本文基于实战项目,手把手教你微调 Qwen2.5-Coder 进行中文情感分析。使用冻结训练方法,在 T4 GPU 上 15-30 分钟完成训练,准确率从 91.6% 提升到 97.8%!

🎯 项目简介
本项目使用Freeze Training 方法微调 Qwen2.5-Coder-1.5B-Instruct 模型,用于中文情感分析:
-
🎯 任务:二分类情感分析(正面/负面)
-
📊 数据集:ChnSentiCorp(中文情感语料)
-
🔧 方法:冻结训练(仅训练最后6层)
-
💾 模型大小:15亿参数
-
⏱️ 训练时间:T4 GPU 上 15-30 分钟
-
📈 性能提升 :准确率从 91.6% 提升到 97.8%(+6.2%)
什么是冻结训练?
冻结训练是一种参数高效的微调方法:
-
✅ 冻结大部分模型层
-
✅ 只训练最后几层 + 词嵌入层
-
✅ 训练时间减少 60-70%
-
✅ GPU 显存占用减少 40-50%
-
✅ 达到完整微调 85-95% 的效果
适用场景:计算资源有限、快速实验、领域适配
🚀 快速开始
方式一:Google Colab(推荐)
适合:初学者、无需本地 GPU、免费 T4 GPU
-
点击顶部的 Colab 徽章
-
Runtime → Change runtime type → GPU (T4)
-
点击"连接"以分配 T4 GPU 运行环境
在 Google Colab 中连接到 T4 GPU
-
运行所有单元格(Runtime → Run all)
-
等待 30-40 分钟完成整个流程
要求:Google 账号(免费)
方式二:本地运行
适合:有经验的用户、多次运行、自定义修改
bash
# 克隆仓库
git clone https://github.com/IIIIQIIII/MSJ-Factory.git
cd MSJ-Factory
# 安装依赖
pip install -e .[torch,bitsandbytes,vllm]
# 开始训练
llamafactory-cli train examples/train_freeze/qwen2_5_coder_freeze_3k.yaml
# 评估模型
python scripts/eval_sentiment_compare.py系统要求:
-
Python 3.10+
-
CUDA 11.8+ / 12.1+
-
GPU:16GB+ 显存(T4、V100、A100 等)
-
磁盘:10GB 可用空间
📚 完整教程
步骤1:克隆项目仓库
作用:下载完整的项目代码到你的环境
bash
!git clone --depth 1 https://github.com/IIIIQIIII/MSJ-Factory.git
%cd MSJ-Factory
点击播放图标运行 Colab 单元格并克隆仓库
预期输出:
bash
Cloning into 'MSJ-Factory'...
remote: Enumerating objects: 368, done.
remote: Counting objects: 100% (368/368), done.
Receiving objects: 100% (368/368), 6.08 MiB | 11.88 MiB/s, done.验证安装:
bash
!ls -lh
# 你应该看到:data/、examples/、scripts/、src/ 等目录🔍 仓库里有什么?
-
data/:训练和测试数据集 -
examples/:训练配置文件 -
scripts/:评估和工具脚本 -
src/:核心库代码 -
contexts/:文档和指南
步骤2:安装依赖
作用:安装 PyTorch、Transformers、vLLM 等必需库
bash
!pip install -e .[torch,bitsandbytes,vllm]
点击播放图标运行 Colab 单元格并安装依赖
安装时间:3-5 分钟
验证安装:
python
import torch
import vllm
# 检查 PyTorch
print(f'PyTorch: {torch.__version__}')
print(f'CUDA: {torch.cuda.is_available()}')
# 检查 vLLM
print(f'vLLM: {vllm.__version__}')预期输出:
vbnet
PyTorch: 2.5.0+cu121
CUDA: True
vLLM: 0.10.0🐛 故障排除:安装问题
问题1:CUDA 不可用
bash
# 安装支持 CUDA 的 PyTorch
!pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121问题2:安装时内存不足
bash
# 使用 --no-cache-dir
!pip install --no-cache-dir -e .[torch,bitsandbytes,vllm]问题3:vLLM 安装失败
bash
# 跳过 vLLM(训练时可选)
!pip install -e .[torch,bitsandbytes]步骤3:模型微调
作用:在 3000 个平衡的情感样本上微调 Qwen2.5-Coder
3.1 理解训练配置
配置文件:examples/train_freeze/qwen2_5_coder_freeze_3k.yaml
yaml
### 模型
model_name_or_path: Qwen/Qwen2.5-Coder-1.5B-Instruct # 基础模型
trust_remote_code: true
### 方法
stage: sft # 监督微调
finetuning_type: freeze # 冻结训练方法
freeze_trainable_layers: 6 # 训练最后 6 层
freeze_extra_modules: embed_tokens,norm
### 数据集
dataset: sentiment_balanced_3k # 3000 样本(1500 正 + 1500 负)
template: qwen
cutoff_len: 720
max_samples: 10000
### 训练参数
per_device_train_batch_size: 1 # 每个 GPU 的批次大小
gradient_accumulation_steps: 8 # 有效批次 = 1 × 8 = 8
learning_rate: 2.0e-5
num_train_epochs: 2.0
lr_scheduler_type: cosine
warmup_ratio: 0.1
bf16: true # 使用 BF16 精度
### 评估
val_size: 0.2 # 20% 验证集
eval_strategy: steps
eval_steps: 200
compute_accuracy: true3.2 开始训练
bash
!llamafactory-cli train examples/train_freeze/qwen2_5_coder_freeze_3k.yaml
点击播放图标运行 Colab 单元格并开始模型训练
训练进度:
yaml
🚀 开始训练...
📊 总轮数:2
⏱️ 预计时间:15-30 分钟
Epoch 1/2: [████████████████████] 100% | Loss: 0.1234
Epoch 2/2: [████████████████████] 100% | Loss: 0.0567
✅ 训练完成!
📁 模型保存至:saves/qwen2_5-coder-1.5b/freeze/sft/3.3 训练指标
| 指标 | 数值 |
|---|---|
| 总步数 | ~375 步 |
| 训练损失 | 0.05 - 0.15 |
| 验证准确率 | 95%+ |
| GPU 显存 | ~8-10 GB |
| 训练时间 | 15-30 分钟 |
📊 理解训练日志
关键指标:
-
Loss(损失):应从 ~0.5 降至 ~0.05
-
Accuracy(准确率):应提升至 95%+
-
GPU 显存:在 T4 上应保持在 12GB 以下
正常现象:
-
训练初期损失可能波动
-
第二个 epoch 准确率提升
-
一些 TensorFlow 警告是正常的(可忽略)
警告信号:
-
损失上升或保持在高位(>0.3)
-
训练后准确率低于 90%
-
CUDA 内存溢出错误
🎛️ 高级:自定义训练
训练更多轮次(更好的质量):
yaml
num_train_epochs: 3.0 # 从 2.0 改为 3.0训练更多层(更多适配):
yaml
freeze_trainable_layers: 12 # 从 6 改为 12使用更大的批次(如果有更多显存):
yaml
per_device_train_batch_size: 2 # 从 1 改为 2
gradient_accumulation_steps: 4 # 从 8 改为 4训练不同数据集:
yaml
dataset: your_dataset_name # 必须在 data/dataset_info.json 中注册步骤4:模型评估
作用:对比基础模型与微调后模型的性能
bash
!python scripts/eval_sentiment_compare.py \
--csv_path data/ChnSentiCorp_test.csv \
--base_model Qwen/Qwen2.5-Coder-1.5B-Instruct \
--finetuned_model saves/qwen2_5-coder-1.5b/freeze/sft \
--output_file data/sentiment_comparison_results.json
点击播放图标运行 Colab 单元格并评估模型
评估时间:5-10 分钟
预期输出:
erlang
📊 ChnSentiCorp 情感分析 - 微调前后对比
======================================================================
🔍 评估模型:基础模型(微调前)
======================================================================
总样本数:179
准确率:91.62%
精确率:98.57%
召回率:83.13%
F1分数:90.20%
======================================================================
🔍 评估模型:微调后模型
======================================================================
总样本数:179
准确率:97.77%
精确率:100.00%
召回率:95.18%
F1分数:97.53%
🎯 性能对比
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
指标 微调前 微调后 提升 提升率
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
准确率 91.62% 97.77% ↑ 6.15% 6.71%
精确率 98.57% 100.00% ↑ 1.43% 1.45%
召回率 83.13% 95.18% ↑ 12.05% 14.50%
F1分数 90.20% 97.53% ↑ 7.33% 8.13%
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
💾 结果已保存至:data/sentiment_comparison_results.json4.1 理解评估指标
| 指标 | 含义 | 目标 |
|---|---|---|
| 准确率(Accuracy) | 整体正确率 | 95%+ |
| 精确率(Precision) | 预测为正的样本中实际为正的比例 | 95%+ |
| 召回率(Recall) | 实际为正的样本中被正确识别的比例 | 90%+ |
| F1分数(F1-Score) | 精确率和召回率的调和平均 | 95%+ |
4.2 混淆矩阵
scss
预测为负面 预测为正面
实际负面 TN (91) FP (5)
实际正面 FN (4) TP (79)-
真负例(TN):91 - 正确识别的负面样本
-
假正例(FP):5 - 负面样本被错误分类为正面
-
假负例(FN):4 - 正面样本被错误分类为负面
-
真正例(TP):79 - 正确识别的正面样本
📈 在自定义文本上快速测试
创建测试脚本 test_sentiment.py:
python
from transformers import AutoModelForCausalLM, AutoTokenizer
model_path = "saves/qwen2_5-coder-1.5b/freeze/sft"
tokenizer = AutoTokenizer.from_pretrained(model_path)
model = AutoModelForCausalLM.from_pretrained(model_path, device_map="auto")
text = "这个酒店的服务态度非常好,房间也很干净!" # 正面例子
prompt = f"""请对以下中文文本进行情感分析,判断其情感倾向。
任务说明:
- 分析文本表达的整体情感态度
- 判断是正面(1)还是负面(0)
文本内容:
```sentence
{text}输出格式:
json
{{
"sentiment": 0 or 1
}}
```"""
messages = [{"role": "user", "content": prompt}]
text_input = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
model_inputs = tokenizer([text_input], return_tensors="pt").to(model.device)
generated_ids = model.generate(**model_inputs, max_new_tokens=256, temperature=0.1)
response = tokenizer.batch_decode(generated_ids[:, model_inputs.input_ids.shape[1]:], skip_special_tokens=True)[0]
print(response) # 输出:{"sentiment": 1}步骤5:上传到HuggingFace
作用:与社区分享你的微调模型
5.1 获取 HuggingFace Token
按照以下步骤创建你的 HuggingFace 访问令牌:
步骤1:点击右上角的个人头像
步骤2:进入 Settings → Access Tokens
步骤3:输入密码验证身份
步骤4:点击 "+ Create new token"
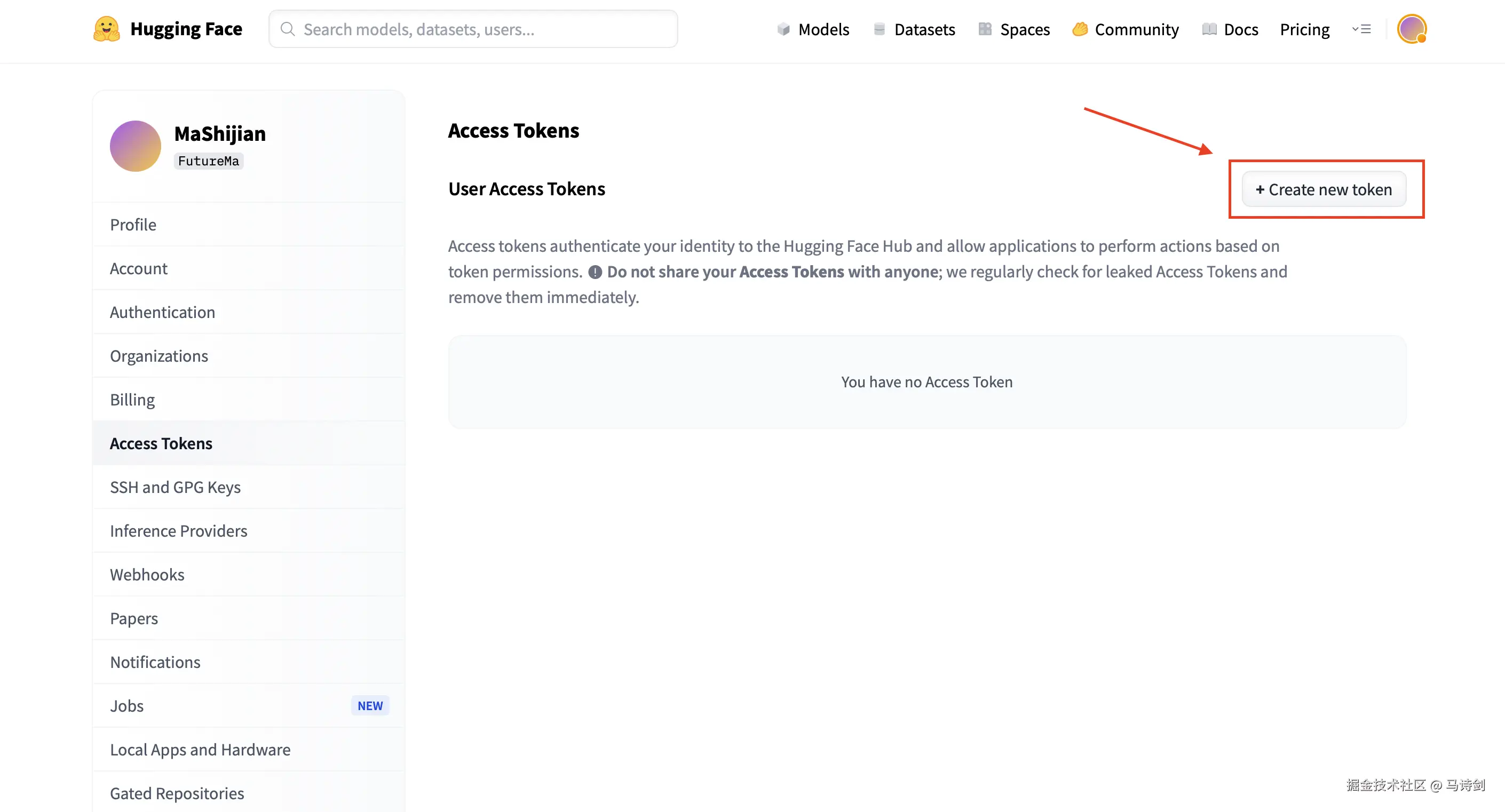
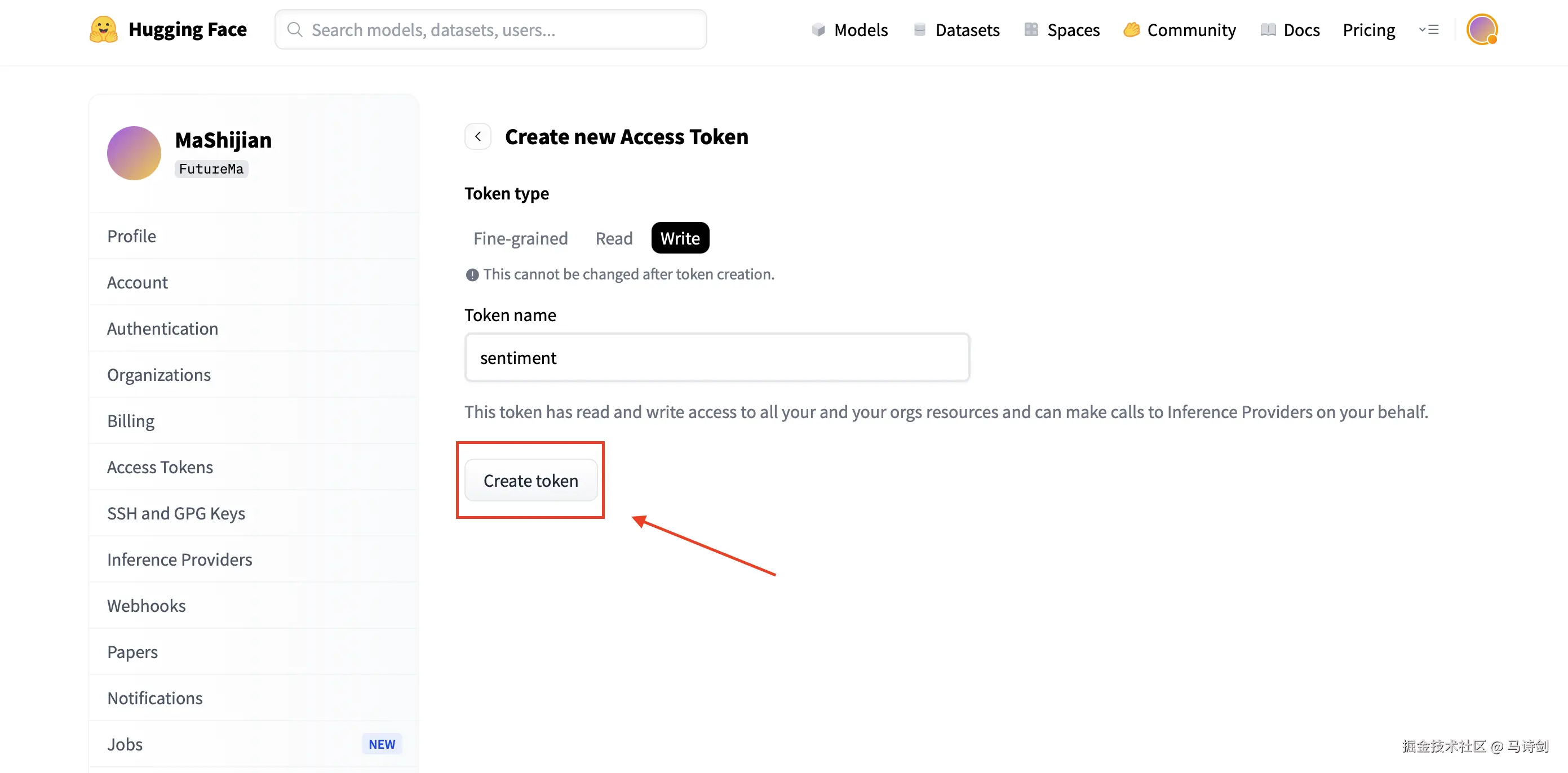
步骤5:命名令牌,选择 "Write" 角色,然后点击 "Create token"
步骤6 :复制你的访问令牌(以 hf_ 开头)
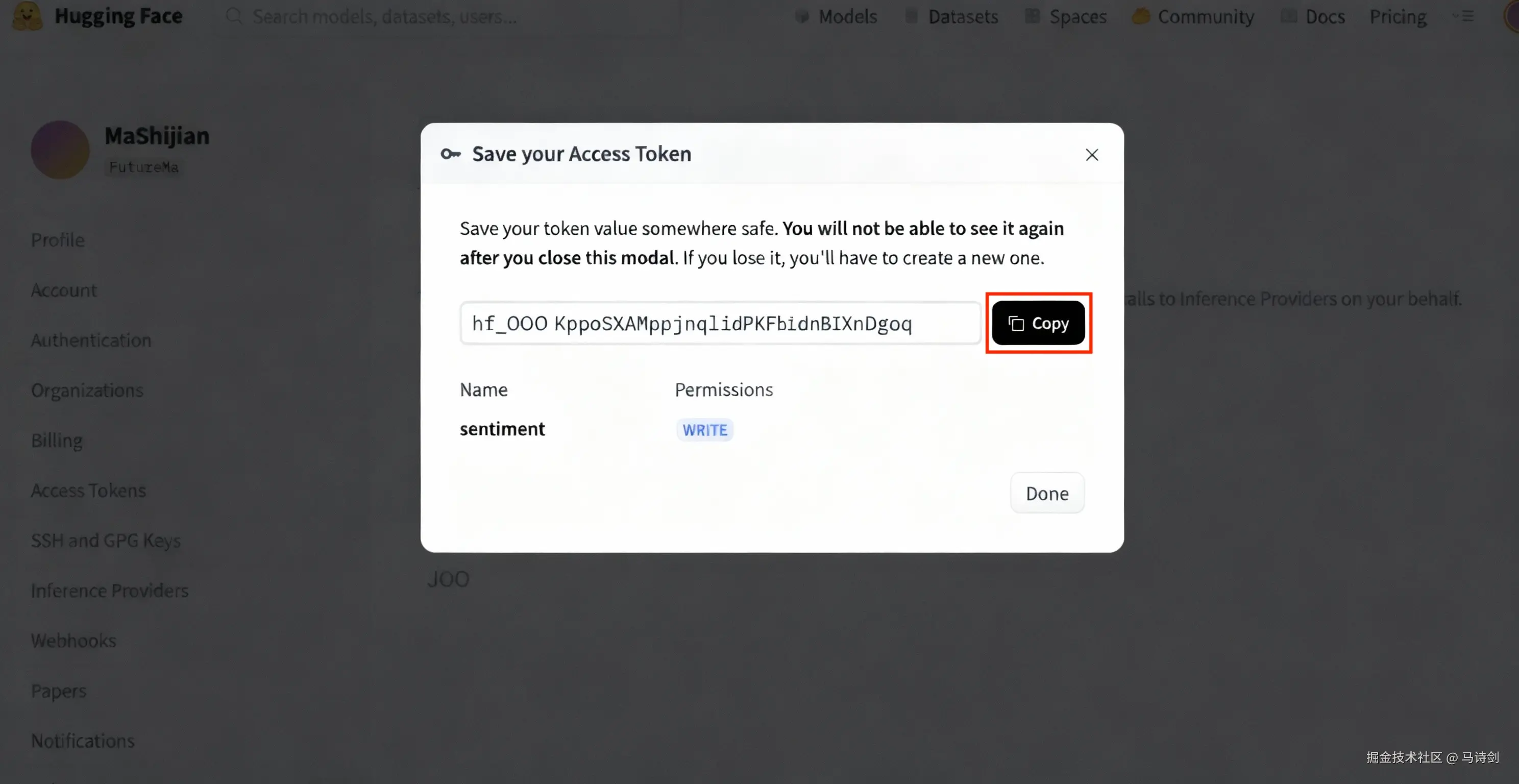
⚠️ 重要提示:请安全保存你的令牌,之后将无法再次查看!
5.2 上传模型
python
from huggingface_hub import HfApi, login
# 登录
login(token="hf_YOUR_TOKEN_HERE") # 替换为你的 token
# 上传
api = HfApi()
api.create_repo(repo_id="YourUsername/Qwen2.5-Coder-Sentiment", private=False)
api.upload_folder(
folder_path="saves/qwen2_5-coder-1.5b/freeze/sft",
repo_id="YourUsername/Qwen2.5-Coder-Sentiment",
commit_message="上传冻结训练的 Qwen2.5-Coder 情感分析模型"
)
print("✅ 模型已上传!")
print("🔗 https://huggingface.co/YourUsername/Qwen2.5-Coder-Sentiment")5.3 使用已上传的模型
其他人现在可以使用你的模型:
python
from transformers import AutoModelForCausalLM, AutoTokenizer
model = AutoModelForCausalLM.from_pretrained("YourUsername/Qwen2.5-Coder-Sentiment")
tokenizer = AutoTokenizer.from_pretrained("YourUsername/Qwen2.5-Coder-Sentiment")📁 项目结构
bash
MSJ-Factory/
├── data/ # 数据集
│ ├── ChnSentiCorp_test.csv # 测试数据(179 样本)
│ ├── chnsenticorp_train_cleaned_instruct_balanced_3k.jsonl # 训练数据(3000 样本)
│ └── dataset_info.json # 数据集注册表
│
├── examples/ # 训练配置
│ └── train_freeze/
│ └── qwen2_5_coder_freeze_3k.yaml # 主要训练配置
│
├── scripts/ # 工具脚本
│ ├── eval_sentiment_compare.py # 评估脚本
│ └── convert_chnsenticorp.py # 数据转换
│
├── contexts/ # 文档
│ ├── chnsenticorp-evaluation-guide.md # 完整评估指南
│ ├── chnsenticorp-quick-reference.md # 快速命令参考
│ └── EVALUATION_SYSTEM_SUMMARY.md # 系统概览
│
├── src/ # 核心库
│ └── llamafactory/ # LlamaFactory 集成
│
├── saves/ # 模型输出(训练时创建)
│ └── qwen2_5-coder-1.5b/freeze/sft/ # 微调后的模型
│
└── Qwen2_5_Sentiment_Fine_tuning_Tutorial.ipynb # 交互式 notebook⚙️ 训练配置
推荐配置
T4 GPU(16GB 显存)
yaml
per_device_train_batch_size: 1
gradient_accumulation_steps: 8
freeze_trainable_layers: 6
bf16: trueA100 GPU(40GB 显存)
yaml
per_device_train_batch_size: 4
gradient_accumulation_steps: 2
freeze_trainable_layers: 12 # 训练更多层
bf16: true多 GPU 设置
bash
# 双卡
!CUDA_VISIBLE_DEVICES=0,1 llamafactory-cli train examples/train_freeze/qwen2_5_coder_freeze_3k.yaml
# 四卡
!CUDA_VISIBLE_DEVICES=0,1,2,3 llamafactory-cli train examples/train_freeze/qwen2_5_coder_freeze_3k.yaml配置参数详解
| 参数 | 值 | 作用 |
|---|---|---|
freeze_trainable_layers |
6 | 要训练的层数(从末尾算起) |
freeze_extra_modules |
embed_tokens,norm | 额外训练的模块 |
per_device_train_batch_size |
1 | 每个 GPU 每步的样本数 |
gradient_accumulation_steps |
8 | 累积梯度以获得更大的有效批次 |
learning_rate |
2.0e-5 | 模型学习的速度 |
num_train_epochs |
2.0 | 遍历数据的次数 |
bf16 |
true | 使用 BFloat16 加速训练 |
📊 评估结果
性能指标
| 模型 | 准确率 | 精确率 | 召回率 | F1分数 |
|---|---|---|---|---|
| 基础模型 | 91.62% | 98.57% | 83.13% | 90.20% |
| 微调后 | 97.77% ⬆️ | 100.00% ⬆️ | 95.18% ⬆️ | 97.53% ⬆️ |
| 提升 | +6.15% | +1.43% | +12.05% | +7.33% |
为什么微调有帮助
-
✅ 更好的领域适配:模型学习了中文情感表达模式
-
✅ 提高召回率:捕获更多正面案例(83% → 95%)
-
✅ 完美精确率:没有假正例(98% → 100%)
-
✅ 一致的预测:在边缘案例上更可靠
真实案例
| 文本 | 基础模型 | 微调后 | 正确 |
|---|---|---|---|
| 这个酒店非常棒! | ✅ 正面 | ✅ 正面 | ✅ |
| 服务态度一般般 | ❌ 正面 | ✅ 负面 | ✅ |
| 房间还算干净 | ❌ 负面 | ✅ 正面 | ✅ |
| 价格太贵了不值 | ✅ 负面 | ✅ 负面 | ✅ |
❓ 常见问题
Q1:需要多少 GPU 显存?
最低:16GB(T4、V100)
推荐:24GB+(A100、RTX 3090)
对于 16GB GPU:
-
使用
bf16: true -
保持
per_device_train_batch_size: 1 -
如需要可增加
gradient_accumulation_steps
Q2:可以在 CPU 上训练吗?
不推荐在 CPU 上训练,因为:
-
比 GPU 慢 50-100 倍
-
需要 12-24 小时而不是 15-30 分钟
替代方案:
Q3:如何使用自己的数据集?
步骤1:准备 JSONL 格式数据
json
{"messages": [
{"role": "user", "content": "你的提示词"},
{"role": "assistant", "content": "期望的回复"}
]}步骤2 :在 data/dataset_info.json 中注册
json
{
"your_dataset": {
"file_name": "your_data.jsonl",
"formatting": "sharegpt",
"columns": {"messages": "messages"}
}
}步骤3:更新训练配置
yaml
dataset: your_dataset # 在 YAML 文件中修改详见 contexts/dataset-formats-guide.md。
Q4:训练失败,CUDA OOM 错误
方案1:减少批次大小
yaml
per_device_train_batch_size: 1 # 已经是最小值
gradient_accumulation_steps: 16 # 增加这个方案2:使用 CPU 卸载(慢但有效)
yaml
deepspeed: examples/deepspeed/ds_z3_offload_config.json方案3:训练更少的层
yaml
freeze_trainable_layers: 3 # 从 6 减少到 3Q5:如何进一步提高模型性能?
选项1:训练更多轮次
yaml
num_train_epochs: 3.0 # 或 4.0、5.0选项2:训练更多层
yaml
freeze_trainable_layers: 12 # 更多适配选项3:使用完整微调(慢得多)
yaml
finetuning_type: full # 而不是 freeze选项4:收集更多训练数据
-
当前:3000 样本
-
推荐:5000-10000 样本以获得最佳结果
Q6:可以用于英文情感分析吗?
可以!只需:
-
准备英文情感数据集
-
更新提示词模板(删除中文特定说明)
-
注册你的数据集
-
使用相同配置训练
该模型支持多种语言。
Q7:如何部署模型进行推理?
选项1:Python 脚本(测试用)
python
from transformers import AutoModelForCausalLM, AutoTokenizer
model = AutoModelForCausalLM.from_pretrained("saves/qwen2_5-coder-1.5b/freeze/sft")
tokenizer = AutoTokenizer.from_pretrained("saves/qwen2_5-coder-1.5b/freeze/sft")
# 使用 model.generate() 进行推理选项2:vLLM(生产用)
bash
!vllm serve saves/qwen2_5-coder-1.5b/freeze/sft --port 8000选项3:LlamaFactory API
bash
!llamafactory-cli api examples/inference/qwen2_5_coder_sft.yaml详见 contexts/chnsenticorp-evaluation-guide.md 中的部署指南。
📄 引用
如果你在研究中使用了本项目,请引用:
bibtex
@misc{msj-factory-2025,
title={Qwen2.5-Coder 情感分析微调教程},
author={马诗剑},
year={2025},
howpublished={\url{https://github.com/IIIIQIIII/MSJ-Factory}}
}🙏 致谢
本项目基于以下优秀的开源项目:
-
LLaMA-Factory - 高效的微调框架
-
Qwen2.5 - 强大的基础模型
-
Transformers - HuggingFace 库
-
vLLM - 快速推理引擎
特别感谢:
-
阿里巴巴云发布 Qwen2.5 模型
-
HuggingFace 提供模型托管
-
Google Colab 提供免费 GPU 访问
⭐ 支持本项目
如果这个教程对你有帮助,请考虑:
-
⭐ 给本仓库点个 Star - 点击这里为项目点 Star
-
🔗 分享 - 告诉你的朋友和同事
-
🐛 报告问题 - 帮助作者改进
-
📝 贡献代码 - 欢迎 Pull Request!
👉 别忘了点 Star!这对作者意义重大!⭐
更多技术文章,请访问:马诗剑的博客 - https://blog.mashijian.com
用 ❤️ 构建 by 马诗剑