CPU前言
cache作为现代处理器一个基本部件,可能很多时候对程序员都是无感(透明)的,但要写出高性能的程序,还是要对其原理有个基本了解,网上介绍的cache的文章很多,有些写的很好,我们就直接引用了。我们以ARM平台为主,来进行相关分析和实践,底层软件程序员来讲,还要面临对cache进行操作各种操作(比如enable cache、cache flush等等),我们也往下稍微探究一下cache的一些硬件知识。最后作为SoC产商,SLC(System Level cache)对芯片整体性能非常重要,我们会以CI700为例,介绍下它的基本原理、存在的问题以及从高通开源代码摸索下他们使用SLC的方式。
所以,本文会包含分为上下两篇-上篇介绍CPU cache,下篇介绍SLC。上篇主要包括:
- cache基本原理
- 为什么需要cache缓存(局部性原理、多级存储结构及延迟)
- cache的基本结构(硬件结构tag/data ram/组相连、组织方式:PIPT/VIPT、包含关系、分配策略、cacheline)
- 多核cache一致性问题(MESI/MOESI、PoC/PoU点)
- ARM处理器的cache
- DSU维护多核一致性(SCU、snoop filter)
- cache别名和歧义的问题
- cache 伪共享的问题
- 如何探测各级cache大小
cache基本原理
什么是cache,为什么cache有助于提高性能、为什么要分多级、cache latency
以手机或者平板这类移动基于ARM CPU设计的SoC为例,一个程序要运行起来,一般先从flash(eMMC或者UFS)中读取到主存中(如LPDDR5)驻留(把硬盘当虚拟内存的技术我们暂不讨论),而无论什么程序,基本可能分成逻辑/算术运算、访存等组成。所有的操作都要借助寄存器来执行。对于访存操作来讲,就是在寄存器和主存之间来回倒腾数据。以下面C代码为例。
c
#include <stdio.h>
int main()
{
int sum=0;
int i = 1, j=2;
sum += i;
i++;
sum += j;
j++;
printf("sum = %d,i=%d, j=%d", sum, i, j);
return 0;
}我们只看C代码第9-10行对应的汇编(使用 O0编译选项):
assembly
main:
// 省略其他
ldr w1, [sp, 28] //将sum的值从内存读到寄存器W1
ldr w0, [sp, 24] //将i从内存读到寄存器W0
add w0, w1, w0 // 执行相加运算将结果暂存在W0
str w0, [sp, 28] // 将W0的结果写回sum所在的内存地址处
ldr w0, [sp, 24] // 将i从内存读到寄存器W0
add w0, w0, 1 // 执行++运算暂存在W0
str w0, [sp, 24] // 将W0的结果写回i所在的内存地址处
// 省略其他寄存器访问基本上单个cycle就能完成(例如汇编第5行),而访问DDR需要几百个cycle(例如汇编第3、4行)。
对于高通sm8650平台而言,最高主频在3.3GHz,那1个cpu cycle不到1ns,也就是访问寄存器不到1ns;而从前文(lmbench的latency测试)的分析我们知道,DDR的访问时延在~120ns。中间有着上百倍的差异,所以如果单纯地让CPU对内存进行读写,所消耗的时间绝大部分是在内存对数据的处理 上,而这时候CPU就在空等 ,浪费了资源,因此就需要在CPU与内存之间增加一个Cache来作为缓冲,减轻处理器ALU单元"饿肚子等数据"的现象。
但是cache不能太大,因为其代价比较昂贵(主要area代价较大包括设计复杂度较高),因为程序的局部性原理(locality)的存在,所以定性讲,使用一定容量的cache,能起到提升程序运行性能。所谓局部性原理,简单来讲,访问过的数据大概率的会被再次访问,程序代码和数据在时间和空间上都具有局部性:
时间局部性(temporal locality):如果一个数据现在被访问了,那么以后很有可能也会被访问。空间局部性(spatial locally):如果一个数据现在被访问了,那么它周围的数据在以后可能也会被访问。
当CPU在cache中找到需要的数据,我们称之为命中(hit)。反之没有找到数据,我们称之为缺失(miss),这时候就要去外层存储中寻找所需数据。
cache为什么要分级
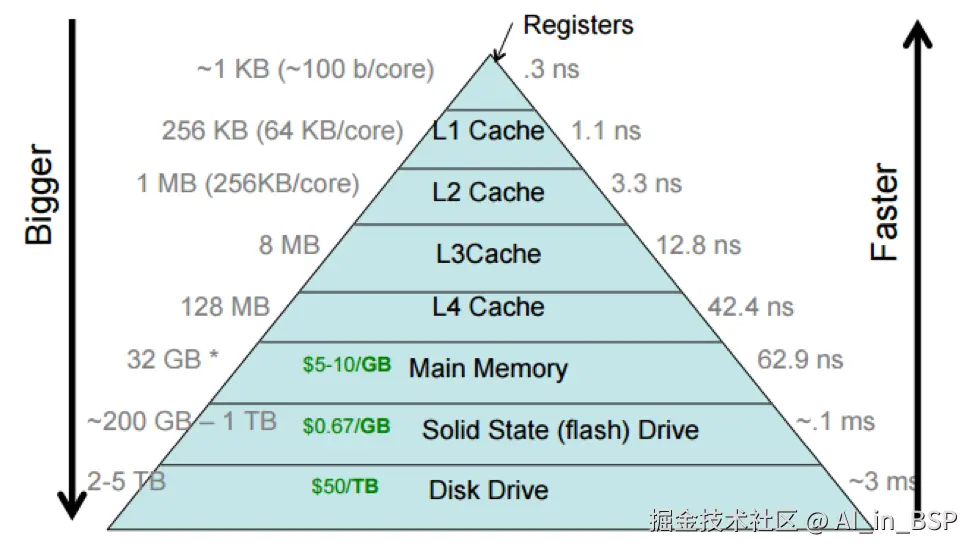 从上图我们可以看到,cache分为L1,L2,L3(利用高通8650平台还有L4,也就是system level cache)等多级,可以看到越靠近CPU访问延迟越低,但代价也会更高。大家可能想到一个问题是,是不是可以不计代价把L1尽可能做大,把层级做少,但实际上拿L1 cache为例,L1 cache一般工作在CPU的时钟频率,虽然L1和L2往往都是SRAM,但构成存储单元的晶体管并不一样。L1是为了更快的速度访问而专门优化过的,它用了更多/更复杂/更大的晶体管,从而更加昂贵和更加耗电。
从上图我们可以看到,cache分为L1,L2,L3(利用高通8650平台还有L4,也就是system level cache)等多级,可以看到越靠近CPU访问延迟越低,但代价也会更高。大家可能想到一个问题是,是不是可以不计代价把L1尽可能做大,把层级做少,但实际上拿L1 cache为例,L1 cache一般工作在CPU的时钟频率,虽然L1和L2往往都是SRAM,但构成存储单元的晶体管并不一样。L1是为了更快的速度访问而专门优化过的,它用了更多/更复杂/更大的晶体管,从而更加昂贵和更加耗电。
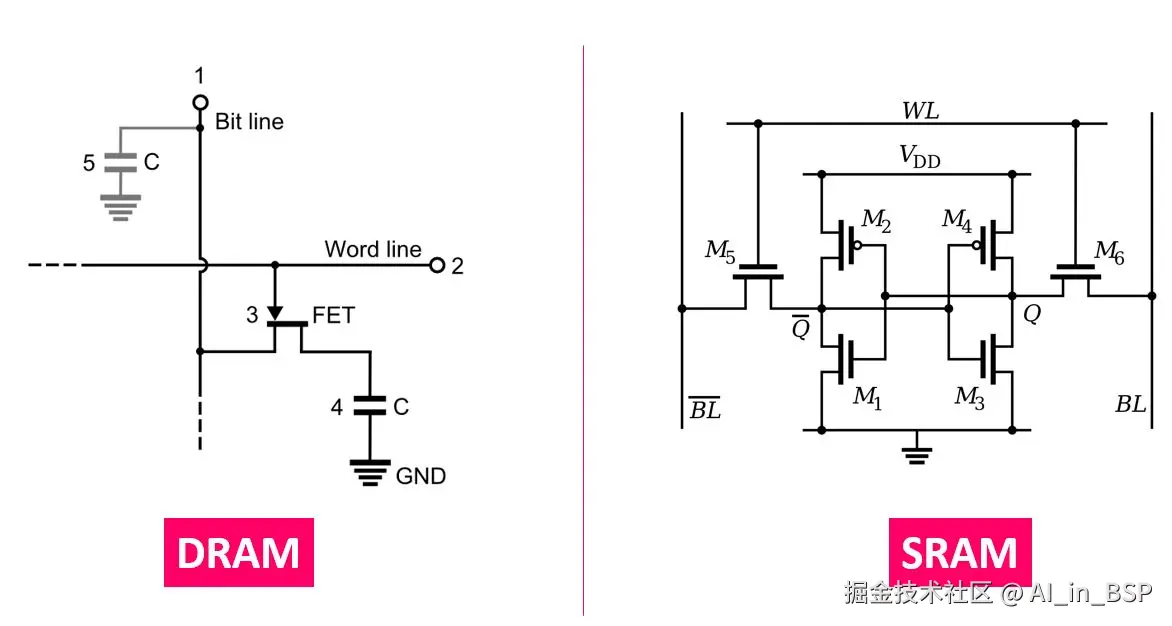
一般各级cache都是用SRAM搭的,DDR一般是DRAM搭的(有电容需要自刷新),如下图所示:
另外,如果将cache容量做大,那么存储单元的选通将会复杂。从而很难满足高时钟频率的要求。另外,当cache容量很小时增加容量,命中率增加的比较明显;当容量达到一定程度,提高cache容量对于提高cache命中率的贡献就很有限了。
综上,以及结合计算机体系结构的要求来讲,现代CPU都是一个多级cache的配置。
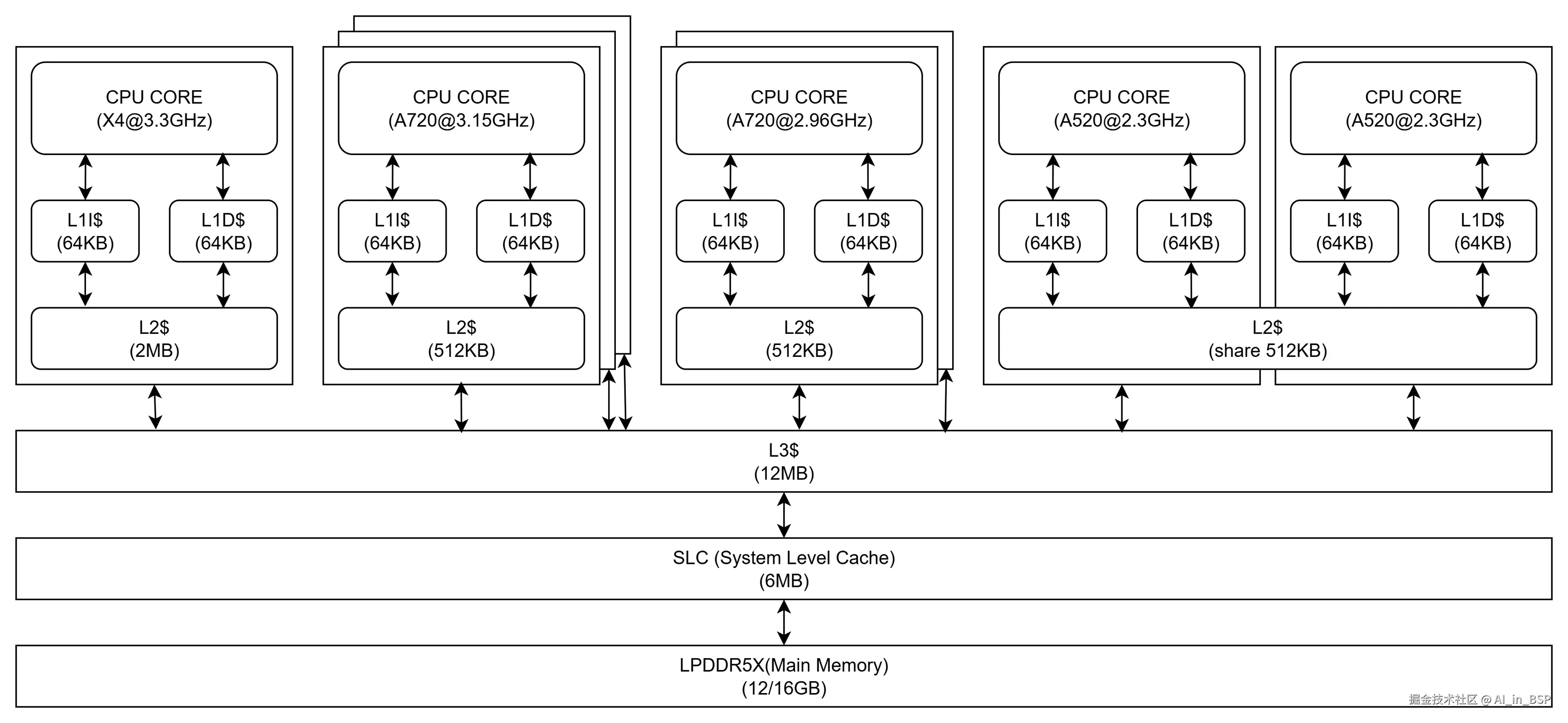
如上图所示:高通8650有4个cluster:1个X4、3个高频的A720、2个低频的A720和2个A520。除了2个A520共享512KB,其他L2都是各自CPU核心所私有的,L3为所有CPU所共享,SLC是整个SoC所共享。
我们来看下各级cache访问速度(后文有更准确的实测数据,这里看下量级):
- L1 的访问延迟:~1ns
- L2 的访问延迟: ~4ns
- L3 的访问延迟:~7ns
- SLC的访问延迟:~18ns
- DDR内存的访问延迟:~120ns
cache和主存之间的数据传输
对CPU来说,它和主存(DDR)之间不会一个字节一个字节的交换数据,这样效率太过低下了,一般来说都是要一块一块的来交换的,即如果发生cache miss,那也会从主存捞一整块数据分配到cache中,这一整块数据的大小就叫做 cacheline,笔者接触的ARM CPU的cacheline 都是 64 Bytes,是二者之间数据交换的最小单位。
Linux服务器有文件节点可以直接查询,但高通移动SoC平台没看到适配。
bash
# x86平台可以直接读取
cat /sys/devices/system/cpu/cpu0/cache/index0/coherency_line_size
64我们再来看下面这段程序:
c
#define ARR_LEN (64 * 1024 * 1024)
int arr[ARR_LEN];
arr[0] = 1;
// Loop 1
for (int i = 0; i < ARR_LEN; i++) arr[i] *= 3;
// Loop 2
for (int i = 0; i < ARR_LEN; i += 16) arr[i] *= 3;
//预期结果:两个示例运行时间相差无几对数组的加载, CPU 就会加载数组里面连续的多个数据到 Cache 里,因此我们应该按照物理内存地址分布的顺序去访问元素,这样访问数组元素的时候,Cache 命中率就会很高,于是就能减少从内存读取数据的频率, 从而可提高程序的性能。
把loop2的步长值尝试不同值,可以看到结果如下(直接借用网上的图)
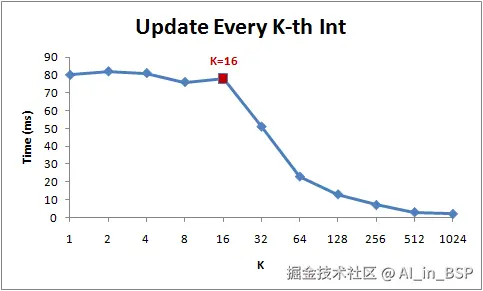
注意当步长在1到16范围内,循环运行时间几乎不变。但从16开始,每次步长加倍,运行时间减半。利用该程序原则上可以用探查cacheline的大小(但实际上cacheline探测程序的构造要比这个复杂,后文展开)。
对于高通8650平台而言,各级cache总大小(20MB左右)远小于主存(16GB),接下来我们看看如何解决主存中的数据映射到cache中来的问题,并讨论下cache内部的结构。
cache和主存之间的映射
通常会有以下几种映射方式:
直接映射(Direct Mapping):采用多对一的固定映射的方式,相当于对主存地址进行求模运算即可完成映射。比如:高通8650 X4 CPU的L1 Cache有1024个cacheline,那么(内存地址 mod 1024)* 64就可以直接找到所在的Cache地址的偏移了。就是主存中的一个Block只能映射到Cache中固定的某一行,直接映射缓存在硬件设计上会比较简单,成本较低,但因为程序一般并非均匀的从低地址到高地址依次访问从而容易产生冲突而导致cacheline不断地被踢出cache。这就是cache颠簸(cache thrashing)现象。全相连(Fully Associative):任何一个内存地址的数据可以被缓存在任何一个cacheline里,这种方法是最灵活的,但是,如果我们要知道一个内存是否存在于Cache中,我们就需要进行O(n)复杂度的Cache遍历,延迟较大,适用于小容量的cache(比如ARM处理器的iTLB就能见到)。组相连(Set-associative):为了避免上述的两种方案的问题,于是就要容忍一定的hash冲突,也就出现了一种叫做N路组相连的折中方案( N-Way Set Associativity,主存中的一个地址的数据可以被映射N个cacheline中)。也就是把连续的N个cacheline绑成一组。寻址时,先把找到相关的组,然后再在这个组内找到相关的cacheline。

source:Arm® Cortex®-X4 Core Technical Reference Manual
我们以高通8650 X4核的L1 Dcache为例,其大小为64KB、4路组相连、cacheline大小为64Byte。意味着:
- 64KB的cache可分为,64KB/64B=1024个cacheline;
- 有4路,每路有1024/4=256个cacheline,每路大小为16KB。
- PA有40bit,VA有48bit的,是VIPT(Virtually-Indexed, Physically-Tagged, 这种组织方式方式涉及
MMU我们暂且按下不表,后文展开),这种方式通过PA来获取tag并进行后续操作。
也就意味着:
- 每个cacheline大小为64B(2^6 = 64),需要内存地址的最低6bit来寻址(bit0, 5);
- 每组(way)有256个cacheline,需要8个bit来寻址(bit6, 13)
- 剩下的40-8-6=26bit作为Tag(bit14, 39)
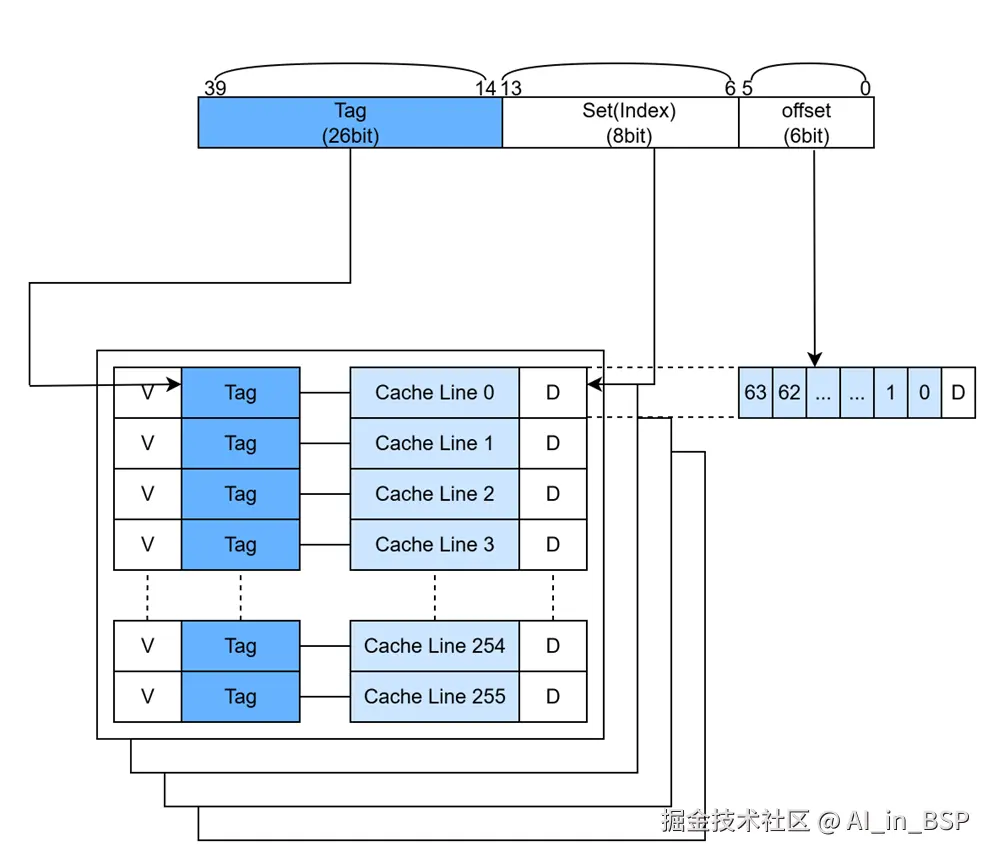
如上图所示,可以看到cache除了cacheline存储数据外,还有专门的Tag Ram用来存储对应的Tag段,V(Valid) bit来表示cache是否有效,D(Dirty)bit表示cache是否和主存中的数据一致,这些都需要cache控制器来维护,当然,还有其他逻辑电路(比如Tag比较器等)来执行cache look-up,以便在 cache hit时拿到cache里的数据或者在 cache miss时继续把地址往下游转发。简单来讲各个地址段是这样和cache控制器的相关逻辑单元关联的。假设CPU要访问某个地址的一个Byte),一般可能得过程如下:
- 先用CPU PA的8bit的set(index,bit6, 13)来寻址way中的某个cacheline,假设就是8bit的set0,寻址到第0个cacheline;
- 在v bit有效的前提下,再用地址Tag段(26bit,bit14, 39)的作为Tag,跟4个way的第0个cacheline对应的Tag Ram依次比较,所有的都不相等,则表示没命中,有其中一个匹配则表示命中;
- 假设第0个way的第0个cacheline命中,最后再用地址Offset段(6bit)来看具体是哪个Byte数据,返回给CPU即可。
行文至此,我们可以知道,主存和cache之间数据交换最小单位是cacheline,除了效率之外,也是因为每个cacheline只有一个dirty bit。这一个dirty bit代表着整个cacheline是否被修改的状态。
cache 控制器工作流程
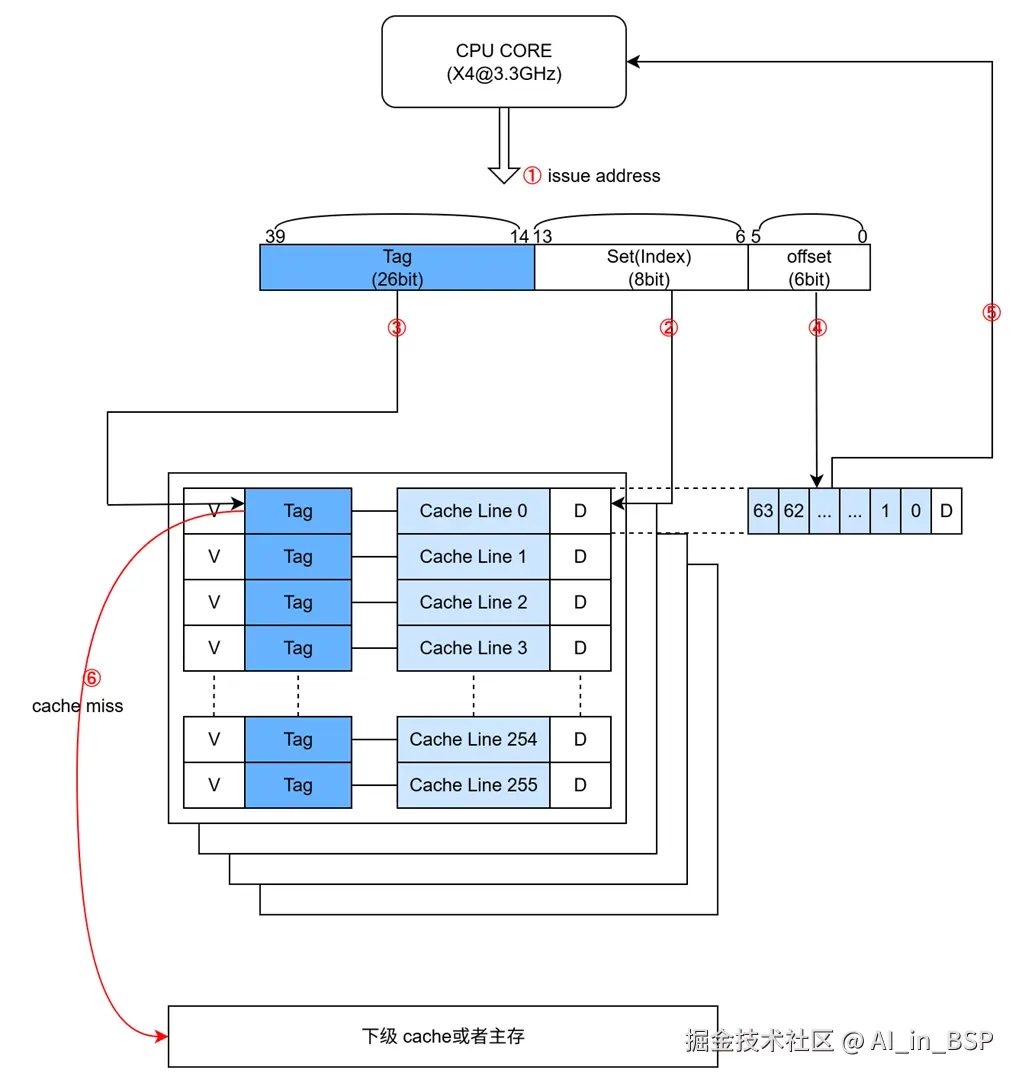
上文其实已经简单涉及,下面我们再来具体看下工作流程,cache控制器主要执行 cache look-up 看数据是否在cache(以高通8650 L1D$为例)中:
- CPU发出发出访存操作(先发出address)
- 获取index,寻址到way中的某一条cacheline
- 比较Tag,在valid bit为1的前提下,如果tag相等,说明数据在cache中。称为
cache hit。进入步骤4;否则Cache miss,进入步骤6,需要去L2中获取数据。(注意 cacheline只保存Tag和index的地址) - 根据访问方式(单字节、word等方式)通过offset获取在cacheline中的具体哪个字节
- CPU获取对应数据,执行后续操作
- 访问主存,并根据分配方式,如果是write allocate或者read allocate,则把数据返给CPU的同时,还需要送一份到对应cacheline中,并且把valid bit置为1
cache的组织方式以及别名和歧义的问题
之前的分析我们都绕过了CPU另一个关键部件 MMU,该部件负责虚拟地址VA到物理地址PA的转换。cache的硬件设计既可以采用VA也可以采用PA,或者部分PA加部分VA的方式来查找Cache。一共有3种常见组织方式:
VIVT(Virtually Indexed Virtually Tagged):查找way中的某一条cacheline以及比较tag均使用VA,不经过MMU进行地址转换,速度较快,但会有歧义(ambiguity,tag一样)和别名(alias,index一样)的问题,需要OS操作系统负责处理,避免出现这两个问题。VIPT(Virtually Indexed Physically Tagged):查找way中的某一条cacheline使用VA,比较tag使用PA,这样做的好处是查找cache的同时,Cache控制器将VA发到MMU转换成PA,最后比较tag,这样可以加快执行速度。不会有歧义的问题,但一般会有别名的问题(当每路的cache size小于或等于页表大小时不存在问题)PIPT(Physically Indexed Physically Tagged):查找way中的某一条cacheline以及比较tag均使用PA,没有别名和歧义的问题,但硬件成本更高,每次查找都要先经过MMU转换拿到PA,才能进行下一步,所以理论上性能上不如VIPT。
如图所示:
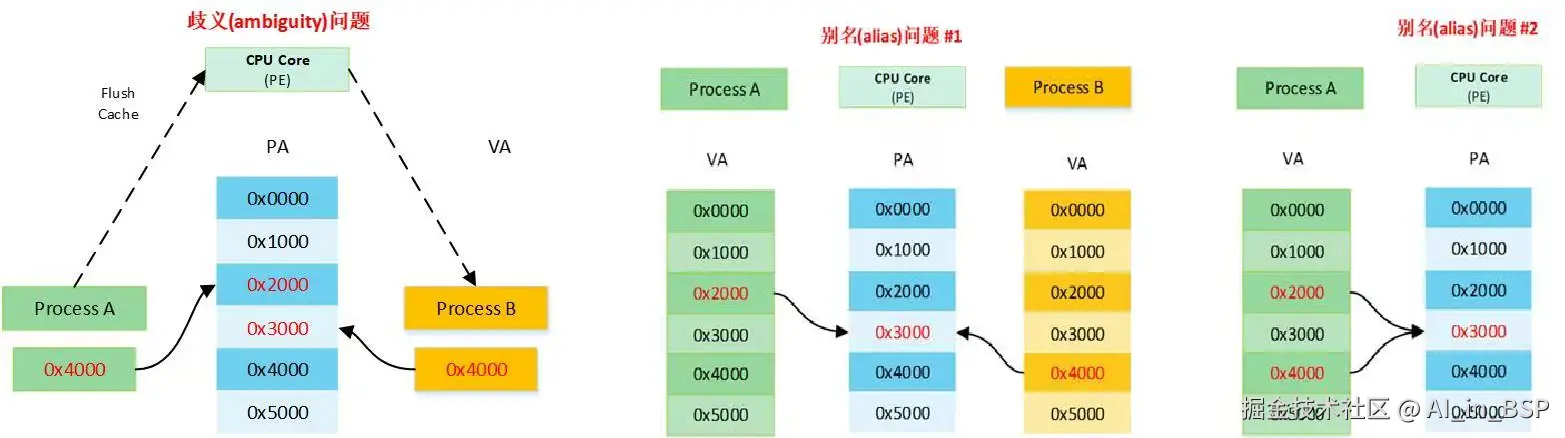
歧义:是指一个虚拟地址先后指向两个(或者多个)物理地址 别名:是指两个(或者多个)虚拟地址同时指向一个物理地址
VIVT在早期比较古老的CPU cache中使用,现在一般使用VIPT和PIPT,对于VIPT而言:
- 硬件不具备alias detection能力,OS需要通过
page colouring方式解决别名问题。- 硬件具备alias detection能力,软件把cache当成PIPT用
这个图之前出现过,我们现在来看下cache组织方式,虽然是VIPT但硬件上表现为PIPT(硬件处理别名问题,软件不感知):
笔者曾经调查TC21这代处理器的cache组织方式:
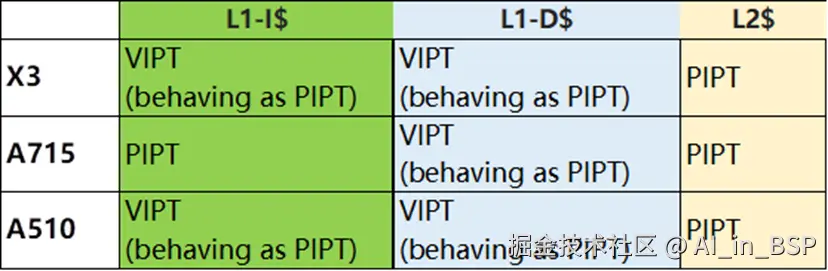
可以看到,对于当前ARM移动端处理器而言,要么是VIPT,硬件解决别名问题;要么是PIPT。总之软件(操作系统)不用处理别名和歧义的问题。
多级cache之间的包含关系
根据一个cache的内容是否同时存在于其他级cache来分类,即Cache inclusion policy。
- 如果较低级别cache中的所有cacheline也存在于较高级别cache中,则称较高级别cache包含(inclusive )较低级别cache。
- 如果较高级别的cache仅包含较低级别的cache中不存在的cacheline,则称较高级别的cache不包含(exclusive )较低级别的cache。
- 如果较高级cache的内容既不严格包含也不排除较低级cache,则称为非包含非排他(non-inclusive non-exclusive ,NINE)cache。
| 类别 | 定义 | 优点 | 缺点 | 约束 |
|---|---|---|---|---|
| 包含的(inclusive) | 外层(较高级别的)cache包含了内层cache(较低级别的)的内容 | 上级缓存缺失的时候想看看所需的块是不是在其他处理器的私有cache中,不需要再去一个个查其他处理器的cache了,只需要看看共享的外层cache中有没有即可 | 整体cache的容量变小 | 1、无论set的数量,L2 way的数量都必须大于或等于 L1 way的数量。``2、无论 L2 way的数量,L2 set的数量必须大于或等于 L1 set的数量 |
| 排他的(exclusive) | 外层cache只包含不在内层cache中的数据块 | 可以最大限度的存储不同的数据块,相当于增大整体了cache的容量 | 需要频繁填充新的数据块(分配和逐出时会再各级cache之间频繁移动),会消耗更多的内外层间缓存带宽,并且对Tag和cacheline产生更高的占用率 | 暂不涉及 |
详细参考该文章多级cache的包含策略(Cache inclusion policy)
笔者曾经调查TC21这代处理器的各级cache之间的包含关系,如下表所示
| Processor | L1 & L2 cache | relationship | Comment |
|---|---|---|---|
| A510 | L1 instruction & L2 | Pseudo-inclusive | NA |
| L1 data & L2 | Pseudo-exclusive | NA | |
| A715 | L1 instruction & L2 | Weakly inclusive | Instruction fetches that miss in the L1 instruction cache and L2 cache allocate both caches, but the invalidation of the L2 cache does not cause back-invalidates of the L1 instruction cache. |
| L1 data & L | Strictly exclusive | Any data contained in the L1 data cache is never present in the L2 cache. | |
| X3 | L1 instruction & L2 | Weakly inclusive | Instruction fetches that miss in the L1 instruction cache and L2 cache allocate both caches, but the invalidation of the L2 cache does not cause back-invalidates of the L1 instruction cache. |
| L1 data & L2 | Strictly inclusive | Any data contained in the L1 data cache is also present in the L2 cache. Victimization of L2 data will cause invalidations of the L1 data cache. | |
| DSU | L3 & Cluster | Typically exclusive | In normal use, a line is either in the cache of one or more cores (or complexes) or in the L3 cache, but not in both caches. Only Cacheable, shareable memory locations are allocated in the L3 cache. Non-shareable memory locations are not allocated in the L3 cache. Exclusive allocation is used when data is allocated in only one core or complex. Inclusive allocation is sometimes used when data is shared between cores or complexes. |
cache分配和更新策略
cache的分配策略是指我们什么情况下应该为数据分配cacheline。cache分配策略分为读和写两种情况。
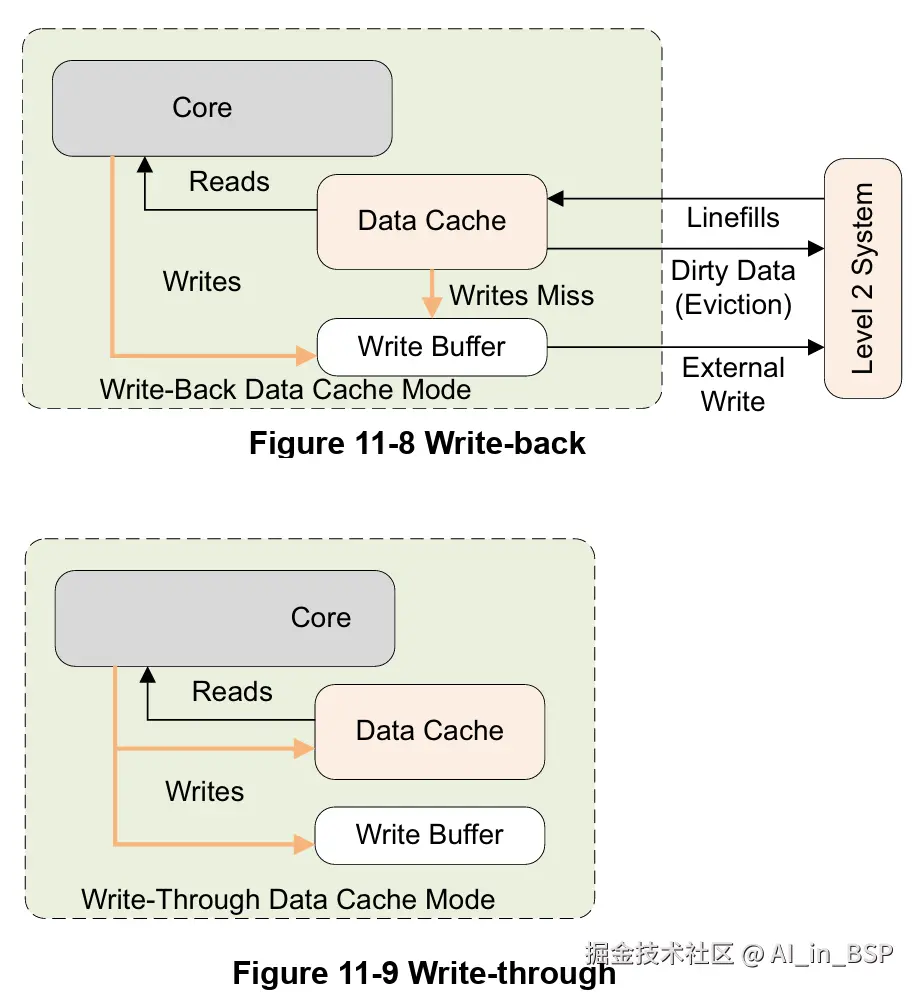
读分配(read allocation):当CPU读数据时,发生cache缺失,这种情况下都会分配一个cacheline缓存从主存读取的数据。默认情况下,cache都支持读分配。写分配(write allocation):当CPU写数据发生cache缺失时,才会考虑写分配策略。当我们不支持写分配的情况下,写指令只会更新主存数据,然后就结束了。当支持写分配的时候,我们首先从主存中加载数据到cacheline中(相当于先做个读分配动作),然后会更新cacheline中的数据。
cache更新策略是指当发生cache命中时,写操作应该如何更新数据。cache更新策略分成两种:写直通和回写。
写直通(write through):当CPU执行store指令并在cache命中时,我们更新cache中的数据并且更新主存中的数据。cache和主存的数据始终保持一致。写回(write back):当CPU执行store指令并在cache命中时,我们只更新cache中的数据。并且每个cacheline中会有一个bit位记录数据是否被修改过,称之为dirty bit(cacheline旁边有一个D就是dirty bit)。我们会将dirty bit置位。主存中的数据只会在cacheline被替换或者显示的clean操作时更新。因此,主存中的数据可能是未修改的数据,而修改的数据躺在cache中。cache和主存的数据可能不一致。
PS:本章节内容直接摘自Cache的基本原理-知乎-smcdef
多核cache一致性
之前的分析,我们还没有涉及多核,有了多核以后,每个核基本都有各自L1/L2 cache,还有个所有核共享L3 cache,这些cache副本之间的一致性要如何保证,我们来一起分析下。当然一般对软件来说是透明的。
概述
为了提高写的性能,一般来说,ARM处理器采用的是 Write Back的策略,从前文的访存latency数据,我们知道直接访问DDR主存实在是太慢了(高通8650平台访存DDR要120ns左右)。
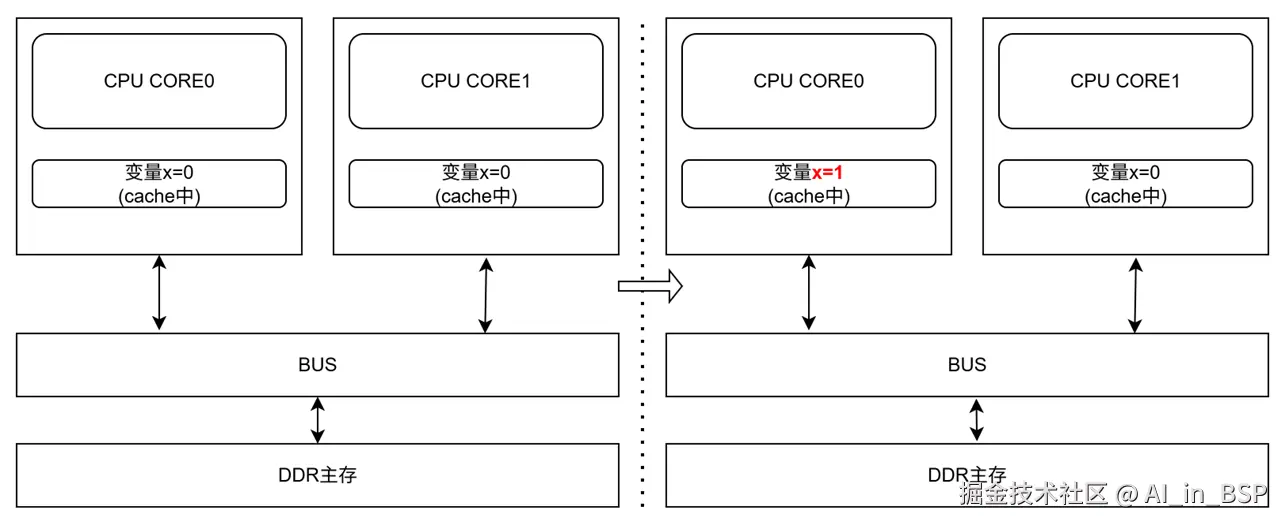
如上图所示,假设系统中有2个CPU核心,有两个线程A和线程B,分别绑定在CPU0和CPU1上,两个线程都要访问变量X,初始值都为0。
如果,线程A要把变量X改为1,此时CPU0的缓存上被更新了,那么CPU1上的缓存也要被某个硬件单元更新成1,否则,此时如果线程B要去读到错的值(比如拿X==0去做逻辑判断,可能走错分支),这就是缓存一致性的问题。
当然,对于我们上层的程序我们不用关心CPU多个核的缓存是怎么同步的,这对上层的代码来说都是透明的。
各个CPU核心之间是需要通过内部总线(BUS)去连接的,一致性的问题,需要靠总线这块去解决(ARM处理器CPU子系统内部靠DSU去解决;SLC需要靠支持如CCI-500这类支持一致性的总线去解决)。可能会有两种硬件解决方案:
Directory 协议。这种方法的典型实现是要设计一个集中式控制器,它是主存储器控制器的一部分。其中有一个目录存储在主存储器中,其中包含有关各种本地缓存内容的全局状态信息。当单个CPU Cache 发出读写请求时,这个集中式控制器会检查并发出必要的命令,以在主存和CPU Cache之间或在CPU Cache自身之间进行数据同步和传输。服务器一般会用目录协议。Snoopy 协议。这种协议更像是一种数据通知的总线型的技术。CPU Cache通过这个协议可以识别其它Cache上的数据状态。如果有数据共享的话,可以通过广播机制将共享数据的状态通知给其它CPU Cache。这个协议要求每个CPU Cache 都可以窥探(snoop)数据事件的通知并做出相应的反应。
对于移动端ARM处理器而言,一般采用Snoopy协议,并且每个CPU核心之间会有一个内部总线,通过这个内部总线去实现CPU核心之间的数据同步。这种实现方案相对简单,但要需要每时每刻监听总线上的一切活动。一定程度上加重了总线负载,也增加了读写延迟。针对该问题,提出了一种 状态机机制降低带宽压力。ARM处理器一般使用 MESI protocol(协议)。
MESI协议
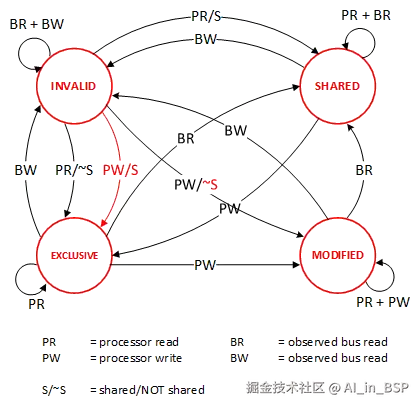
如上图所示,MESI协议缓存数据有四个状态:Modified(已修改), Exclusive(独占的),Shared(共享的),Invalid(无效的)。
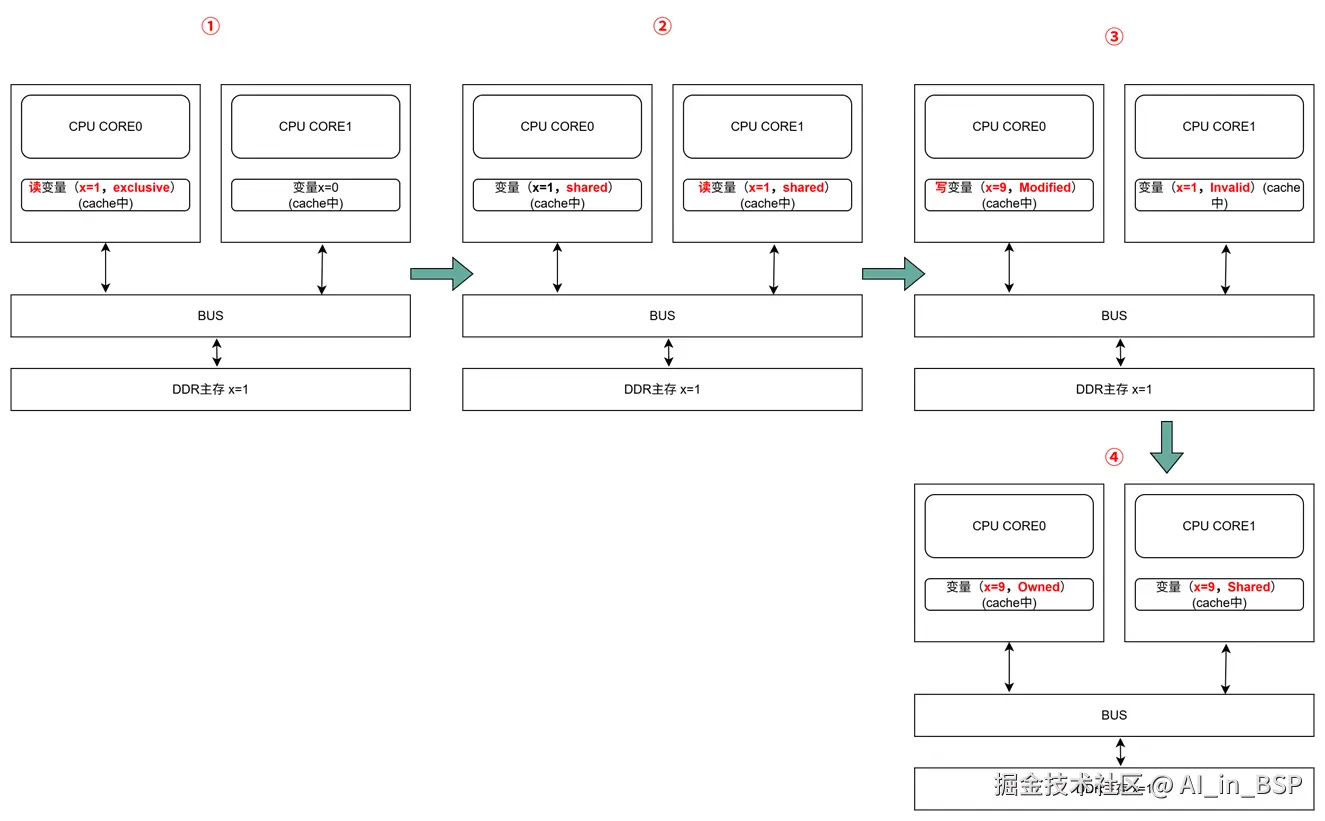
| 当前操作 | CPU0 | CPU1 | Memory | 说明 |
|---|---|---|---|---|
| ① CPU0 read(x) | x=1 (E) | x=1 | 只有一个CPU有 x 变量,所以,状态是 Exclusive |
|
| ② CPU1 read(x) | x=1 (S) | x=1(S) | x=1 | 有两个CPU都读取 x 变量,所以状态变成 Shared |
| ③ CPU0 write(x,9) | x=9 (M) | x=1(I) | x=1 | 变量改变,在CPU0中状态 变成 Modified,在CPU1中状态变成 Invalid |
| ④ 变量 x 写回内存 | x=9 (M) | X=1(I) | x=9 | 状态保持不变 |
| ⑤ CPU1 read(x) | x=9 (S) | x=9(S) | x=9 | 变量同步到所有的Cache中,状态回到 Shared |
MESI 这种协议在数据更新后,会标记其它共享的CPU缓存的数据拷贝为Invalid状态,然后当其它CPU再次read的时候,就会出现 cache miss 的问题,此时再从内存中更新数据。从内存中更新数据意味着N多倍的速度降低。我们能不能直接从我隔壁的CPU缓存中更新?答案肯定是可以的,但是状态控制也变麻烦了。还需要多来一个状态:Owner(宿主),用于标记,我是更新数据的源头。于是,出现了 MOESI 协议
MOESI协议的状态机和演示,可以参考Berkeley上看看相关的课件, MOESI协议允许 CPU Cache 间同步数据,降低了对内存的操作 ,提升了性能,但是控制逻辑也会变复杂。
ARM处理器如何维护多核一致性
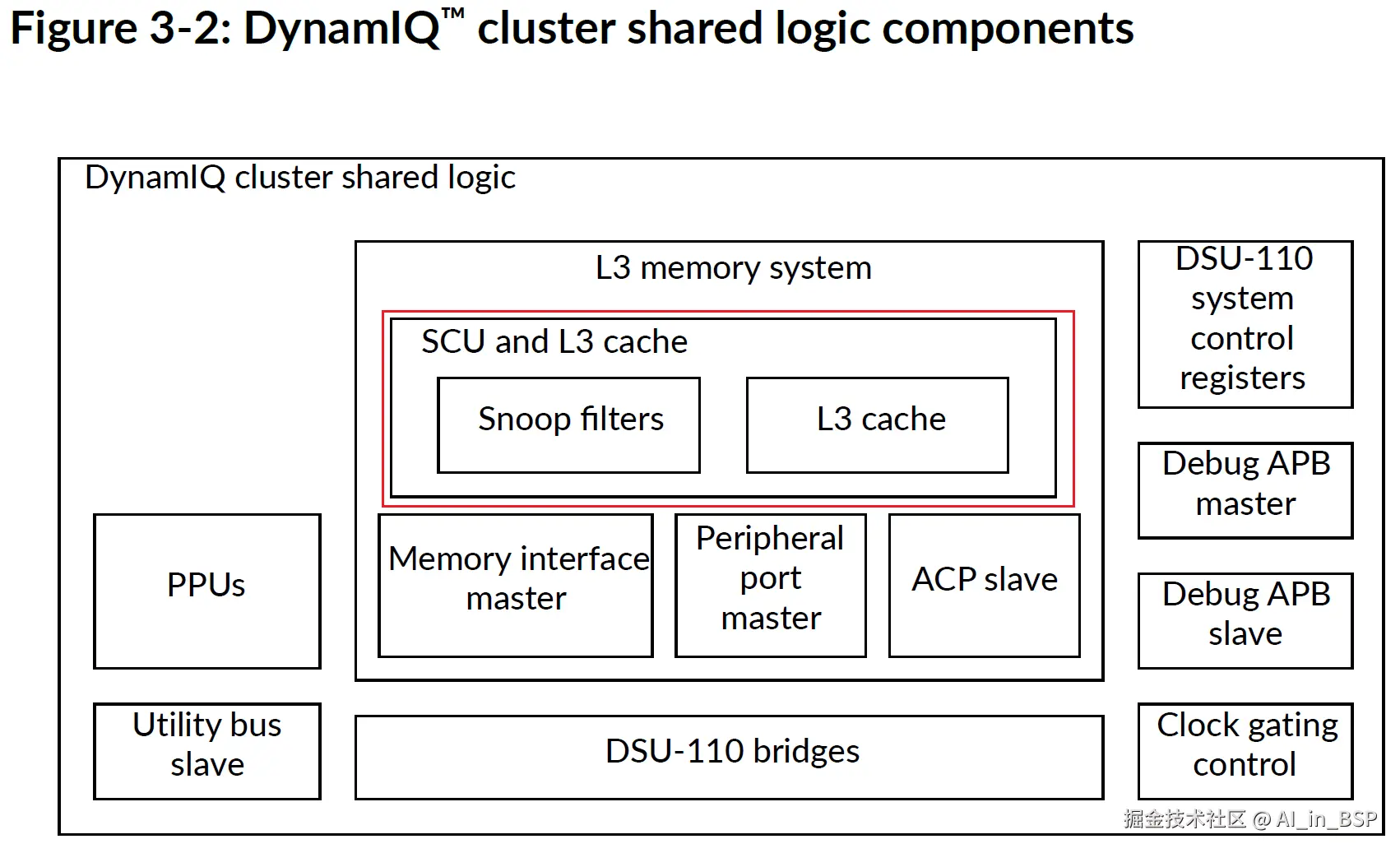
如上图所示,DSU中的SCU(Snoop Control Unit)负责维护多核之间的一致性,也是snoop方式,使用MESI协议。也就是说,前文我们分析的MESI状态的变更,主要就是靠SCU来发出相应操作给各个CPU的cache控制器来变更cacheline的状态。我们知道这种广播,必然造成CPU子系统内部总线带宽的冲击。图中的snoop Filter本质上解决在cache miss的时候,在本地放一份cacheline的备份(可以是对应的Tag),这样就不用发起操作给其他CPU,造成其他CPU核心和总线的Transaction增多而导致的带宽损失和性能下降。
ARM处理器PoC、PoU、inner和outer shareable等概念
在ARM体系结构中,一致性点(Point of Coherency, PoC) 和 点对统一(Point of Unification, PoU)是两个关键的概念,用于描述数据在内存体系中的一致性和可见性。架构并不禁止在PoC之后实现缓存,只要这些缓存不影响内存系统代理之间的一致性。
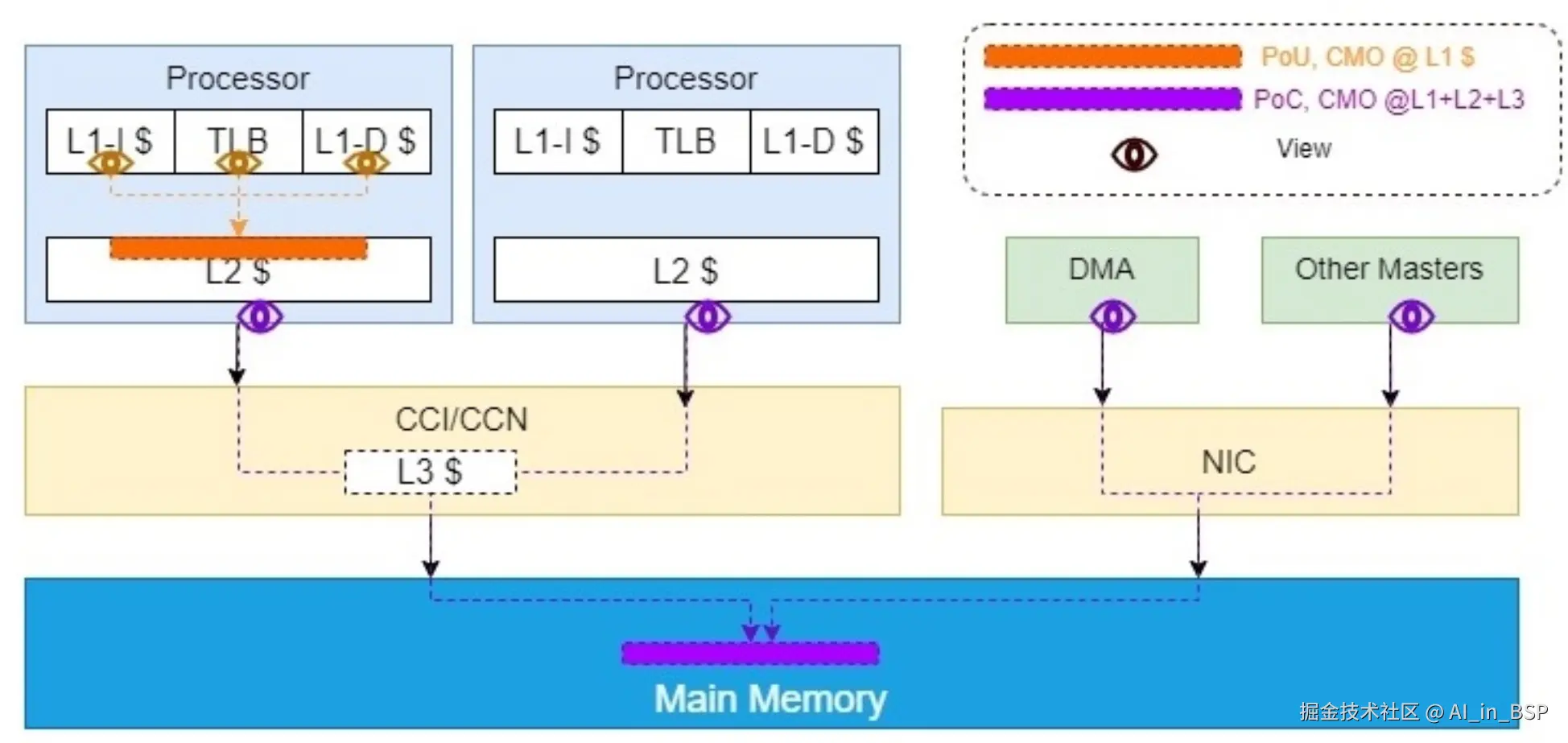
source:arm处理器cache结构的进化,及PoC, PoU的使用-技术社区
- PoU(Point of Unification,处理器缓存一致性角度):是指对于某一个CPU核心及其ICache、Dcache以及TLB,如果在某一点上,它们能看到一致的内容,那么这个点就是PoU。如上图所示PoU点在L2Cache上;
- PoC(Point of Coherency,全局缓存一致性角度):是指对于系统中所有Master( CPU、DMA以及其他master),如果存在某个点,它们的指令,数据缓存和TLB能看到同一个源,那么这个点就是PoC。如上图右侧,L2 Cache此时不能作为PoC,因为 DMA和其他master在它的范围之外直接访问内存。所以此时内存是PoC。
我们使用CMO(Cache Maintenance Operation)操作的时候,可以看到不同指令的范围,如下所示:
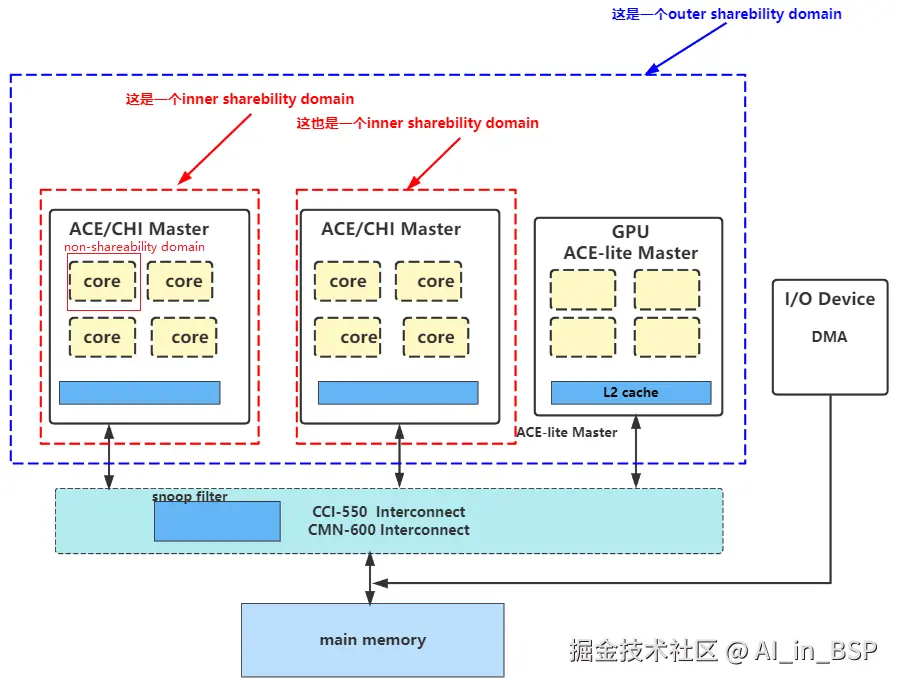
source:有关Inner、Outer等相关词汇的理解(二)-技术社区
- Shareability 属性: Shareability的由来为了支持数据一致性协议,需要增加硬件很多开销,会降低系统的性能,同时也会增加系统的功耗。但是,很多时候并不需要系统中的所有模块之间都保持数据一致性,而只需要在系统中的某些模块之间保证数据一致性就行了。因此,需要对系统中的所有模块,根据数据一致性的要求,做出更细粒度的划分;
- Non-Shareable 属性:配置为 non-shareable 属性的内存位置一般只能被唯一处理器访问, 如果还有其他处理器能访问该位置,需要软件用缓存一致性指令来保证缓存一致性。比如:在单核的场景下,cpu 往某一块配置为non-shareable (同时配置了cacheable)属性的内存写一段数据,由于这段内存只对cpu可见,所以如果当使用DMA来搬运这块内存中的数据时,需要先进行 cache clean 将缓存中的数据刷入memory中,否者dma搬运的数据可能会有一些stale data。
- Inner-Shareable 属性:该内存位置可以被 Inner Shareability domain 中的所有处理器访问,并且硬件保证该位置在这些处理器间的数据一致性,Inner Shareability domain中的处理器一般被同一个 虚拟机 监视器或操作系统控制,如下图中的两个 cluseter 都在 inner shareability domain中。一般不同的cluseter会共享L2 cache;
- Out-Shareable 属性:能被外部共享的观察者(cpu, gpu, dma) 观察到,它适用于内部可共享和外部可共享域。一个outer shareable domain 可以由一个或多个 inner shareable domain组成,并且当一个操作影响到outer shareable domain时,也会影响到其下所有的 inner shareable domain。
只有配置为 Normal Memory 内存属性的内存才能设置 inner 和 outer shareability,device memory 是不能设置 Shareability。另外,这些shareability属性是硬件连线。当然也有CPU寄存器(AArch64_clidr_el1)可以读出来他们之间的连接关系。
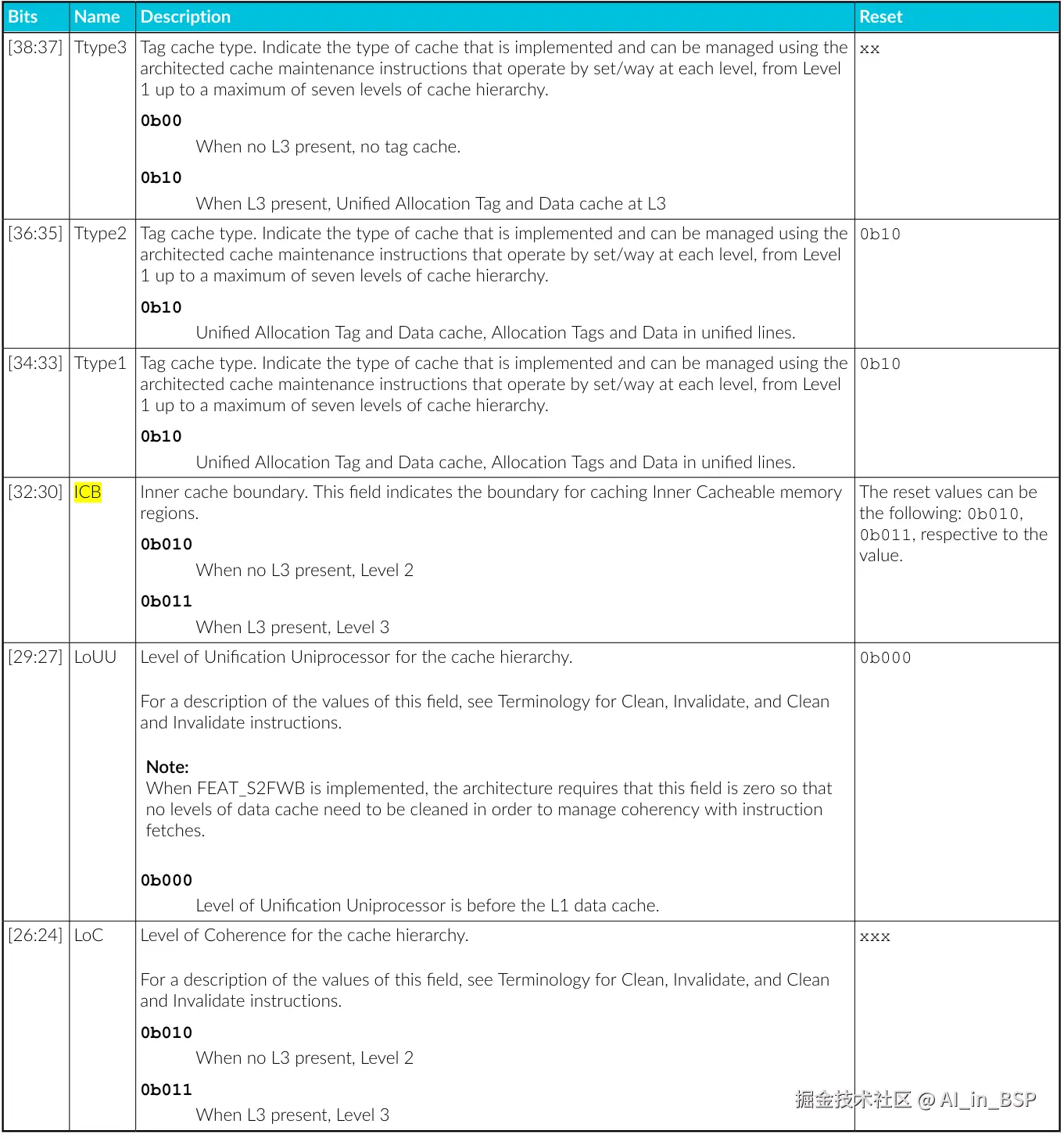
搞清楚上述基础概念,我们底层软件程序员就知道如何指定下列CMO操作的范围了:
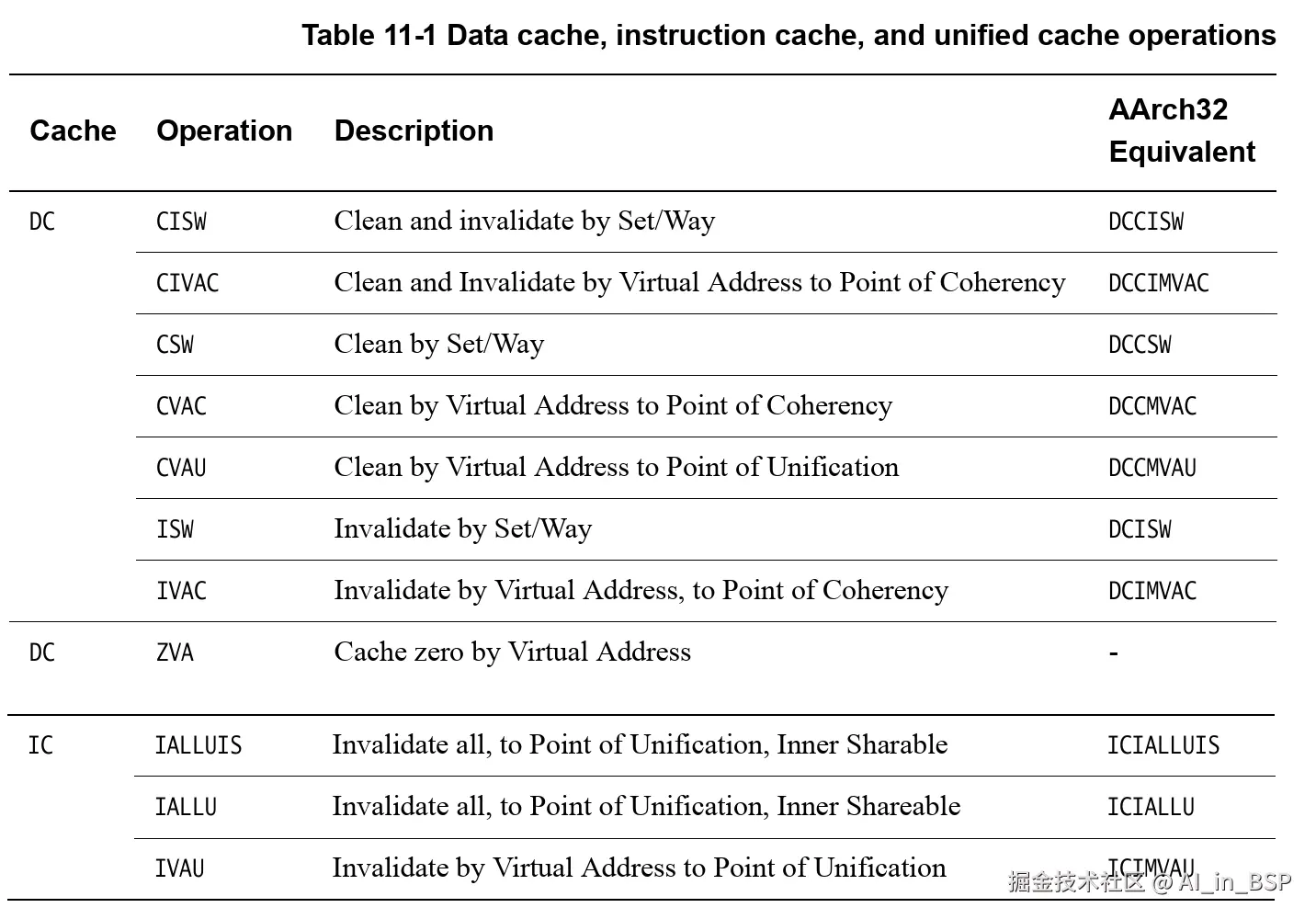
伪共享的问题
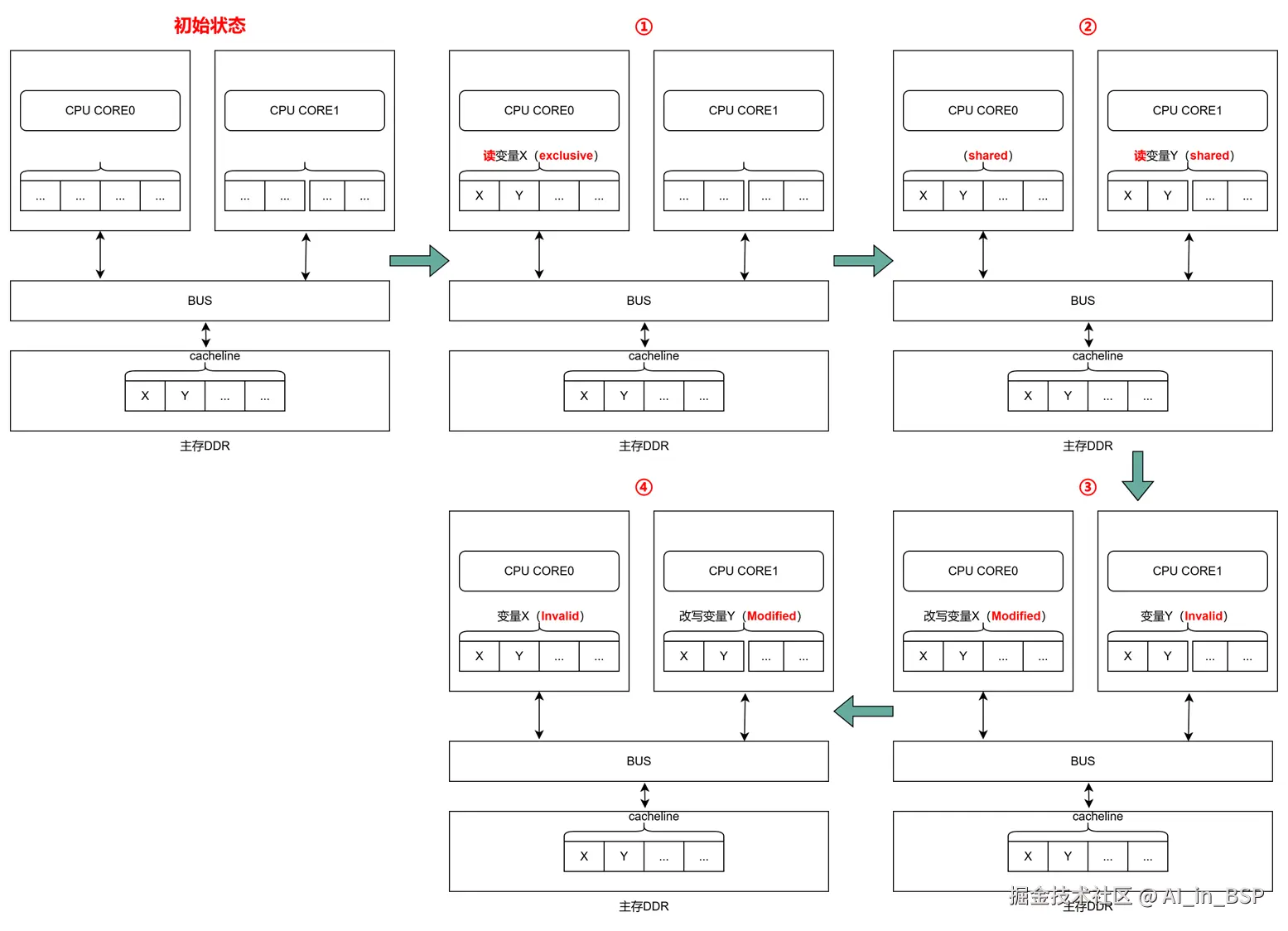 如上图所示,假设有两个变量X和Y,在PA上挨着放置,分别在CPU0和CPU1上,现在有两个线程A和B分别支访问X和Y。初始状态下只在主存DDR中。假设经历以下几个过程:
如上图所示,假设有两个变量X和Y,在PA上挨着放置,分别在CPU0和CPU1上,现在有两个线程A和B分别支访问X和Y。初始状态下只在主存DDR中。假设经历以下几个过程:
| 当前操作 | CPU0 | CPU1 | Memory | 说明 |
|---|---|---|---|---|
| ① CPU0 read(X) | X=1 (E) | X=1,Y=1 | CPU0读取变量 X,把变量 Y也会读取CPU0的cache中。 cacheline状态是 Exclusive |
|
| ② CPU1 read(Y) | X=1 (S) | Y=1(S) | X=1,Y=1 | CPU1读取变量 Y,把变量 X也会读取CPU1的cache中。 cacheline状态都是 Shared |
| ③ CPU0 write(X,2) | x=2 (M) | Y=1(I) | X=2,Y=1 | CPU0改写变量 X,通过总线发消息给CPU1将其状态变为 Invalid 。然后CPU0的cacheline状态变更为 Modified,最终主存中X也被写为2 |
| ④ CPU1 write(Y,2) | x=2 (I) | X=2(M) | X=2,Y=2 | CPU1改写变量 Y,通过总线发消息给CPU0将其状态变为 Invalid 。然后CPU1的cacheline状态变更为 Modified,最终主存中Y也被写为2 |
如果依次重复步骤③和步骤④,最终发现Cache 并没有起到缓存的效果,尽管变量 X和 Y之间逻辑上并没有任何的关系,但是因为同时归属于一个 Cache Line ,这个 Cache Line 中的任意数据被修改后,都会相互影响,导致不断有cache失效,出现cache颠簸。这种多个线程同时读写同一个 Cache Line 的不同变量时,而导致 CPU Cache 失效的现象称为伪共享( False Sharing )。
在 Linux 内核中使用 __cacheline_aligned_in_smp 宏定义,将这两个变量强制隔开,分散到2个cacheline中即可解决该问题。(本质上用空间换性能)
如何探查各级cache
我们还是以高通SM8650平台为例,我们以X4超大核和A510小核为例,进行测试,最后和官方给出的数据对比,校正下我们的测试程序是否正确。
cacheline探查
笔者对比网上多个测试benchmark,最后还是 lmbench自带的 line测试程序能更准确的完成高通sm8650平台的cacheline测量。
核心代码是line.c,line_find函数如下,我们只看核心逻辑:
c
size_t
line_find(size_t len, int warmup, int repetitions, struct mem_state* state)
{
size_t i, j, big_jump, line;
size_t maxline = getpagesize() / 16;
double baseline, t;
big_jump = 0;
line = 0;
state->line = sizeof(char*); // 从8个字节开始猜cacheline代销
line_initialize(0, state); // 1.
for (i = sizeof(char*); i <= maxline; i<<=1) {
t = line_test(i, warmup, repetitions, state); //2.
if (t == 0.) break;
if (i > sizeof(char*)) { //3.
if (t > 1.3 * baseline) {
big_jump = 1;
} else if (big_jump && t < 1.15 * baseline) {
line = (i>>1);
break;
}
}
baseline = t;
}
return line;
}核心代码有三段,分别是:
line_initialize:该函数逻辑与前文lmbench的latency类似,创建一个特殊的循环列表(访问顺序随机,cacheline的第一个元素来存放指针),用于测试不同缓存行大小下的内存访问性能;line_test:该函数的测量在特定缓存行大小下遍历指针链的性能。它接收一个假设的缓存行大小,并返回按照该大小访问内存的平均时间(这个函数内的其他细节跟之前分析的latency及其类似,不再赘述);- 通过比较不同cacheline大小访存时间的变化,当检测到一个性能突变点(时间变大然后又回落到一个较小值),认为这是大小就是cacheline大小
我们来看下高通8650平台进行实测分析,首先打开 line_test函数中的打印。
c
double line_test(size_t line, int warmup, int repetitions, struct mem_state* state)
{
// 省略
set_results(r_save);
free(r);
// 打开这个注释掉的代码
fprintf(stderr, "%d\t%.5f\t%d\n", line, t, state->len);
/* fixup full path again */
if (nlines < state->nlines) {
// 省略其他代码
}
}交叉编译 lmbench后的,选择 line这个binary放到8650设备进行实测,结果如下:
bash
# taskset 80 ./line
8 3.60496 67108864
16 4.14573 67108864
32 6.44596 67108864
64 7.94071 67108864
128 6.10419 67108864
64
# taskset 80 ./line
8 3.87029 67108864
16 4.32956 67108864
32 5.89473 67108864
64 8.84220 67108864
128 6.50318 67108864
64
# taskset 01 ./line
8 20.84050 67108864
16 24.99751 67108864
32 59.05088 67108864
64 134.59870 67108864
128 115.08443 67108864
64
# taskset 01 ./line
8 20.16442 67108864
16 27.64931 67108864
32 59.02939 67108864
64 121.27737 67108864
128 122.01869 67108864
64我们分别测试了X4和A510这两个CPU核心。输出的三列分别是猜测的cacheline大小、访存延迟,访存总大小。其中都是64Byte时访存延迟突然增大,然后128Byte处回落,逻辑比较合理,同时也跟这两个CPU TRM的数据一致,猜测合理。
各级cache大小探查
笔者对比网上多个测试benchmark,最后还是阿里云开发社区的揭秘 cache 访问延迟背后的计算机原理.同样考虑TLB的影响这块,后续需要继续改进,这里主要看测试思路。
代码就不贴了(如需代码留言获取,后续会整理到GitHub上),本质上还是类似 lmbench的 latency测试case,跟cacheline也有类似之处,区别在于,我们相同访存大小落在不同cache区间内的访存延迟不一样,直接看实测结果(以高通8650 X4超大核CPU核心为例):
bash
# taskset 80 ./test-mem-lat.sh
Buffer size: 1 KB, stride 128, time 0.001431 s, latency 1.36 ns
Buffer size: 2 KB, stride 128, time 0.001293 s, latency 1.23 ns
Buffer size: 4 KB, stride 128, time 0.001270 s, latency 1.21 ns
Buffer size: 8 KB, stride 128, time 0.001270 s, latency 1.21 ns
Buffer size: 16 KB, stride 128, time 0.001272 s, latency 1.21 ns
Buffer size: 32 KB, stride 128, time 0.001327 s, latency 1.27 ns
Buffer size: 64 KB, stride 128, time 0.001330 s, latency 1.27 ns
# 以上落到L1 cache区间内(64KB),后面出现延迟跳变点
Buffer size: 128 KB, stride 128, time 0.002785 s, latency 2.66 ns
Buffer size: 256 KB, stride 128, time 0.003088 s, latency 2.95 ns
Buffer size: 512 KB, stride 128, time 0.003719 s, latency 3.55 ns
Buffer size: 1024 KB, stride 128, time 0.004473 s, latency 4.27 ns
Buffer size: 2048 KB, stride 128, time 0.004997 s, latency 4.77 ns
# 以上落到L2 cache和上级cache区间内(2MB,L1/L2总共包住2MB+64KB大小)
Buffer size: 4096 KB, stride 128, time 0.006283 s, latency 5.99 ns
Buffer size: 8192 KB, stride 128, time 0.008005 s, latency 7.63 ns
# 以上落到L3 cache和上级cache区间内(12MB,L2/L3总共包住略大于14MB大小)
Buffer size: 16384 KB, stride 128, time 0.019004 s, latency 18.12 ns
# 以上落到SLC cache和上级cache区间内(6MB;L2/L3/SLC总共包住略大于20MB大小)
Buffer size: 32768 KB, stride 128, time 0.069055 s, latency 65.86 ns
Buffer size: 65536 KB, stride 128, time 0.100027 s, latency 95.40 ns可以看到:
- 在cache大小包住的范围内,访存较小,每一级cache处,出现访存时延的跳变;
- 考虑到L1/L2 cache大小一般是2的整数次幂,从2MB往后访存间隔可以以每MB左右递增,对源码进行改造,以便更准确测出各级cache大小
cache友好的编程建议
最基本cache友好程序实例
利用缓存空间局部性的最佳方式是进行顺序内存访问。通过这样做,可以让硬件预取器识别内存访问模式并提前引入下一块数据(同时cacheline也能保证能多获取一些数据到cache中)。它执行了此类缓存友好访问。该代码之所以"缓存友好":
c
for (row = 0; row < NUMROWS; row++)
for (column = 0; column < NUMCOLUMNS; column++)
matrix[row][column] = row + column;这是经典例子,但现实世界中的应用程序通常要复杂得多,需要付出更多努力才能编写缓存友好的代码。例如,在已排序的大数组中进行二分搜索的标准实现并没有利用空间局部性,因为它测试的是彼此相距甚远、不共享同一缓存行的不同位置的元素。解决这个问题最著名的方式是使用 Eytzinger 布局存储数组元素。
数据布局优化
将频繁访问的字段集中放置,如下代码所示
c
struct HotData {
int key; // 热数据
char metadata[4]; // 热数据
//...其他高频访问字段
// 填充剩余字节
char padding[cacheline- sizeof(int) - sizeof(double)];
};- 程序相关管理数据结构放在同一个结构体中,关联性大尽量集中一起放置;
- 整个结构体对齐到cacheline。
避免伪共享问题
为了解决上文提到的伪共享,可以填充 S 使得成员 a 和 b 不共享同一个缓存行,如 下所示:
基线版本代码版本:
c
struct S {
int a; // written by thread A
int b; // written by thread B
};改进版本(在 Linux 内核中使用 __cacheline_aligned_in_smp宏即可):
c
#define CACHELINE_ALIGN alignas(64)
struct S {
int a; // written by thread A
CACHELINE_ALIGN int b; // written by thread B
};显式的内存预取
在Linux中有专门API进行预取
c
# 提示CPU预取指定地址的数据到缓存层级(通常L1或L2)
void prefetch(const void *addr)
# 批量预取连续内存区域(通常以cacheline为单位)
void prefetch_range(void *addr, size_t len);
c
// 链表遍历预取示例
struct list_head *p;
prefetch(list_next(p)); // 预取下个节点
for (p = list; p != NULL; p = p->next) {
prefetch(p->next); // 流水线预取
process_data(p->data);
}减少TLB Miss的影响
使用大页面通常会导致更少的页面遍历,并且在 TLB 未命中情况下遍历内核页表的惩罚也会减少,因为表本身更加紧凑。
Linux 供透明大页面支持 (THP),它具有两种操作模式:系统范围和每个进程。启用系统范围的 THP 时,内核会自动管理大页面,这对应用程序是透明的。操作系统内核尝试在需要大量内存块时将大页面分配给任何进程,并且如果可以分配这样的页面,则无需手动保留大页面。如果启用每个进程的 THP,内核仅将大页面分配给单个进程的内存区域。
另外,例如Android15内核的page size已经切换成16KB大小,也可以减少TLB miss提高性能。
细节本文不再展开
验证
具体验证可结合本系列文章arm top-down方法论验证
本文完,周末愉快!
下一篇我们专门讨论下system level cache。
参考
- 多级cache的包含策略(Cache inclusion policy)
- 什么是伪共享-小林coding
- 10 张图打开 CPU 缓存一致性的大门-小林coding
- 与程序员相关的CPU缓存知识-coolshell
- 知乎-高速缓存与一致性专栏-smcdef
- Arm® Cortex®-X4 Core Technical Reference Manual
- Arm® DynamIQ™ Shared Unit-110 Technical Reference Manual
- ARM® Cortex®-A Series Programmer's Guide for ARMv8-A
- ARM Cache 与 MMU 系列文章 2 -- Cache Coherence及内存顺序模学习-博客园
- 揭秘 cache 访问延迟背后的计算机原理-阿里云开发者社区
- 《Performance Analysis and Tuning on Modern CPU》