Python基础全总结
- [一. python基础知识](#一. python基础知识)
-
- [1. 单行注释](#1. 单行注释)
- [2. 多行注释](#2. 多行注释)
- [3. 算术运算符](#3. 算术运算符)
- [4. 比较运算符](#4. 比较运算符)
- [5. 逻辑运算符](#5. 逻辑运算符)
- [6. 赋值运算符](#6. 赋值运算符)
- [7. 运算符的优先级](#7. 运算符的优先级)
- [8. 变量的命名和使用](#8. 变量的命名和使用)
- [9. 格式化输出与格式化符号](#9. 格式化输出与格式化符号)
- [10. 常量](#10. 常量)
- [11. 字符串](#11. 字符串)
- [12. 字符串常用的操作方法](#12. 字符串常用的操作方法)
- [13. if语句](#13. if语句)
- 14.循环语句
- [15. break 和 continue](#15. break 和 continue)
- [16. 列表](#16. 列表)
- [17. 元组](#17. 元组)
- [18. 字典](#18. 字典)
- [19. 集合](#19. 集合)
- [20. 函数](#20. 函数)
- [21. 类与面向对象](#21. 类与面向对象)
- [22. 模块](#22. 模块)
- [23. 异常](#23. 异常)
- [24. 文件操作](#24. 文件操作)
- [25. with语句](#25. with语句)
- [26. json操作](#26. json操作)
- 27.单元测试
人生苦短,我用python
一. python基础知识
1. 单行注释
单行注释以 # 开头,# 右边的所有东西都被当做说明文字,而不是真正要执行的程序,只起到辅助说明作用。单行注释既可以但独占一行,也可以位于标识的代码之后,与标识的代码共占一行。示例代码如下:
python
# 这是第一个单行注释
print("hello python")为了保证代码的可读性,# 后面建议先添加一个空格,然后再编写相应的说明文字。
在程序开发时,同样可以使用 # 在代码的后面(旁边)增加说明性的文字。但是,需要注意的是,为了保证代码的可读性 ,注释和代码之间 至少要有 两个空格。示例代码如下:
python
print("hello python") # 输出 `hello python`2. 多行注释
如果希望编写的 注释信息很多,一行无法显示 ,就可以使用多行注释。要在 Python 程序中使用多行注释,可以用 一对 连续的 三个 引号(单引号和双引号都可以)。示例代码如下:
python
"""
这是一个多行注释
在多行注释之间,可以写很多很多的内容......
"""
print("hello python")3. 算术运算符
| 运算符 | 描述 | 实例 |
|---|---|---|
| + | 加 | 10 + 20 = 30 |
| - | 减 | 10 - 20 = -10 |
| * | 乘 | 10 * 20 = 200 |
| / | 除 | 10 / 20 = 0.5 |
| // | 取整除(向下取整,即返回商的整数部分) | 返回除法的整数部分(商) 9 // 2 输出结果 4 |
| % | 取余数 | 返回除法的余数 9 % 2 = 1 |
| ** | 幂 | 又称次方、乘方,2 ** 3 = 8 |
在 Python 中 * 运算符还可以用于字符串,计算结果就是字符串重复指定次数的结果
python
print("-" * 50)
# 输出--------------------------------------------------将任意两个数相除时,结果总是浮点数,即便是两个数都是整数且能整除。
python
print(4/2)
# 输出2.0在其他任何运算中,如果一个操作数是整数,另一个操作数是浮点数,则其结果也总是浮点数。
python
print(1+1.0)
print(1*2.0)
# 输出2.0 2.0数中的下划线:书写很大的数字时,可以使用下划线将其中的数字分组,使其更清晰易懂。如 14_000_000_000等于14000000000,在python里这样定义数时,不会打印其中的下划线。
python
print(14_000_000_000)
# 输出140000000004. 比较运算符
| 运算符 | 描述 |
|---|---|
| == | 检查两个操作数的值是否 相等,如果是,则条件成立,返回 True |
| != | 检查两个操作数的值是否 不相等,如果是,则条件成立,返回 True |
| > | 检查左操作数的值是否 大于 右操作数的值,如果是,则条件成立,返回 True |
| < | 检查左操作数的值是否 小于 右操作数的值,如果是,则条件成立,返回 True |
| >= | 检查左操作数的值是否 大于或等于 右操作数的值,如果是,则条件成立,返回 True |
| <= | 检查左操作数的值是否 小于或等于 右操作数的值,如果是,则条件成立,返回 True |
5. 逻辑运算符
| 运算符 | 逻辑表达式 | 描述 |
|---|---|---|
| and | x and y | 只有 x 和 y 的值都为 True,才会返回 True 否则只要 x 或者 y 有一个值为 False,就返回 False |
| or | x or y | 只要 x 或者 y 有一个值为 True,就返回 True 只有 x 和 y 的值都为 False,才会返回 False |
| not | not x | 如果 x 为 True,返回 False 如果 x 为 False,返回 True |
6. 赋值运算符
| 运算符 | 描述 | 实例 |
|---|---|---|
| = | 简单的赋值运算符 | c = a + b 将 a + b 的运算结果赋值为 c |
| += | 加法赋值运算符 | c += a 等效于 c = c + a |
| -= | 减法赋值运算符 | c -= a 等效于 c = c - a |
| *= | 乘法赋值运算符 | c *= a 等效于 c = c * a |
| /= | 除法赋值运算符 | c /= a 等效于 c = c / a |
| //= | 取整除赋值运算符 | c //= a 等效于 c = c // a |
| %= | 取 模 (余数)赋值运算符 | c %= a 等效于 c = c % a |
| **= | 幂赋值运算符 | c **= a 等效于 c = c ** a |
7. 运算符的优先级
以下表格的算数优先级由高到最低顺序排列:
| 运算符 | 描述 |
|---|---|
| ** | 幂 (最高优先级) |
| * / % // | 乘、除、取余数、取整除 |
| + - | 加法、减法 |
| <= < > >= | 比较运算符 |
| == != | 等于运算符 |
| = %= /= //= -= += *= **= | 赋值运算符 |
| not or and | 逻辑运算符 |
8. 变量的命名和使用
(1) 变量定义
在 Python 中,每个变量在使用前都必须赋值 ,变量赋值以后 该变量才会被创建 。等号=用来给变量赋值 , = 的左边是一个变量名 ,= 的右边是存储在变量中的值,变量定义之后,后续就可以直接使用了,不用声明变量类型。
python
变量名 = 值可在一行代码中给多个变量赋值,这有助于缩短程序并提高其可读性。这种做法最常用于将一系列数赋给一组变量。
例如,下面演示了如何将变量 x、y 和 z 都初始化为零:
python
x, y, z = 0, 0, 0在程序中,可以随时更改变量的值,而python始终记录变量的最新值。变量名只能包含字母、数字、下划线,变量名不能有空格,要用下划线_取代空格。不要用关键字做变量名,变量名尽量简短有意义,严格区分大小写。变量名能以字母或下划线打头,但不能以数字打头。
(2) python数据类型
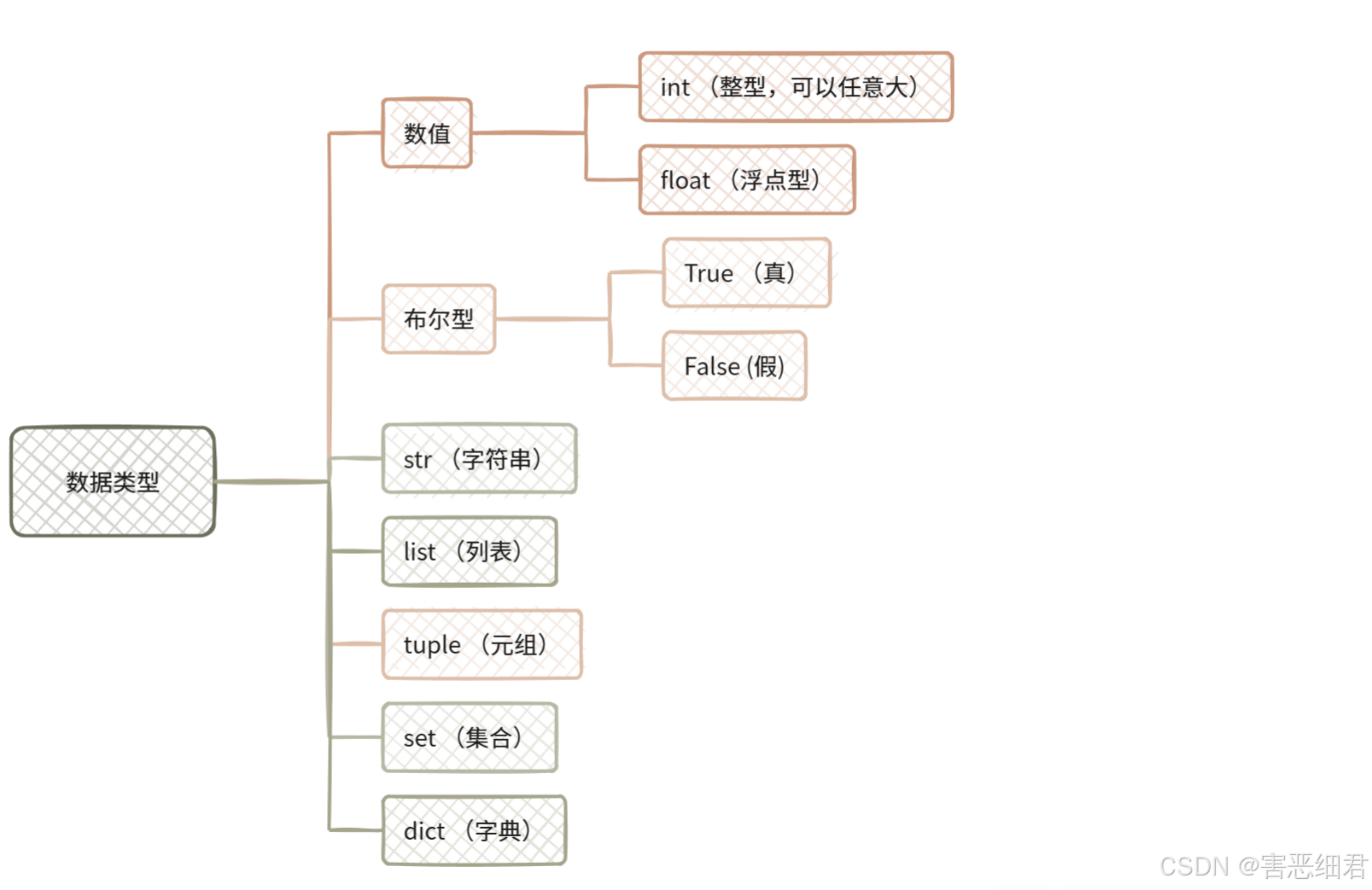
可以使用 type() 函数可以查看一个变量的类型。
9. 格式化输出与格式化符号
| 常用的格式化符号 | 作用 |
|---|---|
| %s | 字符串 |
| %d | 有符号的十进制整数 |
| %f | 浮点数 |
| %c | 字符 |
| %u | 无符号的十进制整数 |
| %0 | 八进制整数 |
举例:
python
age = 18
name = 'tom'
weight = 75.5
stu_id = 1
print("年龄:%d岁" % age)
print("名字:%s" % name)
print("体重:%2f公斤" % weight)
print("学号为:%06d" % stu_id)
print("我是%s,今年%d岁。" % (name,age))在 Python 3.6 + 中,推荐使用 f-string 进行格式化,语法更简洁、可读性更高,上述代码可改写为:
python
age = 18
name = 'tom'
weight = 75.5
stu_id = 1
print(f"年龄:{age}岁") # 直接嵌入变量
print(f"名字:{name}") # 字符串无需额外处理
print(f"体重:{weight:.2f}公斤") # 控制浮点数保留2位小数(更实用)
print(f"学号为:{stu_id:06d}") # 控制整数固定6位,不足补0
print(f"我是{name},今年{age}岁。")在 Python 中还可以使用 input 函数从键盘等待用户的输入,用户输入的 任何内容 Python 都认为是一个 字符串 ,语法如下:
python
字符串变量 = input("提示信息:")10. 常量
常量(constant)是在程序的整个生命周期内都保持不变的变量。Python 没有内置的常量类型,但 Python 程序员会使用全大写字母来指出应将某个变量视为常量,其值应始终不变:
python
MAX_CONNECTIONS = 5000在代码中,要指出应将特定的变量视为常量,可将其变量名全大写。
11. 字符串
在python中,用引号括起来的都是字符串,其中的引号可以是单引号',也可以是双引号",也可以是三引号""",三引号的字符串支持换行。
在字符串中,使用变量:
python
first_name = "ada"
last_name = "lovelace"
full_name = f"{first_name} {last_name}"
print(full_name)这是python3.6+引入的,如果使用3.6之前的版本,则需要用format() 方法:
python
full_name = "{}{}".format(first_name,last_name)字符串的下标:可以通过字符串的变量名来获取字符串中的字符。
python
str = "abc"
print(str[1]) # b12. 字符串常用的操作方法
(1) 查找字符串
find() 检测某个字符串是否包含在这个字符串中。如果在,返回这个子串开始位置的下标,否则返回-1。语法如下:
python
字符串序列.find(子串,开始下标,结束下标)注意:开始和结束下标的位置可以省略,标识在整个字符串中查找。
index() 方法和 find()方法用法基本一样:
python
字符串序列.index(子串,开始位置,结束位置)但是,find在找不到子串的时候返回-1 , 而index在找不到子串的时候报错显示找不到字符串。
(2) 修改字符串
replace() :返回修改后的字符串,不影响原来的字符串。语法如下:
python
字符串系列.replace(旧字符串,新子串,替换次数)替换次数可以不写。
split():按照指定字符串分割字符串,返回一个list列表。语法如下:
python
字符串系列.split(分割字符,num)num为出现分割字符的次数,可以不写。
join() :用一个字符串或子串合并字符串,即将多个字符串合并为一个字符串。语法如下:
python
字符串.join(多个字符串)eg:
python
list1 = ["zero","zaki","haiexijun"]
print("_".join(list1)) # zero_zaki_haiexijuntittle() :以首字母大写的方式显示每个单词,即每个单词的首字母都改为大写。
capitalize() :仅仅只把字符串第一个字母大写,其他的字符都小写。
python中可以对字符串的空白进行操作,比如删除空白:
rstrip() :删除字符串右侧的空白字符
lstrip() :删除字符串左侧的空白字符
strip() :删除字符串两侧的空白字符
注意:这些修改操作均不影响原来的字符串。
(3) 判断字符串
此类方法返回的结果为True 或 False
startswith() :判断字符串是否以指定子串开头
python
字符串序列.startswith(子串,开始下标,结束下标)开始下标和结束下标可以省略,写了则设定其判断范围。
endswith() :判断字符串是否以指定子串结尾
python
字符串序列.endswith(子串,开始下标,结束下标)开始下标和结束下标可以省略,写了则设定其判断范围。
len(字符串) :用于获取字符串的长度。
isalpha() :如果字符串至少有一个字符并且所有的字符都是字母,返回True,否则返回False。
isdight() :判断字符串里是否包含数字。
isspace() :判断字符串里面是否含有空格。
(4) 切片
切片指的是对操作的对象截取其中一部分的操作。字符串、列表、元组都支持切片操作。语法如下:
python
序列[开始位置的下标:结束位置的下标:步长]注意:不包含结束位置下标对应的数据。正负整数都可以做下标。步长是选取间隔,正负数均可,默认步长为1.
python
str = "012345678"
print(str[2:5:2]) # 24
print(str[2:5]) # 23413. if语句
判断是否相等可以用到! 和 != ,如果有多个条件,用and 或 or。
(1) 简单的 if 语句
python
if 判断表达式:
执行语句执行语句要有缩进,没有缩进则不会属于if语句里面。
python
age = 19
if age >= 18:
print("你大于等于18岁")(2) if-else 语句
python
if 判断表达式:
执行语句1
else:
执行语句2举例:
python
age = 11
if age >= 18:
print("你大于等于18岁")
else:
print("你未满18岁")(3) if-elif-else 语句
你经常需要检查两个以上的情形,此时可使用 Python 提供的 if-elif-else 语句。还可以根据需要使用任意数量的 elif 代码块。
python
if 判断表达式1:
执行语句1
elif 判断表达式2:
执行语句2
else:
执行语句3age >=18 and age <=21 可以写成 18 <= age <= 21
14.循环语句
(1) while循环
while 循环是 Python 中用于实现重复执行代码块的核心结构之一,其核心逻辑是 "条件为真则持续执行",直到循环条件变为 False 时终止。
while 循环的本质是 "基于条件的迭代":先判断条件,再决定是否执行循环体(代码块)。基本语法如下:
python
while 循环条件: # 条件必须是布尔表达式(结果为 True/False)
循环体代码块 # 条件为 True 时执行,需缩进(通常 4 个空格)
[可选:更新循环条件变量的代码] # 避免无限循环的关键举例:
python
x = 1 # 初始化循环变量
while x <= 5: # 循环条件:x 不大于 5
print(x) # 循环体:打印 x
x += 1 # 更新循环变量(x 自增 1)
print("循环结束")死循环 :由于程序员的原因,忘记 在循环内部 修改循环的判断条件,导致循环持续执行,程序无法终止!
(2) for循环
在 Python 中,for 循环是一种常用的迭代结构,用于遍历序列(如列表、元组、字符串)或其他可迭代对象。
基本语法:
python
for 变量 in 可迭代对象:
# 循环体(缩进部分)常见用法:
(1) 遍历列表
python
fruits = ["苹果", "香蕉", "橙子"]
for fruit in fruits:
print(fruit)(2) 遍历字符串
python
message = "Hello"
for char in message:
print(char)(3) 使用 range() 函数生成数字序列
python
# 打印 0 到 4(不包含 5)
for i in range(5):
print(i)
# 打印 2 到 6(不包含 7)
for i in range(2, 7):
print(i)
# 打印 1 到 10 之间的奇数(步长为 2)
for i in range(1, 11, 2):
print(i)(4) 遍历字典
python
person = {"name": "张三", "age": 30, "city": "北京"}
# 遍历键
for key in person:
print(key)
# 遍历值
for value in person.values():
print(value)
# 同时遍历键和值
for key, value in person.items():
print(f"{key}: {value}")(5) 嵌套循环
python
# 打印 5x5 的乘法表
for i in range(1, 6):
for j in range(1, 6):
print(f"{i}x{j}={i*j}", end="\t")
print() # 换行15. break 和 continue
在 Python 中,break 和 continue 是用于控制循环流程的关键字。
(1) break 语句
break 用于立即终止当前所在的循环,并跳出循环体,继续执行循环之后的代码。
python
for i in range(1, 10):
if i == 5:
print("遇到 5,终止循环")
break # 当 i 等于 5 时,立即终止循环
print(i)
# 输出:
# 1
# 2
# 3
# 4
# 遇到 5,终止循环(2) continue 语句
continue 用于跳过当前循环中的剩余代码,直接进入下一次循环的判断条件。
python
for i in range(1, 10):
if i % 2 == 0:
continue # 当 i 是偶数时,跳过本次循环的剩余代码
print(i) # 只打印奇数
# 输出:
# 1
# 3
# 5
# 7
# 916. 列表
列表由一系列按特定顺序排列的元素组成用逗号隔开。列表中可以包含数字、字母、列表等其他数据,其中的元素之间可以没有任何关系,可以是不同类型。
python
list1 = [1,"haiexijun",[1,2],{"age":23}](1) 访问列表元素
通过索引(从 0 开始)访问列表中的元素:
python
fruits = ["apple", "banana", "cherry"]
print(fruits[0]) # 输出: apple(第一个元素)
print(fruits[-1]) # 输出: cherry(最后一个元素,负索引表示从末尾开始)索引可以是负数,此时索引为负索引加列表长度。
index() 返回指定数据所在下标,如果不存在则报错。
count() 统计指定数据在当前列表中出现的次数
len(列表名) 用于统计列表的长度
in :判断指定数据是否在某个列表中,是则返回True。not in :判断指定数据是否不在某个列表中,不在返回True。
(2) 修改列表元素
通过索引直接修改元素:
python
fruits = ["apple", "banana", "cherry"]
fruits[1] = "orange"
print(fruits) # 输出: ["apple", "orange", "cherry"]append() :向列表的结尾追加数据,语法:列表序列.append(数据) 。如果append() 追加的数据是一个序列,则追加整个序列到列表。
insert() :可以在列表的任何位置添加新元素。语法:列表序列.insert(位置下标,数据)
python
fruits = ["apple", "banana"]
fruits.append("cherry") # 在末尾添加元素,输出: ["apple", "banana", "cherry"]
fruits.insert(1, "orange") # 在指定索引插入元素,输出: ["apple", "orange", "banana", "cherry"]
fruits.append(["red","pink"]) # 输出['apple', 'orange', 'banana', 'cherry', ['red', 'pink']]extend() :向列表结尾最佳数据,如果数据是一个序列,则将这个序列逐一加到列表。
python
fruits.extend(["red","pink"]) # 输出['apple', 'orange', 'banana', 'cherry', 'red', 'pink'](3) 删除元素
使用del语句删除列表中的元素,要知道需要删除的元素的下标。
python
name = ["zc","zwb","yjw"]
del name[0] # ['zwb', 'yjw']可以使用pop()删除列表末尾的元素,但可以传入下标,来删除任意指定位置的元素。这个方法会返回被删除那个元素。
可以使用remove() 移除列表中的某个元素。传入元素的值进行删除。如果一个列表中有两个相同的值,则remove会移除第一个值,而不会全部移除。
python
fruits = ["apple", "banana", "cherry"]
fruits.remove("banana") # 删除指定值的元素,输出: ["apple", "cherry"]
popped = fruits.pop(0) # 删除指定索引的元素并返回,输出: ["cherry"],popped的值为"apple"(4) 列表的遍历
使用 for 循环遍历列表元素:
python
fruits = ["apple", "banana", "cherry"]
for fruit in fruits:
print(fruit)(5) 列表解析
列表解析将for循环和创建新元素的代码合并成一行,并自动附加新元素。
python
squares = [value**2 for value in range(1,11)]
print(squares) # [1, 4, 9, 16, 25, 36, 49, 64, 81, 100](6) 复制列表
copy():用于复制列表
python
name = ["zc","zwb","yjw"]
list1 = name.copy()(7) 列表切片
Python 列表切片是一种非常灵活的操作,可以快速获取列表中的部分元素。切片操作的基本语法是 list[start:end:step],其中:start:起始索引(包含该位置元素),end:结束索引(不包含该位置元素),step:步长(可选,默认为 1)。**切片操作不会修改原列表,而是返回一个新的子列表(切片赋值除外)。**当 start 大于等于 end 时,会返回空列表。合理使用切片可以让代码更简洁高效。
基本切片:
python
numbers = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
# 获取索引 2 到 5 的元素(不包含索引 5)
print(numbers[2:5]) # 输出: [2, 3, 4]
# 从开头到索引 4
print(numbers[:4]) # 输出: [0, 1, 2, 3]
# 从索引 6 到结尾
print(numbers[6:]) # 输出: [6, 7, 8, 9]指定步长:
python
# 每隔一个元素取一个(步长为 2)
print(numbers[::2]) # 输出: [0, 2, 4, 6, 8]
# 从索引 1 开始,每隔 3 个元素取一个
print(numbers[1::3]) # 输出: [1, 4, 7]负索引使用:
python
# 获取最后 3 个元素
print(numbers[-3:]) # 输出: [7, 8, 9]
# 从开头到倒数第 2 个元素
print(numbers[:-2]) # 输出: [0, 1, 2, 3, 4, 5, 6, 7]逆序切片:
python
# 步长为 -1 表示逆序
print(numbers[::-1]) # 输出: [9, 8, 7, 6, 5, 4, 3, 2, 1, 0]
# 从索引 5 逆序到索引 1
print(numbers[5:0:-1]) # 输出: [5, 4, 3, 2, 1]复制列表:
要复制列表,也可以创建一个包含整个列表的切片,整个列表的切片写作[:] 。这样可以深度复制,而不受原列表的影响。
python
name1 = ["pizza","apple","cake"]
naem2 = name1[:](8) 列表推导式
列表推导式是 Python 中一种简洁高效的创建列表的方式,它可以用一行代码实现原本需要多行循环和条件判断才能完成的列表创建操作。
基本语法格式如下:
python
[表达式 for 变量 in 可迭代对象 if 条件]基本用法:创建简单列表
python
# 生成1-10的平方列表
squares = [x**2 for x in range(1, 11)]
print(squares) # [1, 4, 9, 16, 25, 36, 49, 64, 81, 100]带条件筛选:只保留符合条件的元素
python
# 生成1-20中的偶数列表
even_numbers = [x for x in range(1, 21) if x % 2 == 0]
print(even_numbers) # [2, 4, 6, 8, 10, 12, 14, 16, 18, 20]多重循环:处理嵌套结构
python
# 生成两个列表元素的乘积(排除相同元素的乘积)
list1 = [1, 2, 3]
list2 = [4, 5, 6]
products = [x*y for x in list1 for y in list2 if x != y]
print(products) # [4, 5, 6, 4, 10, 12, 12, 15, 18]字符串处理:
python
# 将字符串列表中的每个元素转为大写
words = ["hello", "world", "python"]
upper_words = [word.upper() for word in words]
print(upper_words) # ['HELLO', 'WORLD', 'PYTHON'](9) 使用 * 获取余下的项
星号 * 可以用于序列解包(sequence unpacking),用来获取列表、元组等可迭代对象中剩余的项。这种语法非常实用,尤其在需要获取部分元素并将剩余元素打包成一个列表时。
获取列表中前几个元素和剩余元素:
python
numbers = [1, 2, 3, 4, 5, 6]
# 获取前两个元素,剩下的元素打包成一个列表
first, second, *rest = numbers
print(first) # 1
print(second) # 2
print(rest) # [3, 4, 5, 6]获取中间和剩余元素:
python
a, *middle, b = [10, 20, 30, 40, 50]
print(a) # 10
print(middle) # [20, 30, 40]
print(b) # 50处理函数参数:
python
def process_data(first, *others):
print(f"第一个元素: {first}")
print(f"其他元素: {others}")
process_data(1, 2, 3, 4, 5)
# 输出:
# 第一个元素: 1
# 其他元素: (2, 3, 4, 5)在嵌套结构中使用:
python
data = [1, 2, [3, 4, 5], 6, 7]
a, b, *c, d = data
print(a) # 1
print(b) # 2
print(c) # [[3, 4, 5], 6]
print(d) # 717. 元组
列表非常适合用于存储在程序运行期间可能变化的数据集,列表是可以修改的。你有时候需要创建一系列不可修改的元素,元组可满足这种需求。Python 将不能修改的值称为不可变的列表称为元组(tuple)。
(1) 定义元组
元组看起来很像列表,但使用圆括号而不是方括号来标识。定义元组后,就可使用索引来访问其元素,就像访问列表元素一样。
python
# 几种创建方式
t1 = (1, 2, 3)
t2 = 1, 2, 3 # 省略括号也可以
t3 = tuple([1, 2, 3]) # 使用 tuple() 函数
t4 = (5,) # 单元素元组必须加逗号,否则会被视为普通值注意:严格地说,元组是由逗号标识的,圆括号只是让元组看起来更清晰。如果要定义只包含一个元素的,必须在这个元素后面加上逗号。
python
t4 = (5,) # 单元素元组必须加逗号,否则会被视为普通值(2) 不可变性
元组创建后不能修改、添加或删除元素,尝试修改会引发 TypeError。
python
t = (1, 2, 3)
t[0] = 4 # 报错: 'tuple' object does not support item assignment(3) 访问元素
与列表一样,通过索引访问元素(从 0 开始),也支持切片操作。
python
t = ('a', 'b', 'c', 'd')
print(t[1]) # 输出: 'b'
print(t[-1]) # 输出: 'd'(最后一个元素)
print(t[1:3]) # 输出: ('b', 'c')(切片操作)(4) 常用操作与方法
python
t1 = (1, 2)
t2 = (3, 4)
print(t1 + t2) # 输出: (1, 2, 3, 4)
print(t1 * 3) # 输出: (1, 2, 1, 2, 1, 2)
print(2 in t1) # 输出: True
print(len(t1)) # 输出: 2
print((1, 2, 2, 3).count(2)) # 输出: 2
print((1, 2, 3).index(2)) # 输出: 1(5) 元组拆包
python
nums = (1,2)
num1,num2 = nums
print(num1) # 1
print(num2) # 218. 字典
在 Python 中,字典(dictionary)是一系列键值对。每个键都与一个值关联,可以使用键来访问与之关联的值。与键相关联的值可以是数、字符串、列表乃至字典。事实上,可将任意 Python 对象用作字典中的值。
(1) 字典的创建
可以使用大括号{} 或dict()函数创建字典:
python
# 方法1:使用大括号
person = {
"name": "Alice",
"age": 30,
"city": "New York"
}
# 方法2:使用 dict() 函数
person = dict(name="Alice", age=30, city="New York")
# 空字典
empty_dict = {}
empty_dict = dict()(2) 访问字典中的值
通过键(key)来访问对应的值(value):
python
person = {"name": "Alice", "age": 30, "city": "New York"}
print(person["name"]) # 输出: Alice
print(person["age"]) # 输出: 30使用 get() 方法访问更安全,如果键不存在会返回 None 或指定的默认值:
python
person = {"name": "Alice", "age": 30, "city": "New York"}
print(person.get("name")) # 输出: Alice
print(person.get("gender")) # 输出: None
print(person.get("gender", "Unknown")) # 输出: Unknown(3) 修改和添加键值对
python
person = {"name": "Alice", "age": 30}
# 修改已有键的值
person["age"] = 31
print(person["age"]) # 输出: 31
# 添加新的键值对
person["gender"] = "Female"
print(person) # 输出: {'name': 'Alice', 'age': 31, 'gender': 'Female'}注意:如果key存在,则修改这个key对应的值。如果key不存在,则新增此键值对。
(4) 删除元素
python
person = {"name": "Alice", "age": 30, "city": "New York"}
# 删除指定键值对
del person["city"]
print(person) # 输出: {'name': 'Alice', 'age': 30}
# 弹出指定键的值(并删除该键值对)
age = person.pop("age")
print(age) # 输出: 30
print(person) # 输出: {'name': 'Alice'}
# 清空字典
person.clear()
print(person) # 输出: {}(5) 字典的常用方法
| 方法 | 作用 |
|---|---|
| keys() | 返回所有键 |
| values() | 返回所有值 |
| items() | 返回所有键值对(元组形式) |
| update() | 合并另一个字典 |
| copy() | 复制字典 |
python
person = {"name": "Alice", "age": 30}
print(person.keys()) # 输出: dict_keys(['name', 'age'])
print(person.values()) # 输出: dict_values(['Alice', 30])
print(person.items()) # 输出: dict_items([('name', 'Alice'), ('age', 30)])
# 合并字典
person.update({"city": "New York", "email": "alice@example.com"})
print(person) # 输出: {'name': 'Alice', 'age': 30, 'city': 'New York', 'email': 'alice@example.com'}(6) 遍历字典
python
person = {"name": "Alice", "age": 30, "city": "New York"}
# 遍历所有键
for key in person:
print(key)
# 遍历所有键值对
for key, value in person.items():
print(f"{key}: {value}")(7) 字典推导式
字典推导式(Dictionary Comprehension)是 Python 中一种简洁高效的创建字典的方式,它的语法类似于列表推导式,但生成的是字典(键值对集合)。
基础用法:通过可迭代对象创建字典
python
# 创建一个数字到其平方的字典
squares = {x: x**2 for x in range(5)}
print(squares) # 输出: {0: 0, 1: 1, 2: 4, 3: 9, 4: 16}字典的转换与过滤:
python
# 原字典
original = {'a': 1, 'b': 2, 'c': 3, 'd': 4}
# 将值翻倍,并过滤掉值小于5的项
transformed = {k: v*2 for k, v in original.items() if v*2 >= 5}
print(transformed) # 输出: {'b': 4被过滤, 'c': 6, 'd': 8} -> {'c': 6, 'd': 8}键值互换:
python
original = {'a': 1, 'b': 2, 'c': 3}
swapped = {v: k for k, v in original.items()}
print(swapped) # 输出: {1: 'a', 2: 'b', 3: 'c'}(8) 字典拆包
对字典进行拆包,取出来的是字典的key。
python
dicts = {"name":"haiexijun","age":23}
a,b = dicts
print(a) # name
print(b) # age
print(dicts[a]) # haiexijun
print(dicts[b]) # 2319. 集合
Python 集合(Set)是一种无序 、不重复的数据结构,非常适合用于去重、集合运算等场景。以下是集合的常用操作和使用方法:
(1) 集合的创建
可以使用 {} 或 set() 函数创建集合。但创建空集合不能用{},{}表示空字典,如果要创建空集合,只能使用set()。
python
# 创建空集合(注意:空集合不能用{},{}表示空字典)
empty_set = set()
# 创建包含元素的集合
fruits = {"apple", "banana", "cherry"}
numbers = set([1, 2, 3, 4, 5]) # 从列表创建(2) 集合的特性
无序性 :集合中的元素没有固定顺序,不能通过索引下标来访问。
唯一性:集合会自动去除重复元素。
python
nums = {1, 2, 2, 3, 3, 3}
print(nums) # 输出: {1, 2, 3}(3) 基本操作
添加元素 :add() 方法添加单个元素,update() 方法添加多个元素
python
fruits = {"apple", "banana"}
fruits.add("orange")
fruits.update(["grape", "mango"])
print(fruits) # 输出: {'apple', 'banana', 'orange', 'grape', 'mango'}删除元素 :remove()(元素不存在会报错)、discard()(元素不存在不会报错)、pop()(随机删除一个元素)
python
fruits = {"apple", "banana"}
fruits.remove("banana")
fruits.discard("watermelon") # 不会报错
fruits.pop() # 随机删除一个元素清空集合 :clear() 方法
python
fruits.clear()(4) 集合运算
交集(& 或 intersection ()):两个集合共有的元素
并集(| 或 union ()):两个集合所有的元素
差集(- 或 difference ()):存在于第一个集合但不存在于第二个集合的元素
对称差集(^ 或 symmetric_difference ()):两个集合中不重复的元素
python
a = {1, 2, 3, 4}
b = {3, 4, 5, 6}
print(a & b) # 交集: {3, 4}
print(a | b) # 并集: {1, 2, 3, 4, 5, 6}
print(a - b) # 差集: {1, 2}
print(a ^ b) # 对称差集: {1, 2, 5, 6}(5) 集合的其他常用方法
len(set):返回集合中元素的数量
in:检查元素是否在集合中
issubset():检查是否为另一个集合的子集
issuperset():检查是否为另一个集合的超集
python
a = {1, 2}
b = {1, 2, 3}
print(a.issubset(b)) # True(a是b的子集)
print(b.issuperset(a)) # True(b是a的超集)
print(1 in a) # True20. 函数
(1) 函数定义和调用
定义格式:使用 def 关键字
python
def 函数名(参数):
函数体
return 返回值调用方式:直接使用函数名加括号
python
result = 函数名(参数)函数要先定义后调用,如果先调用会报错。
(2) 函数说明文档
在 Python 中,为函数编写自定义说明文档是一种良好的编程实践,它可以帮助其他开发者理解函数的功能、参数、返回值和使用方法。
函数说明文档通常位于函数定义的第一行 ,使用三重引号(单引号或双引号均可)包裹。常见的文档字符串格式有以下几种:
python
def greet(name, greeting="Hello"):
"""生成问候语
Args:
name (str): 要问候的人的名字
greeting (str, optional): 问候语前缀,默认是"Hello"
Returns:
str: 完整的问候语字符串
Examples:
>>> greet("Alice")
'Hello, Alice!'
>>> greet("Bob", "Hi")
'Hi, Bob!'
"""
return f"{greeting}, {name}!"访问文档字符串可以使用 help() 函数或 .__doc__ 属性来查看函数的文档字符串:
python
print(help(greet)) # 显示格式化的帮助信息
print(greet.__doc__) # 直接获取文档字符串(3) 参数类型
位置参数:必须按顺序传递的参数。而且要求实参的顺序于形参的顺序相同,必须一致。
python
def add(a, b):
return a + b
add(2, 3) # 5关键字参数:指定参数名传递,可改变顺序
python
add(b=3, a=2) # 5默认值参数:。函数的参数可以设置默认值,当调用函数时如果没有提供该参数的值,就会使用默认值。这就是默认参数的概念。
python
def greet(name, message="Hello"):
print(f"{message}, {name}!")
# 只传递必填参数
greet("Alice") # 输出: Hello, Alice!
# 传递所有参数,覆盖默认值
greet("Bob", "Good morning") # 输出: Good morning, Bob!注意事项:
默认参数必须放在非默认参数后面,定义函数时,有默认值的参数必须位于没有默认值的参数之后,否则会报错。
python
# 正确写法
def func(a, b=2, c=3):
pass
# 错误写法(默认参数在非默认参数前)
def func(b=2, a, c=3): # SyntaxError
pass如果默认参数是可变对象(如列表、字典等),这一点需要特别注意,因为默认值会被所有调用共享。
python
def add_item(item, lst=[]):
lst.append(item)
return lst
print(add_item(1)) # [1]
print(add_item(2)) # [1, 2] (而不是预期的 [2])解决方法:将默认值设为 None,在函数内部重新初始化.
python
def add_item(item, lst=None):
if lst is None:
lst = []
lst.append(item)
return lst默认参数可以是表达式。
python
def get_info(name, age=2023-1990): # 计算式作为默认值
print(f"{name} is {age} years old")
get_info("Tom") # 输出: Tom is 33 years old (假设当前计算结果为33)(4) 函数返回值
使用 return 语句返回结果,可返回多个值(自动打包为元组)
python
def divide(a, b):
return a // b, a % b # 返回商和余数
quotient, remainder = divide(10, 3) # 3, 1(5) 不定长参数
也叫可变参数,是一种特殊的参数形式,允许函数接受任意数量的参数。这在不确定需要传递多少个参数时非常有用。Python 提供了两种类型的可变参数:
*args:用于接收任意数量的位置参数,这些参数会被打包成一个元组 (tuple)
**kwargs:用于接收任意数量的关键字参数,这些参数会被打包成一个字典 (dict)
使用示例:
python
# 使用*args接收任意数量的位置参数
def sum_numbers(*args):
total = 0
for num in args:
total += num
return total
print(sum_numbers(1, 2, 3)) # 输出: 6
print(sum_numbers(10, 20, 30, 40)) # 输出: 100
# 使用**kwargs接收任意数量的关键字参数
def show_info(**kwargs):
for key, value in kwargs.items():
print(f"{key}: {value}")
show_info(name="Alice", age=30, city="New York")
# 输出:
# name: Alice
# age: 30
# city: New York
# 同时使用*args和**kwargs
def mixed_example(*args, **kwargs):
print("位置参数:", args)
print("关键字参数:", kwargs)
mixed_example(1, 2, 3, name="Bob", score=95)
# 输出:
# 位置参数: (1, 2, 3)
# 关键字参数: {'name': 'Bob', 'score': 95}注意事项:
参数定义的顺序很重要,应该遵循:普通参数 → *args → **kwargs 。*args 和 **kwargs 只是约定俗成的命名,你可以使用其他名称,但建议保持这一惯例。可以将列表 或者元组解包为 *args,将字典解包为 **kwargs:
python
numbers = [1, 2, 3, 4]
print(sum_numbers(*numbers)) # 等价于 sum_numbers(1, 2, 3, 4)
person = {"name": "Charlie", "age": 25}
show_info(** person) # 等价于 show_info(name="Charlie", age=25)(6) 函数作用域
局部变量:函数内部定义,仅在函数内有效。
全局变量:函数外部定义,需用 global 声明才能在函数内修改和操作全局变量。
python
count = 0
def increment():
global count
count += 1嵌套作用域:出现在嵌套函数中,内层函数可以访问外层函数的变量。果要修改外层函数的变量,需要使用 nonlocal 关键字声明。
python
def outer_func():
x = 10 # 外层函数变量
def inner_func():
nonlocal x # 声明要修改外层函数变量
x = 20
print("内层函数:", x)
inner_func()
print("外层函数:", x)
outer_func()
# 输出:
# 内层函数: 20
# 外层函数: 20(7) lambda表达式
lambda 表达式也叫做匿名函数,是一种创建匿名函数的简洁方式,它可以让你快速定义简单的函数,而不必使用 def 关键字。lambda 表达式的基本语法如下:
python
lambda 参数: 表达式注意:lambda的参数可有可无,lambda表达式可以接收任意数量的参数,但只能返回一个值。
示例:
python
# 基本用法:创建一个简单的加法函数
add = lambda x, y: x + y
print(add(3, 5)) # 输出: 8
# 在sorted()中使用,按元组的第二个元素排序
points = [(1, 5), (3, 2), (2, 8)]
sorted_points = sorted(points, key=lambda x: x[1])
print(sorted_points) # 输出: [(3, 2), (1, 5), (2, 8)]
# 与map()一起使用,对列表元素进行处理
numbers = [1, 2, 3, 4]
squared = list(map(lambda x: x **2, numbers))
print(squared) # 输出: [1, 4, 9, 16](8) 高阶函数
高阶函数是指能够接受其他函数作为参数,或者能够返回一个函数作为结果的函数。它们是函数式编程的重要组成部分,让代码更加简洁和灵活。
以下是 Python 中常见的高阶函数及其用法:
map(function, iterable) :对可迭代对象中的每个元素应用 function,返回一个迭代器。
python
numbers = [1, 2, 3, 4]
squared = map(lambda x: x**2, numbers)
print(list(squared)) # 输出: [1, 4, 9, 16]filter(function, iterable) :根据 function 的返回值(布尔值)筛选可迭代对象中的元素。
python
numbers = [1, 2, 3, 4, 5, 6]
evens = filter(lambda x: x % 2 == 0, numbers)
print(list(evens)) # 输出: [2, 4, 6]reduce(function, iterable[, initial]) : 对可迭代对象中的元素进行累积计算(需要从 functools 导入)。
python
from functools import reduce
numbers = [1, 2, 3, 4]
product = reduce(lambda x, y: x * y, numbers)
print(product) # 输出: 24 (1*2*3*4)sorted(iterable, key=None, reverse=False) :对可迭代对象进行排序,key 参数接收一个函数作为排序依据。
python
people = [("Alice", 30), ("Bob", 25), ("Charlie", 35)]
# 按年龄排序
sorted_by_age = sorted(people, key=lambda x: x[1])
print(sorted_by_age) # 输出: [('Bob', 25), ('Alice', 30), ('Charlie', 35)](9) 递归函数
函数调用自身(需注意终止条件)
python
def factorial(n):
if n == 1:
return 1
return n * factorial(n-1)(10) 装饰器
装饰器是一种特殊的函数,它可以用来修改其他函数的功能,而无需修改函数本身的代码。装饰器本质上是一个高阶函数,它接收一个函数作为参数,并返回一个新的函数。
下面是一个简单的装饰器示例,它会在函数执行前后打印一些信息:
python
# 定义装饰器
def my_decorator(func):
def wrapper():
print("函数执行前...")
func() # 调用被装饰的函数
print("函数执行后...")
return wrapper
# 使用装饰器
@my_decorator
def say_hello():
print("Hello, World!")
# 调用函数
say_hello()输出结果:
text
函数执行前...
Hello, World!
函数执行后...带参数的装饰器 : 如果被装饰的函数需要接收参数,可以在 wrapper 函数中处理。
python
def my_decorator(func):
def wrapper(name):
print("函数执行前...")
func(name) # 传递参数
print("函数执行后...")
return wrapper
@my_decorator
def say_hello(name):
print(f"Hello, {name}!")
say_hello("Alice")输出结果:
text
函数执行前...
Hello, Alice!
函数执行后...通用装饰器 (适用于任何参数的函数):使用 *args 和 **kwargs 可以创建适用于任何参数的装饰器。
python
def my_decorator(func):
def wrapper(*args, **kwargs):
print("函数执行前...")
result = func(*args, **kwargs) # 传递所有参数
print("函数执行后...")
return result # 返回函数执行结果
return wrapper
@my_decorator
def add(a, b):
return a + b
result = add(3, 5)
print(f"结果: {result}")输出结果:
text
函数执行前...
函数执行后...
结果: 8带参数的装饰器 :装饰器本身也可以接收参数,这需要在原有装饰器外再包裹一层函数。
python
def repeat(num_times):
def decorator(func):
def wrapper(*args, **kwargs):
# 这里的 _ 只是为了让循环执行 num_times 次
for _ in range(num_times):
result = func(*args, **kwargs)
return result
return wrapper
return decorator
@repeat(num_times=3)
def say_hello():
print("Hello!")
say_hello()输出结果:
text
Hello!
Hello!
Hello!21. 类与面向对象
Python 中的类与面向对象编程(OOP)是核心概念,它通过封装、继承和多态等特性,帮助开发者构建模块化、可复用的代码。
(1) 类的创建
类的基本结构:
python
class 类名:
# 类属性(所有实例共享)
类变量 = 值
# 构造方法(初始化对象)
def __init__(self, 参数1, 参数2, ...):
# 实例属性(每个实例独立)
self.属性1 = 参数1
self.属性2 = 参数2
# 类方法
def 方法名(self, 参数...):
# 方法体类:是一种抽象的数据类型,用于定义对象的属性(数据)和方法(行为)。
对象:是类的实例,根据类创建的具体实体。
类属性:定义在类中,所有实例共享。
实例属性:定义在 __init__ 方法中,每个实例独立拥有。
python
# 定义类
class Person:
# 属性(类变量,所有实例共享)
species = "人类"
# 初始化方法(构造函数)
def __init__(self, name, age):
# 实例变量(每个实例独有)
self.name = name
self.age = age
# 方法(行为)
def say_hello(self):
print(f"你好,我叫{self.name},今年{self.age}岁")
# 创建对象(实例化)
person1 = Person("张三", 20)
person2 = Person("李四", 30)
# 访问属性和方法
print(person1.name) # 输出:张三
person2.say_hello() # 输出:你好,我叫李四,今年30岁
print(Person.species) # 输出:人类__init__ 方法:这是构造方法,当创建类的实例时自动执行,用于初始化对象的属性>
self 关键字:类中每个方法都有一个self属性,代表类的实例,指向实例本身的引用,必须作为第一个参数出现在方法定义中,用于访问实例的属性和方法。
Python 中的特殊方法(也称为魔术方法或双下划线方法)是以双下划线 __ 开头和结尾的方法。下面介绍一些常用的特殊方法。
__init__(self, ...): 构造方法,创建实例时调用。
__del__(self) : 析构方法,实例被销毁时调用。
__new__(cls, ...): 创建实例的方法,在 init 之前调用。
python
class MyClass:
def __new__(cls, *args, **kwargs):
print("创建实例")
return super().__new__(cls)
def __init__(self, value):
print("初始化实例")
self.value = value
def __del__(self):
print("实例被销毁")__str__(self) : 当使用print输出对象的时候,默认打印对象的内存地址。如果使用__str__(self) 方法,那么就会打印从这个方法中return的数据。类似于Java的toString()方法。
python
class Person:
def __init__(self, name, age):
self.name = name
self.age = age
def __str__(self):
return f"{self.name}, {self.age}岁"(2) 类的继承
一个类(子类)可以继承另一个类(父类)的属性和方法,实现代码复用。子类可以扩展或重写父类的方法。在python中,所有的类默认继承自Object类这个顶级类。
基本语法:
python
class 父类名:
# 父类属性和方法
class 子类名(父类名):
# 子类可以添加自己的属性和方法
# 也可以重写父类的方法继承的主要特点:
代码复用:子类可以直接使用父类中定义的属性和方法,无需重复编写。
方法重写:子类可以定义与父类同名的方法,从而覆盖父类的实现。
扩展功能:子类可以在继承父类的基础上添加新的属性和方法。
python
# 定义父类
class Animal:
def __init__(self, name):
self.name = name
def speak(self):
print(f"{self.name} 发出声音")
def move(self):
print(f"{self.name} 在移动")
# 定义子类 Dog,继承自 Animal
class Dog(Animal):
# 重写父类的 speak 方法
def speak(self):
print(f"{self.name} 汪汪叫")
# 添加子类特有的方法
def fetch(self):
print(f"{self.name} 正在叼东西")
# 定义子类 Cat,继承自 Animal
class Cat(Animal):
# 重写父类的 speak 方法
def speak(self):
print(f"{self.name} 喵喵叫")
# 创建对象并使用
dog = Dog("旺财")
dog.speak() # 调用重写的方法
dog.move() # 调用继承的方法
dog.fetch() # 调用子类特有方法
cat = Cat("咪咪")
cat.speak() # 调用重写的方法
cat.move() # 调用继承的方法多继承 : Python 还支持多继承,即一个子类可以同时继承多个父类。
python
class A:
def method_a(self):
print("这是A类的方法")
class B:
def method_b(self):
print("这是B类的方法")
class C(A, B): # 同时继承A和B
def method_c(self):
print("这是C类自己的方法")
c = C()
c.method_a() # 调用A类的方法
c.method_b() # 调用B类的方法
c.method_c() # 调用C类自己的方法super () 函数: 用于调用父类的方法,通常在子类的 init 方法中使用,以初始化父类的属性。
python
class Parent:
def __init__(self, name):
self.name = name
print(f"Parent 初始化: {self.name}")
class Child(Parent):
def __init__(self, name, age):
# 调用父类的 __init__ 方法
super().__init__(name) # 等价于 Parent.__init__(self, name)
self.age = age
print(f"Child 初始化: {self.name}, {self.age}岁")
child = Child("小明", 10)
# 输出:
# Parent 初始化: 小明
# Child 初始化: 小明, 10岁查看一个类继承的父类有哪些,可以使用__mro__或者mro() 方法(用类名调用):
python
class A:
pass
class B(A):
pass
class C(B):
pass
print(C.__mro__)
# 输出: (<class '__main__.C'>, <class '__main__.B'>, <class '__main__.A'>, <class 'object'>)多继承中的 MRO 示例:
python
class A:
def method(self):
print("A 的方法")
class B(A):
def method(self):
print("B 的方法")
super().method()
class C(A):
def method(self):
print("C 的方法")
super().method()
class D(B, C):
def method(self):
print("D 的方法")
super().method()
# 查看 MRO
print(D.__mro__)
# 输出: (<class '__main__.D'>, <class '__main__.B'>, <class '__main__.C'>, <class '__main__.A'>, <class 'object'>)
print(D.mro())
# 输出: [__main__.D, __main__.B, __main__.C, __main__.A, object]
# 调用方法时会按照 MRO 顺序查找
d = D()
d.method()
# 输出:
# D 的方法
# B 的方法
# C 的方法
# A 的方法(3) 多态
不同类的对象对同一方法可以有不同的实现,调用时无需关心具体类型。
定义父类(统一接口):先定义一个抽象的父类 Animal,包含一个统一的方法 make_sound()(这就是 "接口"),但不实现具体逻辑(也可写默认逻辑)。
python
class Animal:
def make_sound(self):
# 父类方法:可留空(抽象),或定义默认行为
raise NotImplementedError("子类必须重写 make_sound 方法")这里用 raise NotImplementedError 强制子类重写,避免忘记实现(类似 "抽象方法" 的效果。
定义子类(不同实现):创建多个子类(如 Dog、Cat、Bird),均继承自 Animal,并重写 make_sound() 方法,实现各自的 "叫声逻辑"。
python
class Dog(Animal):
# 重写父类方法:狗的叫声
def make_sound(self):
print("汪汪汪!")
class Cat(Animal):
# 重写父类方法:猫的叫声
def make_sound(self):
print("喵喵喵!")
class Bird(Animal):
# 重写父类方法:鸟的叫声
def make_sound(self):
print("叽叽喳喳!")定义一个通用函数 animal_sound(animal),接收一个 Animal 类型的对象,调用其 make_sound() 方法。此时,函数无需判断对象是 Dog、Cat 还是 Bird,只需调用统一接口,不同对象会自动执行自己的实现:
python
def animal_sound(animal):
# 统一调用接口,不关心 animal 的具体类型
animal.make_sound()
# 创建不同对象
dog = Dog()
cat = Cat()
bird = Bird()
# 同一操作作用于不同对象,行为不同
animal_sound(dog) # 输出:汪汪汪!
animal_sound(cat) # 输出:喵喵喵!
animal_sound(bird) # 输出:叽叽喳喳!这就是多态的核心价值:降低代码耦合度,新增子类时无需修改通用函数(如 animal_sound),只需重写方法即可。
(4) 封装
Python 并没有严格的访问控制关键字,但通过命名约定来实现类似效果:单下划线 _:表示 "受保护" 的成员(建议不直接访问,非强制)。双下划线 __:表示 "私有" 的成员(会被改名,无法直接访问)。
python
class BankAccount:
def __init__(self, balance):
self.__balance = balance # 私有属性
def deposit(self, amount):
if amount > 0:
self.__balance += amount
def get_balance(self): # 提供公开接口访问私有属性
return self.__balance
account = BankAccount(1000)
print(account.get_balance()) # 输出:1000
print(account.__balance) # 报错:无法直接访问私有属性一般通过定义函数get_xx() 来获取私有属性,定义set_xx()来修改私有属性。
(5) 类属性
类属性通常在类定义中、所有方法之外进行定义:
python
class MyClass:
# 定义类属性
class_attr = "我是类属性"
def __init__(self, instance_attr):
# 实例属性
self.instance_attr = instance_attr类属性的访问:可以通过类名直接访问,也可以通过类的实例访问:
python
# 通过类名访问
print(MyClass.class_attr) # 输出: 我是类属性
# 创建实例
obj1 = MyClass("实例1的属性")
obj2 = MyClass("实例2的属性")
# 通过实例访问
print(obj1.class_attr) # 输出: 我是类属性
print(obj2.class_attr) # 输出: 我是类属性类属性的修改:通过类名修改类属性,会影响所有实例对该属性的访问。通过实例修改类属性,实际上是给该实例创建了一个同名的实例属性,不会影响类属性和其他实例。
python
# 通过类名修改类属性
MyClass.class_attr = "修改后的类属性"
print(obj1.class_attr) # 输出: 修改后的类属性
print(obj2.class_attr) # 输出: 修改后的类属性
# 通过实例"修改"类属性(实际是创建实例属性)
obj1.class_attr = "实例1的属性"
print(obj1.class_attr) # 输出: 实例1的属性(访问的是实例属性)
print(obj2.class_attr) # 输出: 修改后的类属性(访问的还是类属性)
print(MyClass.class_attr) # 输出: 修改后的类属性(类属性未变)(6) 类方法
类方法(Class Method)是一种绑定到类而不是实例的方法。它可以访问和修改类的状态,而不需要创建类的实例。类方法使用 @classmethod 装饰器定义,第一个参数通常是 cls,代表类本身(类似实例方法的 self)。类方法可以通过类名直接调用,也可以通过实例调用。类方法无法直接访问实例属性,只能访问类属性。
类方法的基本用法:
python
class MyClass:
# 类属性
class_attr = "我是类属性"
def __init__(self, instance_attr):
# 实例属性
self.instance_attr = instance_attr
# 类方法
@classmethod
def class_method(cls):
print(f"这是类方法,访问类属性: {cls.class_attr}")
# 使用类方法创建实例(常用模式)
@classmethod
def from_string(cls, string):
# 处理字符串,创建实例
return cls(string)调用类方法的方式:
python
# 通过类名调用
MyClass.class_method()
# 通过实例调用
obj = MyClass("实例属性值")
obj.class_method()
# 使用类方法创建实例
new_obj = MyClass.from_string("通过类方法创建的实例")(7) 静态方法
静态方法(Static Method)是类中定义的一种特殊方法,它与类和实例都没有直接关联,不需要访问类变量或实例变量。调用时不需要传递 self 或 cls 参数 , 定义时需要使用 @staticmethod 装饰器 ,可以通过类名直接调用,也可以通过实例调用,无法访问类的属性或实例的属性。静态方法通常用于实现与类相关但不依赖于类状态的功能,相当于类的 "工具函数"。
示例代码:
python
class MathUtils:
# 定义静态方法
@staticmethod
def add(a, b):
"""静态方法:计算两个数的和"""
return a + b
@staticmethod
def multiply(a, b):
"""静态方法:计算两个数的积"""
return a * b
# 通过类名直接调用静态方法
print(MathUtils.add(3, 5)) # 输出:8
print(MathUtils.multiply(4, 6)) # 输出:24
# 也可以通过实例调用静态方法
math_instance = MathUtils()
print(math_instance.add(2, 8)) # 输出:10(8) 抽象类
抽象类(Abstract Base Class,简称 ABC)是一种不能被实例化的类,它主要用于定义接口,强制子类实现特定的方法。抽象类通常包含一个或多个抽象方法,这些方法只有声明而没有具体实现。
要创建抽象类,需要使用 abc 模块,具体步骤如下:
1)导入 abc 模块中的 ABC 类和 abstractmethod 装饰器
2)让你的类继承 ABC 类
3)使用 @abstractmethod 装饰器标记抽象方法
下面是一个简单的抽象类示例:
python
from abc import ABC, abstractmethod
# 定义抽象类
class Shape(ABC):
@abstractmethod
def area(self):
"""计算面积的抽象方法"""
pass
@abstractmethod
def perimeter(self):
"""计算周长的抽象方法"""
pass
# 子类实现抽象类
class Rectangle(Shape):
def __init__(self, width, height):
self.width = width
self.height = height
# 实现抽象方法 area
def area(self):
return self.width * self.height
# 实现抽象方法 perimeter
def perimeter(self):
return 2 * (self.width + self.height)
# 子类实现抽象类
class Circle(Shape):
def __init__(self, radius):
self.radius = radius
# 实现抽象方法 area
def area(self):
import math
return math.pi * self.radius **2
# 实现抽象方法 perimeter
def perimeter(self):
import math
return 2 * math.pi * self.radius
# 使用示例
if __name__ == "__main__":
rect = Rectangle(5, 3)
print(f"矩形面积: {rect.area()}")
print(f"矩形周长: {rect.perimeter()}")
circle = Circle(4)
print(f"圆形面积: {circle.area()}")
print(f"圆形周长: {circle.perimeter()}")22. 模块
在 Python 中,模块(Module)是一个包含 Python 代码的文件(以.py为扩展名),它可以包含函数、类、变量和可执行代码。模块的主要作用是将代码组织成可重用的单元,便于管理和维护。
(1) 模块的基本使用
导入模块:可以使用import语句导入整个模块。
python
import math # 导入math模块
print(math.sqrt(16)) # 使用模块中的函数,输出4.0导入模块中的特定内容:使用from...import可以只导入需要的部分。
python
from math import sqrt, pi # 只导入sqrt函数和pi常量
print(sqrt(25)) # 输出5.0
print(pi) # 输出3.141592653589793使用as关键字给模块或导入的内容起别名:
python
import math as m # 给math模块起别名m
print(m.pow(2, 3)) # 输出8.0
from math import sqrt as square_root # 给函数起别名
print(square_root(36)) # 输出6.0导入模块中的所有内容 : 可以使用*导入模块中的所有公开内容(但是不推荐,可能导致命名冲突)。
python
from math import *
print(cos(0)) # 输出1.0(2) 常见的内置模块
| 模块名 | 用法 |
|---|---|
| math | 数学运算相关函数 |
| random | 生成随机数 |
| datetime | 处理日期和时间 |
| os | 与操作系统交互 |
| sys | 访问 Python 解释器的变量和函数 |
| json | 处理 JSON 数据 |
| re | 正则表达式操作 |
(3) 创建自己的模块
可以创建自己的模块,例如创建一个mymodule.py文件:
python
# mymodule.py
def greet(name):
return f"Hello, {name}!"
pi = 3.14159然后在其他 Python 文件中导入使用:
python
import mymodule
print(mymodule.greet("Alice")) # 输出"Hello, Alice!"
print(mymodule.pi) # 输出3.14159(4) python包的基本结构和使用
Python 包(Package)是组织和管理多个模块(Module)的方式,它能帮助开发者更好地结构化代码、避免命名冲突,并实现代码的复用。
包是一个包含多个 Python 模块(.py 文件)的目录,并且必须包含一个特殊的__init__.py文件。
一个典型的包结构如下:
plaintext
my_package/ # 包目录
├── __init__.py # 包初始化文件(可选但推荐)
├── module1.py # 模块1
├── module2.py # 模块2
└── subpackage/ # 子包
├── __init__.py
└── submodule.py # 子模块__init__.py 文件的作用:
- 标识该目录为 Python 包,否则 Python 会将其视为普通目录。
- 可以在其中执行包的初始化代码(如设置版本号、导入常用模块等)。
- 控制包的公开接口(通过
__all__变量指定from package import *时可导入的模块)。
示例:
python
# my_package/__init__.py
__version__ = "1.0.0" # 定义包版本
# 当使用 from my_package import * 时,只导入以下模块
__all__ = ["module1", "module2"]
# 自动导入子模块(可选)
from . import module1包的导入方式:
假设 module1.py 中有如下内容:
python
# my_package/module1.py
def func1():
print("This is func1 in module1")导入整个包:
python
import my_package
my_package.module1.func1() # 调用方法导入包中的特定模块:
python
from my_package import module1
module1.func1() # 直接使用模块名调用导入模块中的特定函数 / 类:
python
from my_package.subpackage import submodule
submodule.subfunc() # 调用子模块中的函数(5) 第三方模块的安装与使用
python
pip install 模块名 # 安装
pip uninstall 模块名 # 卸载
pip list # 查看已安装模块23. 异常
在 Python 中,异常是程序执行过程中发生的错误事件,它会中断正常的程序流程。合理处理异常可以提高程序的健壮性和容错能力。
(1) 异常的基本概念
异常:程序运行时发生的意外情况(如除零、变量未定义、文件不存在等)。
表现形式:当异常发生时,Python 会创建一个异常对象,如果不处理,程序会终止并显示错误信息。
常见内置异常:
| 异常 | 说明 |
|---|---|
| SyntaxError | 语法错误(编译时错误) |
| NameError | 使用未定义的变量 |
| TypeError | 操作或函数应用于不适当类型的对象 |
| ValueError | 操作或函数接收到的参数类型正确但值不合适 |
| ZeroDivisionError | 除法或取模运算的第二个参数为零 |
| FileNotFoundError | 尝试打开不存在的文件 |
(2) 异常处理语句
Python 提供try-except结构来捕获和处理异常:
python
try:
# 可能会发生异常的代码块
result = 10 / 0
except ZeroDivisionError:
# 当发生 ZeroDivisionError 时执行的代码
print("错误:除数不能为零")捕获多个异常:
python
try:
num = int(input("请输入一个数字:"))
result = 10 / num
print(f"10 除以 {num} 的结果是:{result}")
except ValueError:
print("错误:请输入有效的数字")
except ZeroDivisionError:
print("错误:除数不能为零")
except Exception as e:
# 捕获其他所有未指定的异常
print(f"发生了未知错误:{e}")(3) else 和 finally 子句
else:当 try 块中没有发生异常时执行
finally:无论是否发生异常,都会执行(通常用于清理资源)
python
try:
file = open("example.txt", "r")
content = file.read()
except FileNotFoundError:
print("错误:文件不存在")
else:
print("文件内容:", content)
finally:
# 确保文件被关闭
if 'file' in locals() and not file.closed:
file.close()
print("操作完成")(4) 主动抛出异常
使用 raise 语句可以主动抛出异常:
python
def check_age(age):
if age < 0:
# 主动抛出ValueError
raise ValueError("年龄不能为负数")
return age
try:
check_age(5)
except ValueError as e:
print(e) # 输出: 年龄不能为负数(5) 异常的传递机制
当函数中发生异常而没有处理时,异常会向上传递到调用它的地方,直到被捕获或导致程序终止:
python
def divide(a, b):
return a / b # 可能发生ZeroDivisionError
def calculate():
try:
divide(10, 0)
except ZeroDivisionError as e:
print(f"在calculate中捕获异常: {e}")
calculate() # 异常从divide传递到calculate并被处理(6) 自定义异常
可以通过继承 Exception 类创建自定义异常:
python
# 定义自定义异常
class InvalidScoreError(Exception):
"""当分数不在有效范围内时抛出"""
def __init__(self, score, message="分数必须在0-100之间"):
self.score = score
self.message = message
super().__init__(self.message)
# 使用自定义异常
def check_score(score):
if not (0 <= score <= 100):
raise InvalidScoreError(score)
print(f"有效分数: {score}")
try:
check_score(150)
except InvalidScoreError as e:
print(f"错误: {e}, 输入的分数是: {e.score}")24. 文件操作
Python 中文件操作是非常基础且重要的知识点,涉及文件的创建、读取、写入、关闭等操作。
(1) 文件打开与关闭
使用open()函数打开文件,语法:file = open(file_path, mode)
file_path:文件路径(相对路径或绝对路径)。
mode:打开模式,常见模式有:
基础模式
| 模式 | 说明 |
|---|---|
| r | 只读模式(默认),文件必须存在,否则报错 |
| w | 写入模式,若文件不存在则创建,若存在则覆盖原有内容 |
| a | 追加模式,在文件末尾添加内容,文件不存在则创建 |
读写模式
| 模式 | 说明 |
|---|---|
| r+ | 读写模式,文件必须存在,可读取也可写入(会覆盖原有内容) |
| w+ | 读写模式,创建新文件或覆盖原有文件,既可读又可写 |
| a+ | 追加读写模式,可在末尾追加内容,也可读取文件 |
二进制模式(用于处理非文本文件,如图片、音频等)
| 模式 | 说明 |
|---|---|
| rb | 二进制只读 |
| wb | 二进制写入 |
| ab | 二进制追加 |
| rb+、wb+、ab+ | 对应的二进制读写组合模式 |
文本模式(默认,可显式指定)
| 模式 | 说明 |
|---|---|
| rt | 文本只读(同 r) |
| wt | 文本写入(同 w) |
| at | 文本追加(同 a) |
特殊模式
| 模式 | 说明 |
|---|---|
| x | 创建模式,只能用于新建文件,若文件已存在则报错 |
| x+ | 创建并读写模式 |
选择模式时需注意:
处理文本文件(.txt、.csv 等)用默认文本模式。
处理二进制文件(.png、.mp3 等)必须加 b 模式。
谨慎使用 w 模式,避免误删文件内容。
a 模式下写入始终追加到文件末尾,不受 seek() 影响。
关闭文件:file.close(),建议使用with语句自动关闭文件(上下文管理器)。
(2) 文件读取方法
read(size):读取指定字节数(默认读取全部内容)
python
with open('file.txt', 'r') as f:
content = f.read() # 读取全部
# content = f.read(100) # 读取前100字节readline():读取一行内容(包括换行符)
python
with open('file.txt', 'r') as f:
line1 = f.readline() # 第一行
line2 = f.readline() # 第二行readlines():读取所有行,返回列表(每行作为一个元素)
python
with open('file.txt', 'r') as f:
lines = f.readlines() # 列表形式存储所有行迭代文件对象(高效读取大文件):
python
with open('large_file.txt', 'r') as f:
for line in f:
print(line) # 逐行处理,内存友好(3) 文件写入方法
write(str):写入字符串,返回写入的字符数
python
with open('output.txt', 'w') as f:
f.write("Hello, World!\n") # 需手动添加换行符
f.write("Python 文件操作")writelines(iterable):写入可迭代对象(如列表),不会自动添加换行符
python
lines = ["第一行\n", "第二行\n", "第三行"]
with open('output.txt', 'w') as f:
f.writelines(lines)(4) 文件指针操作
文件指针记录当前读写位置,可通过 seek() 移动:
python
with open('file.txt', 'r') as f:
f.seek(5) # 从开头移动5个字节
content = f.read() # 从第5字节开始读取seek(offset, whence):offset 为偏移量,单位是字节(一个英文占1一个字节,一个utf-8的中文占3个字节),whence 为基准(0:文件开头,1:当前位置,2:文件末尾)
tell():返回当前文件指针位置
python
with open('file.txt', 'r') as f:
f.read(10)
print(f.tell()) # 输出10(当前位置在第10字节后)(5) 文件路径处理
使用os.path模块处理路径(跨平台兼容):
python
import os
# 获取当前工作目录
cwd = os.getcwd()
# 拼接路径
file_path = os.path.join(cwd, 'data', 'file.txt')
# 判断文件是否存在
if os.path.exists(file_path):
print("文件存在")
# 获取文件名/目录名
print(os.path.basename(file_path)) # 文件名:file.txt
print(os.path.dirname(file_path)) # 目录:.../dataPython 3.4+ 推荐使用 pathlib 模块(面向对象的路径处理):
python
from pathlib import Path
file = Path('data/file.txt')
if file.exists():
with file.open('r') as f:
content = f.read()(6) 异常处理
文件操作可能出现错误(如文件不存在、权限不足),需用 try-except 捕获异常:
python
try:
with open('file.txt', 'r') as f:
content = f.read()
except FileNotFoundError:
print("文件不存在")
except PermissionError:
print("没有权限访问文件")
except Exception as e:
print(f"发生错误:{e}")(7) 文件夹的操作
可以使用内置的os模块和pathlib模块(Python 3.4+)来进行文件夹操作。
创建文件夹:
python
import os
import pathlib
# 使用os模块创建单个文件夹
os.mkdir("./new_folder")
# 使用os模块创建多级文件夹
os.makedirs("./parent_folder/child_folder", exist_ok=True) # exist_ok=True避免文件夹已存在时报错
# 使用pathlib模块创建文件夹
pathlib.Path("./new_folder2").mkdir(exist_ok=True)
pathlib.Path("./parent2/child2").mkdir(parents=True, exist_ok=True) # parents=True允许创建多级目录删除文件夹:
python
import os
import pathlib
# 删除空文件夹
os.rmdir("./new_folder")
pathlib.Path("./new_folder2").rmdir()
# 删除非空文件夹(包括所有内容)
import shutil
shutil.rmtree("./parent2", ignore_errors=True) # ignore_errors=True忽略错误列出文件夹内容
python
import os
import pathlib
# 列出指定目录下的所有文件和文件夹
contents = os.listdir("./target_directory")
print(f"目录内容: {contents}")
# 使用pathlib
path = pathlib.Path("./target_directory")
for item in path.iterdir():
print(item.name)
# 只列出文件夹
folders = [f for f in os.listdir("./target_directory") if os.path.isdir(os.path.join("./target_directory", f))]
print(f"文件夹: {folders}")查看和修改当前工作目录
python
import os
# 获取当前工作目录
current_dir = os.getcwd()
print(f"当前工作目录: {current_dir}")
# 改变当前工作目录
os.chdir("/path/to/new/directory")重命名或移动文件夹
python
import os
import pathlib
# 重命名文件夹
os.rename("old_name", "new_name")
pathlib.Path("old_name2").rename("new_name2")
# 移动文件夹
os.rename("source_folder", "destination/path/new_name")25. with语句
在 Python 中,with 语句是一种用于简化资源管理的语法结构,尤其适合处理文件、网络连接、数据库连接等需要手动释放的资源。它的核心作用是自动管理资源的获取和释放,确保资源在使用完毕后被正确关闭,避免资源泄露。
(1) with 语句的基本语法
python
with 表达式 [as 变量]:
# 操作资源的代码块表达式 :通常是返回一个 "上下文管理器"(实现了__enter__() 和 exit() 方法的对象)的函数,例如 open() 函数返回的文件对象。
as 变量:可选,将表达式返回的对象赋值给一个变量,方便在代码块中操作。
(2) 常见应用场景
1.文件操作(最常用)
传统方式需要手动关闭文件,而 with 会自动关闭:
python
# 传统方式
f = open("file.txt", "r")
try:
content = f.read()
finally:
f.close() # 必须手动关闭
# with方式(更简洁安全)
with open("file.txt", "r") as f:
content = f.read()
# 离开代码块后,文件自动关闭2.数据库连接
确保数据库连接在使用后正确关闭:
python
import sqlite3
with sqlite3.connect("mydb.db") as conn:
cursor = conn.cursor()
cursor.execute("SELECT * FROM users")
# 连接自动关闭(3) 自定义上下文管理器
如果需要为自己的类实现 with 语句支持,只需在类中定义 __enter__() 和__exit__()方法:
python
class MyResource:
def __enter__(self):
print("获取资源")
return self # 返回给 as 后的变量
def __exit__(self, exc_type, exc_val, exc_tb):
print("释放资源")
# 可以处理异常:如果返回 True,则异常不会向外传播
return False
# 使用自定义资源
with MyResource() as res:
print("使用资源")输出结果:
text
获取资源
使用资源
释放资源26. json操作
Python 的 json 模块提供了处理 JSON 数据的功能,包括解析 JSON 字符串为 Python 对象,以及将 Python 对象转换为 JSON 字符串。以下是常见的 JSON 操作方法:
(1) 导入 json 模块
python
import json(2) Python 对象转 JSON 字符串(序列化)
使用 json.dumps() 方法,将 Python 的字典、列表等对象转换为 JSON 格式的字符串。
python
# 定义一个 Python 字典
data = {
"name": "Alice",
"age": 30,
"is_student": False,
"hobbies": ["reading", "coding"]
}
# 转换为 JSON 字符串
json_str = json.dumps(data)
print(json_str)
# 输出: {"name": "Alice", "age": 30, "is_student": false, "hobbies": ["reading", "coding"]}
# 格式化输出(增加缩进和排序)
json_str_pretty = json.dumps(data, indent=4, sort_keys=True)
print(json_str_pretty)(3) JSON 字符串转 Python 对象(反序列化)
使用 json.loads() 方法,将 JSON 字符串解析为 Python 的字典或列表。
python
# JSON 字符串
json_str = '{"name": "Bob", "age": 25, "scores": [90, 85, 95]}'
# 解析为 Python 字典
data = json.loads(json_str)
print(data["name"]) # 输出: Bob
print(data["scores"][0]) # 输出: 90(4) 读写 JSON 文件
json.dump(): 将 Python 对象写入 JSON 文件json.load(): 从 JSON 文件读取数据并转换为 Python 对象
(5) 处理自定义对象
默认情况下,json 模块不能直接序列化自定义类的实例。需要自定义序列化和反序列化方法:
python
class Person:
def __init__(self, name, age):
self.name = name
self.age = age
# 自定义序列化函数
def person_to_dict(person):
return {"name": person.name, "age": person.age}
# 自定义反序列化函数
def dict_to_person(d):
return Person(d["name"], d["age"])
# 创建对象
p = Person("David", 40)
# 序列化
json_str = json.dumps(p, default=person_to_dict)
# 反序列化
p2 = json.loads(json_str, object_hook=dict_to_person)
print(p2.name) # 输出: David(6) 注意事项:
- JSON 支持的数据类型:字符串、数字、布尔值、null、对象(字典)、数组(列表)
- Python 中的
None会被转换为 JSON 的null - Python 中的
True/False会被转换为 JSON 的true/false - 日期、时间等类型需要先转换为字符串才能序列化
通过这些方法,可以方便地在 Python 中处理 JSON 数据,满足大多数数据交换场景的需求。
27.单元测试
单元测试是软件开发中验证单个代码单元(如函数、类方法)是否正确工作的重要实践。Python 标准库提供了 unittest 模块(基于 xUnit 框架),也有第三方库如 pytest 可以简化测试过程。
(1) 使用unittest模块
unittest 提供了类似 JUnit 的测试框架,核心概念包括:
TestCase:测试用例的基类
assert 方法:验证结果是否符合预期
setUp()/tearDown():测试前后的准备和清理工作
以下是一个简单示例:
python
import unittest
# 要测试的函数
def add(a, b):
return a + b
def multiply(a, b):
return a * b
# 测试类,继承自 unittest.TestCase
class TestMathFunctions(unittest.TestCase):
# 测试前的准备工作
def setUp(self):
print("准备测试数据...")
# 测试后的清理工作
def tearDown(self):
print("测试结束,清理资源...")
# 测试加法函数,方法名必须以 test 开头
def test_add(self):
self.assertEqual(add(2, 3), 5) # 验证相等
self.assertEqual(add(-1, 1), 0)
self.assertNotEqual(add(2, 2), 5) # 验证不相等
# 测试乘法函数
def test_multiply(self):
self.assertEqual(multiply(3, 4), 12)
self.assertEqual(multiply(0, 5), 0)
self.assertRaises(TypeError, multiply, "2", 3) # 验证异常
# 判断当前模块是作为主程序运行还是被其他模块导入
if __name__ == '__main__':
unittest.main() # 运行所有测试用例(2) 常用断言方法
unittest.TestCase 提供了多种断言方法:
| 方法 | 说明 |
|---|---|
| assertEqual(a, b) | 验证 a == b |
| assertNotEqual(a, b) | 验证 a != b |
| assertTrue(x) | 验证 x 为 True |
| assertFalse(x) | 验证 x 为 False |
| assertIs(a, b) | 验证 a 是 b(同一对象) |
| assertIsNone(x) | 验证 x 是 None |
| assertIn(a, b) | 验证 a 在 b 中 |
| assertNotIn(a, b) | 验证 a 不在 b 中 |
| assertRaises(exception, func, *args) | 验证调用函数会抛出指定异常 |
(3) 使用 pytest(第三方库)
pytest 是更简洁的测试框架,无需继承特定类,支持函数式测试:
安装:pip install pytest
示例:
python
# 测试文件命名通常为 test_*.py 或 *_test.py
def add(a, b):
return a + b
def test_add():
assert add(2, 3) == 5
assert add(-1, 1) == 0
def test_add_strings():
assert add("Hello", " World") == "Hello World"运行:pytest test_math.py -v(-v 显示详细信息)
