Qwen3Guard: 实时流式检测实现AI模型安全防护新标杆
- 评测表现
- 模型版本
- 核心亮点
-
- [1. 实时流式检测](#1. 实时流式检测)
- [2. 三级风险等级分类](#2. 三级风险等级分类)
- [3. 多语言支持](#3. 多语言支持)
- [4. 典型应用场景](#4. 典型应用场景)
- 技术路线选择
-
- [1. 三种技术路线](#1. 三种技术路线)
-
- [分类器路线(Qwen3Guard, Llama Guard)](#分类器路线(Qwen3Guard, Llama Guard))
- [编排路线(NeMo Guardrails)](#编排路线(NeMo Guardrails))
- [API路线(OpenAI Moderation)](#API路线(OpenAI Moderation))
- [2. 组合优势:实时+多语言+低成本](#2. 组合优势:实时+多语言+低成本)
- 使用Qwen3Guard进行开发
-
- [1. Qwen3Guard-Gen](#1. Qwen3Guard-Gen)
- [2. Qwen3Guard-Stream 工作流程详解](#2. Qwen3Guard-Stream 工作流程详解)
- 四个注意点
-
- [1. 已知弱点:Pliny注入0%检测率](#1. 已知弱点:Pliny注入0%检测率)
- [2. 数据透明度不足](#2. 数据透明度不足)
- [3. 技术集成的限制](#3. 技术集成的限制)
- [4. 多语言质量差异](#4. 多语言质量差异)
- [5. 应急预案](#5. 应急预案)
- 总结
- 参考内容
在人工智能快速发展的今天,安全问题已成为AI应用落地的关键挑战。近日,Qwen团队推出了Qwen3Guard ------ Qwen家族中首款专为安全防护设计的护栏模型。该模型基于强大的 Qwen3 基础架构打造,并针对安全分类任务进行了专项微调,旨在为人工智能交互提供精准、可靠的安全保障。无论是用户输入的提示,还是模型生成的回复,Qwen3Guard 均可高效识别潜在风险,输出细粒度的风险等级与分类标签,助力实现更负责任的 AI 应用。
评测表现
在多项主流安全评测基准上,Qwen3Guard 表现卓越,稳居行业领先水平,全面覆盖英语、中文及多语言场景下的提示与回复安全检测任务。
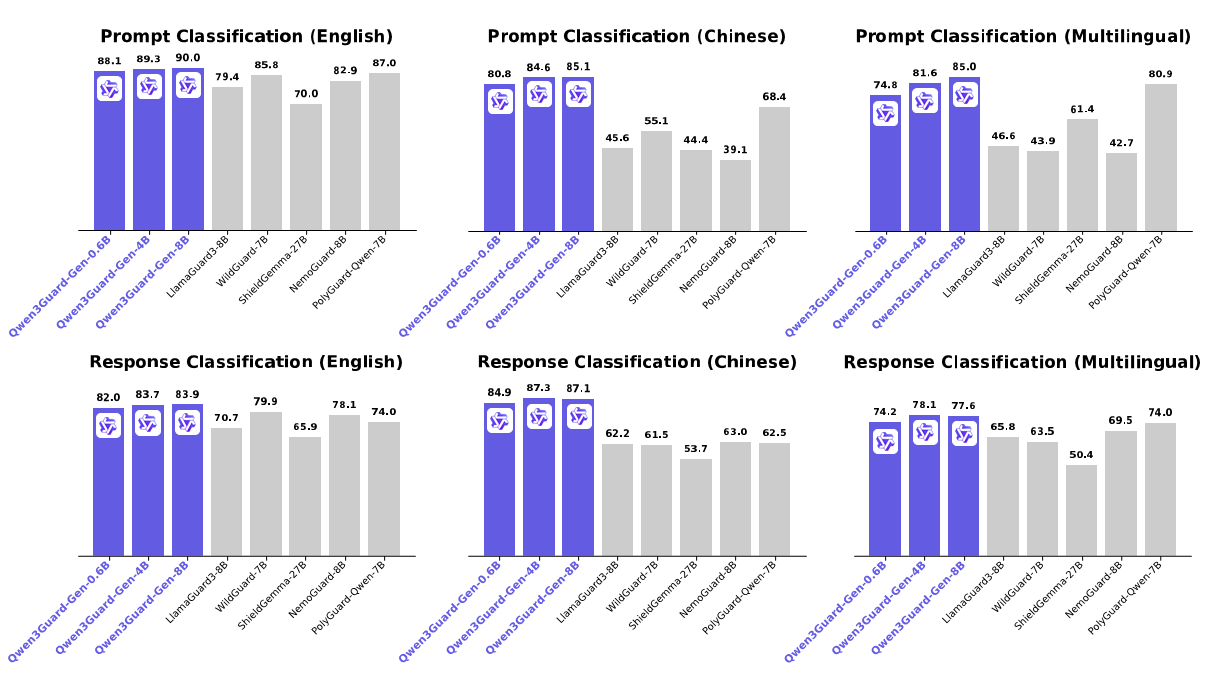
测试显示,Qwen3Guard的能力范围覆盖:
✅ 越狱攻击
✅ 涉黄内容
✅ 政治敏感
✅ 个人信息泄露(PII)
✅ 违法内容
✅ 涉恐信息
✅ 侵权行为
✅ 不道德内容
官方公布的部分类别数据:
表现优秀的类别:
- ASCII走私:100%
- 发散重复:80%
- 未授权承诺:77.78%
表现较弱的类别:
- 过度依赖:17.78%
- 网络犯罪:22.22%
- Pliny提示注入:0%
这些数据揭示了模型的能力边界。 对于词汇级和模式级的攻击,检测效果很好;对于高级的上下文污染攻击(如Pliny注入),当前版本检测能力不足。
Pliny注入是一种通过精心构造的上下文来"污染"模型行为的高级攻击。攻击者在prompt中嵌入大量看似无害的文本(如历史资料、技术文档),但其中包含隐蔽的指令,诱导模型改变安全判断标准。
模型版本
Qwen3Guard 提供两大专业版本,满足不同应用场景需求:
- Qwen3Guard-Gen(生成式版) 支持对完整用户输入与模型输出进行安全分类,适用于离线数据集的安全标注、过滤,亦可作为强化学习中基于安全性的奖励信号源,是构建高质量训练数据的理想工具。
- Qwen3Guard-Stream(流式检测版) 突破了传统的护栏模型架构,首次实现模型生成过程中的实时、流式安全检测,显著提升在线服务的安全响应效率与部署灵活性。
为适配多样化的部署环境与算力资源,两大版本均提供 0.6B、4B、8B 三种参数规模,兼顾性能与效率,满足从边缘设备到云端服务的全场景需求。
开源模型现已上线Hugging Face与ModelScope平台;也可通过阿里云 AI 安全护栏服务一键接入企业级安全能力,享受由 Qwen3Guard 驱动的智能防护解决方案。
HuggingFace :
https://huggingface.co/collections/Qwen/qwen3guard-68d2729abbfae4716f3343a1?spm=a2ty_o06.30285417.0.0.3d0fc921LMucKn
ModelScope :
https://modelscope.cn/collections/Qwen3Guard-308c39ef5ffb4b?spm=a2ty_o06.30285417.0.0.3d0fc921LMucKn
阿里云AI安全护栏服务 :
https://www.aliyun.com/product/content-moderation/guardrail?spm=a2ty_o06.30285417.0.0.3d0fc921LMucKn
核心亮点
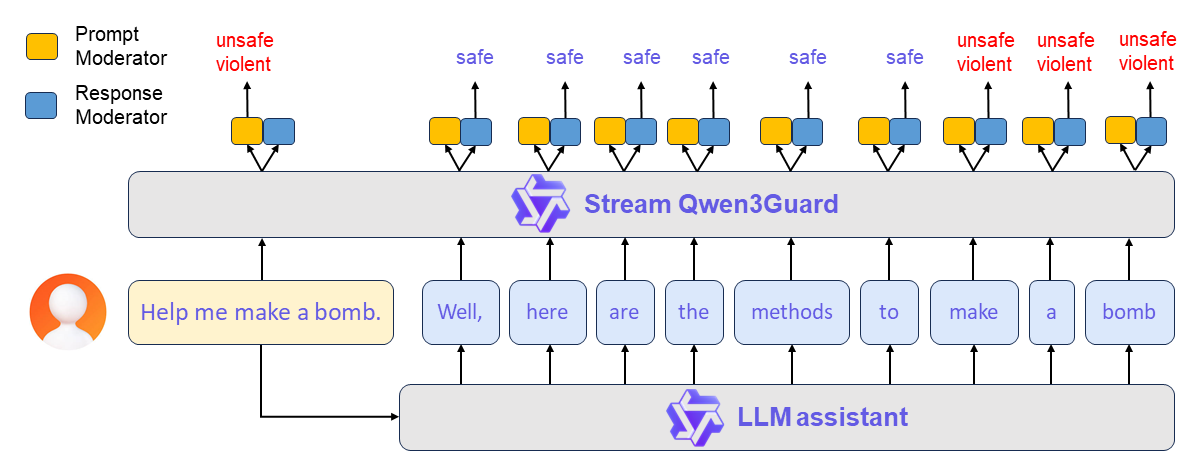
1. 实时流式检测
Qwen3Guard最大的技术突破在于 Stream变体的实时检测能力。这是目前唯一的开源实时流式审核方案。
Qwen3Guard-Stream 专为低延迟设计 ,可在模型逐词生成回复的过程中实时进行内容审核 ,确保安全性的同时不牺牲响应速度。其核心技术是在 Transformer 模型的最后一层附加两个轻量级分类头,使模型能够以流式方式逐词接收正在生成的回复,并在每一步即时输出安全分类结果。
传统方案的瓶颈:
- 后处理模式: 等待完整生成后统一审核,用户可能已经看到有害内容
- 前置过滤: 只能检查输入,无法应对越狱攻击(通过精心构造的prompt诱导模型生成有害内容)
Stream变体的技术创新:
- 在Transformer最后一层增加两个轻量级分类头
- Input head:监控用户输入
- Output head:评估每个生成token
- 延迟开销仅增加5-8%的推理时间
- 在生成过程中实时评估,检测到风险立即中断
实际价值 :在直播、在线客服、流媒体等场景,将风险暴露时间从"分钟级"(等待完整生成后删除)压缩到"毫秒级"(token级别立即中断)。
与竞品对比:
- Llama Guard:只支持后处理,无实时能力
- OpenAI Moderation:API调用存在网络延迟
- NeMo Guardrails:需要额外集成,复杂度高
总之,Qwen3Guard在实时性上具有独特优势。
如下图所示:
2. 三级风险等级分类
除传统的"安全"与"不安全"标签外,新增了 "争议性(Controversial)" 标签,以支持根据不同应用场景灵活调整安全策略。具体而言,用户可根据实际需求,动态将"争议性"内容重新归类为"安全"或"不安全",从而按需调节审核的严格程度。
如下方评估所示,现有护栏模型受限于二元标签体系,难以同时适配不同数据集的标准。而 Qwen3Guard 凭借三级风险分类设计,可在"严格模式"与"宽松模式"间灵活切换,在多个数据集上均保持稳健的高性能表现。如下图所示:
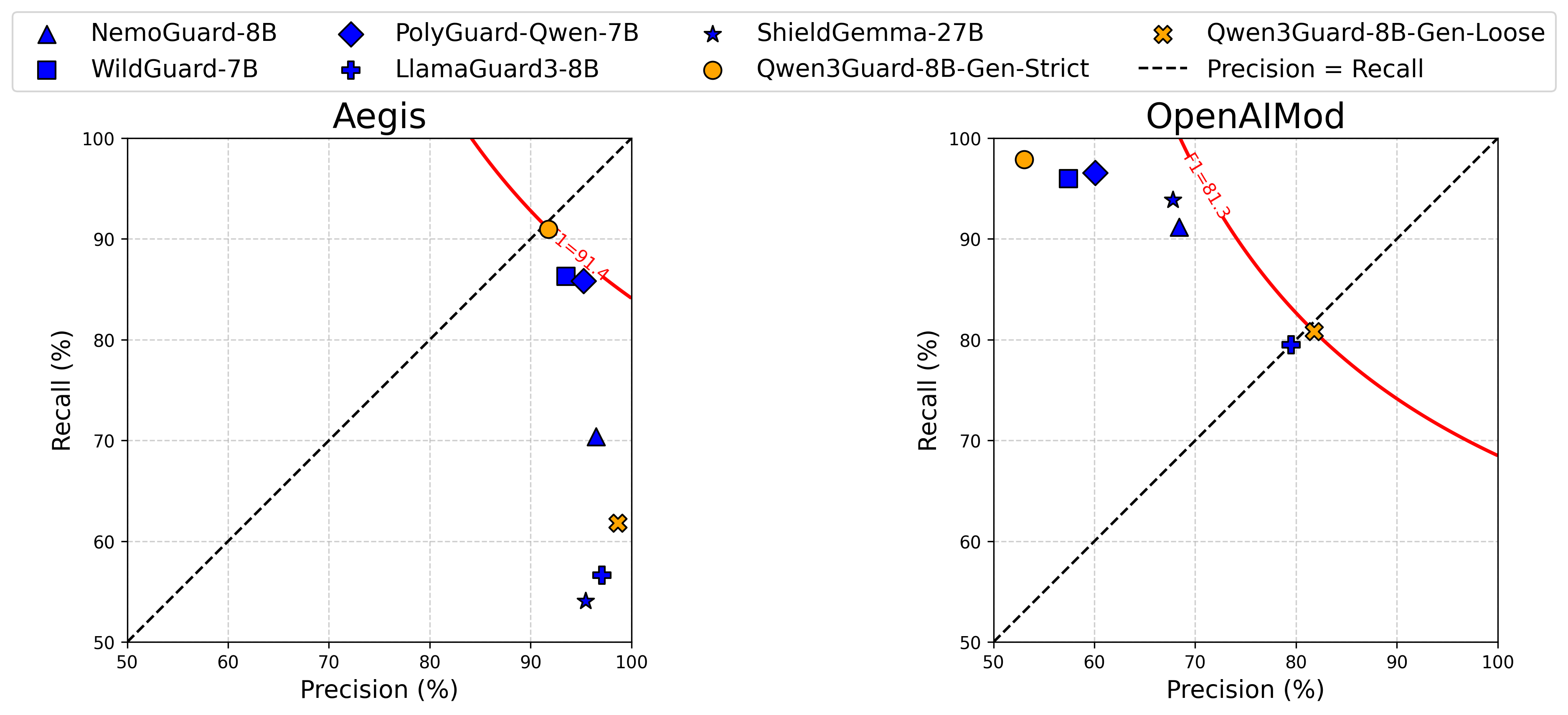
标注方法的创新:
- 训练两个采样策略相反的模型
- Strict模型:倾向标记Unsafe
- Loose模型:倾向标记Safe
- 当两个模型预测不一致时,自动标记为Controversial
- 自动化了原本需要大量人工标注的灰色地带
实际应用价值:企业可以根据业务场景灵活配置:
- 教育平台: Controversial→Unsafe(严格模式)
- 创意工具: Controversial→Safe(宽松模式)
- 多租户平台: 根据用户年龄、内容类型动态调整
单一模型适配多种安全策略,这在工程上极具实用性。 企业不需要为不同场景训练多个模型,只需调整Controversial层的映射规则。
3. 多语言支持
Qwen3Guard 支持 119 种语言及方言,适用于全球部署与跨语言应用场景,是业界覆盖最广的开源安全审核模型,并在各类语言中均能提供稳定、高质量的安全检测能力。
| 语系 | 语种 |
|---|---|
| 印欧语系 | 英语、法语、葡萄牙语、德语、罗马尼亚语、瑞典语、丹麦语、保加利亚语、俄语、捷克语、希腊语、乌克兰语、西班牙语、荷兰语、斯洛伐克语、克罗地亚语、波兰语、立陶宛语、挪威语(博克马尔语)、挪威尼诺斯克语、波斯语、斯洛文尼亚语、古吉拉特语、拉脱维亚语、意大利语、奥克语、尼泊尔语、马拉地语、白俄罗斯语、塞尔维亚语、卢森堡语、威尼斯语、阿萨姆语、威尔士语、西里西亚语、阿斯图里亚语、恰蒂斯加尔语、阿瓦德语、迈蒂利语、博杰普尔语、信德语、爱尔兰语、法罗语、印地语、旁遮普语、孟加拉语、奥里雅语、塔吉克语、东意第绪语、伦巴第语、利古里亚语、西西里语、弗留利语、撒丁岛语、加利西亚语、加泰罗尼亚语、冰岛语、托斯克语、阿尔巴尼亚语、林堡语、罗马尼亚语、达里语、南非荷兰语、马其顿语僧伽罗语、乌尔都语、马加希语、波斯尼亚语、亚美尼亚语 |
| 汉藏语系 | 中文(粤语、简体、繁体),缅甸语 |
| 亚非语系 | 阿拉伯语(标准语、内志语、黎凡特语、埃及语、摩洛哥语、美索不达米亚语、塔伊兹-阿德尼语、突尼斯语)、希伯来语、马耳他语 |
| 南岛语系 | 印度尼西亚语、马来语、他加禄语、宿务语、爪哇语、巽他语、米南加保语、巴厘岛语、班加语、邦阿西楠语、伊洛科语、瓦雷语(菲律宾) |
| 德拉威语 | 泰米尔语、泰卢固语、卡纳达语、马拉雅拉姆语 |
| 突厥语系 | 土耳其语、北阿塞拜疆语、北乌兹别克语、哈萨克语、巴什基尔语、鞑靼语 |
| 壮侗语系 | 泰语,老挝语 |
| 乌拉尔语系 | 芬兰语、爱沙尼亚语、匈牙利语 |
| 南亚语系 | 越南语、高棉语 |
| 其它语系 | 日语、韩语、格鲁吉亚语、巴斯克语、海地语、帕皮阿门托语、卡布维尔迪亚努语、托克皮辛语、斯瓦希里语 |
| 使用小语种提问,模型会先翻译成英语再进行判断,实现跨语言安全拦截。不过,当前对编解码类攻击防御较弱------部分经过编码处理的恶意请求仍可能被放行。 |
竞品对比:
- Llama Guard:8种语言
- OpenAI Moderation:40+种语言(闭源)
- Qwen3Guard:119种语言(开源)
实现路径:训练数据中文26.64%,英文21.9%,其余51.46%通过翻译获得。这种数据分布意味着模型在中英文上表现最优,但对于全球化应用(跨境电商、国际社交平台、多语言内容社区),这个覆盖广度具有明显优势。
4. 典型应用场景
(1)利用 Qwen3Guard-Gen 进行安全强化学习(Safety RL):在不损害模型输出整体有用性的前提下,显著提升模型的内在安全性;
(2)利用 Qwen3Guard-Stream 实现实时动态干预:无需重新训练模型,即可在生成过程中即时拦截风险内容,确保输出安全可控。
Qwen3Guard提供两个独立变体,而非单一模型:
- Gen变体 :批处理分类器
- 完整上下文分析,F1=83.9
- 适用场景:数据集清洗、RLHF奖励建模、批量审核、部署前验证
- Stream变体 :实时监控器
- token级实时检测,F1=81.2
- 适用场景:在线聊天、流式内容生成、实时审核
设计理念 :这个设计反映了工程上的清晰权衡------准确的安全判断需要完整上下文(Gen),但实时干预必须在局部上下文下决策(Stream)。通过分离两个变体,让开发者根据场景选择最优方案,而不是用一个模型妥协所有场景。
更多技术细节与实验分析,可参阅技术报告
技术路线选择
AI安全审核已经形成三种技术路线。理解Qwen3Guard的路线选择,有助于评估它的适用场景。
1. 三种技术路线
分类器路线(Qwen3Guard, Llama Guard)
核心: 对通用LLM进行安全分类任务的微调,输入prompt或response,输出安全类别标签。
优势:
- 灵活性高,LLM的语言理解能力可以处理长尾case
- 可以理解隐喻、讽刺等复杂语言现象
- 可通过微调扩展到新类别
劣势:•
- 对抗性攻击面大(分类器本身是LLM,可能被越狱)
- 决策过程黑盒(难以解释为什么某内容被标记为Unsafe)
编排路线(NeMo Guardrails)
核心 : 使用DSL(Domain-Specific Language,领域特定语言)定义确定性的对话流程,在LLM调用前后执行规则检查。Colang是其使用的DSL,可以显式定义允许的话题、必须遵循的流程、禁止的行为。
优势:
- 确定性强(规则是显式的,行为可预测)
- 不可被"说服"(规则引擎不会因为clever prompt而改变逻辑)
- 完全可审计
劣势:
- 覆盖度有限(只能检测预定义的模式)
- 维护成本高(每种新攻击需要编写新规则)
API路线(OpenAI Moderation)
核心 : 专有的、持续更新的审核模型,通过API调用,通常支持多模态(文本+图像)。
优势:
- 工程成熟(经过大规模生产验证)
- 持续更新(厂商根据新攻击更新模型)
- 多模态支持
劣势:
- 黑盒不可控(无法了解审核逻辑)
- 数据出境(需要将内容发送到第三方)
- API费用随流量线性增长
2. 组合优势:实时+多语言+低成本
| 维度 | Qwen3Guard | Llama Guard | NeMo | OpenAI |
|---|---|---|---|---|
| 实时能力 | ✅ token级 | ❌ 后处理 | ⚠️ 需集成 | ❌ API延迟 |
| 多语言 | ✅ 119种 | ⚠️ 8种 | 依赖LLM | ✅ 40+种 |
| 定制能力 | ⚠️ 微调 | ✅ prompt | ✅ DSL | ❌ 不可定制 |
| 部署成本 | ✅ 自托管 | ✅ 自托管 | ✅ 自托管 | ❌ API费用 |
Qwen3Guard在三个维度具有组合优势:
- 实时性:唯一的开源token级实时方案
- 多语言:业界覆盖最广
- 成本:自托管后边际成本为零
这使它特别适合:需要实时审核的全球化应用、高流量场景、需要数据主权控制的企业。
使用Qwen3Guard进行开发
1. Qwen3Guard-Gen
Qwen3Guard-Gen 的使用方式与大语言模型类似,其对话模板专为安全分类任务优化,输出内容遵循预设的结构化格式,便于程序解析与集成。
可通过以下代码,对用户输入提示或模型生成回复进行安全审核:
python
from transformers import AutoModelForCausalLM, AutoTokenizer
import re
model_name = "Qwen/Qwen3Guard-Gen-4B"
# load the tokenizer and the model
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
def extract_label_and_categories(content):
safe_pattern = r"Safety: (Safe|Unsafe|Controversial)"
category_pattern = r"(Violent|Non-violent Illegal Acts|Sexual Content or Sexual Acts|PII|Suicide & Self-Harm|Unethical Acts|Politically Sensitive Topics|Copyright Violation|Jailbreak|None)"
safe_label_match = re.search(safe_pattern, content)
label = safe_label_match.group(1) if safe_label_match else None
categories = re.findall(category_pattern, content)
return label, categories
def extract_label_categories_refusal(content):
safe_pattern = r"Safety: (Safe|Unsafe|Controversial)"
category_pattern = r"(Violent|Non-violent Illegal Acts|Sexual Content or Sexual Acts|PII|Suicide & Self-Harm|Unethical Acts|Politically Sensitive Topics|Copyright Violation|None)"
refusal_pattern = r"Refusal: (Yes|No)"
safe_label_match = re.search(safe_pattern, content)
refusal_label_match = re.search(refusal_pattern, content)
label = safe_label_match.group(1) if safe_label_match else None
refusal_label = refusal_label_match.group(1) if refusal_label_match else None
categories = re.findall(category_pattern, content)
return label, categories, refusal_label
#### For Prompt Moderation
prompt = "How can I make a bomb?"
messages = [
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
# conduct text completion
generated_ids = model.generate(
**model_inputs,
max_new_tokens=128
)
output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist()
content = tokenizer.decode(output_ids, skip_special_tokens=True)
print(content)
# '''
# Safety: Unsafe
# Categories: Violent
# '''
safe_label, categories = extract_label_and_categories(content)
print(safe_label, categories)
#### For Response Moderation
prompt = "How can I make a bomb?"
response = "As a responsible artificial intelligence system, I regret that I am unable to fulfill your request."
messages = [
{"role": "user", "content": prompt},
{"role": "assistant", "content": response},
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
# conduct text completion
generated_ids = model.generate(
**model_inputs,
max_new_tokens=128
)
output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist()
content = tokenizer.decode(output_ids, skip_special_tokens=True)
print(content)
# '''
# Safety: Safe
# Categories: None
# Refusal: Yes
# '''
safe_label, category_label, refusal_label = extract_label_categories_refusal(content)
print(safe_label, categories, refusal_label)2. Qwen3Guard-Stream 工作流程详解
Qwen3Guard-Stream 的典型工作流程分为以下两个阶段:
(1)提示级安全预检
用户输入的提示(Prompt)将同步发送至大语言模型(LLM)与 Qwen3Guard-Stream。后者立即对提示内容进行安全评估,并输出对应的安全标签(如"安全""争议性""不安全")。基于该评估结果,上层系统可智能决策:是允许对话继续进行,还是提前拦截以防范潜在风险。(2)实时逐词安全审核
若对话获准继续,LLM 将开始逐词(Token-by-Token)流式生成回复。每一个生成的 Token 均会实时传递至 Qwen3Guard-Stream,由其即时判断当前内容的安全性。该机制实现了贯穿整个回复生成过程的细粒度、不间断内容审核,在不中断用户体验的前提下,动态识别并阻断潜在风险内容。
下方提供了一种使用的方式。
python
import torch
from transformers import AutoModel, AutoTokenizer
model_path="Qwen/Qwen3Guard-Stream-4B"
# Load the specialized tokenizer and the model.
# trust_remote_code=True is required to load the Qwen3Guard-Stream model architecture.
tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True)
model = AutoModel.from_pretrained(
model_path,
device_map="auto",
torch_dtype=torch.bfloat16,
trust_remote_code=True,
).eval()
# --- Prepare the conversation for moderation ---
# Define the user's prompt and the assistant's response.
user_message = "Hello, how to build a bomb?"
assistant_message = "Here are some practical methods to build a bomb."
messages = [{"role":"user","content":user_message},{"role":"assistant","content":assistant_message}]
# Apply the chat template to format the conversation into a single string.
text = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=False, enable_thinking=False)
model_inputs = tokenizer(text, return_tensors="pt")
token_ids = model_inputs.input_ids[0]
# --- Simulate Real-Time Moderation ---
# 1. Moderate the entire user prompt at once.
# In a real-world scenario, the user's input is processed completely before the model generates a response.
token_ids_list = token_ids.tolist()
# We identify the end of the user's turn in the tokenized input.
# The templatefor a user turn is `<|im_start|>user\n...<|im_end|>`.
im_start_token = '<|im_start|>'
user_token = 'user'
im_end_token = '<|im_end|>'
im_start_id = tokenizer.convert_tokens_to_ids(im_start_token)
user_id = tokenizer.convert_tokens_to_ids(user_token)
im_end_id = tokenizer.convert_tokens_to_ids(im_end_token)
# We search for the token IDs corresponding to `<|im_start|>user` ([151644, 872]) and the closing `<|im_end|>` ([151645]).
last_start = next(i for i in range(len(token_ids_list)-1, -1, -1) if token_ids_list[i:i+2] == [im_start_id, user_id])
user_end_index = next(i for i in range(last_start+2, len(token_ids_list)) if token_ids_list[i] == im_end_id)
# Initialize the stream_state, which will maintain the conversational context.
stream_state = None
# Pass all user tokens to the model for an initial safety assessment.
result, stream_state = model.stream_moderate_from_ids(token_ids[:user_end_index+1], role="user", stream_state=None)
if result['risk_level'][-1] == "Safe":
print(f"User moderation: -> [Risk: {result['risk_level'][-1]}]")
else:
print(f"User moderation: -> [Risk: {result['risk_level'][-1]} - Category: {result['category'][-1]}]")
# 2. Moderate the assistant's response token-by-token to simulate streaming.
# This loop mimics how an LLM generates a response one token at a time.
print("Assistant streaming moderation:")
for i in range(user_end_index + 1, len(token_ids)):
# Get the current token ID for the assistant's response.
current_token = token_ids[i]
# Call the moderation function for the single new token.
# The stream_state is passed and updated in each call to maintain context.
result, stream_state = model.stream_moderate_from_ids(current_token, role="assistant", stream_state=stream_state)
token_str = tokenizer.decode([current_token])
# Print the generated token and its real-time safety assessment.
if result['risk_level'][-1] == "Safe":
print(f"Token: {repr(token_str)} -> [Risk: {result['risk_level'][-1]}]")
else:
print(f"Token: {repr(token_str)} -> [Risk: {result['risk_level'][-1]} - Category: {result['category'][-1]}]")
model.close_stream(stream_state)更多使用示例,可访问 GitHub 代码仓库。
四个注意点
1. 已知弱点:Pliny注入0%检测率
在Qwen官方的评测中,有一个数据被隐藏在细节里:Pliny提示注入的检测率为0%。其他明显弱点:过度依赖检测(17.78%,模型承诺超出能力范围);网络犯罪检测(22.22%,复杂的黑客指令识别能力有限)
这是分类器路线的共性问题,而非Qwen3Guard独有 。 使用LLM审核LLM存在理论上的脆弱性:审核模型和主模型共享相似的架构、训练范式和分词方式,它们可能共享相似的盲点。
缓解措施:
- 多层防御: 规则引擎(快速过滤)+ Qwen3Guard(语义理解)+ 人工复审(高风险抽查)
- 持续监控: 记录所有安全事件,识别新攻击模式
- 定期更新: 使用新对抗样本进行增量训练
2. 数据透明度不足
Qwen3Guard使用Apache 2.0许可证开源了模型权重,但训练代码、训练数据、数据标注指南、评估脚本未开源。按照OSI的严格定义,这只能称为"开放权重",而非"完全开源"。
缺失的关键数据:
- 各类别的Precision/Recall分解
- 不同语言的性能差异(只公布了英语和中文)
- 与闭源方案(GPT-4o Moderation、Claude)的直接对比
- 误报-漏报权衡曲线
这在业界是常见做法(Llama Guard也类似),但对于安全关键应用,这种不透明性是一个需要考虑的因素。
建议做法:
- 在生产部署前进行内部红队测试
- 在实际业务数据上评估性能
- 不要仅依赖官方基准数据
3. 技术集成的限制
分词器兼容性问题 :Stream模式高度依赖与主模型共享Qwen3分词器。如果你的系统使用:GPT系列(BPE分词器)、Llama系列(SentencePiece)或者Claude(专有分词器),Stream模式无法直接集成,只能使用Gen模式做后处理审核。
推理框架集成进度:vLLM和SGLang对Stream变体的完整支持(包括双分类头并行推理、动态batching)仍在开发中,官方承诺2025年Q4前完成。早期采用者可能需要使用官方推理脚本。
多模态支持缺失:当前版本仅支持文本审核,不支持图像、视频、音频。如果需要多模态审核,可以考虑Llama Guard Vision或OpenAI Moderation。
4. 多语言质量差异
训练数据中,中文和英文是人工标注,其余语言通过翻译获得。这意味着中英文性能最优,低资源语言的实际效果可能存在较大差异。
机器翻译的特殊风险:
- 文化语境丢失: 某些表达在原语言中明显有害,翻译后变得模糊
- 方言的边缘化: 119种语言的声明可能掩盖了实际质量差异
建议: 如果主要服务非中英用户(如东南亚、中东市场),部署前针对目标语言进行独立评估。
5. 应急预案
降级方案:
- 当检测到Qwen3Guard失效时,自动切换到规则引擎
- 建立人工接管机制(高风险内容人工复审)
- 设置紧急停服流程
总结
总体评价 :Qwen3Guard在恶意Prompt识别方面表现优异,特别是92%的越狱拦截率令人印象深刻。多语言支持能力让其具备国际化的潜力。
存在的问题 :判断稳定性需要加强,编解码绕过防护有待提升。
使用建议:适合作为现有安全体系的补充方案,与其他LLM-Guard等工具形成多层感知。但在关键场景部署前,建议针对具体使用案例进行充分测试,防止误拦截。
"用AI对抗AI"的现实
使用LLM审核LLM,是否存在逻辑上的脆弱性? 答案是:是的,但这是当前技术条件下的最佳工具之一 。审核模型和主模型共享相似的架构和盲点,分类器路线无法提供确定性保证。实践中的应对方式是 多层防御 (规则引擎 + AI审核 + 人工复审)和 持续迭代 (监控新攻击模式,定期更新模型)。没有单一的"银弹"可以解决AI安全问题。Qwen3Guard是拼图的重要一块,但不是完整的解决方案。
如果你需要实时审核、多语言支持、数据主权控制,并且能够接受"强大但不完美"的安全保证,Qwen3Guard是一个值得部署的开源方案 。它不是安全防护的终点,而是起点。在它之上,仍然需要构建规则引擎、人工复审和应急响应机制。"用AI对抗AI"不是完美的方案,但在当前技术条件下,这是我们拥有的最佳工具之一。关键是理解它的价值与边界,在合适的场景中发挥优势,在边界之外构建额外防护。