作者:来自 Elastic Alexander Dávila

学习如何使用 UBI 数据创建判断列表,以在 Elasticsearch 中自动化训练你的 LTR 模型。
亲身体验 Elasticsearch:深入我们的示例笔记本,开始免费云试用,或在本地机器上尝试 Elastic。
使用学习排序( Learning-to-rank )模型时,一个重大挑战是创建高质量的判断列表来训练模型。传统上,这个过程需要人工评估查询与文档的相关性,为每个结果分配评分。这是一个缓慢、难以扩展且难以维护的过程(想象一下需要手动更新包含数百条记录的列表)。
那么,如果我们可以利用真实用户与搜索应用的交互来创建这些训练数据呢?使用 UBI 数据正好可以做到这一点。我们可以创建一个自动系统,捕获并利用我们的搜索、点击及其他交互来生成判断列表。这个过程比人工方式更易扩展和重复,并且往往能产生更好的结果。在这篇博客中,我们将探索如何查询存储在 Elasticsearch 中的 UBI 数据,以计算有意义的信号,从而为 LTR 模型生成训练数据集。
你可以在这里找到完整的实验。
为什么 UBI 数据对训练你的 LTR 模型有用
UBI 数据相比人工标注有几个优势:
- 数据量:由于 UBI 数据来自真实交互,我们可以收集比人工生成更多的数据。当然,这需要有足够的流量来生成这些数据。
- 真实用户意图:传统的人工判断列表来自专家对现有数据的评估。而 UBI 数据反映了真实的用户行为。这意味着我们可以生成更优质的训练数据,从而提升搜索系统的准确性,因为这些数据基于用户实际如何与内容交互并从中获得价值,而不是基于理论假设。
- 持续更新:判断列表需要定期刷新。如果我们基于 UBI 数据创建它们,就可以获得实时数据,从而生成最新的判断列表。
- 成本效益:不需要人工创建判断列表的额外工作,这个过程可以高效、反复地执行。
- 自然查询分布:UBI 数据代表真实的用户查询,可以带来更深入的改进。例如,用户是否会用自然语言进行搜索?如果是,我们可能需要实现语义搜索或混合搜索方案。
不过,也有一些注意事项:
- 偏差放大:热门内容因为曝光更多而更容易被点击,这可能会放大受欢迎的结果,从而掩盖更优的选项。
- 覆盖不全:新内容缺乏交互,因此可能难以在结果中排名靠前。罕见查询也可能缺少足够的数据点来生成有意义的训练数据。
- 季节性变化:如果用户行为会随时间显著变化,那么历史数据可能无法很好地反映当前的好结果。
- 任务模糊性:一次点击并不总能保证用户找到了他们真正想要的内容。
评分计算
LTR 训练的评分
为了训练 LTR 模型,我们需要为查询和文档之间的相关性提供某种数值表示。在我们的实现中,这个数值是一个从 0.0 到 5.0+ 的连续得分,分数越高表示相关性越强。
为了展示这个评分系统如何工作,下面是一个人工创建的示例:
| 查询 | 文档内容 | 评分 | 说明 |
|---|---|---|---|
| "best pizza recipe" | "Authentic Italian Pizza Dough Recipe with Step-by-Step Photos" | 4.0 | 高度相关,正是用户在寻找的内容 |
| "best pizza recipe" | "History of Pizza in Italy" | 1.0 | 有一定相关性,主题是披萨但不是食谱 |
| "best pizza recipe" | "Quick 15-Minute Pizza Recipe for Beginners" | 3.0 | 相关,是个不错的结果,但可能不完全符合"最佳"食谱的预期 |
| "best pizza recipe" | "Car Maintenance Guide" | 0.0 | 完全无关,与查询毫无关系 |
正如我们在这里看到的,评分是文档与示例查询 "best pizza recipe" 的相关性的数值表示。通过这些得分,LTR 模型可以学习哪些文档应该在结果中排得更靠前。
如何计算评分是训练数据集的核心。有多种方法可以实现这一点,每种方法都有其优缺点。例如,我们可以为相关文档赋值 1、不相关赋值 0,或者仅统计每个查询下结果文档的点击次数。
在这篇博客中,我们将采用一种不同的方法,把用户行为作为输入,并计算出一个评分作为输出。同时,我们会修正一种常见偏差 ------ 即靠前的结果往往更容易被点击,无论文档是否真正相关。
评分计算 ------ COEC 算法
COEC(Clicks over Expected Clicks)算法是一种基于用户点击计算判断评分的方法。
正如前面提到的,用户往往会点击排名较高的结果,即使该文档与查询的相关性不强,这被称为 "位置偏差(Position Bias)"。使用 COEC 算法的核心思想是:并非所有点击都具有相同的意义 ------ 点击第 10 位的文档比点击第 1 位的文档更能表明该文档与查询的相关性更高。引用 COEC 算法研究论文中的一句话:
"众所周知,搜索结果或广告的点击率(click-through rate - CTR)会随着位置的不同而显著下降。"
你可以在这里进一步了解位置偏差。
为了解决这个问题,COEC 算法遵循以下步骤:
1. 建立位置基线:我们为每个搜索位置(从 1 到 10)计算点击率(CTR)。这意味着我们确定通常有多少百分比的用户会点击第 1 位、第 2 位等结果。这个步骤用于捕捉用户的自然位置偏差。
我们使用以下方式计算 CTR:
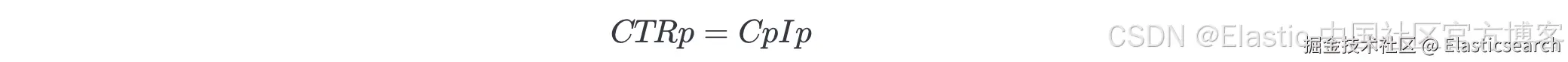
其中:
p = 位置,从 1 到 10
Cp = 在所有查询中,位置 p 上的总点击次数(任意文档)
Ip = 总展示次数:在所有查询中,任意文档出现在位置 p 的次数
在这里,我们预期靠前的位置会获得更多点击。
2. 计算预期点击数(Expected Clicks - EC):
该指标用于确定某个文档根据其出现的位置及该位置的点击率(CTR)应当 获得多少点击。我们使用以下方法计算 EC:
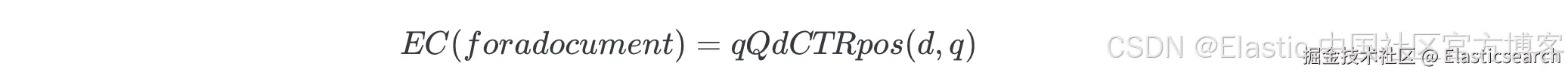
其中:
Qd = 文档 d 出现过的所有查询
pos(d, q) = 文档 d 在查询 q 的结果中的位置
3. 统计实际点击次数:我们统计文档在所有出现过的查询中实际收到的总点击次数,记作 A(d)。
4. 计算 COEC 分数:这是实际点击次数 A(d) 与预期点击次数 EC(d) 的比值:
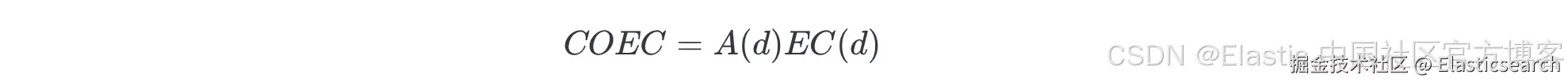
该指标通过如下方式对位置偏差进行归一化:
-
分数为 1.0 表示文档的表现正好符合其出现位置的预期。
-
分数高于 1.0 表示文档的表现优于其位置预期,因此该文档对查询更相关。
-
分数低于 1.0 表示文档的表现低于其位置预期,因此该文档对查询相关性较低。
最终结果是一个评分数字,它反映了用户的实际需求,同时考虑了从真实搜索交互中提取的位置基准预期。
技术实现
我们将创建一个脚本来生成判断列表,以训练 LTR 模型。
该脚本的输入是索引在 Elastic 中的 UBI 数据(查询和事件)。
输出是使用 COEC 算法从这些 UBI 文档生成的 CSV 格式判断列表。这个判断列表可以与 Eland 一起使用,用于提取相关特征并训练 LTR 模型。
快速开始
要从本博客的示例数据生成判断列表,可以按以下步骤操作:
1. 克隆代码库:
bash
`
1. git clone https://github.com/Alex1795/elastic-ltr-judgement_list-blog.git
2. cd elastic-ltr-judgement_list-blog
`AI写代码2. 安装所需库
对于这个脚本,我们需要以下库:
-
pandas:用于保存判断列表
-
elasticsearch:从我们的 Elastic 部署中获取 UBI 数据
我们还需要 Python 3.11
go
`pip install -r requirements.txt`AI写代码3. 在 .env 文件中更新 Elastic 部署的环境变量
-
ES_HOST
-
API_KEY
要添加环境变量,请使用:
bash
`source .env`AI写代码5. 运行 Python 脚本:
go
`python judgement_list-generator.py`AI写代码如果你按照这些步骤操作,你应该会看到一个名为 judgment_list.csv 的新文件,看起来如下:
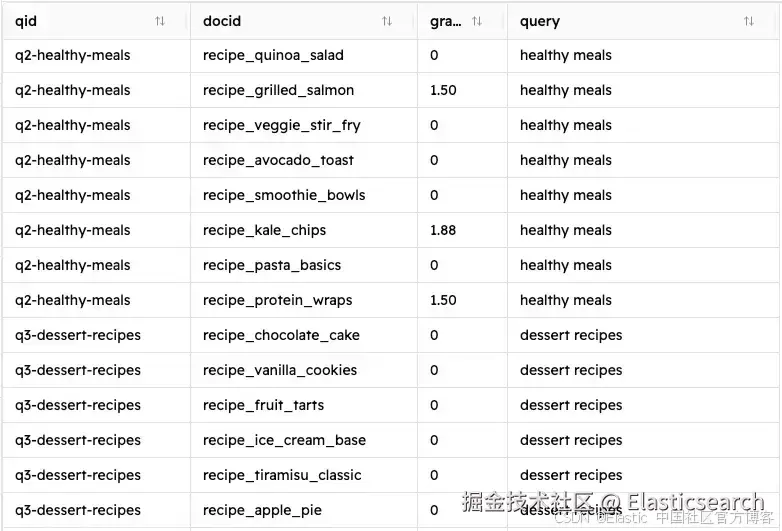
这个脚本使用前面讨论的 COEC 算法,通过下面显示的 calculate_relevance_grade() 函数计算评分。
数据架构
UBI 查询
我们的 UBI 查询索引包含关于在搜索系统中执行的查询的信息。以下是一个示例文档:
bash
`
1. {
2. "client_id": "client_002",
3. "query": "italian pasta recipes",
4. "query_attributes": {
5. "search_type": "recipe",
6. "category": "food",
7. "cuisine": "italian"
8. },
9. "query_id": "q002",
10. "query_response_id": "qr002",
11. "query_response_object_ids": [
12. "doc_011",
13. "doc_012",
14. "doc_013",
15. "doc_014",
16. "doc_015",
17. "doc_016",
18. "doc_017",
19. "doc_018",
20. "doc_019",
21. "doc_020"
22. ],
23. "timestamp": "2024-08-14T11:15:00Z",
24. "user_query": "italian pasta recipes"
25. }
`AI写代码在这里,我们可以看到来自用户的数据(client_id)、查询结果的数据(query_response_object_ids)以及查询本身的数据(timestamp, user_query)。
UBI 点击事件
我们的 ubi_events 索引包含每次用户点击结果文档时的数据。以下是一个示例文档:
bash
`
1. {
2. "action_name": "click",
3. "application": "recipe_search",
4. "client_id": "client_001",
5. "event_attributes": {
6. "object": {
7. "description": "Authentic Italian Pizza Dough Recipe with Step-by-Step Photos",
8. "device": "desktop",
9. "object_id": "doc_001",
10. "position": {
11. "ordinal": 1,
12. "page_depth": 1
13. },
14. "user": {
15. "city": "New York",
16. "country": "USA",
17. "ip": "192.168.1.100",
18. "location": {
19. "lat": 40.7128,
20. "lon": -74.006
21. },
22. "region": "NY"
23. }
24. }
25. },
26. "message": "User clicked on document doc_001",
27. "message_type": "click",
28. "query_id": "q001",
29. "timestamp": "2024-08-14T10:31:00Z",
30. "user_query": "best pizza recipe"
31. }
`AI写代码判断列表生成脚本
脚本概览
该脚本使用存储在 Elasticsearch 中的查询和点击事件的 UBI 数据,自动生成判断列表。它执行以下任务:
-
获取并处理 Elasticsearch 中的 UBI 数据
-
将 UBI 事件与其查询相关联
-
计算每个位置的 CTR
-
计算每个文档的预期点击数(EC)
-
统计每个文档的实际点击次数
-
计算每个查询-文档对的 COEC 分数
-
生成判断列表并写入 CSV 文件
下面逐个介绍各个函数:
connect_to_elasticsearch()
python
`
1. def connect_to_elasticsearch(host, api_key):
2. """Create and return Elasticsearch client"""
3. try:
4. es = Elasticsearch(
5. hosts=[host],
6. api_key=api_key,
7. request_timeout=60
8. )
9. # Test the connection
10. if es.ping():
11. print(f"✓ Successfully connected to Elasticsearch at {host}")
12. return es
13. else:
14. print("✗ Failed to connect to Elasticsearch")
15. return None
16. except Exception as e:
17. print(f"✗ Error connecting to Elasticsearch: {e}")
18. return None
`AI写代码该函数使用 host 和 api key 返回一个 Elasticsearch 客户端对象。
fetch_ubi_data()
python
`
1. def fetch_ubi_data(es_client: Elasticsearch, queries_index: str, events_index: str,
2. size: int = 10000) -> Tuple[List[Dict], List[Dict]]:
3. """
4. Fetch UBI queries and events data from Elasticsearch indices.
6. Args:
7. es_client: Elasticsearch client
8. queries_index: Name of the UBI queries index
9. events_index: Name of the UBI events index
10. size: Maximum number of documents to fetch
12. Returns:
13. Tuple of (queries_data, events_data)
14. """
15. logger.info(f"Fetching data from {queries_index} and {events_index}")
17. # Fetch queries with error handling
18. try:
19. queries_response = es_client.search(
20. index=queries_index,
21. body={
22. "query": {"match_all": {}},
23. "size": size
24. }
25. )
26. queries_data = [hit['_source'] for hit in queries_response['hits']['hits']]
27. logger.info(f"Fetched {len(queries_data)} queries")
29. except Exception as e:
30. logger.error(f"Error fetching queries from {queries_index}: {e}")
31. raise
33. # Fetch events (only click events for now) with error handling
34. try:
35. events_response = es_client.search(
36. index=events_index,
37. body={
38. "query": {
39. "term": {"message_type.keyword": "CLICK_THROUGH"}
40. },
41. "size": size
42. }
43. )
44. events_data = [hit['_source'] for hit in events_response['hits']['hits']]
45. logger.info(f"Fetched {len(events_data)} click events")
47. except Exception as e:
48. logger.error(f"Error fetching events from {events_index}: {e}")
49. raise
51. logger.info(f"Data fetch completed successfully - Queries: {len(queries_data)}, Events: {len(events_data)}")
53. return queries_data, events_data
`AI写代码该函数是数据提取层;它连接 Elasticsearch 来获取 UBI 查询,使用 match_all 查询,并过滤 UBI 事件,仅获取 "CLICK_THROUGH" 事件。
process_ubi_data()
ini
`
1. def process_ubi_data(queries_data: List[Dict], events_data: List[Dict]) -> pd.DataFrame:
2. """
3. Process UBI data and generate judgment list.
5. Args:
6. queries_data: List of query documents from UBI queries index
7. events_data: List of event documents from UBI events index
9. Returns:
10. DataFrame with judgment list (qid, docid, grade, keywords)
11. """
12. logger.info("Processing UBI data to generate judgment list")
14. # Group events by query_id
15. clicks_by_query = {}
16. for event in events_data:
17. query_id = event['query_id']
18. if query_id not in clicks_by_query:
19. clicks_by_query[query_id] = {}
21. # Extract clicked document info
22. object_id = event['event_attributes']['object']['object_id']
23. position = event['event_attributes']['object']['position']['ordinal']
25. clicks_by_query[query_id][object_id] = {
26. 'position': position,
27. 'timestamp': event['timestamp']
28. }
30. judgment_list = []
32. # Process each query
33. for query in queries_data:
34. query_id = query['query_id']
35. user_query = query['user_query']
36. document_ids = query['query_response_object_ids']
38. # Get clicks for this query
39. query_clicks = clicks_by_query.get(query_id, {})
41. # Generate judgment for each document shown
42. for doc_id in document_ids:
43. grade = calculate_relevance_grade(doc_id, query_clicks, document_ids, queries_data, events_data)
45. judgment_list.append({
46. 'qid': query_id,
47. 'docid': doc_id,
48. 'grade': grade,
49. 'query': user_query
50. })
52. df = pd.DataFrame(judgment_list)
53. logger.info(f"Generated {len(df)} judgment entries for {df['qid'].nunique()} unique queries")
55. return df
`AI写代码该函数负责判断列表的生成。它首先处理 UBI 数据,将 UBI 事件与查询关联,然后对每个文档-查询对调用 calculate_relevance_grade() 函数,以获得判断列表的条目。最后,它将生成的列表作为 pandas dataframe 返回。
calculate_relevance_grade()
python
`
1. def calculate_relevance_grade(document_id: str, clicks_data: Dict,
2. query_response_ids: List[str], all_queries_data: List[Dict] = None,
3. all_events_data: List[Dict] = None) -> float:
4. """
5. Calculate COEC (Click Over Expected Clicks) relevance score for a document.
7. Args:
8. document_id: ID of the document
9. clicks_data: Dictionary of clicked documents with their positions for current query
10. query_response_ids: List of document IDs shown in search results (ordered by position)
11. all_queries_data: All queries data for calculating position CTR averages
12. all_events_data: All events data for calculating position CTR averages
14. Returns:
15. COEC relevance score (continuous value, typically 0.0 to 5.0+)
16. """
18. # If no global data provided, fall back to simple position-based grading
19. if all_queries_data is None or all_events_data is None:
20. logger.warning("No global data provided, falling back to position-based grading")
21. # Simple fallback logic
22. if document_id in clicks_data:
23. position = clicks_data[document_id]['position']
24. if position > 3:
25. return 4.0
26. elif position >= 1 and position <= 3:
27. return 3.0
28. if document_id in query_response_ids:
29. position = query_response_ids.index(document_id) + 1
30. if position <= 5:
31. return 2.0
32. elif position >= 6 and position <= 10:
33. return 1.0
34. return 0.0
36. # Calculate rank-aggregated click-through rates
37. position_ctr_averages = {}
38. position_impression_counts = {}
39. position_click_counts = {}
41. # Initialize counters
42. for pos in range(1, 11): # Positions 1-10
43. position_impression_counts[pos] = 0
44. position_click_counts[pos] = 0
46. # Count impressions (every document shown contributes)
47. for query in all_queries_data:
48. for i, doc_id in enumerate(query['query_response_object_ids'][:10]): # Top 10 positions
49. position = i + 1
50. position_impression_counts[position] += 1
52. # Count clicks by position
53. for event in all_events_data:
54. if event.get('action_name') == 'click':
55. position = event['event_attributes']['object']['position']['ordinal']
56. if position <= 10:
57. position_click_counts[position] += 1
59. # Calculate average CTR per position
60. for pos in range(1, 11):
61. if position_impression_counts[pos] > 0:
62. position_ctr_averages[pos] = position_click_counts[pos] / position_impression_counts[pos]
63. else:
64. position_ctr_averages[pos] = 0.0
66. # Calculate expected clicks for this specific document
67. expected_clicks = 0.0
69. # Count how many times this document appeared at each position for any query
70. for query in all_queries_data:
71. if document_id in query['query_response_object_ids']:
72. position = query['query_response_object_ids'].index(document_id) + 1
73. if position <= 10:
74. expected_clicks += position_ctr_averages[position]
76. # Count total actual clicks for this document across all queries
77. actual_clicks = 0
78. for event in all_events_data:
79. if (event.get('action_name') == 'click' and
80. event['event_attributes']['object']['object_id'] == document_id):
81. actual_clicks += 1
83. # Calculate COEC score
84. if expected_clicks > 0:
85. coec_score = actual_clicks / expected_clicks
86. else:
87. coec_score = 0.0
89. logger.debug(
90. f"Document {document_id}: {actual_clicks} clicks / {expected_clicks:.3f} expected = {coec_score:.3f} COEC")
92. return coec_score
`AI写代码这是实现 COEC 算法的函数。它计算每个位置的 CTR,然后比较文档-查询对的实际点击次数,最后计算每个对的实际 COEC 分数。
generate_judgment_statistics()
python
`
1. def generate_judgment_statistics(df: pd.DataFrame) -> Dict:
2. """Generate statistics about the judgment list."""
3. stats = {
4. 'total_judgments': len(df),
5. 'unique_queries': df['qid'].nunique(),
6. 'unique_documents': df['docid'].nunique(),
7. 'grade_distribution': df['grade'].value_counts().to_dict(),
8. 'avg_judgments_per_query': len(df) / df['qid'].nunique() if df['qid'].nunique() > 0 else 0,
9. 'queries_with_clicks': len(df[df['grade'] > 1]['qid'].unique()),
10. 'click_through_rate': len(df[df['grade'] > 1]) / len(df) if len(df) > 0 else 0
11. }
12. return stats
`AI写代码它从判断列表中生成有用的统计信息,例如总查询数、总唯一文档数或评分分布。这些信息仅供参考,并不会改变生成的判断列表。
结果与影响
如果你按照快速开始部分的说明操作,你应该会看到一个包含 320 条记录的 CSV 判断列表(你可以在代码库中看到示例输出)。字段包括:
-
qid:查询的唯一 ID
-
docid:结果文档的唯一标识
-
grade:计算得出的查询-文档评分
-
query:用户查询
下面看看查询 "Italian recipes" 的结果:
| qid | docid | grade | query |
|---|---|---|---|
| q1-italian-recipes | recipe_pasta_basics | 0.0 | Italian recipes |
| q1-italian-recipes | recipe_pizza_margherita | 3.333333 | Italian recipes |
| q1-italian-recipes | recipe_risotto_guide | 10.0 | Italian recipes |
| q1-italian-recipes | recipe_french_croissant | 0.0 | Italian recipes |
| q1-italian-recipes | recipe_spanish_paella | 0.0 | Italian recipes |
| q1-italian-recipes | recipe_greek_moussaka | 1.875 | Italian recipes |
从结果可以看到,对于查询 "Italian recipes":
-
烩饭食谱(risotto recipe)绝对是最佳结果,实际点击量是预期的 10 倍
-
玛格丽塔披萨(Pizza Margherita)也是一个很好的结果
-
希腊慕萨卡(Greek mousaka,令人惊讶地)也是一个不错的结果,其表现比结果中的位置所显示的要好。这意味着一些寻找意大利食谱的用户对这个食谱产生了兴趣。也许这些用户对地中海菜肴总体感兴趣。最终,这说明这个结果可以作为前面讨论的另外两个"更好"匹配结果的补充显示。
结论
使用 UBI 数据可以让我们自动化训练 LTR 模型,从自己的用户中创建高质量的判断列表。UBI 数据提供了一个大数据集,反映了我们的搜索系统是如何被使用的。通过使用 COEC 算法生成评分,我们既考虑了固有偏差,同时也反映了用户认为更好的结果。这里介绍的方法可以应用于实际用例,以提供随着真实使用趋势演进的更好搜索体验。