前两天百度在海外账号介绍了轻量级文字识别模型 PP-OCRv5。看到"OCR"让我想起打工时的经历。
公司的主产品需要车牌识别,本该有技术储备,但早期为了快,功能是外购的,后来才有人手研发。
当时有两种方案:
- 主流做法:训练车牌识别模型。
- 另类做法:用 OpenCV 计算出车牌的位置,再识别里面的文字,但效果一般。
生产环境自然走主流路线:拍照收集数据 → 请人标记车牌 → 训练模型。
为了减轻标注工作量,我们还用 OpenCV 先自动框选车牌,再人工微调。但整个流程既繁琐又低效。识别率不高,就得不断换图、改算法、重新标记、重新训练。对中小公司来说,既耗力又不讨好。真佩服当时的手段和力气。

这两年多模态大模型很火,领导说以后直接用大模型就能搞定车牌识别。我微微一笑"领导英明"。
其实,用多模态大模型识别车牌未免有点"大炮打蚊子",而且不够精准、低效、成本高。
专业的事交给专业的模型。文字识别该用 OCR,而不是多模态大模型。
🔍 PP-OCRv5是什么东东?
不查不知道,一查吓一跳。PP-OCRv5 是最新训练出来的OCR模型,而在背后调用这个模型的工具叫 PaddleOCR。PaddleOCR 在 GitHub 上的 Star 已经达到 55K,从2020年开源至今,下载量超过900万次。在OCR圈名副其实的国产第一!

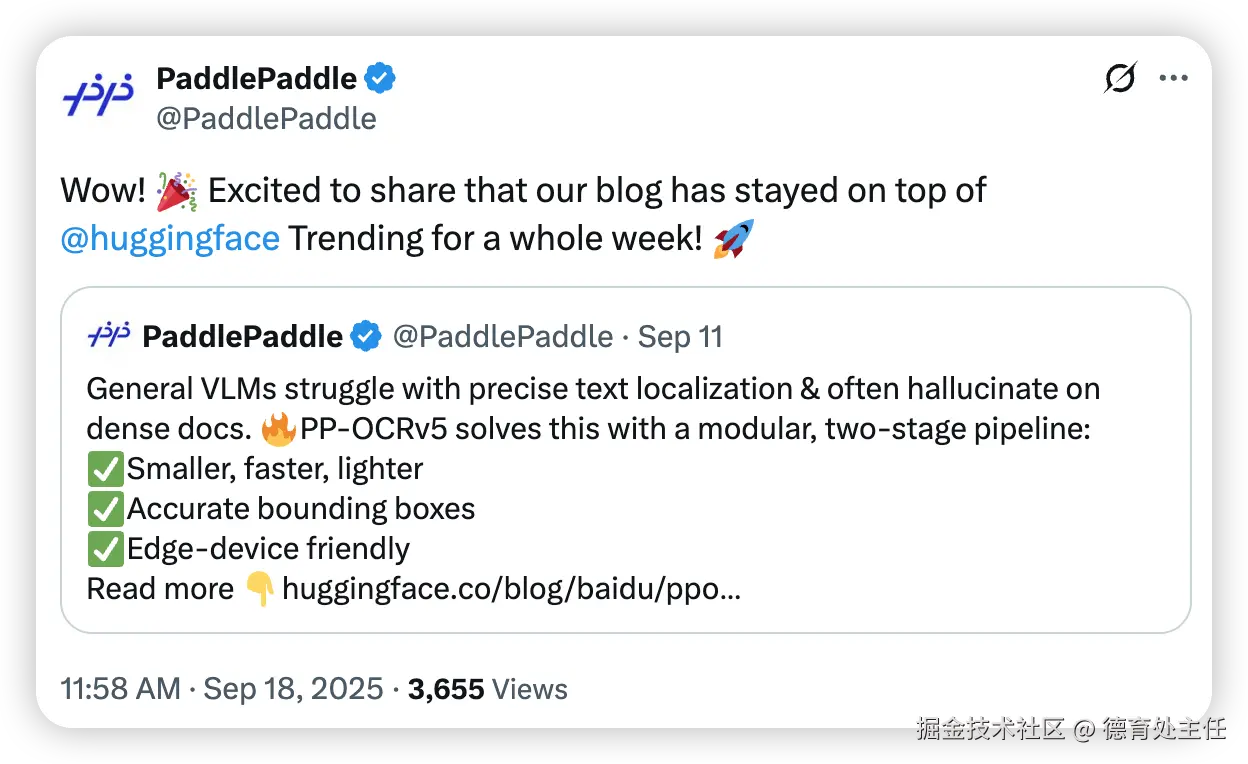
新鲜出炉的 PP-OCRv5 是 PP-OCR 的第5个版本,仅有 0.07B 参数,做到了媲美 700 亿参数 大模型 的 OCR 精度。 极致轻量,使计算开销和部署成本远低于大型多模态模型。
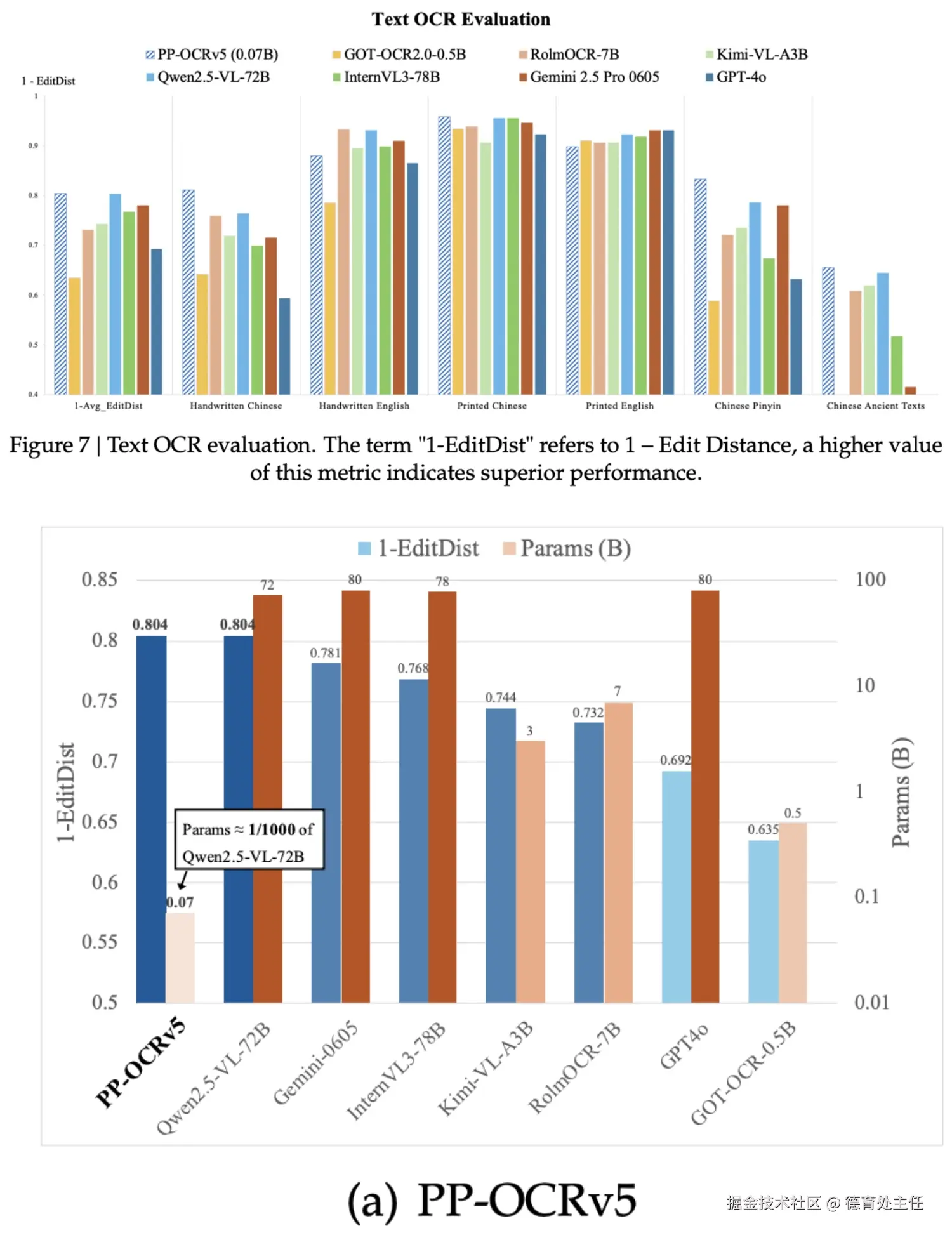
PP-OCRv5 极致轻量到底有多轻?
安卓摄影旗舰机拍一张照片2-5MB,半画幅微单一张照片20-30MB,高端点的全画幅接近100MB,最近新出的哈苏X2D II一张照片超200MB。
PP-OCR v5 只有70M,分分钟照片还比它还要大。今天想买个70MB这么小的U盘都买不到了。
🧐 是驴子还是千里马,试试就知道
用0.07B的参数训练出来的 PP-OCRv5 在 OCR 方面真的能和700亿参数的大模型分庭抗礼吗?试试就知道了。
这是 PP-OCRv5 的体验地址👉 aistudio.baidu.com/community/a...
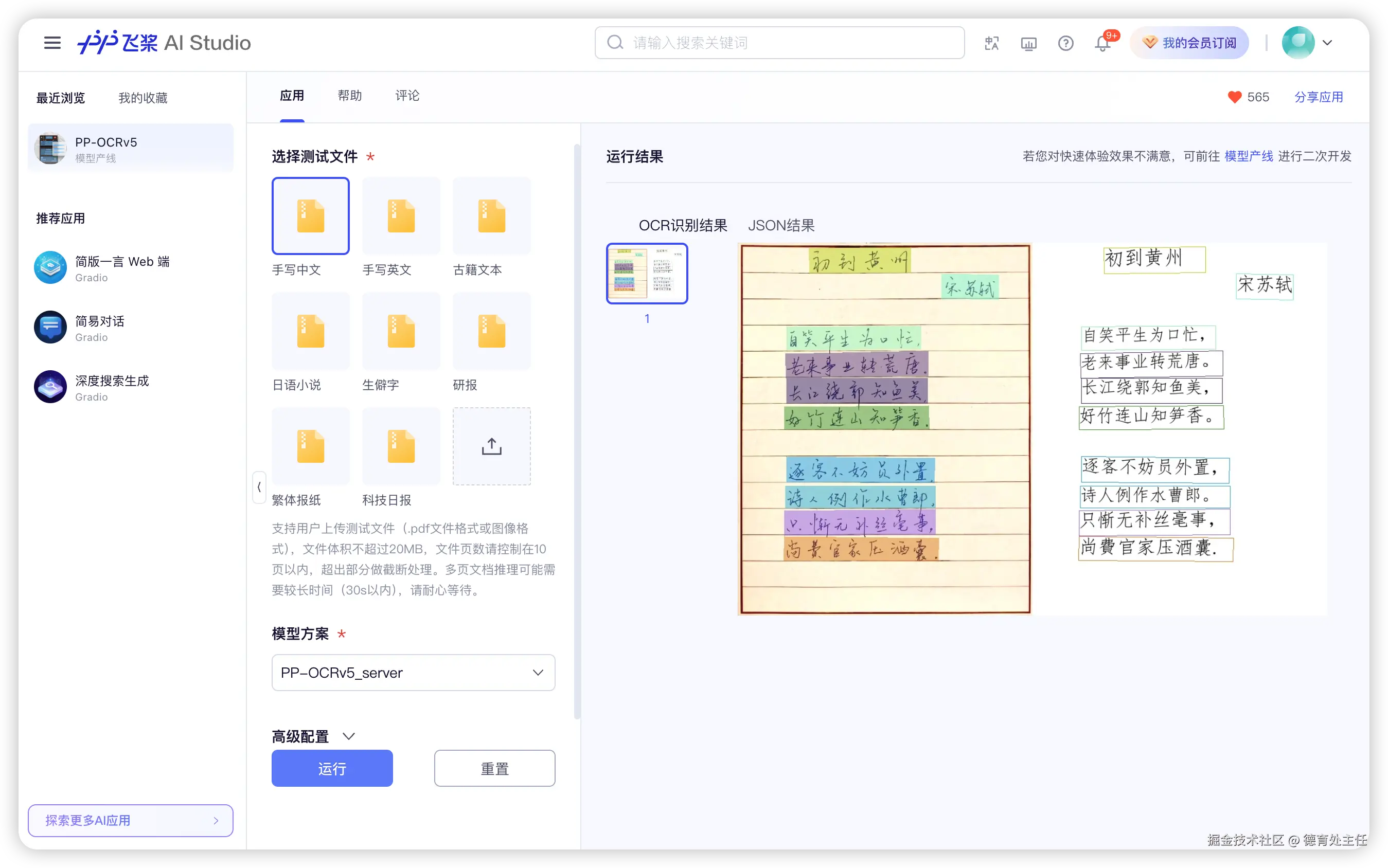
小学生手写体
我用一张图小学生手写体的图片测试。

先看看 PP-OCRv5 的识别效果,全对!

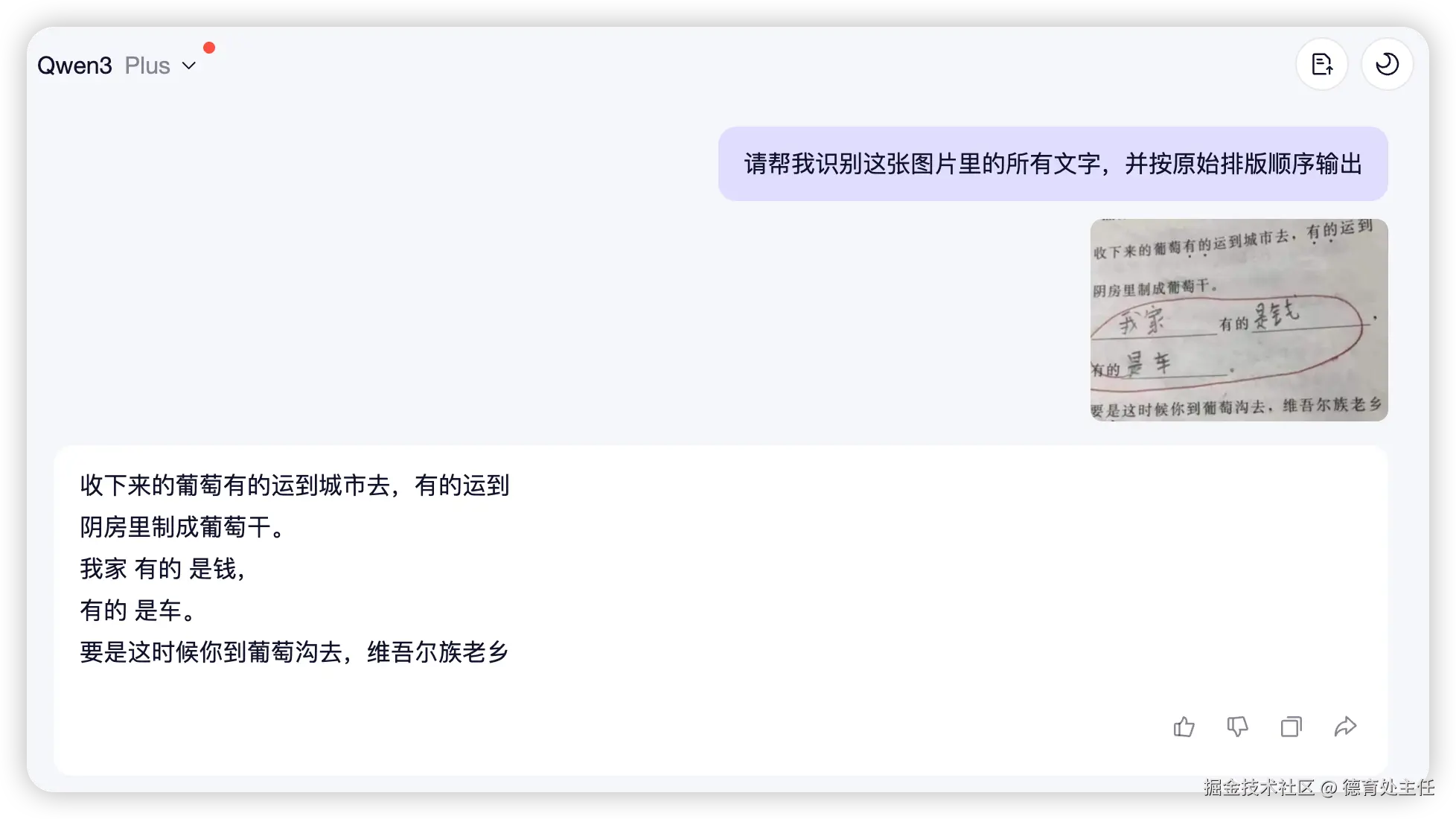
再看看千问的识别效果。
英文手写体
识别英文手写体对于 PP-OCRv5 来说也是洒洒水的事。

接着是千问的识别效果。
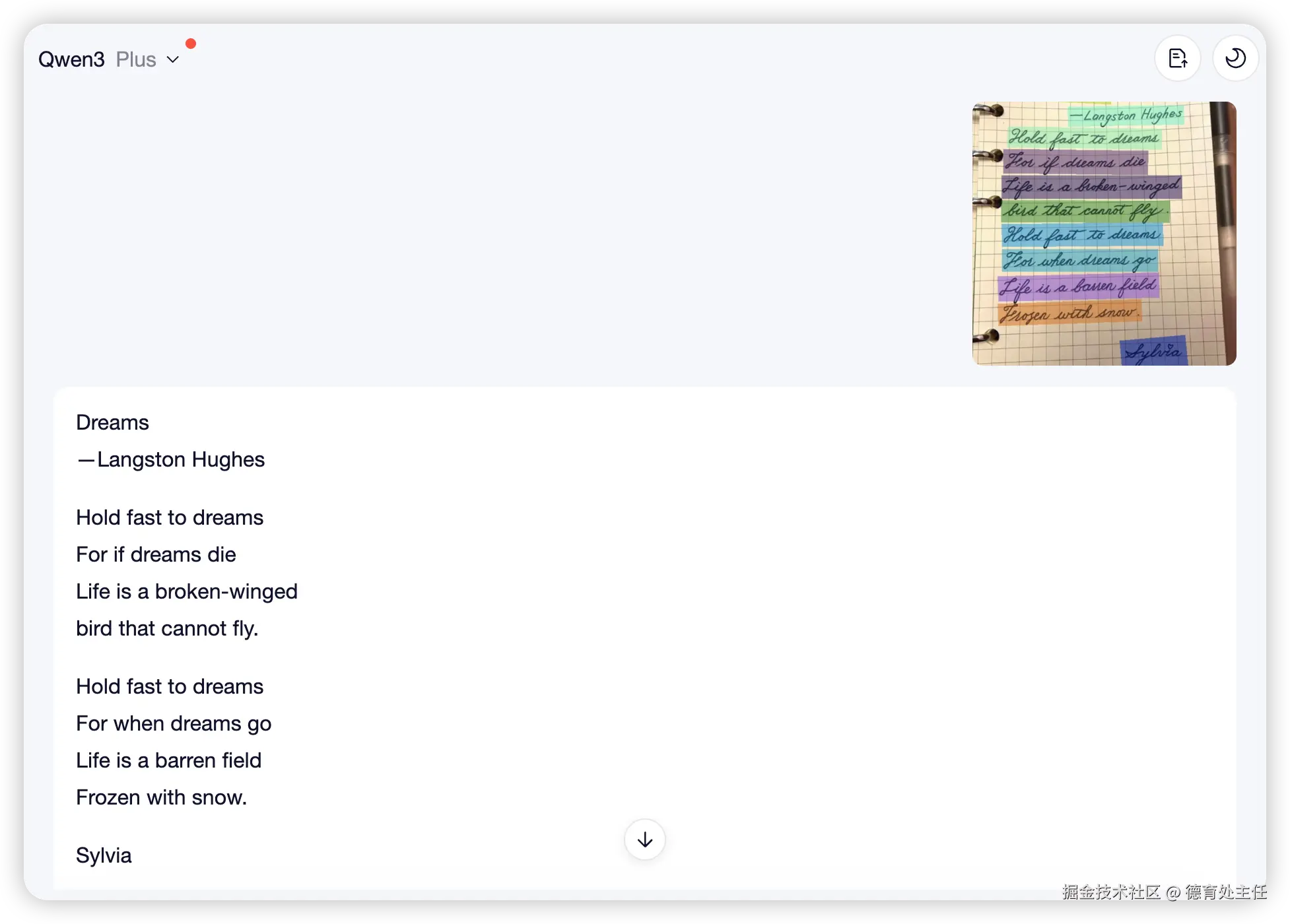
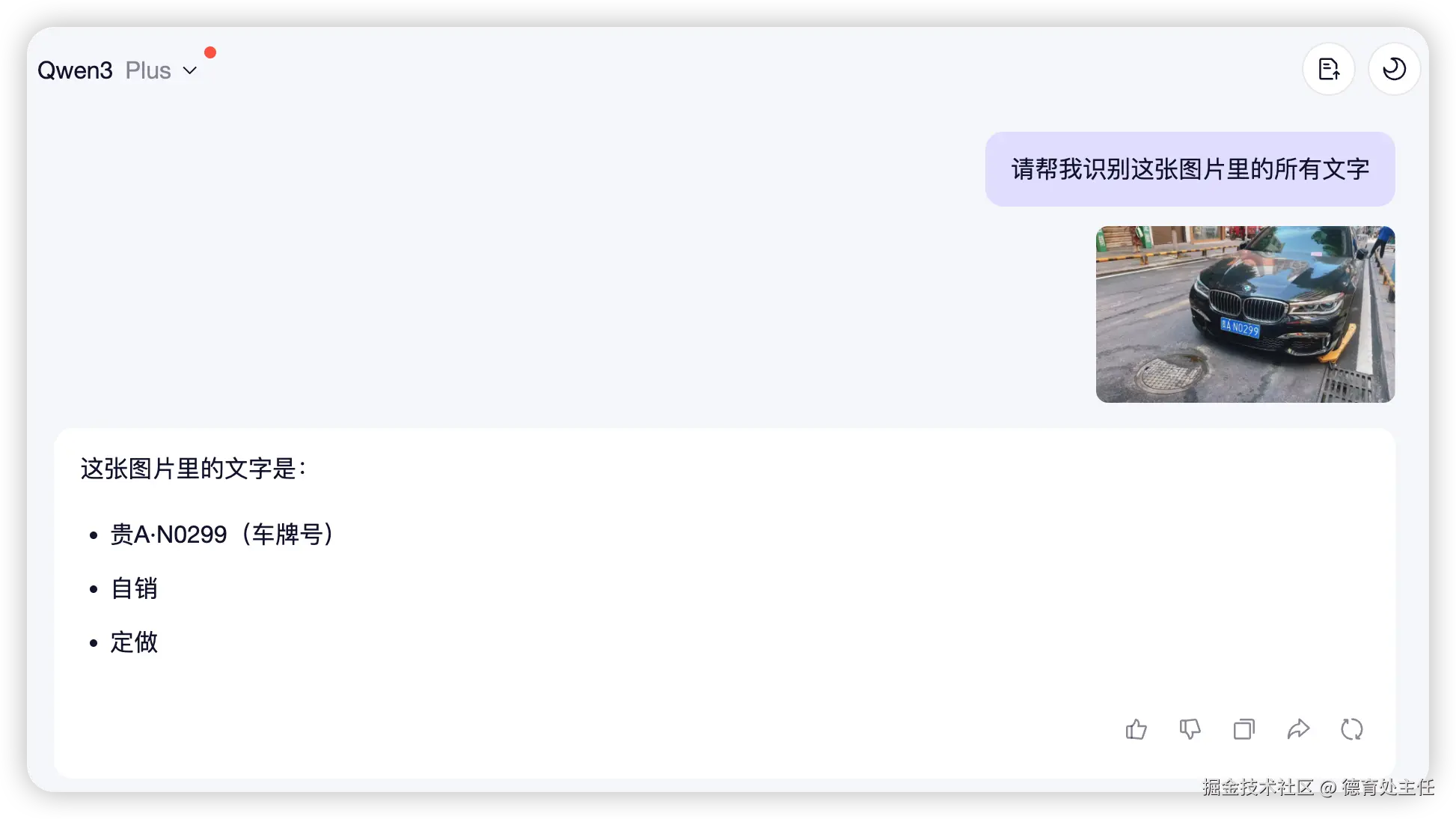
车牌识别
我找了一张模拟接近低位桩角度的车辆照片,车牌不是正对着摄像头,PP-OCRv5 识别起来毫不费劲。左上角的招牌并不完整,PP-OCRv5 也能推理出相关的文字出来。

千问在这次测试中也没跟 PP-OCRv5 拉开多大差距。唯一的一点差距就是车牌的那一点。
总体来说,PP-OCRv5 一点都不输给AI大模型,而且 PP-OCRv5 仅有70MB。这么发展下去,说不定以后 PP-OCR 连唇语都读得懂了🤔
🧑💻 调用起来也超简单~
对于产品来说,PP-OCRv5 完全达到投入生产环境的标准。
对于程序员来说,开发起来也要顺手才行。这点可以大大的放心,飞桨的文档写得极其详细,PaddleOCR 上手也极其简单,跟着官方示例走完全跑得通。
环境搭建
1、首先需要在你的环境中安装好 Python。
2、安装 PaddlePaddle。
根据你的硬件和系统环境选择对应的安装方法👉 www.paddlepaddle.org.cn/install/qui...
我用自己的电脑演示,在Mac中使用以下命令可以安装PaddlePaddle
ini
python -m pip install paddlepaddle==3.2.0 -i https://www.paddlepaddle.org.cn/packages/stable/cpu/3、安装 paddleocr
paddleocr 的详细文档可以参考这里👉 www.paddleocr.ai/latest/vers...
为了方便,我用下面这条命令安装完整版的 PaddleOCR。
arduino
python -m pip install "paddleocr[all]"安装成功后可以用这条命令查看版本号
paddleocr -v
小试牛刀
我准备了下图,用来测试。

把图片保存到指定的目录里,我这张图片名叫"p1.png"。然后在当前目录在打开终端,输入以下指令就开始运行程序了。
bash
paddleocr ocr -i ./p1.png第一次使用需要下载相关的库,之后就不会再重新下载了。
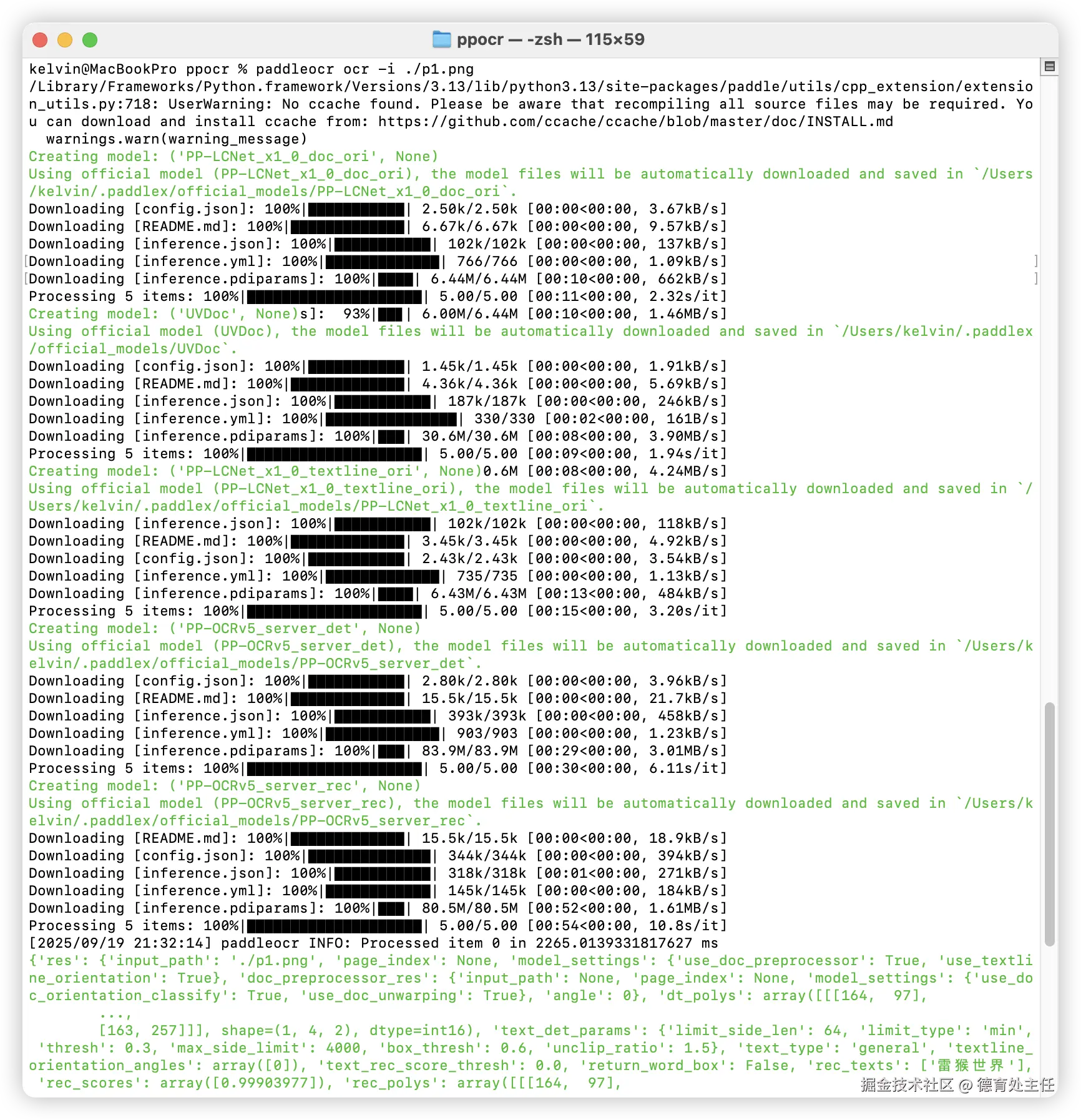
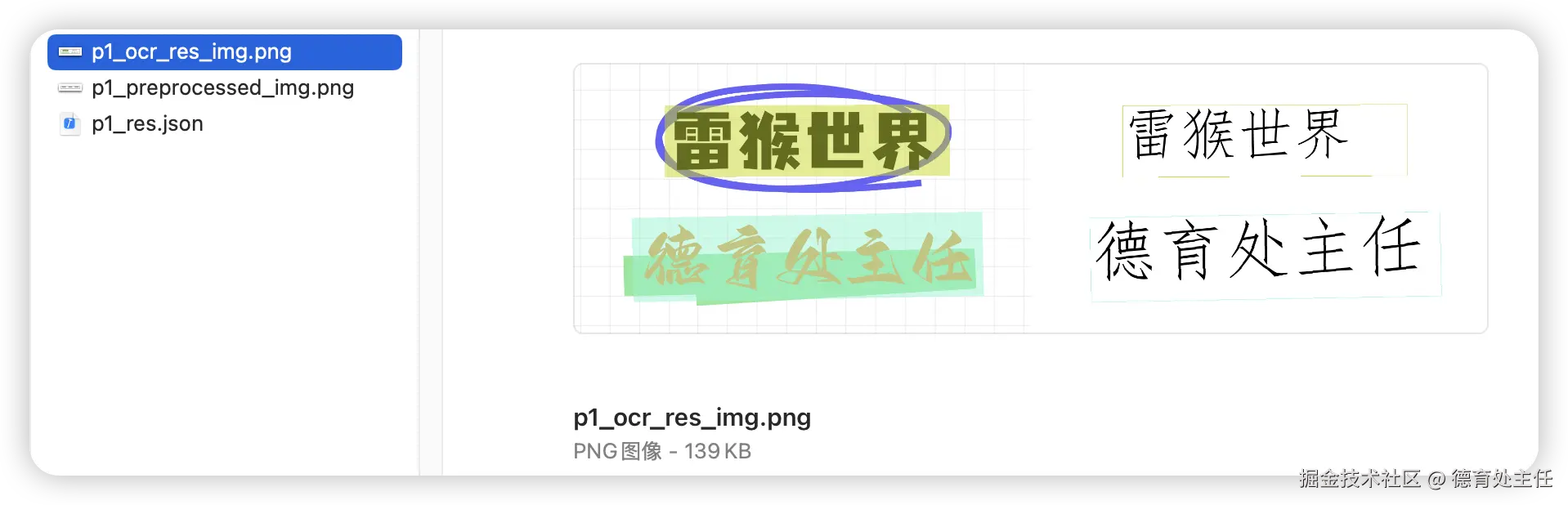
可以看到上图倒数第二行最右侧,已经识别到测试图中"雷猴世界"这几个字了。
用 Python 开发
在终端测试没问题,投入生产环境还是把相关功能写进项目里稳妥一点。
这次我准备了一张复杂点的图,有2行文字,并且用了2种字体。

代码如下。
ini
from paddleocr import PaddleOCR
ocr = PaddleOCR(
use_doc_orientation_classify=False,
use_doc_unwarping=False,
use_textline_orientation=False) # 文本检测+文本识别
result = ocr.predict("./p1.png")
for res in result:
res.print()
res.save_to_img("output")
res.save_to_json("output")首先从 paddleocr 包里导入 PaddleOCR 类 ,这是一个更高层的 OCR 接口,相比 TextRecognition,它同时包含 文本检测 + 文本识别。接着初始化 OCR 模型实例
通过 ocr.predict("./p1.png") 导入图片。
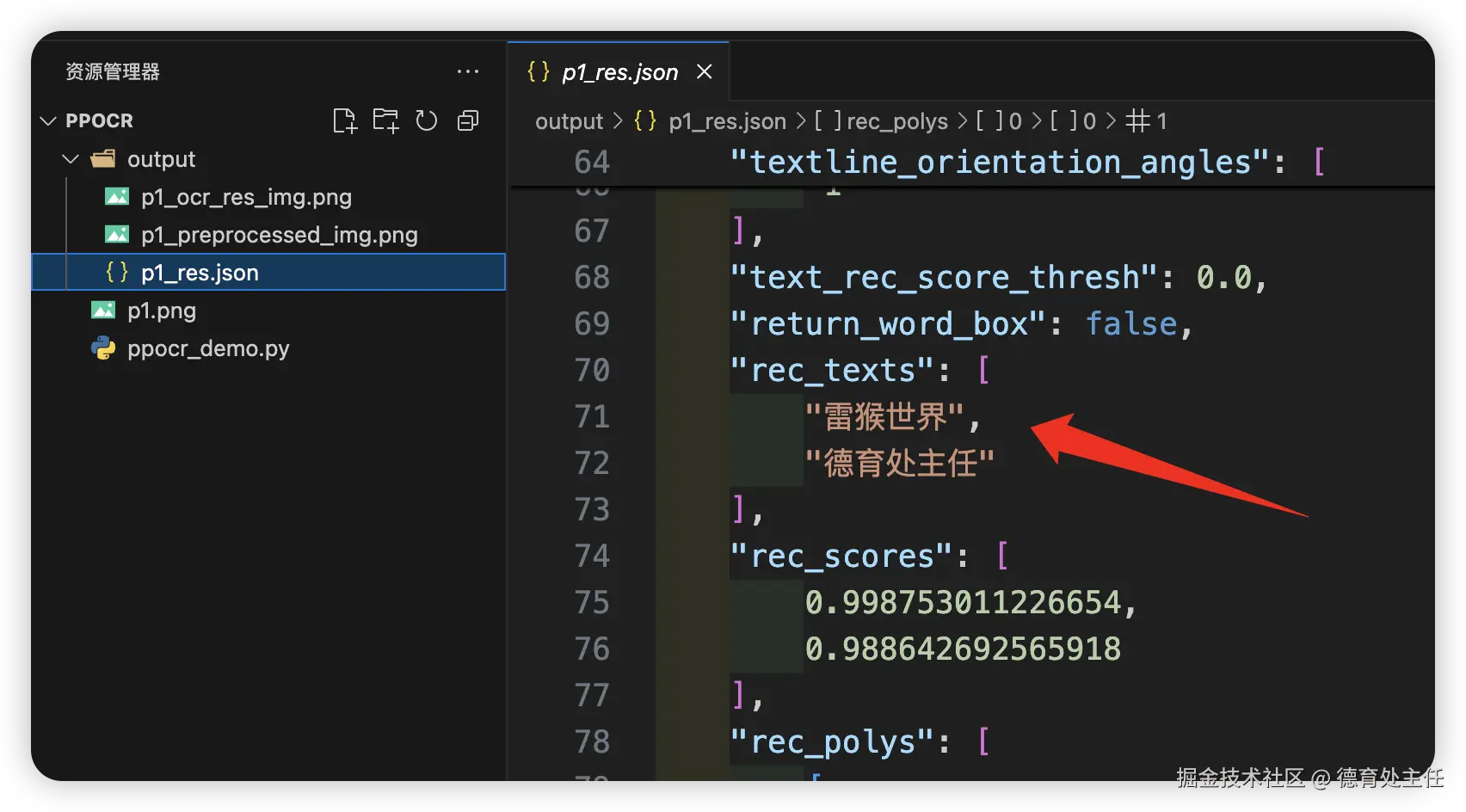
最后用 save_to_img("output") 和 save_to_json("output") 把识别后的图片以及JSON版本的结果保存在 /output 目录里。
运行代码后会得到2张图,和1份JSON文件。
p1_ocr_res_img.png 是识别结果的展示图。
p1_res.json 是识别结果的JSON版。在项目中我们通常就是拿着这份JSON结果返回给客户端使用。
📚 总结
还是那句,专业的事交给专业的模型,大炮打蚊子实在没必要。
模型继续往大的卷真的没必要,像 PP-OCRv5 这个"小身板"其实更容易落地,能适应更多的应用场景。在文字识别领域能把模型体积做得这么小,还能保持这么高的精确度,不仅在高端设备里能用,在稍微低配点的客户端都能流程运行。
更更更重要的是,飞桨还支持国产芯片。这对于做政企项目的公司来说简直是福音了。
在前面的测试中也看到,从车牌这种标准的字体到小学生灵魂书法家,再到艺术性接近医生风格的英文字母 PP-OCRv5 都能精准识别出来。面对批改作业、校验合同这类产品需求 PP-OCRv5 完全能扛得住。
要同时满足以上条件(支持国芯、精准识别、体积够小、速度够快)的 OCR 工具,除了 PP-OCR 应该没其他选项了。
最后再贴一次体验地址⬇️
- 文字识别PP-OCRv5:大模型社区-飞桨星河AI Studio大模型社区
- 文档解析PP-StructureV3:大模型社区-飞桨星河AI Studio大模型社区