目录
[1 transformer分支](#1 transformer分支)
[1.1 概述](#1.1 概述)
[1.2 Encoder-only](#1.2 Encoder-only)
[1.2.1 文章背景](#1.2.1 文章背景)
[1.2.2 方法](#1.2.2 方法)
[1.2.3 实验结果分析](#1.2.3 实验结果分析)
[2 simon算法](#2 simon算法)
[3 总结](#3 总结)
摘要
本周首先了解了Transformer的三大分支;其次通过阅读论文对其中的Encoder-only分支进行了了解,学习了BERT模型的方法、创新与优势所在;最后学习了量子计算中的simon算法,了解了其方法步骤以及相对经典计算的优越性。
Abstract
This week, I first learned about the three main branches of the Transformer architecture. Then, by reading relevant papers, I gained an understanding of the Encoder-only branch and studied the methodology, innovations, and advantages of the BERT model. Finally, I explored Simon's algorithm in quantum computing, comprehending its procedural steps and its advantages over classical computing.
1 transformer分支
1.1 概述
Transformer家族中最重要的三大架构分支分别是 Encoder-only、Decoder-only 与 Encoder-Decoder。
其中 Encoder-only 的核心思想是双向上下文编码以全面理解输入信息,代表性模型包括BERT、RoBERTa 与 DeBERTa,主要适用于文本分类、情感分析命名实体识别与问答等任务;Decoder-only 的核心思想是单向自回归生成,主要根据上文来预测下一个词,代表性模型有GPT系列, LLaMA与Bloom等,主要适用于文本生成、对话、续写、代码生成等任务;Encoder-Decoder 则完整采用前面学习的原始Transformer的编码器-解码器结构,先编码输入,再基于编码结果解码输出,代表性模型包括Transformer、BART与T5,主要用于翻译、摘要和问答生成。
1.2 Encoder-only
通过阅读论文《BERT: Pre-training of Deep Bidirectional Transformers》来了解 Encoder-only这一分支。这篇文章主要提出了 BERT 模型以解决和改进自然语言处理(NLP)任务中预训练语言表示的双向上下文建模问题。
1.2.1 文章背景
文章提出,当前(2018)将预训练的语言表示应用于下游任务有两种策略,基于特征和微调。而这两者均使用单向语言模型,例如使用左到右的Transformer,导致预训练时模型只能关注单侧上下文,限制了预训练表示的能力,尤其对于微调方法。 这种限制使得模型无法充分捕捉语言的双向依赖关系,理解深层次上下文时性能受限,从而在句子级任务(如自然语言推理)和词级任务(如问答)中表现不佳。
BERT通用性强,只需通过快速的微调即可适应多种任务,无需针对每个任务设计复杂架构,减少了工程开销。而且它在11个NLP任务上实现了最先进的性能,例如将 GLUE 分数提升至80.5%(绝对提升7.7%)等,证明了双向预训练对于语言表示的重要性。这也是其创新点所在,另外它不仅结合 MLM 和下一句预测(NSP)任务以同时学习词级和句子级表示,还在预训练和微调时使用相同的架构,简化了流程。
p.s. GLUE 是 General Language Understanding Evaluation 的缩写,它是一个综合性的多任务自然语言理解基准和评测平台。
1.2.2 方法
文章中预训练语料库采用的是包含8亿单词的 BooksCorpus 与包含25亿单词的英语维基百科(提取文本段落,忽略列表、表格以及标题)。其关键与特殊之处在于使用文档级语料(而非打乱的句子级)以获取连续长序列,提升上下文学习能力,并使用词汇表大小为30,000的 WordPiece 分词来处理未登录词和子词。
p.s. BooksCorpus,有时也被称为 Toronto BookCorpus,是一个大规模、纯文本的语料库,其内容来源于数千本尚未出版的原著书籍。
BERT最核心的创新是 MLM 与 NSP 的协同。一方面,它引入MLM(掩码语言模型, Masked Language Model),其思想是随机掩码输入序列中15%的令牌,然后训练模型根据未被掩码的上下文来预测被掩码的原始词。由于被掩码的词本身位于序列中间,Transformer Encoder 的Self-Attention 机制可以同时关注所有位置的令牌来获取信息,这使得模型从第一层开始就是双向的,每一层的表示都融合了完整的上下文信息。另一方面,它引入NSP任务(下一句预测,Next Sentence Prediction),其思想是在预训练时,给模型输入两个句子 A 和 B ,其中50%的情况下 B 是 A 的真实下一句,50%的情况下 B 是随机选取的句子。模型要做的就是预测B是否是A的下一句。这个任务迫使模型学习如何编码单个句子的语义,以及如何比较和对比两个句子,并从中学习到句子间的连贯性、因果关系等逻辑。MLM 和 NSP 任务在同一个模型中联合训练,使得BERT学到的表示同时蕴含了词级的深层语义信息和句级的逻辑关系信息,成为一个功能强大的通用语言表示模型。
p.s. 在 MLM 中也有一个小创新。其解决的问题是如果在预训练时总是用 MASK 令牌替换目标词,那么在微调阶段,由于输入中是真实词语而没有 MASK,会导致模型看到的数据分布与预训练时不同,产生性能损失。解决方法是对于15%被选中的待预测令牌,采用随机替换策略,即80%的概率替换为 MASK,10%的概率替换为随机词,10%的概率保持不变,这一策略迫使模型减少对输入的偏见,必须依赖上下文做出预测。
另外,BERT在流程与架构上也进行了创新。在流程上,先利用 MLM 与 NSP 协同进行预训练,再直接用下游任务的数据和标签,对整个预训练BERT模型的所有参数进行轻微的再训练(端到端微调),不仅简单高效,性能也高;在架构上,它完全基于Transformer Encoder,其自注意力机制如上文所述,关注序列中的其他所有位置,天然适合 MLM 任务,而且预训练和微调使用完全相同的核心架构。从预训练到下游任务,只需更换最顶层的输出,而无需改动主体模型结构,极大地简化了流程,降低了应用门槛
1.2.3 实验结果分析
文章展示了 BERT 在11个 NLP 任务上的微调结果。
在GLUE基准上,BERT-BASE 和 BERT-LARGE 在全部任务上都超越了之前的最佳系统,平均准确率分别提升4.5%和7.0%。例如,在MNLI任务上准确率分别提升2.5%与4.6%,在CoLA上分别提升6.7%与15.1%;
在斯坦福问答数据集上(SQuAD v1.1与v2.0),BERT-LARGE 单模型 F1 分别达90.9与83.1;
在SWAG(Situations With Adversarial Generations)上,BERT-LARGE准确率也比 OpenAI GPT 高出8.3%。
p.s. BERT-BASE 包含110M参数,BERT-LARGE 包含340M参数。
文章还指出,进行消融实验(用于了解模型各个方面的相对重要性)后发现,首先,去除NSP任务会导致QNLI、MNLI和SQuAD性能下降,其次,更大的模型在四个数据集上的准确率都有明确的提升;最后,它对于微调和基于特征的方法都是有效的。
2 simon算法
上周学习的Deutsch算法与Deutsch-Josa算法只能用来判断函数的性质(常数or平衡),而无法得知函数的具体内容。
在此基础上,计算机科学家丹尼尔·西蒙(Daniel R. Simon)在1994年提出了一种量子算法--Simon算法。它解决的是一个被称为"Simon问题"(Simon's problem)的特定计算问题,并且在该问题上展示了量子计算相对于经典计算的指数级加速。
Simon问题是:假设给定一个未知函数 (将一个 n 位的二进制字符串映射到另一个 n 位的二进制字符串),并承诺存在一个秘密字符串 ,使得对于所有
均存在:
目标就是找到这个秘密字符串 s (,函数为单射;
,函数为二对一)。
在经典计算模型下,要确定 s ,最有效的方法是不断对函数进行查询,寻找碰撞(即找到两个不同的输入使得它们输出相等),在最坏的情况下,可能需要查询函数高达 次才能保证找到一个碰撞。因此,它的时间复杂度是关于 n 的指数级
而Simon算法利用了量子叠加和量子并行性的特性,可以在多项式时间内解决这个问题。它的量子电路大致如下:
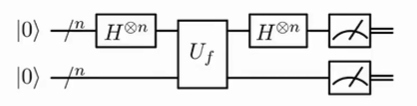
步骤大致如下:

最后对两个寄存器均进行测量
上图最后一步结果可重新组织求和顺序如下:
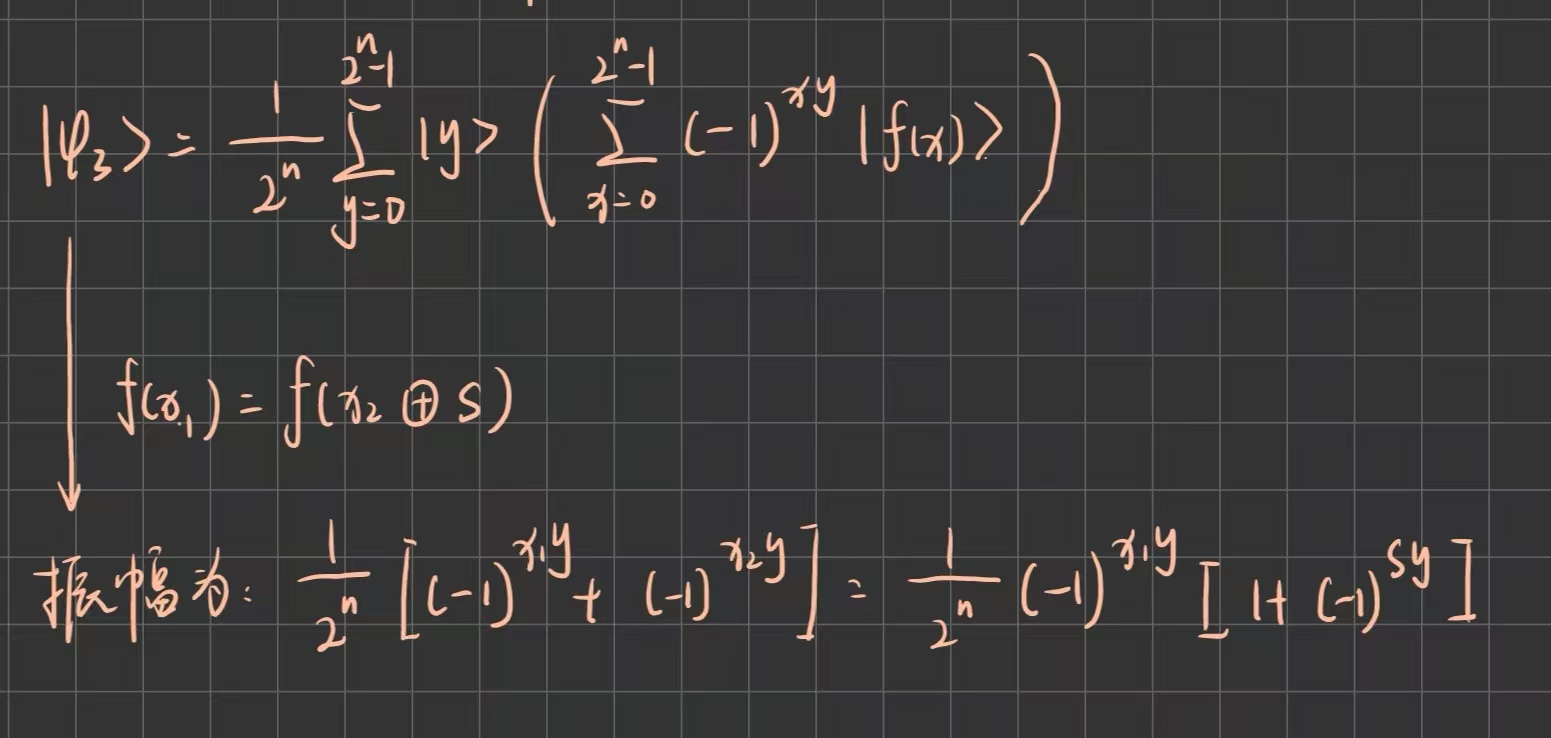
若 ,则振幅不为0(相长干涉);若
,则振幅为0(相消干涉)。
p.s. 相长干涉是指当两个路径的振幅相位相同时,它们相互加强;相消干涉是指当两个路径的振幅相位相反时,它们相互抵消。可以想象两个水波相遇,相长干涉是指波峰与波峰相遇,振幅增强;相消干涉则指波峰与波谷相遇,振幅抵消。
因此,测量结果 y 必须满足 ,这也给出了关于 s 的一个线性方程(测出的 y 与 s 按位相乘并求和,最终结果为0)。
完整算法步骤需要重复执行上述量子部分以收集 n-1 个线性无关的方程(如果收集到了n个,则代表方程组有唯一解(即零解,s=0,此时函数为单射)),然后利用高斯消元法求解 s,并通过对所有可能的 y 进行计算,观察其与测量结果是否一致来验证其是否正确。
以 n = 3 为例:

可发现可能测量到的 y 值为000, 011, 101, 110,与测量结果一致。
Simon算法只需要O(n)次查询(即运行量子电路O(n)次)就可以以高概率得到 n-1 个线性无关的方程,然后通过经典的高斯消元(复杂度O(n^3))求解 s ,实现了从经典到量子的指数级加速,是量子计算优越性的一个早期、严格的证明,展示了量子计算机在处理具有隐藏结构(如周期性)的问题上的巨大潜力。它的思想直接启发了用于大数质因数分解和离散对数问题的Shor算法的设计,对现代密码学(如RSA)构成了潜在威胁。
3 总结
本周首先通过论文对BERT进行了了解,感觉学得比较浅显,下周考虑找个实战项目做;在阅读文献时,文章中提到的很多东西(例如*BooksCorpus,GLUE)*都是第一次接触,虽然文中有介绍,但感觉仍需进行积累;在量子计算方面主要学习了simon算法,由于其对shor算法的启发性,下周可能会对它进行学习,也有可能会对前两个算法进行代码复盘。