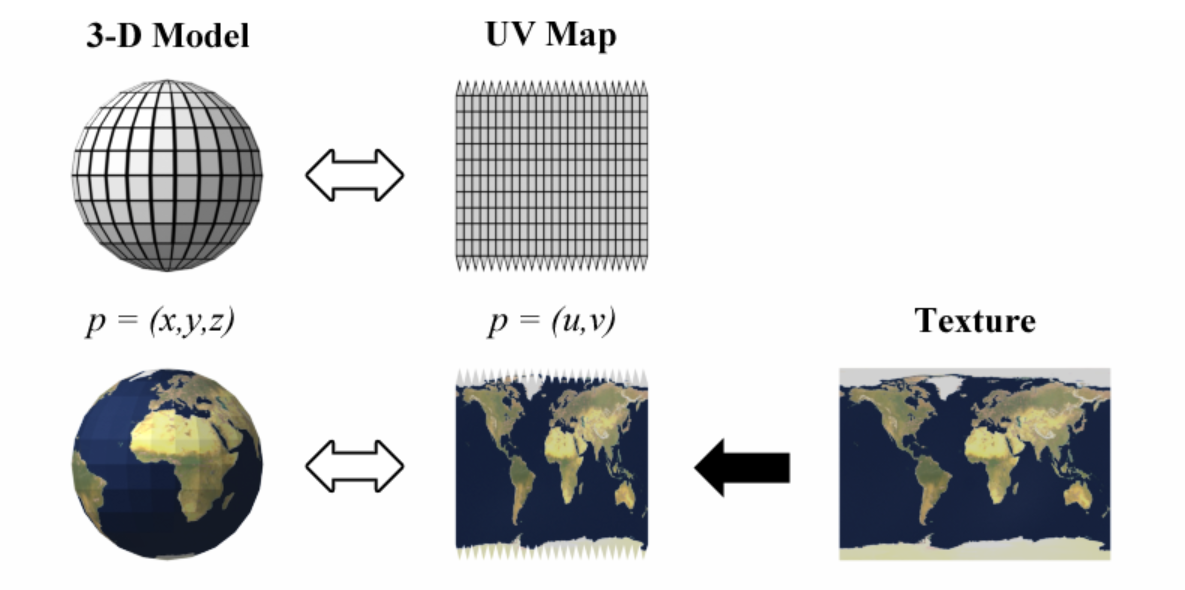
从最基础的"UV贴图"开始 (The Basics: UV Mapping)
想象一下,你有一个3D的橙子模型,但它是灰色的。你希望把它变得和真实的橙子一样,有橙色的果皮和纹理。你会怎么做?
最直接的方法是给它"贴"上一张橙子皮的图片。但问题来了:3D模型是立体的,而图片是2D的。怎么才能把一张平面的图片,完美地、没有扭曲地贴到一个球状的物体上呢?
UV贴图 就是解决这个问题的技术。
-
"展开" (Unwrapping): 就像你真的剥橙子皮然后把它摊平在桌子上一样。在3D软件里,我们对3D模型进行一次虚拟的"切割"和"展开",把它变成一个2D的平面图。这个过程叫做 UV Unwrapping。
-
"坐标" (Coordinates): 这个展开后的2D平面,我们给它一个坐标系。不像3D空间用
(X, Y, Z),这个2D平面我们用(U, V)来表示坐标。U 代表水平方向,V 代表垂直方向。这就是"UV"的由来。
所以,UV Map(UV图)本质上是3D模型表面在2D平面上的一张"地图"或"索引"。它告诉我们3D模型上的每一个点,对应到2D贴图上的哪一个像素。
从"颜色贴图"到"位置图" (From Color Map to Position Map)
通常情况下,我们展开UV后,会在这个2D平面上画上颜色、图案,比如橙子皮的纹理、人脸的皮肤、衣服的图案等等。这张图叫做 Texture Map (纹理/颜色贴圖)。
当渲染3D模型时,渲染引擎会:
-
找到模型表面的一个点(比如鼻子尖)。
-
通过UV Map,查找这个点对应在2D平面上的
(U, V)坐标。 -
去Texture Map上找到这个
(U, V)坐标对应的像素颜色。 -
把这个颜色"刷"到3D模型的鼻子尖上。
现在,我们进入核心概念:UV Position Map。
请思考一个关键转变:如果我们在UV图对应的像素上,存储的不是颜色信息 (R, G, B),而是空间位置信息 (X, Y, Z),会怎么样?
这就是 UV Position Map (UV 位置图) 的核心思想。
定义: UV Position Map 是一张2D图像,它的UV坐标对应着3D模型的表面。但每个像素的颜色值(通常用R, G, B三个通道)并不代表视觉上的颜色,而是直接编码了该点在 原始3D空间中的 (X, Y, Z) 坐标。
也就是说:
为什么要有这个"奇怪"的图?(The "Why": Why is it so useful?)
你可能会问,我们已经有3D模型本身了,为什么还要多此一举,用一张2D图来存储它的3D坐标呢?
这正是它在深度学习,尤其是3D Avatar任务中变得极其强大的原因。主要有以下几点:
-
将不规则问题转化为规则问题
-
3D Mesh (网格): 是一个拓扑结构不规则的图(Graph),点和点的连接方式复杂,处理起来很麻烦,直接输入神经网络的效果不佳。
-
UV Position Map: 是一张标准的2D图像,结构非常规整(比如 256x256 的像素网格)。
-
优势: 我们可以直接利用在图像处理领域发展得极其成熟的卷积神经网络 (CNN) 来分析和处理它。CNN非常擅长处理这种网格结构的数据。我们等于用一张图,把复杂的3D几何问题,"降维"成了一个神经网络擅长的2D图像问题。
-
-
建立"稠密对应" (Dense Correspondence)
-
想象一下,给你一张任意的人体照片。我怎么知道照片上,你夹克的左边口袋上的第三个像素,对应到你标准3D人体模型的哪个具体位置?
-
通过UV Position Map,这个对应关系就建立起来了。UV图的每一个像素都和一个特定的身体部位绑定。比如,(U=0.5, V=0.5) 这个坐标可能永远代表人体的肚脐。
-
在类似 DensePose 这样的著名工作中,神经网络的任务就是从一张2D照片中,预测出这张UV Position Map。一旦预测成功,我们就等于获得了照片中每一个可见像素在标准3D人体模型上的精确对应位置,这是一个非常强大的信息。
-
-
解耦姿态和身份 (Decoupling Pose and Identity)
-
一个3D Avatar可以有标准形态 (比如T-Pose姿势下的模型),我们称之为 Canonical Shape。这张UV Position Map通常存储的就是这个标准形态下的 (X, Y, Z) 坐标。
-
当这个Avatar做出各种动作时(走路、跑步、跳跃),它的3D顶点位置会不断变化。但是,它的"皮"------也就是UV展开图------是不变的。
-
这意味着,无论Avatar摆出什么姿势,肚脐在UV图上的坐标永远是(0.5, 0.5)。深度学习模型可以专注于学习姿态变化导致的3D坐标变化,而不用关心这个人是谁、长什么样。
-
在实践中如何运作 (How it Works in Practice)
我们来看一个典型的3D Avatar生成流程:
-
输入: 一张普通的人物照片。
-
神经网络(通常是CNN): 模型的任务是输出一张或多张图,其中最重要的一张就是UV Position Map。
-
模型如何学习?
-
在训练阶段,研究人员会用大量成对的数据:人物照片, 对应的真实UV Position Map。
-
模型通过学习,掌握从人物照片的像素、轮廓、光影中,推断出其身体各部位在标准3D空间中位置的能力。
-
-
输出: 一张彩色的UV Position Map。
-
重建3D模型:
-
我们读取这张图的每一个像素。
-
假设在 (U=12, V=34) 处的像素值为 (R=0.8, G=0.2, B=0.5)。
-
我们将其解码为3D坐标 (X=0.8, Y=0.2, Z=0.5)。(注:实际中会有归一化和缩放处理)
-
这样,我们就得到了成千上万个3D空间中的点,这些点云(Point Cloud)就构成了人物的3D形状。再通过预定义的网格拓扑连接起来,就得到了一个完整的、带有姿态的3D Avatar Mesh。
-