1. 引言
PDF(Portable Document Format)是一种以"视觉一致性"为核心的文档格式。
它与普通文本文件不同,PDF 并不直接存储"字符信息",而是存储"绘制指令"------包括字体、大小、坐标和字形路径等信息。
为了确保文档在任意平台上显示完全一致,PDF 引入了一个复杂的 字体系统(Font System) 与 编码机制(Encoding System) 。
这种机制虽然保证了跨平台的稳定性,但也带来了诸如"乱码""复制错误""字体缺失"等常见问题。
要理解并修复这些问题,必须从 PDF 的底层结构出发,深入了解其字体与编码的设计逻辑。
2. 字体对象(Font Object)
2.1 字体对象的作用
PDF 中的字体对象定义了页面上使用的文字应如何被绘制。
它并不是具体的文字内容,而是描述文字外观的容器,包含字体名称、类型、编码方式、字形信息等。
一个典型的字体对象示例如下:
css
7 0 obj
<<
/Type /Font
/Subtype /Type0
/BaseFont /ABCDEE+SimSun
/Encoding /Identity-H
/DescendantFonts [8 0 R]
/ToUnicode 9 0 R
>>
endobj2.2 字体对象关键字段说明
| 字段 | 含义 |
|---|---|
/Subtype |
字体类型:Type1、TrueType(简单字体)或 Type0(复合字体) |
/BaseFont |
字体名称;带前缀如 ABCDEE+ 表示"子集字体" |
/Encoding |
字符编码方式,如 /WinAnsiEncoding、/Identity-H |
/DescendantFonts |
复合字体(Type0)中指向实际字形数据的 CIDFont 对象 |
/ToUnicode |
定义字符代码与 Unicode 的对应关系(用于复制与搜索) |
2.3 字体类型概览
| 类型 | 特征 | 适用场景 |
|---|---|---|
| Type1 / TrueType / Type3 | 单字节字体(最多256个字符) | 西文字体、符号 |
| Type0 + CIDFontType0 / 2 | 多字节复合字体(支持上万字符) | 中文、日文、韩文 |
Type0 是 PDF 为 CJK 文字设计的复合字体结构,通过 CID(Character ID)与 CMap 实现多字节字符支持。
3. 编码结构(Encoding Structure)
PDF 的编码系统定义了"字节 → 字形"的映射关系。
根据字体类型不同,PDF 采用不同的编码机制。
3.1 简单字体编码(Simple Encoding)
简单字体采用单字节映射表,常见定义如下:
/Encoding /WinAnsiEncoding或:
javascript
/Encoding <<
/BaseEncoding /WinAnsiEncoding
/Differences [128 /Euro 130 /quotesinglbase]
>>此类字体最多支持256个字符,常见于英文、符号字体。
3.2 复合字体编码(Composite Encoding)
复合字体通过 CMap 文件建立多字节映射关系,例如:
sql
/Encoding /Identity-H/Identity-H:水平书写的"直通映射",PDF 代码值直接作为 CID;/Identity-V:垂直书写映射;/GB-EUC-H、/UniJIS-UCS2-H等为具体语言映射表。
CMap 的作用是:
把输入的字节序列映射为字体内部的字符ID(CID)。
3.3 ToUnicode 映射
ToUnicode 是一种反向映射,用于将 PDF 内部的字符代码还原为标准 Unicode。
示例如下:
javascript
9 0 obj
<< /Type /CMap /CMapName /ToUnicode >>
stream
begincmap
1 begincodespacerange
<00> <FF>
endcodespacerange
2 beginbfchar
<41> <0041>
<42> <0042>
endbfchar
endcmap
endstream
endobj若 ToUnicode 缺失,则 PDF 仍可显示文字,但复制、搜索、提取文字都会乱码。
4. 字体渲染流程(Font Rendering Process)
PDF 的字体渲染本质上是一个"多层映射"过程。
4.1 显示流程
objectivec
PDF 内容流 (文字代码)
↓
/Encoding 或 CMap
↓
字形 ID (CID)
↓
/FontFile(字形轮廓)
↓
渲染成图形4.2 复制 / 搜索流程
markdown
PDF 内容流 (文字代码)
↓
/ToUnicode
↓
Unicode 字符
↓
文本输出 / 搜索匹配4.3 字体对象间的引用关系
css
Page对象 → /Resources → /Font → [字体对象]
↓
/DescendantFonts → [CIDFont]
↓
/FontDescriptor → /FontFile通过这种层层引用,PDF 能在不依赖系统字体的前提下精确控制显示效果。
5. 字体乱码实例分析
上面理论都比较虚,现在我通过分析一个实际的pdf来展示像pdf.js这种程序到底是如何渲染页面文字内容的。
5.1 问题场景
如下图,这个pdf中中文显示正常,但英文字符部分乱码了。

通过对pdf底层的对象分析,发现页面对象引用了两个字体:
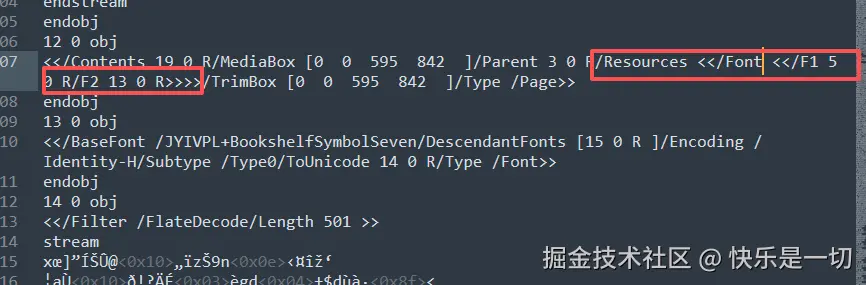
字体的obj对象如下所示
javascript
5 0 obj % 中文字体
<</BaseFont/SEHAGU+DengXian/Encoding/Identity-H/Subtype/Type0>>
endobj
13 0 obj % 符号字体
<</BaseFont/JYIVPL+BookshelfSymbolSeven/Encoding/Identity-H/Subtype/Type0>>
endobj根据上文对字体对象的分析,可以知道这两个字体一个是等线字体,一个是符号字体。然后我们再找到页面中Contents指向的对象流19 0 R。
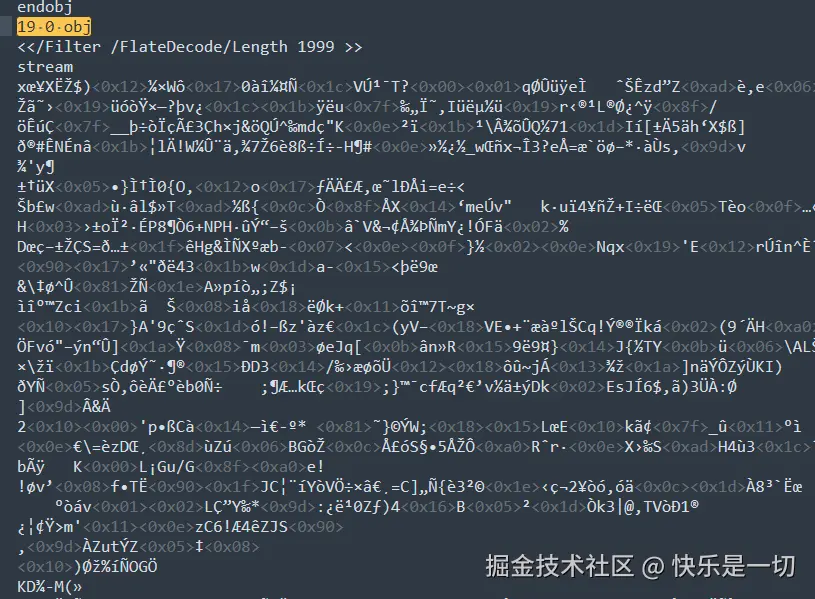 这是一个流式对象,解码为文本格式为:
这是一个流式对象,解码为文本格式为:
 这个其实很好看懂,以下面为例:
这个其实很好看懂,以下面为例:
css
BT
/F1 12 Tf
72.5 760.97 Td
(测试) Tj
/F2 12 Tf
140 737.52 Td
(123) Tj
ET- BT和ET是开始和结束;
- Tj标明渲染的内容;
- Tf标明这段内容使用F1字体,字体大小为12;
- Td标明这段内容渲染的位置
而这篇PDF通过分析发现:
- 中文部分使用
/F1→ DengXian 字体; - 数字部分使用
/F2→ BookshelfSymbolSeven 符号字体; - 因符号字体的字形映射不同,导致数字显示成乱码。
可以看到在实际的pdf中,内容部分是数据和字符串加密后的编码,你找到字体对象
/ToUnicode指向的对象,一般是个流式对象,解压后可以看到他的明文大概是如下图样式,从beginbfrange开始的每一行含义是:<源编码><对应Unicode><实际字符>,意思是上面内容中的023b对应的Unicode编码也是023b,实际的字符是 3001(、号)。

5.2 底层修复方案
如上分析可知,这个pdf字符乱码的主要原因是符号字体的映射错误了,应该映射到f1字体,修改思路如下。
方法一:资源层重定向(推荐)
修改页对象的字体资源:
diff
/Font <<
/F1 7 0 R
- /F2 8 0 R
+ /F2 7 0 R
>>此时 /F2 被重定向到正确字体,内容流无需改动。
方法二:内容流修正
直接将内容流中的 /F2 替换为 /F1:
diff
/F1 12 Tf
(测试) Tj
- /F2 12 Tf
+ /F1 12 Tf
(123) Tj方法三:重新导出
在源文件中统一字体,确保数字和中文使用同一字体。
对于pdf的用户来说,直接选中乱码部分,修改字体为其他正常字体即可
6. 常见的字体错误类型
| 错误类型 | 症状 | 原因 | 修复建议 |
|---|---|---|---|
| 字体未嵌入 | 不同电脑显示不同字体 | 缺少 /FontFile |
重新导出并启用"嵌入字体" |
| 缺少 ToUnicode | 复制、搜索乱码 | 无 /ToUnicode 映射 |
重新生成映射或导出时启用"Unicode支持" |
| 混用字体 | 部分符号乱码 | 内容流切换错误字体 | 统一字体或重定向资源 |
| 错误编码声明 | 特殊字符显示异常 | /Encoding 不匹配 |
修正编码或使用标准映射 |
| Type3 字体兼容性差 | 显示模糊或错位 | 使用绘图命令定义字形 | 转为 TrueType / CIDFont |
| 字体子集冲突 | 同页字体样式不一致 | 重复嵌入多个子集 | 合并字体子集或重新导出 |
7. 总结
PDF 的字体系统由三层结构构成:
- 字体对象层(Font Object)
定义字体类型、名称与引用关系; - 编码层(Encoding / CMap)
决定字符代码与字形之间的映射; - Unicode 层(ToUnicode)
建立 PDF 内部代码与标准字符集的桥梁。
它们共同构成以下逻辑链:
markdown
字符代码 → 编码映射 → 字形 → 显示
↘
ToUnicode → Unicode → 复制/搜索正是这套体系让 PDF 实现了跨平台的视觉一致性。
但由于机制复杂,任何环节出错都会导致乱码或字体异常。
理解 /Encoding、/CMap、/ToUnicode 三者的关系,
是彻底解决 PDF 字体问题的关键。