点一下关注吧!!!非常感谢!!持续更新!!!
大模型篇章已经开始!
- 目前已经更新到了第 22 篇:大语言模型 22 - MCP 自动操作 Figma+Cursor 自动设计原型
Java篇开始了!
- MyBatis 更新完毕
- 目前开始更新 Spring,一起深入浅出!
目前已经更新到了:
- Hadoop(已更完)
- HDFS(已更完)
- MapReduce(已更完)
- Hive(已更完)
- Flume(已更完)
- Sqoop(已更完)
- Zookeeper(已更完)
- HBase(已更完)
- Redis (已更完)
- Kafka(已更完)
- Spark(已更完)
- Flink(已更完)
- ClickHouse(已更完)
- Kudu(已更完)
- Druid(已更完)
- Kylin(已更完)
- Elasticsearch(已更完)
- DataX(已更完)
- Tez(已更完)
- 数据挖掘(已更完)
- Prometheus(已更完)
- Grafana(已更完)
- 离线数仓(已更完)
- 实时数仓(正在更新...)
- Spark MLib (正在更新...)
Bagging和Boosting区别
数据方面
● Bagging:对数据进行采样训练
● Boosting:根据前一轮学习结果调整数据的重要性
投票方面
● Bagging:所有学习器平权投票
● Boosting:对学习器进行加权投票
学习顺序
● Bagging:学习是并行的,每个学习器没有依赖关系
● Boosting:学习是串行的,学习有先后顺序
主要作用
● Bagging:主要用于提高泛化性能,解决过拟合
● Boosting:主要用于提高训练精度,解决欠拟合
GBDT
基本介绍
GBDT的全称是:Gradient Boosting Decision Tree,梯度提升树,在传统机器学习算法中,GBDT算的上是TOP3的算法。
Decision Tree
无论是处理回归问题还是二分类还是多分类问题,GBDT使用的决策树统统都是CART回归树。
对于回归树算法来说最重要的是寻找最佳的划分点,那么回归树中可划分点包含了所有的特征的所有可取的值。
在分类树中最佳划分点的判断标准是熵或者基尼系数,都是纯度来衡量的,但是在回归树中的样本标签华四连续数值,所以再使用熵之类的指标不再合适,取而代之的是平方误差,他能很好的评判拟合程度。
回归决策树
不管是回归决策树还是分类决策树,都会存在两个问题:
● 如何选择划分点?
● 如何决定叶节点的输出值?
一个回归树对应输入空间(即特征空间)的一个划分以及在划分单元上的输出值。分类决策树中,采用的信息论中的方法信息增益以及信息增益率,通过计算选择最佳划分点。
在回归树中,采用的是启发式的方法,假设数据集有 n 个特征:
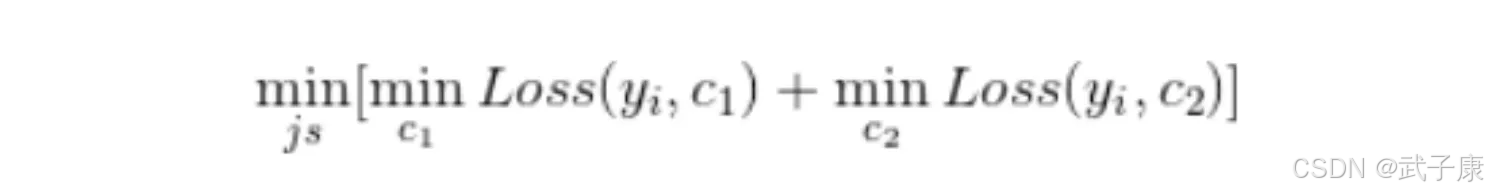
假设将输入空间划分为M个单元,R1、R2...Rm,那么每个区域的输出值就是:cm = avg(yi | xi ∈ Rm) 也就是该区域内所有点y值的平均数
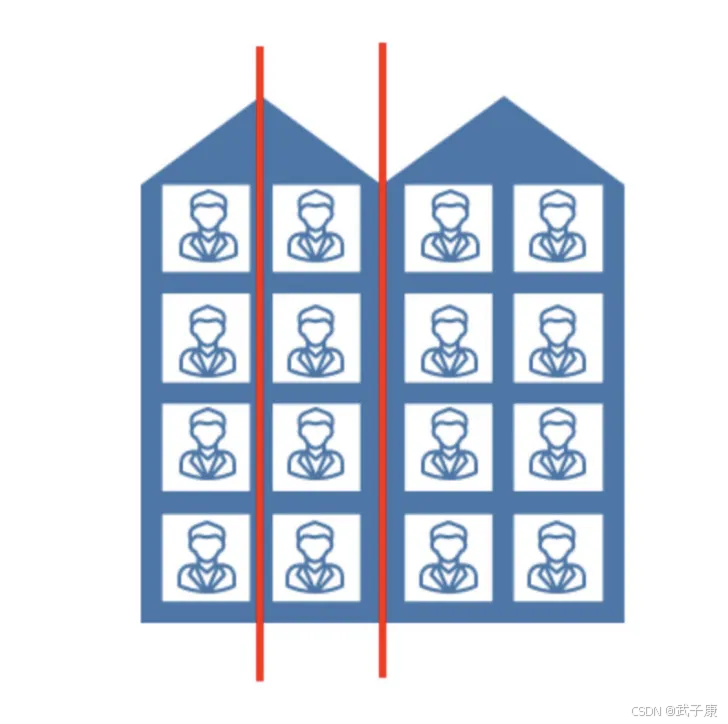
举例:
如下图,加入要对楼内居民的年龄进行回归,将楼划分为3个区域R1,R2,R3,那么R1的输出就是第一列居民年龄的平均值,R2输出的就是第二列居民年龄的平均值,R3的输出就是第三、四列八个居民年龄的平均值
算法流程
输入:训练数据集D
输出:回归树 f(x)
在训练数据集所在的输入空间中,递归的将每个区域划分为两个子区域并决定每个子区域上的输出值,构建二叉决策树:
1.选择最优切分特征j与切分点s,求解:
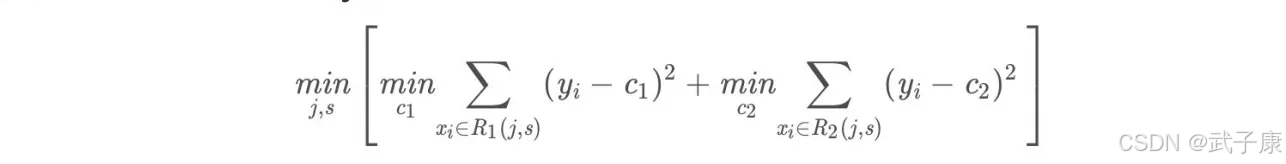
遍历特征j对固定的切分特征j扫描切分点s,选择使得上式达到最小值的对(j,s)
2.用选定的对(j,s)划分区域并决定相应的输出值:
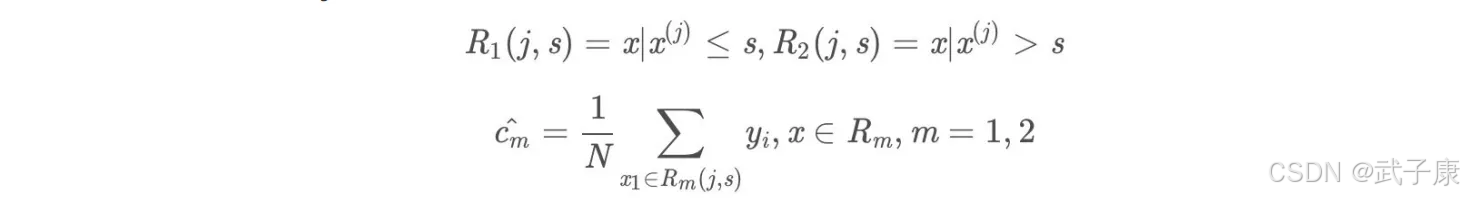
3.继续对两个子区域调用步骤(1)和(2),直到满足停止条件。
4.将输入空间划分M个区域 R1,R2...Rm,生成决策树:
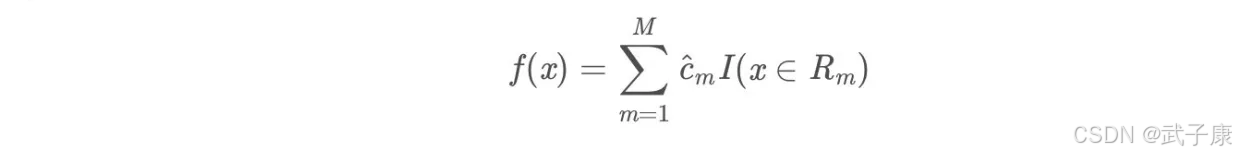
测试案例
通过一个实例加深对回归决策树的理解
训练数据
训练数据见下表

计算过程
选择最优的切分特征j与最优切分点s:
● 确定第一个问题:选择最优切分特征:在本数据集中,只有一个特征,因此最优切分特征自然是X
● 确定第二个问题:我们考虑9个切分点1.5,2.5,3.5,4.5,5.5,6.5,7.5,8.5,9.5:损失函数定义平方损失函数 Loss(y,f(x))= (f(x) - y) -y)^2,将上述9个切分点依次带入下面的公式 cm=avg(yi | xi ∈ Rm)
计算子区域的输出值:
例如:取 s = 1.5,此时 R1 = {1}, R2 = {2,3,4,5,6,7,8,9,10},这两个区域的输出值分别为:
● c1 = 5.56
● c2 = (省略...) = 7.50
同理,可以得到其他各切分点的子区域输出值,如下表所示:

计算损失函数值,找到最优切分点:
把c1,c2的值代入到同平方损失函数 Loss(y, f(x)) = (f(x)- y) ^ 2
当 s = 1.5 时

同理,计算得到其他各切分点的损失函数值,可获得下表:

显然取 s = 6.5 时,m(s)最小,因此,第一个划分变量【j=x, s=6.5】
用选定的 (j, s) 划分区域,并决定输出值:
● 两个区域分别是 R1={1,2,3,4,5,6}, R2={7,8,9,10}
● 输出值 cm = avg(yi | xi ∈ Rm),c1 = 6, c2 = 8.91
调用步骤(1)、(2),继续划分,对R1继续划分:

取切分点1.5,2.5,3.5,4.5,5.5,则各区域的输出值c如下表:

计算损失函数m(s):

s=3.5,m(s)最小。
生成回归树:
假设在生成3个区域之后停止划分,那么最终生成的回归树形式如下:
