1. TC 的基本原理
流量控制 Traffic Control (TC),表示网络设备接收和发送数据包的排队机制。比如,数据包的接收速率、发送速率、多个数据包的发送顺序等。
Linux 实现了流量控制子系统,它包括两部分:
- 内核部分的 traffic control 框架
- 用户态的规则配置工具:iproute2 软件包中的 tc 程序
它们有些类似于内核态的 netfilter 框架和用户态的 iptables 程序。但相较于 netfilter, 关于 tc 的资料非常少,并且也较为古老,彻底理解它的机制还是需要对照源码。
Traffic Control 的作用包括以下几种:
-
调整(Shaping): 通过推迟数据包发送来控制发送速率,只用于网络出方向(egress)
-
时序(Scheduling):调度不同类型数据包发送顺序,比如在交互流量和批量下载类型数据包之间进行发送顺序的调整。只用于网络出方向(egress)
-
监督(Policing): 根据到达速率决策接收还是丢弃数据包,用于网络入方向(ingress)
-
丢弃(Dropping): 根据带宽丢弃数据包,可以用于出入两个方向
要实现对数据包接收和发送的这些控制行为,需要使用队列结构来缓存数据包。
在Linux实现中,把这种包括数据结构和算法实现的控制机制抽象为结构队列规程 : Queuing discipline,简称为 qdisc。
qdisc 对外暴露两个回调接口:
- enqueue
- dequeue
分别用于数据包入队和数据包出队。
而具体的排队算法实现则在 qdisc 内部隐藏。
不同的 qdisc 实现在 Linux内核中实现为不同的内核模块,在系统的内核模块目录里可以查看前缀为 sch_ 的模块:
bash
▶ ls -l /usr/lib/modules/6.1.0-38-amd64/kernel/net/sched/sch_*
-rw-r--r-- 1 root root 63299 Aug 2 21:13 /usr/lib/modules/6.1.0-38-amd64/kernel/net/sched/sch_cake.ko
-rw-r--r-- 1 root root 30171 Aug 2 21:13 /usr/lib/modules/6.1.0-38-amd64/kernel/net/sched/sch_cbs.ko
-rw-r--r-- 1 root root 21411 Aug 2 21:13 /usr/lib/modules/6.1.0-38-amd64/kernel/net/sched/sch_choke.ko
-rw-r--r-- 1 root root 21507 Aug 2 21:13 /usr/lib/modules/6.1.0-38-amd64/kernel/net/sched/sch_codel.ko
-rw-r--r-- 1 root root 32027 Aug 2 21:13 /usr/lib/modules/6.1.0-38-amd64/kernel/net/sched/sch_drr.ko
-rw-r--r-- 1 root root 23347 Aug 2 21:13 /usr/lib/modules/6.1.0-38-amd64/kernel/net/sched/sch_etf.ko
-rw-r--r-- 1 root root 38411 Aug 2 21:13 /usr/lib/modules/6.1.0-38-amd64/kernel/net/sched/sch_ets.ko
-rw-r--r-- 1 root root 33627 Aug 2 21:13 /usr/lib/modules/6.1.0-38-amd64/kernel/net/sched/sch_fq.ko
-rw-r--r-- 1 root root 27499 Aug 2 21:13 /usr/lib/modules/6.1.0-38-amd64/kernel/net/sched/sch_fq_pie.ko
-rw-r--r-- 1 root root 37099 Aug 2 21:13 /usr/lib/modules/6.1.0-38-amd64/kernel/net/sched/sch_gred.ko
-rw-r--r-- 1 root root 48363 Aug 2 21:13 /usr/lib/modules/6.1.0-38-amd64/kernel/net/sched/sch_hfsc.ko
-rw-r--r-- 1 root root 22787 Aug 2 21:13 /usr/lib/modules/6.1.0-38-amd64/kernel/net/sched/sch_hhf.ko
-rw-r--r-- 1 root root 65883 Aug 2 21:13 /usr/lib/modules/6.1.0-38-amd64/kernel/net/sched/sch_htb.ko
-rw-r--r-- 1 root root 17739 Aug 2 21:13 /usr/lib/modules/6.1.0-38-amd64/kernel/net/sched/sch_ingress.ko
-rw-r--r-- 1 root root 24963 Aug 2 21:13 /usr/lib/modules/6.1.0-38-amd64/kernel/net/sched/sch_mqprio.ko
-rw-r--r-- 1 root root 24443 Aug 2 21:13 /usr/lib/modules/6.1.0-38-amd64/kernel/net/sched/sch_multiq.ko
-rw-r--r-- 1 root root 37707 Aug 2 21:13 /usr/lib/modules/6.1.0-38-amd64/kernel/net/sched/sch_netem.ko
-rw-r--r-- 1 root root 26211 Aug 2 21:13 /usr/lib/modules/6.1.0-38-amd64/kernel/net/sched/sch_pie.ko
-rw-r--r-- 1 root root 11627 Aug 2 21:13 /usr/lib/modules/6.1.0-38-amd64/kernel/net/sched/sch_plug.ko
-rw-r--r-- 1 root root 24915 Aug 2 21:13 /usr/lib/modules/6.1.0-38-amd64/kernel/net/sched/sch_prio.ko
-rw-r--r-- 1 root root 50491 Aug 2 21:13 /usr/lib/modules/6.1.0-38-amd64/kernel/net/sched/sch_qfq.ko
-rw-r--r-- 1 root root 31867 Aug 2 21:13 /usr/lib/modules/6.1.0-38-amd64/kernel/net/sched/sch_red.ko
-rw-r--r-- 1 root root 27227 Aug 2 21:13 /usr/lib/modules/6.1.0-38-amd64/kernel/net/sched/sch_sfb.ko
-rw-r--r-- 1 root root 31531 Aug 2 21:13 /usr/lib/modules/6.1.0-38-amd64/kernel/net/sched/sch_sfq.ko
-rw-r--r-- 1 root root 14955 Aug 2 21:13 /usr/lib/modules/6.1.0-38-amd64/kernel/net/sched/sch_skbprio.ko
-rw-r--r-- 1 root root 62299 Aug 2 21:13 /usr/lib/modules/6.1.0-38-amd64/kernel/net/sched/sch_taprio.ko
-rw-r--r-- 1 root root 28755 Aug 2 21:13 /usr/lib/modules/6.1.0-38-amd64/kernel/net/sched/sch_tbf.ko
-rw-r--r-- 1 root root 23555 Aug 2 21:13 /usr/lib/modules/6.1.0-38-amd64/kernel/net/sched/sch_teql.ko简单来说
qdisc 的实现可以非常简单,比如只包含单个队列,数据包先进先出,如: pfifo, 代码位于 net/sched/sch_fifo.c。
复杂的情况
也可以实现相当复杂的调度逻辑。比如,可以根据数据包的属性进行过滤分类,而针对不同的分类:
- class 采用不同的算法来进行处理。
- class 可以理解为 qdisc 的载体,它还可以包含子类与 qdisc。
- 用来实现过滤逻辑的组件叫做 filter,也叫做分类器 classfier, 它需要挂载在 qdisc 或者 class 上。
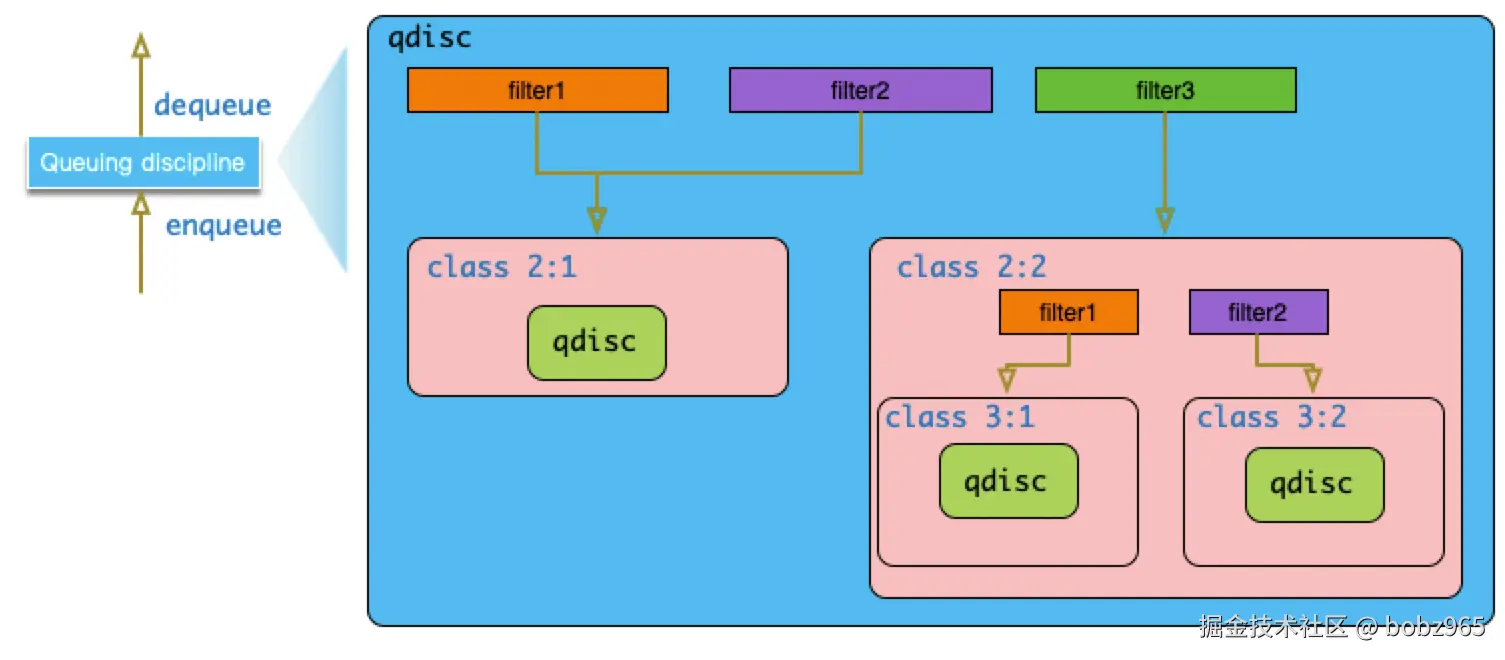
基于 qdisc, class 和 filter 种三元素可以构建出非常复杂的树形 qdisc 结构,极大扩展流量控制的能力。
对于树形结构的 qdisc, 当数据包流程最顶层 qdisc 时,会层层向下递归进行调用:
- 比如,父对象(qdisc/class)的 enqueue 回调接口被调用 时,其上所挂载的所有 filter 依次被调用,直到一个 filter 匹配成功。
- 然后将数据包入队到 filter 所指向的 class,具体实现则是调用 class 所配置的 Qdisc 的 enqueue 函数 。没有成功匹配 filter 的数据包分类到默认的 class 中。
大约在 2015 年的时候,TC 框架实现中又加入了 Classifier-Action 机制。上文提到的 filter 实际作用就是 classifier,当数据包匹配到特定的 filter 之后,可以执行该 filter 所挂载的 actions 对数据包进行处理。
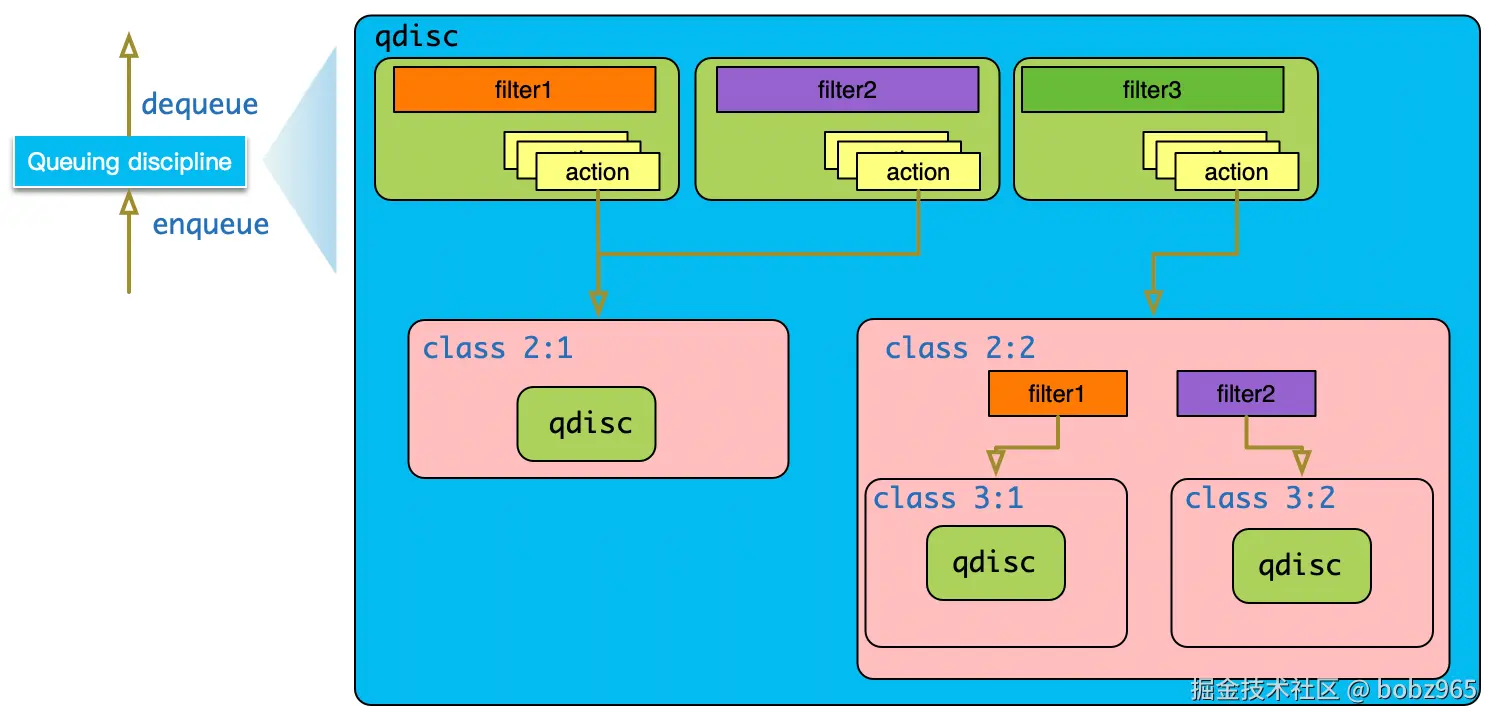
filter 和 action 也可以实现为独立的内核模块,tc 框架的扩展性非常灵活。
一个网络接口有两个默认的 qdisc 锚点。
- 入方向的锚点叫做 ingress,
- 出方向叫做 root。
入方向的 ingress 功能比较有限,不能挂载其他的 class,只是做为Classifier-Action 机制的挂载点。
2. TC 的锁竞争问题
Linux 内核 tc(流量控制)的锁竞争,本质是多个执行单元(进程/软中断)同时申请操作共享资源(如 qdisc、filter 结构)的锁,导致彼此阻塞等待的现象。
其具体原理可拆解为以下3个核心环节:
1. 共享资源的必然存在
tc 操作的核心数据结构(如队列规则 qdisc、过滤器 filter、流量分类 class)是全局或设备级别的共享资源。例如:
- 用户通过
tc命令行工具(用户态进程)修改网卡的 qdisc 配置。 - 内核软中断(如
NET_RX_SOFTIRQ)在处理数据包时,会实时访问该 qdisc 进行流量调度。 这些不同执行单元的操作目标是同一份数据,必须通过锁来保证操作的原子性(避免数据错乱)。
2. 锁的"排他性"引发等待
为保护共享资源,tc 模块会使用内核锁(如 spinlock_t 自旋锁)。这类锁的核心特性是排他性:
- 当执行单元 A 成功获取锁后,会持有锁并操作共享资源。
- 若此时执行单元 B 也尝试获取同一把锁,会因锁已被占用而进入等待状态(自旋锁会循环等待,互斥锁会睡眠)。 这种"一人占用、他人等待"的机制,就是锁竞争的直接表现。
3. 高并发场景放大竞争
锁竞争的严重程度与资源访问频率正相关,以下场景会显著加剧竞争:
- 高数据包吞吐量:软中断频繁访问 qdisc 进行封包/调度,持续占用锁。
- 频繁配置变更 :用户态进程反复执行
tc add/del命令,频繁申请锁以修改配置。 - 多 CPU 核心并行:不同核心上的软中断/进程同时发起对同一锁的请求,冲突概率大幅提升。
例如,在 10G 网卡高流量场景下,软中断每秒可能上万次访问 qdisc 锁;若此时管理员频繁执行 tc 配置命令,用户态进程会与软中断激烈争夺同一把锁,导致软中断等待锁的时间变长,最终表现为网络延迟增加、吞吐量下降。
3. 如何解决该锁竞争
解决 Linux 内核 tc 的锁竞争问题,核心思路是减少锁的持有时间、降低锁的竞争频率、优化锁的粒度,具体可通过以下四类方案实现:
一、优化锁本身的设计与使用
这是从内核底层机制层面的优化,需修改 tc 模块源码,核心是让锁"更高效"。
- 缩小锁粒度 :将原有的全局/设备级大锁,拆分为针对单个
qdisc、class或filter的细粒度锁。例如,不同网卡的qdisc用独立锁保护,避免一个网卡的操作阻塞所有网卡。 - 替换锁类型 :根据场景选择更合适的锁。例如,将长时间持有(如配置修改)的
spinlock(自旋锁,忙等)替换为mutex(互斥锁,睡眠),避免软中断长时间自旋占用 CPU;对只读操作,使用rwlock(读写锁),允许多个读操作并发,仅阻塞写操作。 - 缩短锁持有时间 :将锁保护范围内的非核心操作(如统计数据计算、打印调试信息)移到锁外执行,仅在修改共享数据结构(如
qdisc的队列长度、filter的匹配规则)时持有锁。
二、优化 tc 配置与使用策略
这是用户/管理员可直接操作的层面,通过规避高竞争场景减少冲突。
- 减少配置变更频率 :避免在高流量场景下频繁执行
tc add/del/change等命令。例如,提前规划好流量控制策略,一次性配置完成,而非动态频繁调整。 - 简化
tc规则复杂度 :- 避免使用过多层级的
class(如嵌套多层 HTB/CBQ),减少锁的嵌套持有和访问路径。 - 用更高效的过滤器(如
clsact结合bpf)替代复杂的u32多级匹配,降低每次数据包处理时的锁访问次数。
- 避免使用过多层级的
- 分散资源竞争 :将高流量的应用流量分散到不同的网卡或
qdisc实例中。例如,通过网卡绑定(RSS)将不同端口的流量分配到不同 CPU 核心,配合mq(多队列)qdisc,让每个核心的软中断仅操作本地队列的锁,减少跨核心竞争。
三、利用 BPF 技术实现无锁/低锁逻辑
eBPF(扩展 Berkeley 包过滤器)是近年解决内核网络性能问题的关键技术,可绕过传统 tc 的锁竞争瓶颈。
- 核心原理 :将流量分类、限速等逻辑通过 BPF 程序直接加载到内核的数据包处理路径(如
clsact钩子),BPF 程序运行在无锁或低锁环境中,无需频繁访问tc的共享数据结构。 - 优势 :BPF 程序执行高效且隔离性强,不同程序间无共享资源竞争;同时支持动态加载,兼顾灵活性与性能。例如,用 BPF 实现的
htb或fq_codel变体,可大幅降低锁的使用频率。
四、升级内核版本与使用优化补丁
Linux 内核社区持续优化 tc 模块的锁机制,新内核版本常包含性能改进。
- 升级到最新稳定版 :例如,5.10+ 内核对
qdisc的锁粒度、软中断调度做了多项优化;5.15+ 进一步增强了 BPF 与tc的整合,减少锁依赖。 - 应用针对性补丁 :对于特定场景(如高并发
tc配置),可关注内核邮件列表(LKML)或第三方厂商(如 Intel、Red Hat)发布的优化补丁,解决特定锁竞争问题。
总结
实际优化中,通常优先从配置层面(方案二) 快速规避问题;若性能仍不满足,再考虑BPF 改造(方案三) ;对于内核开发者或深度优化场景,才需要涉及锁机制重构(方案一)。升级内核(方案四)则是低成本获取社区优化成果的基础手段。
参考: