这生成与无监督学习 ------ 奶茶店的 "新品研发与原料优化体系"
- 速读
- [自编码器(Autoencoder):原料与流程的 "智能精炼机"](#自编码器(Autoencoder):原料与流程的 “智能精炼机”)
- [生成对抗网络(GAN):新品研发的 "创意碰撞台"](#生成对抗网络(GAN):新品研发的 “创意碰撞台”)
- [Diffusion 模型:细节控新品的 "精细雕刻师"](#Diffusion 模型:细节控新品的 “精细雕刻师”)
速读
当奶茶店不需要人工标注 "哪些步骤重要""哪种配方好喝",却想主动优化流程、研发新品时,3 类无监督生成模型就能派上用场 ------ 它们像 "隐形研发师",从数据里自己找规律,解决 "无标注也能创造" 的难题。但要真正用好这些模型,需先理解其底层逻辑、局限与优化方向。
自编码器(Autoencoder):原料与流程的 "智能精炼机"
场景
复杂配方 "瘦身":10 步果茶配方的 "洗茶、晾茶" 等步骤,在 MSE 损失计算中会被判定为 "对重建口感贡献低" 的冗余信息,编码层会自动剔除,最终输出 "煮茶→调果泥→控糖→摇匀→装杯"5 步核心流程,新手操作效率提升 40%;
原料杂质过滤:带渣茶汤的图像中,碎渣像素与纯净茶汤像素的灰度值差异大,编码层会忽略碎渣对应的低贡献特征,解码层重建时只还原纯净茶汤的像素分布,利用率提升 30%,顾客投诉率降 25%。
技术描述
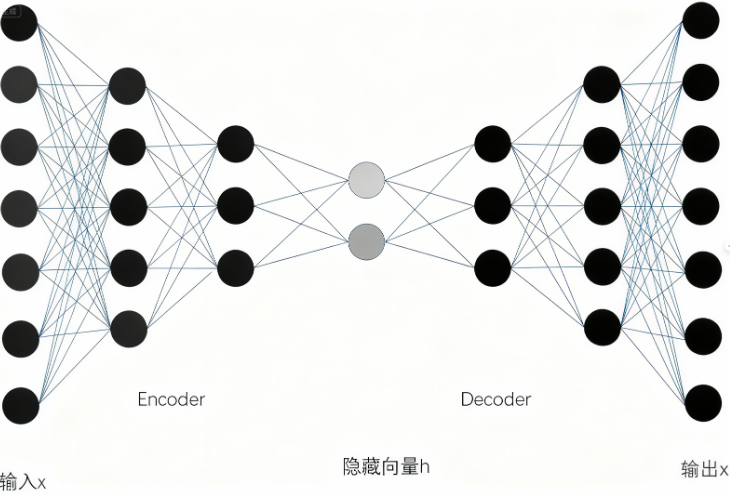
自编码器是一种 "对称式神经网络",结构分为输入层→编码层→瓶颈层(Latent Space)→解码层→输出层,核心目标是让 "输出" 尽可能接近 "输入",全程无监督(无需人工标注标签)。
编码过程:通过卷积、全连接等层将高维输入(如 10 步配方的操作参数、带渣茶汤的图像像素)压缩到低维瓶颈层,强制模型丢弃冗余信息(如 "晾茶" 这类对口感影响极小的步骤、茶汤中的碎渣像素),只保留核心特征(如 "煮茶温度""茶汤浓度");
解码过程:从瓶颈层的低维特征反向重建高维输出(如 5 步简化配方、纯净茶汤),通过均方误差(MSE)损失函数优化网络,让重建结果与原始输入的差异最小化;
关键特性:瓶颈层的 "压缩约束" 是核心 ------ 若瓶颈层维度过高,模型会 "偷懒" 保留冗余信息;维度过低,则会丢失关键特征,需通过交叉验证确定最优维度(如奶茶配方压缩中,3-5 维瓶颈层效果最佳)。
工程价值与适用场景
优点:训练简单(无需复杂损失设计)、计算成本低(网络结构对称且浅)、可解释性强(瓶颈层特征可对应实际物理意义,如 "煮茶温度""糖度"),适合中小奶茶店做流程优化;
缺点:生成能力弱(只能 "优化现有数据",无法创造全新配方,如不能从 0 生成 "栗子奶绿")、重建精度有限(简化配方的口感可能比原始配方略差,需人工微调)。
生成对抗网络(GAN):新品研发的 "创意碰撞台"
场景
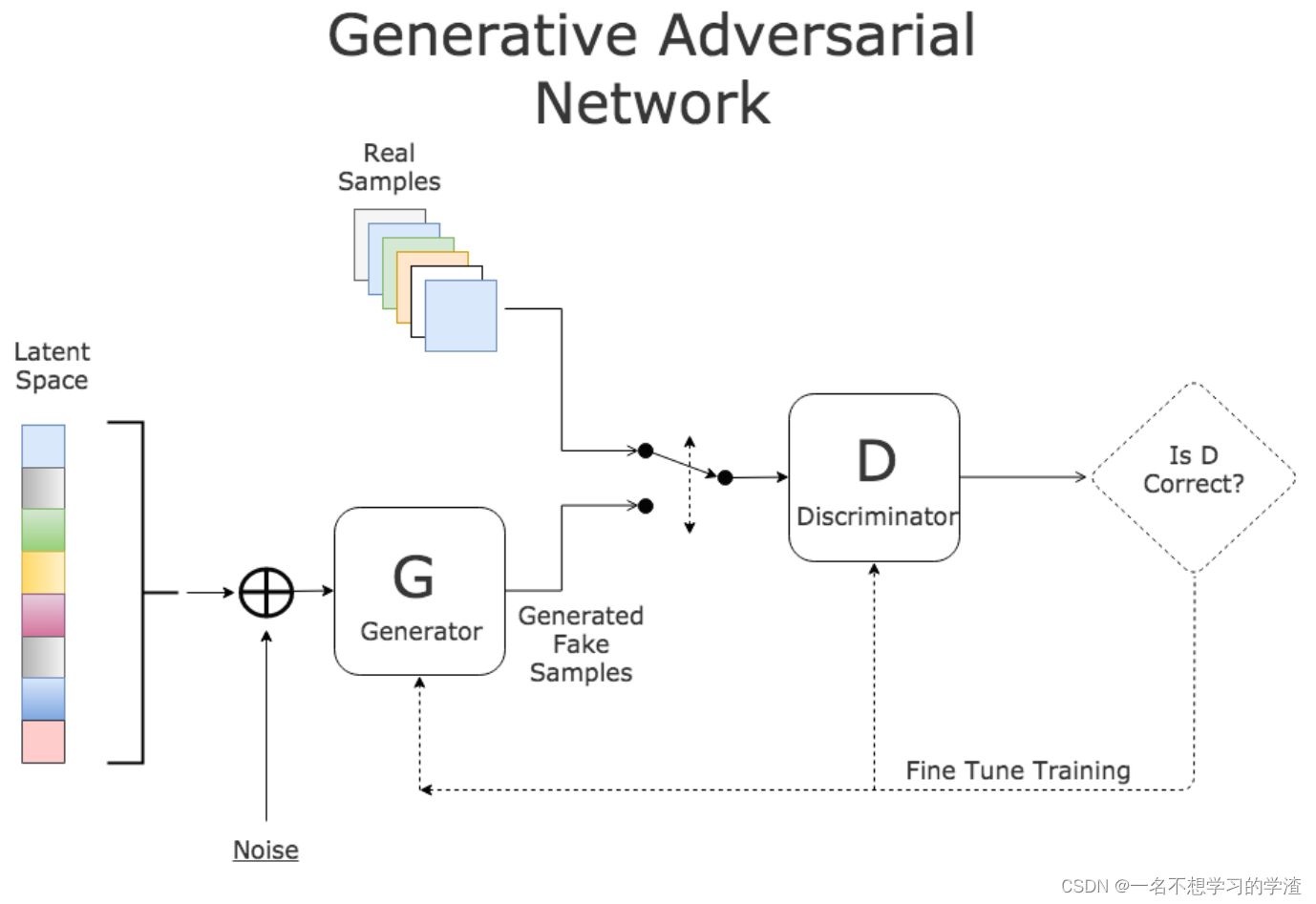
生成器 = 研发部:输入随机噪声(对应 "茶底类型、小料比例、糖度" 的随机组合),生成 "栗子泥 + 绿茶 + 奶盖" 等 10 组候选配方;
判别器 = 顾客 + 品控部:用历史畅销奶茶的 "口感评分、复购率" 作为真实样本标签,对候选配方打分,淘汰 "栗子味太淡"(D 判定为 "假" 的概率 > 80%)的方案;
迭代优化:3 轮博弈后,G 生成的 "栗子泥 25%+ 乌龙茶底 + 奶盖" 让 D 的判定准确率降至 51%(接近随机),达到纳什均衡,试销满意度从 50% 升至 80%。
技术描述
基本构成:GAN 由 Generator ( G(z; \theta_G) ) 和 Discriminator ( D(x; \theta_D) ) 构成。典型的原始目标是一个 min-max 问题:
min G max D V ( D , G ) = E x ∼ p data log D ( x ) + E z ∼ p z log ( 1 − D ( G ( z ) ) ) \min_G \max_D V(D, G) = \mathbb{E}{x \sim p{\text{data}}} \\log D(x) + \mathbb{E}_{z \sim p_z} \\log(1 - D(G(z))) GminDmaxV(D,G)=Ex∼pdatalogD(x)+Ez∼pzlog(1−D(G(z)))
其中 ( p_z ) 是简单先验(如高斯或均匀分布),( G ) 将噪声 ( z ) 映射为样本,( D ) 的目标是区分真实样本和生成样本。GAN 是隐式模型(implicit generative model),它不直接估计数据的显式概率密度,而是通过对抗优化使生成分布接近数据分布。
工程价值与适用场景
优点:生成能力强(可从 0 创造全新配方,如跨界联名款)、样本多样性高(能生成多种风格的新品,如 "栗子奶绿""栗子拿铁");
缺点:训练不稳定(易出现 "模式崩溃",即 G 只生成 1-2 种配方,无法多样化)、可解释性差(无法解释 "为什么这个配方好喝",只能靠结果验证)、计算成本高(需双网络同步训练,对硬件要求高)。
Diffusion 模型:细节控新品的 "精细雕刻师"
场景
前向加噪:对 10 款畅销厚乳奶茶的 "芋泥比例、厚乳量、茶底温度" 添加 βₜ噪声,生成 100 组混乱配方(如 "芋泥 30%+ 厚乳 10%+95℃茶底",明显结块);
反向去噪: 去噪网络每步估计 "当前配方的噪声来源"(如 "厚乳太少" 是口感差的噪声),8 步后生成 "芋泥 25%+ 厚乳 30%+80℃茶底",品控评价 "细腻无结块",复购率高 35%。
技术描述
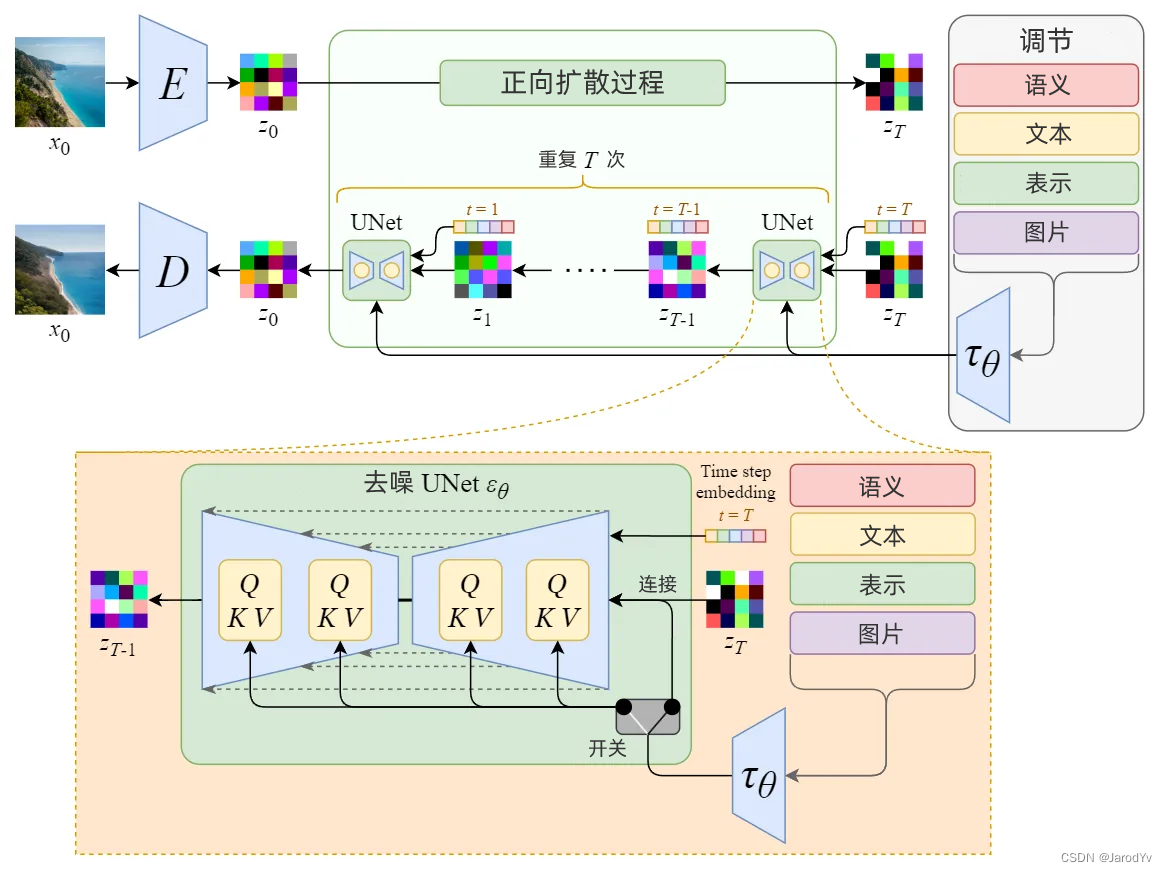
1. 前向(正向)过程
- 用一个固定的 Markov 链将真实样本 ( x_0 ) 逐步加高斯噪声,得到一系列 ( x_1, ... , x_T )。常见的前向转移写法为:
q ( x t ∣ x t − 1 ) = N ( x t ; 1 − β t x t − 1 , β t I ) q(x_t \mid x_{t-1}) = \mathcal{N}\bigl(x_t; \sqrt{1 - \beta_t}\, x_{t-1},\ \beta_t I\bigr) q(xt∣xt−1)=N(xt;1−βt xt−1, βtI)
其中 β t \beta_t βt是预设的小噪声比率(噪声逐步累加到 ( T ) 步)。
2. 反向(生成)过程
学习一个参数化的反向条件分布 p θ ( x t − 1 ∣ x t ) p_\theta(x_{t-1} \mid x_t) pθ(xt−1∣xt) ,目标是从纯噪声 x T x_T xT 逐步去噪回到 x 0 x_0 x0 。在实践中,模型通常被训练为预测被加入的噪声 ϵ \epsilon ϵ
ϵ θ ( x t , t ) ≈ ϵ ⟹ x ^ t − 1 = 函数 ( x t , ϵ θ ( x t , t ) , t ) \epsilon_\theta(x_t, t) \approx \epsilon \implies \hat{x}{t-1} = \text{函数}\bigl(x_t, \epsilon\theta(x_t, t), t\bigr) ϵθ(xt,t)≈ϵ⟹x^t−1=函数(xt,ϵθ(xt,t),t)
3. 训练目标(常见简化形式)
- DDPM 风格常用的"简化损失"(simple loss)是均方误差(MSE)去拟合噪声:
L simple = E x 0 , ϵ , t ∥ ϵ − ϵ θ ( x t , t ) ∥ 2 . L_{\text{simple}} = \mathbb{E}_{x_0, \epsilon, t}\bigl\\\|\\epsilon - \\epsilon_\\theta(x_t, t)\\\|\^2\\bigr. Lsimple=Ex0,ϵ,t∥ϵ−ϵθ(xt,t)∥2. - 从理论上也可以把扩散模型视作对某个变分下界 或 score matching 的优化(score-based / SDE 视角),这两种视角在实现与调参上互补。
工程价值与适用场景
优点:生成细节极致(能优化 "芋泥蒸制时间""茶底温度" 等微观参数)、训练稳定(无模式崩溃问题)、样本保真度高(新品口感与顾客预期偏差小);
缺点:推理速度慢(生成 1 个配方需 8-10 步,比 GAN 慢 5-10 倍,不适合紧急新品需求)、数据需求量大(需至少 50 + 款历史产品数据,小奶茶店可能数据不足)。