性能优化
我们平时说性能优化是在说什么东西?
- 开发时态的构建速度优化: npm run dev 敲下的瞬间到呈现结果要占用多少时长
- webpack在这方面下的功夫是很重:
-
- webpack4 会用到 cache-loader, webpack5 提供了cache选项, 作用就是: 如果两次构建源代码没有产生变化,则直接使用缓存 不调用loader,
- thread-loader 开启多线程去构建
- vite 是按需加载,所以我们不需要太在意这方面
- 页面性能指标: 和我们怎么去写代码有关
- 首屏渲染时长: fcp (页面中第一个元素的渲染时长)
-
- 懒加载: 需要我们去写代码实现的
- 服务端渲染
- http优化: 协商缓存和强缓存
- 强缓存: 服务端给响应头追加一些字段(expires),客户端会记住这些字段,在expires(截止失效时间)没有到达之前,无论你怎么刷新页面,浏览器都不会重新请求页面,而是从缓存里取
- 协商缓存: 是否使用缓存要跟后端商量一下,当服务端给我们打上协商缓存的标记以后,客户端在下次刷新页面, 需要重新请求资源时会发送一个协商请求给到服务端,服务端如果说需要变化, 则会响应具体的内容,如果服务端觉得没变化则会响应304
- 页面最大元素的一个时长: lcp (largest content paint)
- js逻辑
-
我们要注意副作用的清除, 组件是会频繁的挂载和卸载: 如果我们在某一个组件中有计时器(setTimeout),如果我们在卸载的时候不去清除这个计时器,下次再次挂载的时候计时器等于开了两个线程
经常看到这样的react代码
const [timer,setTimer]=useState(null);
userEffect(()=>{
setTimer(setTimeout(()=>{}));
return()=>clearTimeout(timer);
}) -
我们再写法上一个注意事项: requestAnimationFrame,requestIdleCallback 这两个API卡浏览器帧率 对浏览器渲染原理要有一定的认识 然后再这方面做优化
-
- requestIdleCallback: 传一个函数进去, 这个函数会在js逻辑和重排重绘完成之后执行
- 浏览器的帧率:16.6ms去更新一次(执行js逻辑 以及重排重绘..),假设我的js执行逻辑超过了16.6, 重排重绘的时间就会被挤占, 就会出现掉帧
-
防抖节流,要使用lodash.js, 自己写的通常不是最佳实践
-
对于大量循环, 不使用 Array.prototype.forEach()方法, 使用lodash.js提供的forEach()方法
-
对于作用域的控制
const arr = [1,2,3]
for(let i=0, len=arr.length; i<len; i++) {
}
- css
- 关注继承属性: 能继承的旧不要重复写
- 尽量避免太过于深的css嵌套
- 构建优化: vite(rollup) webpack
- 优化体积: 代码压缩,treeshaking,图片资源压缩,cdn加载,分包
分包策略
-
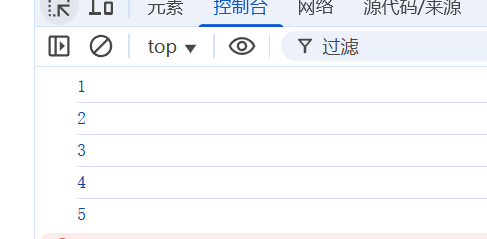
使用odash, 完成一个简单的循环任务, 然后查看打包结果
npm install lodash
import { forEach } from "lodash";
const arr = [1, 2, 3, 4, 5]
forEach(arr, (item) => {
console.log(item);
})
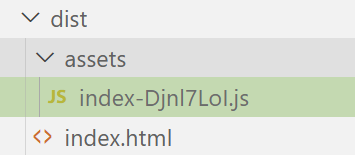
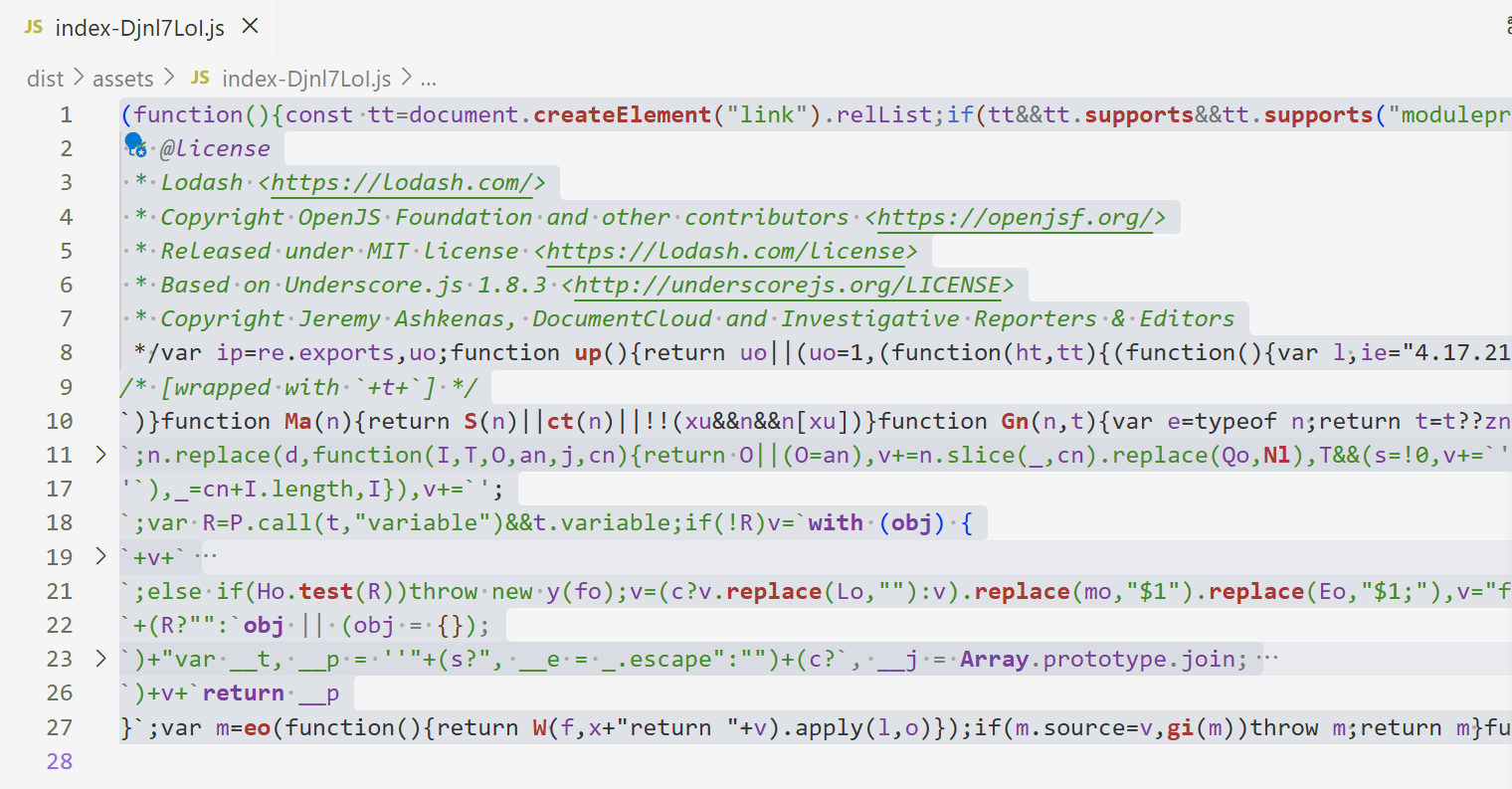
-
打包后的代码是经过压缩的, 很难阅读, 我们配置一下不压缩
import { defineConfig } from "vite"
import check from "vite-plugin-checker"export default defineConfig({
"build": {
"minify": false
},
plugins: [check({
typescript: true
})]
}) -
再打包看结果, 业务代码和工具代码被打包在一起了, 这样并不是最好的方式, 因为业务代码经常变动, 工具代码基本不变, 从浏览器缓存这个角度考虑, 把不会常规更新的文件单独打包处理, 可以让浏览器更好的复用缓存资源, 减少HTTP传输压力
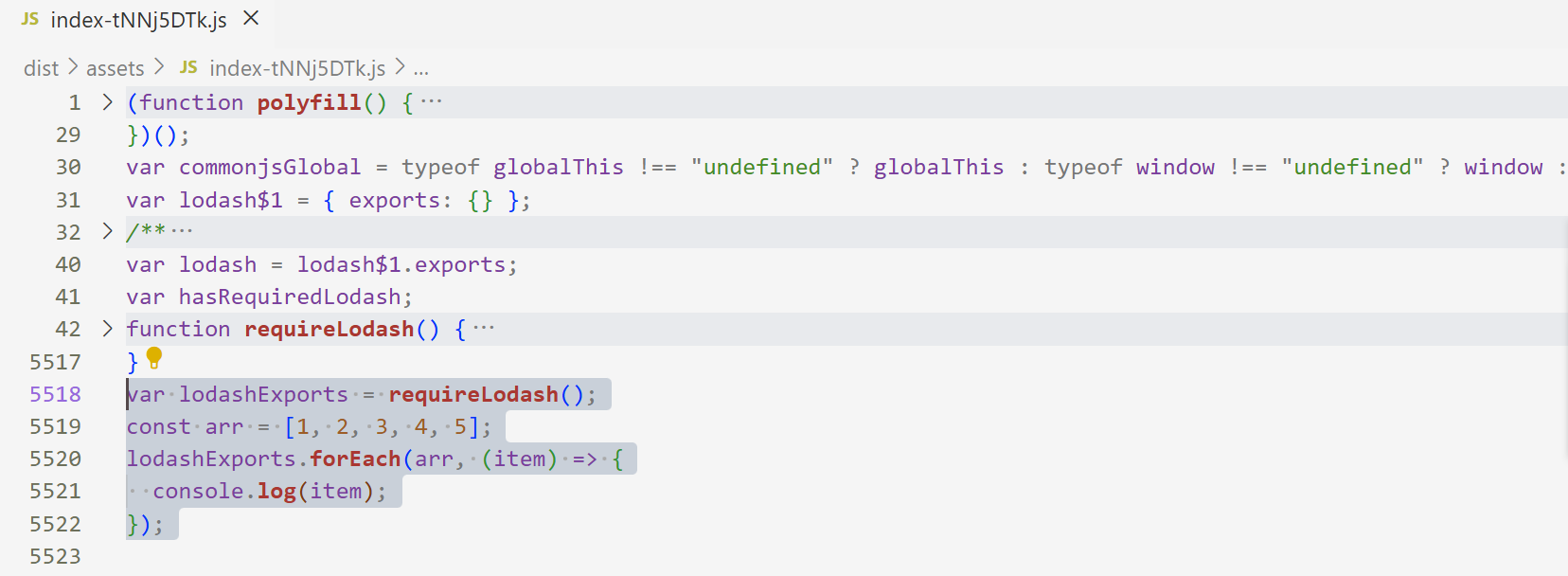
-
这样去配置
import { defineConfig } from "vite"
import check from "vite-plugin-checker"export default defineConfig({
"build": {
"minify": false,
"rollupOptions": {
"output": {
"manualChunks": (id: string) => {
console.log("id:", id); // 拿到工程中所有的文件路径
/**
* 这是一个简单处理:
* 1.所有路径包含node_modules的文件我们都认为是工具包
* 2.所有工具包都打包到 vendor-随机哈希值 文件中
* 3.报错: includes()这个方法是es6之后的方法, ts默认工程环境是es5, 所以要配置一下
*/
if (id.includes("node_modules")) {
return "vendor";
}
}
}
}
},
plugins: [check({
typescript: true
})]
})// 配置一些ts的检查手段和规则
{
"compilerOptions": {
"moduleResolution": "node", // 模块解析方案
"skipLibCheck": true, // 忽略对node_modules目录的检查
"module": "ESNext", // 编译为最新的ES语法
"lib": [ // 配置ts工程环境是es7
"ES2017",
"DOM"
]
}
} -
重新打包, 业务代码和工具代码分在不同包, 这样用户就可以更多的使用vendor.js缓存, index.js传输体积也会更小

gzip压缩
- 有时候我们的文件资源实在是太大了
- js文件 ---> 打包后2000kb --->http传输压力大
- 将所有的静态文件进行压缩,已达到减少体积的目的
- vite服务端 -> 执行打包 --> 压缩文件 -> 得到压缩过的打包结果
- 客户端请求资源 -> 收到压缩包资源 --> 浏览器解压缩 --> 得到原始资源 -> 渲染
-
使用打包插件
npm install vite-plugin-compression
import { defineConfig } from 'vite'
import viteCompression from 'vite-plugin-compression'export default defineConfig({
plugins: [
viteCompression()
]
})
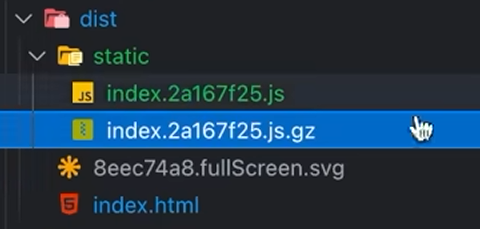
- 浏览器不能直接渲染压缩后的资源
- 用户请求 index.html, 服务端返回 index.js.gz
- 当服务端读取到gzip文件 (.gz后缀), 就要设置一个响应头 (content-encoding: gzip)
- 代表告诉浏览器该文件是使用gzip压缩过的
- 浏览器收到响应结果 发现响应头里有gzip对应字段,赶紧解压, 得到原来原原本本的js文件 (浏览器是要承担一定的解压时间的)
- 如果体积不是很大的话 不要用gzip压缩
动态导入
- 动态导入的作用和按需加载的作用是差不多的
- 按需加载: 一个文件导出了很多方法, 用到哪个方法就导入哪个方法, 不要把整个文件都引入进来
- 动态导入: 一个工程会有很多文件, 当前页面用到哪些文件就去解析对应文件, 不要把所有文件都解析完
- vite和webpack实现动态导入的方式是不一样的
-
vite使用的es6提供的动态导入技术 (新特性)
// 静态导入
import "./src/imageLoader"// 动态导入(es6新特性)
// import函数始终返回一个Promise
import("./src/imageLoader").then(data => {
log(data)
})// 动态导入典型的应用场景是路由
const Home = () => import('@/view/home')
// 挂载页面
router: [
{path: '/', component: Home}
] -
webpack是自己封装的动态导入方法
function import(path) {
//resolve不被调用的话 Promise永远是pending状态
return new Promise((resolve)=>{
//进入到对应路由时将webpack_require.e这个promise的状态设置为fullfilled (调用resolve)
//如果我从来没进入过home页面,我就让这个webpack_require.e永远在悬停(pending)状态
webpack__require.e().then(()=>{
const result = await webpack__require(path)
})
})
}// 核心思想
// 当没有进入过某个页面或者组件的时候,我们让这个组件的代码放入一个script标签里 但是这个script标签不塞入到body里去
// 当进入这个页面时,我们将script标签塞入到整个body里去
// 动态导入的文件会不会被webpack编译???? 肯定是会被编译
// 动态导入的文件会不会被加载?? 不会,用到了才会加载
cdn加速
- cdn全称 content delivery network (内容分发网络)
- 我们的所有依赖以及源码文件在我们进行打包以后(yarn build)会放到我们的服务器上面去
- 我的服务器在深圳, 你在纽约访问我这个网站, 由于网络传输距离太远, 就会有点卡
- 典型情况, 就是不翻墙的情况下, 访问没有被封的网站, 比如github, 普遍就很慢
- cdn加速就是将我们依赖的第三方模块全部写成cdn的形式,就近加载, 提高速度
- 并且也让我们自身的代码体积变小了, 服务器和客户端的传输就更轻松 (依赖的lodash是通过cdn加载的, 源码自身的体积也就变小了)
- 搭建基础工程
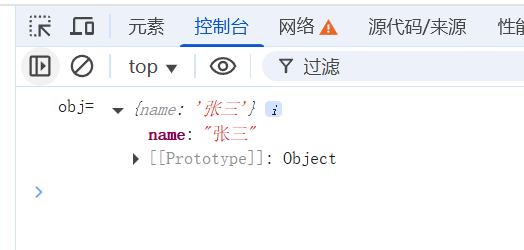
import _ from "lodash"
const obj = _.cloneDeep({
name: "张三"
})
console.log("obj=", obj);
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
</head>
<body>
<script src="./src/main.js" type="module"></script>
</body>
</html>
npm init -y
npm install lodash
{
"name": "05vite-cnd",
"version": "1.0.0",
"main": "index.js",
"scripts": {
"dev": "vite",
"test": "echo \"Error: no test specified\" && exit 1"
},
"keywords": [],
"author": "",
"license": "ISC",
"description": "",
"dependencies": {
"lodash": "^4.17.21",
"vite": "^7.1.4"
}
}
-
在工程中使用cnd插件实现优化
npm install vite-plugin-cdn-import -D
import { defineConfig } from "vite";
import viteCDNPPlugin from "vite-plugin-cdn-import"export default defineConfig({
plugins: [
viteCDNPPlugin({
modules: [{
name: "lodash",
var: "_",
path: "https://cdn.jsdelivr.net/npm/lodash@4.17.21/lodash.min.js"
}]
})
]
}) -
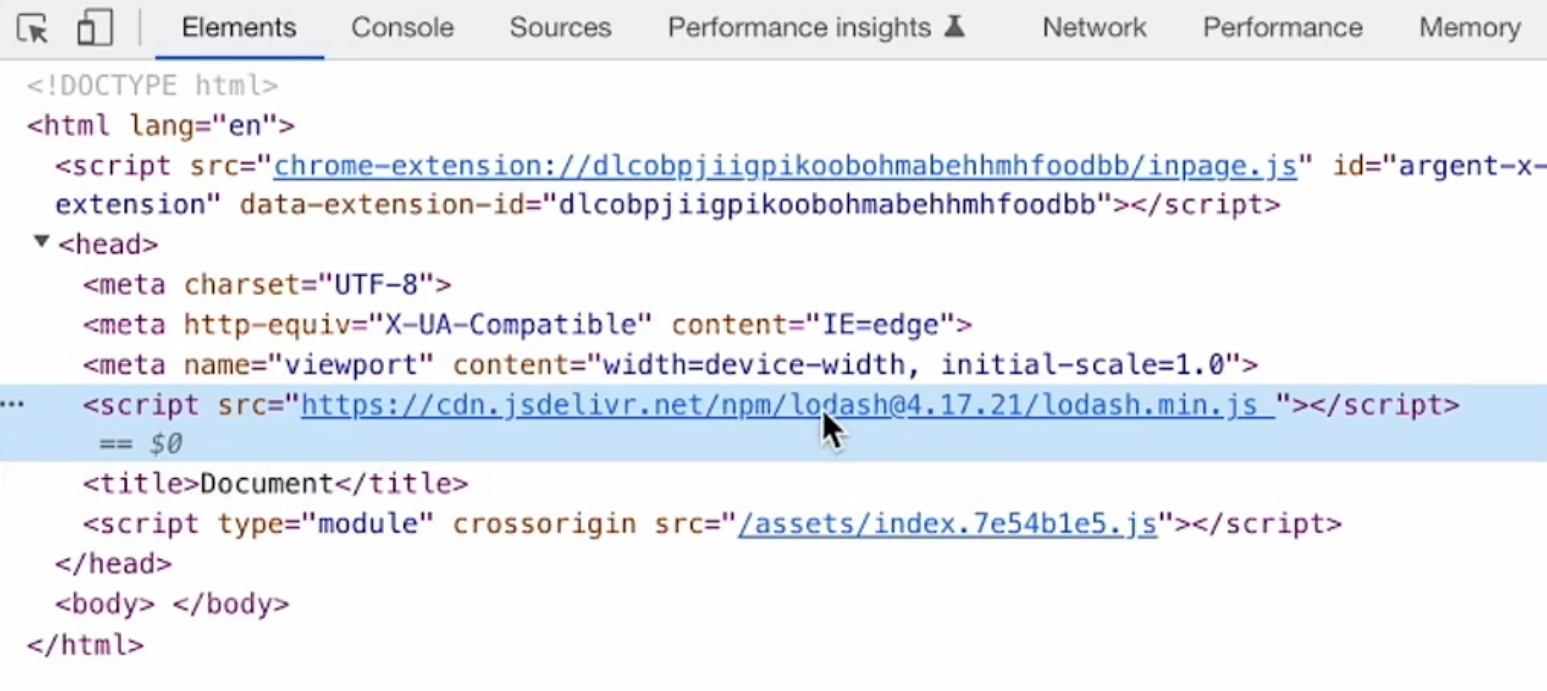
打包工程, 打包后的文件中不再有loadsh的内容, 而是通过cnd就近分发给用户

- 插件的原理
- 区分工程环境, 开发环境不工作, 生产环境的话就开始做事情
- 往head中注入script标签, 引用第三方库
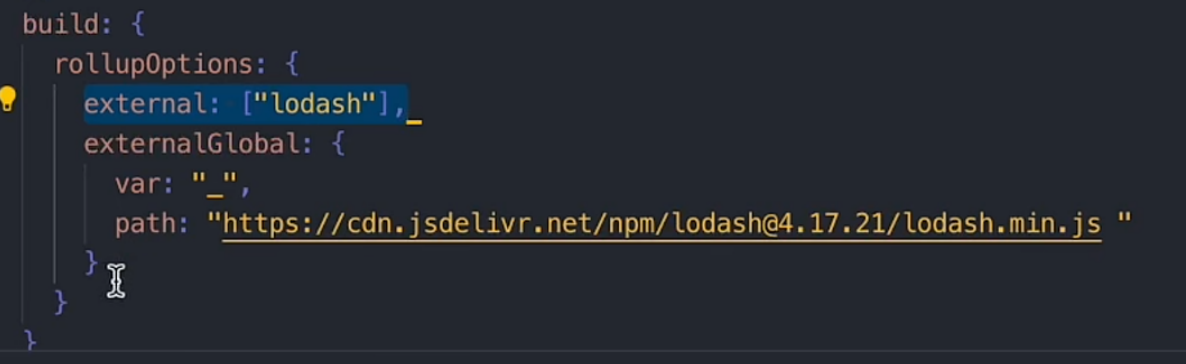
- 因为vite生产环境的打包使用rollup, 所以还会修改一下rollup的配置, 类似于下面的效果
配置跨域
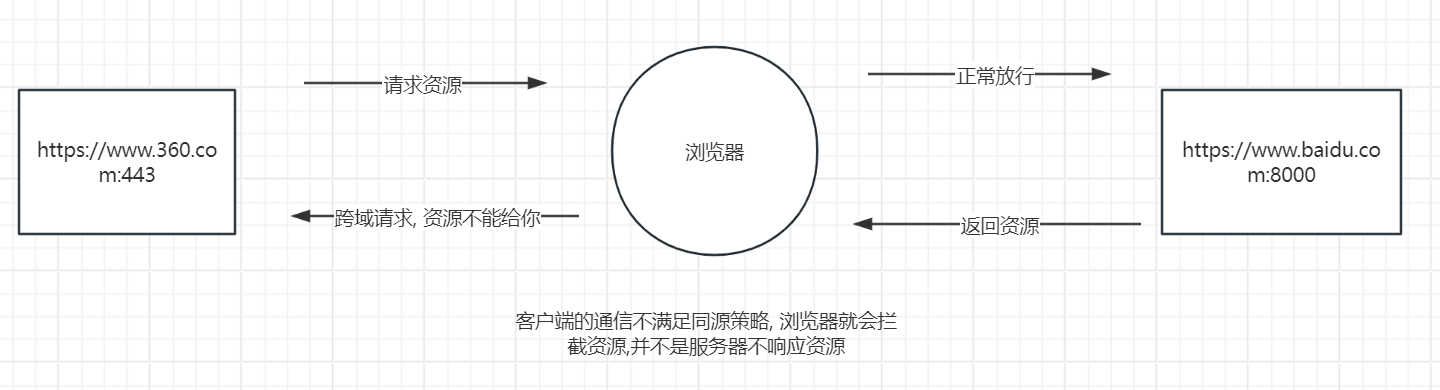
- 同源策略
http交互默认情况下只能在同协议同域名同端口的两台终端进行通信
- 什么是跨域
跨域【仅发生在浏览器】: 当A源浏览器的网页 向 B源的服务器地址(不满足同源策略,满足同源限制) 请求对应信息,就会产生跨域,跨域请求默认情况下会被浏览器拦截,除非对应的请求服务器出具标记说这个A源是值得信任的
- 跨域解决方案
开发时态
-
我们一般就利用构建工具或者脚手架或者第三方库的proxy 代理配置
import { defineConfig }from "vite";
export default defineConfig({
server:{ //开发服务器中的配置
proxy:{ // 配置跨域解决方案
"/api":{
target:"https://www.360.com", // 目标地址
changeOrigin: true,// 要换源
rewrite:(path)=> path.replace(/^/api/,'') // 路径重写
}
}
}
}) -
或者我们自己搭一个开发服务器来解决这个问题
// vite服务器处理跨域的伪代码
if(ctx.request.url.includes("/api")) {
const target =proxy.target;
const rewrite = str => str
const result =await request(target + rewrite("/api"));
ctx.response.body = result;
}// 基本原理
// 1.前端启动本地vite服务
// 2.前端请求基地址都使用127.0.0.1
// 3.所以的请求都会打到我们自己的vite服务
// 4.使用服务端去请求资源, 然会返回给前端
// 5.本质就是通过vite服务转发请求, 绕过同源策略
生产时态: 我们一般是交给后端去处理跨域
-
nginx代理服务
-
配置身份标记
Access-Control-Allow-Origin: 被信任的朋友, 被标记的域名不再受同源策略限制
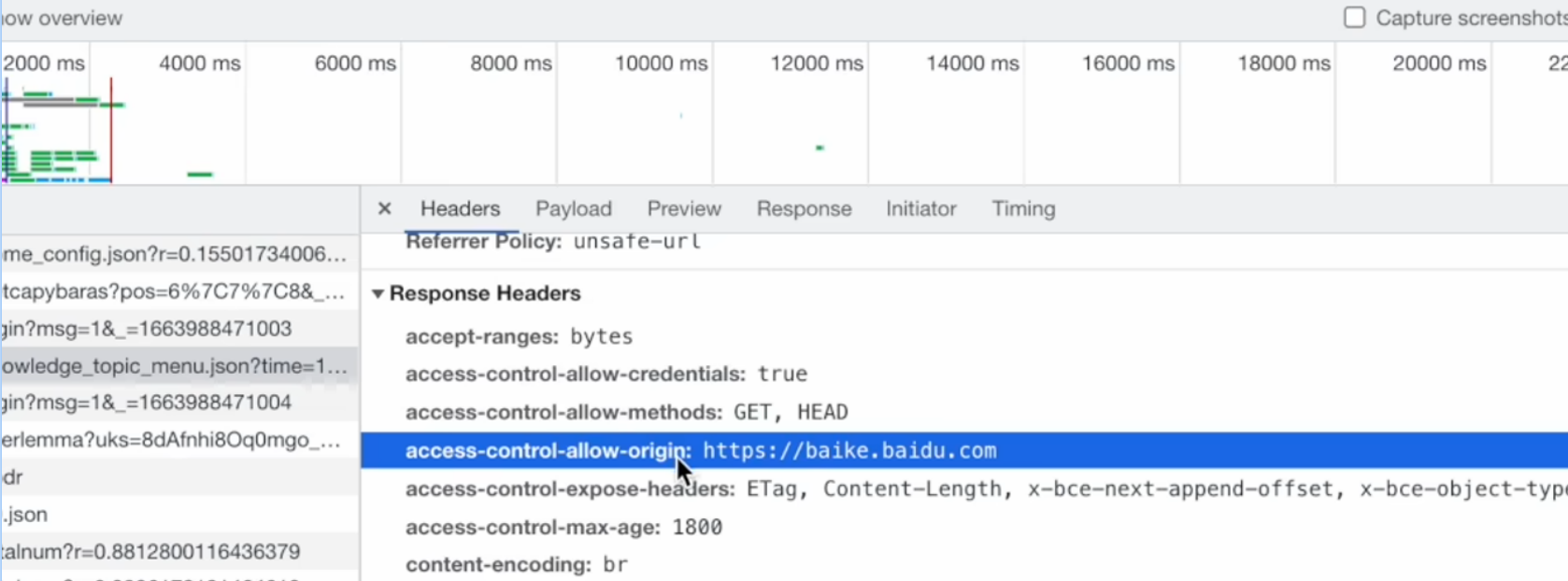
// 声明服务器支持范围请求(Range Requests), 客户端可请求资源的部分内容(如大文件分块下载、断点续传)
accept-ranges:bytes
access-control-allow-credentials: true // 允许跨域请求携带凭证信息(如Cookies、HTTP认证)
access-control-allow-methods:GET,HEAD // 允许的跨域请求的方法
access-control-allow-origin: https://baike.baidu.com // 指定允许跨域访问的源(Origin)
// 暴露自定义响应头给浏览器, 使客户端可通过JavaScript(如response.headers)读取这些头信息
access-control-expose-headers: ETag, Content-Length, x-bce-next-append-offset,x-bce-object-type, x-bce-request-id
// 设置CORS预检请求(OPTIONS)的缓存时间。在30分钟内,相同请求的跨域预检结果可被缓存,无需重复发送OPTIONS请求,减少网络开销。
access-control-max-age:1800public
我们可以在项目根目录创建一个public目录, 这里面的资源不会经过vite打包处理, 直接放到dist结果中
const img = import("/public/morgan.png")
console.log("img=", img);
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
</head>
<body>
<img src="/public/morgan.png" alt="">
<script src="./src/main.js" type="module"></script>
</body>
</html>
- 也不是经常使用, 因为尽量让资源都经过vite处理, 这样会有一些压缩优化
- 如果有资源确实不需要vite处理, 就放在里面挺合适