from pyspark.sql import SparkSession
from pyspark.ml import Pipeline
from pyspark.ml.feature import (
VectorAssembler, StandardScaler, MinMaxScaler,
StringIndexer, OneHotEncoder, Bucketizer,
QuantileDiscretizer, Normalizer, MaxAbsScaler,
RobustScaler, PCA, ChiSqSelector
)
from pyspark.ml.classification import LogisticRegression
from pyspark.sql.functions import col, when
from pyspark.sql.types import *
# 创建SparkSession
spark = SparkSession.builder \
.appName("DataPreprocessingPipeline") \
.getOrCreate()
# 创建示例数据
data = [
(1, 25, 50000, "male", "engineer", "high", 85.5, 1),
(2, 30, 75000, "female", "doctor", "medium", 92.3, 1),
(3, 35, 60000, "male", "teacher", "low", 78.9, 0),
(4, 45, 90000, "female", "engineer", "high", 88.7, 1),
(5, 28, 45000, "male", "artist", "medium", 76.2, 0),
(6, 40, 85000, "female", "doctor", "low", 91.5, 1),
(7, 22, 35000, "male", "teacher", "high", 82.1, 0),
(8, 55, 120000, "female", "engineer", "medium", 89.9, 1)
]
columns = ["id", "age", "income", "gender", "occupation", "education", "score", "label"]
df = spark.createDataFrame(data, columns)
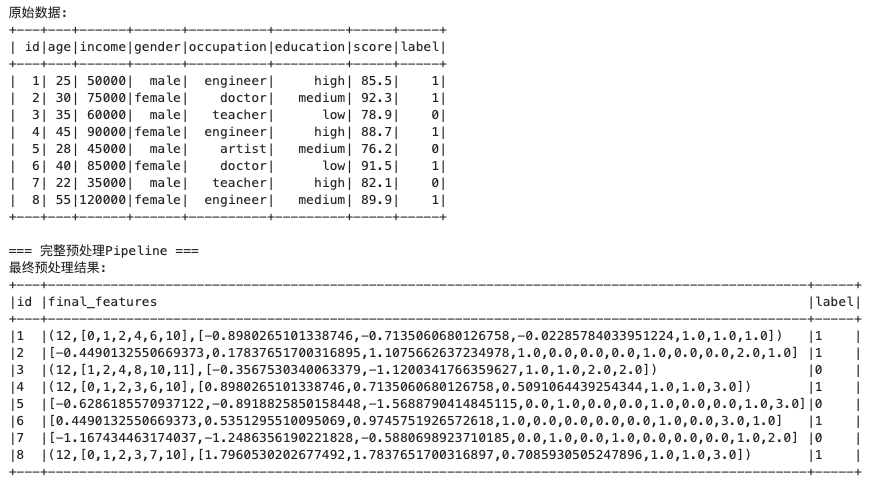
print("原始数据:")
df.show()
print("=== 完整预处理Pipeline ===")
# 最推荐的方案
complete_pipeline = Pipeline(stages=[
# 两个onehot 一个labelEncoder
StringIndexer(handleInvalid="keep", inputCols=["gender","education","occupation"], outputCols=["gender_idx","education_idx","occupation_idx"]),
OneHotEncoder(handleInvalid="keep", inputCols=["gender_idx","education_idx"], outputCols=["gender_onehot","education_onehot"], dropLast=True),
# 数值标准化
VectorAssembler(inputCols=["age", "income", "score"], outputCol="numerical_features"),
StandardScaler(
inputCol="numerical_features",
outputCol="scaled_numerical",
withMean=True, # withMean=True 会把稀疏向量变稠密
withStd=True
),
# 分桶特征保持原样(如果需要的话)
Bucketizer(splits=[-float("inf"),0, 30, 40, 100,float("inf")], inputCol="age", outputCol="age_bucket"),
# 最终组装
VectorAssembler(
inputCols=["scaled_numerical","gender_onehot","education_onehot","age_bucket","occupation_idx"]
,outputCol="final_features"
)
])
# 训练Pipeline
complete_model = complete_pipeline.fit(df)
final_result = complete_model.transform(df)
print("最终预处理结果:")
final_result.select("id", "final_features", "label").show(truncate=False)
原始数据:
+---+---+------+------+----------+---------+-----+-----+
| id|age|income|gender|occupation|education|score|label|
+---+---+------+------+----------+---------+-----+-----+
| 1| 25| 50000| male| engineer| high| 85.5| 1|
| 2| 30| 75000|female| doctor| medium| 92.3| 1|
| 3| 35| 60000| male| teacher| low| 78.9| 0|
| 4| 45| 90000|female| engineer| high| 88.7| 1|
| 5| 28| 45000| male| artist| medium| 76.2| 0|
| 6| 40| 85000|female| doctor| low| 91.5| 1|
| 7| 22| 35000| male| teacher| high| 82.1| 0|
| 8| 55|120000|female| engineer| medium| 89.9| 1|
+---+---+------+------+----------+---------+-----+-----+
=== 完整预处理Pipeline ===
最终预处理结果:
+---+-------------------------------------------------------------------------------------------------+-----+
|id |final_features |label|
+---+-------------------------------------------------------------------------------------------------+-----+
|1 |(12,[0,1,2,4,6,10],[-0.8980265101338746,-0.7135060680126758,-0.02285784033951224,1.0,1.0,1.0]) |1 |
|2 |[-0.4490132550669373,0.17837651700316895,1.1075662637234978,1.0,0.0,0.0,0.0,1.0,0.0,0.0,2.0,1.0] |1 |
|3 |(12,[1,2,4,8,10,11],[-0.3567530340063379,-1.1200341766359627,1.0,1.0,2.0,2.0]) |0 |
|4 |(12,[0,1,2,3,6,10],[0.8980265101338746,0.7135060680126758,0.5091064439254344,1.0,1.0,3.0]) |1 |
|5 |[-0.6286185570937122,-0.8918825850158448,-1.5688790414845115,0.0,1.0,0.0,0.0,1.0,0.0,0.0,1.0,3.0]|0 |
|6 |[0.4490132550669373,0.5351295510095069,0.9745751926572618,1.0,0.0,0.0,0.0,0.0,1.0,0.0,3.0,1.0] |1 |
|7 |[-1.167434463174037,-1.2486356190221828,-0.5880698923710185,0.0,1.0,0.0,1.0,0.0,0.0,0.0,1.0,2.0] |0 |
|8 |(12,[0,1,2,3,7,10],[1.7960530202677492,1.7837651700316897,0.7085930505247896,1.0,1.0,3.0]) |1 |
+---+-------------------------------------------------------------------------------------------------+-----+