随着工作负载规模扩大以及对更快数据处理需求的增长,与基于CPU的系统相比,GPU加速的数据库和查询引擎已被证明能够带来显著的性价比提升。GPU的高内存带宽和线程数尤其有利于计算密集型工作负载,例如多重连接、复杂聚合、字符串处理等。GPU节点日益普及以及GPU算法广泛的功能覆盖,使得GPU数据处理比以往任何时候都更易用。
通过解决性能瓶颈,数据和业务分析师现在可以查询海量数据集以生成实时洞察并探索分析场景。
为支持日益增长的需求,IBM与NVIDIA正携手将NVIDIA cuDF引入Velox执行引擎,为Presto和Apache Spark等广泛使用的平台实现GPU原生查询执行。这是一个开放项目。
Velox与cuDF如何协同翻译查询计划
如图1所示,Velox作为中间层,将来自Presto和Spark等系统的查询计划转换为由cuDF驱动的可执行GPU流水线。更多细节请参阅《扩展Velox------使用cuDF实现GPU加速》。
在本文中,我们很高兴分享Presto和Spark使用Velox中GPU后端的初步性能结果。我们将深入探讨:
•端到端Presto加速•扩展Presto以支持多GPU执行•在Apache Spark中演示CPU-GPU混合执行
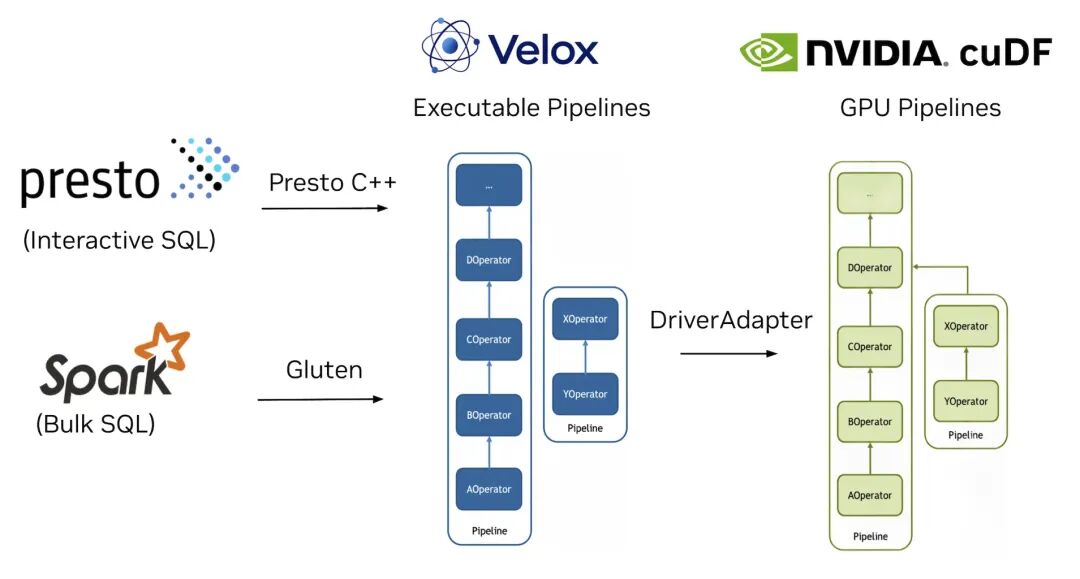
图1. 查询从Presto或Apache Spark流经Velox引擎,被转换为由cuDF驱动的可执行GPU流水线
将完整Presto查询计划移至GPU以实现更快执行
查询处理的第一步是将传入的SQL命令转换为查询计划,其中包含集群中每个节点的任务。在每个工作节点上,Velox的cuDF后端从Presto协调器接收计划,使用GPU Operators 重写计划,然后执行该计划。
使用支持cuDF的Velox运行Presto计划需要对TableScan、HashJoin、HashAggregation、FilterProject等GPU运算符进行改进:
•TableScan:Velox TableScan在CPU端扩展,以兼容cuDF中的GPU I/O、解压缩和解码组件。•HashJoin:支持的 Join 类型已扩展至包含左连接、右连接和内连接,并支持过滤器和空语义。•HashAggregation:引入了流式接口来管理 partial aggregations 和 final aggregations。
总体而言,Velox的cuDF后端中的运算符扩展实现了Presto中的端到端GPU执行,充分利用了Presto SQL解析器、优化器和协调器。
团队使用Presto tpch(源自TPC-H)基准测试收集查询运行时间数据,数据源为Parquet,同时使用Presto C++和Presto-on-GPU工作节点类型。请注意,Presto C++在标准配置选项下无法完成Q21,因此图中突出显示了21个成功查询的总运行时间。
如图2所示,在 SF1,000下,我们观察到Presto C++在AMD 7965WX上的运行时间为1,246秒,Presto在NVIDIA RTX PRO 6000 Blackwell工作站上的运行时间为133.8秒,Presto在NVIDIA GH200 Grace Hopper超级芯片上的运行时间为99.9秒。我们还使用CUDA托管内存在GH200上完成了Q21(见图2星号标注),使得Presto GPU在完整查询集上的运行时间为148.9秒。
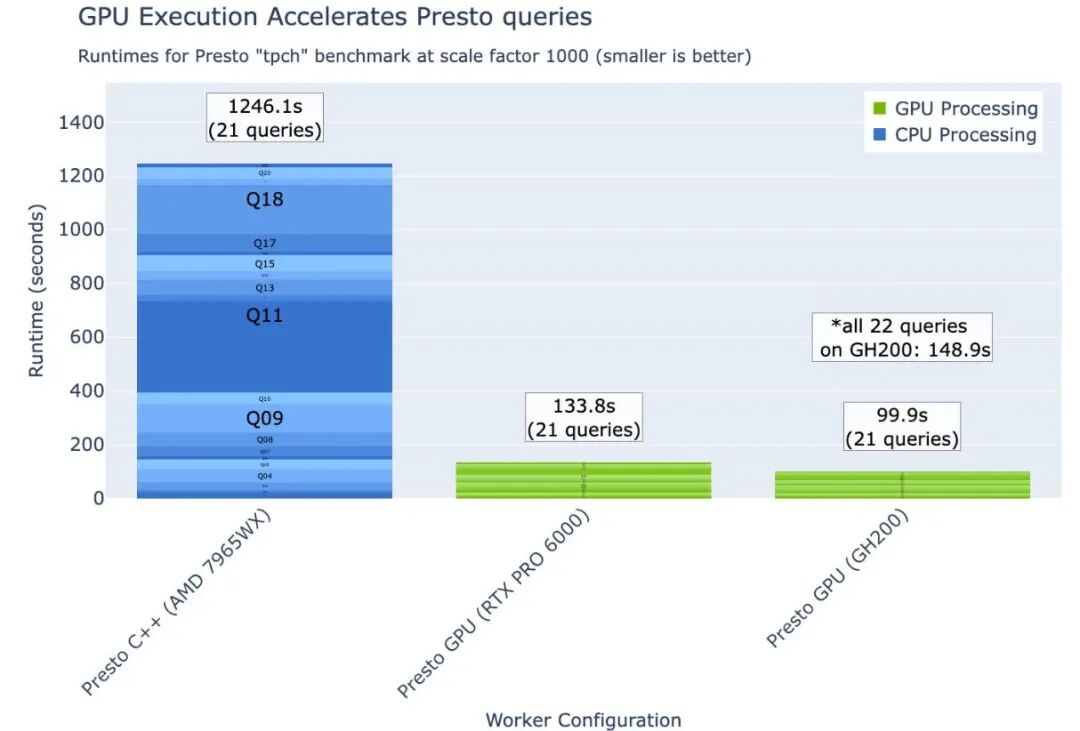
图2. SF1,000下,使用单节点Presto C++ on CPU和Presto on NVIDIA GPU执行Presto tpch中定义的22个查询中的21个查询的运行时间结果
多GPU Presto以实现更快数据交换和更低查询运行时间
在分布式查询执行中,Exchange是一个关键运算符,控制同一节点上工作节点之间以及节点之间的数据移动。GPU加速的Presto使用基于UCX的Exchange运算符,支持在整个执行流水线上运行GPU。UCX核心利用高带宽NVLink实现节点内连接,并利用RoCE或InfiniBand实现节点间连接。UCX(统一通信-X框架)是一个开源通信库,旨在为HPC应用实现最高性能。
Velox支持多种Exchange类型以适应不同的数据移动类型:Partitioned、Merge和Broadcast。Partitioned Exchange使用哈希函数对输入数据进行分区,然后将分区发送到其他工作节点进行进一步处理。Merge Exchange接收来自其他工作节点的多个输入分区,然后生成单个的、排序后的输出分区。Broadcast Exchange在一个工作节点中加载数据,然后将数据复制到所有其他工作节点。GPU exchange与Velox的cuDF后端的集成正在进行中,该实现已在Velox主线上提供。
如图3所示,Presto在使用新的基于UCX的exchange时在GPU上实现了高效性能,尤其是在GPU之间提供了高带宽节点内连接的情况下。与使用Presto基线HTTP exchange相比,在八GPU NVIDIA DGX A100节点上,在exchange运算符中使用NVLink实现了超过6倍的加速。结果收集自使用基线HTTP Exchange方法和基于UCX的cuDF Exchange方法的Presto on GPU。使用八个GPU工作节点时,Presto可以使用默认的异步内存分配完成所有22个查询,而无需使用托管内存。
请注意,图3使用了来自Presto协调器的多节点执行计划和冷缓存远程数据源。这些结果与图2所示的单节点热缓存运行时间不能直接比较。
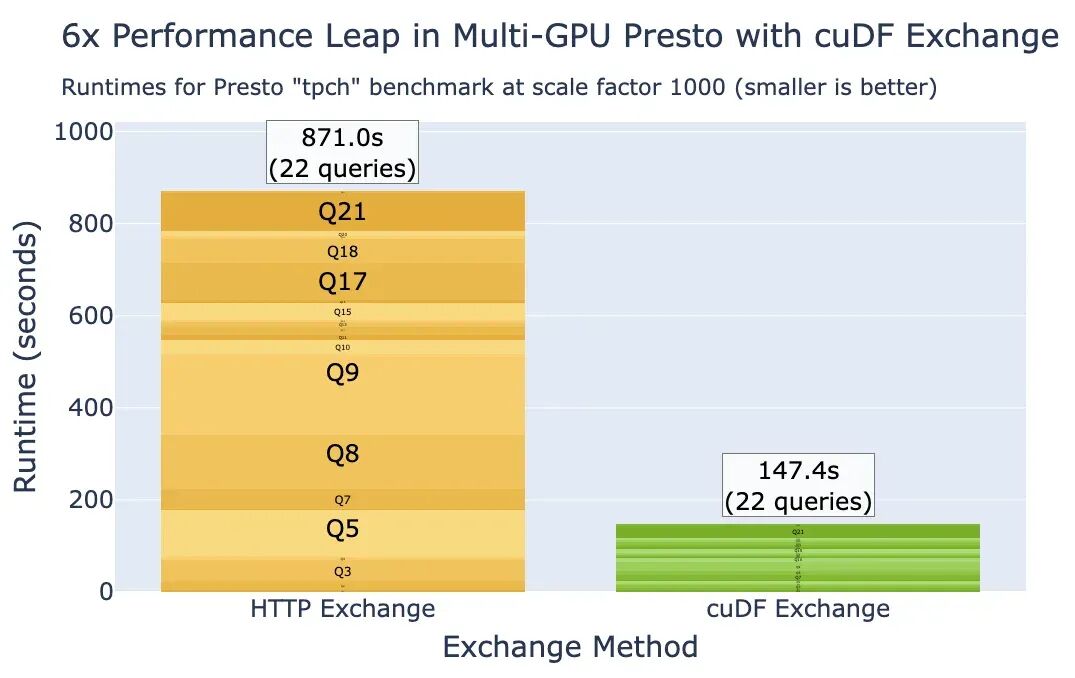
图3. SF1,000下,使用Presto GPU在NVIDIA DGX A100(八个A100 GPU)上执行Presto tpch基准测试定义的22个查询的运行时间结果
Apache Spark中的CPU-GPU混合执行
虽然Presto集成侧重于端到端GPU执行,但Apache Spark与Apache Gluten和cuDF的集成目前侧重于卸载特定的查询阶段。此功能允许将工作负载中计算最密集的部分分派给GPU,并且该策略可以最有效地利用包含CPU和GPU节点的混合集群中的GPU资源。
例如,TPC-DS Query 95 SF100的第二阶段是计算密集型的,使用CPU的集群运行速度会很慢。将此阶段卸载到GPU可带来显著的性能提升。集群上剩余的CPU容量可用于其他查询或工作负载。
如图4所示,即使TableScan的第一阶段使用CPU执行,当第二阶段卸载到GPU时,CPU和GPU之间的高效互操作性仍能实现更快的总运行时间。"CPU only"条件使用八个vCPU,"First Stage CPU+GPU"使用八个vCPU和一个NVIDIA T4 GPU (g4dn.2xlarge)。
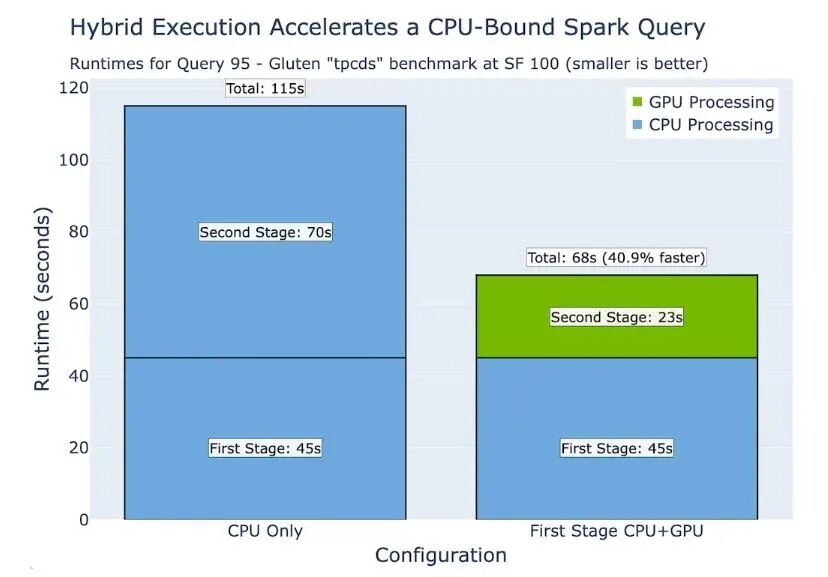
图4. SF100下,使用单节点单GPU执行Gluten tpcds中定义的查询95的运行时间结果
参与GPU驱动的大规模数据分析
在共享执行引擎Velox中推动GPU加速,为整个数据处理生态系统中的各种下游系统释放了性能增益。团队正在与多家公司的贡献者合作,在Velox中实现可重用的GPU运算符,进而加速Presto、Spark(通过Gluten)和其他系统。这种方法减少了重复工作,简化了维护,并在开放数据栈中引入了新的创新。
我们很高兴与社区分享这项开源工作并听取您的反馈。我们邀请您:
•尝试使用Velox GPU后端对Presto进行基准测试•献新的运算符或测试工作负载•加入关于Velox、cuDF和Presto的讨论•查看GitHub代码库:•Velox•Presto•Apache Gluten•cuDF
致谢
许多开发者为这项工作做出了贡献。IBM的贡献者包括Zoltán Arnold Nagy, Deepak Majeti, Daniel Bauer, Chengcheng Jin, Luis Garcés-Erice, Sean Rooney, 和 Ali LeClerc。NVIDIA的贡献者包括Greg Kimball, Karthikeyan Natarajan, Devavret Makkar, Shruti Shivakumar, 和 Todd Mostak。