如果有人能把你过去一年的聊天记录全部看完,然后告诉你
你在沟通中有哪些盲区对方真正在意什么群里藏着哪些商业机会
你会不会很想听?这就是我做EchoSoul的初衷。 它能读取微信聊天记录,结合AI和自定义Prompt,生成性格分析、需求洞察、群聊精华等各种报告。 数据全程本地处理,隐私安全;操作简单到只需三步,小白也能用。 今天这篇文章,既讲怎么用,也讲怎么做,干货拉满。
先看个真实场景
周日晚上,我打开 EchoSoul,选了 vibe coding 群的聊天记录,点击"需求洞察"模板,一键生成。30 秒后,一份分析报告出现:本周讨论最多的痛点、潜在需求、可以立刻动手的产品方向。这些信息原本淹没在几千条消息里,我自己看完可能要 2 小时,还不一定能提炼得这么清晰。
这就是 EchoSoul 的日常使用体验------把信息过载变成洞察收获。
三步就能上手
- 选择聊天对象 - 任意微信好友或群聊,支持多选
- 设定时间范围 - 最近一周、一个月、一个季度,或者自定义日期
- 选择分析模板 - 从 6 个内置模板里选,或者自己写 Prompt
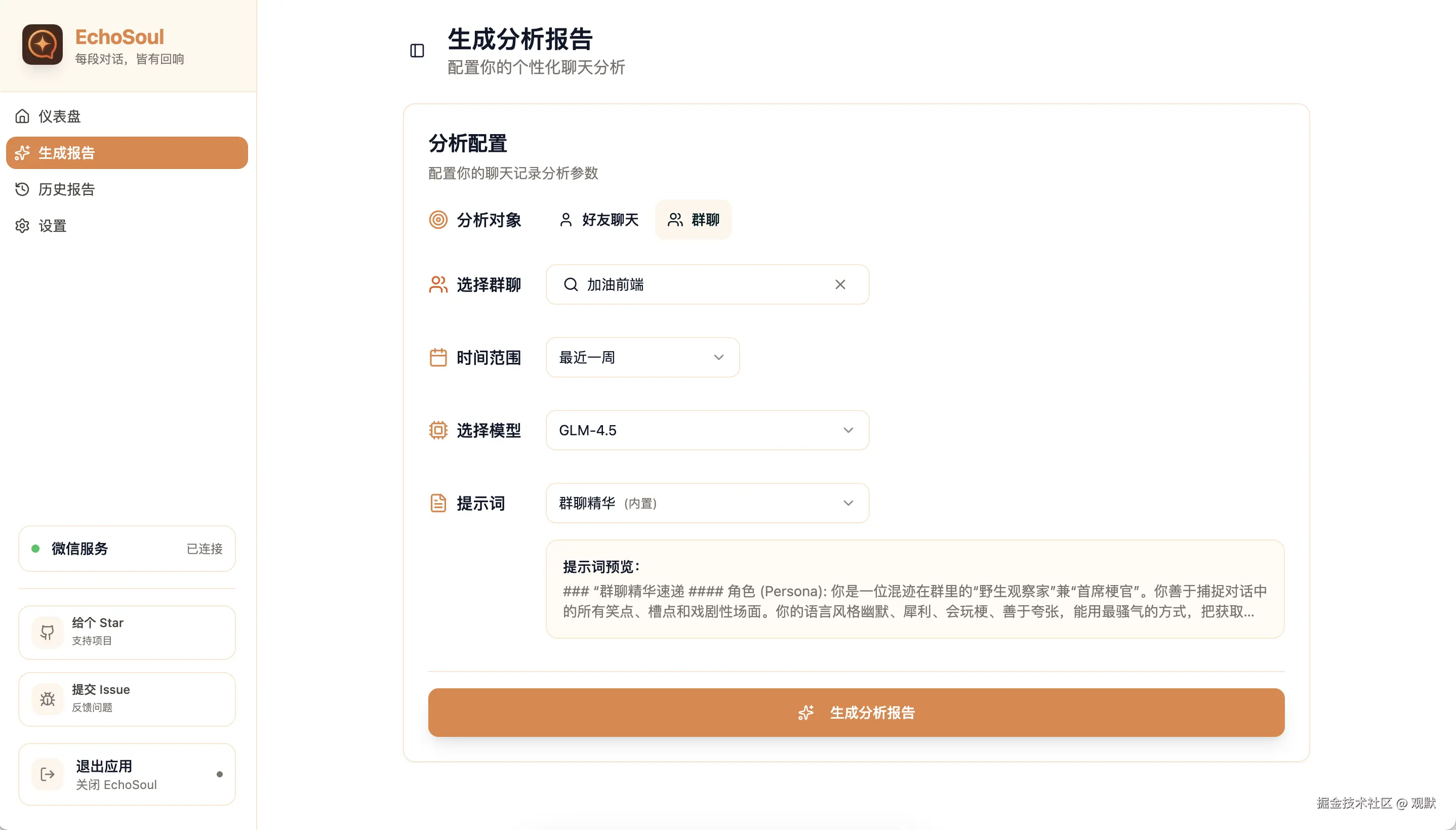
点击生成,AI 开始工作。你能实时看到报告一个字一个字地生成出来,就像有人在给你写分析报告。生成完毕后,可以导出 Markdown 文件,或者一键生成海报分享到朋友圈。
能做什么?6 个内置模板
EchoSoul 内置了 6 个精心设计的分析模板,覆盖不同场景:
| 模板 | 适合场景 | 核心价值 |
|---|---|---|
| 需求洞察 | 垂直领域群聊 | 从聊天中挖掘产品需求和商业机会 |
| 对方性格分析 | 重要谈判、了解新同事 | 读懂对方沟通偏好,给出 MBTI 预测和建议 |
| 我的性格分析 | 年度复盘、自我成长 | 客观指出行为盲区,直面真实自我 |
| 群聊精华 | 工作群 999+、兄弟群日常 | 新闻播报风格总结,不错过重要信息 |
| 心智蓝图 | 长期合作伙伴、亲密关系 | 解码思维模式、决策逻辑、信任建立方式 |
| 动漫化双人模仿 | 娱乐玩梗 | 创作日式动漫风格对话脚本 |
每个模板都经过反复打磨,不是简单的"总结聊天",而是有洞察、有温度、有可执行建议的深度分析。

我的使用体验
用"需求洞察"分析编程群,AI 帮我从几千条消息里提取出 15 个高频痛点和 8 个产品机会,直接确定了下个项目做什么。
用"我的性格分析"看自己和朋友的聊天,发现自己"经常打断别人""喜欢讲道理而忽略情绪",虽然扎心但确实是成长的起点。
用"群聊精华"分析兄弟群,生成的"本月最沙雕言论 Top5"做成海报发到群里,笑果拉满。

常见问题
数据安全吗? 所有数据本地处理,不上传云端。
需要懂技术吗? 不需要。选对象、选时间、选模板、点生成,就这么简单。
支持哪些 AI? 兼容 OpenAI API 格式的服务都支持(GPT-4、Claude、DeepSeek、智谱等)。
能分析多久的记录? 取决于 AI 模型上下文长度。GPT-4 支持 128K tokens,Claude 3.5 支持 200K tokens,一般能处理几万条消息。
立即开始
下载地址 : GitHub Release (支持 macOS 和 Windows)
首次使用建议:
- 先用"群聊精华"试试手,选个活跃的群,分析最近一周的记录,感受一下效果
- 然后尝试"对方性格分析"或"需求洞察",体验深度分析的价值
- 如果觉得好用,可以研究一下自定义 Prompt,解锁更多玩法
遇到问题?
- GitHub Issues: 提交问题
为什么要做这个项目
做 EchoSoul 之前,我以为这只是个周末小项目:读取微信聊天记录,调用 AI API,生成报告,应该很简单吧?
结果遇到了三个大坑,每个都够我折腾好几天:
- chatlog 不是开箱即用的库 - 只提供 CLI 工具,需要自己封装完整的服务层
- 如何设计提示词 - 简单的提示词只能得到机械总结,没有洞察和温度
- AI 生成报告要 30-60 秒 - 如何让等待不枯燥,体验不拉胯
这三个问题,每个都值得单独写一篇文章。下面我会讲讲我是怎么一个个解决的,以及踩过的坑。
第一道坎:封装 chatlog
问题: 如何读取微信聊天记录?
微信的聊天记录存储在加密的 SQLite 数据库中,没有官方 API。幸运的是,我找到了 chatlog 这个开源库。
转机与挑战
看到 chatlog 的时候我以为问题解决了,结果发现它只提供了 3 个命令行工具:
chatlog key- 提取密钥chatlog decrypt- 解密数据库chatlog server- 启动 HTTP 服务
这些命令需要你自己封装、管理进程、处理错误。这才是真正的难点。
解决方案: 自建完整的服务层
我构建了 5 个核心服务来封装 chatlog:
- WeChatDetectionService - 检测微信进程,找到数据目录
- WeChatKeyService - 提取加密密钥
- WeChatDatabaseService - 解密数据库
- ChatlogProcessService - 管理 chatlog server 进程
- ChatlogApiService - 封装 HTTP 接口
关键技术: 如何找到微信数据目录?
微信 v3 的目录结构相对固定,我用 lsof、handle.exe 分析微信进程打开的文件,反推数据目录:
typescript
// 1. 找到微信进程
const { stdout } = await execa('pgrep', ['-f', 'WeChat'])
const pid = parseInt(stdout.trim())
// 2. 分析进程打开的文件
const { stdout: files } = await execa('lsof', ['-p', pid.toString(), '-F', 'n'])
// 3. 从文件路径反推数据目录
for (const filePath of files.split('\n')) {
if (filePath.includes('msg_0.db')) {
return { dataDir: path.dirname(path.dirname(filePath)), version: 3 }
}
}当前限制 : 目前 EchoSoul 只支持微信 3.x 版本 。微信 4.0+ 的数据库结构有较大调整,还在适配中。如果你有相关经验,欢迎到 GitHub Issues 一起讨论解决方案!
完整流程:
检测微信进程 → 提取密钥 → 解密数据库 → 启动服务 → 读取消息每一步都有错误处理、超时控制、状态管理。这部分开发比我想象的复杂的多,但用户使用时是完全感知不到的,因为体验就是"一键初始化"。
第二道坎:设计有灵魂的提示词
问题: 如何让 AI 生成真正有价值的报告?
拿到聊天记录后,我兴冲冲地写了个简单的提示词:
"请分析这段聊天记录,总结对方的性格特点。"
结果 AI 给我返回了一堆正确的废话:
"该用户性格开朗,善于沟通,逻辑清晰..."
这不是我想要的。我要的是:
- 有具体证据支撑的洞察
- 能指导实际沟通的建议
- 让人看完有收获感的分析
我的方案: 精心设计提示词模板
经过反复打磨,我总结出了 4 个核心设计原则:
1. 证据至上 - 所有结论必须来自聊天记录,不能瞎编
不能说"该用户性格开朗",而要说:
"从这句话可以看出:"2024-01-15 14:23 张三: 哈哈哈这个想法太棒了!我们可以...",该用户展现出积极响应他人想法的特质。"
2. 聚焦目标 - 分析谁就只看谁的发言
双人聊天记录中,要明确告诉 AI:"你的分析目标是对方名称,我的消息仅用于提供对话背景。"避免 AI 混淆分析对象。
3. 优势优先 - 发掘亮点而非挑刺
同样的行为模式,可以有不同的解读角度:
- 负面视角:"该用户话少,可能不善社交"
- 优势视角:"该用户惜字如金,每次发言都直击要点,是高效沟通者"
我选择后者,让用户看完报告有收获感而非挫败感。
4. 结构化输出 - 不是一大段文字,而是分维度呈现
每个维度包含:
- 观察结论
- 引用证据(带时间戳的原文)
- 潜在优势
- 沟通建议
实战案例:"对方性格分析"的设计
这是最复杂的一个模板,包含:
- 角色定位: "你是一位资深心理学家,善于在对话中洞察人心"
- 分析工具箱: 6个维度(沟通风格、情感内核、认知框架、人际动力、价值体系、MBTI预测)
- 工作流程: 数据筛选 → 通读欣赏 → 确定维度 → 深入分析
- 输出格式: 核心闪光点 → 人物画像 → 分维度分析 → MBTI预测
每个维度都要求 AI 给出:
- 具体的行为证据
- 这个特质的潜在优势
- 如何与对方更好沟通的建议
消息格式化: 极简主义
相比提示词的复杂,消息格式化反而很简单:
typescript
const formatMessages = messages
.map((msg) => `[${msg.time}] ${msg.senderName}: ${msg.content}`)
.join('\n')每条消息格式化为 [时间] 发送者: 内容,然后直接喂给 AI。现代大模型的理解能力足够强,简单格式反而更稳定。
第三道坎:让等待不枯燥
问题: AI 生成报告要 30-60 秒,用户会不会等得不耐烦?
这是体验设计的关键问题。如果用户只能看到 loading 动画转圈圈,30 秒会感觉像 3 分钟。
我的方案: 流式渲染
让用户能实时看到报告一个字一个字地生成出来,就像有人在给你写分析报告。这样等待变得可感知,体验完全不同。
技术实现: 三个关键环节
- AI 流式输出 - 调用 AI API 时开启
stream: true,逐块接收响应 - Electron IPC 实时传递 - 主进程收到 chunk 后立刻推送给渲染进程
- Markdown 增量渲染 - 使用 streamdown 库实时渲染,不会重新渲染整个文档
完整的数据流:
scss
AI API (流式) → 主进程 (IPC) → 渲染进程 (streamdown) → 用户看到体验优化细节:
- 增量保存: 每收到 100 个 chunk 就保存一次,防止生成中途崩溃
- 状态管理: idle → generating → completed,清晰的状态机
- 错误处理: 超时、网络中断、AI 服务不可用,都有友好提示
海报生成: 一键分享到朋友圈
报告生成后,可以用 markdown-to-image 转成海报。我配置了渐变背景、合适的字体和间距,颜值在线,可以直接分享。
技术栈总结
最终用到的核心库:
- electron-vite - 构建工具,HMR 体验丝滑
- chatlog - 微信数据库解密的基石
- better-sqlite3 - SQLite 操作,M 芯片记得 rebuild
- streamdown - Markdown 流式渲染,体验关键
- markdown-to-image - 海报生成,配置简单
- execa - 执行系统命令,比原生 API 好用
- tweakcn - Tailwind 多主题支持
写在最后
从"周末小项目"到解决三个大坑,再到打磨出 6 个提示词模板,EchoSoul 的开发过程比我想象的复杂得多。但自己用下来,经常被 AI 生成的报告惊艳到------那些我完全没注意到的沟通模式、被忽略的需求信号、藏在日常对话里的洞察,都被一一提炼出来。
我们每天都在产生海量的聊天记录,但很少有人真正从中获得洞察。EchoSoul 想做的,就是把这些被忽略的对话,变成你成长的养分。
这是个开源项目,也意味着它还有很多不完美:微信 4.0+ 还在适配、更多 Prompt 模板等待设计。如果你有想法、有技术、或者只是想提个建议,都欢迎到 GitHub 一起参与。
下载试用 → 给个反馈 → 觉得有用就 Star 一下 → 转发给需要的朋友
愿你不再被聊天淹没,而是被洞察点亮。🌟