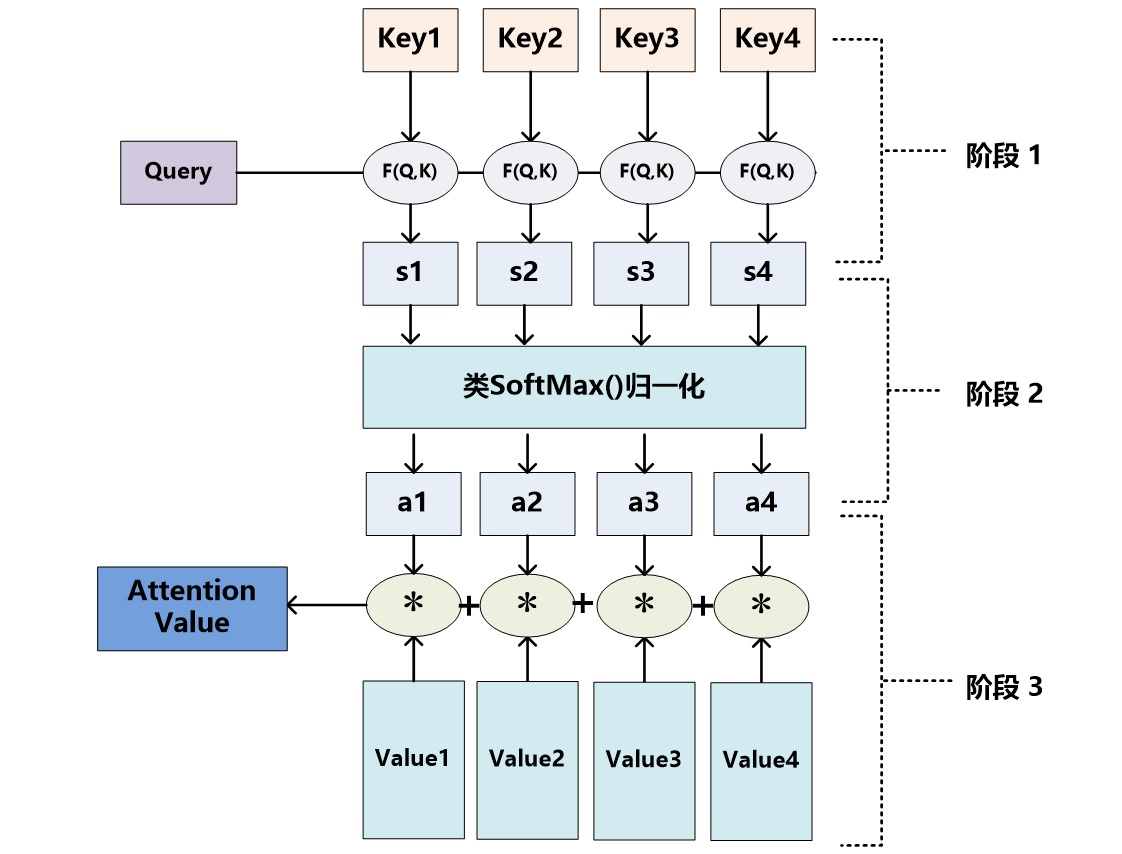
多头注意力机制(MultiheadAttention)是Transformer架构中的核心组件,通过并行计算多个注意力头,使模型能够同时关注输入序列中不同表示子空间的信息 ,从而更有效地捕捉长距离依赖和复杂模式。MultiheadAttention通过将输入特征分割到多个子空间并独立计算注意力,然后合并结果,实现了更强大的序列建模能力。
一、MultiheadAttention介绍
1.1 结构
-
输入层 :序列数据,形状为
(batch_size, seq_len, embed_dim)的张量 -
MultiheadAttention层:
-
核心机制:
- 查询投影(Query Projection):将输入转换为查询向量
- 键投影(Key Projection):将输入转换为键向量
- 值投影(Value Projection):将输入转换为值向量
- 多头分割:将投影后的特征分割到多个注意力头
- 缩放点积注意力:每个头独立计算注意力权重
- 头合并:将多个头的输出拼接并投影回原始维度
-
可学习参数:
- 投影权重 :
in_proj_weight,形状为(3 * embed_dim, embed_dim) - 输出投影权重 :
out_proj.weight,形状为(embed_dim, embed_dim) - 偏置项 :
in_proj_bias和out_proj.bias,形状均为(embed_dim,)
- 投影权重 :
-
-
激活函数:
- 注意力权重计算 :使用
Softmax函数,确保权重和为1 - 值变换:通常使用线性变换,但可结合非线性激活函数
- 注意力权重计算 :使用
-
多头机制的意义:
- 并行处理:多个注意力头同时计算不同的表示子空间
- 多样化捕捉:每个头关注序列中不同类型的关系模式
- 计算效率:将高维注意力计算分解为多个低维计算
- 表示能力增强:通过多头机制获得更丰富的序列表示
1.2 参数
- embed_dim:模型的总维度,必须是num_heads的倍数
- num_heads:并行注意力头的数量,每个头的维度为embed_dim // num_heads
- dropout:注意力权重的dropout概率,默认0.0
- bias:是否在输入/输出投影层添加偏置,默认True
- add_bias_kv:是否为key和value序列在dim=0添加偏置,默认False
- add_zero_attn:是否在key和value序列的dim=1添加零批次,默认False
- kdim:key的特征维度,默认None(使用embed_dim)
- vdim:value的特征维度,默认None(使用embed_dim)
- batch_first :输入输出张量格式,
False为(seq, batch, feature),True为(batch, seq, feature)
1.3 输入输出维度
在 batch_first=True 模式下,输入张量维度如下:
- Query(查询) :
(Batch Size, Query Sequence Length, Query Embedding Dimension) - Key(键) :
(Batch Size, Key Sequence Length, Key Embedding Dimension) - Value(值) :
(Batch Size, Value Sequence Length, Value Embedding Dimension)
输出维度如下:
- 注意力输出 (attn_output) :
(Batch Size, Query Sequence Length, Output Embedding Dimension) - 注意力权重 (attn_output_weights) :
- 当
average_attn_weights=True(默认):(Batch Size, Query Sequence Length, Key Sequence Length),表示每个批次中每个查询位置对所有键位置的平均注意力权重 - 当
average_attn_weights=False:(Batch Size, Number of Attention Heads, Query Sequence Length, Key Sequence Length),提供每个注意力头的独立权重,便于分析不同头的注意力模式
- 当
| 参数类型 | 维度格式 | 关键含义 |
|---|---|---|
| Query 输入 | (N, L, E_q) | 批量大小 × 查询序列长度 × 查询嵌入维度 |
| Key 输入 | (N, S, E_k) | 批量大小 × 键序列长度 × 键嵌入维度 |
| Value 输入 | (N, S, E_v) | 批量大小 × 值序列长度 × 值嵌入维度 |
| 注意力输出 | (N, L, E) | 批量大小 × 查询序列长度 × 输出嵌入维度 |
| 注意力权重(平均) | (N, L, S) | 批量大小 × 查询序列长度 × 键序列长度 |
| 注意力权重(分头) | (N, H, L, S) | 批量大小 × 注意力头数 × 查询序列长度 × 键序列长度 |
- 维度一致性 :Query Embedding Dimension (E_q) 必须等于模块的
embed_dim参数 - 灵活配置 :Key 和 Value 的嵌入维度(E_k, E_v)可通过
kdim和vdim参数独立设置,默认等于embed_dim参数 - 序列长度独立性:Query Sequence Length (L) 和 Key Sequence Length (S) 可以不同,支持跨序列注意力计算
- 输出维度稳定 :注意力输出维度始终与
embed_dim保持一致,无论输入维度如何变化
python
import torch.nn as nn
attention_layer = nn.MultiheadAttention(embed_dim=512, num_heads=8, batch_first=True)
output, weights = attention_layer(query, key, value)在 attention_layer(query, key, value) 调用中,Query、Key、Value 的来源取决于具体的注意力类型和应用场景。以下是常见来源的总结表格:
| 注意力类型 | Query 来源 | Key 来源 | Value 来源 | 典型应用场景 |
|---|---|---|---|---|
| 自注意力 (Self-Attention) | 输入序列 | 输入序列 | 输入序列 | Transformer 编码器、BERT、文本分类 |
| 交叉注意力 (Cross-Attention) | 目标序列 | 源序列 | 源序列 | Transformer 解码器、机器翻译、文本生成 |
| 编码器-解码器注意力 | 解码器输出 | 编码器输出 | 编码器输出 | Seq2Seq 模型、语音识别 |
| 记忆检索注意力 | 查询向量 | 记忆键 | 记忆值 | 问答系统、知识检索 |
| 多头键值注意力 | 外部查询 | 键序列 | 值序列 | 推荐系统、个性化建模 |
在 PyTorch 的 MultiheadAttention 中:
- Query、Key、Value 的来源是灵活的,取决于具体任务和注意力类型
- 自注意力是最常见的形式,Q、K、V 都来自同一输入
- 交叉注意力广泛用于序列到序列任务,Q 来自目标序列,K/V 来自源序列
- 模块不关心输入的具体来源,只负责根据给定的 Q、K、V 计算注意力
- 正确的来源选择对模型性能至关重要,需要根据任务需求设计
1.4 计算过程
见这两篇文章:
深度学习:注意力机制(Attention Mechanism)
论文解读:Attention Is All You Need
二、代码示例
通过多头注意力层处理一段音频频谱,打印每层的输出形状、参数形状,并可视化特征图。
python
import torch
import torch.nn as nn
import matplotlib.pyplot as plt
import matplotlib
import librosa
import numpy as np
matplotlib.rcParams['axes.unicode_minus'] = False # 解决负号 '-' 显示为方块的问题
matplotlib.rcParams['font.family'] = 'Kaiti SC' # 可以替换为其他字体
# 定义多头注意力模型
class MultiheadAttentionModel(nn.Module):
def __init__(self, input_size, embed_dim, num_heads):
super(MultiheadAttentionModel, self).__init__()
# 输入投影层(可选,用于调整输入维度)
self.input_proj = nn.Linear(input_size, embed_dim)
# 多头注意力层
self.attention = nn.MultiheadAttention(
embed_dim=embed_dim,
num_heads=num_heads,
batch_first=True
)
def forward(self, x):
# 输入投影
projected = self.input_proj(x)
# 多头注意力(自注意力模式)
attn_output, attn_weights = self.attention(projected, projected, projected)
return projected, attn_output, attn_weights
# 读取音频文件并处理
file_path = 'test.wav' # 替换为您的音频文件路径
waveform, sample_rate = librosa.load(file_path, sr=16000, mono=True)
# 选取3秒的数据
start_sample = int(1.5 * sample_rate)
end_sample = int(4.5 * sample_rate)
audio_segment = waveform[start_sample:end_sample]
# 转换为频谱
n_fft = 512
hop_length = 256
spectrogram = librosa.stft(audio_segment, n_fft=n_fft, hop_length=hop_length)
spectrogram_db = librosa.amplitude_to_db(np.abs(spectrogram))
spectrogram_tensor = torch.tensor(spectrogram_db, dtype=torch.float32).unsqueeze(0)
spectrogram_tensor = spectrogram_tensor.permute(0, 2, 1) # (batch, seq_len, input_size)
print(f"Spectrogram tensor shape: {spectrogram_tensor.shape}")
# 创建多头注意力模型实例
input_size = spectrogram_tensor.shape[2]
embed_dim = 128 # 嵌入维度
num_heads = 8 # 注意力头数量
model = MultiheadAttentionModel(input_size, embed_dim, num_heads)
# 前向传播
projected, attn_output, attn_weights = model(spectrogram_tensor)
# 打印输出形状
print("\n=== 输出形状 ===")
print(f"投影后输出形状: {projected.shape}")
print(f"注意力输出形状: {attn_output.shape}")
print(f"注意力权重形状: {attn_weights.shape}")
# 打印参数形状
print("\n=== 参数形状 ===")
print("输入投影层:")
print(f" 权重: {model.input_proj.weight.shape}")
print(f" 偏置: {model.input_proj.bias.shape}")
print("\n多头注意力层:")
print(f" 输入投影权重: {model.attention.in_proj_weight.shape}")
print(f" 输入投影偏置: {model.attention.in_proj_bias.shape}")
print(f" 输出投影权重: {model.attention.out_proj.weight.shape}")
print(f" 输出投影偏置: {model.attention.out_proj.bias.shape}")
# 可视化
plt.figure(figsize=(15, 10))
# 原始频谱
plt.subplot(2, 2, 1)
plt.imshow(spectrogram_db, aspect='auto', origin='lower', cmap='inferno')
plt.title("原始频谱")
plt.xlabel("时间帧")
plt.ylabel("频率点")
plt.colorbar(format='%+2.0f dB')
# 投影后特征
plt.subplot(2, 2, 2)
plt.imshow(projected[0].detach().numpy().T, aspect='auto', origin='lower', cmap='viridis')
plt.title("投影后特征")
plt.xlabel("时间步")
plt.ylabel("特征维度")
plt.colorbar(label='特征值')
# 注意力输出
plt.subplot(2, 2, 3)
plt.imshow(attn_output[0].detach().numpy().T, aspect='auto', origin='lower', cmap='plasma')
plt.title("注意力输出")
plt.xlabel("时间步")
plt.ylabel("特征维度")
plt.colorbar(label='特征值')
# 注意力权重(平均)
plt.subplot(2, 2, 4)
plt.imshow(attn_weights[0].detach().numpy(), aspect='auto', cmap='viridis')
plt.title("注意力权重(平均)")
plt.xlabel("键位置")
plt.ylabel("查询位置")
plt.colorbar(label='注意力权重')
plt.tight_layout()
plt.savefig('attention_spectrogram_features.png', dpi=300)
plt.show()
python
Spectrogram tensor shape: torch.Size([1, 188, 257])
=== 输出形状 ===
投影后输出形状: torch.Size([1, 188, 128])
注意力输出形状: torch.Size([1, 188, 128])
注意力权重形状: torch.Size([1, 188, 188])
=== 参数形状 ===
输入投影层:
权重: torch.Size([128, 257])
偏置: torch.Size([128])
多头注意力层:
输入投影权重: torch.Size([384, 128])
输入投影偏置: torch.Size([384])
输出投影权重: torch.Size([128, 128])
输出投影偏置: torch.Size([128])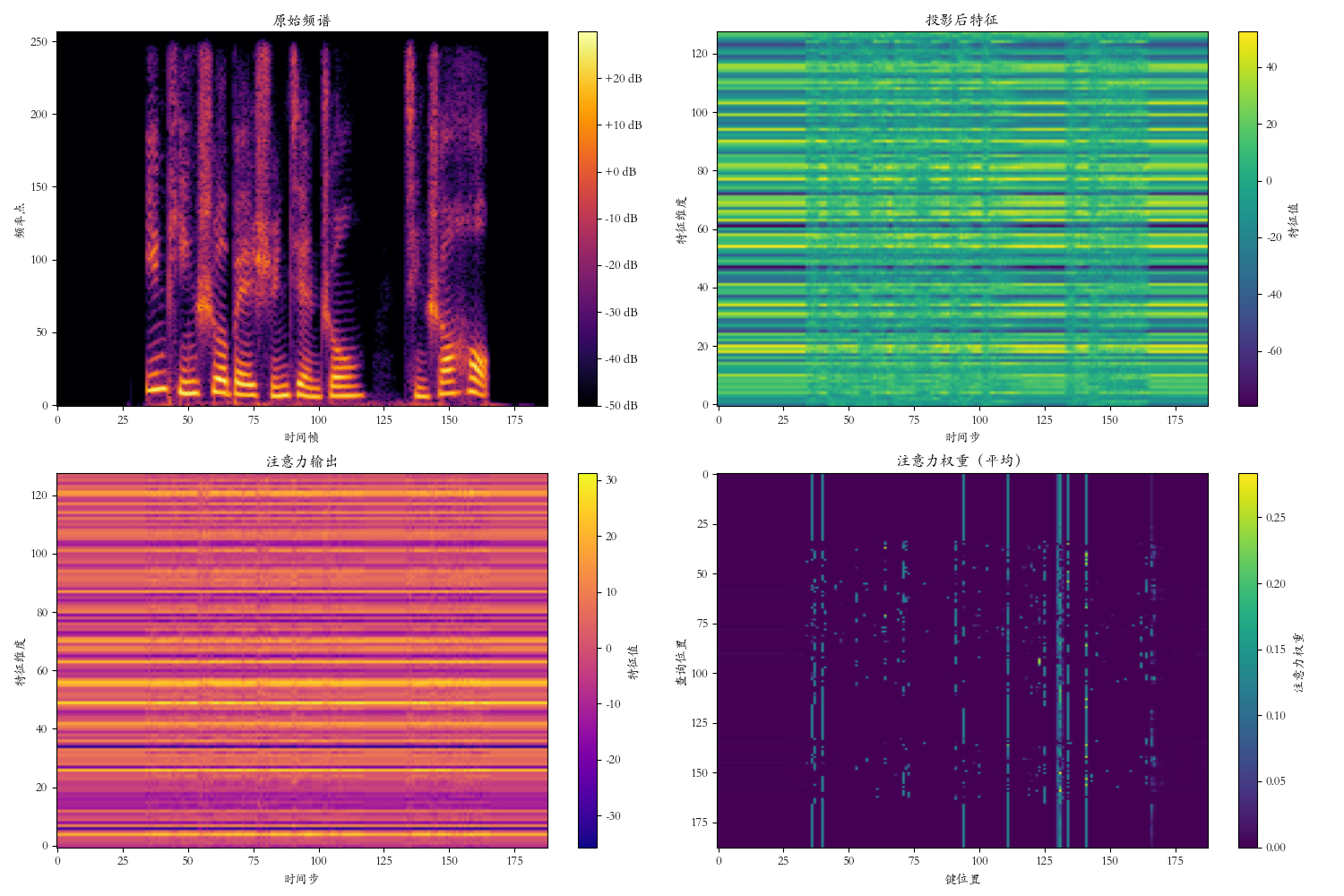
python
attn_output, attn_weights = self.attention(projected, projected, projected)-
self.attention是一个多头注意力层,通常是通过nn.MultiheadAttention创建的。它实现了多头自注意力机制,能够处理输入序列并计算注意力权重。 -
这一行代码的输入参数为
projected,这是经过输入投影层处理后的特征张量,形状为(batch_size, seq_length, embed_dim)。它被传递了三次,分别作为查询(Query)、键(Key)和值(Value)。 -
自注意力机制,在这里,使用相同的张量作为查询、键和值,表示模型在处理输入序列时关注自身的不同部分。这种方式称为自注意力(Self-Attention),允许模型在序列的不同位置之间建立关系。
python
在多头注意力机制中,即使使用相同的张量作为查询(Query)、键(Key)和值(Value),模型仍然能够学习到丰富的特征表示,这主要归功于以下关键机制:
1. 可学习的线性变换(核心机制)
虽然输入是相同的张量,但在内部计算过程中,模型会应用不同的可学习线性变换:
# 内部计算过程(简化表示)
Q = projected @ W_q # 查询变换
K = projected @ W_k # 键变换
V = projected @ W_v # 值变换
• W_q, W_k, W_v:三个独立的可学习权重矩阵
• 这些权重矩阵在训练过程中学习不同的特征表示
• 即使输入相同,不同的变换会产生不同的特征表示
2. 多头机制(多视角学习)
多头注意力将嵌入维度分割为多个"头",每个头有自己的变换:
# 多头分割
Q_heads = split_heads(Q) # [batch, num_heads, seq_len, head_dim]
K_heads = split_heads(K)
V_heads = split_heads(V)
• 每个头学习不同的表示子空间
• 不同头关注输入的不同方面
• 即使输入相同,多头机制提供多视角分析
3. 注意力计算(动态加权)
注意力机制的核心是计算权重并加权求和:
# 注意力计算
attention_scores = softmax(Q @ K.T / sqrt(d_k))
attn_output = attention_scores @ V
• 动态权重分配:根据输入内容动态计算权重
• 内容相关:权重取决于输入特征之间的关系
• 位置无关:权重基于内容相似度,而非固定位置
4. 特征增强过程
使用相同输入的自注意力实际上是一种特征增强:
1. 特征变换:通过W_q, W_k, W_v学习不同的特征表示
2. 关系建模:计算元素之间的相似度关系
3. 信息聚合:基于相似度加权聚合特征
4. 特征精炼:输出包含全局上下文的新特征
5. 类比理解
想象一位艺术家画自画像:
• 相同输入:艺术家本人(就像相同的输入张量)
• 不同视角:
• 镜子反射(W_q变换)
• 照片参考(W_k变换)
• 自我感知(W_v变换)
• 最终作品:融合多视角的独特自画像(就像attn_output)
6. 实际学习过程
在训练中:
1. 随机初始化:W_q, W_k, W_v初始化为不同值
2. 梯度下降:通过反向传播独立更新三个矩阵
3. 专业化:每个矩阵学习不同的特征提取模式
• W_q:学习如何构建有效的查询
• W_k:学习如何创建可匹配的键
• W_v:学习如何编码有价值的信息attn_output:这是多头注意力层的输出,形状为(batch_size, seq_length, embed_dim)。它是通过对值(Value)进行加权求和得到的,权重由查询(Query)和键(Key)之间的相似度计算得出。attn_weights:这是注意力权重,形状为(batch_size, num_heads, seq_length, seq_length)。它表示每个查询位置对所有键位置的注意力分配。每个头的权重矩阵显示了模型在计算输出时关注的不同部分。