前言
过去一周(25年9.23-9.27),我虽然在北京接连出差,但长沙分部的同事们 每天都在努力着(当然,我和搭档朝阳一直在努力提升大家每天每周的效率、产出)
-
比如先是跑通了ASAP
之前有个客户让跳舞,成功之前失败过多次,这次第N个新客户/新项目,涉及走路,先让ASAP来个(自主)小步跳跃的测试,当然了,一般第一版都不咋地 -
之后又跑通了宇树开源的RL走路算法 『如果你也遇到类似这个issue《G1 机器人在速度模式下无响应 --- Sim2Real 问题》所提到的问题,原因即为674360914所说的,lowcmd中未设置mode变量,将mode设置为1即可』
从而后续便可以扔掉遥控器,调用该算法完成一系列行走-操作 『做的很多东西没法对外发------包括很多同事在客户现场 驻场开发的,但这种科研复现的 可以随便发*,是一个很有意义的记录*』七月具身:训练宇树开源的RL走路算法
顺带说下,团队里985的实习生越来越多,包括从北京985过来的
期待更多985/211硕士实习生来我司(暂先长沙招,如有意敬请私我,且欢迎推荐 推成必奖),共同折腾、创造长远落地价值 -
再之后,则完成了GR00T N1.5部署在宇树G1上的第3版,自主完成桌面收纳
且节前还完成了自主导航、和搬箱子的新的版本..
正因为一直在不断优化搬箱子的任务,故对于行走-操作方面的算法,一直保持着高度关注,今天便来解读下前几天刚发布的VisualMimic
第一部分
1.1 引言与相关工作
1.1.1 引言
人类是如何设法推动一个仅靠手臂无法移动的沉重箱子的?
作者首先通过视觉感知定位箱子,并依靠视觉反馈来引导与箱子的互动。为了产生足够的推力,作者可能会弯下身,用双手推,借助手臂和肩膀的力量前倾,甚至用脚将箱子向前顶
在这种情况下,身体的每一个部位都可以参与进来以完成任务。这些策略强调了人类本体操控的两个基本方面:以自我为中心的视觉感知和全身灵巧性
赋予人形机器人类似人类的物体交互能力一直是一个长期存在的挑战。目前的方法根据任务可分为三大范式:
-
首先是以运动为核心的方法1,2擅长地形穿越,但未能解决物体交互问题
-
其次,依赖外部动作捕捉系统3,4进行物体状态估计的方法,将其应用限制在受控的实验室环境中
-
第三,基于视觉的物体交互方法主要分为两条路径:
1)通过人类演示训练视觉运动策略的模仿学习方法5--7,但受限于大规模演示数据的稀缺,导致泛化能力有限;
2)具有更强鲁棒性和泛化能力的从仿真到现实的强化学习(RL)方法8,9然而,基于视觉的强化学习目前仅限于如坐下8和爬楼梯8,9等简单的环境交互,远未达到人类水平的物体交互能力,原因在于人形机器人探索与动作空间巨大
作者旨在推动基于视觉的人形机器人-物体交互领域中,从仿真到现实(sim-to-real)强化学习的进一步发展
为了提升sim-to-real强化学习的泛化能力,作者采用了包含低层策略和高层策略的分层设计。在该分层框架中,与任务无关的低层策略负责平衡控制,并跟踪高层策略下发的指令;而任务相关的高层策略则基于自我中心视觉输入生成简化的跟踪指令
这样的设计能够实现更高效的任务特定训练------作者称之为VisualMimic

- 其paper地址为:VisualMimic: Visual Humanoid Loco-Manipulation via Motion Tracking and Generation
其作者包括
Shaofeng Yin*、Yanjie Ze*、Hong-Xing Yu、C. Karen Liu†、Jiajun Wu† - 其项目地址为:visualmimic.github.io
其GitHub地址为:github.com/visualmimic/VisualMimic
且作者将指令接口形式化为身体关键点(躯干、手、脚、头),以确保接口既简洁又具备表达力
首先,作者为了获得一个在跟踪指令时能够表现出类人行为的低级关键点跟踪器,作者整理了人体动作数据,并通过动作模仿奖励对跟踪器进行监
然而,由于仅依靠关键点指令无法完全捕捉人体动作的全部特征,且观察到关键点跟踪器虽然可以跟踪目标关键点,但未必能够完美再现类人行为
为了解决这一问题,作者采用了教师--学生训练方案:
- 首先训练一个动作跟踪器,使其能够完全访问当前及未来的全身动作,从而能够精确地跟随人体参考动作
- 随后,将该动作跟踪器的知识蒸馏到一个基于简化关键点指令的关键点跟踪器中
通过这种方式,作者的关键点跟踪器既能够捕捉人体动作行为,同时又保持了紧凑的指令空间。值得注意的是,该关键点跟踪器在训练完成后++具有任务无关性++,可在不同任务间共享
其次,基于这一通用关键点跟踪器,作者通过仿真到现实的强化学习训练高级关键点生成器。直接通过视觉强化学习训练策略会显著降低训练速度,并导致次优解
因此,作者再次采用了教师-学生机制:
-
首先训练一个基于状态的策略,该策略能特权访问物体状态,从而高效完成任务
-
随后,将基于状态的策略蒸馏到只依赖自我中心视觉和机器人本体感知的视觉-运动策略,使其无需外部物体状态估计即可直接部署于现实世界
为应对巨大的视觉仿真到现实差距(见图8),作者在仿真中对深度图像进行了大幅遮罩处理,以近似真实环境下的传感器噪声
由于强化学习具有探索性,作者发现当高层策略探索超出训练动作数据集中人类运动空间(HMS)范围的动作空间时,高层策略的训练并不稳定
为缓解这一问题,作者采用了两种策略:
- 在训练低层策略时注入噪声,以帮助其适应来自高层策略的潜在噪声指令
- 对高层策略的动作进行裁剪,使其保持在可行的人类运动空间(HMS)内
最终形成的框架VisualMimic,使得能够获得稳健且具有良好泛化能力的视觉运动策略,这些策略可以实现零样本迁移到真实机器人,涵盖广泛的人形机器人行走与操作任务,同时只需相对简单的任务特定奖励设计,并且无需配对的人-物体运动数据
在真实世界实验中(见图4和图3),作者展示了他们训练出来的人形机器人能够:

- 将0.5千克的箱子提升到1米高处
- 用全身将一个与机器人等高、重达3.8千克的大箱子稳定直线推行
- 以熟练球员的流畅动作带球行进
- 用双脚交替将箱子向前踢出
值得注意的是,我们还展示了视觉运动策略在户外场景下也能实现稳定表现,对光照变化和地面不平等真实环境中的多样性表现出极强的鲁棒性
1.1.2 相关工作
首先,对于人形机器人行走与操作的学习
使类人机器人能够在非结构化环境中执行类似于人类的多样化行走与操作任务,一直是机器人研究者长期追求的目标
目前主要有两条研究路径:
-
基于全身遥操作收集的真实世界数据进行模仿学习 5--7,12,13
尽管这些方法在任务多样性方面展现出良好前景,但依然受限于高质量数据的稀缺性以及数据收集难以扩展的问题 -
基于大规模仿真交互的仿真到现实强化学习3,8,9,14--16。这些方法在特定类人运动技能(如地形穿越 9,15、箱体搬运16、乒乓球 3)上表现出较强的泛化能力,但在任务多样性方面仍不及模仿学习
有些工作依然局限于仿真环境,例如 HumanoidBench 14 和SkillBlender 17 采用了与我们类似的分层框架
然而,它们的策略通常存在过度抖动或依赖特权物体状态的问题,从而阻碍了在现实世界中的成功部署
总之,以往针对类人机器人视觉运动策略学习的研究,通常侧重于上半身操作10,18--20或感知驱动的行走9,21,22
- 最近,VideoMimic8提出了一种real2sim2real流程,使真实机器人能够执行如坐下等环境交互,但其交互仍局限于地面或石椅等静态场景
- 其他工作,如PDC23,在基于视觉的全身行走与操作方面展示了有前景的仿真结果,但仅限于仿真环境
相比之下,作者提出了一种从仿真到现实的框架,使现实中的类人机器人能够通过自我视角视觉实现多样化的物体交互与行走操作
1.2 VisualMimic
VisualMimic是一种将自中心视觉感知与全身灵巧性先验相结合的仿真到现实框架,用于实现现实世界中的类人机器人行走与操作(见图2总览)
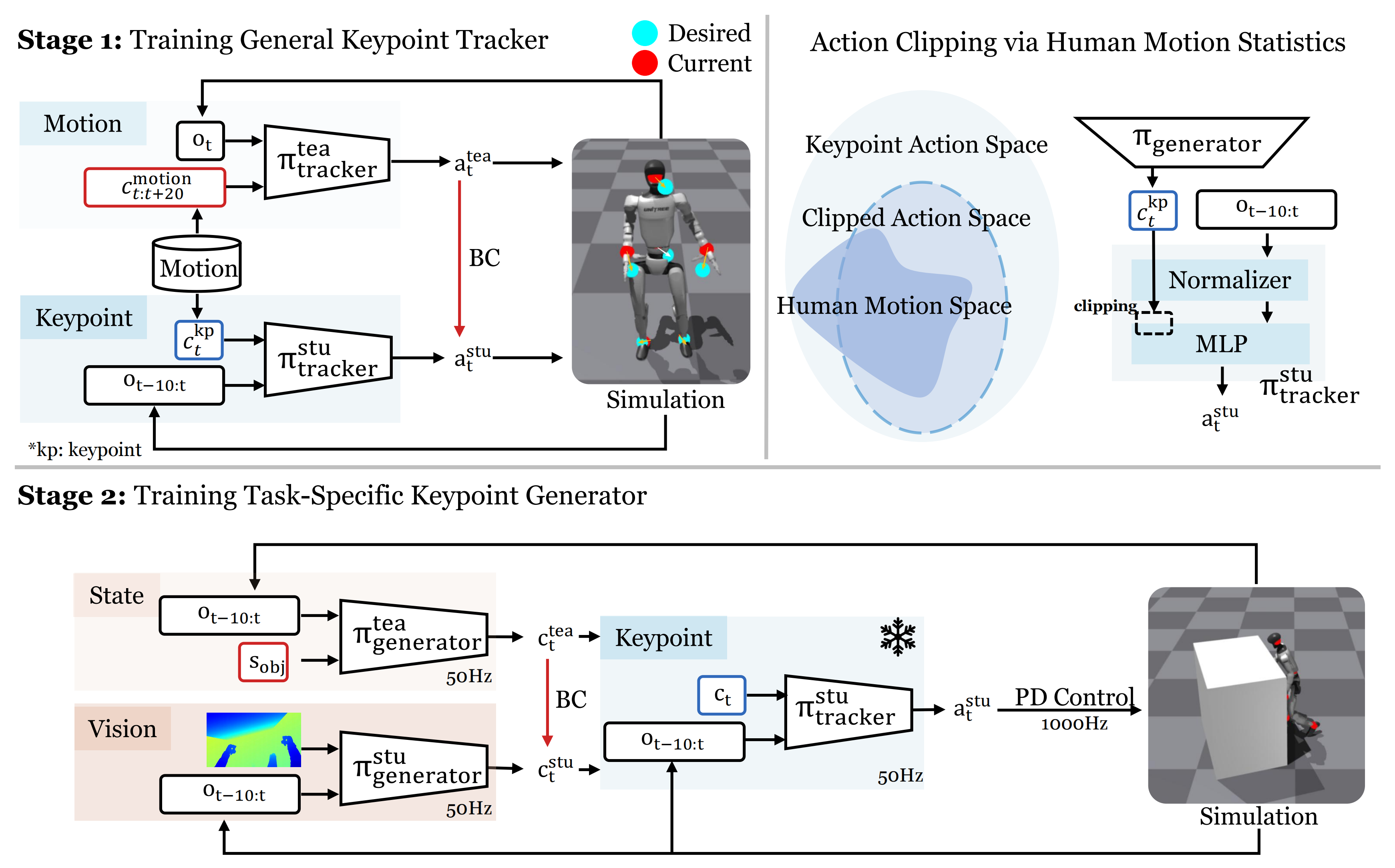
该方法包含两个主要组件:
- 一个低层次、任务无关的关键点跟踪策略
,从人体运动数据中学习全身灵巧性先验
- 一个高层次、任务相关的视觉运动策略
这两种策略均完全通过大规模仿真训练,并实现零样本迁移到真实机器人。该分层设计有助于快速适应新任务,因为只有高级策略需要针对每个任务进行训练
1.2.1 通用关键点跟踪器(低层策略、与任务无关):师生框架下的RL训练
尽管关键点跟踪策略可以直接进行训练,但由于其控制指令大大简化,其捕捉运动的能力弱于运动跟踪策略,从而导致生成的行为不如人类自然(见图6)
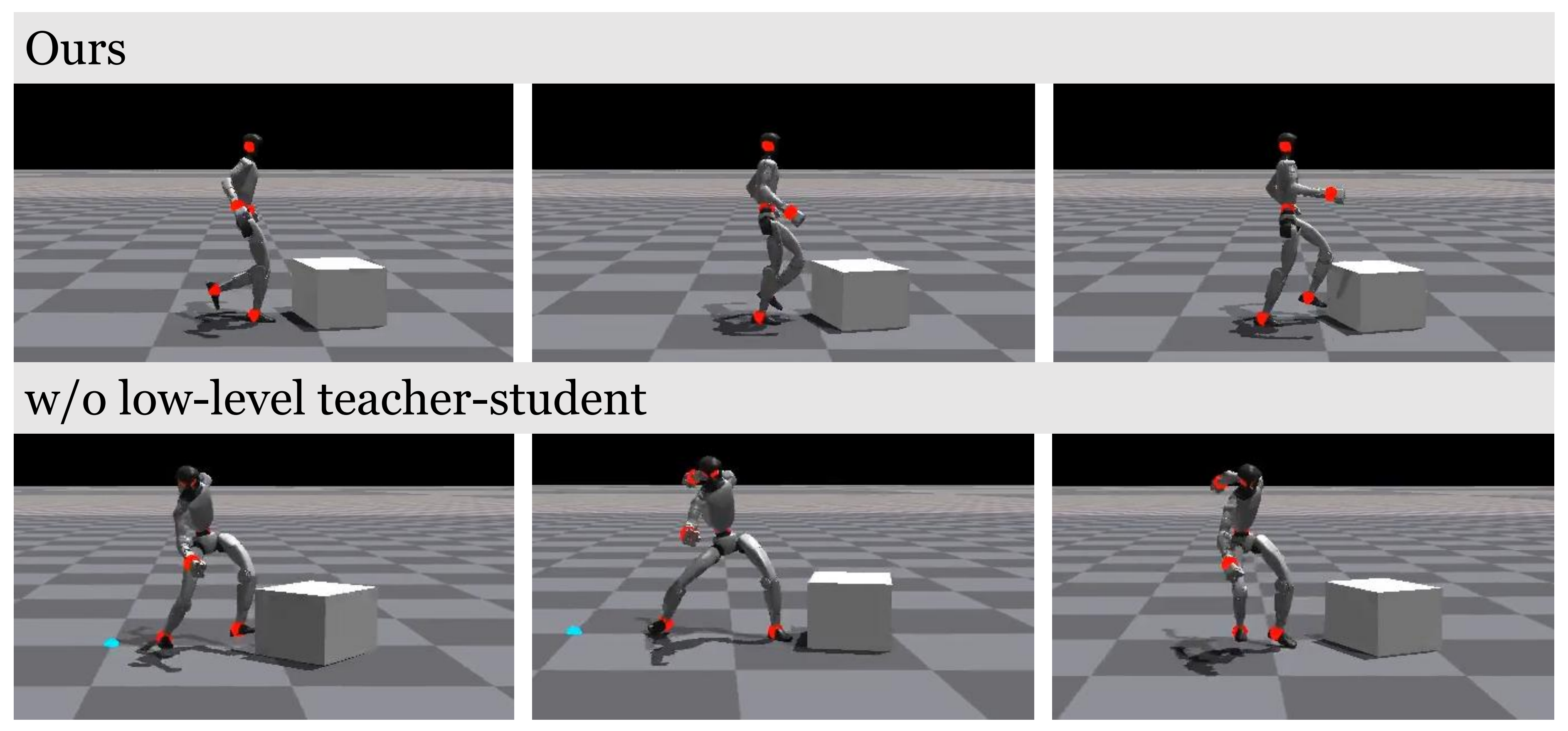
作者通过设计一个两阶段的教师-学生蒸馏流程来解决这一问题
- 具体来说,在教师训练阶段,特权教师运动跟踪器通过强化学习进行训练,并能够访问未来的参考动作
- 随后,学生关键点跟踪器采用DAgger 24 进行训练,仅依赖本体感知和每个时间步从参考帧计算得到的关键点指令
首先,对于a) 教师动作跟踪器
-
由于教师策略在部署过程中不会被使用,作者为其提供了足够的动作和本体感觉信息,以便其能够尽可能准确地进行跟踪
-
教师动作跟踪器
作者实现了
按照5中的奖励结构,奖励函数鼓励精确的动作跟踪,同时惩罚诸如抖动和脚部滑移等伪影:
值得注意的是,作者在世界坐标系中跟踪机器人身体的位置和根部速度。对于运动数据集,作者使用GMR 5,27将AMASS 28和OMOMO 29重定向为仿人机器人运动
其次,对于b) 学生关键点跟踪器
在获得生成器后,作者将其蒸馏为
生成器,通过DAgger 24,该方法以关键点指令
作为输入,并可在真实环境中部署
作者定义
其中根部位置误差为
而关键点误差(针对头部、双手和双脚)为
这里,"des"和"cur"分别表示期望(参考)轨迹和当前轨迹。关键点跟踪器跟踪器仅依赖于 pro-本体感受与即时指令
随后教师跟踪器实现为一个三层的MLP
1.2.2 任务特定关键点生成器
在低层关键点跟踪器训练完成后,下一步是开发一个高层关键点生成器,用于引导跟踪器执行多样化的任务。得益于以人体动作训练的低层跟踪器,只需专注于引导机器人完成任务即可------设计少量任务奖励,无需额外确保类人动作或收集人与物体交互的成对数据
然而,直接通过视觉强化学习训练这样的关键点生成器效率极低(见表III),因为诸如物体位置和接触力等关键信息仅能部分观测到,并且在Isaac-Gym中引入视觉会进一步降低仿真速度
为了解决这些挑战,作者采用了两阶段方法来训练任务特定的关键点生成器
- 第一阶段,具有任务相关物体状态访问权限的教师生成器通过PPO25进行训练
- 第二阶段,仅依赖深度图像获取物体信息的学生关键点跟踪器通过蒸馏得到
首先,对于a)基于状态的教师关键点生成器
如前文所述,教师关键点生成器利用物体状态加速训练。物体状态在环境中定义,并与本体感知信息拼接后作为基于状态的关键点生成器的输入。该生成器由三层MLP实现,采用PPO2526和任务特定奖励函数进行训练
作者专注于本地操作任务,例如推动/触及/踢击物体。其任务奖励如下:leftmargin=1.5em
-
接近(Rapproach)
鼓励与目标物体上的目标点接触
对于单点接触:
对于如用双手推动箱子等双点接触的情况,作者采用调和平均数来实现平衡:
其中 -
前进推进(Rforward)
奖励物体新的前向运动:
其中 -
力
奖励对物体施加了足够的力:
其中
此外,作者还有以下用于规范策略任务行为的项:leftmargin=1.5em
- 注视目标(Rlook):鼓励机器人面向目标物体:
- 漂移惩罚(Rdrift):惩罚横向偏离:
其次,对于b) 学生视觉关键点生成器
由于在部署过程中无法获取物体状态,基于状态的关键点生成器生成器被蒸馏为学生关键点生成器
关键点生成器仅依赖视觉观测和本体感知输入。由于RGB图像存在显著的仿真到现实差距,作者仅使用深度图像作为唯一的视觉模态
深度输入通过CNN编码器处理,其输出与本体感知特征拼接后输入到MLP中。学生关键点生成器通过DAgger 24进行蒸馏
1.2.3 将动作空间裁剪至人体运动空间
作者发现,即使采用了紧凑的指令空间,的训练稳定性仍然难以维持,因为强化学习在训练过程中需要大量探索,而这种探索很容易超出从人体动作中提取的关键点指令的可行空间
故作者将这一可行空间称为人体运动空间(Human Motion Space,HMS)。为缓解动作探索超出HMS的问题,作者提出了以下两种技术方案
-
a) 用于低层学生训练的加噪关键点指令
为了增强低层策略的鲁棒性并扩展人体运动空间的范围,作者在训练过程中对关键点指令的每一个维度注入乘性噪声形式化地,带噪声的指令定义为
其中作者将相对噪声水平设定为50%,该水平足以丰富关键点指令的多样性,同时保留运动信号。实验证明,这一策略显著提升了后续关键点生成器的训练效果(见图9a)
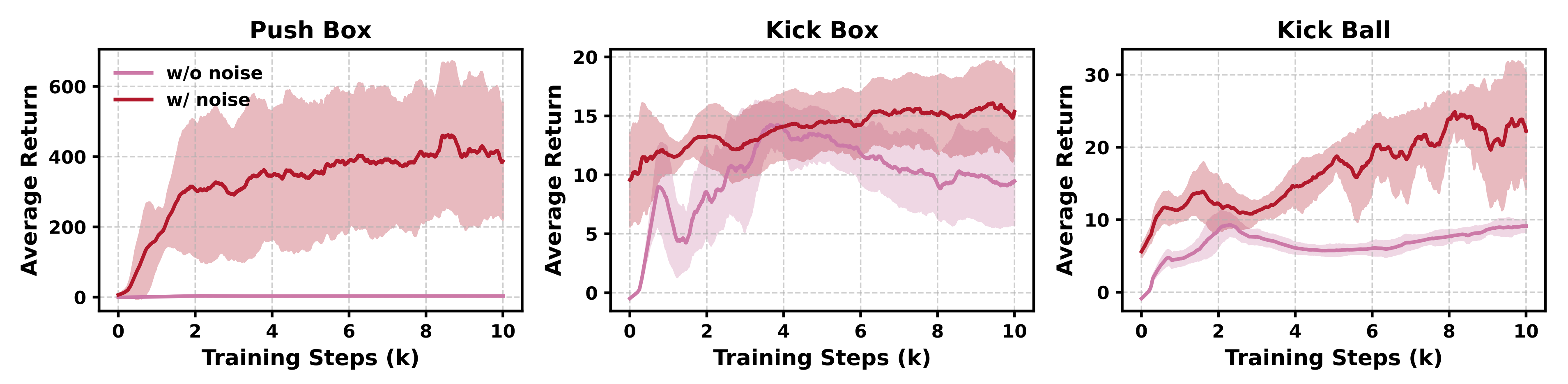
-
b) 高层策略的动作裁剪
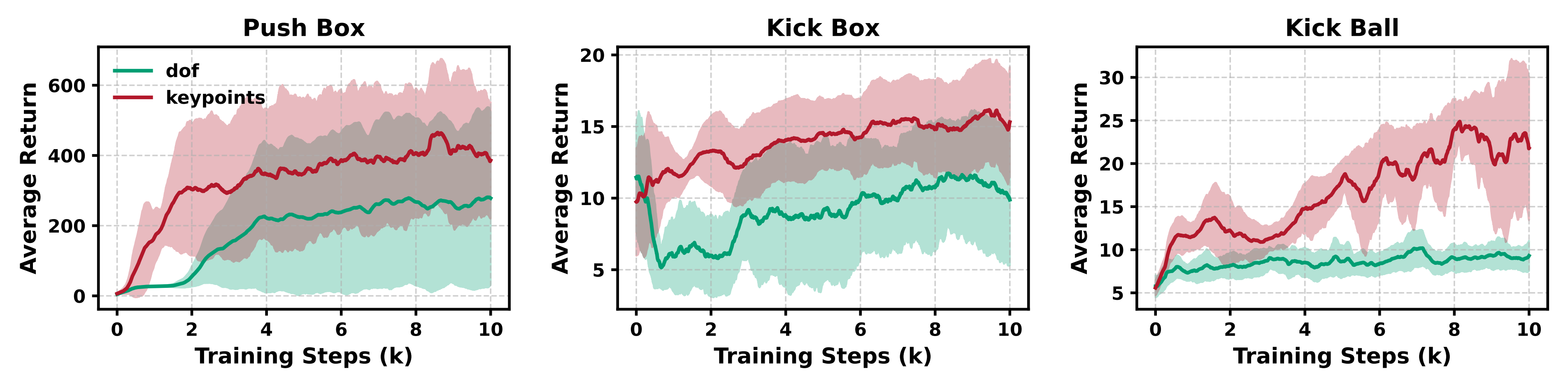
除了通过注入噪声提升鲁棒性外,作者还进一步对 π 生成器的输出进行正则化为此,作者首先利用低层策略输入归一化器估算 HMS 边界,然后对高层策略的输出施加动作裁剪,将其限制在该范围内
具体而言,每个输入维度被建模为高斯分布,高层策略的可行输出范围被定义为图 9b 显示,动作裁剪显著提升了关键点生成器训练的稳定性
1.2.4 实际环境部署
a) 基于视觉的仿真到现实迁移
-
作者观察到来自RealSense 摄像头的深度图像存在大量噪声
为减轻这一问题,作者对真实世界的深度图像应用了空间和时间滤波器以实现平滑
-
如图 8 所示,即使经过平滑处理,仿真与现实深度图像之间仍存在显著差距
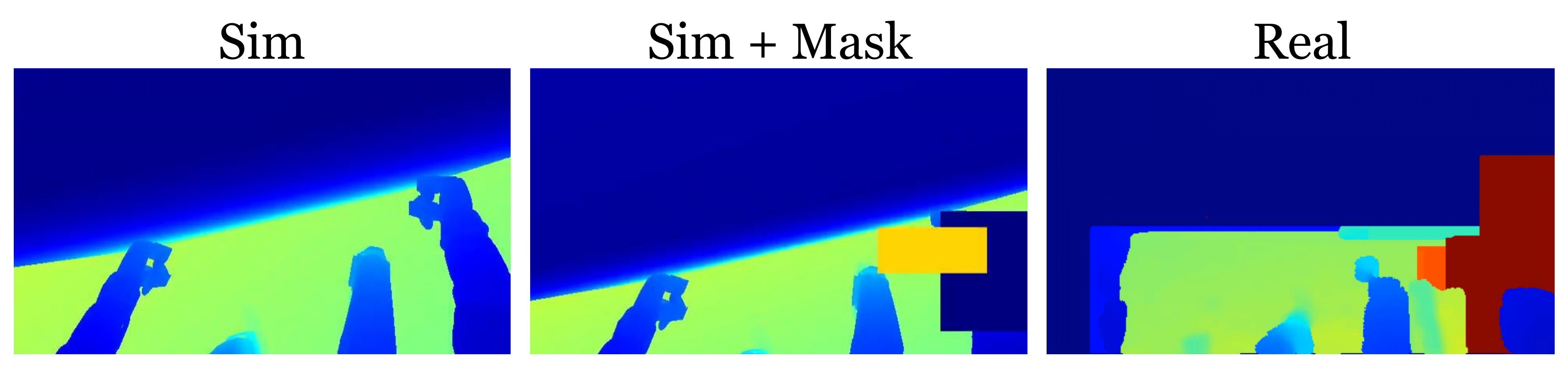
故,作者为了彻底解决该问题,他们在训练过程中大量采用随机遮罩,以更好地逼近真实世界的视觉噪声具体而言,他们以 20% 的概率应用固定的左下角白色遮罩,并分别以 10% 的概率最多添加六个独立采样的矩形遮罩。这些遮罩填充为白色、黑色或灰色,灰色值在 0 到 1 之间均匀采样。每个遮罩在 80×45分辨率的画面上最多覆盖 30×30 像素(占图像的25%)
如果不进行此类遮罩处理,机器人在部署时会表现出不稳定的行为。且他们还注意到,UnitreeG1 上的 RealSense 摄像头由于颈部未能牢固固定,存在轻微的角度漂移
为补偿这一影响,作者对机器人摄像头视角的朝向进行最多 ±5° 的随机扰动
b) 通过二进制指令实现安全的真实环境部署
在真实环境部署中,确保机器人在任务执行过程中能够安全地启动、暂停或结束至关重要,因为简单地终止程序可能导致机器人跌倒并受损
因此,作者引入了一个二进制指令信号(0 或 1),用于指示机器人暂停或执行任务。机器人可以在这两种状态之间自由切换,并且总是以暂停状态启动
且通过如下奖励设计来训练该行为:
- 当指令为 0 时,任务奖励被禁用
- 当指令为 1 时,暂停奖励被禁用。暂停奖励对应于跟踪静止站立的动作
两种指令的采样概率均为 50%
1.3 实验与分析
// 待更