
uv pip install -e .[all] -i https://mirrors.aliyun.com/pypi/simple3、模型下载
MinerU默认使用huggingface作为模型源,若用户网络无法访问huggingface,可以通过环境变量便捷地切换模型源为modelscope;
ini
export MINERU_MODEL_SOURCE=modelscope使用命令下载模型到本地,查看命令使用情况。下载好的模型目录通过 mineru.json 来调用,ineru.json 文件会在您使用内置模型下载命令 mineru-models-download 时自动生成,生成在用户目录,当前使用root用户,生成位置为 /root/mineru.json。
bash
mineru-models-download --help
mineru-models-download默认模型下载位置,若需要修改模型位置,可以移动模型到其它位置,然后修改 mineru.json文件。

4、推理框架
-
pipeline:代码中集成,不需要启动后端
-
vlm-transformers:代码中集成,不需要启动后端
-
vlm-sglang(推荐):需要启动后端,速度快
cssmineru-sglang-server --port 30000 --model-path /root/.cache/modelscope/hub/models/OpenDataLab/MinerU2___0-2505-0___9B --max-running-requests 64 --mem-fraction-static 0.75 --weight-loader-disable-mmap
5、使用
通过fast api 方式调用。
css
mineru-api --host 0.0.0.0 --port 8080通过访问 /docs 可以查看调用方式。
(推荐)使用gradio webui。
css
mineru-gradio --server-name 0.0.0.0 --server-port 8080-
在浏览器中访问
http://127.0.0.1:8080使用 Gradio WebUI。 -
访问
http://127.0.0.1:8080/?view=api使用 Gradio API。 -
已修改默认使用
sglang环境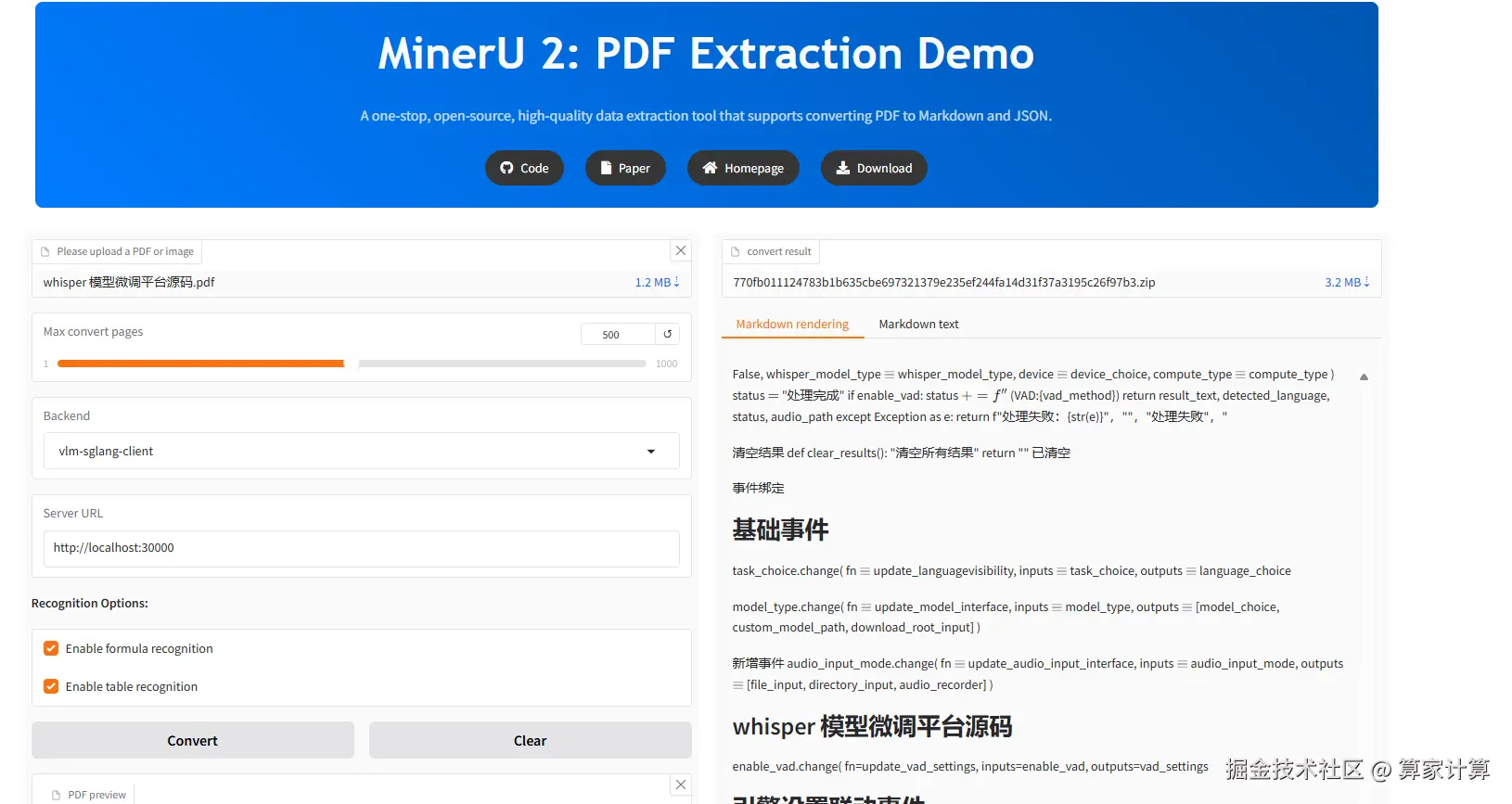
5、配置文件扩展 MinerU 功能
通过编辑用户目录下的 mineru.json 文件,添加自定义配置。
latex-delimiter-config:用于配置 LaTeX 公式的分隔符,默认为$符号,可根据需要修改为其他符号或字符串。llm-aided-config:用于配置 LLM 辅助标题分级的相关参数,兼容所有支持openai协议的 LLM 模型,默认使用阿里云百炼的qwen2.5-32b-instruct模型,您需要自行配置 API 密钥并将enable设置为true来启用此功能。models-dir:用于指定本地模型存储目录,请为pipeline和vlm后端分别指定模型目录,指定目录后您可通过配置环境变量export MINERU_MODEL_SOURCE=local来使用本地模型。