前言
昨天25年10.19,我个人在朋友圈说道,让双足人形干活,比让其跳舞更难(行内人都懂的)
-
上周我司『七月在线』完成了对机器人口头指定目的地,然后机器人自主导航到目的地,且过程中可以避开突然出现的人,最后通过机器视觉理解周围的环境
人形自主导航 第4个版本(可口头指定目的地、可绕开障碍)
-
本周,我们会让人形最后走到操作台前,完成简单的桌面收纳任务
如此,集齐『语音对话 自主导航 动态避障 识别环境 灵巧操作』等一系列技能且所有一切全部自主,无任何摇操,无任何人工干预
且很快,我们会让它干越来越多的活,让它的干活技能开始起飞,从而让大家开始感受一系列震撼,让机器人干好活,让我们更兴奋
当然了,过程中 除了我司自行独立研发之外,也会关注到市面上其他同行的一些工作,特别是行走-操作类的
而本文所要解读的TrajBooster(来自浙大和西湖大学等单位),在上个月便已关注到了,只是当时忙于我司内部的开发,没时间去细看,近期有点时间了,可以仔细了解下
第一部分 TrajBooster:通过轨迹中心学习提升人形机器人全身操作能力
1.1 引言与相关工作
1.1.1 引言
如TrajBooster原论文所说,近期的进展显著推动了人形操作技术的发展 *比如1-Being-0、2-Egovla、3-Gr00t n1、4-Humanoid policy˜ human policy、5-Agibot world colosseo*
在此基础上,视觉-语言-动作(VLA)模型使人形机器人能够自主且更可靠地执行各种家庭任务,并提升了其泛化能力
其中,轮式仿人机器人在需要全身协调动作的家务任务中表现尤为出色,例如蹲下和跨越不同高度的伸手动作,这突显了真实家庭环境中对实用作业范围和灵巧性的需求
-
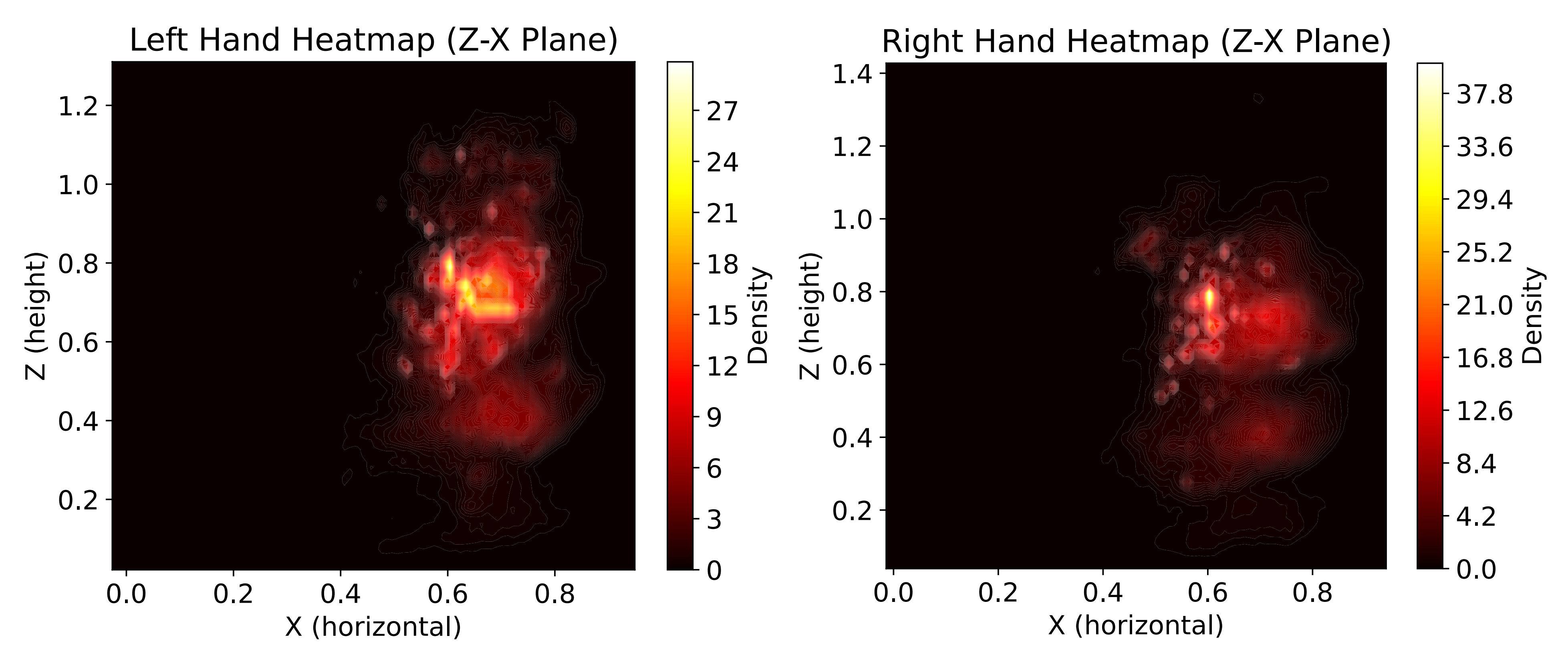
来自 Agibot-World Beta 数据集 5 的证据显示

末端执行器的轨迹集中在0.2--1.2 米之间『见图2,Agibot-World Beta数据集中Z-X平面上的手部位置热力图。利用核密度估计(KDE)可视化左右手分布。X轴正方向与机器人前进方向一致,Z轴正方向与重力相反(向上)』,进一步强调了日常家务任务需要在超越桌面范围的广阔工作空间内进行多样化操作
-
相比之下,双足仿人机器人在操作时必须用上半身进行操控,同时用下半身保持动态平衡,这使得大范围的全身操作变得尤为具有挑战性
与此同时,先前的 VLA 研究主要集中在
- 复杂环境中的行走 *6-Humanoidvla,7-Leverb: Humanoid whole-body control with latent vision-language instruction*
- 或桌面操作 *2-Egovla、3-Gr00t n1*
因此存在一个关键空白:如何实现双足仿人机器人的大范围全身操作,而实现这一能力需要大规模的演示,但数据收集仍然是瓶颈
- 而现有的远程操作流程需要昂贵的基础设施,并且专家操作员通常只能生成规模较小、在不同场景和任务间多样性有限的数据集
- 因此,视觉语言动作模型(VLA)在后训练阶段难以适应新型人形机器人平台的动作空间。虽然在异构机器人语料库上进行预训练有所帮助,但这无法替代高质量、与人形机器人高度相关且覆盖全面的全身演示数据------说白了,就是不同本体的数据做预训练有用,但毕竟不如当前本体的实采数据
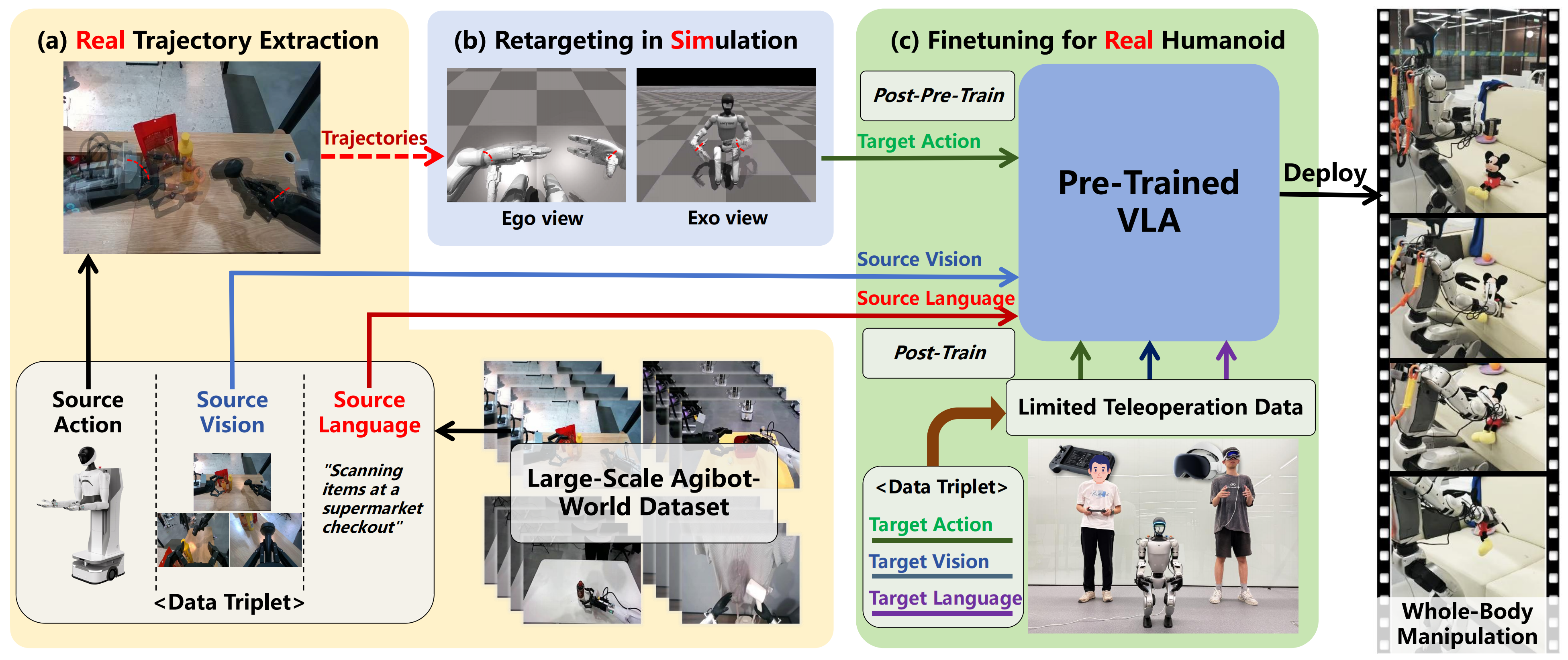
好在来自1 Zhejiang University, 2 Westlake University, 3 Shanghai Jiao Tong University, 4 Shanghai Innovation Institute的研究者提出了TrajBooster来解决这个问题,这是一种跨形态框架(见图1)
- 其paper地址为:TrajBooster: Boosting Humanoid Whole-Body Manipulation via Trajectory-Centric Learning
其作者包括
Jiacheng Liu1,2,4*, Pengxiang Ding1,2*, Qihang Zhou3,4, Yuxuan Wu3,4, Da Huang3,4,Zimian Peng1,4,Wei Xiao2
Weinan Zhang3,4, Lixin Yang3,4, Cewu Lu3,4†, Donglin Wang2,4† - 其项目地址为:jiachengliu3.github.io/TrajBooster
其GitHub地址为:github.com/OpenHelix-Team/OpenTrajBooster
具体而言,其能够利用末端执行器轨迹的形态无关特性,将演示从轮式机器人迁移到双足人形机器人,从而缓解双足VLA微调过程中的数据稀缺问题,并提升VLA动作空间的理解能力,及全身操作任务泛化能力
他们的关键见解在于,尽管形态结构存在差异,末端执行器轨迹可以作为共享接口,弥合不同实体之间的关节空间差距。从而可以通过利用轮式人形机器人Agibot G1的大规模数据,通过真实-仿真-真实的流程,间接提升了对双足Unitree G1的VLA训练
该TrajBooster框架包含以下三个步骤:
-
真实轨迹提取
该过程首先从源机器人中提取末端执行器的轨迹。TrajBooster 并不是将全身动作直接映射到目标人形机器人,而是**++利用双臂末端执行器的 6D 坐标作为目标++** ,使得在 Isaac Gym 仿真器中的重定向模型能够通过跟踪该目标,实现全身动作的重定向 -
仿真中的重定向
重定向模型采用作者经过启发式增强的统一在线DAgger算法,在目标人形机器人Unitree G1上进行训练,使其利用全身控制跟踪这些参考轨迹
在此过程中,人形机器人学习协调其各关节,使末端执行器能够跟随重定向后的目标,从而将低维参考信号有效映射为可行的全身高维动作
该阶段生成了大量与真实世界目标人形机器人形态兼容的动作数据 -
针对真实人形机器人进行微调:利用这些新生成的数据,TrajBooster 构建了异构三元组,形式为⟨source vision, source language, target action⟩,将感知输入与适用于人形机器人的行为相连接
由此生成的合成数据集随后用于对已有的VLA 模型进行后预训练
接着,仅需额外10分钟的真实遥操作数据,即⟨target vision,target language, target action⟩,即可对后预训练的 VLA 进行微调,并部署在 Unitree G1 上,覆盖广泛的全身操作任务
1.1.2 相关工作
首先,对于人形机器人的全身控制
-
近年来,现实世界中人形机器人全身控制的研究取得了显著进展,许多工作8--15主要通过远程操作的方法推动了该领域的发展
8-Twist
9-Clone
10-H2O
11-Omnih2o
12-Exbody
13-A unified and general humanoid whole-body controller for
fine-grained locomotion
14-Mobile-television
15-Unleashing humanoid reaching potential via real-world-ready skill space诸如Humanoid-VLA6和Leverb7等研究通过采用VLA模型生成全身动作,探索了自主策略
然而,这些工作主要集中在粗粒度的控制上,例如坐下、挥手或行走等动作相比之下,关于人形机器人操作任务的研究已探索通过视觉运动策略 4,16-DP3 或 VLA 模型 2,3 进行动作生成,但这些研究大多局限于桌面场景
这种设定未能充分利用人形机器人下肢的运动能力,从而限制了机器人的操作空间 -
尽管 Homie 17 通过其视觉运动控制策略在解决这一限制方面取得了显著进展,但其实用性仍受限于需要为每个任务单独训练策略 ,因此在多样化任务场景中的可扩展性有限
为克服这一局限性,TrajBooster利用统一的 VLA 模型,使双足人形机器人在现实环境中能够实现多任务的全身操作,展现出在广泛操作高度范围内的多样化操作能力
其次,对于跨体态学习
-
跨体态学习旨在实现不同形态代理之间的知识迁移。多种方法通过修复、分割或基于物理的渲染18--21来缓解感知差异,有效对齐观测结果,但这些方法仍局限于感知层面
18-Ag2manip
19-Egomimic
20-H2r: A human-to-robot data augmentation for robot pretraining from videos
21-Masquerade: Learning from in-the-wild human videos using data-editing超越感知层面,研究者们开始探索体态无关的动作抽象
潜在动作表示
5-Agibot world colosseo
22-Latent action pretraining from videos
23-Igor: Image-goal representations are the atomic control units for foundation models in
embodied ai
24-villa-x:Enhancing latent action modeling in vision-languageaction models
提供了粗粒度、隐式的编码方式而基于轨迹的方法
2-Egovla
25-Dexmv
26-H-rdt: Human manipulation enhanced bimanual robotic manipulation
则将操作技能提取为显式形式
例如,DexMV25将人类三维手势映射到机器人轨迹
尽管这些方法在灵巧的手-物体交互方面表现有效,但尚无法扩展到全身动作迁移 -
近期如*27-Umi on legs: Making manipulation policies mobile with manipulation-centric whole-body controllers*的研究可以生成全身动作,然而其适用性受限于四足机器人工作空间的配置
本研究针对上述局限性,首次将该方法应用于类人机器人场景,利用执行器空间的6D位姿重映射,跨多种双臂机器人演示,实现了向目标类人机器人的跨体型迁移,从而达成了跨体型的双足类人机器人操作,并实现了广泛的全身工作空间覆盖
1.2 TrajBooster的完整方法
TrajBooster,是一个真实-到-仿真-到-真实的流程,如图1所示
在本节中,作者依次描述
- 如何从现有数据集中提取真实轨迹以用于重定向
- 介绍重定向模型的架构和策略学习算法
- 详细说明通过两步后训练流程对预训练的 VLA 进行适应:
i)利用在仿真中收集的重定向全身操作数据进行后预训练,即二次预训练
以及 ii)利用在真实环境中少量遥操作数据进行后训练,即微调
1.2.1 实际轨迹提取
作者使用 Agibot-World beta 数据集 5 的操作数据作为真实机器人数据源。该数据集包含超过一百万条真实机器人轨迹,包括多视角视觉信息、语言指令和 6D 末端执行器位姿
-
然而,基于末端执行器位置和姿态轨迹的直接迁移并不适用,因为 Agibot 和Unitree G1 之间的工作空间存在差异
例如,Agibot 的机械臂完全伸展时臂展可达 1.8 米,而Unitree G1 的臂展仅为 1.2 米 -
为了解决这一问题,作者将Agibot 数据集的轨迹映射到Unitree 官方G1 操作数据集28-unitreerobotics/G1 Dataset,后者包含7 个桌面级任务的2,093 个片段
具体而言,作者通过基于G1 数据进行z-score 归一化,将Agibot 数据的x 轴与G1 对齐,使用与机械臂长度成比例的缩放因子
对y 轴进行缩放,并将z 轴裁剪到0.15, 1.25 的安全范围内
1.2.2 仿真中的重定向:涉及模型架构、分层模型训练、使用重定向数据的后预训练
第一,对于模型架构
鉴于Agibot-World数据集涵盖了大量家务任务,其中z轴坐标主要分布在0.2--1.2米之间(见图2)
因此,要实现成功的全身操作,需要下半身动作的协调配合(如下蹲)
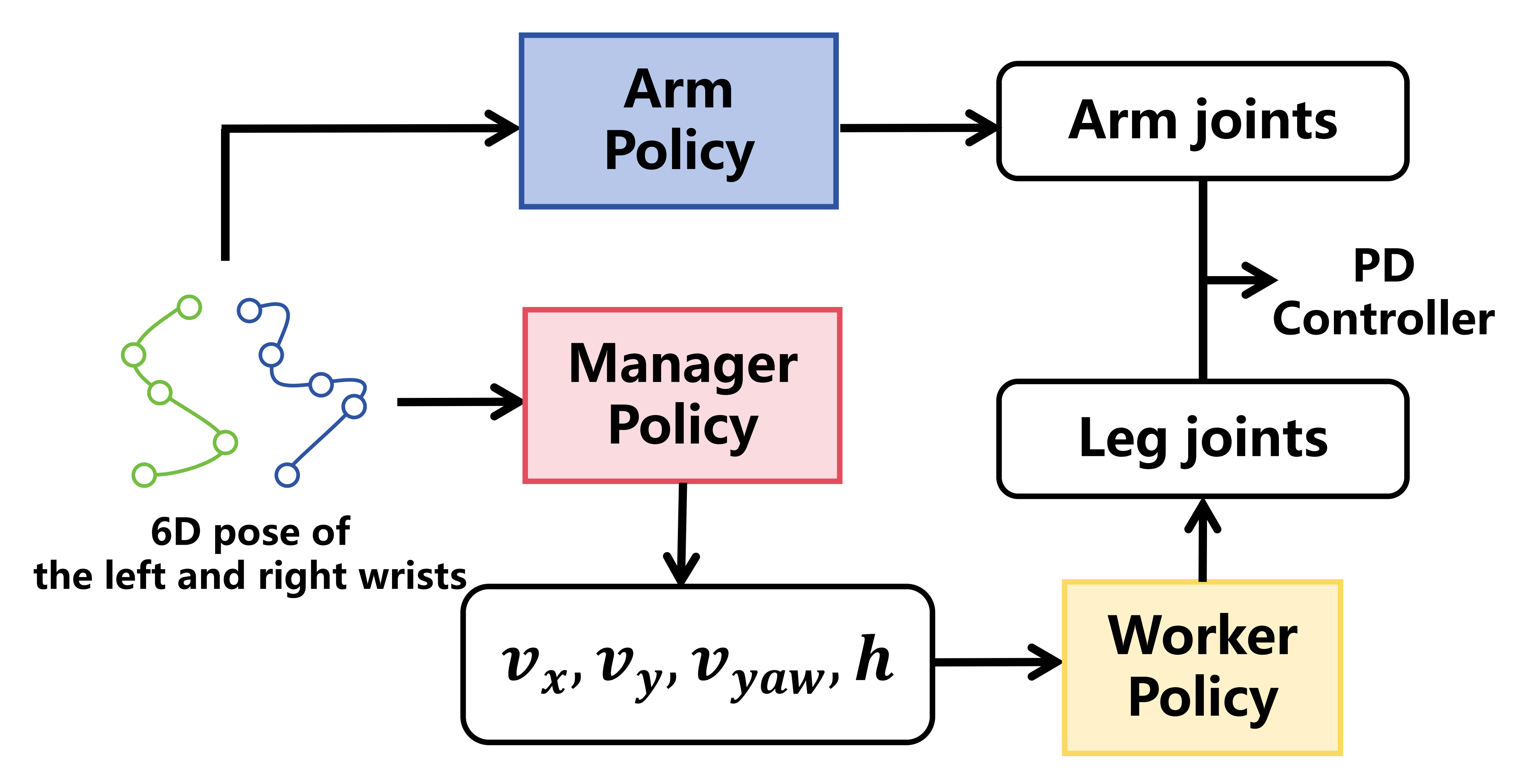
为此,作者提出了一种用于全身操作重定向的复合分层模型(见下图图3)
具体而言:
- ++手臂策略(PIK)++ :通过Pinocchio *29-The pinocchio c++ library: A fast and flexible implementation of rigid body dynamics algorithms and their analytical derivatives*中的闭环逆运动学(CLIK)计算目标关节角度
其中 - ++工作者策略(
一种按照17 训练的目标条件强化学习策略,采用上半身运动课程以增强对干扰的鲁棒性。它为12 自由度下肢输出目标关节位置:
其中, - 管理者策略(
根据手腕姿态生成下半身指令
最终,该复合分层模型 H 集成了以下组件
该模型以末端执行器相对于机器人基座的位姿 作为输入,输出通过 PD 控制器执行的 Unitree G1 关节指令
第二,对于分层模型训练
分层模型训练包括两个阶段:首先进行 训练,然后通过基于启发式的在线学习(算法1)进行
训练

训练的关键方面如下:
-
种子轨迹采集
在 MuJoCo 中,将 Unitree G1 初始化为站立状态,重放包含 2,093 个片段的上肢运动数据集 28,并记录生成的轨迹 -
轨迹增强
对种子轨迹应用 PCHIP(分段三次 Hermite 插值多项式)插值方法,生成高度变化范围为 0.15m,1.25m 的数据,从而实现不同高度下的全身操作
-
启发式目标指令(
启发式真实高度目标
启发式速度指令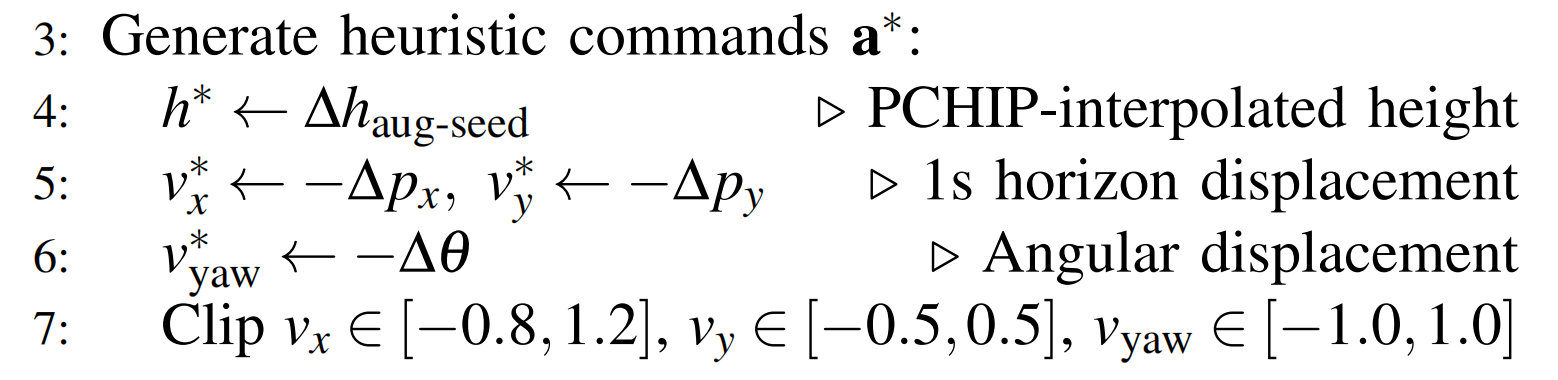
-
统一的在线DAgger
为简洁起见,
在每次迭代中,Pm 在Isaac Gym 中的N 个并行环境上执行一次T 步的rollout(T = 50)
损失被最小化为
-
另,作者为缓解在持续学习中出现的灾难性遗忘问题,他们实现了一种协调的数据集聚合(DAgger)策略

具体而言,与标准的 DAgger *30-A reduction of imitation learning and structured prediction to no-regret online learning* 不同「标准 DAgger 在每次迭代时都会聚合数据」,作者通过在聚合过程中进行子采样来平衡数据效率和计算效率------具体来说,他们每 M = 10 次迭代才纳入新的演示数据:
随后,作者对聚合后的数据集损失进行最小化:
关键的是,该流程利用了在实际部署中无法获得的特权信息。具体而言,在仿真中,作者可以获取与当前目标6D操作轨迹对应的躯干高度,以及人形机器人基座相对于相应身体位置的位移。这些特权信息使得能够高效生成启发式目标指令
第三,对于使用重定向数据的后预训练
后预训练(PPT)是一种介于预训练和后训练之间的中间阶段,在大语言模型(LLMs)31,32和视觉-语言模型(VLMs)*33-Post-pre-training for modality alignment in visionlanguage foundation models*中被广泛采用------其实就是二次预训练
类似地,对于VLA,作者预计该方法也将提升模型对下游任务的快速适应能力,并增强其对动作空间的适应性和理解能力,如图4所示
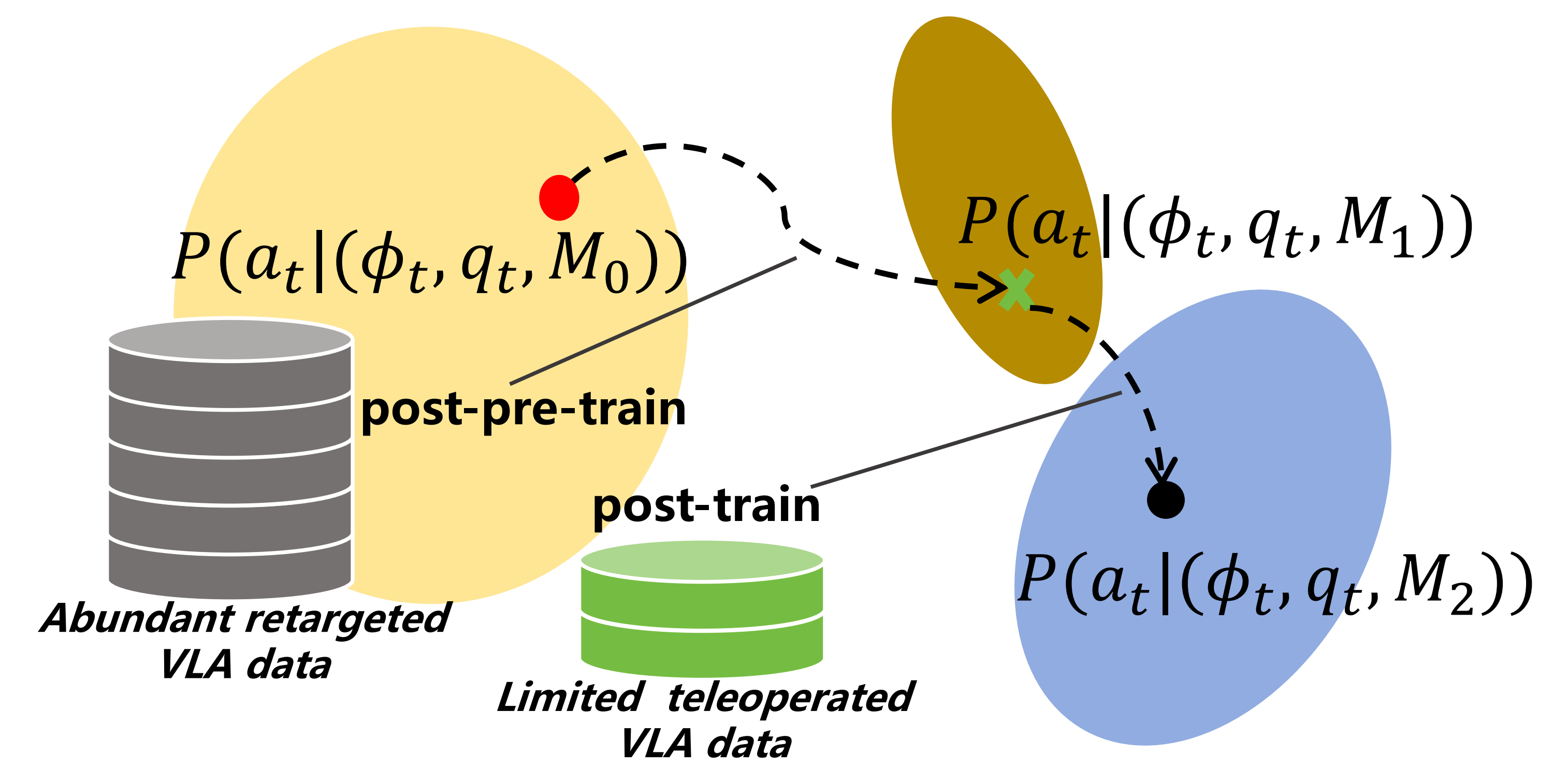
在本研究中,作者通过整合重定向的动作数据、语言指令以及来自原始 Agibot-World 数据集的视觉观测,构建了多模态数据三元组。这些三元组被用于对预训练的 GR00T N1.5 模型 3 进行后预训练
后预训练阶段采用与3 中描述的后训练阶段相同的目标函数。给定一个真实动作片段 和采样噪声
,作者构造一个加噪动作片段:
,其中
表示流匹配时间步。模型
通过最小化流匹配损失,预测去噪向量场
:
其中,表示视觉-语言令牌嵌入,
编码UnitreeG1的全身关节状态,
为从N(0,I)采样的高斯噪声,期望值在
服从
的均匀分布下取
在推理过程中,作者以4 步去噪生成跨越16 个时间步、频率为20Hz 的动作片段。每个片段包含双臂和双手的关节位置指令,以及用于 模块的下半身控制指令
,使VLA 模型能够实现对人形机器人的全身控制
第四,对于后训练
-
遥操作数据采集
作者采用与
然而,与分层模型H 不同,且使用两个手腕RGB 相机(左侧和右侧)以及一个头部RGB 相机收集视觉数据
-
在目标人形机器人上微调VLA
收集到的远程操作数据被用于对已预训练的VLA模型进行后续训练,通过最小化公式(8)中定义的流匹配损失来实现
1.3 实验
如原论文所说,作者的实验设计针对四个主要问题展开:
- Q1:分层训练框架(结合了协调化的在线DAgger)在类人轨迹重定向任务中是如何优于基线方法的?
- Q2:在微调过程中,用模拟重定向动作替换动作数据,是否能加速对真实环境中类人动作空间的适应?
- Q3:后预训练是否能够增强物体在分布外位置上的轨迹泛化能力?
- Q4:后预训练能否在真实遥操作任务中为未见过的操作技能解锁零样本能力?
1.3.1 重定向模型的评估
-
基线
分层模型使用Harmonized Online DAgger 进行训练
为了验证该方法在跟踪模型训练中的有效性和效率,作者与多个基线方法进行了比较:基于奖励的PPO、标准DAgger、在线学习(M = 1 且不使用DAgger)、标准在线DAgger(M = 1 且使用DAgger) -
实现细节
所有实验均使用个并行环境,训练200次迭代,PPO因其额外的价值模型训练,采用800次迭代。训练与推理均在单块RTX 4090 GPU和Intel Core i9-14900K CPU上完成 -
卓越的跟踪性能
通过仿真评估跟踪性能,计算Unitree G1手腕轨迹与目标轨迹之间的位置平均绝对误差(MAE, 单位cm)和旋转误差(单位度)如表I所示
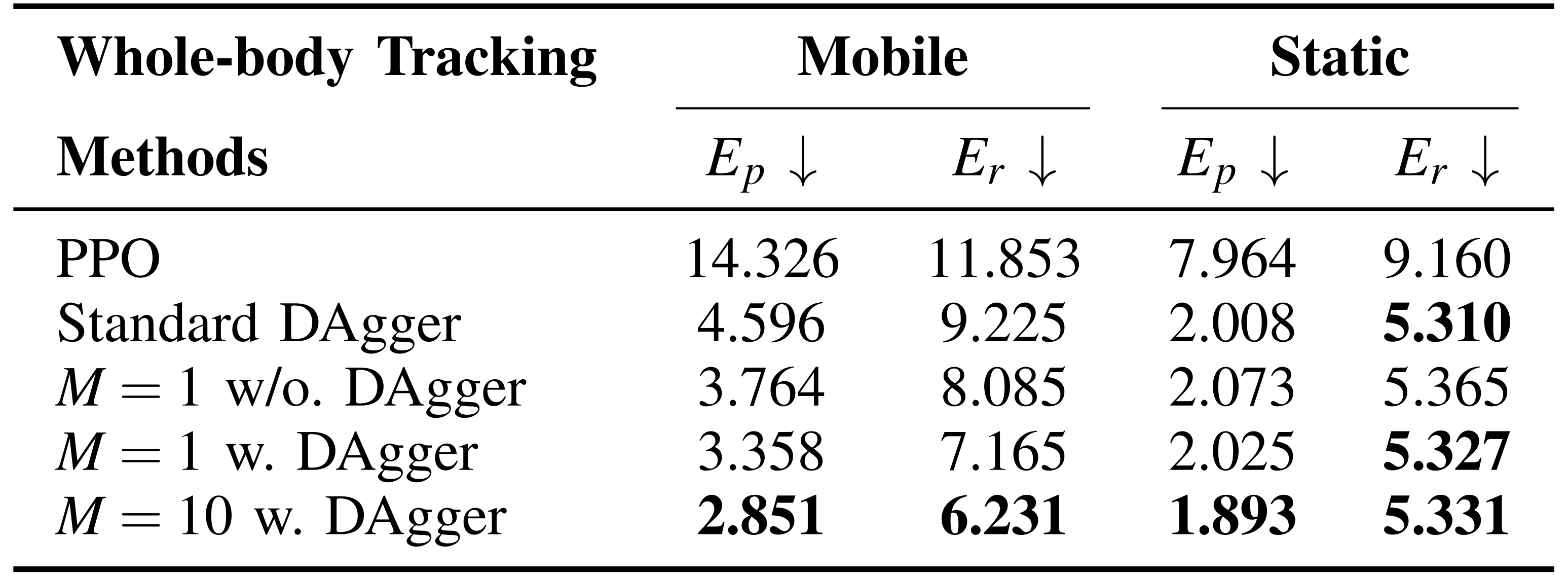
作者的协调化在线DAgger在实现运动-操作跟踪能力(见图5)的同时,具备更低的存储开销和更高的学习效率
// 待更