【 音频标注】 - 音频标项目调研
- 背景
- 音频标注工具
- 音频标注样本
-
- [1. 数据源评分排序表格](#1. 数据源评分排序表格)
- [2. 样本标注类型小结](#2. 样本标注类型小结)
- [3. 样本案例](#3. 样本案例)
-
- [3.1 Common Voice](#3.1 Common Voice)
-
- [clip_durations.tsv 文件内容格式如下](#clip_durations.tsv 文件内容格式如下)
- validated_sentences.tsv文件内容格式如下:
- [3.2 VoxCeleb](#3.2 VoxCeleb)
- [3.3 CLESC-dataset(CLESC|语音分析数据集|情感识别数据集)](#3.3 CLESC-dataset(CLESC|语音分析数据集|情感识别数据集))
- [3.4 小结](#3.4 小结)
- 重难点分析
- 工作量预估
- 现有最佳音频标注方法探讨
- 意义价值和未来业务拓展
-
-
- 一、业务拓展方向
-
- [1. AI训练数据服务](#1. AI训练数据服务)
- [2. 智能标注工具/平台输出](#2. 智能标注工具/平台输出)
- [3. 垂直行业解决方案](#3. 垂直行业解决方案)
- [4. 数据资产商业化](#4. 数据资产商业化)
- 二、可实现的核心功能
- 三、稳定收入来源
- 四、公司定位与类型
- 五、公司规模发展
-
背景
最近可能开始一个音频标注项目,之前没接触过,本文调研一下音频标注工具、样本、重难点、工作量预估、最佳音频标注方法探讨、意义价值和未来业务拓展。
音频标注工具
关于音、视频领域样本标注的工作,从提问反馈来看,豆包明显比元宝更专业。豆包给出的音频标注工具(多模态样本标注工具)推荐列表:
| 工具名称 | 功能覆盖与专业性 | 适用场景广度 | 技术生态与社区 | 综合评分(10分制) |
|---|---|---|---|---|
| Label Studio | 多模态全场景支持(覆盖80+数据类型),企业级协作与AI驱动标注能力突出,自定义模板灵活度高 | 复杂项目、规模化生产、多模态系统集成 | 社区极活跃(GitHub星标超44k),商业化服务完善 | 9 |
| ELAN | 语言学深度标注能力强(多层级标注、毫秒级时间轴同步),跨模态整合与学术工具对接性好 | 学术研究、语言学/跨学科分析 | 学术生态成熟(持续维护20余年),配套资源丰富 | 8 |
| Audio Annotator | 音频垂直领域专业度高(时间戳标注、频谱图可视化等),轻量灵活且AI辅助标注便捷 | 音频专项任务、快速迭代验证 | 社区较活跃(GitHub星标超2k),云原生易扩展 | 7 |
| LabelU | 本地化部署安全,中小项目与新兴任务(如文生音频)针对性优化,但多模态覆盖偏窄 | 中小团队、数据敏感型场景 | 生态较弱但侧重国内用户易用性,针对性功能完善 | 6 |
重点关注推荐的前2工具。不得不说,至少看起来是,豆包在它的领域还是很专业的。
音频标注样本
需要了解音频标注后样本长什么样以及音频标注的类型分为几种,以此大致了解标注过程和结果产出。让豆包推荐若干个网络开源音频样本并按质量打分排序。
1. 数据源评分排序表格
| 数据源类型 | 具体名称 | 数据规模 | 标注丰富度(标签维度/精细度) | 领域普适性(覆盖场景) | 获取便捷性(下载/使用门槛) | 综合评分(10分) |
|---|---|---|---|---|---|---|
| 通用语音数据集 | Common Voice | 10万+小时,多语言 | 文本转写、基础标签(性别、口音) | 通用ASR等多场景 | 开源免费,官网直接下载 | 9.5 |
| 通用语音数据集 | VoxCeleb | 10万+音频片段 | 说话人ID精准标注 | 仅说话人识别 | 开源免费,官网直接下载 | 8.5 |
| GitHub 资源 | 开源仓库(如ltu、bootphon) | 各仓库规模不一,整体中等 | 语音识别、音频问答、音素等多样 | 学术+工程多场景 | GitHub直接下载,开源免费 | 8 |
| Kaggle 竞赛数据 | 竞赛数据集(如Vesuvius) | 竞赛级中等规模 | 语音+图像联合标注,精细度高 | 竞赛特定场景 | Kaggle注册后下载 | 7.5 |
| 特定领域数据集 | CLESC-dataset | 500个语音样本 | 语速、音高、音量、情感等多维度 | 通用语音特征分析 | 特定平台,下载便捷 | 7 |
| 学术研究数据集 | IEMOCAP | 10小时多模态数据 | 情感、对话行为等多模态标注 | 学术(情感、多模态) | 需合规申请,获取有一定门槛 | 7 |
| 工具内置示例 | Label Studio 内置示例 | 小(示例性质) | 时间戳、文本转写、情感标签 | 通用语音转写示例 | 安装工具后直接生成 | 6 |
| 特定领域数据集 | 华为云自动驾驶音频数据集 | 场景化示例,规模小 | 时间戳、场景标签、元数据 | 仅自动驾驶场景 | 短链接访问,下载便捷 | 5.5 |
| 工具内置示例 | Magic Data Annotator 内置示例 | 小(示例性质) | 说话人分段、转写文本 | 客服场景 | 免费版直接使用 | 4.5 |
各数据集下载链接
| 数据集名称 | 下载链接 |
|---|---|
| Common Voice | https://commonvoice.mozilla.org |
| VoxCeleb | https://www.robots.ox.ac.uk/\~vgg/data/voxceleb/ |
| CLESC-dataset | https://www.selectdataset.com/dataset/1545a5919c9aea4628f5c669147c1473 |
| 华为云自动驾驶音频数据集 | http://www.shurl.cc/68cb0f406e2896b08097242fa81cb3a6 |
| IEMOCAP | https://sail.usc.edu/iemocap/ |
| LTU-AS 模型标注数据集(GitHub) | https://github.com/YuanGongND/ltu |
| bootphon-datasets(GitHub) | https://github.com/bootphon/bootphon-datasets |
| Vesuvius 竞赛数据集(Kaggle) | https://www.kaggle.com/c/vesuvius-challenge-ink-detection/data |
| Label Studio 内置示例 | (安装 Label Studio 后创建项目自动生成,无单独下载链接) |
| Magic Data Annotator 内置示例 | (使用 Magic Data Annotator 免费版时自动提供,无单独下载链接) |
2. 样本标注类型小结
主要得看变量 "标注丰富度(标签维度/精细度)",总结起来,主要有如下3种标注类型,对应多种不同的标注格式和内容:
(1)人声音频 -> 文本、人ID、情感、语速、音高、音量、情感、行为、按说话人分段
(2)非人声音频 -> 场景
(3)多模态(音、图)-> 场景、情感
3. 样本案例
3.1 Common Voice
进入链接
https://commonvoice.mozilla.org下载数据
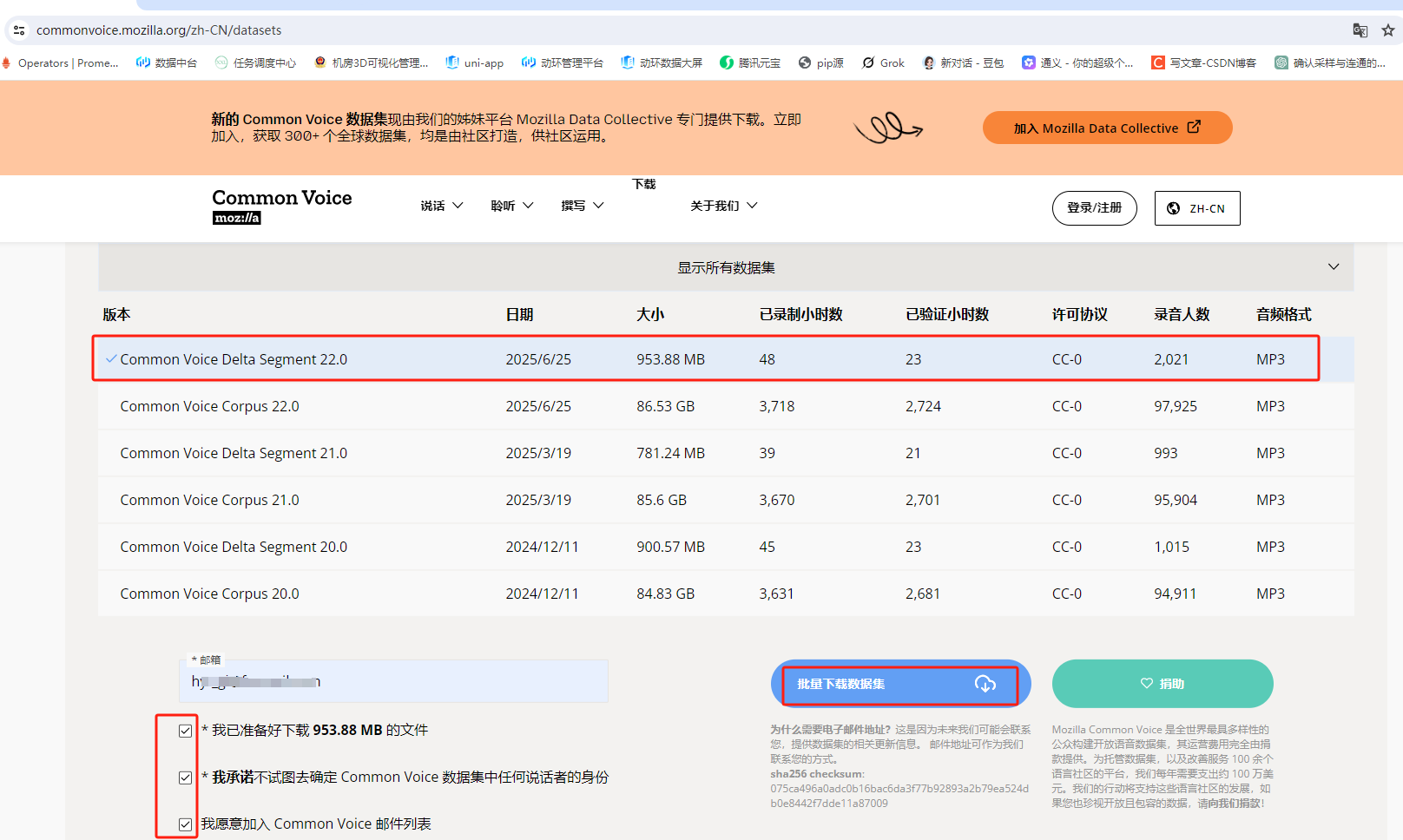
数据样本下载下来,格式如下,其中clips文件夹中是.mp3格式的音频文件。
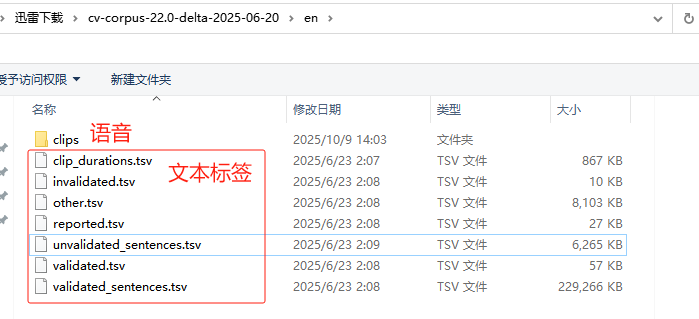
clips外部是7个.tsv格式的样本标签文件。整体不太规则,看不出来一一对应关系,需进行进一步的数据处理(.tsv 一般只用于源数据,按行存储,每行一条样本,固定分隔符)。其中
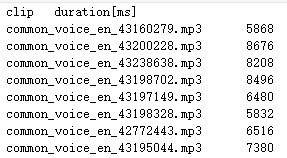
clip_durations.tsv 文件内容格式如下
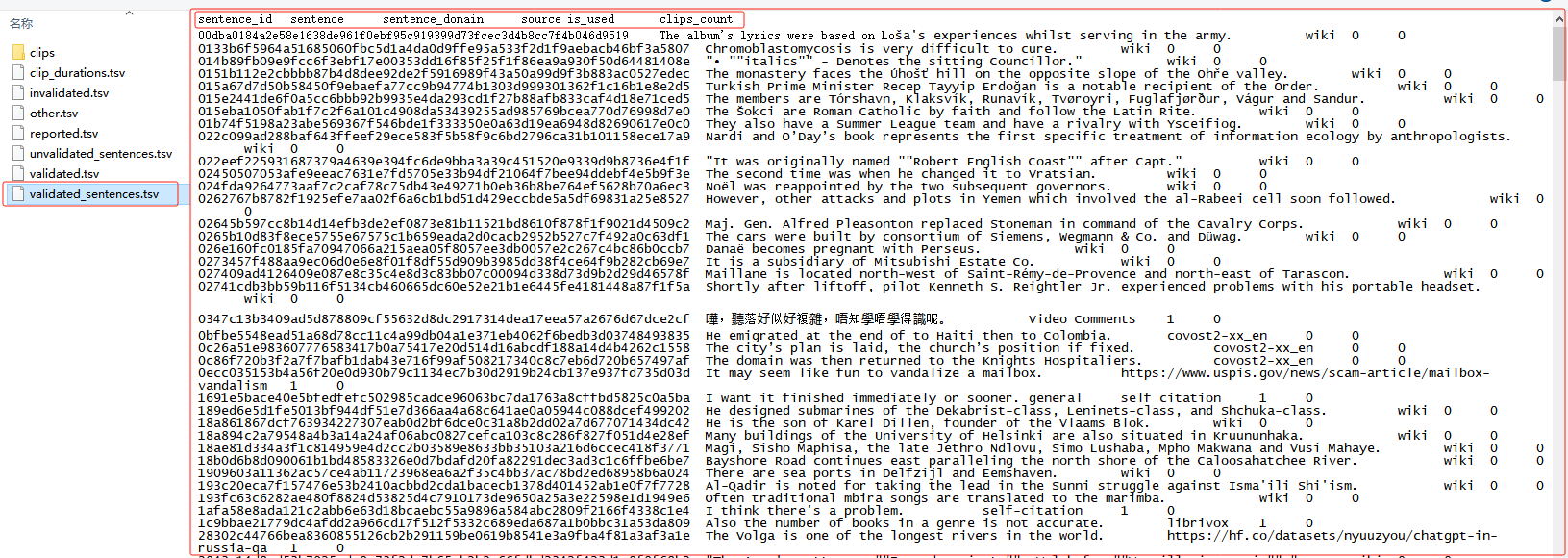
validated_sentences.tsv文件内容格式如下:
其它标签文件内容格式与此类似。clips文件夹中只有音频文件如下
3.2 VoxCeleb
进入链接:
https://www.robots.ox.ac.uk/~vgg/data/voxceleb/vox1.html有如下图的下载页面
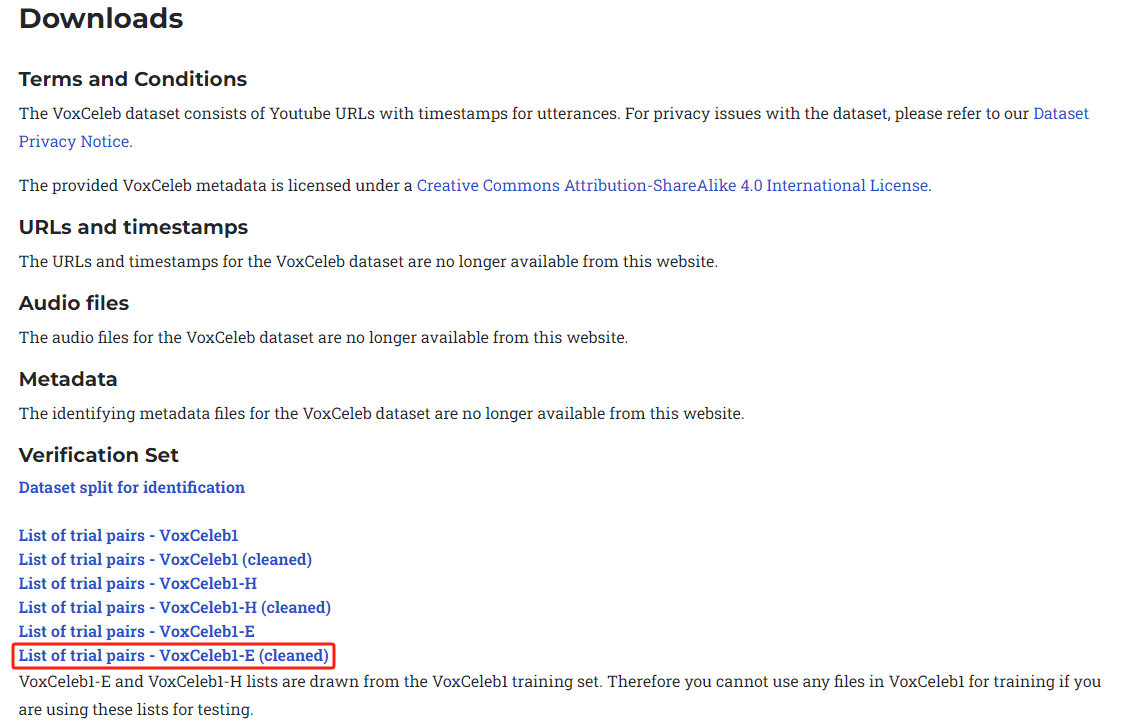
点击下载,得到如下格式内容的 txt 文件:
1 id10001/Y8hIVOBuels/00001.wav id10001/1zcIwhmdeo4/00001.wav
0 id10001/Y8hIVOBuels/00001.wav id10943/vNCVj7yLWPU/00005.wav
1 id10001/Y8hIVOBuels/00001.wav id10001/7w0IBEWc9Qw/00004.wav
0 id10001/Y8hIVOBuels/00001.wav id10999/G5R2-Hl7YX8/00008.wav
1 id10001/Y8hIVOBuels/00002.wav id10001/7w0IBEWc9Qw/00002.wav
0 id10001/Y8hIVOBuels/00002.wav id10787/qZInQxuCSVo/00008.wav
1 id10001/Y8hIVOBuels/00002.wav id10001/7w0IBEWc9Qw/00005.wav
0 id10001/Y8hIVOBuels/00002.wav id11022/BEtpH-sCXjc/00010.wav
1 id10001/Y8hIVOBuels/00003.wav id10001/utrA-v8pPm4/00001.wav
0 id10001/Y8hIVOBuels/00003.wav id10253/bqEyl0msaB0/00008.wav
1 id10001/Y8hIVOBuels/00003.wav id10001/J9lHsKG98U8/00003.wav
0 id10001/Y8hIVOBuels/00003.wav id10222/kCV1i3qhM38/00021.wav
1 id10001/Y8hIVOBuels/00004.wav id10001/J9lHsKG98U8/00001.wav
0 id10001/Y8hIVOBuels/00004.wav id10900/Yaq9vi2lqlY/00001.wav
1 id10001/Y8hIVOBuels/00004.wav id10001/J9lHsKG98U8/00014.wav3.3 CLESC-dataset(CLESC|语音分析数据集|情感识别数据集)
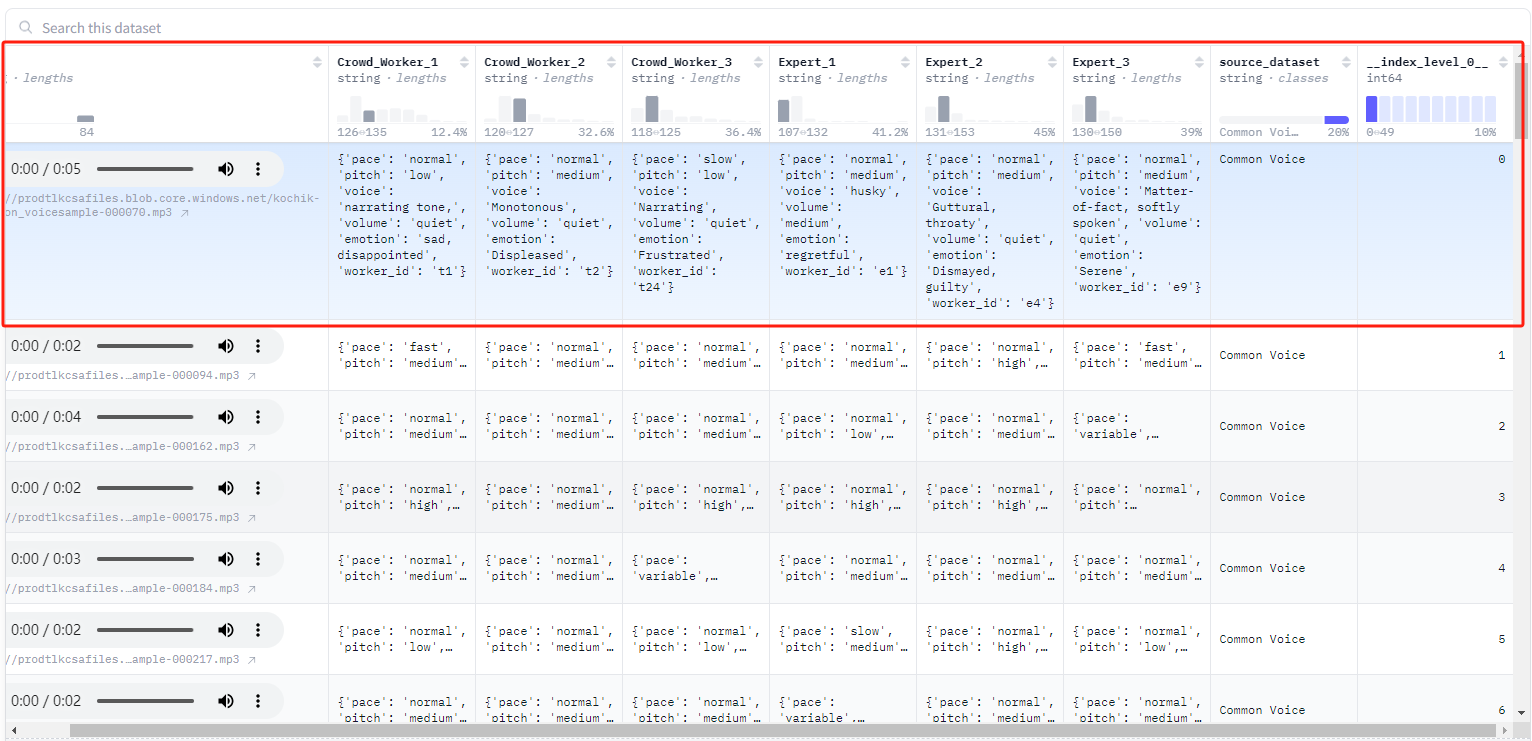
进入链接
https://huggingface.co/datasets/toloka/CLESC/viewer/default/train?views%5B%5D=train&row=0看到数据集如下(多标注者数据集,便于对比不同标注者的结果,有机会获得更好的标签口径上的统一)
3.4 小结
- 不成熟、非标;音频领域目前仍处于发展期,至少不是成熟期,数据样本集,标签标注流程都完全没统一,不像图像领域那样成熟和标准化;
- 很多中间工具可能需自己实现;不同的音频样本标注文件完全不同,可见在音频标注领域做项目,要弥补的基础事务应该还比较多,没有视频领域这么省事儿;
- 答案开放式、多样化;每个专家的标注都不太相同,看起来,音频标注,目前很难标准化。
- 多标签的模型训练起来,每个标签是单独训练还是联合训练?(我理解应该是联合训练)
重难点分析
1. 标注准确性与一致性
标注标准难统一 :音频包含丰富的信息维度,如语音内容、情感、语速、口音等,不同标注者对这些维度的理解和判断可能存在差异。 例如在情感标注中,对于一段音频所表达的情感是 "沮丧" 还是 "失落",不同标注人员可能有不同的看法;在口音标注时,对于某些接近两种口音特征的音频,也难以精准界定。
标注的稳定性受主观因素影响 :标注者的状态、知识背景、经验等主观因素会影响标注结果。比如标注者当天的情绪、疲劳程度,以及是否熟悉特定领域的术语等 。若标注者对医学、法律等专业领域不熟悉,在标注专业领域音频时就容易出现错误。
复杂音频场景下标注困难 :在嘈杂环境、多人同时说话、音频信号弱等复杂场景下,准确提取和标注有效信息极具挑战。例如在街头录制的音频,可能同时包含车辆噪音、行人交谈声等,要从中清晰分辨出目标语音内容并准确标注难度很大。
- 标注效率
标注工具功能限制 :部分标注工具可能缺乏高效的音频处理功能,如不能方便地进行音频剪辑、快速定位时间点、实时预览标注效果等,导致标注过程繁琐,影响效率。 例如,在标注长音频时,如果工具不能快速跳转到指定时间点,标注人员就需要花费大量时间拖动进度条查找。
音频内容的连续性 :音频是时间序列数据,具有连续性,标注时需要逐句甚至逐字听取,无法像图像标注那样快速浏览整体内容。 对于较长的音频文件,标注人员需要花费大量时间完整听取,这大大降低了标注效率。
标注任务的重复性 :在大规模音频标注项目中,可能存在大量相似音频片段的标注,容易使标注人员产生疲劳和厌倦情绪,导致注意力不集中,进而影响标注效率和质量。
3. 标注的可扩展性与灵活性
应对多样化的标注需求 :随着音频应用场景的不断拓展,对音频标注的需求也日益多样化。例如,除了传统的语音内容转写、情感标注外,现在还出现了针对语音合成的韵律标注、针对自动驾驶的环境声音事件标注等新需求,这要求标注项目能够快速适应并满足这些变化。
处理大规模数据 :在实际应用中,为了训练出高性能的模型,往往需要大规模的音频数据进行标注。如何在保证标注质量的前提下,高效地处理和管理大规模标注任务,实现标注流程的可扩展性,是一个关键问题。例如,如何合理分配标注任务,避免任务分配不均导致部分标注人员任务过重,而部分人员闲置。
4. 标注结果的评估与质量控制
缺乏统一的评估标准 :对于音频标注结果,目前没有一套完全统一且适用于所有场景的评估标准。不同的标注任务,如语音识别标注和情感分析标注,其评估重点和方法差异很大,这给全面、客观地评估标注质量带来了困难。
质量控制的复杂性:要对标注结果进行有效的质量控制,需要耗费大量的人力和时间。例如,通过抽检的方式检查标注结果,对于大规模标注数据来说,抽检比例难以确定,抽检过少可能无法发现潜在问题,抽检过多又会增加成本;而且即使发现了问题,如何准确追溯到标注人员并进行有效的修正指导,也是比较复杂的问题。
工作量预估
如果自动化标注(NLP技术或LLM)无法实现足够的精度,那就是灾难级的苦活累活。
现有最佳音频标注方法探讨
目前没有绝对"最好"的音频标注方法,核心取决于标注目标(精度 / 效率 / 成本)、数据规模、应用场景,但结合行业实践和技术发展,"场景化混合标注体系(AI 预标注 + 人工修正 + 领域定制化质控)"是当前综合性能最优的方案,可根据不同需求灵活适配。
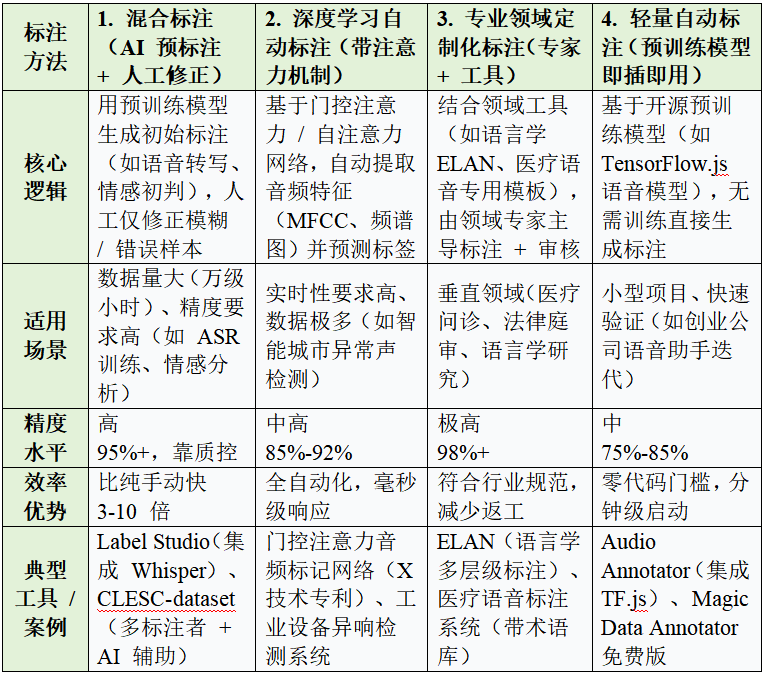
1. 推荐方案 :场景化混合标注体系。
真正高效的音频标注不是依赖单一方法,而是围绕需求构建"模型选择 + 人工介入 + 质量控制"的闭环体系。
2. 步骤:
(1)第一步 :按场景选 AI 预标注模型(决定效率下限)
通用语音转写(ASR)、声音事件检测(如异响、环境声)、情感 / 声学特征标注(语速、音高);
(2)第二步 :精准人工介入(决定精度上限)
人工聚焦3类高价值场景:模糊样本修正、领域术语把关、多标注者交叉验证;
(3)第三步 :自动化质量控制(保障稳定性)
实时校验、抽样评估。
3.小结 - 当前行业共识
混合标注 是平衡 "精度、效率、成本" 的最优解 ,而其核心竞争力在于 "AI 模型与场景的匹配度 " 和 "人工介入的精准度 "。
大模型标注 的精准度显著优于 一般 NLP 方法,尤其在复杂场景(多语言、强噪声、垂直领域)中优势更明显。
一般 NLP 方法(如传统 ASR 模型、简单 CNN 分类模型),预标注正确覆盖度通常在 50%-70%,转写错误率较高,需人工修正40%以上 的内容。
大模型标注(如Label Studio集成的Whisper、CLESC-dataset的多模态模型)可覆盖80%以上的正确标注内容,结合多智能体构建 定制的自检流程,还能进一步提升预标注的准确度。
大模型预标注后,人工仅需处理"低置信度样本" (如置信度 < 90% 的多人重叠说话片段),1小时音频标注仅需 3-5 小时(无大模型辅助时需10-15小时)。
- 一些音频标注工具
(1)分轨
| 模型名称 | 核心优势 | 适用场景 | 分离精度 | 算力需求 | 开源资源与工具支持 |
|---|---|---|---|---|---|
| Conv-TasNet | 1. 端到端时域分离,无需频谱转换,减少信息损失 2. 支持动态调整分离说话人数量(2-4人效果最优) 3. 推理速度快,适合实时分轨场景 | 实时会议录音分轨、电话通话双方/多方语音分离、低延迟语音交互系统 | 中高(干净环境下4人对话分离SI-SNRi可达18-22dB) | 低-中(轻量级架构,支持CPU轻量化部署,GPU加速更优) | - 官方开源:PyTorch实现(GitHub含相关分支) - 工具集成:可直接接入生态,支持批量处理 |
| FastSpeech 2(分离适配版) | 1. 引入说话人声纹嵌入(Speaker Embedding),对说话人特征区分度高 2. 分离后语音音质好,减少失真(尤其适用于人声保留) 3. 支持结合文本信息优化分离(如已知对话脚本时精度提升) | 高质量访谈录音分轨、播客多人对话后期处理、需要保留语音自然度的场景(如有声书多人配音分离) | 高(相同环境下比Conv-TasNet高2-3dB,语音MOS评分提升0.3-0.5) | 中-高(需额外加载声纹模型,推理速度比Conv-TasNet慢15%-20%,建议GPU部署) | - 开源实现:GitHub可修改适配分离任务 - 配套工具:需搭配声纹提取模型(如声纹编码器)使用 |
| Whisper + 分离模块(如Conv-TasNet) | 1. 借助Whisper预训练语音特征(如Mel谱、语音语义特征),抗噪声能力强 2. 支持多语言对话分离(如中英混合多人对话) 3. 可结合Whisper的语音识别结果,辅助修正分离错误(如区分说话人话术) | 嘈杂环境下的对话分轨(如餐厅、户外多人交流录音)、多语言会议记录分轨、需同步生成文字稿的分轨场景 | 高(嘈杂环境下SI-SNRi比单独Conv-TasNet高3-5dB,多语言场景优势明显) | 高(需同时加载Whisper模型与分离模型,显存占用较大,仅建议GPU部署) | - 开源方案:GitHub含分离模块 - 工具链:支持与转录工具联动,实现"分轨+转写"一体化 |
| DPRNN-TasNet | 1. 在Conv-TasNet基础上加入双路径循环网络(DPRNN),增强长时语音依赖捕捉能力 2. 对长对话(如30分钟以上会议)分离稳定性优于Conv-TasNet 3. 对说话人切换频繁的对话适配性更好 | 长时长会议录音分轨(如1小时以上研讨会)、说话人频繁交替的对话分离(如辩论、访谈) | 中高(长对话场景下分离稳定性比Conv-TasNet高10%-15%) | 中(比Conv-TasNet增加约20%算力消耗,支持GPU及高性能CPU部署) | - 官方开源:GitHub含PyTorch实现 - 文档支持:配套论文提供详细参数配置,便于快速复现 |
(2)识别
| 模型名称 | 核心特点 | 关键参数指标 | 适用场景 |
|---|---|---|---|
| Whisper-large-v3 | 支持超100种语言,泛化能力强,准确率极高;无优化时推理速度慢、资源消耗大 | 模型参数约15亿 | 需要处理多语言任务且对识别准确率要求高的应用(如多语言会议转录) |
| Belle-whisper-large-v3-zh | 针对中文优化,提升中文方言/口音识别精度,保留多语言能力;非中文表现稍逊 | 模型参数与原版一致(约15亿) | 中文语音识别任务,尤其需处理方言(如粤语、川语)或复杂口音的场景 |
| Whisper-large-v3-turbo | 通过蒸馏/量化技术优化,推理速度更快、资源占用更低;平衡准确率与性能,极致准确率略有妥协 | - 推理速度优于原版 - 资源消耗低于原版 | 对实时性要求高(如实时语音转文字)或计算资源有限(如边缘设备)的应用 |
| Faster-Whisper | 基于CTranslate2实现,大幅优化推理速度与内存占用;支持CPU/GPU推理 | 比原版推理速度快约4倍 | 需要高效推理且有能力配置复杂环境(如CUDA、cuDNN)的用户(如企业级转录系统) |
| WhisperX | 集成Faster-Whisper,新增语音活动检测(VAD)与强制对齐功能;提供单词级时间戳 | - 支持单词级时间戳 - 适配长音频处理 | 需要精确时间戳(如字幕生成、语音片段定位)的长音频转录任务(如播客、讲座) |
| Distil-Whisper | 通过知识蒸馏压缩模型,减少参数量与推理时间;准确率接近原版,仅支持相对时间戳 | - 参数减少51% - 速度提升5.8倍 | 对转录速度要求高且对时间戳精度要求不高的任务(如短音频快速转文字) |
| Whisper-Medusa | 增加解码头并行预测多token,进一步加速推理;不支持长音频转录 | - 平均速度提升1.5倍 - 对VRAM要求高 | 短音频的快速转录任务(如语音消息、短句指令转文字) |
意义价值和未来业务拓展
若实现了接近自动化的高质量高精度音频标注能力,可从业务拓展、功能落地、收入模式、公司定位、规模发展等维度全面延伸:
一、业务拓展方向
1. AI训练数据服务
为各类AI企业提供定制化音频标注数据,覆盖场景包括:
- 基础技术:语音识别(ASR)、语音合成(TTS)、声纹识别、情感分析。
- 垂直场景:智能汽车(车内语音指令、异响检测)、智能家居(环境声音识别)、金融客服(语音质检)、医疗(问诊语音、手术场景声音)。
2. 智能标注工具/平台输出
将自动化标注技术封装为软件工具或SaaS平台,面向中小AI团队、科研机构开放:
- 本地部署版:满足车企、医疗等"数据不出内网"的安全需求,按"部署规模+授权时长"收费。
- 云端SaaS版:支持按需使用,按"月订阅费+标注量"盈利(如基础版5000元/月,企业版2万元/月)。
3. 垂直行业解决方案
针对细分领域提供端到端的音频AI落地方案,例如:
- 智能汽车:车内语音交互系统标注+模型训练辅助,助力自动驾驶"听觉感知"。
- 金融:客服语音合规性+情感分析标注,搭配质检系统开发。
- 工业:设备异响标注+故障预警模型,服务工厂智能化运维。
4. 数据资产商业化
将积累的高质量标注数据集(如多语种方言库、特殊场景音频库)打包,面向:
- 科研机构:出售学术研究用数据集(如"1000小时罕见病问诊语音库")。
- 企业:授权AI模型训练使用(如"百万小时多语种语音标注库"永久授权)。
二、可实现的核心功能
- 自动化多维度标注:AI自动识别语速、音调、情感、语义、声学特征等,支持自定义标注体系。
- 多模态融合标注:结合音频与文本、图像(如视频音频+画面同步标注),满足复杂AI任务。
- 智能预标注+人工修正:AI先预标注(如语音转写、情感初判),人工仅需少量修正,效率提升数倍。
- 标注质量自动化校验:算法自动检测标注一致性、准确性,替代80%以上人工质检。
- 灵活工作流配置:支持不同行业的标注流程定制(字段、审核规则、输出格式)。
三、稳定收入来源
- 数据服务收入:按"标注量(小时数)+ 精度 + 定制化"分级收费(如普通转写0.5元/分钟,高精度情感+语义标注5元/分钟)。
- 工具/平台收入 :
- 软件授权:向企业售永久授权,按部署规模收费(如单服务器授权5万元)。
- SaaS订阅:云端平台按月/年订阅(基础版5000元/月,企业版2万元/月)。
- 垂直解决方案收入:定制化项目收费(如汽车行业方案,单项目50万-200万元)。
- 数据集销售收入:稀缺数据集按"授权次数/永久授权"销售(如多语种库售价50万-500万元)。
四、公司定位与类型
成立**"AI数据智能服务公司"(或"智能音频标注技术公司"),定位为"AI训练数据全流程解决方案提供商"**,聚焦音频及多模态数据的标注、处理与工具创新。
五、公司规模发展
- 初期(1-2年) :团队10-30人(算法+产品+销售),聚焦1-2个垂直领域,年营收百万级。
- 中期(3-5年) :团队50-100人,工具/方案覆盖数十家头部客户,年营收千万级。
- 长期(5年+) :成为行业头部,团队200人+,业务全球化,年营收数亿级,向"全类型AI数据服务"或"垂直行业AI方案"延伸。
核心逻辑:从"技术能力(自动化标注)"延伸到"服务(数据+工具+方案) ",再通过"多维度收入 "实现商业闭环,最终成长为AI数据领域的标杆企业。