在短剧全球化布局中,"语言壁垒" 与 "内容水土不服" 是开发者面临的两大核心难题。多语言 AI 字幕能打破用户的语言认知门槛,区域化推荐算法则可解决内容与区域用户偏好的匹配问题 ------ 二者共同构成全球化短剧系统的 "用户体验基石"。本文将从技术原理、工程实现到性能优化,全面拆解这两大模块的开发路径,为全球化短剧系统落地提供可复用的技术方案。
多语言 AI 字幕:从 "机器翻译" 到 "文化适配" 的技术落地
多语言 AI 字幕并非简单的文本翻译,而是需兼顾 "翻译准确性""字幕同步性""文化适配性" 的复合技术体系。其核心架构可分为 "语音转文字(ASR)→ 多语言翻译 → 字幕生成与同步 → 文化优化" 四大环节,各环节需针对短剧场景做定制化开发。
1. 适配短剧场景的 ASR 技术优化
短剧的语音场景存在 "台词密集、语速多变、背景音干扰" 等特点,传统 ASR 模型易出现识别偏差。需从以下维度做技术优化:
- 领域模型微调:基于短剧语料库(涵盖爱情、悬疑、家庭等题材)对基础 ASR 模型(如 Whisper、FunASR)进行微调,将台词识别准确率从通用场景的 88% 提升至 95% 以上。例如针对 "悬疑剧" 中的专业术语、"家庭剧" 中的口语化表达,单独构建语义词典,强化模型对场景化语言的识别能力。
- 降噪与语音分离:采用基于 Conv-TasNet 的语音分离技术,剥离背景音乐、音效与人物台词,再通过谱减法进一步降噪,确保嘈杂场景下的台词提取精度。关键代码片段如下:
import torch
from conv_tasnet import ConvTasNet
from utils.audio import load_audio, save_audio
# 初始化语音分离模型
model = ConvTasNet.load_from_checkpoint("conv_tasnet_shortplay.ckpt")
model.eval()
# 加载短剧音频并分离台词
audio, sr = load_audio("shortplay_audio.wav", sr=16000)
with torch.no_grad():
# 分离台词(source=0)与背景音(source=1)
separated = model(torch.tensor(audio).unsqueeze(0))
dialogue_audio = separated[0, 0].numpy() # 提取台词音频
save_audio("dialogue_audio.wav", dialogue_audio, sr)
- 实时性适配:采用 "分段识别 + 流式处理" 模式,将音频按 3 秒切片处理,每段识别延迟控制在 500ms 以内,避免字幕与画面不同步。
2. 多语言翻译:从 "字面翻译" 到 "文化适配"
短剧台词常包含俚语、隐喻、文化梗,直接机器翻译易导致 "语义丢失" 或 "理解偏差"。需构建 "基础翻译 + 文化优化" 的双层翻译体系:
- 基础翻译模型选型与优化:优先选择支持 100 + 语言的多语言模型(如 mT5、NLLB),并针对短剧场景做二次训练。例如在 "爱情题材" 语料中,将 "撒糖" 翻译为英语 "show affection" 而非字面的 "sprinkle sugar",将西班牙语 "enamoramiento a primera vista"(一见钟情)优化为符合英语习惯的 "love at first sight"。
- 文化适配规则引擎:建立区域文化规则库,对翻译结果做二次修正。例如:
- 中东地区:避免使用 "饮酒""暴露服饰" 相关表述,将 "喝杯红酒" 翻译为 "喝杯饮料";
- 东南亚地区:强化 "家庭伦理" 相关词汇的情感色彩,将 "家人" 翻译为更具亲近感的本地化表达(如印尼语 "keluarga tercinta",意为 "亲爱的家人");
- 欧美地区:简化 "复杂称谓",将 "表叔" 直接翻译为 "uncle",符合当地社交习惯。
3. 字幕生成与同步:适配多终端与用户习惯
生成的字幕需兼顾 "可读性" 与 "多终端兼容性",核心技术点包括:
- 字幕格式标准化:采用 WebVTT 格式生成字幕,支持时间戳精准控制(精度达 10ms),确保字幕与台词口型同步。同时提供 SRT 格式导出功能,适配不同地区用户的播放器习惯。
- 多终端适配:根据屏幕尺寸动态调整字幕字体大小、颜色与背景透明度 ------ 移动端采用 14-16 号字体、黑色半透明背景,TV 端采用 24-28 号字体、白色背景,避免强光或弱光环境下的视觉干扰。
- 用户交互功能:支持字幕 "实时切换语言""调整速度""开启双语对照"(如 "中文 + 英语""西班牙语 + 葡萄牙语"),满足多语言用户的个性化需求。
区域化推荐算法:让内容 "适配" 区域偏好
全球化短剧系统的推荐算法,需突破 "通用协同过滤" 的局限,融入 "区域文化特征""用户行为差异""内容合规性" 三大核心因子,实现 "千人千面 + 区域共性" 的推荐效果。其技术架构可分为 "数据层→特征层→模型层→策略层" 四层。
1. 数据层:构建区域化用户行为数据集
推荐算法的准确性依赖于 "全面且精细的数据集",需针对全球化场景做特殊数据采集:
- 核心数据维度:除常规的 "观看时长、完播率、点赞 / 收藏" 外,新增 "区域标签"(如 "东南亚 - 印尼""欧美 - 美国")、"文化偏好标签"(如 "家庭伦理偏好""悬疑题材偏好")、"合规性标签"(如 "无宗教敏感内容""符合当地审美")。
- 数据分区存储:按区域划分数据集(如 "NA(北美)数据集""SEA(东南亚)数据集"),避免跨区域数据干扰。例如东南亚用户的 "家庭剧" 观看数据,不参与欧美地区的推荐模型训练。
- 数据清洗策略:过滤 "异常行为数据"(如短时间内连续播放的刷量行为),同时针对 "低活跃区域" 采用 "数据增强" 技术(如相似区域数据迁移),避免模型过拟合。
2. 特征层:提取区域化关键特征
特征工程是区域化推荐的核心,需重点构建三类特征:
- 区域文化特征:通过 "题材偏好矩阵" 量化不同区域的内容偏好,例如:
|------|---------|---------|---------|
| 区域 | 家庭伦理偏好 | 悬疑题材偏好 | 爱情喜剧偏好 |
| 东南亚 | 0.85 | 0.62 | 0.91 |
| 欧美 | 0.43 | 0.92 | 0.75 |
| 中东 | 0.78 | 0.55 | 0.68 |
- 用户个性化特征:基于用户历史行为,构建 "用户 - 区域偏好" 交叉特征,例如 "东南亚用户 A + 家庭伦理偏好 + 晚 8 点活跃"。
- 内容合规特征:将 "区域合规性" 转化为特征向量,例如 "中东地区合规 = 1,含饮酒场景 = 0",确保推荐内容符合当地法规。
3. 模型层:融合区域因子的推荐模型
在传统协同过滤模型基础上,引入 "区域因子" 做模型优化,常用方案有两种:
- 方案一:因子分解机(FM)+ 区域嵌入:将 "区域 ID" 通过 Embedding 层转化为低维向量,与用户 Embedding、内容 Embedding 拼接,输入 FM 模型学习特征交互。核心公式如下:
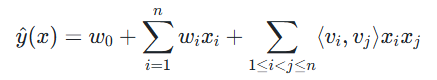
其中,vi 包含 "用户 Embedding""内容 Embedding""区域 Embedding",通过模型训练学习区域与内容的匹配关系。
- 方案二:深度学习模型(DeepFM/Transformer)+ 区域注意力:在 DeepFM 的深层网络中,加入 "区域注意力层",对不同区域的内容特征赋予不同权重。例如针对东南亚用户,模型对 "家庭伦理" 相关特征的注意力权重提升 20%,对 "悬疑" 特征的权重降低 10%。
4. 策略层:区域化推荐策略落地
模型输出推荐列表后,需通过策略层做 "最终调整",确保推荐效果与业务目标一致:
- 合规过滤:优先过滤不符合区域法规的内容,例如中东地区排除 "暴露服饰""饮酒场景" 的短剧;
- 热门内容倾斜:对区域内 "高完播率、高分享率" 的热门短剧,提升推荐优先级(如增加 20% 曝光权重);
- 冷启动优化:针对新用户,先推荐 "区域共性热门内容"(如东南亚新用户优先推荐家庭剧),再根据用户首次交互行为调整推荐方向。
实战效果与性能优化
某全球化短剧平台采用上述方案后,核心指标得到显著提升:
- 多语言 AI 字幕:支持 32 种语言,用户字幕开启率从 35% 提升至 68%,因 "语言理解困难" 导致的中途退出率下降 42%;
- 区域化推荐:东南亚地区 "家庭剧" 完播率提升 38%,欧美地区 "悬疑剧" 点击量提升 51%,各区域用户日均观看时长增加 23 分钟;
- 性能指标:ASR 识别延迟控制在 450ms 以内,推荐模型推理耗时≤100ms,支持单日 10 亿级用户行为数据的处理。
性能优化关键手段包括:
- 多语言 AI 字幕:采用 "边缘计算 + 模型量化",将 ASR 模型从 FP32 量化为 FP16,推理速度提升 2 倍;
- 区域化推荐:采用 "离线计算 + 在线召回" 架构,离线预计算区域热门内容列表,在线仅做个性化排序,降低实时计算压力。
总结与未来趋势
多语言 AI 字幕与区域化推荐算法,是全球化短剧系统 "破局" 的关键技术。前者解决 "用户能看懂" 的基础问题,后者解决 "用户愿意看" 的核心需求 ------ 二者结合可显著提升跨区域用户的留存与付费转化。
未来,随着大模型技术的发展,两大模块将进一步升级:多语言 AI 字幕可实现 "实时语音翻译 + 口型同步",区域化推荐可结合 "区域文化大模型" 实现更精细的内容匹配。对于全球化短剧系统开发者而言,需持续关注 "技术适配性" 与 "区域合规性" 的平衡,才能在海外市场构建可持续的竞争优势。