国产OCR双雄对决?PaddleOCR-VL与DeepSeek-OCR全面解析
OCR 再次火爆:一场由大模型驱动的技术文艺复兴
沉寂已久的 OCR 领域,在 2024 年下半年迎来了前所未有的爆发。短短一个月内,DeepSeek、百度(PaddlePaddle)、上海 AI Lab 等国内顶尖团队接连发布了其最新的 OCR 模型,迅速点燃了全球开发者的热情。
这场热潮有多夸张?在 10 月 21 日的 HuggingFace Trending 榜单上,前三名一度被 OCR 模型包揽 ,而百度的 PaddleOCR-VL 更是连续五天霸榜第一,成为全球瞩目的焦点。这不仅是一场技术的狂欢,更是一次国产 AI 实力的集中展示。PaddleOCR-VL 与 DeepSeek-OCR 的相继亮相,标志着国产 OCR 技术已经走向成熟,并开始引领全球趋势。
那么,为什么 OCR 在这个时间点突然变得如此重要?
- RAG 应用的基石:随着检索增强生成(RAG)成为企业级大模型应用的主流,如何高质量、高效率地将海量私有文档(PDF、扫描件、图片)转化为可供检索的数字知识,成为决定 RAG 应用成败的关键。高精度 OCR 是保证输入质量的"守门员"。
- 产业流程自动化的刚需:从金融票据识别到法律合同审阅,再到物流单据处理,高精度、低成本的文档自动化处理是企业降本增效的核心诉求。
- 大模型能力进化的必然:大模型要真正理解世界,就必须具备解析和理解图片、PDF 等非结构化信息的能力。OCR 正是打通物理世界与数字智能的关键环节。
在这场竞赛中,百度的 PaddleOCR-VL 凭借其独特的设计理念和卓越的性能脱颖而出。
主角登场:PaddleOCR-VL - 0.9B 超轻量全能文档解析器
你是否曾被文档解析的复杂性所困扰?无论是处理扫描的合同、提取财报中的表格,还是识别论文里的公式,传统 OCR 工具在面对多样化版式和复杂元素时,常常力不从心。更不用说,那些效果好的大模型,动辄几十上百亿的参数量,让本地部署和高效推理成为奢望。
今天,我想向你介绍一个由百度开源的,可能会改变这一现状的项目------PaddleOCR-VL。它巧妙地平衡了性能与效率,用一个仅有 0.9B 参数的超紧凑视觉语言模型,实现了业界领先(SOTA)的多语言文档解析能力。
核心价值:小模型,大能量
PaddleOCR-VL 的核心是一个名为 PaddleOCR-VL-0.9B 的视觉语言模型(VLM)。它创新性地将 NaViT 风格的动态分辨率视觉编码器与轻量级的 ERNIE-4.5-0.3B 语言模型相结合。
这种设计的精妙之处在于:
- 紧凑而强大:在保证高精度的同时,极大地降低了计算资源消耗,使得在普通硬件上进行高效、实用的文档处理成为可能。
- 全能解析:它不仅仅是文字识别。无论是常规文本、复杂表格、手写公式,还是图表,它都能精准识别。
- 多语言覆盖:支持包括中文、英语、日语、韩语、拉丁语系,以及俄语、阿拉伯语、印地语等在内的 109 种语言,轻松应对全球化的文档处理需求。
简单来说,PaddleOCR-VL 让开发者感觉到:"这个工具能解决我实际的文档解析问题,而且它足够轻量,我真的可以在自己的项目里用起来。"
Show, Don't Tell
相比于空泛的描述,直接的代码和效果更有说服力。
快速上手
首先,你需要安装 PaddlePaddle 和 PaddleOCR。官方建议使用 Linux 环境(Windows 用户可以使用 WSL 或 Docker)。
bash
# 安装 PaddlePaddle GPU 版本
python -m pip install paddlepaddle-gpu==3.2.0 -i https://www.paddlepaddle.org.cn/packages/stable/cu126/
# 安装 PaddleOCR(包含文档解析功能)
python -m pip install -U "paddleocr[doc-parser]"
# 安装 safetensors
python -m pip install https://paddle-whl.bj.bcebos.com/nightly/cu126/safetensors/safetensors-0.6.2.dev0-cp38-abi3-linux_x86_64.whl安装完成后,无论是通过命令行还是 Python API,调用都极其简单。
命令行调用:
bash
paddleocr doc_parser -i https://paddle-model-ecology.bj.bcebos.com/paddlex/imgs/demo_image/paddleocr_vl_demo.pngPython API 调用:
python
from paddleocr import PaddleOCRVL
# 初始化模型
pipeline = PaddleOCRVL()
# 执行预测
output = pipeline.predict("https://paddle-model-ecology.bj.bcebos.com/paddlex/imgs/demo_image/paddleocr_vl_demo.png")
# 处理并保存结果
for res in output:
res.print() # 打印结果
res.save_to_json(save_path="output") # 保存为 JSON
res.save_to_markdown(save_path="output") # 保存为 Markdown性能如何?
PaddleOCR-VL 不仅在设计上创新,更在性能上取得了 SOTA 的结果。在 OmniDocBench 这个权威的文档解析基准测试中,它在整体性能、文本、公式、表格和阅读顺序等多个维度上都达到了顶尖水平。
在针对文本、表格、公式、图表等元素的单项识别能力上,它也全面超越了现有的解决方案,甚至表现出与顶级 VLM(如 GPT-4V)相媲美的竞争力。
巅峰对决:PaddleOCR-VL vs. DeepSeek-OCR
DeepSeek-OCR 作为同期引爆社区的另一个优秀模型,同样展示了强大的实力。那么,二者相比,开发者该如何选择?
| 特性维度 | PaddleOCR-VL | DeepSeek-OCR | 分析 |
|---|---|---|---|
| 模型大小 | 0.9B (超轻量) | 2B | PaddleOCR-VL 更轻量,对硬件更友好,部署门槛更低。 |
| 核心架构 | NaViT 视觉编码器 + ERNIE-4.5-0.3B 语言模型 | 未明确公布,但为 VLM 架构 | PaddleOCR-VL 架构清晰,创新地结合了动态分辨率视觉与轻量语言模型。 |
| 功能全面性 | 端到端文档解析 (文本、表格、公式、图表、阅读顺序) | 同样支持复杂文档解析 | 两者功能相似,但 PaddleOCR-VL 在公开基准测试中展现了更全面的 SOTA 性能。 |
| 多语言支持 | 109 种语言 | 40+ 种语言 | PaddleOCR-VL 语言覆盖范围更广,全球化应用优势明显。 |
| 生态与工具链 | 完善的 PaddleOCR 生态 (训练、部署、加速工具) | 依赖开源社区生态 | PaddleOCR 作为一个成熟项目,提供了从训练到部署的全套工业级解决方案。 |
| 易用性 | 提供命令行、Python API、vLLM 加速服务 | 提供 Python API | 两者上手都比较简单,但 PaddleOCR-VL 提供了更多样的调用和加速方式。 |
| 开源协议 | Apache 2.0 | Apache 2.0 | 均为商业友好型协议。 |
总结:
- PaddleOCR-VL :一个极致轻量、性能全面、生态成熟的"全能选手"。它更像一个开箱即用的工业级解决方案,特别适合对部署成本、多语言支持和端到端性能有高要求的场景。
- DeepSeek-OCR:一个性能优异、社区活跃的"实力新星"。它为开发者提供了一个强大的开源基座,非常适合进行二次开发和学术研究。
实际评测
理论和榜单性能固然重要,但真实场景下的表现才是检验模型的唯一标准。接下来,我们将通过一系列真实世界的复杂案例,对 PaddleOCR-VL 的能力进行全面评测。
评测对象:
- 常规文本识别:测试不同字体、大小、背景下的文字识别准确率(见示例评测图片1)。
- 复杂表格提取:测试跨页、嵌套、无线框表格的结构化提取能力(示例评测图片2)。
- 公式识别:测试手写及印刷体复杂数学公式的识别准确率(示例评测图片3)。
- 手写体识别:测试中英文混合、潦草字迹的手写内容识别(示例评测图片4)。
- 特殊场景识别:测试竖版文字、印章、票据等特殊场景的识别效果(示例评测图片5、6)。
示例评测图片1:书的封面
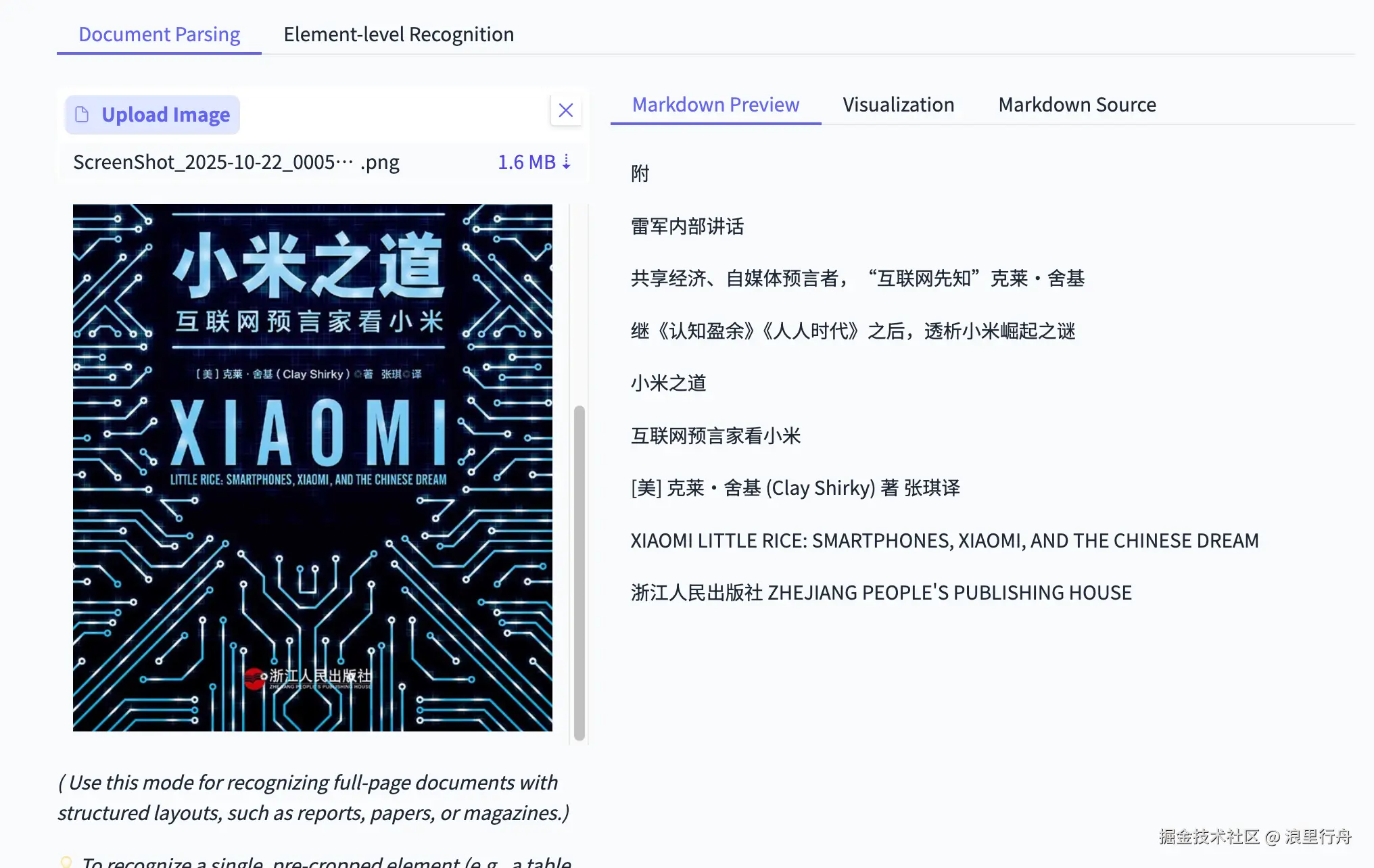
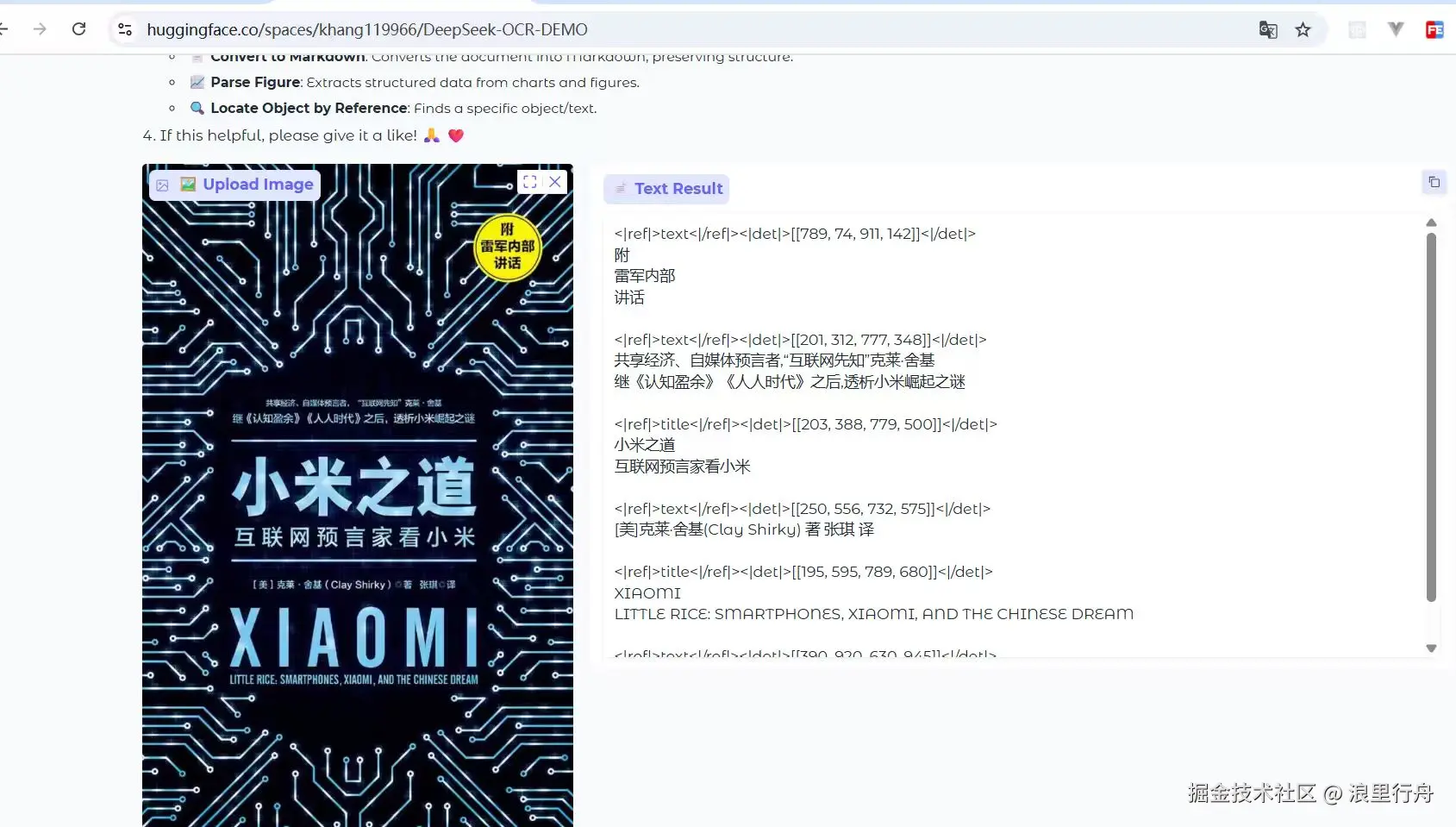
测试结果:识别率不相上下。
示例评测图片2:图表
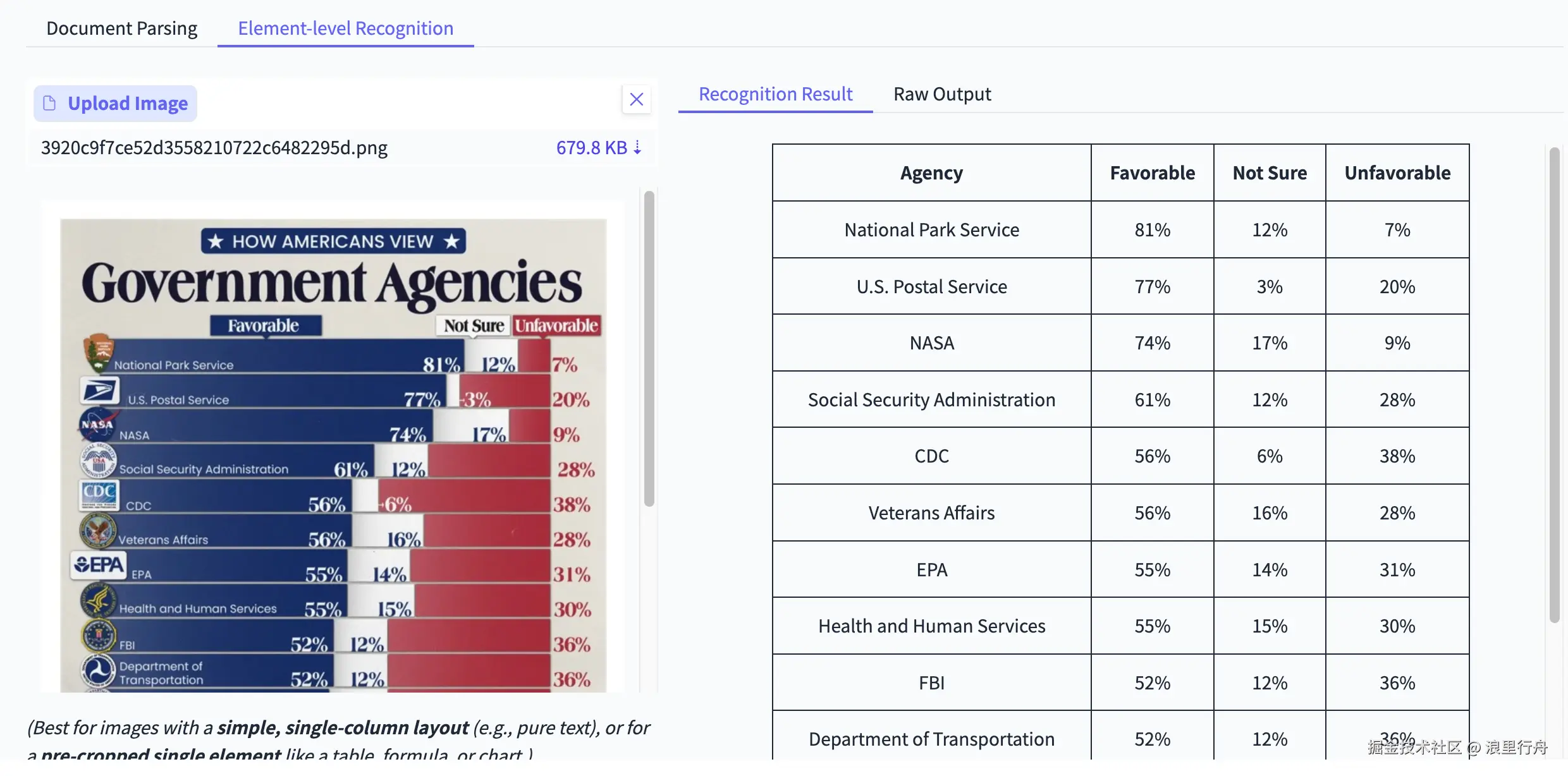
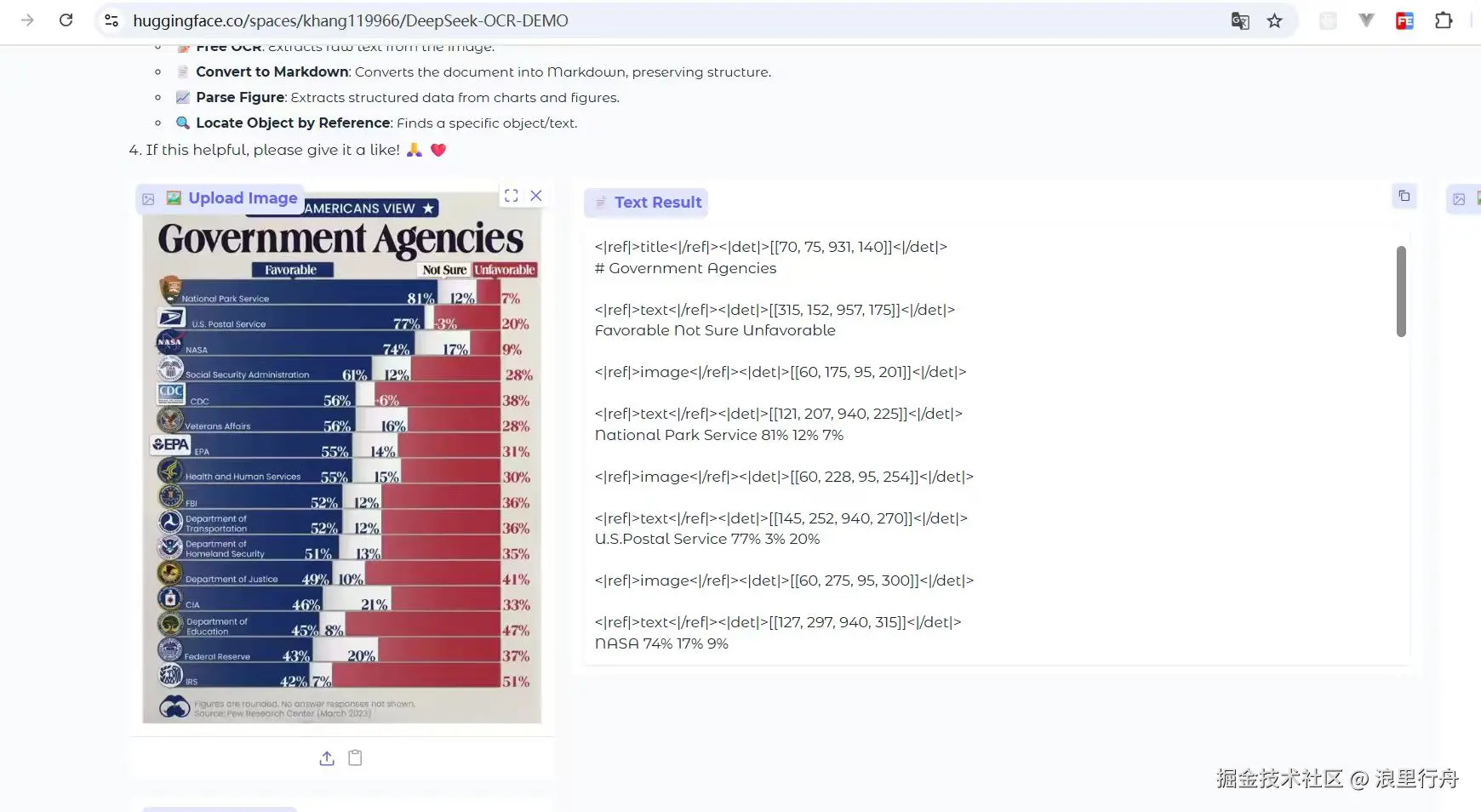
测试结果:PaddleOCR-VL能生成更直观的表格(HTML标签)。
示例评测图片3:数学除法
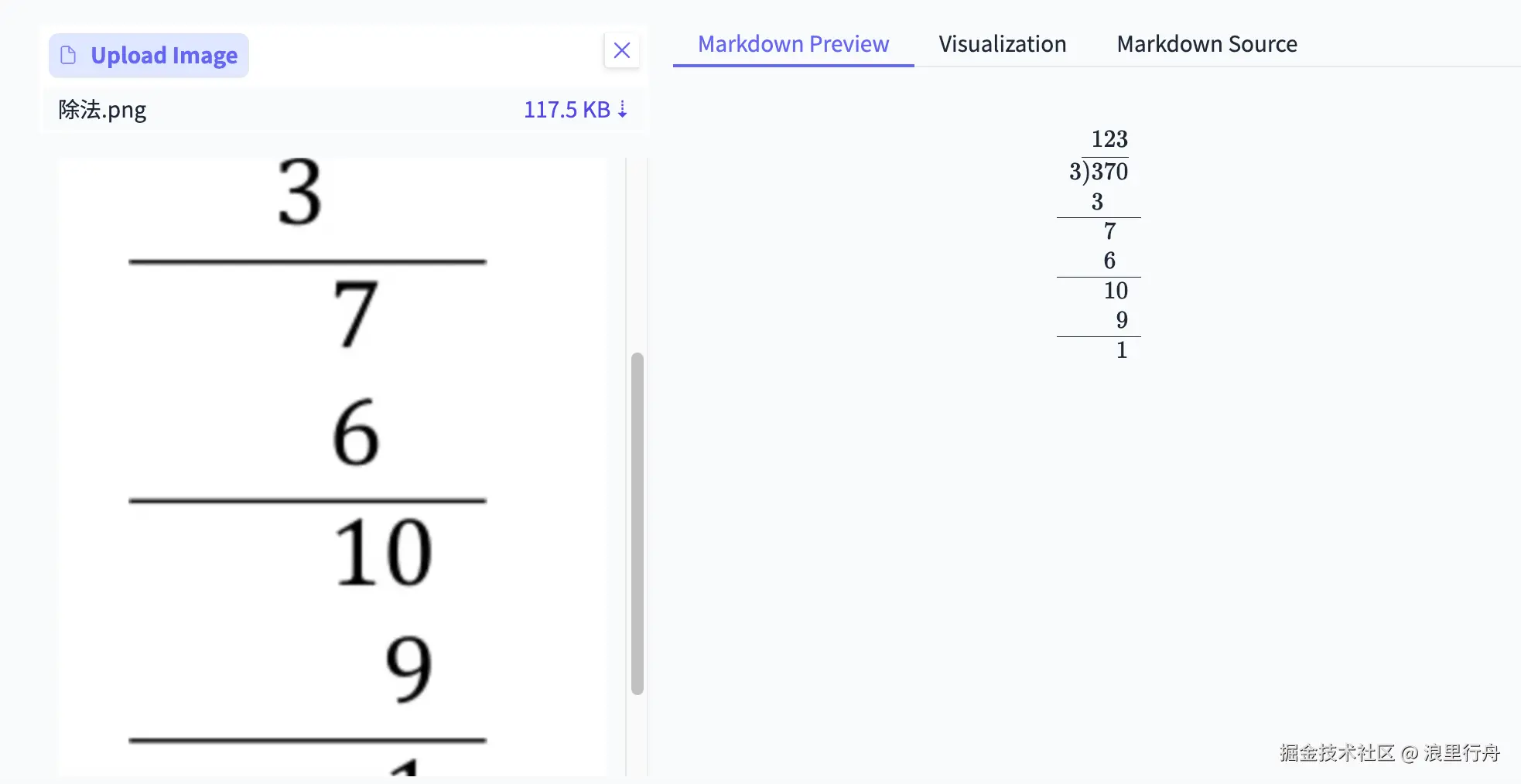
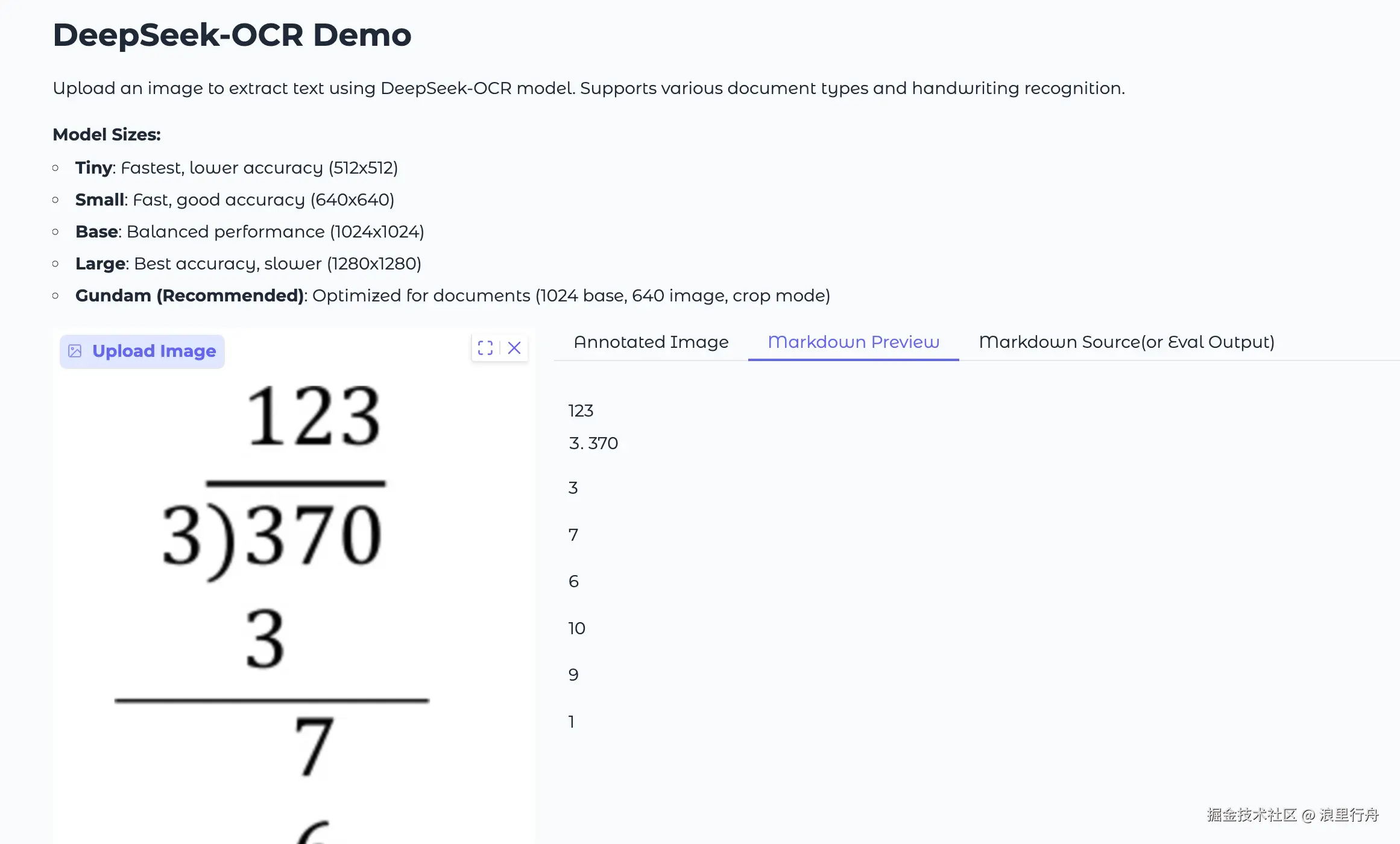
测试结果:PaddleOCR-VL精准识别Deepseek-OCR能识别出图中数字,但并没给出正确的排版
示例评测图片4:药方,手写体
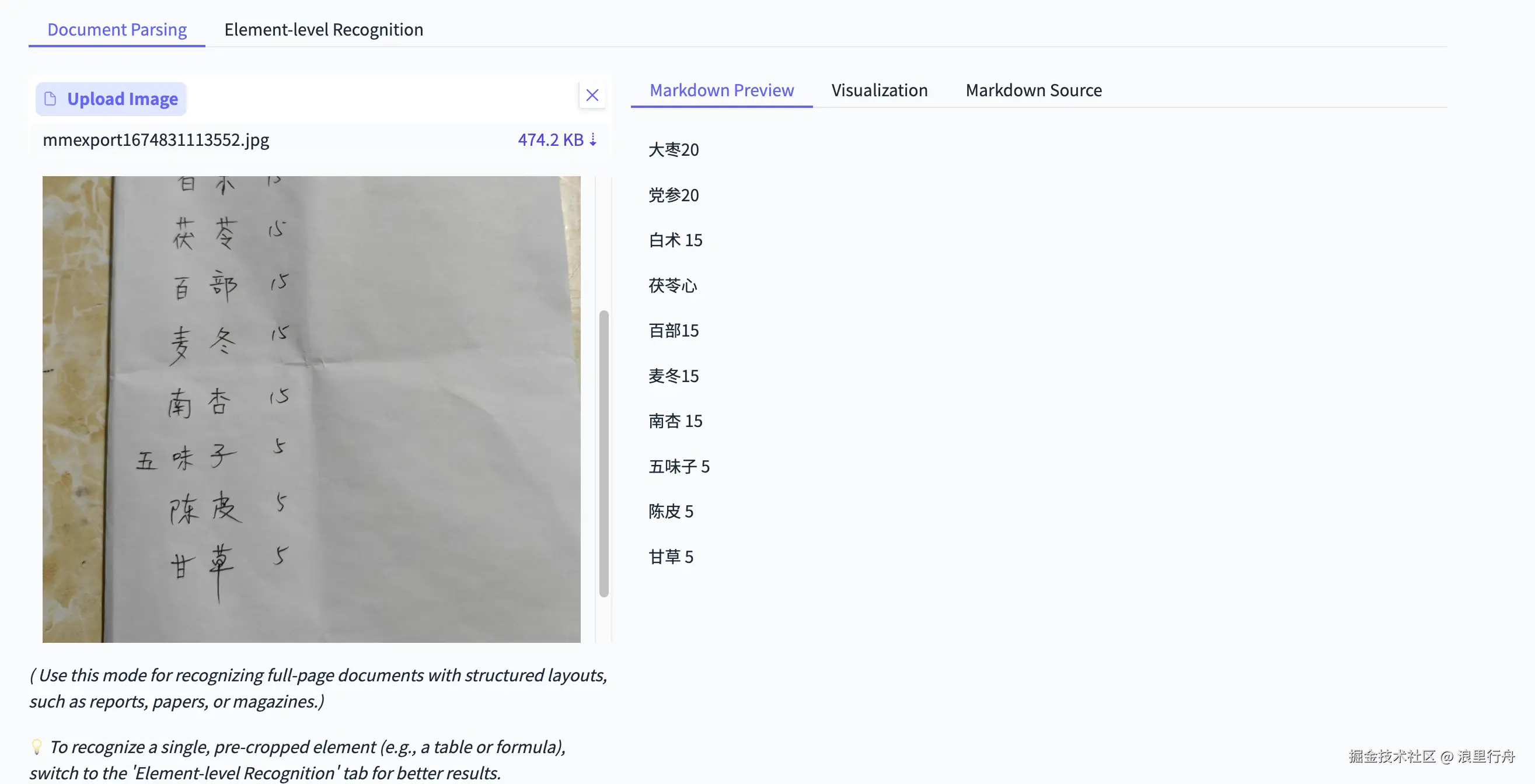
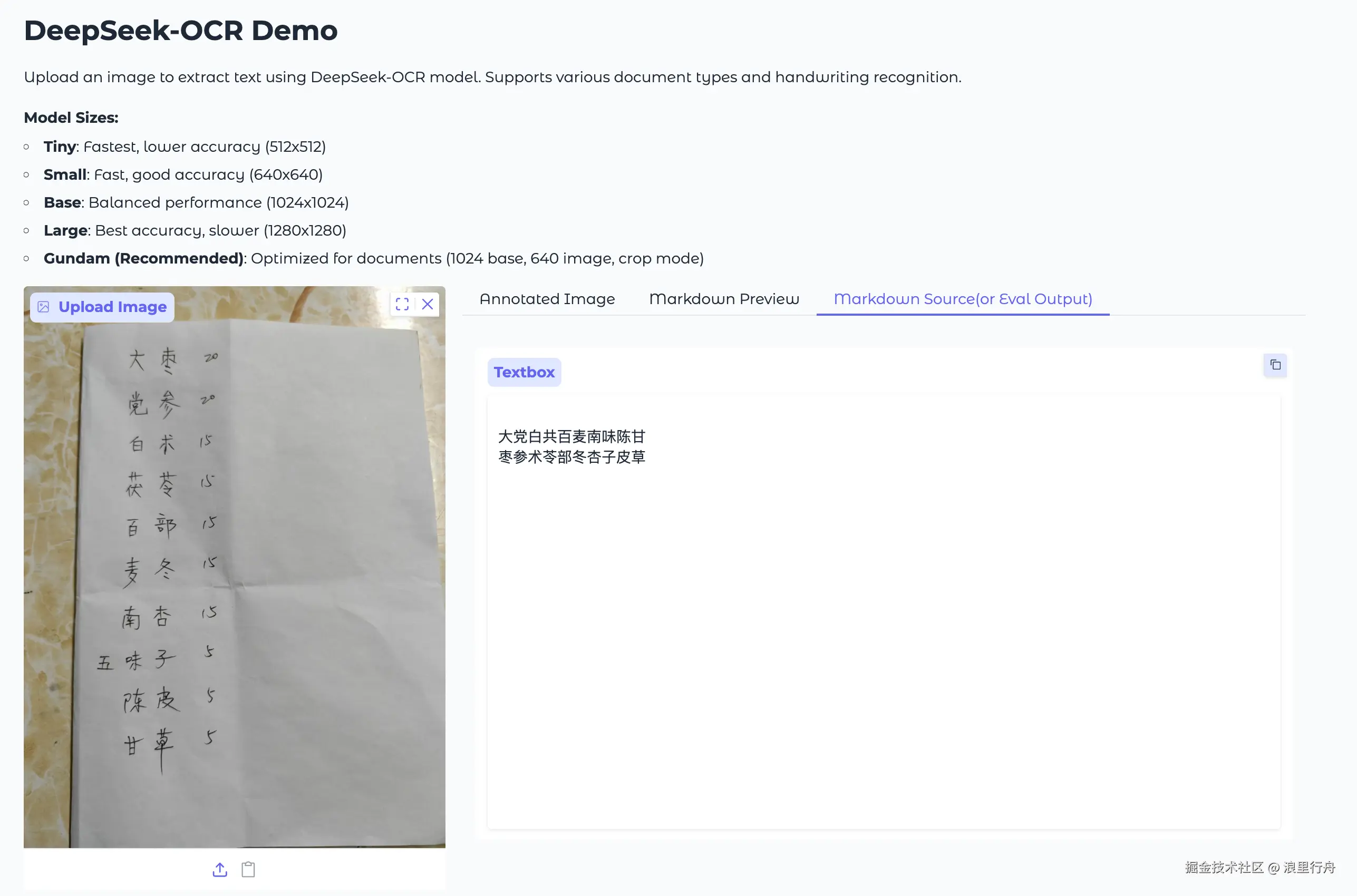
测试结果:PaddleOCR-VL能正确识别中文和数字。Deepseek-OCR识别出中文,但文字排版方向和原图不一致,而且数字被忽略掉了。
示例评测图片5:打印的英文小票的照片
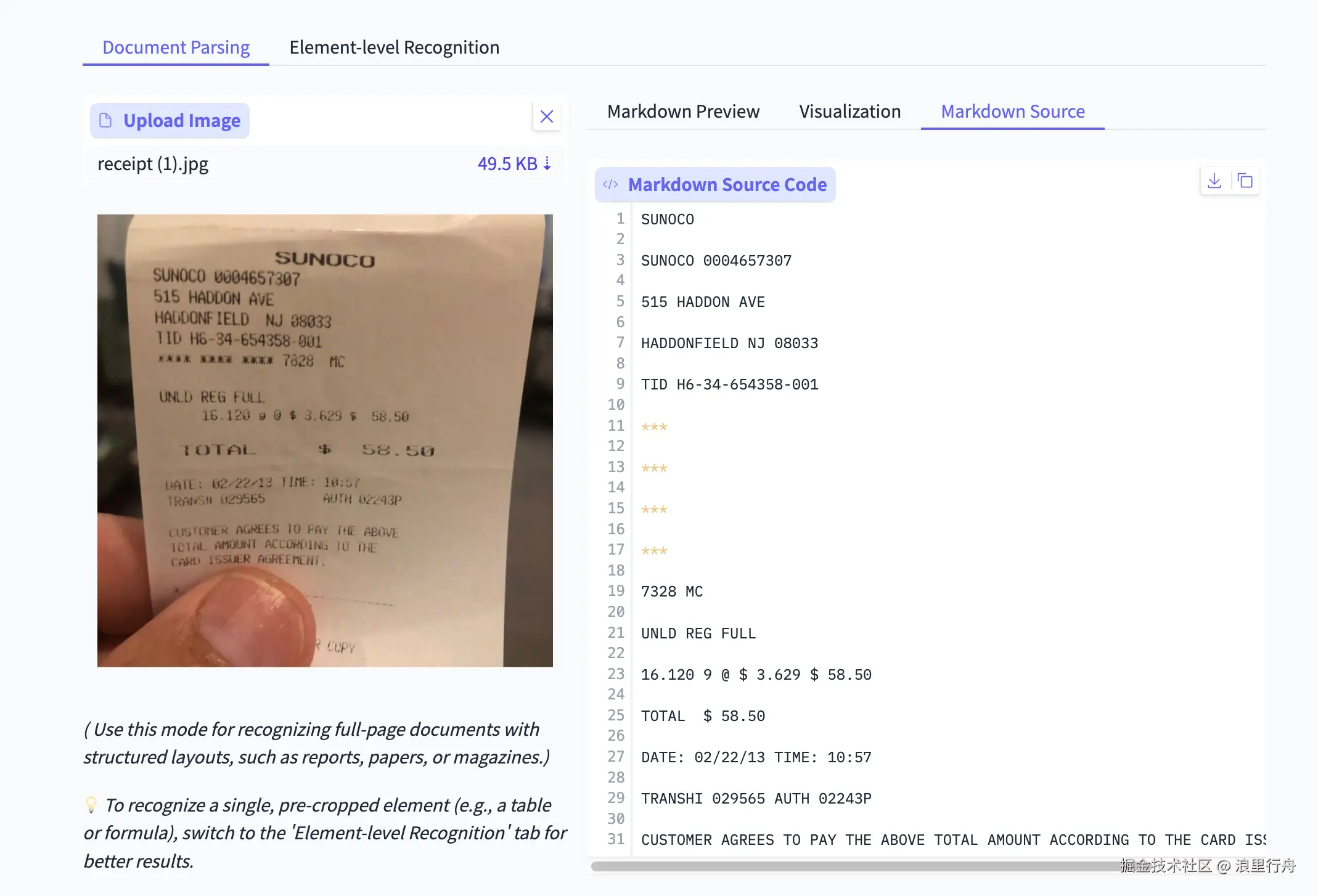
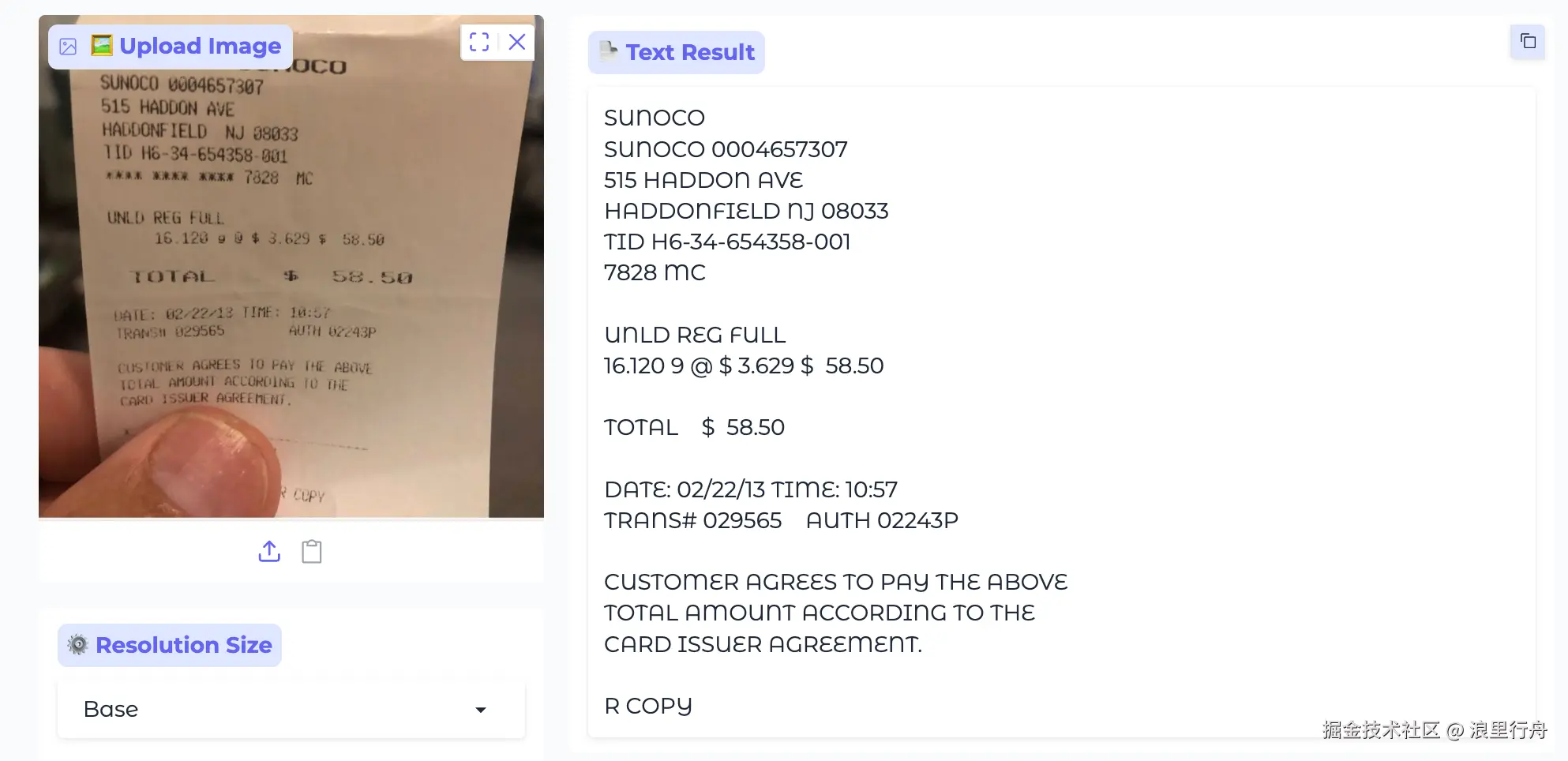
测试结果:PaddleOCR-VL的识别率比Deepseek-OCR高,比如正文第5行开头的星号Deepseek-OCR就没识别出来。
示例评测图片6:书签,艺术字
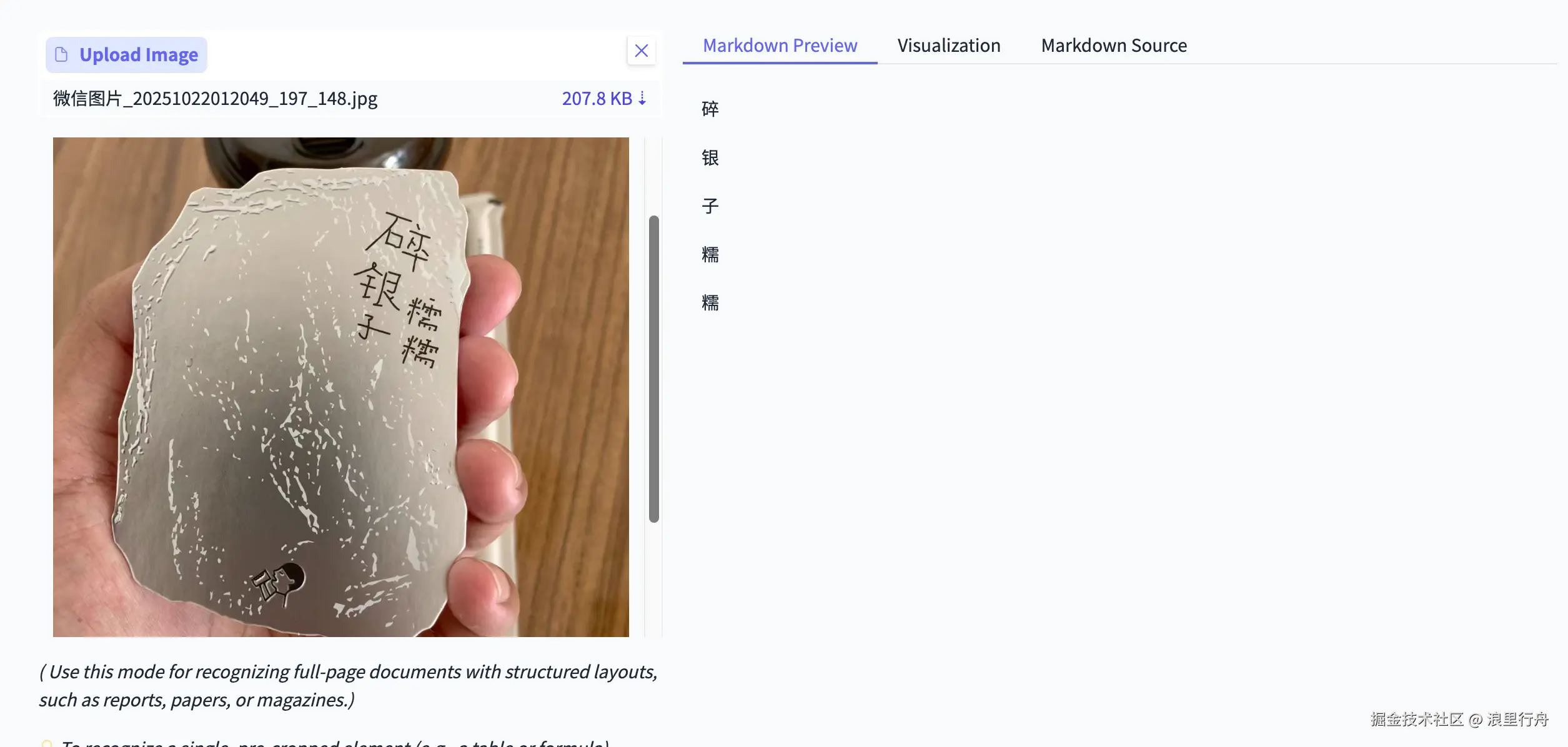
测试结果:PaddleOCR-VL能正确识别出文字和阅读顺序。Deepseek-OCR识别不出任何内容。
总结:横向测评与选择建议
经过实际对比,两款模型都展现了顶尖实力,但侧重点不同:
PaddleOCR-VL:工业级全能选手
- 优势:模型更轻量(0.9B),部署门槛低;在表格、公式、手写体、艺术字等复杂场景和版面理解上表现更鲁棒;拥有更成熟的工业级生态和更广泛的语言支持(109种)。
- 适合:需要开箱即用、处理多样化复杂文档、对部署成本敏感的企业级应用。
DeepSeek-OCR:性能锐利的实力新星
- 优势:基础文本识别能力极强,社区热度高,是一个非常优秀的开源基座模型。
- 适合:以标准文档识别为主,或需要进行二次开发和学术研究的开发者。
一句话总结:追求全能与工程化落地选 PaddleOCR-VL,看重社区生态与二次开发潜力可选 DeepSeek-OCR。