Nginx 基于 Epoll 模型的高性能负载均衡能力确实卓越,但其自身可能成为单点瓶颈的问题也确实存在。不过请放心,业界有非常成熟的高可用(High Availability, HA)方案来解决这个问题,核心思路就是 "为 Nginx 本身也建立一个备份机制"。
下面这张图清晰地展示了最经典的 Nginx 高可用主动-备份方案如何工作: 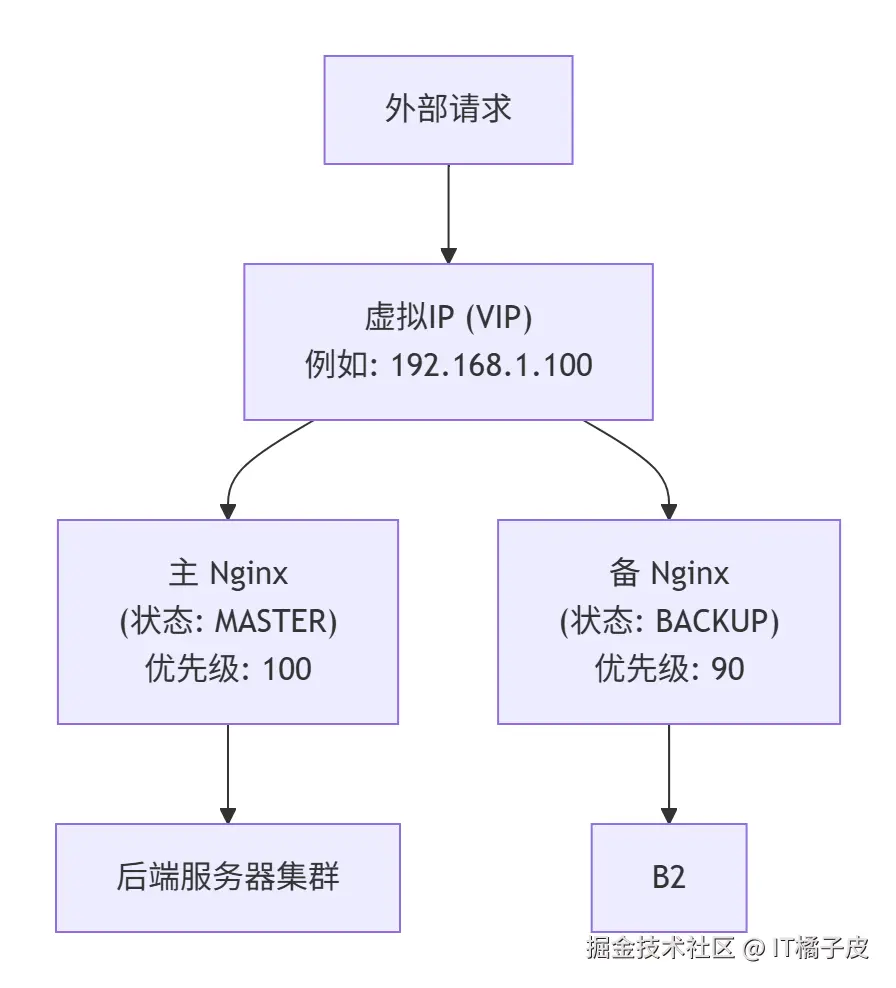
🔄 核心方案:Nginx + Keepalived 实现高可用集群
这是最常见且成熟的解决方案,它通过 Keepalived 软件实现故障自动转移(Failover)。
-
工作原理 :部署至少两台 Nginx 服务器,一主一备。它们共同绑定一个虚拟 IP 地址(Virtual IP, VIP),这个 VIP 是对外提供服务的入口。Keepalived 会在主备节点间维持心跳检测。当主节点故障时,备用节点会自动接管 VIP,继续提供服务,整个过程对用户几乎无感知 。
-
关键工具:
- Keepalived:一个用于实现高可用的软件,负责管理 VIP 并在节点间进行健康检查 。
- VRRP 协议:Keepalived 基于 VRRP(虚拟路由冗余协议)实现 VIP 的漂移 。
⚙️ 部署与优化要点
要确保高可用集群稳定可靠,需要注意以下几个关键配置点:
-
Keepalived 配置 :在主备节点的
keepalived.conf配置文件中,需要明确设置state(主备角色)、priority(优先级,主节点应更高)和共享的virtual_router_id等参数 。 -
Nginx 健康检查 :为了实现真正的端到端高可用,最好配置一个脚本,让 Keepalived 不仅检查 Nginx 进程是否存在,还能检查其端口是否可响应。可以在配置中定义
vrrp_script块,定期执行检查 Nginx 的脚本 。例如:bash#!/bin/bash A=`ps -C nginx --no-header | wc -l` if [ $A -eq 0 ]; then # 尝试重启nginx,若失败则停止keepalived以触发故障转移 /usr/local/nginx/sbin/nginx sleep 2 if [ `ps -C nginx --no-header | wc -l` -eq 0 ]; then killall keepalived fi fi -
脑裂问题处理:确保网络稳定,避免网络分区导致主备节点同时认为自己是主节点(即"脑裂")。可以通过配置合理的认证方式和优先级调整策略来缓解。
🚀 超越主动-备份:更高级的架构
对于需要极致性能和水平扩展的超大型应用,可以考虑以下更高级的架构:
- Nginx 集群 + DNS 轮询或 LVS :可以部署多个对等的 Nginx 服务器组成集群,前端通过 DNS 轮询 或 LVS(Linux Virtual Server) 进行四层负载均衡,将流量分发到整个 Nginx 集群。这消除了单点故障,并能实现性能的线性扩展 。
- 云负载均衡器:如果服务部署在公有云上,直接使用云服务商提供的负载均衡器(如 AWS ALB/NLB、Google Cloud CLB、Azure Load Balancer)是更简单高效的选择。它们天生高可用、无需自行维护,并能自动扩展。
- 容器化与编排:在 Kubernetes 等容器编排平台中,可以轻松部署多个 Nginx 实例作为 Ingress Controller,通过 Kubernetes 的 Service 机制实现负载均衡和故障转移,具备强大的自愈和弹性伸缩能力 。
💎 总结
解决 Nginx 单点瓶颈的核心在于引入冗余和自动故障转移机制 。对于大多数场景,Nginx + Keepalived 的主备方案 是一个稳定、成本效益高的选择。随着业务规模增长,可以考虑演进到集群化架构 或直接采用云原生解决方案。