此分类用于记录吴恩达深度学习课程的学习笔记。
课程相关信息链接如下:
- 原课程视频链接:双语字幕吴恩达深度学习deeplearning.ai
- github课程资料,含课件与笔记:吴恩达深度学习教学资料
- 课程配套练习(中英)与答案:吴恩达深度学习课后习题与答案
经过第二周的基础补充,本周内容的理解难度可以说有了很大的降低,主要是从逻辑回归扩展到浅层神经网络,讲解相关内容,我们按部就班梳理课程内容即可,当然,依旧会尽可能地创造一个较为丝滑的理解过程。
1.神经网络
1.1 逻辑回归的网络结构
在第二周我们已经知道,逻辑回归是通过一次线性组合和sigmoid激活函数来进行二分类的算法,现在,我们用神经网络的结构来描述一下逻辑回归,如下图所示:
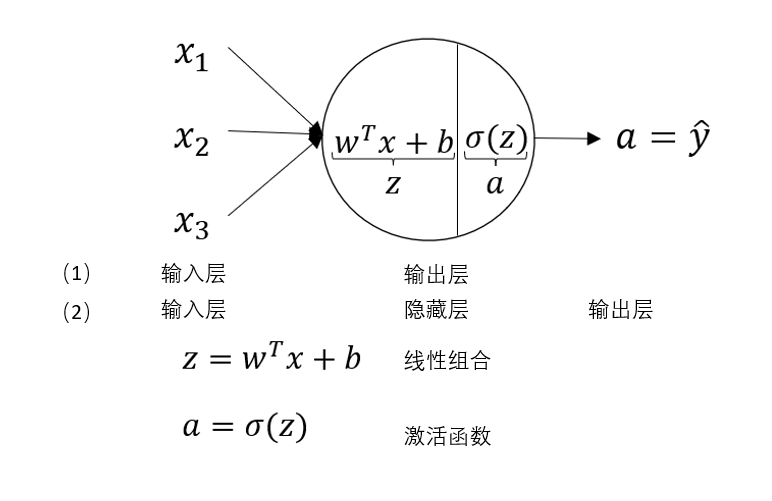
对于输入层,隐藏层,输出层,我们在第一周的内容里就已经进行过相关介绍。
为什么在这里写了两种层级划分形式呢?
我们回到之前总结的内容:逻辑回归 =线性组合+sigmoid
一般来说,对于二分类问题,我们会在输出层设置 sigmoid 激活函数,来对隐藏层的输出再进行最终的组合和映射。
但逻辑回归的结构过于简单,它的内容只有一次线性组合和sigmoid,而这二者在一个神经元里即可完成设置。
因此,我们可以把逻辑回归的网络看作没有隐藏层,又或者输出层不做任何处理。
这些都是结构上的划分,我们明白意思,知道算法的内容即可。
最后总结一下逻辑回归,可以说,逻辑回归的核心还是对数据进行线性拟合,只是其经过sigmoid输出的是概率而非直接的数值。
在上周的代码实践部分中,我们也能发现,逻辑回归展现出的性能略显不足。
我们通过逻辑回归了解了一个最简单的神经网络的运行过程,而现在就需要更进一步了。
1.2 一个浅层神经网络的网络结构
来看这样一个稍复杂点的神经网络:
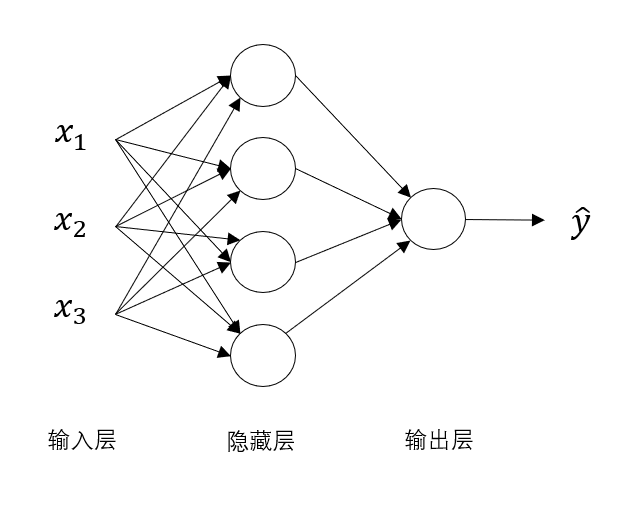
很明显,隐藏层神经元从一个变成了四个,每一个神经元的结构都和刚刚包含线性组合和激活函数的神经元一样。
一直以来,我们都有这样的认知:更复杂的神经网络能拟合更复杂的数据,得到更好的模型 。
而现在,面对这个比逻辑回归复杂了一些的浅层神经网络,它又是如何做到更好的拟合效果呢?
我们用浅层神经网络再来一次传播。
2.浅层神经网络的正向传播
在之前的向量化学习内容中,我们知道了逻辑回归,即只有一个隐藏神经元的神经网络的正向传播过程,而现在我们来看一下浅层神经网络的正向传播。
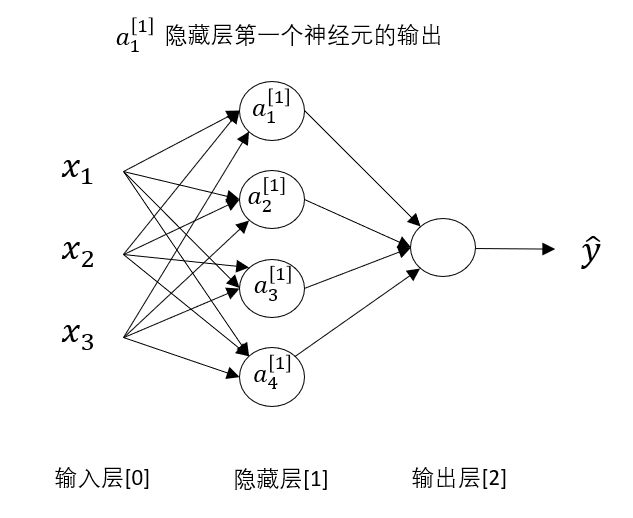
先引入一些新的符号。
在之前的内容里,我们知道:
- \(x^{(i)}\) 中的 \(i\) 代表第 \(i\) 个样本
- \(x_i\) 中的 \(i\) 代表某个样本的第 \(i\) 个变量
现在,我们对神经网络的层级进行划分,规定:\(x^{i}\) 中的 \(i\) 代表这个量来自第 \(i\) 层 。
我们按照课程内容对各层划分,规定输入层为第0层,此后依次增加。
要说明的是并非隐藏层就是第1层,输出就是第2层,只是这个浅层神经网络中只有一层隐藏层,所以输出是第2层。
因此,如图所示: \(a^{1}_1\) 就代表第一层第一个神经元的输出。
现在,我们系统地梳理一遍浅层神经网络的向量化正向传播过程:
2.1 输入特征
没有变化:
- 对于单个样本:
\\\mathbf{x} = \\begin{bmatrix} x_1 \\\\ x_2 \\\\ \\vdots \\\\ x_n \\end{bmatrix} \\quad (n \\times 1) \\
- 对于一个批次,\(m\) 个样本:
\\\mathbf{X} = \\begin{bmatrix} \\vdots \& \\vdots \& \\vdots \& \\cdots \& \\vdots \\\\ x\^{(1)} \& x\^{(2)} \& x\^{(3)} \& \\cdots \& x\^{(m)} \\\\ \\vdots \& \\vdots \& \\vdots \& \\cdots \& \\vdots \\end{bmatrix} \\quad (n \\times m) \\
2.2 隐藏层的参数设置
这里我们按上面的网络结构定为4个隐藏神经元:
- 对于单个神经元,其权重向量为:
\\\mathbf{w\^{\[1}_i} = \begin{bmatrix} w_1 \\ w_2 \\ \vdots \\ w_n \end{bmatrix} \quad (n \times 1)\]
- 现在,我们把4个神经元的权重向量组合在一起得到隐藏层权重矩阵\(W^{1}\),其中每一行 \(\mathbf{w^{1}_i}\)
是连接输入层到第 \(i\) 个隐藏神经元的权重向量。
\\\mathbf{W\^{\[1}} = \begin{bmatrix} - & (\mathbf{w^{1}_1})^T & - \\ - & (\mathbf{w^{1}_2})^T & - \\ - & (\mathbf{w^{1}_3})^T & - \\ - & (\mathbf{w^{1}_4})^T & - \\ \end{bmatrix} \quad (4 \times n) \]
- 同理,我们得到偏置矩阵:
\ \\mathbf{b\^{\[1}} = \begin{bmatrix} b^{1}_1 \\ b^{1}_2 \\ b^{1}_3 \\ b^{1}_4 \end{bmatrix} \quad (4 \times 1) \]
要说明的是,我们已经知道了广播机制,所以现在\(\mathbf{b^{1}}\)中的每个量都是标量,在进行加权和运算时会自动向右复制为 \(m\) 列来配合运算,不直接定义为一个标量是因为每个神经元的偏置不同。
2.3 隐藏层的线性加权和
最终,我们向量化的线性组合公式如下:
\\\mathbf{Z\^{\[1}} = \mathbf{W^{1}} \mathbf{X} + \mathbf{b^{1}} \]
我们展开来看一下\(\mathbf{Z^{1}}\) 的具体内容:
\\\mathbf{Z\^{\[1}} = \begin{bmatrix} | & | & | & \cdots & | \\ \mathbf{z^{1}_1} & \mathbf{z^{1}_2} & \mathbf{z^{1}_3} & \cdots & \mathbf{z^{1}_m} \\ | & | & | & \cdots & | \end{bmatrix} \]
再细化一下:
\\\mathbf{Z\^{\[1}} = \begin{bmatrix} (\mathbf{w^{1}_1})^T \mathbf{x}^{(1)} + b^{1}_1 & \cdots & (\mathbf{w^{1}_1})^T \mathbf{x}^{(m)} + b^{1}_1 \\ (\mathbf{w^{1}_2})^T \mathbf{x}^{(1)} + b^{1}_2 & \cdots & (\mathbf{w^{1}_2})^T \mathbf{x}^{(m)} + b^{1}_2 \\ (\mathbf{w^{1}_3})^T \mathbf{x}^{(1)} + b^{1}_3 & \cdots & (\mathbf{w^{1}_3})^T \mathbf{x}^{(m)} + b^{1}_3 \\ (\mathbf{w^{1}_4})^T \mathbf{x}^{(1)} + b^{1}_4 & \cdots & (\mathbf{w^{1}_4})^T \mathbf{x}^{(m)} + b^{1}_4 \end{bmatrix} \quad (4 \times m) \]
这样,我们就得到了一批次样本在分别在四个隐藏神经元上线性组合得到的加权和。
2.4 隐藏层的激活函数
每个隐藏神经元的输出为:
\\\mathbf{A\^{\[1}} = g(\mathbf{Z^{1}}) \quad (4 \times m) \]
其中 \(g(x)\) 是激活函数(例如 ReLU、tanh、sigmoid)。
到这里,我们就得到了隐藏层的输出,同时,这也是输出层的输入。
2.5 输出层的参数设置
输出层只有一个神经元,用来生成最终的预测值。
我们先再看一眼输入\(\mathbf{A^{1}}\) ,他代表的是一批次样本在分别在四个隐藏神经元上的输出,其中每一个元素就代表一个样本经过一个隐藏层神经元的输出。
再说到行列:
\(\mathbf{A^{1}}\) 的一行代表所有样本在一个隐藏神经元上的输出,一列代表一个样本在所有隐藏神经元上的输出。
按计算的位置来说,在这里一个样本在每个隐藏神经元上的输出和之前的每个样本的输入特征相同
我们再次进行线性组合,依然要以样本为单位。
- 权重向量如下,再次强调区分: 隐藏层存在多个神经元 ,所以 \(\mathbf{W^{1}}\)里的每个元素是向量 ,而输出层只有一个神经元 ,所以 \(\mathbf{W^{2}}\)里的每个元素是标量。
\ \\mathbf{W\^{\[2}} = \begin{bmatrix} w^{2}_1 & w^{2}_2 & w^{2}_3 & w^{2}_4 \end{bmatrix} \quad (1 \times 4) \]
- 偏置矩阵如下,其列数和该层神经元数量相同。
\ \\mathbf{b\^{\[2}} = \begin{bmatrix} b^{2} \end{bmatrix} \quad (1 \times 1) \]
2.6 输出层的线性组合和激活
公式如下:
\\\mathbf{Z\^{\[2}} = \mathbf{W^{2}} \mathbf{A^{1}} + \mathbf{b^{2}} \quad (1 \times m) \]
\ \\mathbf{A\^{\[2}} = g(\mathbf{Z^{2}}) \quad (1 \times m) \]
如果说 \(\mathbf{A^{1}}\) 的每个元素代表了一个样本在经过各个输入特征加权后的中间表达结果,那么 \(\mathbf{A^{2}}\) 的每个元素便进一步综合了该样本在所有隐藏神经元上的响应,得到该样本在输出层的最终预测值。
从这句话,或许便可以从逻辑上来帮助理解更复杂的网络能得到更好的拟合效果的原因。
2.7 总结
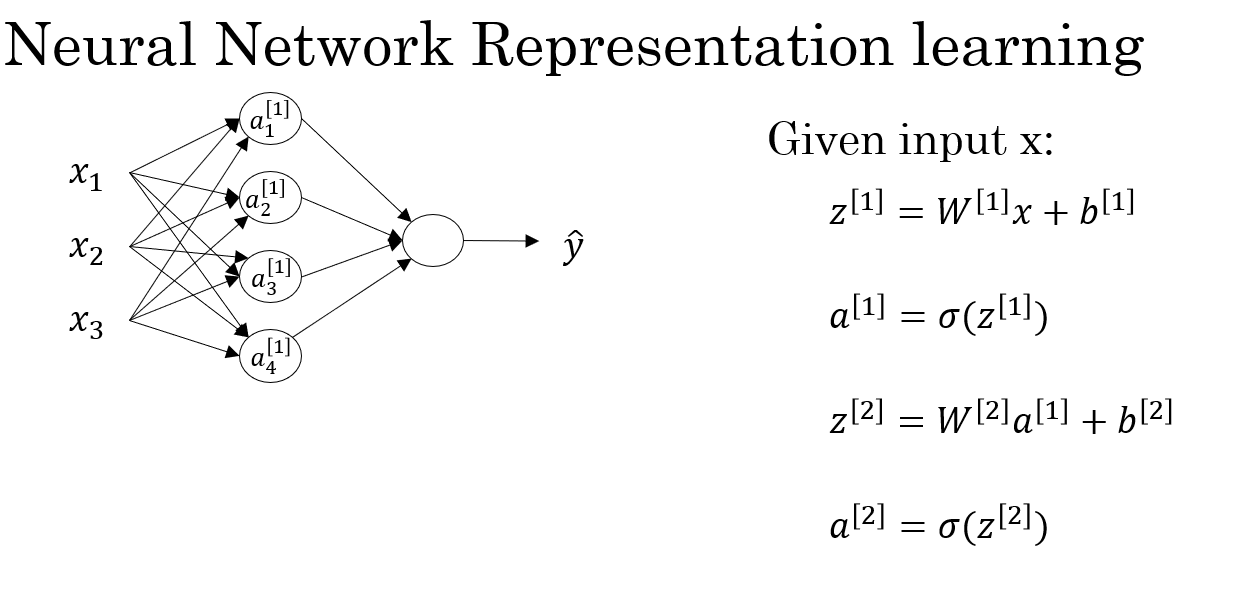
这便是课程中给出的总结部分,一次正向传播实际上便是四个公式的运算,我们也总结一下本次过程中各种量的变化如下:
| 层级 | 符号 | 含义 | 维度 |
|---|---|---|---|
| 输入层 | 𝑋 | 所有输入样本 | (n × m) |
| 隐藏层权重 | \(W^{1}\) | 输入→隐藏层连接 | (4 × n) |
| 隐藏层偏置 | \(b^{1}\) | 每个神经元偏置 | (4 × 1) |
| 隐藏层线性输出 | \(Z^{1}\) | 加权和 | (4 × m) |
| 隐藏层激活 | \(A^{1}\) | 非线性输出 | (4 × m) |
| 输出层权重 | \(W^{2}\) | 隐藏层→输出层连接 | (1 × 4) |
| 输出层偏置 | \(b^{2}\) | 输出层偏置 | (1 × 1) |
| 输出层线性输出 | \(Z^{2}\) | 加权和 | (1 × m) |
| 最终输出 | \(A^{2}\) | 模型预测 | (1 × m) |
下一篇会再展开一下激活函数来叙述复杂网络提高拟合能力的原因,并梳理浅层神经网络如何应用梯度下降,即反向传播的过程。