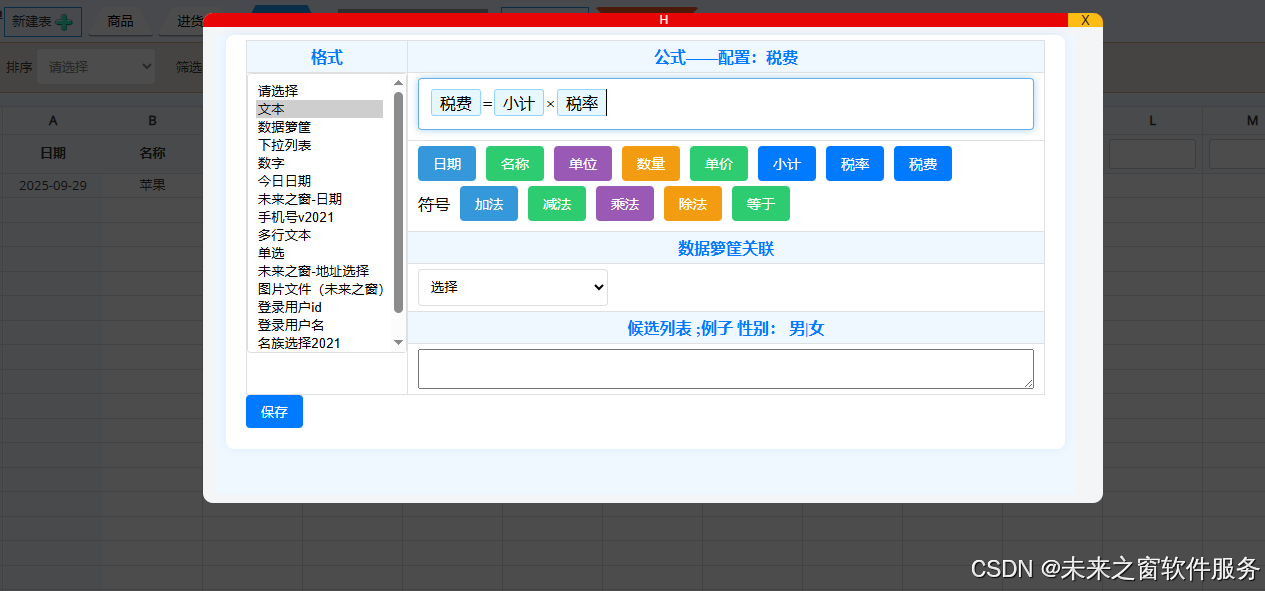
现有混合编辑器适配性分析(结合双向转化需求)
从你提供的编辑器代码来看,它已经具备 **"可视化插入字段 + 格式转换"** 的核心能力,与我们之前讨论的 "双向转化配置" 需求兼容性很高,无需重构,只需针对性扩展即可。以下是具体分析和适配建议:
一、现有编辑器的核心优势(可复用部分)
-
字段可视化插入 :通过按钮插入 "流水号 / 数量 / 单价" 等字段,生成带
data-fieldname(前端显示名)和data-param(数据库字段映射)的结构化部件(span.cm-field),这与我们之前设计的 "字段映射表" 完全匹配(前端显示名→数据库 param),无需重新开发字段选择逻辑。 -
双向格式转换基础:
- 正向转换:
saveEditorContent()能将 "文本 + 部件" 转为=fieldname格式(如 "金额 = 数量单价"→"= 金额 = = 数量 = 单价"),可扩展为生成 "中间配置模型"; - 反向转换:
renderExpression()能解析$param7=$param4*$param5这类表达式,还原为 "文本 + 部件",可扩展为解析 "中间配置模型" 并渲染界面。
- 正向转换:
-
部件完整性保护 :通过
handleDelete()阻止部件被拆分删除,确保字段选择的准确性(比如 "数量" 部件不会被拆成 "数" 和 "量"),这对后续生成正确 SQL 至关重要。
二、需扩展的功能(适配双向转化 + 统计配置)
现有编辑器聚焦 "单表达式编辑"(如 "金额 = 数量 * 单价"),但我们需要的是 "多指标统计配置"(如 "统计进货数量求和、分组分类、筛选日期"),需在现有基础上补充 3 类功能,且均能基于现有代码逻辑扩展:
1. 扩展 "统计指标配置区"(对应 SQL 的 SELECT)
需求:
用户需选择多个统计指标(如 "进货数量求和""库存数量"),每个指标需指定 "字段 + 计算方式"。
适配方案:
-
新增指标列表区:在编辑器上方新增 "统计指标" 列表,支持 "添加指标""删除指标";
-
复用现有字段选择:点击 "添加指标" 时,弹出现有编辑器的 "字段选择按钮"(流水号 / 数量等),用户选择字段后,再下拉选择 "计算方式"(求和 / 平均值 / 最大值,默认 "求和");
-
关联中间模型 :每添加一个指标,自动在 "中间配置模型" 的
statIndicators数组中新增一条记录,示例:json
{ "fieldKey": "in_quantity", // 从data-fieldname映射 "fieldName": "进货数量", // 编辑器选择的字段名 "calcType": "SUM", // 用户选择的计算方式 "dbLogic": "CASE WHEN table_sn='进货表SN' THEN param6 ELSE 0 END" // 从data-param+表SN映射 }
2. 扩展 "分组 / 筛选配置区"(对应 SQL 的 GROUP BY/WHERE)
需求:
用户需选择分组维度(如 "商品分类")和筛选条件(如 "日期介于 2025-01-01 至 2025-01-31")。
适配方案:
-
分组配置 :新增 "分组维度" 下拉框,选项从现有字段列表中获取(复用
data-fieldname和data-param),用户选择 "商品分类" 后,自动在中间模型的groupFields中添加记录:json
{ "fieldKey": "goods_category", "fieldName": "商品分类", "dbField": "param3" // 从data-param获取 } -
筛选配置 :新增 "筛选条件" 区域,点击 "添加条件" 时:
- 下拉选择字段(复用现有字段列表);
- 下拉选择条件("大于 / 小于 / 介于",根据字段类型过滤,如日期字段显示 "介于");
- 输入值(复用现有编辑器的文本输入,若为日期字段则弹出日期选择器);
- 自动在中间模型的
filters中添加记录:
json
{ "fieldKey": "stat_date", "fieldName": "统计日期", "condition": "BETWEEN", "value1": "2025-01-01", "value2": "2025-01-31", "dbLogic": "table_sn IN ('进货表SN','出货表SN') AND param4 BETWEEN #{value1} AND #{value2}" }
3. 扩展 "中间模型双向解析"(核心适配点)
现有编辑器的saveEditorContent()和renderExpression()需扩展为 "中间模型" 的双向解析,而非直接处理表达式:
(1)正向解析:用户配置→中间模型(替代原saveEditorContent())
- 点击 "保存配置" 时,遍历 "统计指标""分组""筛选" 三个区域的配置:
- 统计指标:从 "指标列表" 中读取每个指标的
fieldName(对应data-fieldname)、calcType,结合data-param生成dbLogic; - 分组维度:从 "分组下拉框" 中读取
fieldName和data-param,生成groupFields; - 筛选条件:从 "筛选区域" 中读取
fieldName、condition、value,结合data-param和表 SN 生成dbLogic;
- 统计指标:从 "指标列表" 中读取每个指标的
- 最终组装成完整的 "中间配置模型"(JSON 格式),提交到后端(后端再基于模型生成 SQL)。
(2)反向解析:中间模型→用户配置(替代原renderExpression())
- 用户打开已保存的配置时,后端返回 "中间配置模型",前端解析并还原界面:
- 统计指标:遍历
statIndicators,在 "指标列表" 中添加每条指标,自动选中对应的字段和计算方式; - 分组维度:遍历
groupFields,在 "分组下拉框" 中选中对应的字段; - 筛选条件:遍历
filters,在 "筛选区域" 中添加每条条件,自动填充字段、条件和值;
- 统计指标:遍历
- 整个过程无需解析 SQL,完全基于结构化的中间模型,确保还原准确性。
三、安全适配(防跨表 / 跨用户)
现有编辑器未涉及数据范围控制,需补充 2 点安全逻辑,且不影响用户操作:
- 字段权限过滤:后端返回给前端的 "可选字段列表",需先过滤当前用户无权限的字段(如普通用户看不到 "供应商 ID"),确保用户只能选择有权限的字段。
- 系统级条件隐藏 :中间模型中的
filters包含isSystem=true的系统条件(如user_id=当前用户、realm_sn=当前文件),前端不显示这些条件,仅在正向解析时自动添加到中间模型,用户无法修改。
四、总结:适配可行性
现有混合编辑器的核心架构(字段可视化、结构化部件、双向格式转换)完全可复用,仅需在以下 3 个层面扩展,即可适配 "双向转化 + 统计配置" 需求:
- 界面层:新增 "统计指标""分组""筛选" 三个配置区,复用现有字段选择逻辑;
- 逻辑层 :扩展
saveEditorContent()和renderExpression()为 "中间模型" 的双向解析; - 安全层:添加字段权限过滤和系统级条件隐藏。
扩展后既能保留编辑器原有的 "易用性"(用户全点击操作,无需懂 SQL),又能支撑我们之前设计的 "灵活统计 + 双向编辑 + 数据安全" 需求,开发成本低且兼容性高
阿雪技术观
让我们积极投身于技术共享的浪潮中,不仅仅是作为受益者,更要成为贡献者。无论是分享自己的代码、撰写技术博客,还是参与开源项目的维护和改进,每一个小小的举动都可能成为推动技术进步的巨大力量
Embrace open source and sharing, witness the miracle of technological progress, and enjoy the happy times of humanity! Let's actively join the wave of technology sharing. Not only as beneficiaries, but also as contributors. Whether sharing our own code, writing technical blogs, or participating in the maintenance and improvement of open source projects, every small action may become a huge force driving technological progrss.