你是否还在用那些"祖传"的 append 技巧来删除切片元素? 你是否在每次排序时都不得不写一个繁琐的闭包函数?
在泛型之前,对切片(slice)的常见操作往往依赖于一些模式化的、但又不够直观的代码,例如:
删除:
go
// 泛型之前:通过 append 技巧实现删除
// 假设我们要删除索引为 i 的元素
s = append(s[:i], s[i+1:]...)这段代码虽然常见,却暗藏玄机:
- 需要手动维护索引,不够直观
- 涉及拷贝操作,在性能和内存上可能存在隐患
排序:
go
// 泛型之前:为了排序一个结构体切片,需要编写一个冗长的闭包
sort.Slice(users, func(i, j int) bool {
return users[i].Name < users[j].Name
})上述代码虽然有效,但也存在几个问题:比较函数依赖索引访问,逻辑不够清晰;同时缺少类型检查,编译器也无能为力。
幸运的是,从 Go 1.21 开始,标准库引入了泛型工具包 slices,为我们提供了类型安全 、可读性强 、性能可靠的原生切片操作 API。
本文将带你:
- 功能概览,快速了解
slices包的全貌 - 逐步剖析几个核心函数的源码与实现
- 从正交性、效率优先等多个维度,探讨
slices包背后的设计思想
是时候丢掉这些"祖传技巧",试试更现代的写法了。
slices 功能概览
Go 1.21 引入的 slices 包,为我们提供了处理切片的统一工具集。
从整体上看,这些函数可以被清晰地划分为几大类
1. 查找
Index/IndexFunc:查找指定元素或符合条件的元素,并返回第一个匹配的索引。Contains/ContainsFunc:检查切片是否包含某个元素或符合条件的元素。Min/MinFunc:查找切片中的最小元素。Max/MaxFunc:查找切片中的最大元素。BinarySearch/BinarySearchFunc:使用二分法查找指定元素或符合条件的元素,只能作用于已排序的切片,返回第一个匹配的索引
2. 排序
Sort/SortFunc:对切片进行原地排序,支持默认排序或自定义比较函数。SortStableFunc:对切片进行原地稳定排序,当元素值相等时,保持其原始相对顺序不变。IsSorted/IsSortedFunc:检查切片是否已排序。
3. 修改
Delete/DeleteFunc:删除指定索引范围内的元素或符合条件的元素。Insert:在指定位置插入元素。Replace:替换指定索引范围内的元素。Compact/CompactFunc:原地删除切片中相邻的重复元素。Reverse:反转切片中元素的顺序。
4. 容量管理
Grow:确保切片容量足以容纳指定数量的新元素,避免多次扩容。Clip:将切片容量裁剪到其长度,释放多余的底层数组空间。
5. 组合与连接
Concat:将多个切片连接成一个新切片。Repeat:创建一个包含指定元素重复多次的新切片。
6. 比较
Equal/EqualFunc:比较两个切片是否相等,支持默认比较或自定义比较函数。
7. 迭代器相关 (Go 1.23+)
- 获取切片的迭代器
All:返回切片的index-value的迭代器。Backward:返回切片的反向index-value迭代器Values:返回切片的值迭代器Chunk:返回一个迭代器,用于遍历s的连续子片段,每个子片段最多包含n个元素
- 从迭代器创建切片
AppendSeq:遍历迭代器,从中获取元素并追加到现有切片。Collect:遍历迭代器,将所有元素收集到一个新切片中。Sorted/SortedFunc/SortedStableFunc:遍历迭代器,将所有元素收集到一个新切片中并进行排序。
核心功能与源码剖析
在功能概览中,我们绘制了一张 slices 包的"功能地图",对它提供的各种工具有了宏观的了解。
现在,我们将拿起"放大镜",深入到几个核心函数的内部,探究它们是如何通过简洁的函数签名,优雅地实现高效操作的。
删除操作:Delete、DeleteFunc和Compact
slices.Delete
在 Go 泛型之前,删除切片中的元素通常依赖于 append 技巧,例如删除索引为 i 的元素:
go
s = append(s[:i], s[i+1:]...)这段代码虽然简洁,却暗藏杀机。
除了可读性差、容易出错之外,这种技巧还存在一个潜在的内存泄漏风险。
当切片的容量大于其长度时,被"删除"的元素依然存在于底层数组中。
如果这些元素是引用类型(如指针),Go 的垃圾回收器(GC)无法回收这些对象,从而导致内存占用无法被释放。
slices.Delete 将这个操作简化为一个直观的函数调用,并在底层彻底解决了这一问题
使用示例:
go
s = slices.Delete(s, i, i+1)源码实现:
go
func Delete[S ~[]E, E any](s S, i, j int) S {
_ = s[i:j:len(s)] // bounds check
if i == j {
return s
}
oldlen := len(s)
s = append(s[:i], s[j:]...)
clear(s[len(s):oldlen]) // zero/nil out the obsolete elements, for GC
return s
}从源码中可以看出,slices.Delete 的核心逻辑依然是append 函数,其时间复杂度仍为 O(n)。
关键的设计体现在 clear 函数的调用上。
clear 是 Go 1.21 引入的内置函数,它的作用是将切片中被删除的元素在底层数组中的内存空间手动置为零值。
这一操作切断了对废弃元素的引用,允许垃圾回收器在需要时立即回收这些内存。
除了clear的调用之外,在执行append之前还进行了边界检查,增加了安全性。
这使得 slices.Delete 不仅在可读性 上优于传统的 append 技巧,更重要的是,它从底层解决了内存泄漏的隐患。
slices.DeleteFunc
相比于slices.Delete,slices.DeleteFunc提供了更灵活的删除方式,它允许我们通过自定义函数 del 来确定需要删除哪些元素.
虽然其实现逻辑比 slices.Delete 稍微复杂,但其核心思想是类似的:通过遍历并重写元素来达到"原地删除"的效果,并在最后调用 clear 函数来清理内存。
go
func DeleteFunc[S ~[]E, E any](s S, del func(E) bool) S {
i := IndexFunc(s, del)
if i == -1 {
return s
}
// Don't start copying elements until we find one to delete.
for j := i + 1; j < len(s); j++ {
if v := s[j]; !del(v) {
s[i] = v
i++
}
}
clear(s[i:]) // zero/nil out the obsolete elements, for GC
return s[:i]
}其实现采用了原地重写(overwrite)的策略。这里有两个关键指针:
i写指针 :i指向切片写入位置。j读指针 :j指向切片的读取位置。
当 j 指针遍历到需要保留的元素时,就将其移动到 i 指针指向的位置,然后 i 指针前移一位。
通过这种方式,所有需要保留的元素都会被"压缩"到切片的前部,而需要删除的元素则被原地覆盖。
最后,clear 函数被调用来清理被覆盖的旧元素,彻底释放内存。
slices.Compact
slices.Compact 函数用于原地删除切片中相邻的重复元素 ,其实现与 slices.DeleteFunc 类似, 采用了原地重写的策略,使用经典的双指针算法, 避免额外的内存分配,但是相对而言会更加复杂一点
go
func Compact[S ~[]E, E comparable](s S) S {
if len(s) < 2 {
return s
}
for k := 1; k < len(s); k++ {
if s[k] == s[k-1] {
s2 := s[k:]
for k2 := 1; k2 < len(s2); k2++ {
if s2[k2] != s2[k2-1] {
s[k] = s2[k2]
k++
}
}
clear(s[k:]) // zero/nil out the obsolete elements, for GC
return s[:k]
}
}
return s
}其实现关键利用了一个新的切片s2,和两个关键指针k和k2:
s2新切片:第一个重复的相邻元素后面的切片k写指针:k指向原始切片中需要重写的位置k2读指针:k2指向新切片的读取的位置
当找到第一个重复的相邻元素时,根据索引创建新的切片s2表示后续还没有检查过的元素切片。
之后通过k2遍历s2,当k2指针遍历到重复的相邻元素时,就将其移动到 k 指针指向的位置,然后 k 指针前移一位。
可以理解为slices.DeteleFunc的一个特例,del被指定为:当前元素与前一个元素相同时返回true。
slices.CompactFunc的实现与slices.Compact基本一致,只是可以自定义比较函数,类型不再受comparable约束,其函数签名为:
go
func CompactFunc[S ~[]E, E any](s S, eq func(E, E) bool) S使用eq函数来替代==和!=运算,这里不再赘述。
从源码不难看出,slices.Delete,slices.DeleteFunc,slices.Compact的时间复杂度和空间复杂度均为 O(n),足以满足绝大部分场景的需求。
排序操作:slices.Sort 、 slices.SortFunc和SortStableFunc
在 Go 1.21 之前,对切片进行自定义排序需要依赖 sort.Slice 函数,并传入一个匿名函数(闭包)。
这种方式虽然灵活,但在大型项目中会变得冗长,并且由于其依赖索引访问,失去了类型安全。
slices.Sort 和 slices.SortFunc
考虑以下场景:对一个 User 结构体切片按 Name 字段进行排序。
泛型之前 (sort.Slice)
go
type User struct {
Name string
Age int
}
users := []User{{"Bob", 25}, {"Alice", 30}}
sort.Slice(users, func(i, j int) bool {
return users[i].Name < users[j].Name
})上述代码中,比较函数依赖索引访问,可读性差,并且编译器无法进行有效的类型检查。
泛型之后 (slices.SortFunc)
go
slices.SortFunc(users, func(a, b User) int {
return cmp.Compare(a.Name, b.Name)
})slices.SortFunc 让排序操作变得更加简洁、类型安全。
与slices.Delete类型,排序操作提供了两个函数:slices.Sort和slices.SortFunc
这两个排序操作的最终排序逻辑都指向了sort.pdqsort
go
func Sort[S ~[]E, E cmp.Ordered](x S) {
n := len(x)
pdqsortOrdered(x, 0, n, bits.Len(uint(n)))
}
func SortFunc[S ~[]E, E any](x S, cmp func(a, b E) int) {
n := len(x)
pdqsortCmpFunc(x, 0, n, bits.Len(uint(n)), cmp)
}pdqsort(Pattern-defeating quicksort)结合了快速排序(Quicksort)、堆排序(Heapsort)和插入排序(Insertion Sort)的优点,旨在提供在大多数场景下都表现出色的性能。
-
优点 :
pdqsort能够自动识别数据中的模式,并根据模式切换不同的排序策略,从而避免传统快速排序在面对特定数据(如已排序或逆序)时可能退化为 O(n²) 性能的情况。 -
复杂度分析 :
pdqsort的平均时间复杂度为 O(nlogn) ,最坏时间复杂度也是 O(nlogn)。空间复杂度为 O(logn),这使得它成为一种高效且健壮的通用排序算法。
pdqsort具体实现比较复杂,限于篇幅不做展开,后续有机会在进行详细介绍。
关于pdqsort的更多分析可以参考 paper: arxiv.org/pdf/2106.05...
GitHub 仓库: github.com/orlp/pdqsor... 提供了 C++ 的实现版本,并提供了详细的基准测试和复杂度说明
pqdsort基准测试:
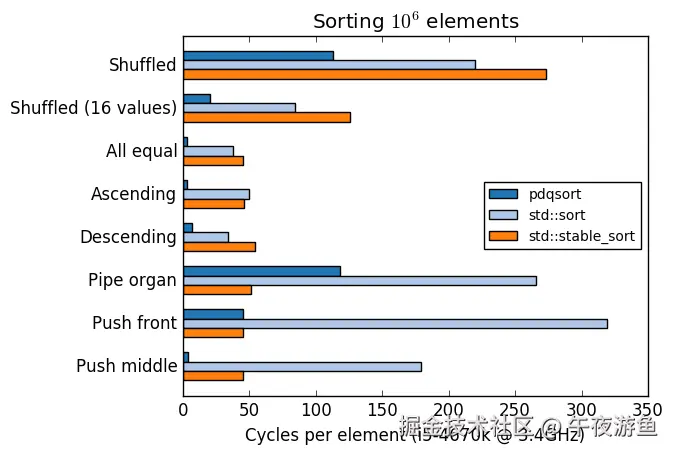
pdqsort 可视化: 
稳定排序:slices.SortStableFunc
除了常规排序,slices 包还提供了 slices.SortStableFunc 来处理稳定排序的需求。
稳定排序意味着当两个元素的值相等时,它们在排序后的相对顺序与排序前保持一致。
由于slices.SortStableFunc的目标是稳定排序,因此不能使用pqdsort(快排不是稳定排序),而是一个精巧的、原地的归并排序变体,结合了插入排序和symMerge原地合并算法。
go
func stableCmpFunc[E any](data []E, n int, cmp func(a, b E) int) {
// 阶段一:使用插入排序`insertionSortCmpFunc`创建初始有序块。
blockSize := 20 // must be > 0
a, b := 0, blockSize
for b <= n {
insertionSortCmpFunc(data, a, b, cmp)
a = b
b += blockSize
}
insertionSortCmpFunc(data, a, n, cmp)
// 阶段二:使用`symMergeCmpFunc`迭代合并有序块
for blockSize < n {
a, b = 0, 2*blockSize
for b <= n {
symMergeCmpFunc(data, a, a+blockSize, b, cmp)
a = b
b += 2 * blockSize
}
if m := a + blockSize; m < n {
symMergeCmpFunc(data, a, m, n, cmp)
}
blockSize *= 2
}
}slices.SortStableFunc的具体实现在stableCmpFunc中,整个排序过程分为两个阶段.
阶段一 :使用插入排序insertionSortCmpFunc创建初始有序块。
插入排序是稳定的,并且对于小规模的数据(这里blockSize限定为20),插入排序的常数因子非常小,性能非常好。pdqsort也是使用插入排序来处理小规模的数据。
在阶段一之后,整个大切片变成了一系列相邻的、有序的小块。
阶段二 :使用symMergeCmpFunc迭代合并有序块
迭代从blocksize为20开始,每次循环后加倍。在每次循环中将相邻的两个已排序的小块合并为一个更大的、有序的块。
核心的合并操作由symMergeCmpFunc完成,其实现基于论文"stable minimum storage merging by symmetric comparisons" 中描述的 SymMerge算法,该过程是稳定和原地的(不使用额外的内存)。
总而言之,slices.SortStableFunc的时间复杂度为 O(NlogN), 空间复杂度为 O(1)的堆空间和 O(logN)的栈空间
slices包的整体设计
效率优先
从对删除操作和排序操作的源码剖析中,不难看出slices 包的核心设计理念之一,就是尽可能地追求效率优先 ,尽可能地追求原地操作(In-place Operation)
比如 slices.DeleteFunc 和 slices.Compact 都是典型的原地操作函数。它们通过双指针或原地重写(overwrite)的方式,在原有切片的底层数组上完成元素的删除或去重,避免了创建新的切片和底层数组,从而显著减少了内存分配和垃圾回收的开销。
XXX 与 XXXFunc 的双版本设计模式
在 slices 包中,我们经常会看到一对孪生函数:一个基础版(如 slices.Sort)和一个以 Func 结尾的变体版(如 slices.SortFunc)。这种双版本设计模式,是 slices 包乃至整个泛型标准库的一个核心思想。
-
基础版 (
XXX) :这类函数通常作用于具有comparable约束的元素类型(如基本数据类型、字符串),或者其他能够进行自然排序的类型。它们为开发者提供了最简单、最直观的 API,无需提供额外的比较函数,大大简化了代码。例如,slices.Sort可以直接对[]int或[]string进行排序,而slices.Equal可以直接比较两个[]int是否相等。 -
变体版 (
XXXFunc) :这类函数则提供了更强的灵活性 。它们的泛型类型参数通常使用any约束,并通过传入一个自定义函数(如less或eq)来定义比较或查找的逻辑。这使得我们可以处理复杂的数据结构,例如根据结构体的某个字段进行排序、查找。
这种设计模式平衡了约定 (为常见类型提供便利)与灵活性(为复杂逻辑提供扩展性)之间的关系。它确保了开发者在处理常见任务时能够获得最佳的用户体验,同时也为那些需要自定义行为的场景提供了强大的支持。
例如,slices.Compact 的函数签名为 func Compact[S ~[]E, E comparable](s S) S,它通过泛型限定了元素类型必须是 comparable 的。而 slices.CompactFunc 的函数签名为 func CompactFunc[S ~[]E, E any](s S, eq func(E, E) bool) S,它提供了自定义的比较方法,因此允许 any 类型。
slices 与 iter 的融合
在 Go 1.23 之后,slices 包不再是一个孤立的工具库,而是与 iter 包结合。
iter 包的核心思想是提供一种迭代器(Iterator)模式,它代表了对数据集合的一种抽象遍历。
通过将两者结合,带来了明显的益处:
- 互操作性 :
slices包将能够无缝地与iter生态系统进行交互。例如,slices.AppendSeq函数可以遍历一个迭代器,并将其产生的元素追加到切片中。这种设计模式使得不同的数据源(切片、Map、甚至是文件流)都可以通过统一的迭代器接口进行处理,极大地增强了代码的通用性。 - 懒计算(Lazy Evaluation) :迭代器模式的一个核心优势是懒计算。在处理大型数据集时,例如从文件中读取数据并进行处理,我们可以使用迭代器来逐个处理元素,而无需一次性将所有数据加载到内存中。这对于内存受限的应用程序来说,是一个巨大的性能提升。
总结
本文先介绍了slices包的功能概览,之后挑选了包中具有代表性的的删除操作和排序操作进行深入解析,最后回顾slices包提供的函数的整体设计。
通过以上的探讨,我们可以清晰地看到 slices包并非简单的语法糖,它为我们带来了三大核心价值:
- 类型安全:泛型的引入使得编译器能在编译期进行严格的类型检查,将运行时错误提前暴露,大大增强了代码的健壮性。
- 内存安全 :通过
clear等机制,slices包从根本上解决了传统append操作可能潜在的内存泄漏隐患,让代码更加安全可靠。 - 性能与简洁性 :
pdqsort等高效算法的采用,在绝大多数场景下提供了优异的性能。同时,直观的 API 设计极大提升了代码的可读性和可维护性,减少了样板代码。
从繁琐的"祖传技巧"到优雅的现代写法,slices包代表了一种更清晰、更安全、更高效的编程范式。它不仅是一个工具集,更是一种最佳实践的倡导。
那么,你现在应该怎么做?
- 在新项目中 :可以大胆地采用
slices包来操作切片。 - 在老项目中 :建议在修改或重构现有切片操作代码时,逐步将其替换为
slices包中的对应函数,这将是一次无声的安全性升级和可读性优化。
是时候拥抱变化,告别那些繁琐且易错的"祖传"代码,享受泛型带来的现代编程体验了。
📃参考资料 stable minimum storage merging by symmetric comparisons
更多内容欢迎关注微信公众号:午夜游鱼