人们记录灵感的方式有很多种,笔记是一种很好的方式,但仅仅通过文字的方式似乎有些局限。我更喜欢画板的方式,通过图形+文字的方式,把一个想法拆成几块,连上关系,再补两行注释,思路会自己"跑起来"。这一版简化文章,专门讲我在 Inspira Board 里接入腾讯混元的过程:不是堆参数,不是喊口号,而是把"生文/生图/生3D"这些能力安安稳稳地搬进一个画布+笔记的工作台里,给它们安排具体岗位、明确输入输出、可回放、可替换。写完之后,我希望任何人拿着这套思路,都能在自己项目里复刻一遍。
我怎么把"模型能力"放进一张日常用的白板
我的第一步并不是写网络请求,而是画一张小图:输入是什么、过程怎么走、输出去哪。最后定了一个朴素的流程:把"具体问题"转换成"结构化提示",用混元的接口拿到"可落地的结构化结果",再把结果变成画布上的对象(或者 Markdown 里的段落、图片、3D资源链接)。这听起来像是废话,但它逼着我把每一步都还原到看得见的东西上。
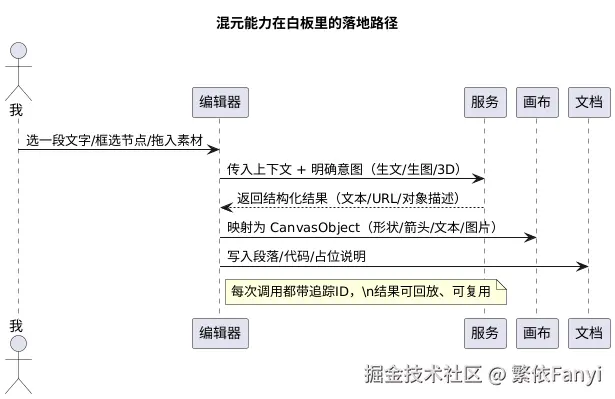
这张小图决定了三件事:
- 我尽量不让"模型"去发号施令,模型只提供建议或生成素材,主导权在我。
- 所有结果都结构化,能回放、能映射、能导出,不让内容"散"在 UI 里。
- 失败路径要能兜住:超时/不合适/风格不对,一键回滚或再试一次。
先让"生文"长在笔记里:不是"通天文案",而是"能用的段落"
在项目里,文字不是"越多越好"的大段话,而是可插可改的段落。实际做法是:我只给混元一个明确的目标,比如"帮我把这五个要素合成一个流畅段落,长度控制在 120~180 字,避免口号"。返回结果进 Markdown,保留上下文链接,便于追踪。
我把模型请求描述放进一个可复用的数据模型里,核心字段不复杂:model、messages、一些影响输出多样性的参数,以及增强/工具开关。chat_models.dart 已经准备好了这些模型结构,这里给出最精简的一段 Dart 代码,演示如何发一个"生成段落"的请求:
dart
import 'core/services/tencent/models/chat_models.dart';
ChatCompletionRequest buildWriteParagraphReq(String topic, String[] bullets) {
return ChatCompletionRequest(
model: "hunyuan-pro",
messages: [
ChatMessage.system("你是一个严谨的技术写作者,语言自然,避免口号"),
ChatMessage.user("请把以下要点组合为一段流畅段落,120-180字,避免空话:\n主题: $topic\n要点:\n- ${bullets.join("\n- ")}"),
],
temperature: 0.6,
topP: 0.9,
enableEnhancement: false, // 生文不需要开启搜索
stream: false,
seed: 7,
);
}这段落生成不是"黑盒"。我会把请求参数与返回内容一起写入笔记的 metadata,方便以后回看与重用。一段简短的回放记录在 Front Matter 里就够用了。
markdown
---
title: 社区运营方案草稿
source: hunyuan
trace_id: 20251008-para-001
prompt_profile: "写作-短段落-120~180字"
---
在做社区运营的过程中,我更在意可复用的动作,而不是一次性的大型活动。...这样做的好处是"收敛":我不追求千奇百怪的语气,反而更喜欢稳定的模板,能从一个段落跑到下一段落;更重要的是,团队里另一个人看见这段文字,也知道它怎么来的,可以用同一套路再生成一个版本。
把"生图"接到画布的手上:生成的不是一张"海报",而是一个"素材位"
我不指望一次请求就得到"完美的图"。我的诉求是"给我一个合适的底图/插画",然后让我在画布里去摆位置、叠图层、配文字。生成图像的接口返回来的是 URL 或文件路径,我把它落成一个 ImageObject,带上基础的变换参数(位置、缩放、旋转),同时把"来源/风格/版权"写进对象的 metadata。
在项目里我会这么做:
- 从剪贴板或图像选择器拿到素材提示词(比如"蓝灰色、几何风的技术插图,用于表示数据流")。
- 调用"生图",拿到 URL。
- 在画布中心插入一张图片对象,scale 默认 0.8,rotation 0。
- 自动切到选择工具(select),让我直接调整它。
这个过程用一张时序图就讲清楚了:
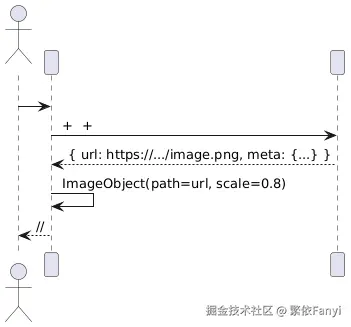
工程上我做了个小约束:生成回来的图片必须可复用。我把 URL、生成参数、时间戳都保存在 WBX 的资源里,导出后同样能落盘。以后我回看这张图的时候,能知道它最初的来源。
不是"自动布局",而是"给我草图建议":生文+结构生成的组合拳
这里是我最喜欢的一段:选择一段"要素"列表,让混元给一个"结构化的草图建议"。这个建议不是图片,而是一份 CanvasObject-like 的 JSON。比如我列出"语法/模型/渲染/交互/导出/协同",模型给我建议"六个矩形+箭头方向+一个小标题的位置"。我把它映射成 Shape/Arrow/TextObject,马上就能在画布里动手调整。
我在请求里会附带清晰的约束:节点最小尺寸、横向网格、颜色建议、箭头连线从左到右。返回结果要尽量简单,能直接落地。
dart
ChatCompletionRequest buildSketchReq(List<String> nodes) {
final hints = """
请输出 JSON,不要多余文字:
{
"objects": [
{"type":"shape","shapeType":"rectangle","id":"m1","start":[200,150],"end":[420,230],"label":"语法"},
{"type":"shape","shapeType":"rectangle","id":"m2","start":[200,260],"end":[420,340],"label":"模型"},
{"type":"arrow","from":"m1","to":"m2"}
],
"theme":{"grid": 20, "palette":"calm"}
}
""";
return ChatCompletionRequest(
model: "hunyuan-pro",
messages: [
ChatMessage.system("你是结构化草图助手,输出可映射到画布的对象描述"),
ChatMessage.user("要素: ${nodes.join(", ")}\n"+hints),
],
temperature: 0.4,
enableEnhancement: false,
stream: false,
);
}接下来就是映射器的工作:把这些对象转成 CanvasObject。矩形变 ShapeType.rectangle,箭头从 from/to 对象中心推导 start/end。第一次渲染出来可能"不是很好看",但我只要两三下移动与缩放,就能到我想要的布局。相比"自动布局一次到位",我更喜欢"可编辑的半成品"。
多轮对话不是"闲聊",而是"任务对齐"
我做过一个时间盒:在 10 分钟内,用三轮交互把一张流程图走通。第一轮:用要素列表生成草图;第二轮:指定某两个节点加一个中间状态;第三轮:让所有连线都从左到右。我把每一轮都当作一次明确的任务,不聊"是不是更美观",只聊"能不能实现"。
多轮消息在 chat_models.dart 里就是 messages 的列表。这里有两个细节我觉得很关键:
- 每一轮把"上下文归纳"作为第一条消息:上一轮做了什么,这一轮的目标是什么,避免模型在语境里迷路。
- 用 seed 固定住风格:参数不变时,输出更稳定,适合在团队里复现同一个结果。
用"生3D"做占位,不打断绘制节奏
视频和 3D 的素材生成更重,我不把它塞到"主流程"。我的做法是:在笔记里创建一个"素材任务块",填入提示与参数,调用接口后拿到 URL 或资源 ID,先放到文档里,画布侧只插入一个"占位卡片"(带封面图、时长/大小),用户愿意时再去"替换成可播放的缩略图"或者"导入 3D 预览"。
这件事解决了两个烦恼:一是重资源不会卡住画布交互;二是素材和场景的关系清清楚楚,查看历史也容易。下面这张小图我觉得很形象:
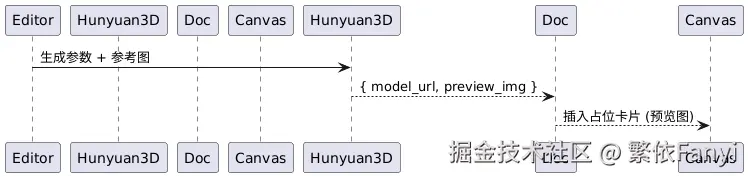
这种"占位卡片"的策略看似保守,但在多人协作时特别稳:谁都不会被大资源下载拖住,也不会出现"卡死后一切未保存"的惨剧。
我尽量少开"增强开关":什么时候需要,什么时候不需要
chat_models.dart 里有一堆参数:enableEnhancement、searchInfo、citation、enableDeepSearch、enableThinking......我不追求"都开"。我的经验是:
- 生文和结构化草图建议:不开增强,给模型一个清晰边界,输出更稳。
- 需要查事实/引用:开启 searchInfo 与 citation,让引用可见。写完记得把引用条目一起落到文档末尾。
- 长篇内容拆解/理解:enableDeepRead 对长文更友好,但要控制输出长度,否则容易跑偏。
- 多模态:enableMultimedia 在"图文混排"的任务很有用,比如让模型顺手给落图片的 alt 文案。
稳定性来自"少而稳"的开关策略。另一个稳定来源是"工具闭环":tools/toolChoice/customTool 在某些场景里能让模型"只做一件事",比如只输出 JSON,不解释,不聊天。
我喜欢"留痕":每一份结果都能追溯来源
这部分我几乎是强迫症:每一段文字、每一张图、每一个 3D 占位,都在 metadata 里留下时间戳、trace id、提示摘要。对图片,我会记一笔色板/风格标签;对段落,我会记字数与关键词。这样做不复杂,但救命:回看历史、滚动版本、对比两个结果之间的差别,一眼就能看出来。
WBX 作为工程文件的容器非常适合记这些东西。对象是强类型(CanvasObject),持久化是通用 Map(WbxObject),二者之间桥接一下就能互通。我的标准是:WBX 打开以后,任何一个对象我都能读出"是谁、什么时候、用什么提示生成的"。
代码片段:我用到的最小必要"生文/草图/插图"组合
为了避免一不小心就绕进"写 SDK"的坑,我只留下最小必要的粘合层。三个函数足够跑起来:
dart
Future<String> writeParagraph(String topic, List<String> bullets) async {
final req = buildWriteParagraphReq(topic, bullets);
final resp = await hunyuanChat(req); // 你自己的 HTTP 封装
final text = resp.choices.first.message?.content ?? "";
// 保存痕迹
notesService.appendParagraph(text, meta: {"trace": resp.id, "topic": topic});
return text;
}
Future<List<CanvasObject>> suggestSketch(List<String> nodes) async {
final req = buildSketchReq(nodes);
final resp = await hunyuanChat(req);
final jsonText = resp.choices.first.message?.content ?? "{}";
final map = json.decode(jsonText) as Map<String, dynamic>;
final ast = DiagramParser().parse(json.encode(map)); // 复用 Parser
final objs = AstMapper().toCanvasObjects(ast);
canvasNotifier.addObjects(objs);
return objs;
}
Future<ImageObject> genIllustration(String prompt) async {
final imageUrl = await hunyuanImage(prompt, size: "1280x720"); // 返回 URL
final pos = canvasCenter();
final obj = ImageObject(
id: uuid.v4(), path: imageUrl,
position: DrawingPoint(x: pos.dx, y: pos.dy),
width: 640, height: 360, layerId: "default",
);
canvasNotifier.addImage(obj);
return obj;
}它们并不"高大上",但我喜欢这种"能跑、能复用、能逐渐加料"的形态。哪天你想多加一个"自动上色"的步骤,也不过是在 suggestSketch 的输出上再套一层样式映射。
失败路径与兜底策略
- 返回结果格式不对:先尝试用正则提取 JSON,失败就降级为"把纯文本写进文档",让人来补充。
- 图片 URL 失效:显示占位符并提供"一键重试"按钮,保留原始提示词,参数不变再生成一次。
- 生成内容不合适:保留历史版本,允许"回滚到上一版",用 seed 固定住风格,重试只调轻微参数。
- 网络超时:UI 侧给出明确的状态提示,结果返回后自动合并,别让用户等"黑盒"。
我更愿意把它叫"人机协作的节拍器"
写到这里,你可能发现我尽量避免那些听起来"更像 AI"的话。我在乎的是"音乐的节拍感":人给出主题和节奏,模型提供稳定、可复用的段落/结构/素材,最后还是人来完成作品。这种方式的好处是:不会在推进中断,也不会在准备时拖延;任何一个环节坏了,都有退路。
如果你也打算参加关于混元的大模型实践征文,我的建议是:贴近一个真实的场景,不要怕"手动";把"生文/生图/生3D"拆成不同的岗位,按节拍接入;把每一步的输入输出做成"看得见摸得着"的对象或文件。这样,你的分享就不只是"能做什么",而是"怎么做,怎么复用,怎么协作"。
最后放一张总览图,收个尾。
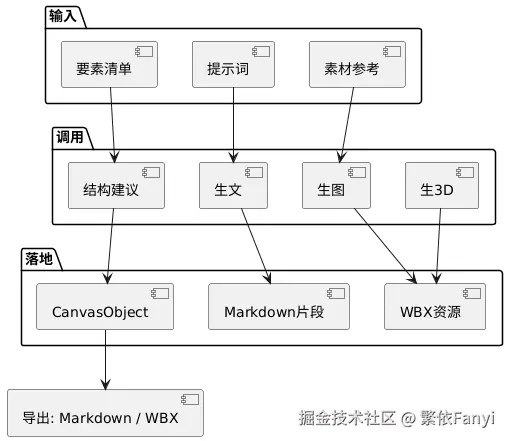
这就是我在 Inspira Board 里用混元做事的方式。它不追求"神奇",只追求"好用";它不求一步到位,只求一步稳一步;它不想替代谁,只是想把每一天的工作与创作,变得更顺手一点。