现如今默认数据的读写都是依赖数据库, 它已经成了一个基础架构,其中的事务为应用程序的正确性提供了可靠的保证。如果追溯在事务之前开发人员是如何开发的,我们便能了解事务到底为我们解决了哪些棘手的问题。
假设我们没有事务,我们在开发一个客户端应用程序。那在读写数据库时会遇到哪些问题呢?
- 数据库或者其运行的机器随时会崩溃。
- 应用程序随时会崩溃。
- 网络随时会变慢或者彻底断联。
- 客户端读数据时,读到部分成功的。
- 并发问题。多个客户端会同时对同一数据进行读写,出现竞态条件。
如果需要每个客户端都去考虑上述问题,那程序员的开发负担可想而知。除了对付业务需求,还要应对这些挑战。但好在这些挑战是偏底层的,和具体业务没有关系,每个涉及数据读写的应用程序都会遇到。数据库的设计人员,抽象出来一个事务的概念,并做出了一系列保证,基于事务去操作数据库,就可以不用担心硬件发生故障、软件崩溃、网络和并发问题。
然而是不是所有数据库都支持事务?事务做了哪些保证?事务是不是银弹,所有场景都需要事务?实现事务需要哪些代价?事务有那么多隔离级别,分别适用何种场景?这些都是我们在使用事务时需要考虑的问题。
事务发展的历史
最早的数据库是没有事务概念的,如1964年的CODASYL's IDS or1968年的 IBM's IMS。
1976 年,IBM 的 Jim Gray 在报告《Notes on Data Base Operating Systems》中首次正式出"Transaction"概念,定义了一系列要么全做要么全不做的操作集合,并讨论了并发控制与日志恢复。
1983年,德国学者 Theo Härder 和 Andreas Reuter 在论文《Principles of Transaction-Oriented Database Recovery》中,首次用 Atomicity(原子性)、Consistency(一致性)、Isolation(隔离性)、Durability(持久性)概括事务的四大特性,奠定了后来所有数据库的设计基础。
1980--1990年代:商用 RDBMS 的普及。Oracle(1979 起)、IBM DB2(1983 起)、微软 SQL Server(1989 起)等产品相继落地,ACID 成为标配。此时又陆续引入了多版本并发控制(MVCC)、更细粒度的锁策略等优化。
MySQL 最早由 Michael "Monty" Widenius 和 David Axmark 在 1994 年着手开发,第一版(MySQL 1.0)于 1995 年 5 月正式发布。MySQL AB 公司则在 1996 年左右正式成立,之后逐步发展成为流行的开源关系型数据库。
ACID
事务的四个特性,开发人员都非常熟悉。这里我只简单提下,原子性保证的是事务能在发生故障时的恢复能力,"要么全做要么全不做"。一致性保证的是数据库内部数据的一致性,如唯一性约束,外键约束等,但这部分的一致性更多和应用有关,如保持会计系统的借贷相等,库存不超卖,用户钱包余额大于 0 。隔离性,保证的是在多个客户端并发读写同一数据的情况下,保持操作的正确性。持久性保证的是在事务提交后,数据肯定落盘了,不会丢失。
原子性和持久性,不怎么需要开发人员参与,数据库会处理的很好。和开发人员最相关的是隔离性和一致性,隔离性,虽然名字如此,其实是并发问题,也是场景最复杂,最容易产生问题的地方,会带来数据的脏写,脏读,更新丢失,幻读这些问题。应用层面的数据一致性,这是开发者为了正确性必须要保证的,实现它的基础也是要基于原子性、隔离性、持久性这些特性。
并发和隔离级别
脏读
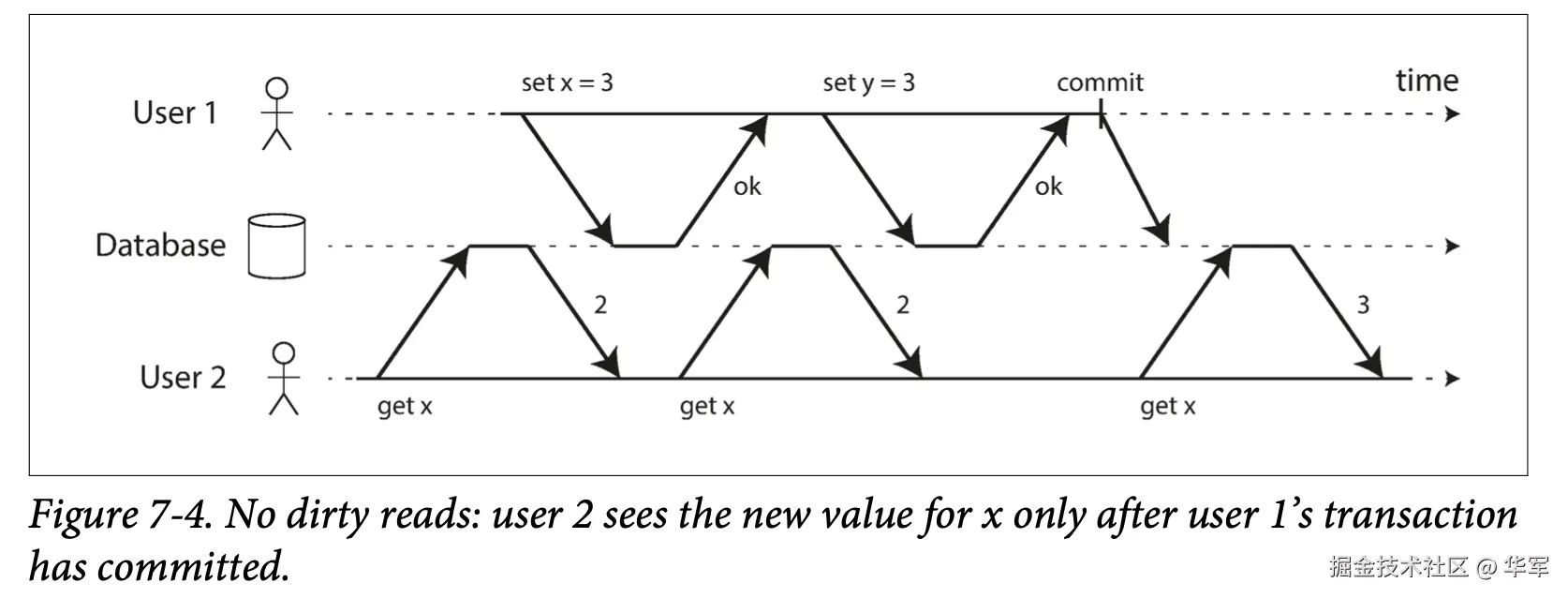
一个事务如果读取到别的事务还没有提交的数据,这就是脏读,很容易理解。脏读会带来两个问题:
一是如果其他事务是多个操作的,那么当前事务只读到了部分数据,可能会造成数据不一致,程序会变得不正确。比如,展示用户资金列表的事务,如果刚好有个的转账操作,userA->userB, 那么在中间状态,读事务可能只看到userA的余额减少了,userB的 余额则没变。
二是,当前事务读取了其他事务的数据后,其他事务回滚了,那之前读的数据就失效了,容易造成问题,这类问题出现会感觉很不正常,且不好排查。
脏写

看这个例子,有两个用户去买同一个车子,id是 1234。有两步操作,一是设置车子的买主,一个是设置开票的接收人,在Alice发起操作的过程中,Bob把买主覆盖成了自己,但票据的接收人是Alice,这就导致了数据不一致的问题,引发了bug。
这种现象就属于脏写,在一个事务未提交前,其他事务写了同一块数据。脏写在事务存在多个操作的情况下,很容易造成数据不一致的情况,直接导致程序不正确。脏写也让程序开发变得不可估计,明明往数据库里写了内容,却发现内容被修改了。。。
读已提交
数据库定义了读已提交这个隔离级别,并做出保证,在这个隔离级别下不会有脏读和脏写。
那是怎么实现的呢?每个数据库实现的具体方式会不太一样,但对于脏写一般都会采用行锁,一个事务想要修改某一行的数据,必须先获取那一行的锁,直到事务退出或者提交后才释放锁;在这之间读写该行的其他锁都会等待直到锁被释放。
脏读的实现一般会有两种方式,读锁和快照两种方式。读锁,就是加短暂的share-lock到记录上,这样会保证读不到脏数据,但是这会导致读事务被写事务堵塞,尤其是在写事务时间比较长的时候会产生连锁反应,导致系统吞吐下降严重。
Read Skew
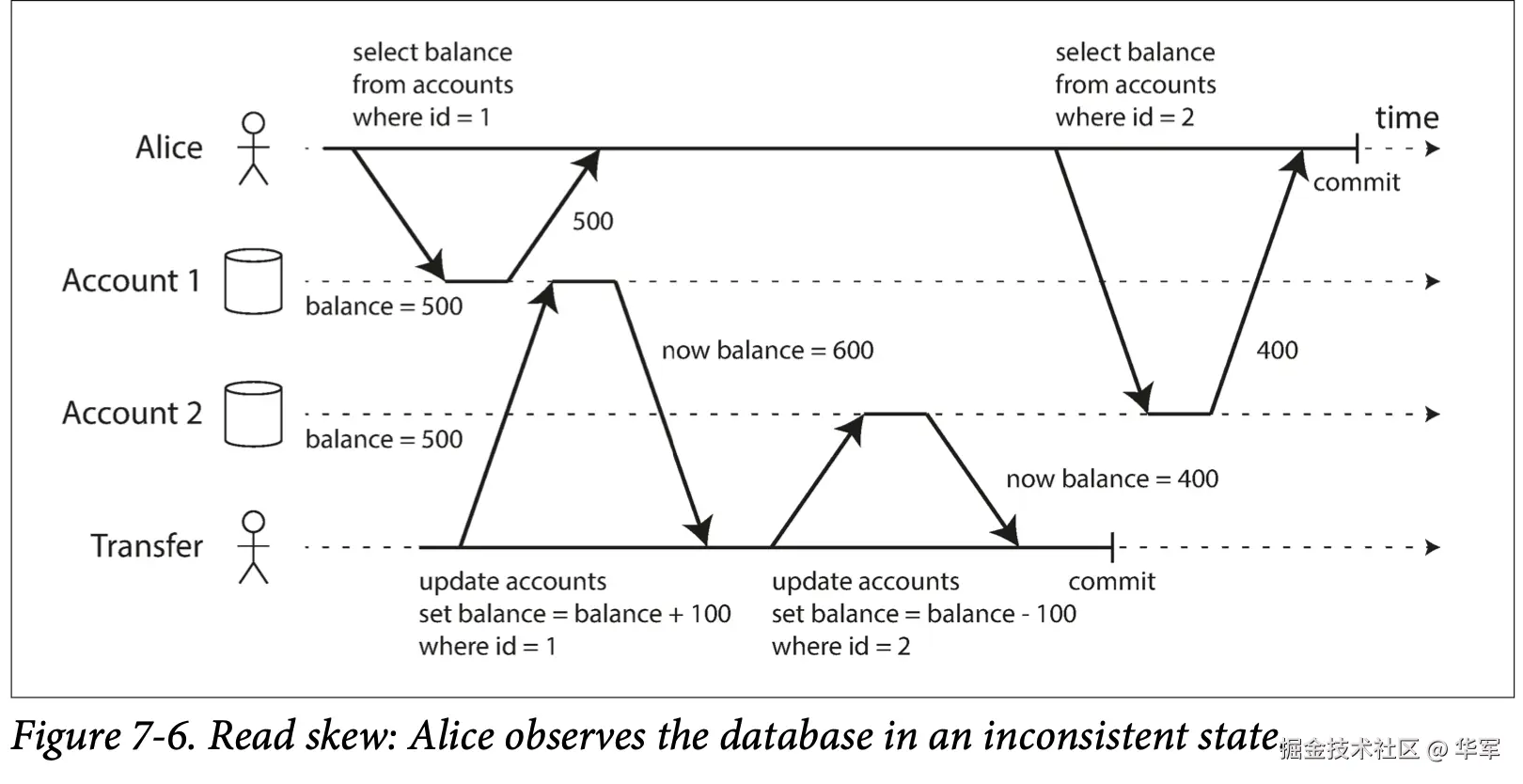
Alice在分别查看自己两个账户余额的时候,刚好发生了一个转账操作,因为读已提交下,读不加锁,所以导致她看到自己账户1、账户2的余额分别是500、400,钱变少了。
这个叫Read Skew或者不可重复读。我个人感觉Skew理解成偏离、偏见更好,我们对一个人或一个事情从不同角度、不同时代看,会有不同的看法,即会产生偏见。此处的Read Skew就是指在时间维度上的偏离,Alice在转帐前看到的数据就是一个时间维度上的偏离,如果在转账后她就能看到最新的数据了。
Read Skew现象在互联网的环境里,一般是容忍的,用户做了个只读操作,他只要刷新下就能看到最新的数据。但是下面两种场景的读事务一般需要防止Read Skew。
- 如果我们有个长时间执行的读事务,做一些分析查询的操作,我们查询出来的数据甚至要满足某些业务约束,如上面的账户1+账户2的总额不变,就不能基于时刻变化的数据去做分析,应当基于一个快照去做。
- 快照数据备份,需要多次读的数据都是一个时间点的数据。(当然这个问题可以用binlog或者mysqldump绕过)
这里给我们的提示时如果有job执行时间长的话,需要关注下是否能容忍Read Skew的现象。
可重复读 Snapshot Isolation
此隔离级别在读已提交的基础上增加了另一个保证,就是防止上面的Read Skew。大多数数据库的实现方式就是我们熟悉的MVCC(multi-version concurrency control)。具体机制我就不在此赘述。
更新丢失
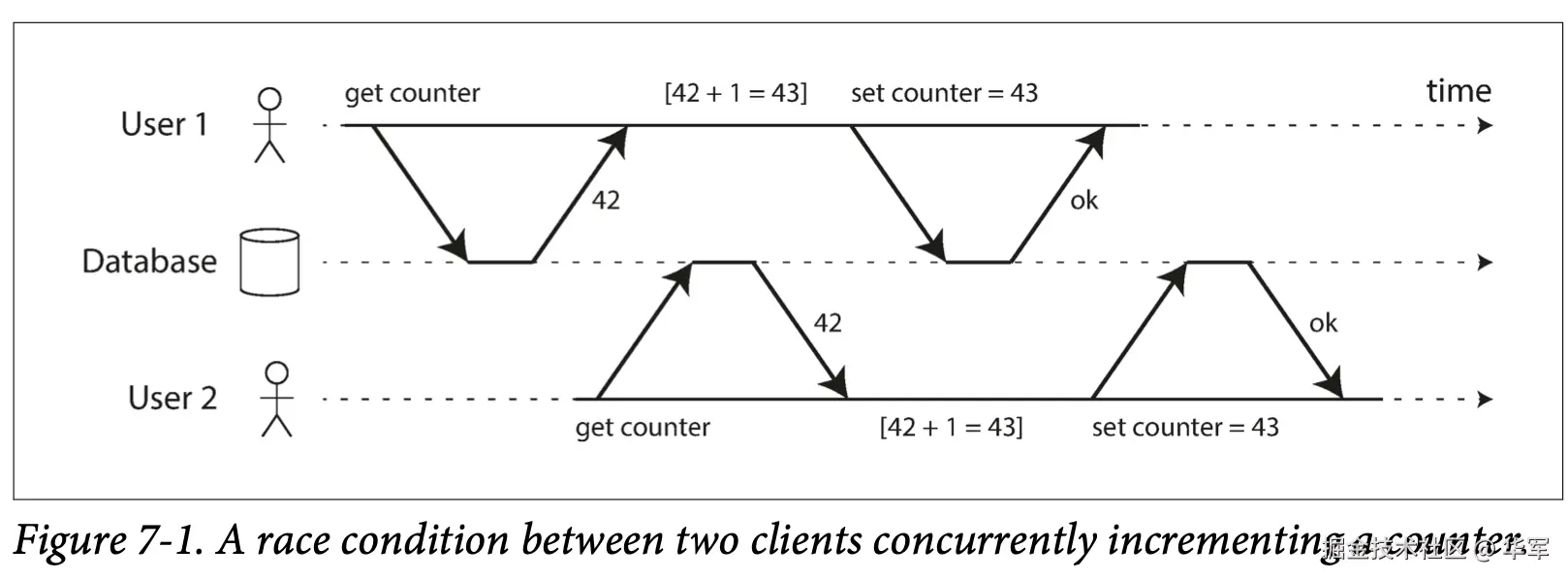
前面的并发问题除了脏写外,说的都是只读事务在遇到并发写的情况会出现脏读、Read Skew等现象。如果当前事务同时包含读写,还会出现哪些并发问题呢?更新丢失是一个,典型的像上图的计数器,最终结果是43,丢失了User1先操作的一次更新。归纳起来,就是后一个写操作覆盖了前一个写操作。
这类问题有个范式,读->内存修改->写,三个操作是连在一起的。
原子化操作
如果上述三个操作可以转化成一个原子操作,变成一个sql让数据库去执行,那是最好不过的了。如:
ini
UPDATE counters SET value = value + 1 WHERE key = 'foo'; 显示锁
但是操作无法转化成原子操作的情况也很多。一般我们读出数据来后内存修改的逻辑很复杂,需要进行计算,在一个查询里根本做不到,又比如我们中间要去调用第三方服务,这时可以用显示锁去做了。
sql
BEGIN TRANSACTION;
SELECT * FROM figures WHERE name = 'robot' AND game_id = 222 FOR UPDATE;
-- Check whether move is valid, then update the position -- of the piece that was returned by the previous SELECT.
UPDATE figures SET position = 'c4' WHERE id = 1234;
COMMIT;这里得先把人物查出来然后进行一些逻辑校验,当移动人物的时候要符合一些游戏定义的规则,如移动的位置不能越界、移动速度不能超过规定等,只有满足这些规则我们才能去修改人物位置。
自动检测更新丢失
很多数据库在快照读级别依据MVCC是可以做到自动检测某一行是否发生了更新丢失,如果出现了,就自动退出当前事务。但是Mysql没有做这个工作,但是我们可以在应用程序通过版本机制同样做到这个效果。
Write Skew & Phantoms
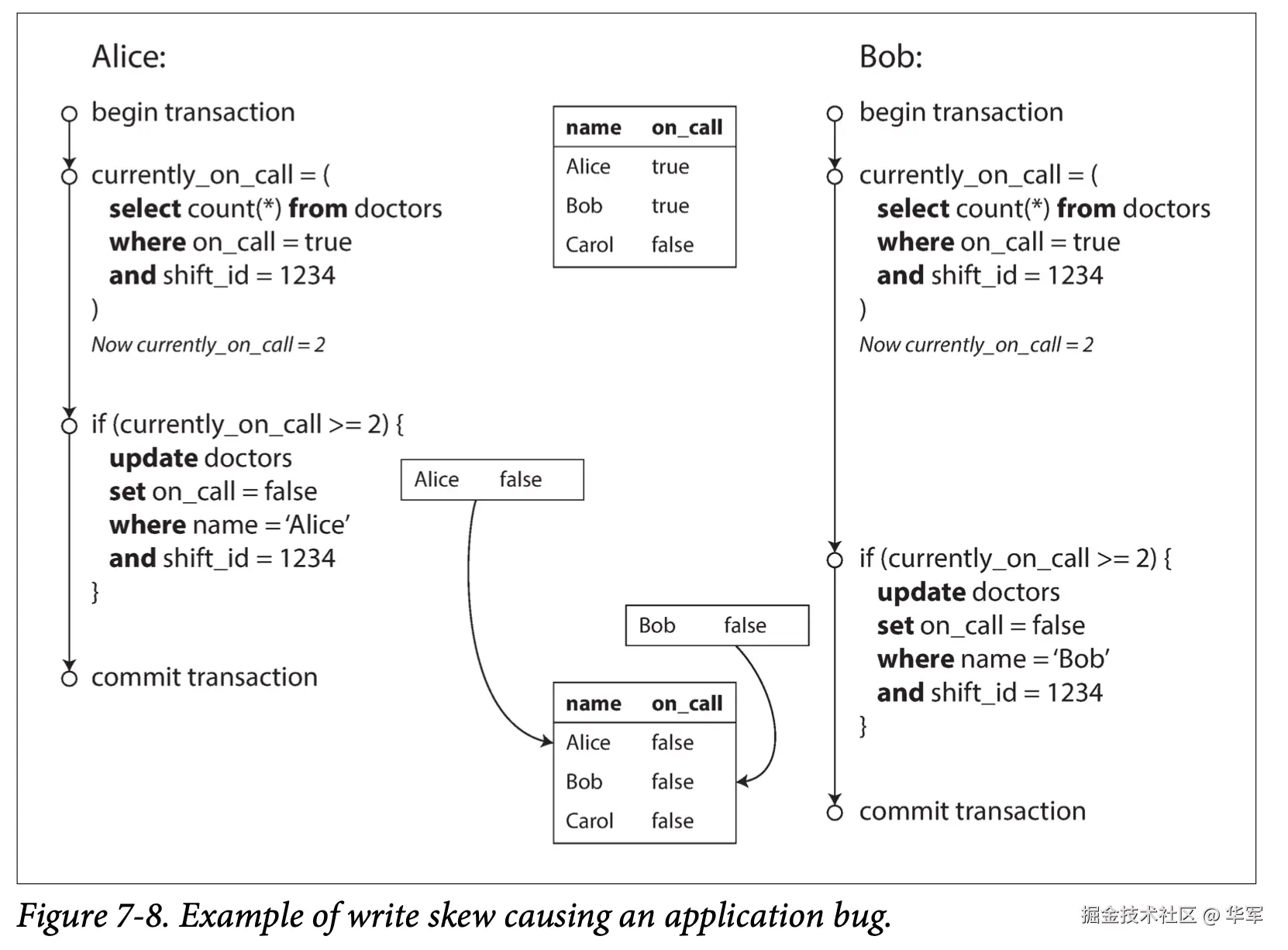
看这医生值班的例子,值班医生可以请假,但要保证每个排班都要有一个值班医生。Alice和Bob两个人不巧此时都感觉不舒服,在他们都去查询1234班次的时候,数据库返回on call的医生都有两个,于是他们都去请假了。最后结果是违反了业务的约束。
首先我们观察这个并发问题,它不是脏写也不是更新丢失,因为两个事务操作的是不同的数据。数据库的研究人员把这种现象定义为Write Skew,即写偏差,我认为这个定义是从Read Skew来的。严格来说Read Skew是针对只读事务来的,前后两次的同一查询返回了两个时间的结果,如果在事务里加入了写操作,那么基于之前的偏见(过期的查询结果),进行的写操作,就会导致写Write Skew,从而违反了数据的一致性约束,造成了bug。
基于之前的偏见(过期的查询结果),又叫做Phantom,即我们常说的幻读,Read Skew和Write Skew里都有。所以如果直接说幻读是个并发问题,我觉得是不准确的,至少是不完整的。
只读事务只会对当前事务造成影响,影响比较小,可以容忍或者通过快照机制解决。但写事务会对整个数据库的一致性产生影响,所以Write Skew这种现象就必须要杜绝,不能让事务基于已经过期的查询结果进行写操作。
更新丢失可以看作成特殊的Write Skew。
- Write Skew:两个事务读取相同的一些对象,做一些修改,写不同的对象。
- 更新丢失:两个事务读取相同的一些对象,做一些修改,写相同的对象。
Write Skew看起来是个很抽象的概念,抽象因为它描述的是一个动态的事情,产生幻读后的写操作。它看起来离我们很远,但只要意识到它,就会发现它存在开发的各个角落。再看几个例子:
- 会议室预定场景,两个预定不能是同一个会议室的同一时间。
sql
BEGIN TRANSACTION;
-- Check for any existing bookings that overlap with the period of noon-1pm
SELECT COUNT(*) FROM bookings WHERE room_id = 123 AND
end_time > '2015-01-01 12:00' AND start_time < '2015-01-01 13:00';
-- If the previous query returned zero:
INSERT INTO bookings
(room_id, start_time, end_time, user_id)
VALUES (123, '2015-01-01 12:00', '2015-01-01 13:00', 666);
COMMIT; - 网站用户名不能重复。在插入一条新用户的时候需要校验用户名是否已存在。
- 游戏里面两个玩家不能移动到同一个位置。在移动一个玩家的时候,要校验将要移动的位置是否被占用。
这些例子都有可能在并发情况下产生幻读导致的Write Skew。它们都遵循一个范式,客户端从数据库读取满足一定条件的数据,客户端基于这些数据做计算,客户端向数据库写数据。
暂时无法在飞书文档外展示此内容
Write Skew的解决方案
- 因为操作的是不同的数据,原子化操作解决不了Write Skew的问题。
- 同样,自动检测版本冲突或一些基于CAS做的乐观锁机制同样都是针对特定行的,也解决不了此问题。
- 显式锁只能针对已经存在的行。它能解决上面医生值班的问题,因为医生的班次已经存在。通过下面的sql锁住班次为1234的所有行,使得要修改班次1234的其它事务阻塞住,便能保证这块逻辑是串行执行的。
ini
BEGIN TRANSACTION;
SELECT * FROM doctors
WHERE on_call = true
AND shift_id = 1234 FOR UPDATE;
UPDATE doctors
SET on_call = false WHERE name = 'Alice' AND shift_id = 1234;
COMMIT;- 显示锁对于其它几个例子就没有办法了。因为预定会议室、创建用户、移动玩家,它们第一步的查询条件可能不返回任何数据或者一部分数据,但是在第三步具体写的时候查询条件返回的结果不一样,有数据了,这就导致我们无法提前进行加锁。
Serializable
串行化的隔离级别做了一个保证:即使事务是并发执行的,它的执行结果也和串行去执行事务是一样的。
实际串行执行,像Redis。绕过了一切并发执行会产生的问题。但是存在某些约束,它只能执行一些小而短的事务,否则一个长事务会影响整个系统的性能。由于是单线程执行,所有写请求依赖单个CPU, 吞吐量有限制。
2PL,两阶段锁:
简单来说,就是读时候加读锁,写时候加写锁,读和读不会阻塞,读写、写写都会阻塞。事务获取到锁,会一直持有到事务提交或退出的时候才会释放锁,两阶段锁就是从这个得名而来,分为两阶段:加锁和释放锁。
两阶段锁的性能:
从实践来看,两阶段锁的性能糟糕。有加锁和释放锁的操作代价,但更多原因是并发的降低。在快照读机制下,读事务不会阻塞写事务,写事务也不会阻塞读事务。但两阶段,读事务会阻塞写事务,写事务也会阻塞读事务。数据库并不限制事务的执行时间,一个长事务就会把一个系统干趴下。两阶段下,死锁发生的概率更高,重试的次数也会更多。
谓词锁:
前面我们讲到会议室预定的并发问题无法用已有的方案去解决,2PL可以解决这个问题,我们看下是怎么解决的。
sql
SELECT * FROM bookings WHERE room_id = 123 AND
end_time > '2018-01-01 12:00' AND start_time < '2018-01-01 13:00'; 数据库使用了谓词锁去解决这个问题。
当事务A在查询某个条件的时候,数据库会尝试在这个查询条件去加上共享的谓词锁,如果同时有另外一个事务B在进行写操作,它写的记录满足这个查询条件,那A会一直等待B完成。
当事务A加上了谓词锁后,有另外一个事务C尝试去进行写操作,需要等待A完成。
核心思想是谓词锁对于数据库里不存在的记录也适用,这样便能解决Write Skew的问题和其它并发问题。
范围锁:(Index-Range locks)
谓词锁因为会对所有正在进行的读写事务,都要去查指定的查询条件,非常耗时。间隙锁是对谓词锁的简化,在预定会议室的例子里,你可以对room_id建个索引,那么加读锁的时候就在room_id=123的索引记录上加个读锁。你也可以对时间进行加锁,加读锁的时候针对特定范围加上间隙锁。
简化后,粗粒度的锁代替了谓词锁,但是同样可以防止Write Skew, 查询性能却可以提升不少。
总结
- 上面讲的隔离级别主要是ANSI SQL 定义的隔离级别
- Read Uncommitted(读未提交):数据库躺平,什么都不做。
- Read Committted(读已提交):防止脏读,脏写。
- REPEATABLE READ:防止不可重复读,但不保证防止Write Skew。
- SERIALIZABLE:防止幻读(利用严格的两段锁,所有读都会加索引范围锁)。
每个供应商数据库对隔离级别的具体实现是有差异的,尤其是可重复读的实现,需要开发者使用时做详细了解。但明白并发到底会出现哪些问题,再结合供应商对隔离级别做了哪些保证,开发者才能更好地对使用哪种隔离级别做出决策。
并发问题是数据库并发读写时一定会出现的问题,隔离级别是数据库想要达到的效果和目的。只有SERIALIZABLE才能真正达到串行化,杜绝所有并发问题。其它几种隔离级别都是弱隔离级别,这是基于性能和数据一致性做的权衡。除了真正物理上的串行化,其它的隔离级别都是通过一系列算法防止并发问题,所有事务读写的还是一份数据。
- Mysql InnoDB的隔离级别
Mysql的隔离级别实现和ANSI SQL 定义的隔离级别定义基本一致,也有不少差别,比较重要的是REPEATABLE READ是通「MVCC + 两段锁混合」实现的,它比ANSI 定义的要求要强,它可以防止Write Skew。 -- 对于普通的、走 MVCC 的快照读(plain SELECT),InnoDB 不加任何锁,所以查询条件的结果有变化会导致写操作产生Write Skew。 -- 只有当你使用 locking read(SELECT ... FOR UPDATE / LOCK IN SHARE MODE)或做 UPDATE/DELETE,InnoDB 才会在索引上加 next-key lock(record lock + gap lock)来"拍下"整个扫描范围,阻止别人往里插行,避免幻读。
- 分布式锁防止并发。在我们的时间开发中我们常会对写操作以商家id或者订单号做key,去锁住某个操作。
优点:
- 灵活,不依赖具体 DB 引擎
- 可以跨库、跨表甚至跨服务统一加锁
代价:
- 开发者必须识别出所有"危险点"(可能幻读/写偏斜的地方)并手动加锁,任何遗漏都可能导致一致性问题;
- 分布式锁稳定性、超时、重试、死锁检测、性能开销等都需要额外处理;
我觉得问题主要出在第一点,要求开发者提前判断可能导致幻读的点,在系统复杂起来的时候,这点变得较为艰难,也使系统变得难维护。
实验
在dev mysql下实验,版本号是5.7.24-log。
创建表并插入数据。
sql
DROP TABLE IF EXISTS t_phantom;
CREATE TABLE t_phantom (
id INT PRIMARY KEY,
msg VARCHAR(20)
) ENGINE=InnoDB;
INSERT INTO t_phantom VALUES (1,'a'),(10,'b'),(20,'c');设置session1,session2,隔离级别都设置为可重复读。
普通读:
session1只是查询
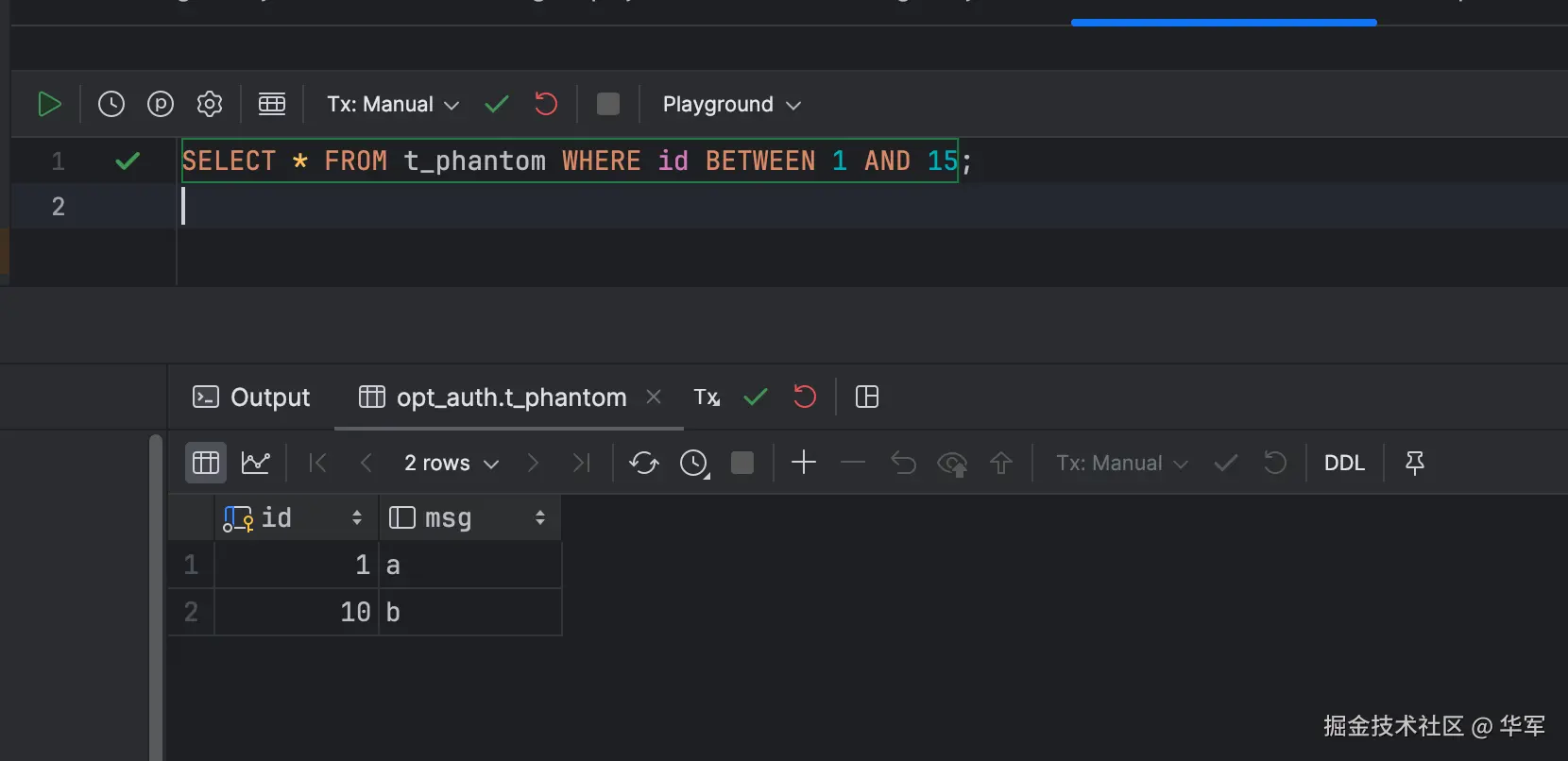
session2 插入数据。
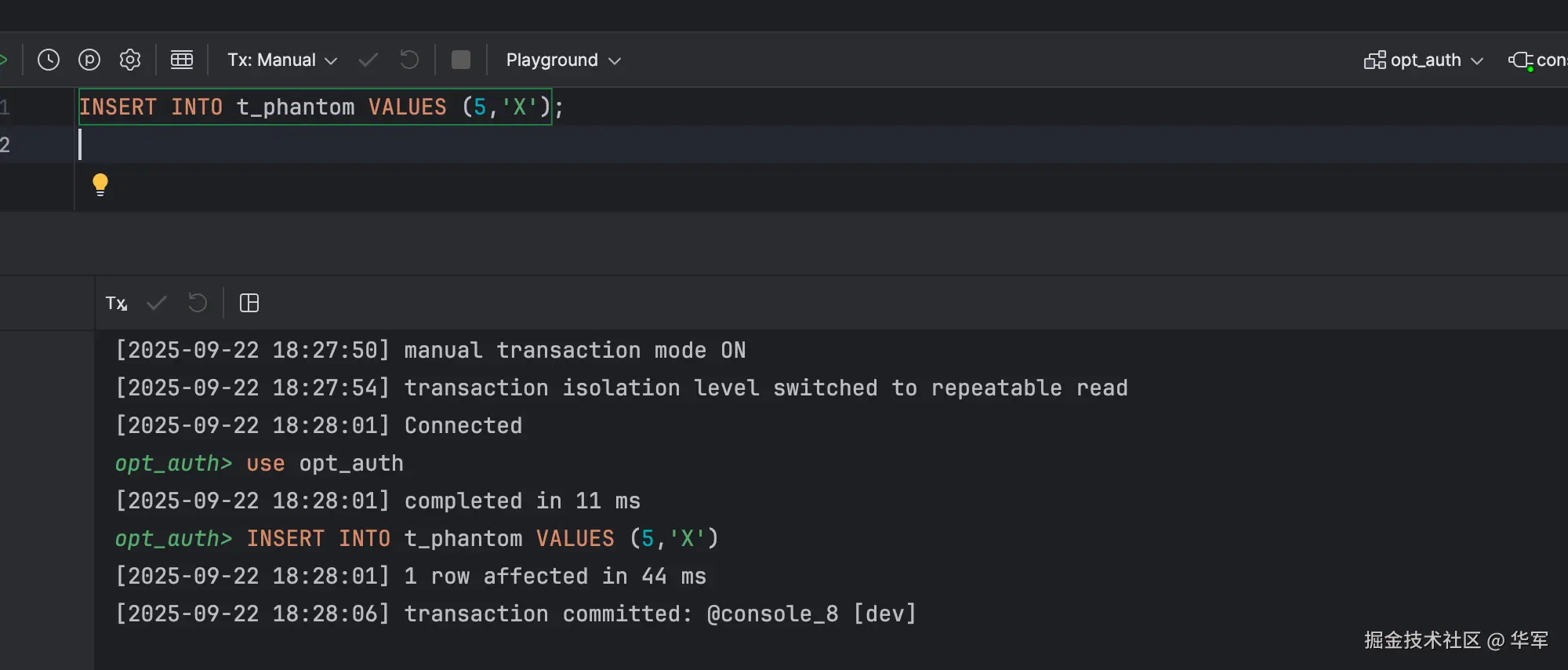
session1这时候如果有写操作,便会看到最新的数据,基于原来的查询结果进行写操作就会产生幻读和Write Skew。
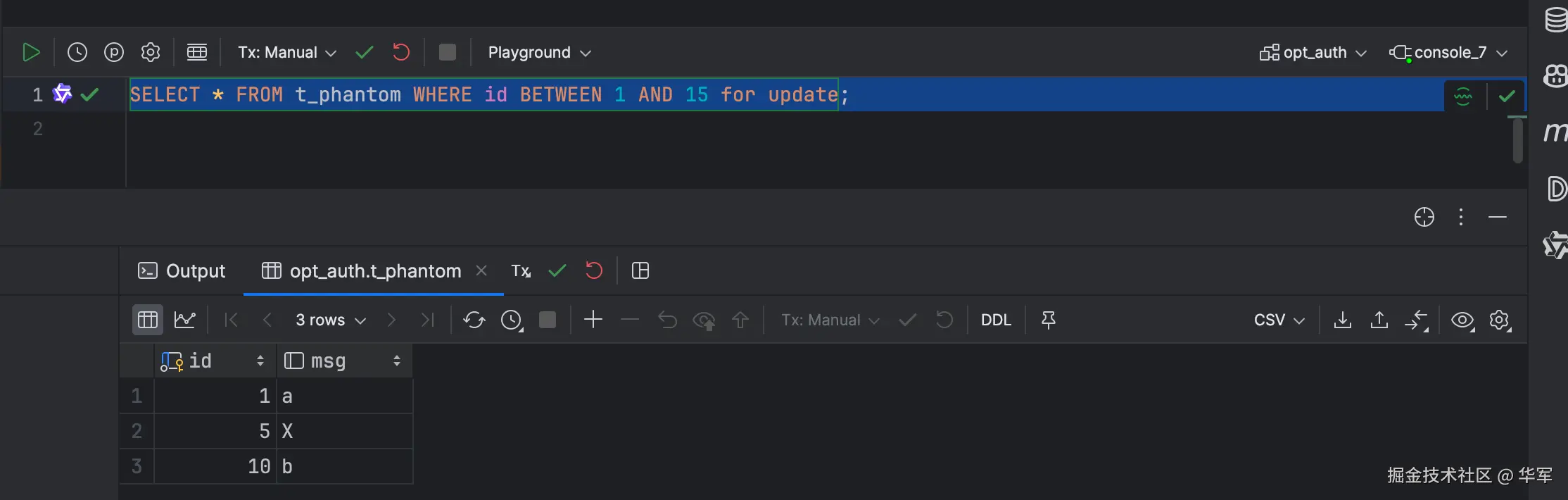
MVCC + 两段锁混合
session1 通过for update,加上gap lock。
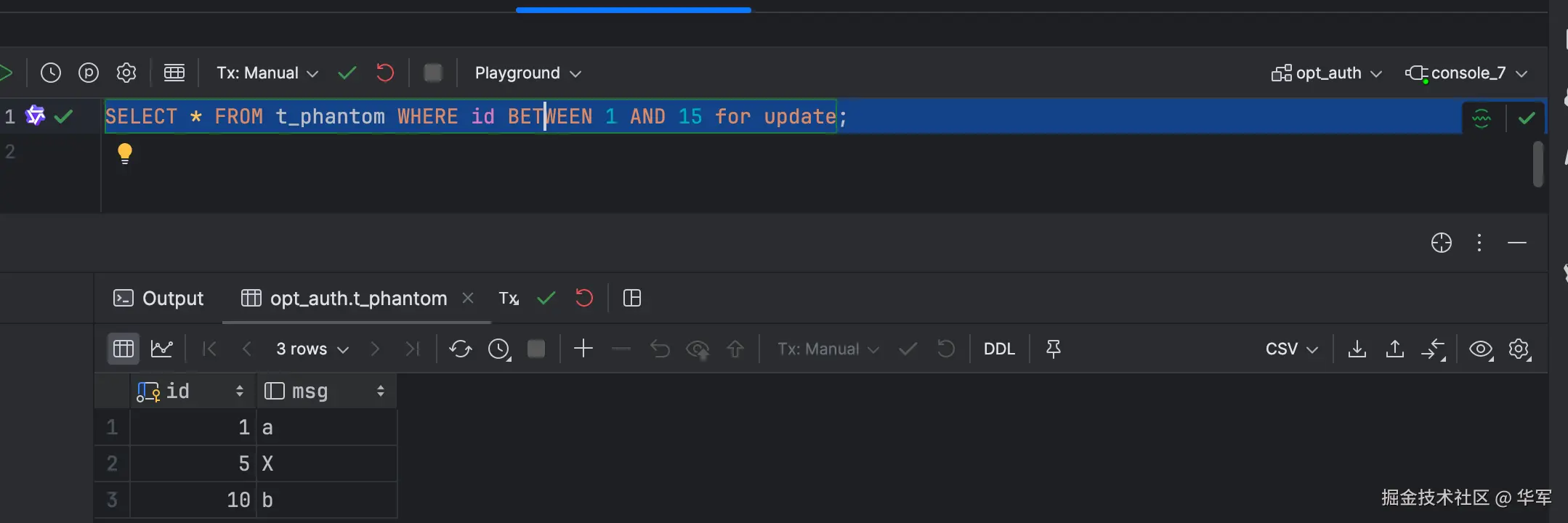
session2 这时想插入数据的id为6,因为有gap lock,所以被阻塞。
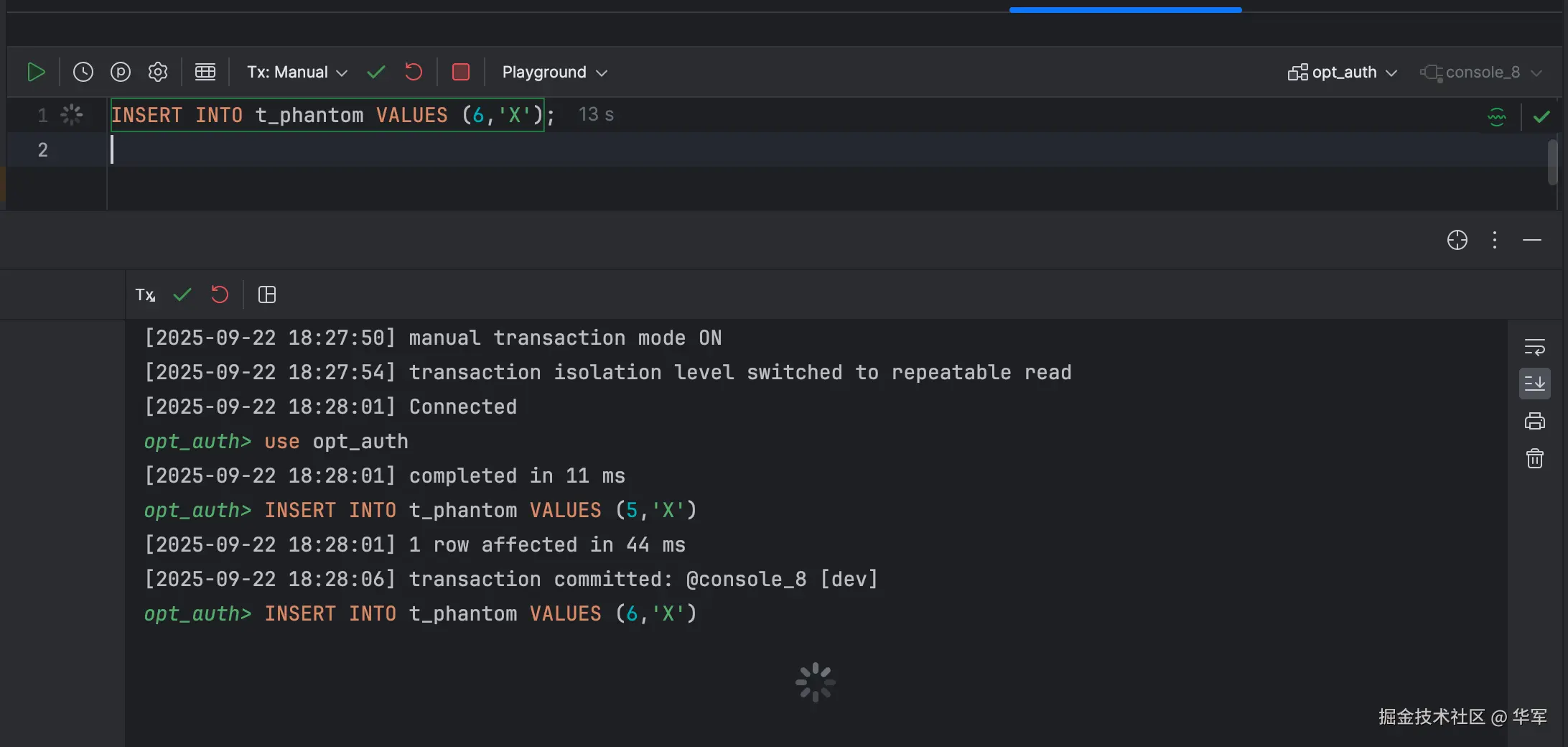
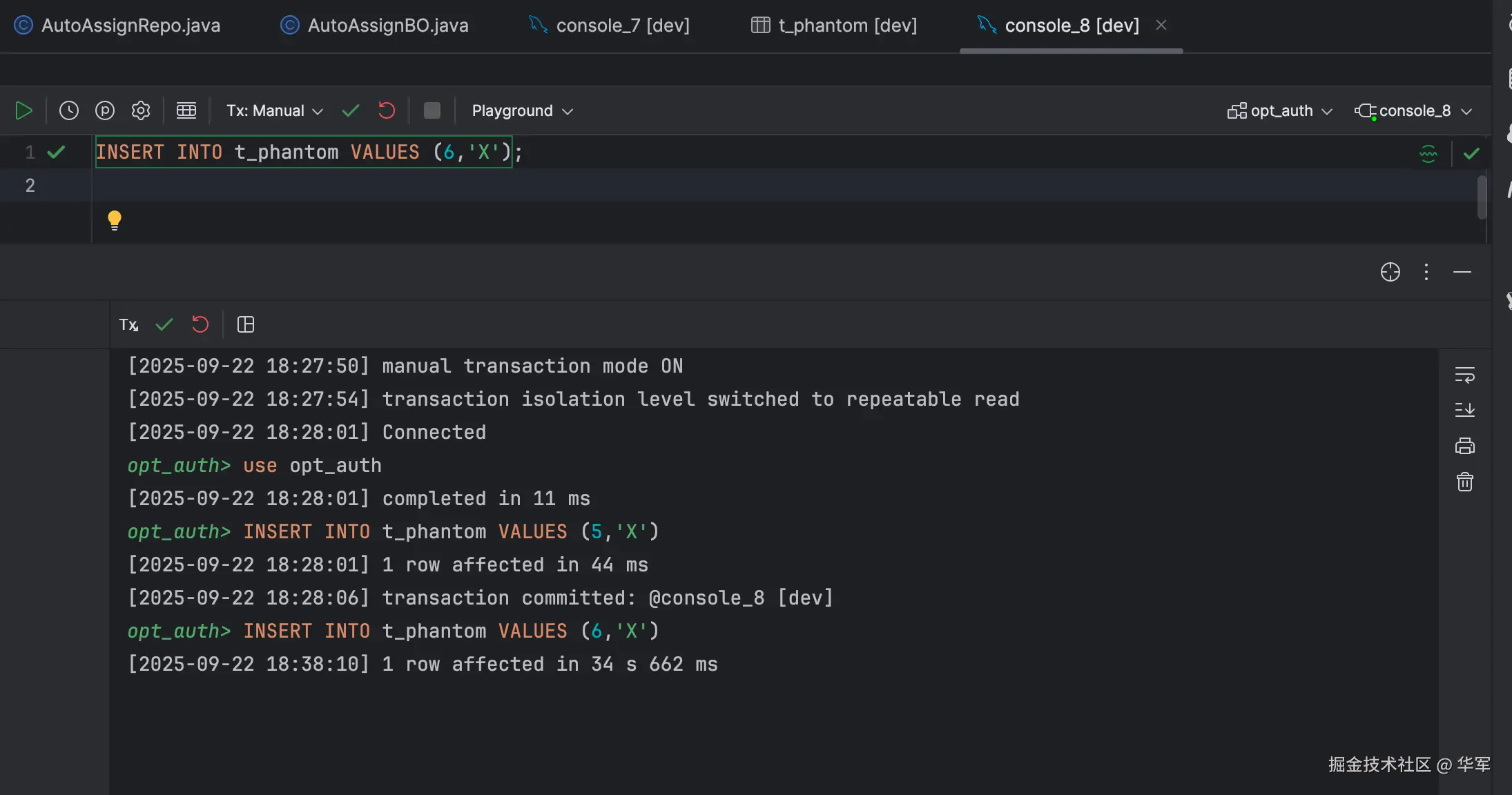
session1的事务提交后,session2的事务才执行成功。
参考资料
- Designing Data-Intensive Applications