导读
本文主要介绍基于流批一体建设的Feed实时数仓在业务高速发展和降本增效的大环境下,所面临的问题和挑战,以及对应的解决方案。文章分为四个部分,首先介绍下旧的Feed实时数仓的整体架构设计;然后介绍随着业务的不断发展,旧的架构所面临的问题;第三部分是文章的重点,着重介绍重构升级后的Feed实时数仓架构设计,以及在重构升级过程中所遇到的关键性问题和解决方案;第四部分是总结和规划,Feed实时数仓重构升级后,带来了什么样的收益和业务效果,以及对实时数仓未来发展的一个思路探讨。
01 简介
Feed实时数仓是一个基于 feed 日志产出 15 分钟的流批日志表,主要用于对日志原始字段的解析,并下沉简单业务逻辑。该表保留最细粒度的用户明细数据,是Feed数据的最底层数仓宽表。其整体架构设计如下图所示
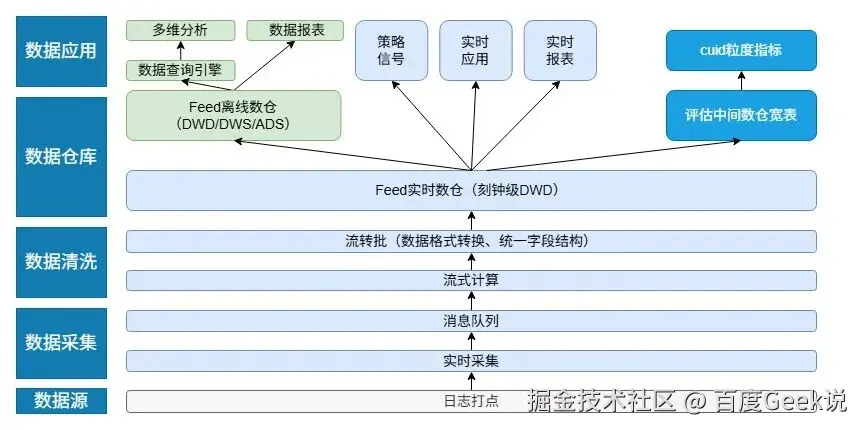
数据源:Feed实时数仓的数据源主要是各种日志打点数据,主要包括手百端打点和服务端打点。通过使用MEG日志中台提供的一站式打点方案,对用户的行为明细打点数据进行收集管理。
数据采集:数据采集过程,首先通过minos(百度自研的新一代的流式日志传输系统)的agent服务将打点服务的日志进行采集传输到实时流中,然后由日志中台的清源系统进行统一的清洗,对所有的日志打点数据进行格式化,统一schema。清源系统会将统一处理后的数据,传输到厂内消息队列bigpipe中(百度自研的分布式中间件系统)。
数据清洗:数据清洗分为两阶段。
第一阶段为基于TM流式框架搭建的Feed流式计算作业,该作业订阅消息队列bigpipe中的数据,对日志的原始字段进行解析,并下沉一些简单的Feed业务逻辑。流式计算处理结束之后,根据打点数据的生成时间进行落盘,生成刻钟级目录的数据。
第二阶段为基于StreamCompute框架搭建的批处理作业,该作业的任务是对第一阶段产出的刻钟级目录数据进行字段结构统一,并生成hive、spark等查询引擎能够直接查询的orc格式文件,最后将数据导入到实时数仓中。
数据仓库:
Feed实时数仓作为底层明细数据,虽然是DWD表,但保留着ods层数据的特点,存储着Feed日志打点的基础数据。
Feed业务基于实时数仓的数据,对复杂的业务逻辑进行下沉,产出小时级的离线DWD表,作为 feed 主要对外服务的数据表。并在DWD表的基础上,拼接其他主题数据,进行数据聚合,产出ads 层的主题宽表、中间表。
Feed评估业务基于Feed实时数仓,对cuid进行聚合,产出cuid粒度的评估中间数仓宽表。
数据应用:Feed实时数仓下游的数据应用,主要包括策略信号、实时应用、实时报表等高时效性的应用,主要用来检测数据趋势,观察实验策略、热点活动等带来的数据变化,主要是对Feed的分发、时长、au等指标的影响。
02 实时数仓面临的核心问题
随着业务的不断发展,越来越多的下游业务开始接入Feed实时数仓,比如商业、电商、直播等业务。Feed实时数仓急需解决以下几个问题
1. 计算过程繁琐,成本高时效慢
Feed实时数仓的整体架构为流处理+批处理的架构。其中流处理主要进行日志的ETL处理,订阅消息队列bigpipe中的实时流数据,进行清洗加工,产出统一的proto格式数据;批处理过程是对ETL后的proto格式数据进行格式转换,生成可供hive查询引擎直接查询的orc格式数据。
时效慢:流+批的数据处理架构,使得实时数仓数据的产出时间达到了45分钟,端到端数据应用的产出时间更是达到了50分钟以上。
随着手百业务的不断发展,实验评估、直播、电商等业务对数据的时效性提出了更高的要求。比如Feed实验对照组需要更快的实时监控来观测不同的实验策略对Feed的分发时长带来的收益,电商直播需要更快的实时监控来观察不同的分发策略对于直播间观看情况的影响。50分钟的实时监控已经无法满足这类高时效性的业务场景,尤其是重要时事热点、重大直播活动等热点项目。
成本高:实时计算处理过程使用了TM+SC两套流式架构,其中TM部分承担流式数据的清洗和简单的指标计算,SC部分主要是负责批处理的字段结构统一工作。流+批的处理架构成本偏高,其中TM部分需要240w/年,而SC部分需要360w/年,其负责的字段结构统一工作和消耗的成本明显不成正比。SC架构本是百度自研的一站式流式计算服务,在此项目中用来进行批处理的工作,造成了严重的资源浪费。
2. 下游业务多,指标对不齐
随着电商、直播等业务的发展,越来越多的业务开始接入Feed数据,原本只是为单一Feed业务提供的实时数仓宽表,其下游不断增加,包括且不限于评估实验、分润、商业、电商、直播、百家号等业务。由于Feed实时数仓只是数据清洗之后的用户明细数据,并不包括指标和维度相关的信息,比如点击、展现、播放时长、互动等指标,入口来源、视频类型、干预类型等维度信息。各下游在使用这些指标、维度时都需要根据宽表中的基础数据进行计算。由于下游使用方比较多,且分属不同的部门,计算口径往往无法统一。
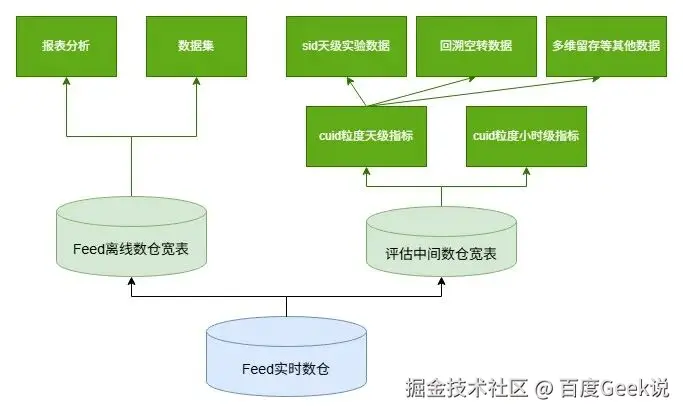
以Feed实验评估业务为例,随着Feed业务的发展,核心指标口径也不断变化,导致实验指标和Feed大盘指标无法完全对齐,已经严重影响Feed业务迭代。对于口径对不齐问题,评估中心,数据中心做过专项治理,对齐Feed大盘+视频口径,解决了部分问题;但随着业务持续迭代,数据对不齐问题再次加剧,所以急需从根本上解决指标对不齐的问题。
3. 系统架构冗杂,稳定性差
Feed实时数仓整体架构从日志采集端到应用端,每个阶段的作业都未区分核心和非核心数据。尤其是数据采集部分和数据清洗部分,都是漏斗形架构。这样的架构就会出现,若非核心数据流量暴涨,会引起整体链路上的水位延迟,甚至会阻塞核心数据的处理,最终影响核心数据的使用。
03 实时数仓重构方案
3.1 整体架构
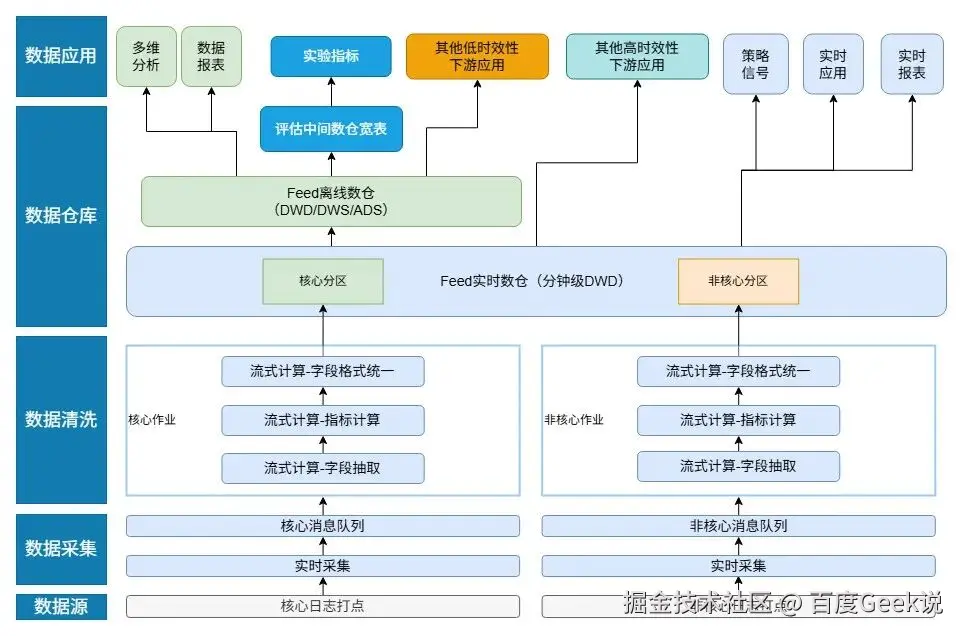
新的实时数仓架构,从数据采集到数仓阶段全部进行了重构升级。
数据采集:
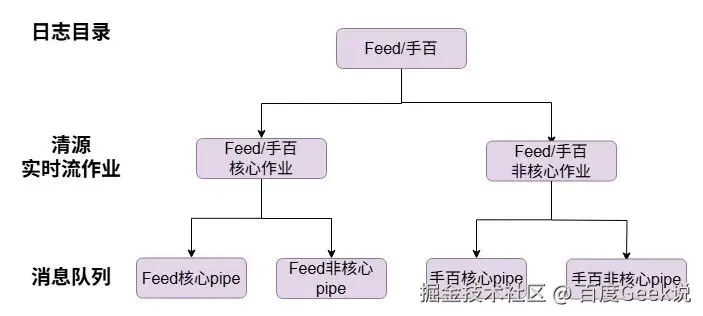
对日志打点从业务、点位重要度 两个维度进行拆分。下图以Feed、手百业务为例,日志中台的清源系统拆分出Feed核心作业、Feed非核心作业,分别处理Feed的核心和非核心数据,核心和非核心日志打点输出到不同的消息队列中,从源头实现核心和非核心数据的解耦。
**数据清洗:**对应核心和非核心消息队列,建立两个独立的数据清洗作业(核心作业和非核心作业)。
1). 字段抽取逻辑保持不变,依旧只是对数据进行简单的清洗。
2). 增加指标计算环节,该指标计算环节对应原架构中Feed离线数仓的小时级明细宽表的逻辑,将离线的复杂业务逻辑下沉到流式计算环节。最终产出的的实时数仓中包含了计算好的指标结果,由于Feed实时数仓为Feed数据的唯一出口,下游在使用时候可以忽略Feed业务逻辑的计算,直接使用Feed实时数仓产出的指标字段,从而解决下游指标对不齐的问题。
3). 删除流转批的处理环节,将字段格式统一的工作集成到流式计算环节中。基于TM流式框架实现了包括字段抽取+指标计算+字段格式统一的全部流式计算处理,减少了流转批的过程,节省大量计算资源,同时还提高数据产出时效性。
数据仓库:新版的Feed实时数据的字段结构与原架构中的Feed离线DWD数仓宽表保持一致,对Feed离线DWD数仓宽表中所有的复杂业务逻辑进行了下沉,新版Feed实时数仓=Feed离线DWD数仓宽表的实时化。下游应用直接通过简单的count/sum操作就能得到feed的各种指标结果,指标查询效率提升90%。
3.2 关键问题解决方案
3.2.1 离线复杂业务逻辑实时化解决方案
由于Feed实时数仓是Feed所有数据的唯一出口,将Feed离线DWD数仓宽表中的复杂业务逻辑下沉到实时数仓中,将从根本上解决下游各业务指标口径对不齐的问题。离线复杂业务逻辑下沉到流式,主要存在以下两个问题。
3.2.1.1 离线和实时数据计算维度不一致
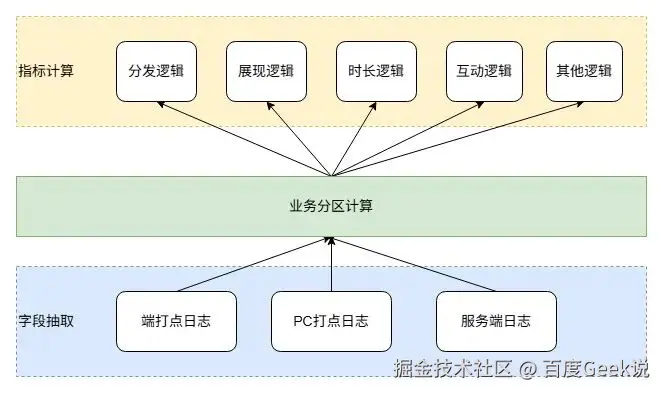
实时数仓和离线数仓建模维度不一样,业务逻辑无法直接下沉。旧的实时数仓是面向数据源建模,所有的字段抽取逻辑是基于不同的日志源进行抽取,比如端打点日志、PC打点日志、服务端日志等;而Feed离线数仓是基于业务建模,分成了点击、展现、时长、互动等业务分区,业务逻辑、指标计算也是在这些业务维度基础上进行处理。
解决方案:
在流式计算环节中,业务逻辑处理分为三层进行。如下图所示,第一层依旧进行字段抽取的数据清洗处理;第二部分根据根据关键字段信息,对所有日志数据进行业务逻辑分区;第三部分,该部分处理逻辑对齐离线的复杂业务逻辑,不同的业务分区,执行不同的业务逻辑计算。最终生成业务维度的实时数仓底层数据。
3.2.1.2 下游用户无法直接进行切换
原Feed实时数仓和Feed离线DWD数仓宽表,数仓建模维度不一样。原Feed实时数仓是简单清洗的日志明细表,只是对日志的字段进行简单的裁剪;Feed离线DWD数仓是对Feed实时数仓宽表进一步加工之后的表(包括删除无用日志字段信息(比如实验sid信息等)、删除无用打点日志、 通过日志明细计算出维度/指标字段)。如果新的实时数仓宽表字段要和离线DWD数仓宽表建模保持一致,原实时数仓下游使用方无法直接迁移到新的Feed实时数仓。
解决方案:
-
功能单一的大字段单独抽出,建立一个新的明细表。如sid字段,建立sid明细表,下游用户使用时通过cuid等字段进行关联。
-
无用打点日志:对于Feed业务来说无用的打点日志,单独保留到非核心分区。
-
新的实时数仓宽表,在离线数仓宽表字段基础上,增加字段用以表示旧实时数仓宽表中分区信息,兼容历史分区逻辑,以供下游切换时使用。
3.2.2 字段格式统一实时化解决方案
字段格式统一,主要是将清洗之后的数据,按照实时数仓的schema进行字段的格式进行统一,同时将最终数据文件(行存)转为ORC列式存储格式,以供hive、spark等查询引擎进行高效的查询。
在原来的数据架构中,字段格式统一只能由sc或者spark进行处理,所以只能使用流+批的方式进行实时数仓的生产,这造成了严重的资源浪费。将该部分处理工作集成到流式计算TM任务中,数据生产成本至少降低200万/年;同时缩短数据生产链路,提升数据产出时效。详细解决方案如下。
3.2.2.1 数据存储格式选定Parquet格式代替之前ORC格式作为最终数据的存储格式
Parquet是一种专为大数据处理系统优化的列式存储文件格式。目标是开发一种高效,高性能的列式存储格式,并且能够与各种数据处理系统兼容。Parquet 在2013年作为开源项目被创建,在2013年6月被 Apache 软件基金会采纳为顶级项目。它的开发受到 Apache Parquet 社区的积极推动。自推出以来,Parquet 在大数据社区中广受欢迎。如今,Parquet 已经被诸如 Apache Spark、Apache Hive、Apache Flink 和 Presto 等各种大数据处理框架广泛采用,甚至作为默认的文件格式,并在数据湖架构中被广泛使用。
Parquet具有以下优势
列式存储:
- Parquet 是一种列式存储格式,有多种文件压缩方式,并且有着很高的压缩比。
文件是可切分(Split)的:
- 在Spark中使用parquet作为表的文件存储格式,不仅节省AFS存储资源,查询任务的输入数据量减少,使用的MapTask也就减少了。
支持谓词下推和基于统计信息优化:
- Parquet 支持谓词下推和统计信息(例如最小值、最大值、空值等),这使得在执行查询时可以更有效地过滤和优化数据访问。这对于加速查询是非常有帮助的。
支持多种数据类型和模式演进:
- Parquet 支持多种数据类型,包括复杂数据结构,这使得它适用于各种类型的数据。此外,Parquet 允许模式演进,即在不破坏现有数据的前提下修改表结构,提供了更大的灵活性。
3.2.2.2 在TM框架中引入Apache Arrow开源库实现输出parquet格式文件
Apache Arrow 定义了一个与语言无关的列式存储内存格式,可以理解为parquet文件加载到内存中的表现。
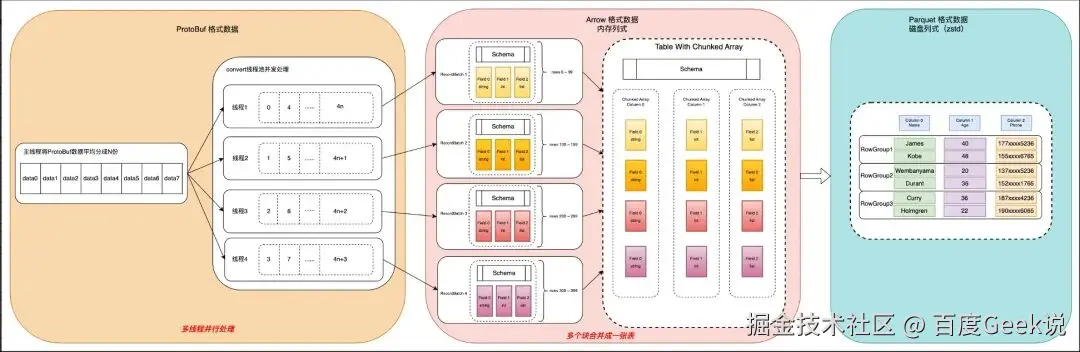
上图为Proto格式数据通过Arrow 转为Parquet格式数据的详细过程。
-
TMSinker算子(TM流式处理框架中输出算子)收到上游产出的proto数据后,首先将数据分成4份,每一份对应一个线程,
-
每个线程将自己负责的数据转成一个RecordBatch; 具体操作是解析Protobuf数据,将数据进行格式映射,构建一个Arrow Schema,填充到RecordBatch中,然后将4个RecordBatch合成一张Table。
-
使用Arrow提供的API,将Arrow Table写入到Parquet Writer,Parquet Writer负责把数据刷新到磁盘上。
部分组件概念如下:
RecordBatch,可以理解为一张子表,有schema信息和每一列数据,常作为并行计算的子数据单元。
Table可以理解为一张列式存储的表在内存中的表现形式,可以由多个RecordBatch合并而成。
3.2.2.3 实现过程中出现的其他问题及解决方案
小文件变多问题
原架构中,字段结构统一是批处理,会等15分钟的数据都产出之后,集中进行处理;而新的架构中,将字段结构统一的处理集成到流式计算中,导致小文件数过多。太多小文件会导致查询引擎增加对元数据读取开销等问题,影响查询稳定性,甚至会出现占满slot情况 影响其他任务。
小文件产出原因:正常TMsinker算子是通过攒task(数据大小+超时时间)减少小文件产生,但会存在跨时间窗口的数据,从而产出小文件问题。平均每15分钟会产生5234个文件,其中小文件951个,小文件占比18%(略早到的文件占比10%;略晚到的占比8%),平均文件大小258MB -- 未压缩)。
解决方案:
-
TMsinker 算子每次请求tm server获取task数由1个变为多个(可配置),避免出现sinker获取1个task就处理的情况,同时降低tm server的压力。
-
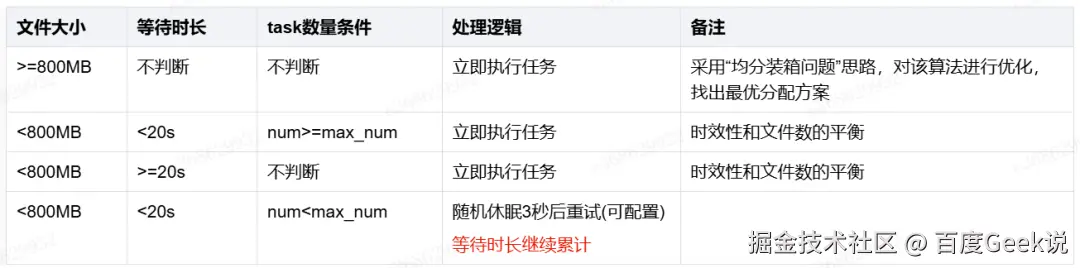
优化时间等待策略和攒数据策略
a. 默认配置
-
默认每次获取task数200个;(默认值200;用户可通过配置项覆盖)
-
最大等待时间20S;(默认20秒;时效和文件size的平衡;用户可通过配置项覆盖
-
最少积攒数据800MB; (默认800mb;用户可通过配置项覆盖)
b. 详细策略
-
max_num: 一次性可获取并锁定的最多task数量
-
last_num: 上一次获取并锁定的的task数量
-
num: 当前获取并锁定的task数量
大文件转parquet失败问题
在使用arrow库把proto格式数据转为parquet格式数据过程中,当某一列 string 类型的数据超过 2G 时格式转换会失败。
首先我们从string在内存中的表现形式来进行分析
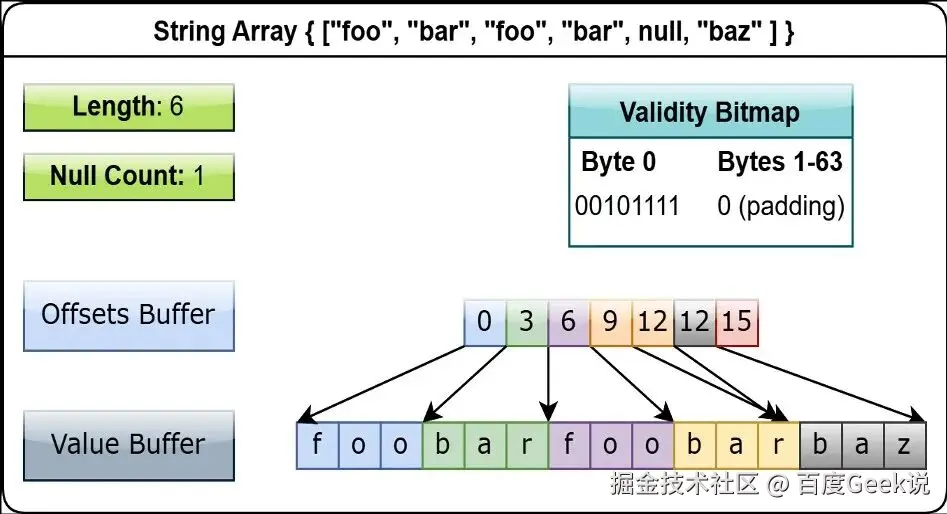
Length:表示这一列一共有多少条数据
Null Count:表示这一列一共有多少条数据是Null
Validity Bitmap:位图,1代表非Null,0代表null,用于快读判断某条数据是否是null
Value Buffer: 存储 string 数据 list;
**Offsets Buffer:**存储每条数据在ValueBuffer中的位置
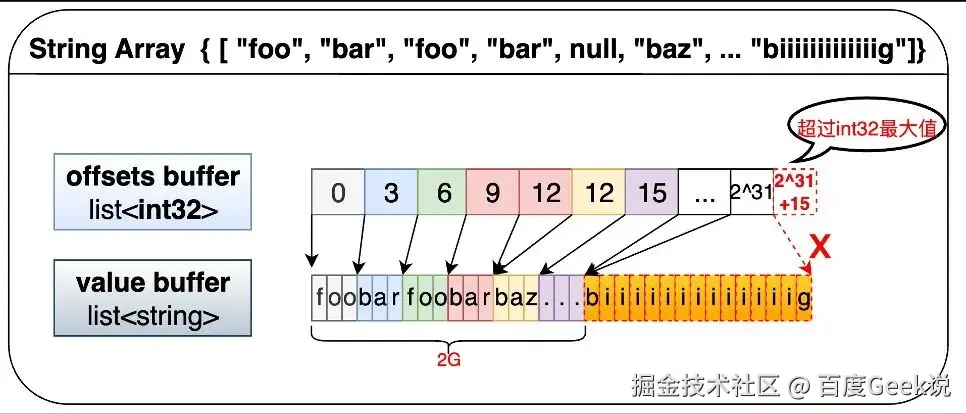
如上图,string的offsets buffer是list,因此string类型最大只能支持2^31字节=2G的数,如果在这条数据之前所有的数据已经超过2G了,那么因为Offset是int32无法表示大于2G的整数,导致这条数据无法转换。
问题原因找到,解决方案就很简单了,将string替换成large_string类型即可,其offsets buffer是list。
压缩耗时高问题
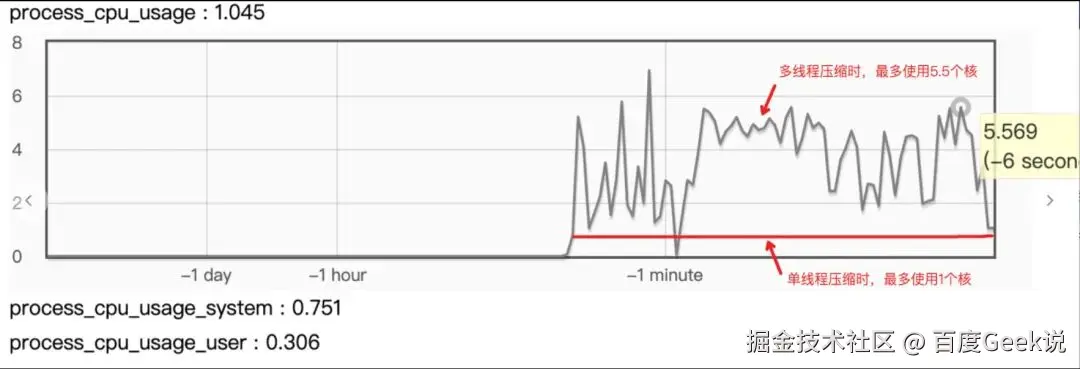
通过查看arrow库的源码,我们发现Arrow库当前使用的ZSTD压缩方法的Simple API,而Zstd库提供了 Simpler/Advanced API。这两个API的区别是Simple API只能设置压缩级别,而Advanced API可以设置压缩级别和压缩线程等。
解决方案:修改源码中ZSTD压缩方法的API,改为Advanced API,并通过环境变量暴漏多线程相关的参数。
以配置6核CPU为例,单线程时最多整使用1个核,多线程时可以使用到5.5个核
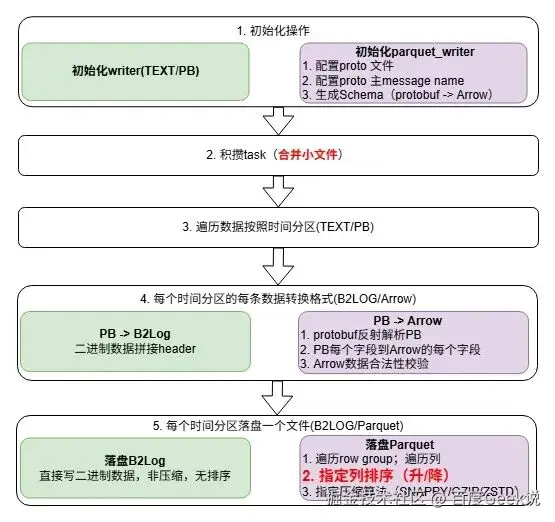
字段结构统一实时化最终整体解决方案如下:
04 总结与规划
Feed实时数仓重构升级完成后,流批一体架构升级为纯流式架构,整体计算成本节省50%,实时数仓数据产出实效缩短30分钟,提速80%。离线复杂业务逻辑下沉,指标查询效率提升90%,DWD明细宽表产出时效提升3小时;Feed宽表统一指标出口,其他下游和Feed业务线完成口径对齐,从根本上解决了指标对不齐的问题;流式计算整体架构统一到流式TM框架,维护成本降低50%,端到端核心非核心数据完成拆分,服务&数据双隔离,互不影响,服务稳定性大幅提升。
针对Feed实时数仓的后续规划,我们计划从计算引擎上进行优化升级,对标业界主流实时计算引擎,改变现有的C++代码开发模式,提高流式计算服务的开发效率,降低开发成本,以应对快速发展手百和Feed业务,满足越来越多的数仓需求。同时未来我们将把Feed实时数仓建设成厂内实时数仓标杆,为更多的业务提供实时数据服务。