前言
博主比较习惯使用WebStorm编写前端代码,而插件市场中比较好用的AI编码工具要属通义灵码了。但灵码最近把DeepSeek的模型给下了,我觉得DeepSeek还是挺好用的,遂想要自己在本地部署一个DeepSeek的14B模型,看一下是否可用(14B的模型只能说勉强能用)。
值得吐槽的一点是灵码不支持使用本地部署的模型,只能用它的云端AI模型。因此IDE上的编码插件就选择了Continue。
用到的工具
我主要用到以下两个工具
1. Ollama:Ollama是一个便于用户在本地部署和管理开源大的应用框架,简化了开源大语言模型的安装和配置细节
2. Continue:Continue 是一个开源平台,用于构建 AI 驱动的编码助手,其中包含可定制的组件,用于 VS Code 和 JetBrains IDE 中的聊天、自动完成、编辑和代理工作流
工具安装与使用
1. Ollama
可以点击该链接直达Ollama的下载页:ollama.com/download
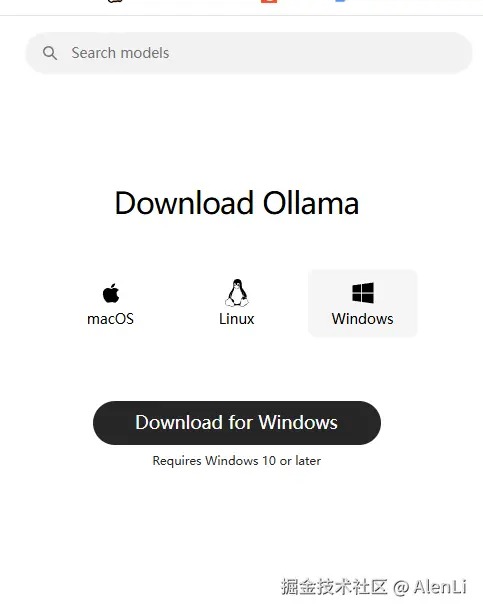
下载完成后回到Ollama的网页中,点击左上方的Models
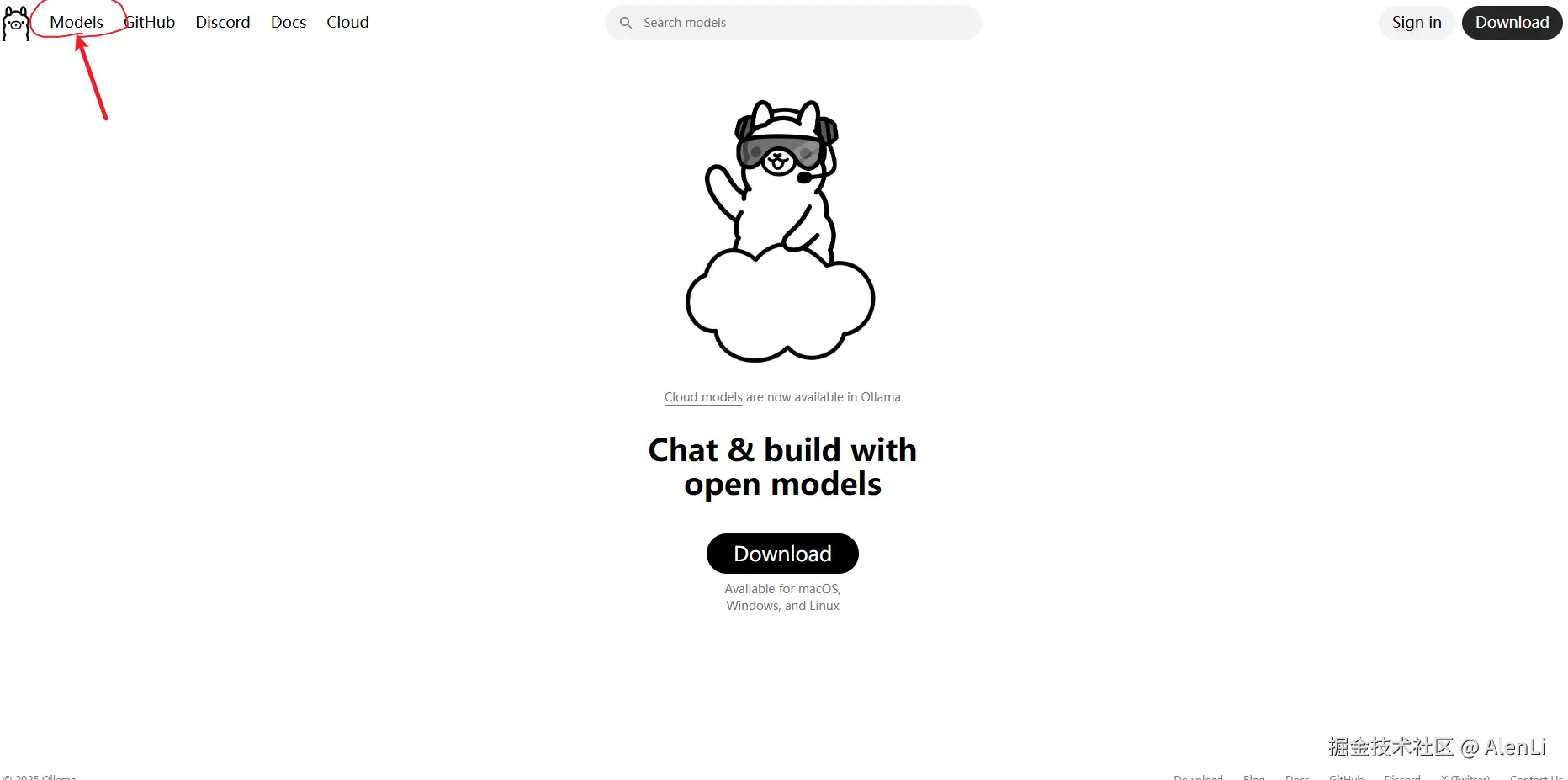
搜索你需要的AI模型去安装
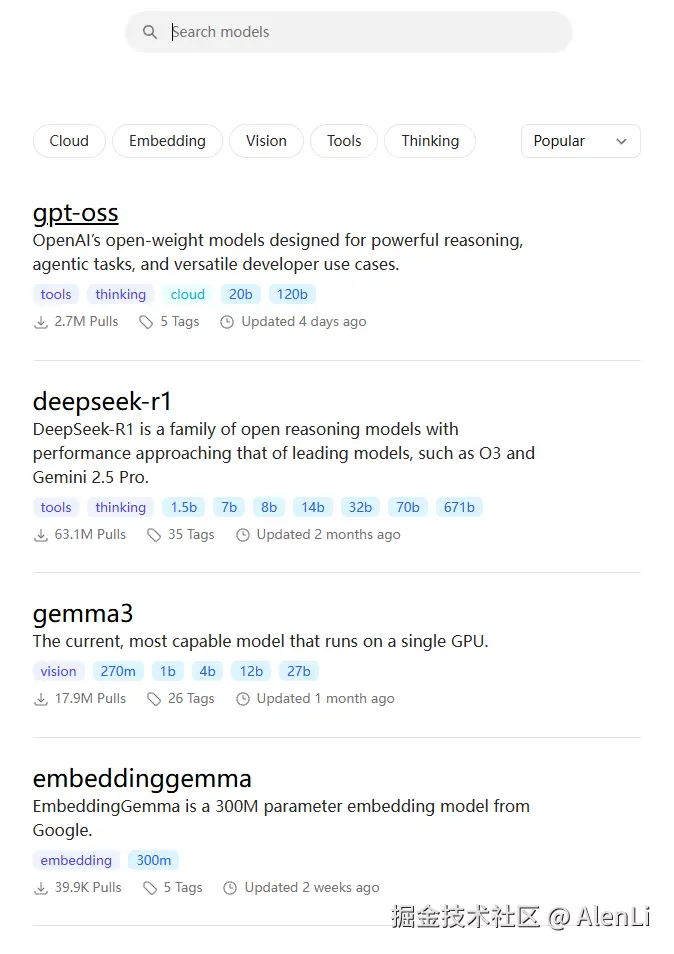
例如我选择了DeepSeek-R1,有以下几个不同参数量的模型可供选择:
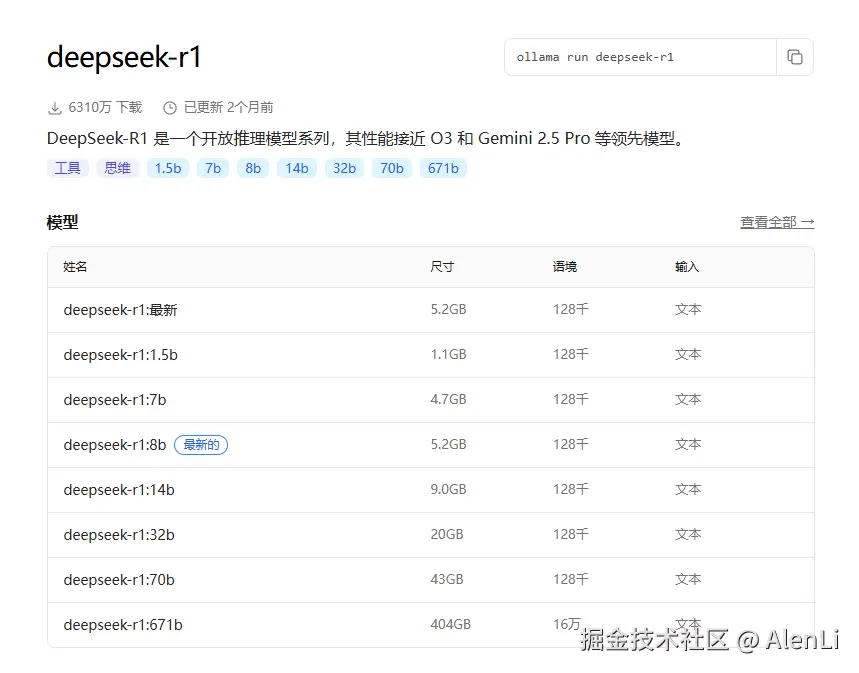
一个模型的体积主要由其参数量 和数值精度(数据类型) 决定。
全精度(FP32) :每个参数占 4 个字节。
14B 模型大小 = 32,000,000,000 参数 × 4 字节/参数 ≈ 56 GB
半精度(FP16/BF16) :每个参数占 2 个字节。这是GPU运行模型时的常用精度。14B 模型大小 = 32,000,000,000 参数 × 2 字节/参数 ≈ 28 GB
所以,要流畅运行一个14B的FP16模型,你至少需要能放下这32GB的显存。但通过把高精度(如FP16)模型转换为低精度(如INT8, INT4)的技术,可以大幅减少模型体积和显存占用,但会轻微损失一些模型质量。这种技术手段也叫做量化。
INT8(8比特整数) :每个参数占 1 个字节。
14B 模型大小 ≈ 14 GB
INT4(4比特整数) :每个参数占 0.5 个字节。14B 模型大小 ≈ 7 GB
如果你没有足够的显存,系统会使用内存作为虚拟显存,通过CPU和GPU之间不断交换数据来加载模型。虽然能让你把模型跑起来,但速度会非常慢,因为数据交换的带宽是瓶颈。如果内存空间都不足了,会去使用磁盘设置的虚拟内存那就更加慢了。
对于Ollama上下载的这些模型,如果后面没有标注数值精度的话,一般是采用INT-4进行量化的模型。其实直接看下载模型的大小也能够知道能否正常跑。图中14B的模型需要9G,那么只要你显存大小超过9G了,就肯定能流畅跑。博主的显卡是5070,只有12G显存,内存是32G。14B的模型在博主的主机上能够流畅使用。
直接复制下Ollama的指令,在命令行粘贴后下载 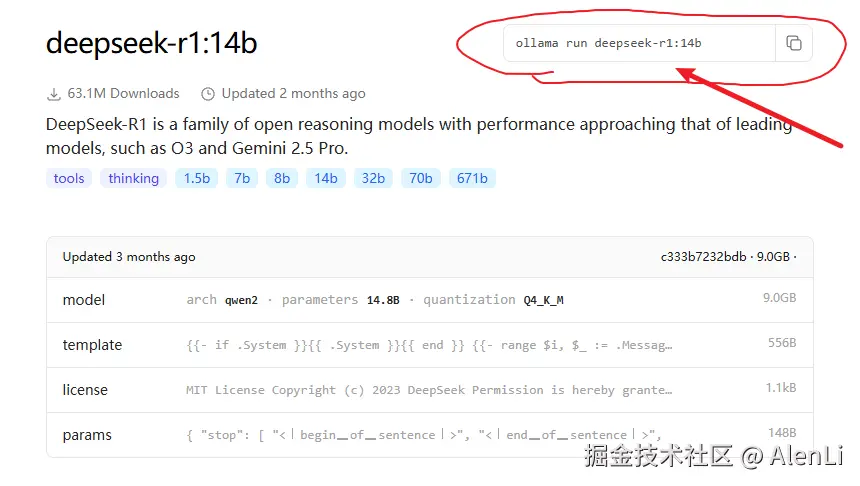
安装完成后可以直接在Ollama的应用界面里选择刚才下好的模型,进行对话
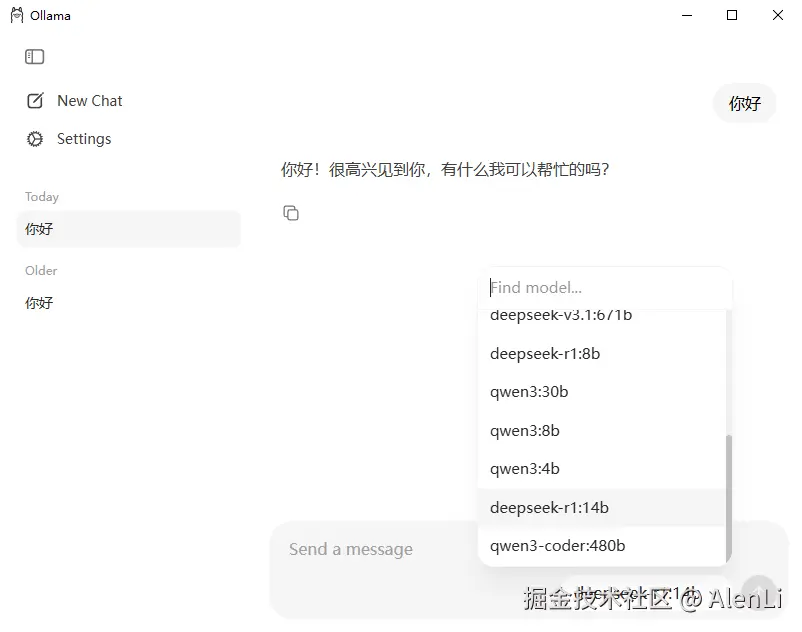
2. Continue
在插件市场里下载Continue
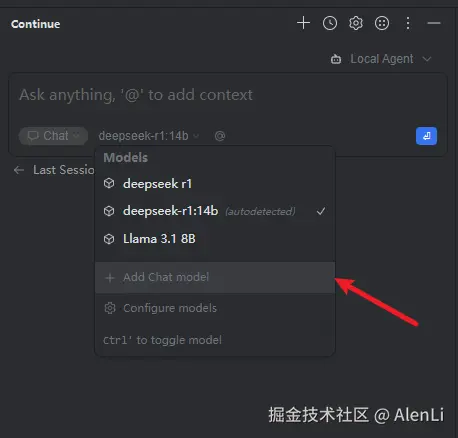
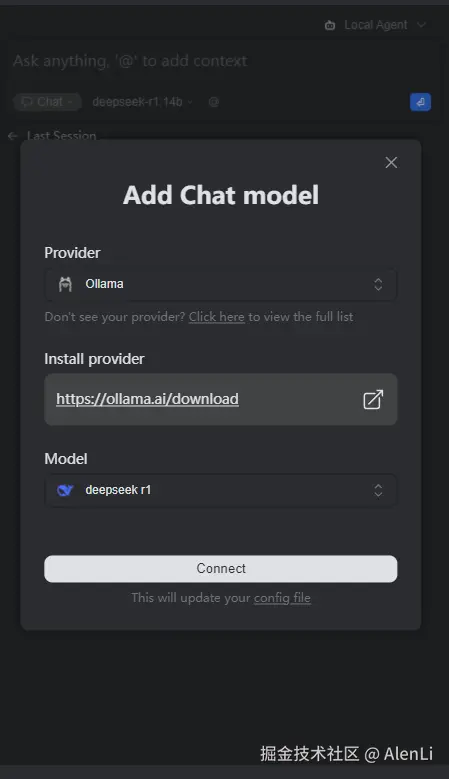
下载好后,默认在右侧工具栏里可以找到Continue,直接添加模型
 \
\
选择Ollama和对应的模型,添加好后就能在模型选择里看到刚刚添加的模型啦
需要注意的是,在使用Continue期间,Ollama应用不能关。Ollama应用起了一个本地服务器,关了它,你Continue里就无法使用本地模型了。