前言
接上一篇文章,基于kernel-6.6,在thermal子目录下可以看到cpufreq_cooling、cpuidle_cooling、devfreq_cooling几种 cooling device 对象的实现,概括一下:
-
cpufreq_cooling:把"冷却状态(cooling state)"映射到 CPU 频率限制(通过 cpufreq / PM QoS / EM),用于用降频来被动散热或按照"功率预算"分配频率。
-
cpuidle_cooling:用 idle injection(模拟/增加空闲时间)来让 CPU 更"空闲"以减少功耗和热量;状态以 0...100% 的注入比表示。适合能在运行时注入空闲的 platform/cluster。
-
devfreq_cooling:把冷却状态映射到 devfreq 设备的频率(通过 PM QoS 限制或直接设置 devfreq),用于对 GPU、NPU、bus 等非-CPU 设备做频率/功耗限速。也可使用 Energy Model(EM)来估算频率→功耗映射。
1 devfreq_cooling
为 devfreq 设备创建一个 thermal cooling device,使 thermal 子系统(或 power-type governor)能以"频率限制"或"功率预算"方式控制该设备,从而调节设备发热与系统温度。实现既支持 Energy Model (EM)/OPP 下的精确功率映射,也向后兼容没有 EM 的情况(通过 OPP 表生成频率表)
1.1 数据结构
1.1.1 devfreq_cooling_power
Linux 内核中 struct devfreq_cooling_power 的成员 get_real_power,它与 Devfreq 的热管理和功耗管理相关。
c
struct devfreq_cooling_power {
int (*get_real_power)(struct devfreq *df, u32 *power,
unsigned long freq, unsigned long voltage);
};- 用途:提供设备在当前状态下的 真实功耗,用于 Devfreq 的热管理和功耗控制。
- get_real_power 成员函数,驱动可选实现:
(1)如果实现 → 框架调用它获取更准确的功耗。
(2)如果没实现 → 框架用表格+利用率计算功耗。
1.1.2 devfreq_cooling_device
c
/**
* struct devfreq_cooling_device - Devfreq cooling device
* devfreq_cooling_device registered.
* @cdev: Pointer to associated thermal cooling device.
* @cooling_ops: devfreq callbacks to thermal cooling device ops
* @devfreq: Pointer to associated devfreq device.
* @cooling_state: Current cooling state.
* @freq_table: Pointer to a table with the frequencies sorted in descending
* order. You can index the table by cooling device state
* @max_state: It is the last index, that is, one less than the number of the
* OPPs
* @power_ops: Pointer to devfreq_cooling_power, a more precised model.
* @res_util: Resource utilization scaling factor for the power.
* It is multiplied by 100 to minimize the error. It is used
* for estimation of the power budget instead of using
* 'utilization' (which is 'busy_time' / 'total_time').
* The 'res_util' range is from 100 to power * 100 for the
* corresponding 'state'.
* @capped_state: index to cooling state with in dynamic power budget
* @req_max_freq: PM QoS request for limiting the maximum frequency
* of the devfreq device.
* @em_pd: Energy Model for the associated Devfreq device
*/
struct devfreq_cooling_device {
// thermal core -> cooling device虚拟结构 -> devfreq_cooling_device 调用链的绑定
struct thermal_cooling_device *cdev; // cooling device对象
// cooling_device 的具体操作函数集
struct thermal_cooling_device_ops cooling_ops;
struct devfreq *devfreq; // 关联的 devfreq 设备(实际硬件抽象)
unsigned long cooling_state; // 状态值
u32 *freq_table; // 频率表(降序),当没有 EM 时使用。
size_t max_state; // 最大 state(索引形式,num_opps - 1)。
struct devfreq_cooling_power *power_ops; // 可选的 driver 提供的"实际功率"函数集合(get_real_power 等)。
u32 res_util; // 资源利用率缩放因子(用于功率估算/缩放,见 SCALE_ERROR_MITIGATION)
int capped_state; // 在 power → state 估算中记录的 cap state。
struct dev_pm_qos_request req_max_freq; // PM-QoS 请求句柄,用来下发最大频率限制(dev_pm_qos_add_request / dev_pm_qos_update_request)。
struct em_perf_domain *em_pd; // Energy Model domain(如果存在),用于频率↔功率的准确映射。
};1.2 关键函数
1.2.1 函数注册/卸载
从头文件定义中可以看到函数注册、卸载的定义。需要配置 CONFIG_DEVFREQ_THERMAL。
c
#ifdef CONFIG_DEVFREQ_THERMAL
struct thermal_cooling_device *
of_devfreq_cooling_register_power(struct device_node *np, struct devfreq *df,
struct devfreq_cooling_power *dfc_power);
struct thermal_cooling_device *
of_devfreq_cooling_register(struct device_node *np, struct devfreq *df);
struct thermal_cooling_device *devfreq_cooling_register(struct devfreq *df);
void devfreq_cooling_unregister(struct thermal_cooling_device *dfc);
struct thermal_cooling_device *
devfreq_cooling_em_register(struct devfreq *df,
struct devfreq_cooling_power *dfc_power);
#else /* !CONFIG_DEVFREQ_THERMAL */其中有多种类型的 register 函数,简单归结一下,执行关系如下:
① devfreq_cooling_register → of_devfreq_cooling_register → of_devfreq_cooling_register_power
② devfreq_cooling_em_register → of_devfreq_cooling_register_power
以下分三个部分解析:
devfreq_cooling_register
(1)devfreq_cooling_register(struct devfreq *df)
作用:
最基础的接口,不依赖 Device Tree。直接在 驱动代码里调用,为一个 devfreq 设备注册 cooling device。只支持"频率状态"型的 cooling device(没有功率模型)。
调用场景:
设备驱动想手动把自己的 devfreq 设备挂到 thermal 框架,不依赖 DT 描述。常见于非 DT 平台,或者驱动自行管理 cooling 注册。
c
/**
* devfreq_cooling_register() - Register devfreq cooling device.
* @df: Pointer to devfreq device.
*/
struct thermal_cooling_device *devfreq_cooling_register(struct devfreq *df)
{
return of_devfreq_cooling_register(NULL, df);
}
EXPORT_SYMBOL_GPL(devfreq_cooling_register);(2)of_devfreq_cooling_register(struct device_node *np, struct devfreq *df)
作用:
和上一个类似,但 不提供功率模型。cooling device 只能实现最基本的 get_max_state / get_cur_state / set_cur_state,仅支持用"频率级别"来限制设备频率。
调用场景:
平台代码想用 devfreq 设备作为 cooling device,但 不需要精确的功率控制,只需要限制频率。比如某些 GPU、总线频率调节。
c
/**
* of_devfreq_cooling_register() - Register devfreq cooling device,
* with OF information.
* @np: Pointer to OF device_node.
* @df: Pointer to devfreq device.
*/
struct thermal_cooling_device *
of_devfreq_cooling_register(struct device_node *np, struct devfreq *df)
{
return of_devfreq_cooling_register_power(np, df, NULL);
}
EXPORT_SYMBOL_GPL(of_devfreq_cooling_register);devfreq_cooling_em_register
作用:
devfreq_cooling_em_register(struct devfreq *df, struct devfreq_cooling_power *dfc_power) 将一个 devfreq 设备注册为 thermal cooling device(热管理冷却设备),并尝试为它注册 Energy Model (EM)。dfc_power 携带能量模型信息,可以用 EM 来做频率/功率映射。用于让 cooling device 和 kernel 的 EM 框架配合,实现更精确的能耗/热管理。
参数说明:
df :指向需要注册为冷却器的 devfreq 设备。
dfc_power:指向 devfreq_cooling_power 结构体,如果代码提供了实现,则会在注册时绑定功耗信息(用于 EM)。
调用场景:
当 devfreq 设备支持 EM(比如 GPU、NPU),驱动就可以用这个接口注册 cooling device。governor(比如 power_allocator)就能用 EM 表来估算功率,分配预算更合理。
函数注释解析:
- 自动注册 Energy Model(EM):
函数会尝试调用 dev_pm_opp_of_register_em() 注册设备的 EM。
EM 用于功耗建模,为 devfreq 的 DVFS(动态电压频率调整)提供能耗数据。 - 关于可用 OPPs(Operating Performance Points):
EM 注册需要设备已经注册了 OPP 表,否则无法正常计算功耗。 - 关于 dfc_power:
如果提供,会注册功耗扩展。
使用简单 EM 模型,需要设备树中 dynamic-power-coefficient 属性。
如果 EM 注册失败,不会导致整个冷却器注册失败(兼容那些没有 DT 属性的驱动)。
c
/**
* devfreq_cooling_em_register() - Register devfreq cooling device with
* power information and automatically register Energy Model (EM)
* @df: Pointer to devfreq device.
* @dfc_power: Pointer to devfreq_cooling_power.
* * Register a devfreq cooling device and automatically register EM. The
* available OPPs must be registered for the device.
* * If @dfc_power is provided, the cooling device is registered with the
* power extensions. It is using the simple Energy Model which requires
* "dynamic-power-coefficient" a devicetree property. To not break drivers
* which miss that DT property, the function won't bail out when the EM
* registration failed. The cooling device will be registered if everything
* else is OK.
*/
struct thermal_cooling_device *
devfreq_cooling_em_register(struct devfreq *df,
struct devfreq_cooling_power *dfc_power)
{
struct thermal_cooling_device *cdev;
struct device *dev;
int ret;
// 先检查输入参数 df 是否为 NULL 或错误指针,如果是,返回错误。
if (IS_ERR_OR_NULL(df))
return ERR_PTR(-EINVAL);
// 获取 devfreq 对应的 父设备(通常是 SoC 内部的硬件设备)。
// df->dev 本身是 devfreq 的 device 结构,这里取 parent 通常是平台设备
dev = df->dev.parent;
ret = dev_pm_opp_of_register_em(dev, NULL);
if (ret)
dev_dbg(dev, "Unable to register EM for devfreq cooling device (%d)\n",
ret);
// of_devfreq_cooling_register_power: 调用 Energy Model 注册函数
// dev->of_node:设备树节点; df:对应 devfreq 设备; dfc_power:功耗数据,真实操作get函数
cdev = of_devfreq_cooling_register_power(dev->of_node, df, dfc_power);
// 如果冷却器注册失败,撤销之前的 EM 注册,保证状态一致性
if (IS_ERR_OR_NULL(cdev))
em_dev_unregister_perf_domain(dev);
return cdev;
}
EXPORT_SYMBOL_GPL(devfreq_cooling_em_register);【注】dev->of_node 解析
- 类型:struct device_node *
- 来源:
① 设备树(Device Tree)节点,用于描述硬件设备信息。
② dev->of_node 指向设备对应的设备树节点。 - 用途:
① 获取硬件属性:比如 reg, clocks, gpios, dynamic-power-coefficient 等。
② 平台设备初始化:驱动通过 of_node 获取硬件配置。
③ 注册 thermal cooling device:在 of_devfreq_cooling_register_power() 中,使用 of_node 获取功耗相关的 DT 属性(如 OPP 表、EM 参数)。
示例
c
cpu0: cpu@0 {
compatible = "arm,cortex-a76";
reg = <0x0 0x0 0x0 0x0>;
clocks = <&clk_cpu>;
dynamic-power-coefficient = <10>;
};dev->of_node 就指向 cpu@0 节点,驱动可以通过它获取 dynamic-power-coefficient。
of_devfreq_cooling_register_power
作用:
注册一个 devfreq cooling device,同时可以绑定 设备树节点(OF node) 和 功耗信息。
通过 Device Tree 节点 np 注册 devfreq cooling device,并且指定一个 功率模型(dfc_power)。这个功率模型提供了频率/电压与功率的映射,用于支持 power allocator governor。
参数说明:
device_node *np :设备树节点指针,对应设备硬件信息。
devfreq *df :devfreq 设备指针。
devfreq_cooling_power *dfc_power:功耗信息指针,如果提供则绑定功耗数据。
调用场景:
平台代码在解析设备树时调用,用来为 devfreq 设备创建 cooling device。如果 thermal zone 在 DT 中绑定了这个节点,thermal core 会自动连接。
关键点:
有功率模型 → cooling device 就能实现 power2state() / state2power() 接口, governor 就能用"功率预算"直接分配给它。
c
/**
* of_devfreq_cooling_register_power() - Register devfreq cooling device,
* with OF and power information.
* @np: Pointer to OF device_node.
* @df: Pointer to devfreq device.
* @dfc_power: Pointer to devfreq_cooling_power.
*
* Register a devfreq cooling device. The available OPPs must be
* registered on the device.
*
* If @dfc_power is provided, the cooling device is registered with the
* power extensions. For the power extensions to work correctly,
* devfreq should use the simple_ondemand governor, other governors
* are not currently supported.
*/
struct thermal_cooling_device *
of_devfreq_cooling_register_power(struct device_node *np, struct devfreq *df,
struct devfreq_cooling_power *dfc_power)
{
struct thermal_cooling_device *cdev; // 定义 cooling device 对象
struct device *dev = df->dev.parent; // 获取 devfreq 对应的 父设备
struct devfreq_cooling_device *dfc; // 内部保存 cooling device 的 devfreq 相关信息
struct em_perf_domain *em; // 指向 Energy Model(EM)的性能域,提供功耗和频率对应关系
struct thermal_cooling_device_ops *ops; // thermal cooling device 的操作接口
char *name;
int err, num_opps;
dfc = kzalloc(sizeof(*dfc), GFP_KERNEL); // 为 devfreq_cooling_device 分配内存
if (!dfc)
return ERR_PTR(-ENOMEM);
dfc->devfreq = df; // 关联 devfreq 设备,由参数传入
ops = &dfc->cooling_ops; // 初始化 ops 接口
// >>>>>>>>>> start: 设置 thermal cooling device 的基本接口函数
// 对标这个结构体 thermal_cooling_device_ops
ops->get_max_state = devfreq_cooling_get_max_state;
ops->get_cur_state = devfreq_cooling_get_cur_state;
ops->set_cur_state = devfreq_cooling_set_cur_state;
// 尝试绑定 Energy Model
em = em_pd_get(dev);
if (em && !em_is_artificial(em)) {
dfc->em_pd = em; // 绑定 EM 性能域 em_pd
// 添加功耗接口函数
ops->get_requested_power =
devfreq_cooling_get_requested_power;
ops->state2power = devfreq_cooling_state2power;
ops->power2state = devfreq_cooling_power2state;
// 设置 thermal cooling device 的基本接口函数 >>>>>>>>>> end
dfc->power_ops = dfc_power;
// 获取 OPP 数量
num_opps = em_pd_nr_perf_states(dfc->em_pd);
} else {
/* Backward compatibility for drivers which do not use IPA */
dev_dbg(dev, "missing proper EM for cooling device\n");
// 获取 OPP 数量
num_opps = dev_pm_opp_get_opp_count(dev);
// 生成冷却器内部 freq 表(devfreq_cooling_gen_tables())
err = devfreq_cooling_gen_tables(dfc, num_opps);
if (err)
goto free_dfc;
}
// 检查 OPP 数量
if (num_opps <= 0) {
err = -EINVAL;
goto free_dfc;
}
/* max_state is an index, not a counter */
// max_state 是状态 索引,所以是 num_opps - 1
dfc->max_state = num_opps - 1;
// PM QoS 用于动态管理最大频率,确保 cooling device 调节频率时可以通过 PM QoS 接口生效
err = dev_pm_qos_add_request(dev, &dfc->req_max_freq,
DEV_PM_QOS_MAX_FREQUENCY,
PM_QOS_MAX_FREQUENCY_DEFAULT_VALUE);
if (err < 0)
goto free_table;
err = -ENOMEM;
// 为 cooling device 创建唯一名字,例如 devfreq-cpu0
name = kasprintf(GFP_KERNEL, "devfreq-%s", dev_name(dev));
if (!name)
goto remove_qos_req;
// 调用 thermal framework 的 thermal_of_cooling_device_register() 注册 cooling device
// np:设备树节点,用于读取硬件信息和属性。
// name:设备名。
// dfc:devfreq_cooling_device。
// ops:接口函数。
cdev = thermal_of_cooling_device_register(np, name, dfc, ops);
kfree(name);
if (IS_ERR(cdev)) {
err = PTR_ERR(cdev);
dev_err(dev,
"Failed to register devfreq cooling device (%d)\n",
err);
goto remove_qos_req; // 注册失败则回滚 PM QoS 请求
}
dfc->cdev = cdev;
return cdev;
remove_qos_req:
dev_pm_qos_remove_request(&dfc->req_max_freq);
free_table:
kfree(dfc->freq_table); // 回收 freq_table
free_dfc:
kfree(dfc); // 回收 dfc 内存
return ERR_PTR(err);
}
EXPORT_SYMBOL_GPL(of_devfreq_cooling_register_power);【归纳】
| 函数 | 是否依赖 DT | 是否有功率模型 | 主要使用者 |
|---|---|---|---|
| of_devfreq_cooling_register_power | ✅ | ✅ | 平台代码 + DT + power governor |
| of_devfreq_cooling_register | ✅ | ❌ | 平台代码 + DT,只需频率限制 |
| devfreq_cooling_register | ❌ | ❌ | 驱动手动注册(非 DT 平台) |
| devfreq_cooling_em_register | ❌ | ✅ | 支持 EM(Energy Model) 的 devfreq 驱动 |
1.2.2 操作函数ops
cooling device的操作函数,映射到 devfreq cooling中,如下:
c
struct thermal_cooling_device_ops {
int (*get_max_state) (struct thermal_cooling_device *, unsigned long *);
// --> devfreq_cooling_get_max_state(struct thermal_cooling_device *cdev, unsigned long *state)
int (*get_cur_state) (struct thermal_cooling_device *, unsigned long *);
// --> devfreq_cooling_get_cur_state(struct thermal_cooling_device *cdev, unsigned long *state)
int (*set_cur_state) (struct thermal_cooling_device *, unsigned long);
// --> devfreq_cooling_set_cur_state(struct thermal_cooling_device *cdev, unsigned long state)
int (*get_requested_power)(struct thermal_cooling_device *, u32 *);
// --> devfreq_cooling_get_requested_power(struct thermal_cooling_device *cdev, u32 *power)
int (*state2power)(struct thermal_cooling_device *, unsigned long, u32 *);
// --> devfreq_cooling_state2power(struct thermal_cooling_device *cdev, unsigned long state, u32 *power)
int (*power2state)(struct thermal_cooling_device *, u32, unsigned long *);
// --> devfreq_cooling_power2state(struct thermal_cooling_device *cdev, u32 power, unsigned long *state)
};devfreq_cooling_xxx_state
devfreq_cooling_xxx_state 系类函数是thermal cooling device 的基本接口函数。逐个分析如下:
(1)devfreq_cooling_get_max_state
功能:获取冷却器的最大状态值。就是告诉 thermal 框架:该冷却器一共有多少个"档位"可以限制
c
static int devfreq_cooling_get_max_state(struct thermal_cooling_device *cdev,
unsigned long *state)
{
struct devfreq_cooling_device *dfc = cdev->devdata;
*state = dfc->max_state;
return 0;
}关键点:
- cdev->devdata 指向 struct devfreq_cooling_device。
- dfc->max_state 表示冷却器可用的最大状态(索引)。
① 状态值从 0 ~ max_state,一共 max_state + 1 个状态。
② 对应设备 OPP(性能点)的数量。
返回值:总是 0(成功)。
(2)devfreq_cooling_get_cur_state
功能:获取冷却器的当前状态。调用这个函数时,可以知道冷却器当前处于哪个档位。
c
static int devfreq_cooling_get_cur_state(struct thermal_cooling_device *cdev,
unsigned long *state)
{
struct devfreq_cooling_device *dfc = cdev->devdata;
*state = dfc->cooling_state;
return 0;
}关键点:
- dfc->cooling_state 保存当前 cooling state(状态索引)。
- 状态值范围:0 ~ max_state。
① 0 → 无限制(即允许最高性能频率)。
② 越大 → 冷却程度越强,对应更低的最大频率限制。
返回值:总是 0(成功)
(3)devfreq_cooling_set_cur_state
设置冷却器的当前状态(即限制设备的最高运行频率)。
c
static int devfreq_cooling_set_cur_state(struct thermal_cooling_device *cdev,
unsigned long state)
{
struct devfreq_cooling_device *dfc = cdev->devdata;
struct devfreq *df = dfc->devfreq;
struct device *dev = df->dev.parent;
unsigned long freq;
int perf_idx;
// 状态值检查,避免重复设置
if (state == dfc->cooling_state)
return 0;
dev_dbg(dev, "Setting cooling state %lu\n", state);
// 合法性检查,非法设置的state直接丢弃
if (state > dfc->max_state)
return -EINVAL;
// 读取绑定的 em_pd 标识,区分是否有 Energy Model
if (dfc->em_pd) {
// 有 Energy Model (EM)
// perf_idx = 性能索引 = 最高性能索引减去 cooling state
perf_idx = dfc->max_state - state;
// state = 0 → perf_idx = max_state(最高频率)
state = max_state → perf_idx = 0(最低频率)
freq = dfc->em_pd->table[perf_idx].frequency * 1000;
} else {
// 无 EM
freq = dfc->freq_table[state];
}
// 更新 PM QoS 限制:将计算出来的频率更新到 PM QoS,限制设备的 最大可用频率。
dev_pm_qos_update_request(&dfc->req_max_freq,
DIV_ROUND_UP(freq, HZ_PER_KHZ));
// 保存 cooling state
dfc->cooling_state = state;
return 0;
}总结:通过传入参数 thermal_cooling_device 表示的cooling device对象,获取对应的devfreq_cooling_device,其中包含状态、操作函数等,进一步将新的state 参数更新到 devfreq_cooling_device中,以便于在后续需要执行温控降温操作时,能有准确的状态判断。
devfreq_cooling_get_requested_power
devfreq_cooling_get_requested_power(struct thermal_cooling_device *cdev, u32 *power) 是 thermal_cooling_device_ops 的扩展接口,专门用于 带功耗建模 (Power Extensions) 的 cooling device,目的是向 IPA (Intelligent Power Allocation) governor 提供 当前功耗估计值。
- 作用:根据当前 devfreq 的运行状态(频率、利用率、电压等),计算设备的 实际功耗 (mW),并返回给 thermal 框架。
- 输入:cdev:冷却器对象。
- 输出:*power:估算的设备功耗(单位:mW)
c
static int devfreq_cooling_get_requested_power(struct thermal_cooling_device *cdev,
u32 *power)
{
struct devfreq_cooling_device *dfc = cdev->devdata;
struct devfreq *df = dfc->devfreq; // 从 thermal_cooling_device 获取 devfreq 对应的父设备
struct devfreq_dev_status status;
unsigned long state;
unsigned long freq; // 频率值
unsigned long voltage;
int res, perf_idx;
mutex_lock(&df->lock);
status = df->last_status; // 从 devfreq 设备中获取上一次记录的状态(devfreq_dev_status)
mutex_unlock(&df->lock);
freq = status.current_frequency; // freq → 当前频率(Hz)
// power_ops即devfreq_cooling_power,如果驱动提供了 get_real_power,则优先调用它获取功耗
if (dfc->power_ops && dfc->power_ops->get_real_power) {
voltage = get_voltage(df, freq); // 获取电压:get_voltage(df, freq)(根据频率查询 OPP 电压)
// 如果电压为 0,说明查询失败 → 返回 -EINVAL
if (voltage == 0) {
res = -EINVAL;
goto fail;
}
// 通过 get_real_power 函数获取真实功耗
res = dfc->power_ops->get_real_power(df, power, freq, voltage);
if (!res) {
// 获取状态
state = dfc->max_state - dfc->capped_state;
/* Convert EM power into milli-Watts first */
/* EM 表里的功耗是 microwatt,需要转成 mW */
dfc->res_util = dfc->em_pd->table[state].power;
dfc->res_util /= MICROWATT_PER_MILLIWATT;
/* 乘一个修正因子 */
dfc->res_util *= SCALE_ERROR_MITIGATION;
/* 如果 power 有效,进一步归一化 */
if (*power > 1)
dfc->res_util /= *power;
} else {
goto fail;
}
} else {
/* Energy Model frequencies are in kHz */
// 根据当前频率 freq 找到 EM 表中的索引。注意 EM 的频率是 kHz,所以要除以 1000
perf_idx = get_perf_idx(dfc->em_pd, freq / 1000);
if (perf_idx < 0) {
res = -EAGAIN;
goto fail;
}
_normalize_load(&status);
/* Convert EM power into milli-Watts first */
*power = dfc->em_pd->table[perf_idx].power;
*power /= MICROWATT_PER_MILLIWATT; // µW → mW
/* Scale power for utilization */
*power *= status.busy_time; // 按实际忙时比例缩放
*power >>= 10; // 除以 1024(近似除以 total_time)
}
trace_thermal_power_devfreq_get_power(cdev, &status, freq, *power);
return 0;
fail:
/* It is safe to set max in this case */
dfc->res_util = SCALE_ERROR_MITIGATION; // 如果失败,res_util 设置成默认值,避免系统崩溃
return res;
}【流程总结】
-
获取 devfreq 的 last_status(频率、利用率)。
-
如果驱动支持 get_real_power:
① 查电压。
② 调用驱动提供的计算函数。
③ 基于 EM 表计算 res_util。
-
否则:
① 根据频率找到 EM 表索引。
② 用利用率缩放 EM 表里的功耗值。
-
返回计算结果给 *power(单位 mW)。
-
出错时返回负值,并设置默认 res_util。
state2power / power2state
(1)devfreq_cooling_state2power
把 cooling state 映射为对应的能量模型(EM)功耗值(返回给调用者的单位是 mW)。简单理解,用 cooling state 进行按模型计算查表,找到对应的功耗后换算一下单位,大家都认可后,把数据用指针送回去。
c
static int devfreq_cooling_state2power(struct thermal_cooling_device *cdev,
unsigned long state, u32 *power)
{
struct devfreq_cooling_device *dfc = cdev->devdata;
int perf_idx;
// 判断 state 是否是合法范围内的值
if (state > dfc->max_state)
return -EINVAL; // 若 state 超出范围返回 -EINVAL
// 计算索引
perf_idx = dfc->max_state - state;
// EM 表(em_pd->table)按 功耗/频率从低到高(ascending) 排序,table[0] 是最低功耗,而 table[max_state] 是最高功耗。
*power = dfc->em_pd->table[perf_idx].power;
// 原单位是 µW(微瓦),函数通过除以 MICROWATT_PER_MILLIWATT 把它转换为 mW(通常 MICROWATT_PER_MILLIWATT == 1000)
*power /= MICROWATT_PER_MILLIWATT;
return 0; // 返回值:0 表示成功
}(2)devfreq_cooling_power2state
将一个 功率预算 power(单位 mW) 转换为对应的 cooling state,也就是找出在该功率预算下应将设备限制到哪个状态(从而通过 state→freq→PM-QoS 限制频率)。
c
static int devfreq_cooling_power2state(struct thermal_cooling_device *cdev,
u32 power, unsigned long *state)
{
struct devfreq_cooling_device *dfc = cdev->devdata;
struct devfreq *df = dfc->devfreq; // 从 thermal_cooling_device 获取 devfreq 对应的父设备
struct devfreq_dev_status status;
unsigned long freq, em_power_mw;
s32 est_power;
int i;
mutex_lock(&df->lock);
status = df->last_status; // 从 devfreq 设备中获取上一次记录的状态(devfreq_dev_status)
mutex_unlock(&df->lock);
freq = status.current_frequency; // freq → 当前频率(Hz)
// power_ops即devfreq_cooling_power,如果驱动提供了 get_real_power,则优先调用它获取功耗
if (dfc->power_ops && dfc->power_ops->get_real_power) {
/* Scale for resource utilization */
// dfc->res_util 在 devfreq_cooling_get_requested_power 从获取后存放在 dfc->res_util 。
// 用来把驱动/测量得到的"真实功耗"与 EM 表的功耗尺度对齐,前面乘SCALE_ERROR_MITIGATION,后面就需要除
est_power = power * dfc->res_util;
est_power /= SCALE_ERROR_MITIGATION;
} else {
/* Scale dynamic power for utilization */
// 把 status.busy_time、total_time 归一化(实现通常把 busy_time 缩放到 0~1024)。
_normalize_load(&status);
// 将 当前利用率影响 反算到"满载(EM 表)功耗"上。
est_power = power << 10; // 移位操作
est_power /= status.busy_time;
// 注:get_requested_power 在无 get_real_power 时是: power = EM_power * busy_time / 1024,此处遂将 power 反算回 EM_power
}
/*
* Find the first cooling state that is within the power
* budget. The EM power table is sorted ascending.
*/
// EM 表按功耗升序排列,从小到大
// 循环 i = max_state .. 1(注意 i>0,若循环落到 i==0 则外层计算会把 state 设置为 max_state)
for (i = dfc->max_state; i > 0; i--) {
/* Convert EM power to milli-Watts to make safe comparison */
// 把 em_pd->table[i].power(µW)转换为 mW,再与 est_power 进行比较
em_power_mw = dfc->em_pd->table[i].power;
em_power_mw /= MICROWATT_PER_MILLIWATT;
// est_power >= em_power_mw,说明在 i 对应的 perf(频率/功耗)下可以满足预算;跳出循环。
if (est_power >= em_power_mw)
break;
}
// 将 perf 索引转换回 cooling state
// 逻辑与 state2power 对称:i = max_state → state = 0(无降频),i = 0 → state = max_state(最高降频)
*state = dfc->max_state - i;
// 保存 state 值,整个方法就为了这个玩意。
dfc->capped_state = *state;
trace_thermal_power_devfreq_limit(cdev, freq, *state, power);
return 0;
}【关键点】
- 单位与缩放
① power 参数与函数内部所有比较/返回的 power 均以 mW 为单位。
② EM 表内 em_pd->table\[\].power 是 µW:必须除以 MICROWATT_PER_MILLIWATT(通常 1000)转换为 mW 才可比较。
③ busy_time 在被 _normalize_load() 标准化后,通常用 10-bit 固定点(0...1024) 来表示利用率,所以乘/除 1024(<< 10 / >> 10)作为缩放因子。 - res_util 的角色
当驱动能返回真实功耗(get_real_power)时,get_requested_power() 内部会计算并保存 dfc->res_util,其计算逻辑大致为 "res_util = (EM_power_for_some_state_in_mW * SCALE_ERROR_MITIGATION) / measured_power_mW"。
于是在 power2state() 中做 est_power = power * res_util / SCALE_ERROR_MITIGATION 时,估计值大致回到 EM_power 的尺度,从而与 EM 表直接比较。 - 边界/异常
① i 循环终止条件使用 i > 0:如果 est_power 小于 em_pd->table1 的功耗,则循环结束时 i == 0,得到 state = max_state(最高降频)------这是安全的降频退化策略。
② busy_time == 0 的风险:在没有 get_real_power 的分支,如果 status.busy_time 为 0,会导致除 0。实务中 _normalize_load() 应确保 status.busy_time 非 0(或在实现里用保护),否则会出现异常。代码没有在此函数显式检查 busy_time == 0,依赖 _normalize_load() 的正确实现。 - 复杂度
主循环按 EM 表长度运行:时间复杂度 O(num_opps)。通常 num_opps 较小(几十、百位以内),可接受。
(3)要点回顾
- state2power:直接把 state 转换为 EM 表中对应的满载功耗(mW)。适用于需要知道某个状态对应的最大功耗。
- power2state:把预算功率映射到合适的 state,考虑当前利用率或用驱动返回的真实功耗进行尺度对齐,最终通过查 EM 表找到合适档位。
- 两函数相互对称、并依赖于 EM 表的升序性质与 max_state - state 的映射规则。
- 注意单位(µW ↔ mW)、busy_time 的缩放(1024)与 res_util 的意义,以及潜在的并发/除零边界。
举例(帮助理解映射)

1.2.3 辅助函数说明
devfreq_cooling_gen_tables
devfreq_cooling_gen_tables 在没有 Energy Model (EM) 的情况下,从设备的 OPP(Operating Performance Points)列表生成一个"按频率降序"的表 dfc->freq_table\[\],表的索引与 cooling state 一一对应(state==0 对应最高频率)。of_devfreq_cooling_register_power 中直接引用这函数。
参数说明:
- dfc:要填充 freq_table 的 devfreq-cooling 结构体
- num_opps:期望的 OPP 数量(通常来自 dev_pm_opp_get_opp_count())
c
/**
- devfreq_cooling_gen_tables() - Generate frequency table.
- @dfc: Pointer to devfreq cooling device.
- @num_opps: Number of OPPs
- - Generate frequency table which holds the frequencies in descending
- order. That way its indexed by cooling device state. This is for
- compatibility with drivers which do not register Energy Model.
- - Return: 0 on success, negative error code on failure.
*/
static int devfreq_cooling_gen_tables(struct devfreq_cooling_device *dfc,
int num_opps)
{
// 获取关联的 devfreq 和 struct device *(用于 OPP 查询)
struct devfreq *df = dfc->devfreq;
struct device *dev = df->dev.parent;
unsigned long freq; // freq 用作搜索上限并被 dev_pm_opp_find_freq_floor() 更新
int i;
// 分配内存空间,为频率表分配 num_opps 个 unsigned long。使用 kcalloc 保证零初始化。
dfc->freq_table = kcalloc(num_opps, sizeof(*dfc->freq_table),
GFP_KERNEL);
if (!dfc->freq_table)
return -ENOMEM;
// 循环体:i 角标增加遍历; freq 初始值ULONG_MAX,循环自减
for (i = 0, freq = ULONG_MAX; i < num_opps; i++, freq--) {
struct dev_pm_opp *opp;
// step1:第一次调用 dev_pm_opp_find_freq_floor(dev, &freq) 会找到 <= ULONG_MAX 的最大 OPP
// 即设备上 最大频率 的 OPP,并把 freq 修改为这个 OPP 的频率值。
// step2:循环体末尾的 freq-- 将 freq 减 1(变成 max-freq-值 减 1)。
// 用于下一次调用,使 dev_pm_opp_find_freq_floor 在下一次返回 比上一次更低 的 OPP,得到下降过程,不断抄底
opp = dev_pm_opp_find_freq_floor(dev, &freq);
// step3:dev_pm_opp_find_freq_floor 返回错误,比如 freq 没有了或者其他的
if (IS_ERR(opp)) {
// 释放已分配的 freq_table 并返回错误码
kfree(dfc->freq_table);
return PTR_ERR(opp);
}
// dev_pm_opp_put(opp) 释放 OPP 引用
dev_pm_opp_put(opp);
// 将每次返回的 freq 写入 dfc->freq_table[i]。因此表中第 i 项是第 i 高的频率(降序)
dfc->freq_table[i] = freq;
}
return 0;
}总结(要点)
-
输出表的顺序:dfc->freq_table0 = 最高频率,dfc->freq_tablenum_opps-1 = 最低频率(降序)。 这样就能把 cooling state 直接作为索引:state == 0 → freq_table0(最高频率),state == max_state → 最低频率。------ 一句话,通过state与dfc->freq_table顺序相反,更好用
-
依赖:dev_pm_opp_find_freq_floor() 的语义 ------ 它通过指针参数返回找到的 OPP 频率并更新该指针,这个函数利用该特性来"逐步向下"遍历 OPP。
-
单位:dev_pm_opp / OPP 接口中频率单位依内核版本而定(常见为 kHz)。这个函数只是把 dev_pm_opp_find_freq_floor 返回的 freq 原样写入 freq_table,上层使用该表时(如 set_cur_state)会依据项目代码中其他的常量(例如 HZ_PER_KHZ)做相应的单元转换。重要的是:表内值与 dev_pm_opp_find_freq_floor 的返回单位保持一致,上游使用时要保持一致性。
示例(帮助理解)
假设设备的 OPP(按频率升序)为: 1000, 1500, 2000 (单位假设为 kHz)
num_opps = 3
循环行为示例:
- i=0: freq = ULONG_MAX → dev_pm_opp_find_freq_floor 返回 freq = 2000 →freq_table0 = 2000 → freq-- => 1999
- i=1: freq = 1999 → dev_pm_opp_find_freq_floor 返回 freq = 1500 → freq_table1 = 1500 → freq-- => 1499
- i=2: freq = 1499 → dev_pm_opp_find_freq_floor returns freq = 1000 → freq_table2 = 1000 → loop ends
结果表(降序):
c
freq_table[0] = 2000 // highest -> maps to state 0
freq_table[1] = 1500 // state 1
freq_table[2] = 1000 // state 2 (max_state)边界情况 / 风险点 / 注意事项
-
num_opps 必须合理
如果传入的 num_opps 大于设备实际 OPP 数,某次 dev_pm_opp_find_freq_floor 会失败,函数会回退并返回错误。调用方应确保 num_opps 是正确的(通常使用 dev_pm_opp_get_opp_count())。 -
freq 的减 1 (freq--)
① freq-- 是在 for 循环的迭代表达式里执行的(即在 loop body 完成后),目的是将下次搜索上限减 1,确保 dev_pm_opp_find_freq_floor 不会再次返回同一个 OPP(避免无限循环)。最后一次迭代后 freq-- 也会执行,但循环结束,不会被再用到 ------ 这一般是安全的。
② 如果某个 OPP 的频率为 0(极不可能),freq-- 可能 underflow,但下次不会用到它(或下一次 dev_pm_opp_find_freq_floor 会报错),总体上内核 OPP 频率不会是 0,所以不是实际问题。
-
并发与生命周期
① 该函数通常在驱动注册/初始化期间调用(single-threaded 初始化路径),因此对 OPP 列表的并发修改风险较小。若在运行时 OPP 列表被修改(动态改变 OPP),表可能过时,但这在内核中通常由上层保证生命周期顺序(在卸载/修改 OPP 之前应先注销 cooling device)。
② 读 dfc->freq_table(例如 set_cur_state)时没有额外锁保护,但因为表一般在初始化完成后才会被并发读取,这被视为安全模式。
-
单元/一致性问题
上游使用 dfc->freq_table 时(比如 set_cur_state),要清楚 freq_table 的单位并作相应转换(该源码上下文中已经有统一的转换逻辑)。不要误把表中值当作 Hz / kHz / MHz。
_normalize_load
这个函数是 devfreq_cooling 模块里用于归一化设备负载数据的关键步骤,保证计算功耗、估算状态时的数值稳定性。
先了解下面这结构体,同样也是函数参数。
c
/**
* struct devfreq_dev_status - Data given from devfreq user device to
* governors. Represents the performance
* statistics.
* @total_time: The total time represented by this instance of
* devfreq_dev_status
* @busy_time: The time that the device was working among the
* total_time.
* @current_frequency: The operating frequency.
* @private_data: An entry not specified by the devfreq framework.
* A device and a specific governor may have their
* own protocol with private_data. However, because
* this is governor-specific, a governor using this
* will be only compatible with devices aware of it.
*/
struct devfreq_dev_status {
/* both since the last measure */
unsigned long total_time;
unsigned long busy_time;
unsigned long current_frequency;
void *private_data;
};struct devfreq_dev_status 是 设备驱动和 devfreq governor 的通信结构体,主要携带 总时间、忙碌时间、当前频率 三个核心统计值,用于推算设备利用率和能耗。
成员变量介绍:
-
unsigned long total_time
含义:采样周期的总时间。
单位:并不是固定的,可以是 µs(微秒)、ns(纳秒)、时钟周期数,依赖具体设备驱动。
用途:作为基准,配合 busy_time 计算利用率。
-
unsigned long busy_time
含义:在 total_time 这一采样周期内,设备处于 工作状态(busy) 的时间
用途: utilization = busy_time / total_time 得到设备利用率。
-
unsigned long current_frequency
含义:设备当前正在运行的频率。
单位:Hz(通常是 KHz 或 MHz,取决于驱动)。
作用:governor 通过它和利用率一起推算功耗;thermal cooling device 通过它限制频率上限/下限。
-
void *private_data
含义:保留字段,不由 devfreq 框架定义,留给 设备驱动和 governor 协议使用。
特点:属于"私有通道",通用 governor 不会依赖它;如果 governor 使用了 private_data,那它只兼容那些设备驱动明确支持这个字段的场景。
接续函数 _normalize_load 分析,
c
static void _normalize_load(struct devfreq_dev_status *status)
{
// 如果 测量时间过大 (total_time > 1,048,575)
if (status->total_time > 0xfffff) {
// 把 total_time 和 busy_time 都右移 10 位(相当于除以 1024)
// 避免 busy_time << 10 时溢出。保持比例不变(两者一起缩小)。
status->total_time >>= 10;
status->busy_time >>= 10;
}
// busy_time <<= 10(左移 10 位) → 乘以 1024,准备做归一化。
status->busy_time <<= 10;
// 除以 status->total_time → 得到比例值,同时做除法条件判断。
status->busy_time /= status->total_time ? : 1;
// 如果计算结果是 0,就强制设为 1,避免后续计算出现完全没有利用率的情况
status->busy_time = status->busy_time ? : 1;
// 强制把总时间归一化为 1024,对应上面的 busy_time
status->total_time = 1024;
}
结果如下:
busy_time = 307
total_time = 1024
utilization = 307 / 1024 ≈ 0.3 (30%)
get_voltage
get_voltage(struct devfreq *df, unsigned long freq) 是在 devfreq cooling / power 计算 时用来获取某一频率下对应的电压值的。
参数说明:
devfreq *df :struct devfreq *,指向 devfreq 设备对象。
long freq:目标频率(Hz,可能是 kHz/MHz,取决于驱动)
c
static unsigned long get_voltage(struct devfreq *df, unsigned long freq)
{
// devfreq 本身挂在一个 device 下,这里拿到它的父设备 dev。
// 频率、电压 OPP 信息都存放在 dev 的 OPP table 里。
struct device *dev = df->dev.parent;
unsigned long voltage;
struct dev_pm_opp *opp;
// 在 OPP 表里查找 与 freq 精确匹配并启用的 OPP
opp = dev_pm_opp_find_freq_exact(dev, freq, true);
// 如果返回 -ERANGE,说明精确找不到启用的 OPP
if (PTR_ERR(opp) == -ERANGE)
// 查找 freq 对应的 未启用 OPP
// 兼容性设计:优先用启用的 OPP,如果没有,则 fallback 到未启用的
opp = dev_pm_opp_find_freq_exact(dev, freq, false);
// 如果仍然找不到 OPP,则打印错误日志,并返回 0(代表失败)
if (IS_ERR(opp)) {
// 打印错误
dev_err_ratelimited(dev, "Failed to find OPP for frequency %lu: %ld\n",
freq, PTR_ERR(opp));
return 0;
}
// step1: dev_pm_opp_get_voltage(opp) 返回电压,单位是 纳伏 (nV)
// step2: 除以 1000 转换为 毫伏 (mV),方便功耗计算
voltage = dev_pm_opp_get_voltage(opp) / 1000; /* mV */
// dev_pm_opp_put(opp):释放 OPP 引用
dev_pm_opp_put(opp);
// 如果电压为 0,说明 OPP 表里电压字段可能缺失或错误,再次打 error
if (voltage == 0) {
dev_err_ratelimited(dev,
"Failed to get voltage for frequency %lu\n",
freq);
}
return voltage;
}在 cooling/power 模块中,在 devfreq_cooling_get_requested_power() 里会调用 "voltage = get_voltage(df, freq)" ,要根据频率 f 找到对应电压 V,才能正确计算功耗。
总结一下get_voltage() 的功能就是:
- 在设备 OPP 表里找到指定频率 freq 的 OPP。
- 提取 OPP 对应的电压(nV → mV)。
- 返回给调用方,用于后续功耗计算。
get_perf_idx
get_perf_idx() 函数很短,但作用非常关键,它是 devfreq cooling 里 频率 → Energy Model (EM) 表索引 的映射函数。
c
/**
* get_perf_idx() - get the performance index corresponding to a frequency
* @em_pd: Pointer to device's Energy Model
* @freq: frequency in kHz
*
* Return: the performance index associated with the @freq, or
* -EINVAL if it wasn't found.
*/
static int get_perf_idx(struct em_perf_domain *em_pd, unsigned long freq)
{
int i;
for (i = 0; i < em_pd->nr_perf_states; i++) {
// 遍历 em_pd->table[],如果找到 frequency 精确匹配的 entry,则返回它的索引 i
if (em_pd->table[i].frequency == freq)
return i;
}
return -EINVAL;
}参数说明:
em_perf_domain *em_pd :指向设备的 Energy Model performance domain。内部包含一个 table\[\],记录每个性能状态(performance state)的:frequency (kHz)、power (µW)、其他功耗/能耗参数。
long freq:要查找的目标频率,单位 kHz。
作用总结
功能:根据指定的频率(kHz),查找设备 Energy Model 表中对应的性能状态索引。
为什么需要它:
em_pd->tableperf_idx.power → 该频率对应的功耗(µW)
em_pd->tableperf_idx.frequency → 确认降频目标
perf_idx 还用于 state ↔ power 转换
1.2.4 pm_qos/pm_opp 关联
PM QoS 相关 API
| 函数名 | 原型(简化) | 作用 |
|---|---|---|
dev_pm_qos_add_request |
int dev_pm_qos_add_request(struct device *dev, struct dev_pm_qos_request *req, enum dev_pm_qos_req_type type, s32 value); |
为设备添加一个 PM QoS 请求,比如设置 最大频率/最小频率限制。 |
dev_pm_qos_remove_request |
void dev_pm_qos_remove_request(struct dev_pm_qos_request *req); |
移除之前添加的 QoS 请求,恢复默认。 |
dev_pm_qos_update_request |
int dev_pm_qos_update_request(struct dev_pm_qos_request *req, s32 new_value); |
更新现有 QoS 请求的值,例如动态调整设备的最大频率限制。 |
PM opp 相关 API
| 函数名 | 原型(简化) | 作用 |
|---|---|---|
dev_pm_opp_find_freq_exact |
struct dev_pm_opp *dev_pm_opp_find_freq_exact(struct device *dev, unsigned long freq, bool available); |
在设备的 OPP 表中查找 与指定频率完全匹配 的 OPP entry;available = true 表示只查找启用的 OPP。 |
dev_pm_opp_get_voltage |
unsigned long dev_pm_opp_get_voltage(struct dev_pm_opp *opp); |
获取 OPP 中定义的电压值(单位:纳伏 nV)。 |
dev_pm_opp_put |
void dev_pm_opp_put(struct dev_pm_opp *opp); |
释放 OPP entry 的引用计数,避免内存泄漏。 |
dev_pm_opp_find_freq_floor |
struct dev_pm_opp *dev_pm_opp_find_freq_floor(struct device *dev, unsigned long *freq); |
查找 OPP 表中 不大于给定频率 的最大 OPP(即向下取整)。 |
dev_pm_opp_get_opp_count |
int dev_pm_opp_get_opp_count(struct device *dev); |
获取设备的 OPP 数量(可用的 performance states 个数)。 |
dev_pm_opp_of_register_em |
int dev_pm_opp_of_register_em(struct device *dev, struct em_data_callback *cb); |
根据设备的 OPP 表,自动注册 Energy Model (EM),供 thermal / EAS / IPA 等子系统使用。 |
总体关系
- OPP (Operating Performance Points):负责管理 频率 ↔ 电压 ↔ 功耗 映射。
- EM (Energy Model):基于 OPP 自动生成,用于计算功耗和做性能约束。
- PM QoS (Power Management QoS):用于对设备施加 运行时约束(如最大频率),thermal cooling 正是通过它来限制 devfreq 设备的性能状态
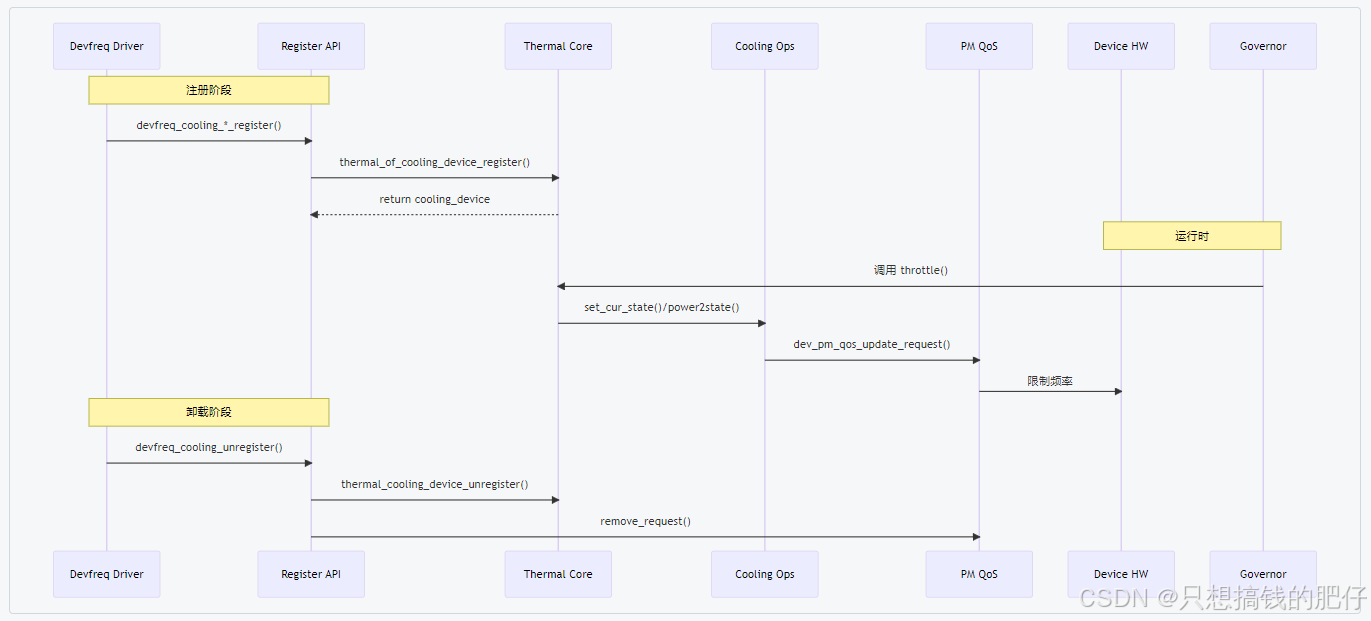
1.3 执行时序图
2 cpuidle_cooling
cpuidle_cooling 通过 idle-injection 机制(idle_inject 子系统)人为插入/延长 CPU idle 周期,从而降低 CPU 的平均利用与功耗。cooling state 采用 百分比(0...100) 来表示"注入比"------100 表示 100% idle(一直 idle),0 表示不注入。实现上把 idle duration 与 running duration 成比例计算。
cpuidle 驱动在初始化 / 注册时会调用 cpuidle_cooling_register(struct cpuidle_driver *drv),函数会遍历 drv->cpumask 中的 CPU,查看每个 CPU 的 device tree 下是否有 thermal-idle 子结点,找到则为该 CPU 创建一个 idle 注入 cooling device 并注册到 thermal 子系统。也就是说:只有当平台/DT 提供 thermal-idle 节点并且内核配置支持 idle_inject 时,才会实际启用该 cooling device。
在"Android thermal (4)_cooling device(上)" 最后的设备截图可以看到,cooling device的type没有cpuidle类型。RK的设备树没有配置该类型。
2.1 执行过程
- 初始化 cpuidle 驱动时 → 调用 cpuidle_cooling_register(drv)
- 遍历 CPU → 如果 DT 中有 thermal-idle 节点 → 调用 __cpuidle_cooling_register()
- 在 __cpuidle_cooling_register() 中:
(1)创建 cooling device
(2)绑定到 thermal 框架
(3)保存 idle_inject 配置 - 当温度超过 thermal zone 的 trip point 时,thermal governor 调用 set_cur_state() → 启动/调整 idle 注入线程
- idle 注入降低 CPU 的平均活动时间 → 降低功耗和发热
- 当温度下降,thermal governor 将 state 调回 0 → 停止 idle 注入
2.2 关键函数
2.2.1 关键前提
(1)cpuidle_cooling_device
c
/**
* struct cpuidle_cooling_device - data for the idle cooling device
* @ii_dev: an atomic to keep track of the last task exiting the idle cycle
* @state: a normalized integer giving the state of the cooling device
*/
struct cpuidle_cooling_device {
struct idle_inject_device *ii_dev; // ilde_inject对象存储,保存最后一次传入的 ilde_inject指针
unsigned long state; // 状态值
};(2)cpuidle_cooling_ops
cpuidle_cooling_ops 是一个静态 struct thermal_cooling_device_ops,包含三个函数指针,
这个 ops 指针在注册 cooling device 时传给了 thermal 子系统(通过thermal_of_cooling_device_register()注册)。
c
/**
* cpuidle_cooling_ops - thermal cooling device ops
*/
static struct thermal_cooling_device_ops cpuidle_cooling_ops = {
.get_max_state = cpuidle_cooling_get_max_state,
.get_cur_state = cpuidle_cooling_get_cur_state,
.set_cur_state = cpuidle_cooling_set_cur_state,
};(3)idle_inject 子系统
idle_inject_* 系列函数来自 idle_inject 子系统:
- idle_inject_register()
- idle_inject_set_duration()
- idle_inject_set_latency()
- idle_inject_start()
- idle_inject_stop()
- idle_inject_get_duration()
(4)thermal_of_cooling_device_register
通过therma core 的 thermal_of_cooling_device_register(np, name, idle_cdev, &cpuidle_cooling_ops):把 idle_cdev(devdata)和 cpuidle_cooling_ops 交给 thermal core 注册,thermal core 把这个 cooling device 暴露到 /sys/class/thermal 并处理与 thermal-zone 的绑定(具体 thermal-core 内部会保存 ops & devdata)。
2.2.2 入口:cpuidle_cooling_register
cpuidle_cooling_register(struct cpuidle_driver *drv) 是注册函数入口,需要开启 config 配置才有可以调用。
c
#ifdef CONFIG_CPU_IDLE_THERMAL
void cpuidle_cooling_register(struct cpuidle_driver *drv);
#else /* CONFIG_CPU_IDLE_THERMAL */
static inline void cpuidle_cooling_register(struct cpuidle_driver *drv)
{
}
#endif /* CONFIG_CPU_IDLE_THERMAL */调用时机 :通常由 cpuidle 驱动在初始化 / 注册 struct cpuidle_driver 时调用(在 cpuidle 子系统或 platform probe 中)。
目的:为 drv->cpumask 中的每颗 CPU(或每个 cluster)查找 device tree 中 thermal-idle 节点,如果存在就为该 CPU 创建并注册一个 idle-injection 基的 cooling device。
c
/**
* cpuidle_cooling_register - Idle cooling device initialization function
* @drv: a cpuidle driver structure pointer
*
* This function is in charge of creating a cooling device per cpuidle
* driver and register it to the thermal framework.
*/
void cpuidle_cooling_register(struct cpuidle_driver *drv)
{
struct device_node *cooling_node;
struct device_node *cpu_node;
int cpu, ret;
// 遍历 cpumask 的 CPU。
for_each_cpu(cpu, drv->cpumask) {
// 取得该 CPU 对应的 device tree node。
cpu_node = of_cpu_device_node_get(cpu);
// 在 CPU 的 DT 节点下查找 thermal-idle 子节点。
cooling_node = of_get_child_by_name(cpu_node, "thermal-idle");
of_node_put(cpu_node); // 释放 cpu_node 引用
if (!cooling_node) {
pr_debug("'thermal-idle' node not found for cpu%d\n", cpu);
continue;
}
// 为找到的 cooling_node 调用辅助注册函数
ret = __cpuidle_cooling_register(cooling_node, drv);
of_node_put(cooling_node); // 释放 cooling_node 引用
if (ret) {
pr_err("Failed to register the cpuidle cooling device" \
"for cpu%d: %d\n", cpu, ret);
break; // 若 __cpuidle_cooling_register 返回错误,打印错误并退出循环/返回
}
}
}2.2.3 核心注册:__cpuidle_cooling_register
__cpuidle_cooling_register 为 DT 节点 np 上描述的 cpu/cluster 创建 idle_inject 设备、准备 cpuidle_cooling_device 私有数据并通过 thermal_of_cooling_device_register() 注册到 thermal core。
c
/**
* __cpuidle_cooling_register: register the cooling device
* @drv: a cpuidle driver structure pointer
* @np: a device node structure pointer used for the thermal binding
*
* This function is in charge of allocating the cpuidle cooling device
* structure, the idle injection, initialize them and register the
* cooling device to the thermal framework.
*
* Return: zero on success, a negative value returned by one of the
* underlying subsystem in case of error
*/
static int __cpuidle_cooling_register(struct device_node *np,
struct cpuidle_driver *drv)
{
struct idle_inject_device *ii_dev;
struct cpuidle_cooling_device *idle_cdev;
struct thermal_cooling_device *cdev;
struct device *dev;
unsigned int idle_duration_us = TICK_USEC;
unsigned int latency_us = UINT_MAX;
char *name;
int ret;
idle_cdev = kzalloc(sizeof(*idle_cdev), GFP_KERNEL); // 分配 struct cpuidle_cooling_device。
if (!idle_cdev) {
ret = -ENOMEM; // 若失败 ret = -ENOMEM → goto out(返回错误)。
goto out;
}
// 注册一个 idle_inject_device,它会创建注入 idle 的基础设施 idle_inject_device 对象。
ii_dev = idle_inject_register(drv->cpumask);
if (!ii_dev) {
ret = -EINVAL; // 若返回 NULL:ret = -EINVAL → goto out_kfree(释放 idle_cdev 并返回)
goto out_kfree;
}
// 从 DT 读取可选属性,若不存在使用默认(TICK_USEC、UINT_MAX)
of_property_read_u32(np, "duration-us", &idle_duration_us);
of_property_read_u32(np, "exit-latency-us", &latency_us);
// 设置 idle 注入的时长与退出延迟(config)
idle_inject_set_duration(ii_dev, TICK_USEC, idle_duration_us);
idle_inject_set_latency(ii_dev, latency_us);
// 把 ii_dev 保存到 cpuidle_cooling_device 的 idle_cdev 的字段里。
// 后续可以通过 idle_cdev->ii_dev 直接获取
idle_cdev->ii_dev = ii_dev;
// 构造一个易识别的 cooling device 名字(例如:idle-cpu0)
dev = get_cpu_device(cpumask_first(drv->cpumask));
name = kasprintf(GFP_KERNEL, "idle-%s", dev_name(dev));
if (!name) {
ret = -ENOMEM;
goto out_unregister; // 分配失败时回退到 out_unregister(会注销 ii_dev 并释放 idle_cdev)
}
// 关键步骤:把 idle_cdev(作为 devdata)和 &cpuidle_cooling_ops(ops 表)交给 thermal core 去注册。
// thermal zone 绑定的 cooling device 可以轻松找到是什么cpuidle_cooling_device
cdev = thermal_of_cooling_device_register(np, name, idle_cdev,
&cpuidle_cooling_ops);
if (IS_ERR(cdev)) {
ret = PTR_ERR(cdev);
goto out_kfree_name; // 获取错误码并走 out_kfree_name -> out_unregister -> out_kfree 回退
}
pr_debug("%s: Idle injection set with idle duration=%u, latency=%u\n",
name, idle_duration_us, latency_us);
kfree(name); // 释放 name
return 0;
out_kfree_name:
kfree(name); // 释放 name
out_unregister:
idle_inject_unregister(ii_dev); // 注销 ii_dev
out_kfree:
kfree(idle_cdev); // kfree idle_cdev
out:
return ret;
}当 thermal_of_cooling_device_register 注册成功,会创建 struct thermal_cooling_device,把 ops 指针、devdata 指针、名字等保存起来;在 sysfs 创建 cooling_deviceX、policy 等节点。
如果 DT 节点 np 中含有绑定信息(比如直接在 thermal zone 的 DT 下),thermal core 可能会立即把此 cooling device 与某个 thermal-zone 绑定(创建 struct thermal_instance)------从而当该 zone 触发被动降温时,thermal core 能直接调用此 cooling device 的 ops。
2.2.4 运行时:cpuidle_cooling_set_cur_state
当 thermal core 决定改变此 cooling device 的状态(例如 governor 要限制负载通过注入 idle),它会调用 set_cur_state()(通过 core)。
从 cpuidle_cooling_ops 中看得到 set_cur_state = cpuidle_cooling_set_cur_state。用户空间通过 sysfs 读取 / 写 cooling_deviceX/cur_state 时(core 会调用 get_cur_state / set_cur_state),由 thermal core(在 governor 或 userspace 请求时)通过 thermal_cooling_device->ops->set_cur_state() 间接调用。
c
/**
* cpuidle_cooling_set_cur_state - Set the current cooling state
* @cdev: the thermal cooling device
* @state: the target state
*
* The function checks first if we are initiating the mitigation which
* in turn wakes up all the idle injection tasks belonging to the idle
* cooling device. In any case, it updates the internal state for the
* cooling device.
*
* Return: The function can not fail, it is always zero
*/
static int cpuidle_cooling_set_cur_state(struct thermal_cooling_device *cdev,
unsigned long state)
{
// 取得私有结构,由注册时传入。 注册函数的参数。
struct cpuidle_cooling_device *idle_cdev = cdev->devdata;
// 取得 idle_inject_device。 cpuidle_cooling_device的成员
struct idle_inject_device *ii_dev = idle_cdev->ii_dev;
// 当前的状态值,cpuidle_cooling_device的成员
unsigned long current_state = idle_cdev->state;
unsigned int runtime_us, idle_duration_us;
// 先更新状态(原子性/同步由 core 的锁或调用位置保证)。传入的状态新参数。
idle_cdev->state = state;
// 读取当前 idle_inject 的配置(injection duration、idle_duration)。
idle_inject_get_duration(ii_dev, &runtime_us, &idle_duration_us);
// 计算"运行时长"(active time)对应于新的注入比(state 是 0..100 百分比)
runtime_us = cpuidle_cooling_runtime(idle_duration_us, state);
// 把新 runtime 与 idle duration 设置到 idle_inject 设备中;idle_inject 内部会据此调整注入比
idle_inject_set_duration(ii_dev, runtime_us, idle_duration_us);
// current_state -> 当前状态,可以理解为正在进行时;state -> 传入的状态,理解为即将发生的变化
if (current_state == 0 && state > 0) {
idle_inject_start(ii_dev); // 从未注入到开始注入:需要启动注入线程 /唤醒注入机制
} else if (current_state > 0 && !state) {
idle_inject_stop(ii_dev); // 从注入到停止:停止注入线程
}
// set_cur_state 几乎不会失败,文件内实现总是返回 0
return 0;
}
/**
* cpuidle_cooling_runtime - Running time computation
* @idle_duration_us: CPU idle time to inject in microseconds
* @state: a percentile based number
* * The running duration is computed from the idle injection duration
* which is fixed. If we reach 100% of idle injection ratio, that
* means the running duration is zero. If we have a 50% ratio
* injection, that means we have equal duration for idle and for
* running duration.
* * The formula is deduced as follows:
* * running = idle x ((100 / ratio) - 1)
* * For precision purpose for integer math, we use the following:
* * running = (idle x 100) / ratio - idle
* * For example, if we have an injected duration of 50%, then we end up
* with 10ms of idle injection and 10ms of running duration.
* * Return: An unsigned int for a usec based runtime duration.
*/
static unsigned int cpuidle_cooling_runtime(unsigned int idle_duration_us,
unsigned long state)
{
// 如果 state == 0 → runtime = 0
if (!state)
return 0;
return ((idle_duration_us * 100) / state) - idle_duration_us;
}cpuidle_cooling_runtime的参数说明:
- idle_duration_us:CPU 空闲持续时间,单位是微秒 (us)。
- state :cooling device 的当前状态(也就是冷却等级/档位)。在 thermal 框架里,state 往往表示降频或者降低性能的程度。
① state = 0 → 不做限制。
② state > 0 → 启用对应的限制。
用 idle 时间与 state 进行比例缩放,计算出一个新的 "运行时长"。

以此类推:
- state 越小 → runtime 越大
- state = 100 时 → runtime = 0
- state > 100 时 → runtime 可能变为负数(但这里返回 unsigned int,负数会变成大整数,不太合理,说明调用方一般不会传入 >100 的 state)
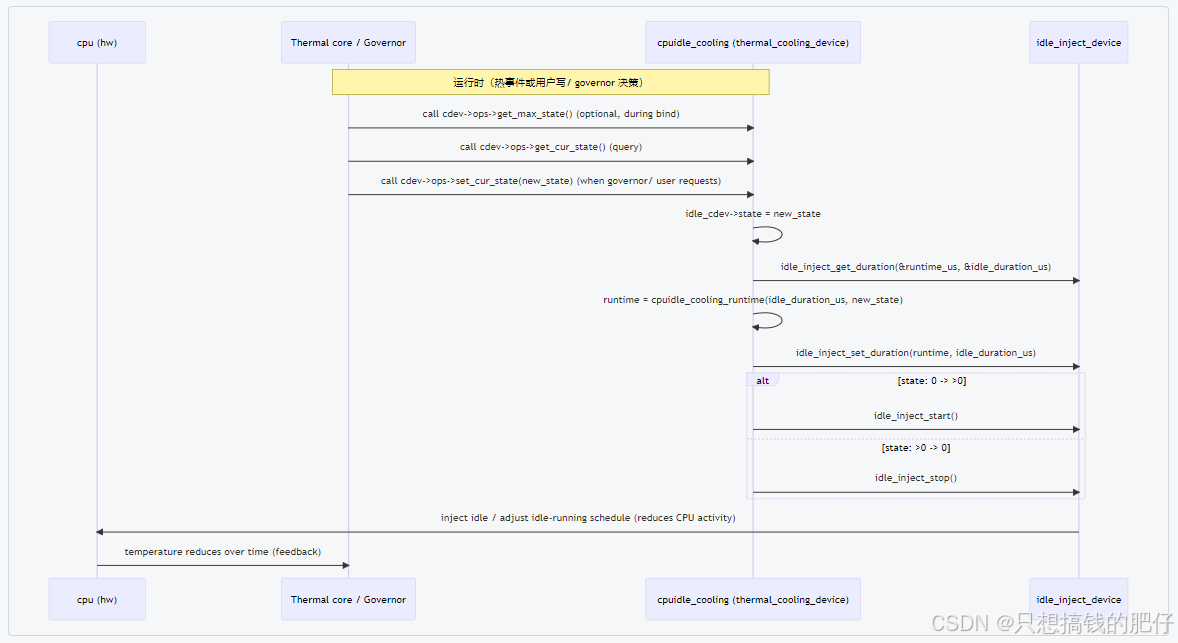
2.3 执行时序图
下图是上面cpuidle-cooling的执行过程。
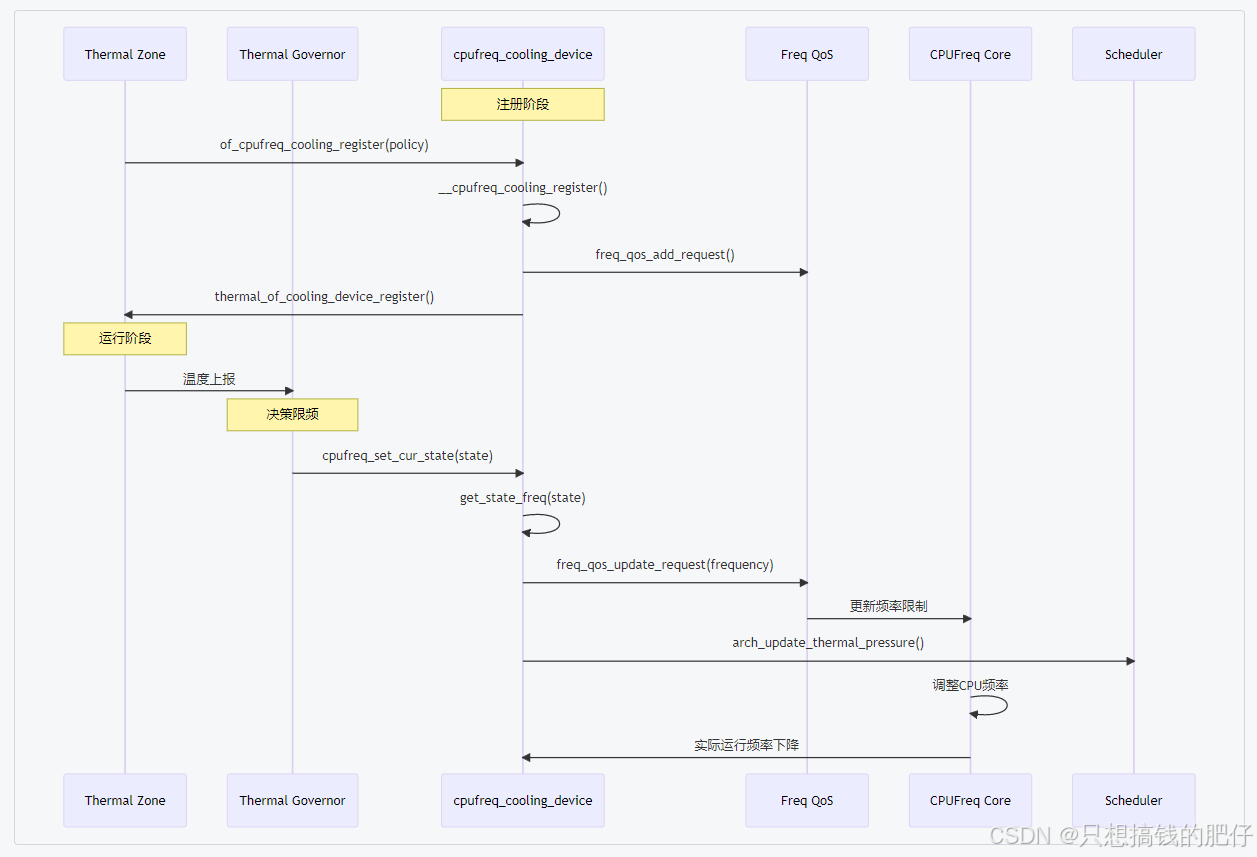
3 cpufreq_cooling
cpufreq_cooling 实现了把 thermal cooling state 与 CPUfreq 的频率/功耗映射起来的 glue 层:在注册时绑定 cpufreq policy(和可选 EM),提供 state→freq/power、power→state、当前请求功率估算等接口,并通过 PM QoS(freq_qos)动态施加频率上限约束以实现热管理策略。
3.1 数据结构
3.1.1 time_in_idle
用途:用于单核(CONFIG_SMP 未启用)情况下按时间差计算 CPU 利用率(见 get_load 非 SMP 分支)。
c
struct time_in_idle {
u64 time;
u64 timestamp;
};time:上一次读取到的该 CPU 的绝对空闲时间(单位依 platform,常是 microseconds 或者 jiffies / tick-count,取决于 get_cpu_idle_time() 实现)。
timestamp:上次调用 get_cpu_idle_time_us()(或相关 API)时的 wall time(通常由 get_cpu_idle_time() 返回的 now),用于计算两次采样间的时间差。
3.1.2 cpufreq_cooling_device
c
struct cpufreq_cooling_device {
u32 last_load;
unsigned int cpufreq_state;
unsigned int max_level;
struct em_perf_domain *em;
struct cpufreq_policy *policy;
struct thermal_cooling_device_ops cooling_ops;
#ifndef CONFIG_SMP
struct time_in_idle *idle_time;
#endif
struct freq_qos_request qos_req;
};成员变量:
- last_load:保存最近一次 cpufreq_get_requested_power() 调用时测得的负载(通常是百分比)。热管理里会根据这个负载估算功耗,决定是否需要进一步降频。
- cpufreq_state:表示 cooling device 当前所处的"冷却状态"(cooling state)。类型是 unsigned int,取值范围是 0, max_level。值越大,表示限制越强(CPU 频率被压到更低档位)。
- max_level :最大的冷却 level,与索引角标类取值似,直接当索引用了。注意 不是频率的数量,而是 (总频率数 - 1)。例如,如果这个 CPU 有 5 个可用频率档位,那么 max_level = 4。这样 cooling state 的合法范围就是 0~max_level。
- em:指向 energy model(能量模型)的 em_perf_domain,里面存放这个 CPU 性能域的性能/功耗表。thermal 框架会用 EM 数据来评估不同频率下的能耗。
- policy:对应的 cpufreq_policy,代表该 CPU 或 CPU cluster 的频率调节策略(最小、最大频率范围,governor 等)。
- cooling_ops:实现 thermal_cooling_device_ops 的一组函数指针。定义了 cooling device 与 thermal 框架交互时的回调,比如设置 state、获取 max state 等。
- idle_time:(仅在非 SMP 配置下才有)保存 CPU 的空闲时间信息。在热管理中,有时需要结合 idle stats 来更准确估算 CPU 活动功耗。
- qos_req:一个 freq_qos_request,用于向 PM QoS 框架提交频率上限约束。当 thermal 框架决定要"降频"时,会通过这个字段影响 cpufreq 的上限。
SMP(Symmetric Multi-Processing - 对称多处理)模式:
- 含义: 在一个系统中,所有 CPU 核心都是对等的(homogeneous)。它们共享同一个内存控制器、同一级缓存(通常是L3缓存),并连接到同一条系统总线上。在操作系统看来,所有核心在功能和性能上完全一致,任务可以被调度到任何一个核心上执行,而不会有效能差异。
- 例子: 传统的单颗多核处理器,如 Intel 或 AMD 的台式机/服务器 CPU(一个物理芯片上有多个相同的核心)。
非SMP / 异构模式(通常指 Arm big.LITTLE 或 DynamIQ):
- 含义: 系统中的 CPU 核心被分成了不同的簇(Cluster)。每个簇内部可能是 SMP 结构,但簇与簇之间的核心在架构、性能和功耗上存在显著差异。最常见的形态就是"大核"簇和"小核"簇。
- 例子: 现代智能手机处理器(如高通骁龙、联发科天玑系列)、苹果 M系列芯片。例如,一个处理器可能包含 2 个 Cortex-X系列(大核)和 6 个 Cortex-A55系列(小核)。
为什么 cpufreq_cooling 需要区分这两种模式?
cpufreq_cooling 是内核热管理(thermal)子系统的一个冷却设备(cooling device)。它的工作原理是:当设备温度过高时,通过限制 CPU 的频率 来减少其功耗和发热,从而达到降温的目的。
区分 SMP 和非SMP 模式的核心原因在于:如何公平、准确、高效地计算因降频而带来的"冷却效果"。
| 特性 | SMP 模式 | 非SMP/异构模式 |
|---|---|---|
| 硬件基础 | 所有CPU核心相同 | CPU核心分簇,不同簇性能功耗不同 |
| cpufreq_cooling 设备 | 通常一个全局设备 | 每个频率域(簇)一个冷却设备 |
| 负载计算 | 所有在线CPU的总负载 | 按簇分别计算负载 |
| 频率控制 | 全局统一频率 | 按簇独立控制频率 |
| 冷却效果计算 | 相对简单,基于总负载和频率差 | 复杂,需按簇计算并加权求和,考虑动态功率系数 |
| 内核中的代表 | 传统x86多核处理器 | Arm big.LITTLE, DynamIQ 处理器 |
3.2 关键函数
【注意】宏定义 CONFIG_THERMAL_GOV_POWER_ALLOCATOR 使用来控制 governor power allocator 开启/关闭的。当配置这个策略时,部分功能函数启用。对于非该策略时,采用默认的空返回调用。
3.2.1 register/unregister
(1)cpufreq_cooling_register
cpufreq_cooling 注册函数。
c
/**
* cpufreq_cooling_register - function to create cpufreq cooling device.
* @policy: cpufreq policy
*
* This interface function registers the cpufreq cooling device with the name
* "cpufreq-%s". This API can support multiple instances of cpufreq cooling
* devices.
*
* Return: a valid struct thermal_cooling_device pointer on success,
* on failure, it returns a corresponding ERR_PTR().
*/
struct thermal_cooling_device *
cpufreq_cooling_register(struct cpufreq_policy *policy)
{
return __cpufreq_cooling_register(NULL, policy, NULL); // 核心注册函数
}
EXPORT_SYMBOL_GPL(cpufreq_cooling_register);(2)of_cpufreq_cooling_register
of_cpufreq_cooling_register 是一个对外导出的 API(见最后的 EXPORT_SYMBOL_GPL)。根据设备树信息,把某个 CPU 的 cpufreq policy 注册成 thermal cooling device。
输入参数:struct cpufreq_policy *policy,即 CPU 频率策略(某个 CPU 或 CPU cluster 的频率范围)。
c
/**
* of_cpufreq_cooling_register - function to create cpufreq cooling device.
* @policy: cpufreq policy
*
* This interface function registers the cpufreq cooling device with the name
* "cpufreq-%s". This API can support multiple instances of cpufreq cooling
* devices. Using this API, the cpufreq cooling device will be linked to the
* device tree node provided.
*
* Using this function, the cooling device will implement the power
* extensions by using the Energy Model (if present). The cpus must have
* registered their OPPs using the OPP library.
*
* Return: a valid struct thermal_cooling_device pointer on success,
* and NULL on failure.
*/
struct thermal_cooling_device *
of_cpufreq_cooling_register(struct cpufreq_policy *policy)
{
// 获取 CPU 的设备树节点
// 根据 policy->cpu(一个 CPU 的逻辑编号)去设备树里找到对应的 CPU 节点。
struct device_node *np = of_get_cpu_node(policy->cpu, NULL);
struct thermal_cooling_device *cdev = NULL;
// 检查设备树节点是否存在
if (!np) {
pr_err("cpufreq_cooling: OF node not available for cpu%d\n",
policy->cpu);
// 如果 of_get_cpu_node() 没找到 CPU 节点,说明设备树没有这个 CPU 的描述,无法注册 cooling device。
return NULL;
}
// 判断设备树节点是否定义了 #cooling-cells 属性
// 若没有此属性,则跳过注册,直接返回 NULL。
if (of_property_present(np, "#cooling-cells")) {
// 获取这个 CPU 的 能量模型(EM perf_domain)。EM 提供 (frequency, power) 表,用于估算能耗。
struct em_perf_domain *em = em_cpu_get(policy->cpu);
// 调用内部函数 __cpufreq_cooling_register(),正式注册 cooling device
// np:CPU 的设备树节点;policy:CPU 的频率策略;em:能量模型。
cdev = __cpufreq_cooling_register(np, policy, em);
// 检查注册是否成功
if (IS_ERR(cdev)) {
pr_err("cpufreq_cooling: cpu%d failed to register as cooling device: %ld\n",
policy->cpu, PTR_ERR(cdev));
cdev = NULL;
}
}
// of_get_cpu_node() 会增加设备树节点的引用计数。
// 用完后必须调用 of_node_put() 释放,否则会内存泄漏。
of_node_put(np); // 释放 device_node 引用
return cdev;
}
EXPORT_SYMBOL_GPL(of_cpufreq_cooling_register);(3)cpufreq_cooling_unregister
cpufreq_cooling 卸载函数。把 CPU cooling device 从 thermal framework 中移除,并清理所有资源
c
/**
* cpufreq_cooling_unregister - function to remove cpufreq cooling device.
* @cdev: thermal cooling device pointer.
*
* This interface function unregisters the "cpufreq-%x" cooling device.
*/
void cpufreq_cooling_unregister(struct thermal_cooling_device *cdev)
{
struct cpufreq_cooling_device *cpufreq_cdev;
// thermal_cooling_device 为空,cooling device是没有的。
if (!cdev)
return;
// 从 cooling_device 中,获取cpufreq_cooling_device 对象。
cpufreq_cdev = cdev->devdata;
// cooling device取消注册。
thermal_cooling_device_unregister(cdev);
// 移除频率 QoS 请求。
freq_qos_remove_request(&cpufreq_cdev->qos_req);
// 释放空闲时间统计资源
free_idle_time(cpufreq_cdev);
// 释放 cpufreq_cooling_device 内存
kfree(cpufreq_cdev);
}
EXPORT_SYMBOL_GPL(cpufreq_cooling_unregister);注册时,系统在 thermal 框架里注册了一个 cooling device:cooling_deviceX。thermal governor 可以调用它来降低 CPU 频率。
注销时,从 thermal 框架注销:cooling_deviceX 消失。删除 CPU 频率限制(QoS request 移除)。释放统计数据和内存。
3.2.2 __cpufreq_cooling_register
__cpufreq_cooling_register() 是 CPUFreq Cooling Device 的注册核心流程,它完成了把一个 cpufreq_policy 包装成 thermal framework 能识别的 thermal_cooling_device。
输入参数:
np:设备树节点(thermal zone 绑定用)
policy:cpufreq 的策略对象(涵盖一个 cluster 的 CPU 频率策略)
em:能效模型(Energy Model),用来做频率 ↔ 功率映射
返回:
成功 → 注册完成的 thermal_cooling_device *
失败 → ERR_PTR(error_code)
c
/**
* __cpufreq_cooling_register - helper function to create cpufreq cooling device
* @np: a valid struct device_node to the cooling device tree node
* @policy: cpufreq policy
* Normally this should be same as cpufreq policy->related_cpus.
* @em: Energy Model of the cpufreq policy
*
* This interface function registers the cpufreq cooling device with the name
* "cpufreq-%s". This API can support multiple instances of cpufreq
* cooling devices. It also gives the opportunity to link the cooling device
* with a device tree node, in order to bind it via the thermal DT code.
*
* Return: a valid struct thermal_cooling_device pointer on success,
* on failure, it returns a corresponding ERR_PTR().
*/
static struct thermal_cooling_device *
__cpufreq_cooling_register(struct device_node *np,
struct cpufreq_policy *policy,
struct em_perf_domain *em)
{
struct thermal_cooling_device *cdev;
struct cpufreq_cooling_device *cpufreq_cdev;
unsigned int i;
struct device *dev;
int ret;
struct thermal_cooling_device_ops *cooling_ops;
char *name;
// 参数合法性检查:policy 必须有效,否则直接失败。
if (IS_ERR_OR_NULL(policy)) {
pr_err("%s: cpufreq policy isn't valid: %p\n", __func__, policy);
return ERR_PTR(-EINVAL);
}
// 获取 policy 主 CPU 的 struct device,失败返回错误。
dev = get_cpu_device(policy->cpu);
if (unlikely(!dev)) {
pr_warn("No cpu device for cpu %d\n", policy->cpu);
return ERR_PTR(-ENODEV);
}
// 统计 cpufreq 表里有效频率数,如果没有,就没法做 cooling。
i = cpufreq_table_count_valid_entries(policy);
if (!i) {
pr_debug("%s: CPUFreq table not found or has no valid entries\n",
__func__);
return ERR_PTR(-ENODEV);
}
// 分配 cpufreq_cooling_device 内存
cpufreq_cdev = kzalloc(sizeof(*cpufreq_cdev), GFP_KERNEL);
if (!cpufreq_cdev)
return ERR_PTR(-ENOMEM);
// 申请 cooling_device 的私有对象 cpufreq_cdev,并绑定 policy
cpufreq_cdev->policy = policy;
// 分配 idle_time 结构
// 为每个 CPU 分配 idle_time 数组(大小 = 这个 cluster 的 CPU 数
ret = allocate_idle_time(cpufreq_cdev);
if (ret) {
cdev = ERR_PTR(ret);
goto free_cdev;
}
/* max_level is an index, not a counter */
// 设置最大 state,max_level 不是频率数,而是最大索引。因此,最大 state 与索引相等。
cpufreq_cdev->max_level = i - 1;
// 绑定基础接口:查询 / 修改 cooling state
cooling_ops = &cpufreq_cdev->cooling_ops;
cooling_ops->get_max_state = cpufreq_get_max_state;
cooling_ops->get_cur_state = cpufreq_get_cur_state;
cooling_ops->set_cur_state = cpufreq_set_cur_state;
// power_allocator governor 可以根据功耗预算做精细控制,配置能效模型 (EM)
#ifdef CONFIG_THERMAL_GOV_POWER_ALLOCATOR
if (em_is_sane(cpufreq_cdev, em)) {
cpufreq_cdev->em = em;
cooling_ops->get_requested_power = cpufreq_get_requested_power;
cooling_ops->state2power = cpufreq_state2power;
cooling_ops->power2state = cpufreq_power2state;
} else
#endif
// 检查频率表是否排序
if (policy->freq_table_sorted == CPUFREQ_TABLE_UNSORTED) {
pr_err("%s: unsorted frequency tables are not supported\n",
__func__);
cdev = ERR_PTR(-EINVAL);
goto free_idle_time; // 无效表,直接清退
}
// 添加 Freq QoS 限制
// step1: 初始值 = state=0 → 最大频率
// step2: 更新这个 qos_req 来限频
ret = freq_qos_add_request(&policy->constraints,
&cpufreq_cdev->qos_req, FREQ_QOS_MAX,
get_state_freq(cpufreq_cdev, 0));
if (ret < 0) {
pr_err("%s: Failed to add freq constraint (%d)\n", __func__,
ret);
cdev = ERR_PTR(ret);
goto free_idle_time;
}
cdev = ERR_PTR(-ENOMEM);
// 生成 cooling device 名字,比如 "cpufreq-cpu0
name = kasprintf(GFP_KERNEL, "cpufreq-%s", dev_name(dev));
if (!name)
goto remove_qos_req;
// 向 thermal 框架注册,绑定 ops & 私有数据
cdev = thermal_of_cooling_device_register(np, name, cpufreq_cdev,
cooling_ops);
kfree(name);
if (IS_ERR(cdev))
goto remove_qos_req;
return cdev;
remove_qos_req:
freq_qos_remove_request(&cpufreq_cdev->qos_req); // 移除 QoS 请求
free_idle_time:
free_idle_time(cpufreq_cdev); // 释放 idle_time
free_cdev:
kfree(cpufreq_cdev); // 释放 cpufreq_cdev
return cdev;
}总结(核心流程)
- 检查 cpufreq_policy 是否有效
- 获取 CPU device,检查频率表
- 分配并初始化 cpufreq_cooling_device
- 分配 idle_time
- 设置 cooling_ops(基本 or power-aware)
- 添加 Freq QoS 请求
- 调用 thermal_of_cooling_device_register() 注册到 thermal 框架
- 如果失败,按顺序释放资源
3.2.3 cpufreq_set_cur_state
函数 cpufreq_set_cur_state() 和 get_state_freq() 是 CPUFreq cooling device 实际 执行限频动作 的关键代码。逐行解析一下:
(1)cpufreq_set_cur_state
输入:
- cdev → cooling device
- state → 目标 cooling state(0 = 不限频,越大代表限制越强)
返回:
- 0 成功
- <0 失败
c
/**
- cpufreq_set_cur_state - callback function to set the current cooling state.
- @cdev: thermal cooling device pointer.
- @state: set this variable to the current cooling state.
- - Callback for the thermal cooling device to change the cpufreq
- current cooling state.
- - Return: 0 on success, an error code otherwise.
*/
static int cpufreq_set_cur_state(struct thermal_cooling_device *cdev,
unsigned long state)
{
// 从 cooling device 拿到 cpufreq_cooling_device 私有数据
struct cpufreq_cooling_device *cpufreq_cdev = cdev->devdata;
struct cpumask *cpus;
unsigned int frequency;
int ret;
/* Request state should be less than max_level */
// state 必须合法 (0 <= state <= max_level)。max_level = 有效频率数 - 1。
if (state > cpufreq_cdev->max_level)
return -EINVAL;
/* Check if the old cooling action is same as new cooling action */
// 如果新 state 和旧 state 相同 → 无需更新,直接返回。
if (cpufreq_cdev->cpufreq_state == state)
return 0;
// 根据 state 映射出实际目标频率。
// 核心:state 是一个抽象的冷却级别,最终要转换成频率
frequency = get_state_freq(cpufreq_cdev, state);
// 更新 QoS 请求,把 CPU cluster 的 最大频率限制 改成目标值。
ret = freq_qos_update_request(&cpufreq_cdev->qos_req, frequency);
// 如果成功,cpufreq framework 会调节频率策略,使实际频率 ≤ frequency。
if (ret >= 0) {
cpufreq_cdev->cpufreq_state = state; // 更新 cooling device 内部记录的当前 state
cpus = cpufreq_cdev->policy->related_cpus;
arch_update_thermal_pressure(cpus, frequency); // 更新 thermal_pressure
ret = 0;
}
// 返回 0 表示成功
return ret;
}cpufreq_set_cur_state() 的功能是:
- 检查 state 是否有效
- 将 state 转换为频率 (get_state_freq())
- 通过 freq_qos_update_request() 更新最大频率限制
- 更新内部状态 & 通知调度器
(2)get_state_freq
输入:state → cooling state
输出:对应的频率(单位:kHz)
c
static unsigned int get_state_freq(struct cpufreq_cooling_device *cpufreq_cdev,
unsigned long state)
{
struct cpufreq_policy *policy;
unsigned long idx;
#ifdef CONFIG_THERMAL_GOV_POWER_ALLOCATOR
/* Use the Energy Model table if available */
// 如果启用了能效模型 (EM),优先用 EM 表
if (cpufreq_cdev->em) {
// 用 max_level - state 做索引
// state=0 → idx = max_level → 表示最高频率
// state=max_level → idx=0 → 表示最低频率
idx = cpufreq_cdev->max_level - state;
return cpufreq_cdev->em->table[idx].frequency;
}
#endif
/* Otherwise, fallback on the CPUFreq table */
// 如果没有 EM,就 fallback 到 cpufreq policy 的频率表
policy = cpufreq_cdev->policy;
// 如果频率表升序排列,用 max_level - state;否则直接用 state
if (policy->freq_table_sorted == CPUFREQ_TABLE_SORTED_ASCENDING)
idx = cpufreq_cdev->max_level - state;
else
idx = state;
// 返回对应频率
return policy->freq_table[idx].frequency;
}整体逻辑总结
- Cooling state ↔ 频率 的映射规则:
state = 0 → 不限频 → 最高频率
state = max_level → 最强冷却 → 最低频率 - cpufreq_set_cur_state() 用 freq_qos_update_request() 来实际限频
- get_state_freq() 负责把抽象的 state 翻译成实际频率
3.2.4 allocate_idle_time/free_idle_time
非 SMP模式下,为 cluster 中每个 CPU 记录 idle 时间,用于计算负载。在注册 / 注销 cooling device 时分配和释放。
c
static int allocate_idle_time(struct cpufreq_cooling_device *cpufreq_cdev)
{
unsigned int num_cpus = cpumask_weight(cpufreq_cdev->policy->related_cpus);
// 分配内存,需要 CPU 数量匹配。
cpufreq_cdev->idle_time = kcalloc(num_cpus,
sizeof(*cpufreq_cdev->idle_time),
GFP_KERNEL);
if (!cpufreq_cdev->idle_time)
return -ENOMEM;
return 0;
}
static void free_idle_time(struct cpufreq_cooling_device *cpufreq_cdev)
{
// 释放内存
kfree(cpufreq_cdev->idle_time);
cpufreq_cdev->idle_time = NULL;
}3.2.5 cpufreq_power2state / cpufreq_state2power
cpufreq_power2state 和 cpufreq_state2power 都是在 CONFIG_THERMAL_GOV_POWER_ALLOCATOR 配置了才有意义。
(1)cpufreq_state2power
从 cooling state → 功耗(假设 100% 负载)。
功能说明:
- 输入:cooling state(state)。
- 输出:假设 100% 负载 时,对应频率下的 功耗(mW)。
- 应用:thermal 框架用它来评估"如果 CPU 被限制到这个 state,会消耗多少功率"。
c
/**
* cpufreq_state2power() - convert a cpu cdev state to power consumed
* @cdev: &thermal_cooling_device pointer
* @state: cooling device state to be converted
* @power: pointer in which to store the resulting power
* * Convert cooling device state @state into power consumption in
* milliwatts assuming 100% load. Store the calculated power in
* @power.
* * Return: 0 on success, -EINVAL if the cooling device state is bigger
* than maximum allowed.
*/
static int cpufreq_state2power(struct thermal_cooling_device *cdev,
unsigned long state, u32 *power)
{
unsigned int freq, num_cpus, idx;
struct cpufreq_cooling_device *cpufreq_cdev = cdev->devdata;
/* Request state should be less than max_level */
// 越界检查:cooling state 必须在 0 ~ max_level 范围内
// state 本质上就是 level 等级
if (state > cpufreq_cdev->max_level)
return -EINVAL;
// 获取这个 cooling device 涵盖的 CPU 数(通常是 cluster 内所有 CPU)
num_cpus = cpumask_weight(cpufreq_cdev->policy->cpus);
// cooling state 映射到频率表索引。获取频率。
idx = cpufreq_cdev->max_level - state;
freq = cpufreq_cdev->em->table[idx].frequency;
// 调用 cpu_freq_to_power() 获取该频率下的单核功耗,再乘以核数
*power = cpu_freq_to_power(cpufreq_cdev, freq) * num_cpus;
return 0;
}(2)cpufreq_power2state
从目标功耗 → cooling state(结合最近负载)。
功能说明:
- 输入:目标功耗上限(power,单位 mW)。
- 输出:对应的 cooling state(state)。
- 应用:thermal governor 通过功耗预算,算出应设置的 cooling state 来限制 CPU。
c
/**
* cpufreq_power2state() - convert power to a cooling device state
* @cdev: &thermal_cooling_device pointer
* @power: power in milliwatts to be converted
* @state: pointer in which to store the resulting state
*
* Calculate a cooling device state for the cpus described by @cdev
* that would allow them to consume at most @power mW and store it in
* @state. Note that this calculation depends on external factors
* such as the CPUs load. Calling this function with the same power
* as input can yield different cooling device states depending on those
* external factors.
*
* Return: 0 on success, this function doesn't fail.
*/
static int cpufreq_power2state(struct thermal_cooling_device *cdev,
u32 power, unsigned long *state)
{
unsigned int target_freq;
u32 last_load, normalised_power;
struct cpufreq_cooling_device *cpufreq_cdev = cdev->devdata;
struct cpufreq_policy *policy = cpufreq_cdev->policy;
// 使用最近一次统计的 CPU 平均负载。空值则默认1.
last_load = cpufreq_cdev->last_load ?: 1;
// 功率按负载进行"归一化"。如果当前负载不是 100%,则需要换算到等效 100% 负载下的功耗。
normalised_power = (power * 100) / last_load;
// 查找能满足 normalised_power 的频率
target_freq = cpu_power_to_freq(cpufreq_cdev, normalised_power);
// 根据目标频率,反推出 cooling state,即level
*state = get_level(cpufreq_cdev, target_freq);
trace_thermal_power_cpu_limit(policy->related_cpus, target_freq, *state,
power);
return 0;
}(3)get_level
c
/**
* get_level: Find the level for a particular frequency
* @cpufreq_cdev: cpufreq_cdev for which the property is required
* @freq: Frequency
* * Return: level corresponding to the frequency.
*/
static unsigned long get_level(struct cpufreq_cooling_device *cpufreq_cdev,
unsigned int freq)
{
int i; // 局部变量,用作索引,从最高的 table 索引向下扫描。使用 int 是为了可以表示 -1(循环结束时 i 可能变为 -1)
// 循环体:从 max_level - 1(表的最后一个索引)开始向下遍历到 0。
// 注意: max_level 是 num_levels - 1,所以 max_level-1 是倒数第二项。
// 注意:如果 max_level 为 0,则 i = -1,循环一次也不进入(安全地跳过循环)。
for (i = cpufreq_cdev->max_level - 1; i >= 0; i--) {
// 目的:在 EM 表中找到第一个 em->table[i].frequency 小于 freq 的索引。
// 注意:当 freq 大于某个表项频率时停止(意味着 freq 位于 i+1 项或更高)
if (freq > cpufreq_cdev->em->table[i].frequency)
break;
}
// (cpufreq_cdev->max_level - 1) - i,计算并返回映射后的 level。
return cpufreq_cdev->max_level - i - 1;
}返回结果:根据 i 的可能取值(-1 到 N-1),返回值落在 0, N(含端点)。
- 若循环在 i = N-1 立刻 break(意味着 freq > tableN-1),返回 N - (N-1) - 1 = 0。
- 若循环完全未触发 break(i 变为 -1,意味着 freq <= table0),返回 N - (-1) - 1 = N。
人能懂的解释-_-! :
① i 是一个循环遍历的角标,初值是 cpufreq_cdev->max_level - 1,这是个什么玩意呢?一步步看,cpufreq_cdev 是一个cpufreq_cooling_device指针,如结构体分析那部分,max_level 最大 cooling level 最大的角标值(倒数第一个),这里(max_level - 1)就指向最大索引的前一个,倒数第二个。
② 这个循环是 i-- 循环的,也就是检索位置不断的从后往前走,一个倒叙遍历过程。
③ freq > cpufreq_cdev->em->tablei.frequency 很直白的解释就是,传入了一个freq,通过检索这个表em->table,找到第一个比传入值小的位置,有链表插入节点时,遍历找节点位置的感觉。
④ 某个 i 满足条件,break跳出。此时,em->tablei.frequency < freq < em->tablei+1.frequency,freq正式可以确定位置。
⑤ 然而不是第三者插足,返回 (cpufreq_cdev->max_level - 1) - i 这个值。这是个什么意思呢?字面上看 (cpufreq_cdev->max_level - 1) - i 这个就是 em->table 中的个数差,从em->tablemax_level - 1 到 em->tablei 这个跨度的差值,从"最大频率tablemax_level - 1.frequency"到"判定标准freq"的差值。恰好用这个差值来表示level,这样就更上面的结果对的上:
- level -> 小,i -> 大,频率值 em->tablei.frequency 比较大,cpu可以高频运行 ------ 限制小,冷却强度低
- level -> 大,i -> 小,频率值 em->tablei.frequency 比较小,cpu需要低频运行 ------ 限制大,冷却强度高
因此,频率越高,返回的 level 越小;频率越低,返回的 level 越大(通常 level 越大表示越强的冷却/更低的频率限制)。
重要实现细节与注意点
- 表必须有序:em->table\[\] 必须按频率升序(table0 <= table1 <= ... <= tableN-1)才能保证此算法语义正确。否则结果不可预期。
- 等号边界:使用 >(严格大于)导致 等于某个 table 项 的 freq 会被映射到更高的 level(比那个 table 项的"档"更严格)。这是刻意行为,但要确认上层期望。
- 返回范围:返回值范围是 0 到 max_level(包含 max_level)。如果上层期待的合法 level 范围是 0...max_level-1,那么这里会出现 越界(off-by-one) 的问题 ------ 需要核对 max_level 的定义(是"最大等级"还是"等级数")。
(4)cpu_freq_to_power / cpu_power_to_freq
cpu_freq_to_power :从频率 → 功耗 的映射。通过频率值,找出CPU能够持续运行的功耗数据映射。
cpu_power_to_freq:从功耗 → 频率 的映射。给定一个 功耗预算(power),算出 CPU 能跑的最高频率。
c
static u32 cpu_freq_to_power(struct cpufreq_cooling_device *cpufreq_cdev,
u32 freq)
{
unsigned long power_mw;
int i;
// for 循环与上面 get_level 相同,寻找比 freq 小的第一个 table[i].frequency
for (i = cpufreq_cdev->max_level - 1; i >= 0; i--) {
if (freq > cpufreq_cdev->em->table[i].frequency)
break;
}
// 确定 i,table[i + 1]的频率更高,table[i + 1].frequency就是第一个 ≥ freq 的频率档。
// 用它的功耗值作为结果,接近要求,限制又过得去 >>>>> 性能还是要考虑下的
power_mw = cpufreq_cdev->em->table[i + 1].power;
// EM 表里的 power 单位是 µW(微瓦),换算成 mW(毫瓦)
power_mw /= MICROWATT_PER_MILLIWATT;
return power_mw;
}
static u32 cpu_power_to_freq(struct cpufreq_cooling_device *cpufreq_cdev,
u32 power)
{
unsigned long em_power_mw;
int i;
// 从最高 level(即最低频率)往回扫描。因为取的是功耗,level 大,power 小,可以按功耗增序遍历
for (i = cpufreq_cdev->max_level; i > 0; i--) {
/* Convert EM power to milli-Watts to make safe comparison */
// 取出该频率档对应的 µW 功耗。
em_power_mw = cpufreq_cdev->em->table[i].power;
// 单位转换 µW → mW。
em_power_mw /= MICROWATT_PER_MILLIWATT;
// 如果目标功率大于等于这一档的功耗,说明目标功耗至少能支撑到这一档。
// 于是选定这个档位,退出循环。
if (power >= em_power_mw)
break;
}
// 此时的位置,指向数据的频率就是满足目标功耗的最佳频率
return cpufreq_cdev->em->table[i].frequency;
}3.2.6 cpufreq_get_requested_power
(1)cpufreq_get_requested_power
cpufreq_get_requested_power 计算当前 CPU cluster 的动态功耗(单位 mW),存入 *power。
c
/**
* cpufreq_get_requested_power() - get the current power
* @cdev: &thermal_cooling_device pointer
* @power: pointer in which to store the resulting power
*
* Calculate the current power consumption of the cpus in milliwatts
* and store it in @power. This function should actually calculate
* the requested power, but it's hard to get the frequency that
* cpufreq would have assigned if there were no thermal limits.
* Instead, we calculate the current power on the assumption that the
* immediate future will look like the immediate past.
*
* We use the current frequency and the average load since this
* function was last called. In reality, there could have been
* multiple opps since this function was last called and that affects
* the load calculation. While it's not perfectly accurate, this
* simplification is good enough and works. REVISIT this, as more
* complex code may be needed if experiments show that it's not
* accurate enough.
*
* Return: 0 on success, this function doesn't fail.
*/
static int cpufreq_get_requested_power(struct thermal_cooling_device *cdev,
u32 *power)
{
unsigned long freq;
int i = 0, cpu;
u32 total_load = 0;
// 从 thermal_cooling_device 获取内部的 cpufreq_cooling_device。
struct cpufreq_cooling_device *cpufreq_cdev = cdev->devdata;
// 通过 policy 获取该 CPU 或 CPU cluster 的调频策略
struct cpufreq_policy *policy = cpufreq_cdev->policy;
// 获取当前 CPU 的频率(kHz)。
freq = cpufreq_quick_get(policy->cpu);
// 遍历该 policy 管理的所有相关 CPU
for_each_cpu(cpu, policy->related_cpus) {
u32 load;
if (cpu_online(cpu))
// 对于在线 CPU:调用 get_load() 获取其负载(%)
load = get_load(cpufreq_cdev, cpu, i);
else
load = 0; // 对于离线 CPU:负载记为 0。
// total_load 是 cluster 的总负载百分比
total_load += load;
}
// 记录最新的总负载,供下一次使用(以及给 governor 或 thermal 框架参考)
cpufreq_cdev->last_load = total_load;
// 根据频率和(隐含的负载信息)计算动态功耗
*power = get_dynamic_power(cpufreq_cdev, freq);
trace_thermal_power_cpu_get_power_simple(policy->cpu, *power);
return 0;
}(2)get_load
非 SMP模式下, 获取单个 CPU 在 上一次调用之后的平均负载(%)。
c
/**
* get_load() - get load for a cpu
* @cpufreq_cdev: struct cpufreq_cooling_device for the cpu
* @cpu: cpu number
* @cpu_idx: index of the cpu in time_in_idle array
*
* Return: The average load of cpu @cpu in percentage since this
* function was last called.
*/
static u32 get_load(struct cpufreq_cooling_device *cpufreq_cdev, int cpu,
int cpu_idx)
{
u32 load;
u64 now, now_idle, delta_time, delta_idle;
// 获取该 CPU 对应的 idle_time 记录,里面存放上次采样的时间戳和 idle 值。
struct time_in_idle *idle_time = &cpufreq_cdev->idle_time[cpu_idx];
// 获取当前时刻的 CPU idle 时间(纳秒/微秒级别,具体实现和架构相关)
// now:当前时间戳。---> now_idle:当前 CPU 累积的空闲时间。
now_idle = get_cpu_idle_time(cpu, &now, 0);
delta_idle = now_idle - idle_time->time; // 空闲时间增量
delta_time = now - idle_time->timestamp; // 总时间增量
if (delta_time <= delta_idle)
// CPU 全程 idle → 负载 = 0
load = 0;
else
// 活跃时间占比,换算成百分比。计算规则见下图
load = div64_u64(100 * (delta_time - delta_idle), delta_time);
// 更新采样点,为下一次调用做准备
idle_time->time = now_idle;
idle_time->timestamp = now;
return load;
}计算公式图:

(3)get_dynamic_power
c
/**
* get_dynamic_power() - calculate the dynamic power
* @cpufreq_cdev: &cpufreq_cooling_device for this cdev
* @freq: current frequency
*
* Return: the dynamic power consumed by the cpus described by
* @cpufreq_cdev.
*/
static u32 get_dynamic_power(struct cpufreq_cooling_device *cpufreq_cdev,
unsigned long freq)
{
u32 raw_cpu_power;
// 用频率查找当前适配的功率
raw_cpu_power = cpu_freq_to_power(cpufreq_cdev, freq);
return (raw_cpu_power * cpufreq_cdev->last_load) / 100;
}3.3 执行过程
3.3.1 流程步骤总结
(1)注册阶段
① of_cpufreq_cooling_register(policy)
- 从 DT 获取 CPU 节点,检查是否有 #cooling-cells。
- 获取 Energy Model (em_cpu_get())。
- 调用 __cpufreq_cooling_register()。
② __cpufreq_cooling_register()
- 分配并初始化 cpufreq_cooling_device。
- 统计 freq table → 设置 max_level。
- 初始化 cooling_ops (get/set state, power2state, state2power 等)。
- 添加 Freq QoS request(最大频率约束)。
- 调用 thermal_of_cooling_device_register() 注册到 thermal 框架。
③ 注册完成后,thermal framework 就能在 thermal_zone_device 中找到这个 cooling device
(2)运行阶段(温控检测)
① Thermal zone 的 sensor 报告温度。
② Thermal governor(如 step_wise 或 power_allocator):
- 判断当前温度是否超过 trip point。
- 如果过热,需要调用 cooling device → 增加 state。
(3)限频触发阶段
① Governor 调用 cpufreq_set_cur_state(cdev, state)。
② 内部执行:
- get_state_freq(cpufreq_cdev, state) → 把 state 转换为目标频率。
- freq_qos_update_request(&cpufreq_cdev->qos_req, frequency) → 更新 QoS 限制。
- 调用 arch_update_thermal_pressure() → 通知调度器该 CPU cluster 的算力下降。
③ Cpufreq core 接收到新的 QoS 限制 → 调整频率 policy,使 CPU 频率 ≤ 限制值。
(4)效果
- CPU cluster 被降频 → 功耗和发热降低 → 热点温度下降。
- Governor 周期性检查温度,动态调整 state(升高/降低)。
3.3.2 执行时序图